YOLOv8由pt文件中读取模型信息
Pytorch的pt模型文件中保存了许多模型信息,如模型结构、模型参数、任务类型、批次、数据集等
在先前的YOLOv8实验中,博主发现YOLOv8在预测时并不需要指定任务类型,因为这些信息便保存在pt模型中,那么,今天我们便来看看,其到底是如何加载这些参数的。
我们首先对pt文件进行一个简单介绍:
pt文格式
pt格式文件是PyTorch中用于保存张量数据的文件格式。与pth文件类似,pt文件也常用于模型的保存和加载,但更侧重于保存单个张量或一组张量数据。通过pt文件,我们可以方便地将张量数据持久化,并在需要时重新加载使用。
张量(Tensor)是PyTorch中的核心数据结构,用于表示多维数组。在深度学习中,张量常用于存储模型的参数、输入数据、中间结果等。因此,掌握pt文件的保存和加载方法对于PyTorch的使用者来说至关重要。
pt文件与pth的区别
pt和.pth都是PyTorch模型文件的扩展名,但是它们的区别在于.pt文件是保存整个PyTorch模型的,而.pth文件只保存模型的参数。(其实现在似乎并没有区别了)
因此,如果要加载一个,pth文件,需要先定义模型的结构,然后再加载参数;而如果要加载一个,pt文件,则可以直接加载整个模型。
如何保存pt格式文件
在PyTorch中,我们可以使用torch.save()函数将张量数据保存到pt文件中。
下面是一个简单的示例:
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 将张量保存到pt文件中
torch.save(tensor, 'tensor.pt')
在上面的代码中,我们首先创建了一个二维张量tensor,然后使用torch.save()函数将其保存到名为tensor.pt的文件中。保存的文件将包含张量的数据和元数据,以便在加载时能够准确地恢复张量的结构和内容。
除了保存单个张量外,我们还可以保存多个张量到一个pt文件中。这可以通过将多个张量放入一个字典或列表中,然后将整个字典或列表保存到文件中实现。
例如:
# 创建多个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([[4, 5], [6, 7]])# 将张量放入字典中
tensors_dict = {'tensor1': tensor1, 'tensor2': tensor2}# 将字典保存到pt文件中
torch.save(tensors_dict, 'tensors_dict.pt')
如何加载pt格式文件
加载pt文件同样使用torch.load()函数。
下面是一个加载pt文件的示例:
# 加载单个张量的pt文件
loaded_tensor = torch.load('tensor.pt')
print(loaded_tensor)# 加载包含多个张量的字典的pt文件
loaded_dict = torch.load('tensors_dict.pt')
print(loaded_dict['tensor1'])
print(loaded_dict['tensor2'])
在加载单个张量的pt文件时,我们直接调用torch.load()函数并传入文件名即可。加载得到的loaded_tensor将是一个与原始张量结构和内容相同的张量对象。
当加载包含多个张量的字典的pt文件时,我们同样使用torch.load()函数。加载得到的loaded_dict将是一个字典对象,其中包含了我们在保存时放入的所有张量。我们可以通过字典的键来访问这些张量。
强烈建议只保存模型参数,而非保存整个网络。PyTorch 官方也是这么建议的。
torch.save(net.state_dict(),path2)#只保留模型参数
(只保存模型参数)是官方推荐的方法,运行速度快,且占空间较小。需要注意的是 net.state_dict() 是将网络参数保存为字典形式(OrderedDict),load_state_dict() 加载的并不是网络参数的pth文件,而是字典。
pt文件保存神经网络
在评估时,记住一定要使用model.eval()来固定dropout和归一化层,否则每次推理会生成不同的结果。
import torch, glob, cv2
from torchvision import transforms
import numpy as np
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module): # 神经网络部分用你自己的def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 2, 1) # nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)self.conv2 = nn.Conv2d(32, 64, 3, 2, 1)self.conv3 = nn.Conv2d(64, 128, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(6272, 128) # 6272=128*7*7self.fc2 = nn.Linear(128, 8)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.relu(x)x = self.conv3(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)self.output = F.log_softmax(x, dim=1)out1 = xreturn self.output,out1def predict_mine():model=Net()model.load_state_dict(torch.load("model.pt"))print(model)images=torch.rand((1,1,64,64))x=model(images)print(x)
def torch_script_save():model=Net()
if __name__ == '__main__':save_model()predict_mine()

可以看到,我们可以通过pt文件读取出来下面的信息:

同时,我们也看到,我们虽然可以使用pt文件保存模型结构,但我们在推理时,依旧需要我们能够生成Net对象才能加载其数据,这其实很不方便,那么,有什么办法可以真正的将模型结构保存进去,让我们在推理过程中不需要再定义相关的类与对象呢,先前博主所使用的ONNX便是其中的一种,但它其实是另一种文件结构了,pt文件真的就不能摆脱环境吗,答案是否定的,TorchScript模型便解决了这个问题。
TorchScript模型
事实上,PyTorch提供了两种主要的模型保存和加载机制,一种是基于Python的序列化,另一种是TorchScript。
普通的PyTorch模型(基于Python的序列化):
- 保存: 使用
torch.save(model.state_dict(), 'model_path.pth'),它保存了模型的权重和参数,但不保存模型的结构。(当然也是可以保存的,但我们需要处理一下才能用,比如定义好Net类)- 加载: 首先,您需要有模型的类定义。 创建该类的一个实例。 使用
model.load_state_dict(torch.load('model_path.pth'))来加载权重。
特点:- 需要
Python环境和模型的原始代码来加载和运行模型。 保存的文件是Python特定的,并且依赖于特定的类结构。 主要用于继续训练或在Python环境中进行推断。
TorchScript模型:
TorchScript是PyTorch的一个子集,它创建了一个可以独立于Python运行的序列化模型。 生成方法:
Tracing: 使用torch.jit.trace方法。这涉及到通过模型运行一个输入示例,从而跟踪模型的执行路径。Scripting: 使用torch.jit.script方法。这转化Python代码到TorchScript,允许更复杂的模型和控制流。- 保存: 使用
torch.jit.save(traced_model, 'model_path.pt')。- 加载: 使用torch.jit.load(‘model_path.pt’)。注意,加载不需要原始的模型类定义。
特点:
- 可以在没有
Python运行时的环境中运行,如C++。- 提供了一种方法,将模型从
Python转移到其他平台或部署环境。- 包含模型的完整定义,包括结构、权重和参数。
Tracing方法:
example_input = torch.randn(1, 10)
traced_model = torch.jit.trace(model, example_input)
torch.jit.save(traced_model, 'traced_model.pt')
Scripting方法:
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, 'scripted_model.pt')
加载模型:
loaded_model = torch.jit.load('model_path.pt')
例程:
import torch
import torch.nn as nnclass SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 10)def forward(self, x):return self.fc(x)model = SimpleModel()# Tracing
example_input = torch.randn(1, 10)
traced_model = torch.jit.trace(model, example_input)
torch.jit.save(traced_model, 'traced_simple_model.pt')# Scripting
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, 'scripted_simple_model.pt')# 加载模型
loaded_model = torch.jit.load('traced_simple_model.pt')
我们采用TorchScript结构去执行先前的Net
def torch_script_save():model=Net()example_input =torch.rand((1,1,64,64))traced_model = torch.jit.trace(model, example_input)torch.jit.save(traced_model, 'traced_simple_model.pt')# Scriptingscripted_model = torch.jit.script(model)torch.jit.save(scripted_model, 'scripted_simple_model.pt')
def predict_script():model1=torch.jit.load("traced_simple_model.pt")image =torch.rand((1,1,64,64))print(model1)model1.eval()x=model1(image)print(x)model2=torch.jit.load("scripted_simple_model.pt")image =torch.rand((1,1,64,64))print(model2)model2.eval()x=model2(image)print(x)

yaml文件内容如下:
{'nc': 1000,
'scales': {'n': [0.33, 0.25, 1024], 's': [0.33, 0.5, 1024], 'm': [0.67, 0.75, 1024], 'l': [1.0, 1.0, 1024], 'x': [1.0, 1.25, 1024]},
'backbone': [[-1, 1, 'Conv', [64, 3, 2]], [-1, 1, 'Conv', [128, 3, 2]], [-1, 3, 'C2f', [128, True]], [-1, 1, 'Conv', [256, 3, 2]], [-1, 6, 'C2f', [256, True]], [-1, 1, 'Conv', [512, 3, 2]], [-1, 6, 'C2f', [512, True]], [-1, 1, 'Conv', [1024, 3, 2]], [-1, 3, 'C2f', [1024, True]]],'head': [[-1, 1, 'Classify', ['nc']]], 'scale': 'n','yaml_file': 'yolov8n-cls.yaml', 'ch': 3}
相关文章:
YOLOv8由pt文件中读取模型信息
Pytorch的pt模型文件中保存了许多模型信息,如模型结构、模型参数、任务类型、批次、数据集等 在先前的YOLOv8实验中,博主发现YOLOv8在预测时并不需要指定任务类型,因为这些信息便保存在pt模型中,那么,今天我们便来看看…...

js遍历效率
1w条数据,遍历效率 1、for 15s let t(new Date()).getTime()let a[]for(var i 0; i < 100000; i){a.push({id:i,val:i})}let ts[]for(var i 0; i < a.length; i){if(a[i].val!2 && a[i].val!4 && a[i].val!8){ts.push(a[i])}}let c(new D…...
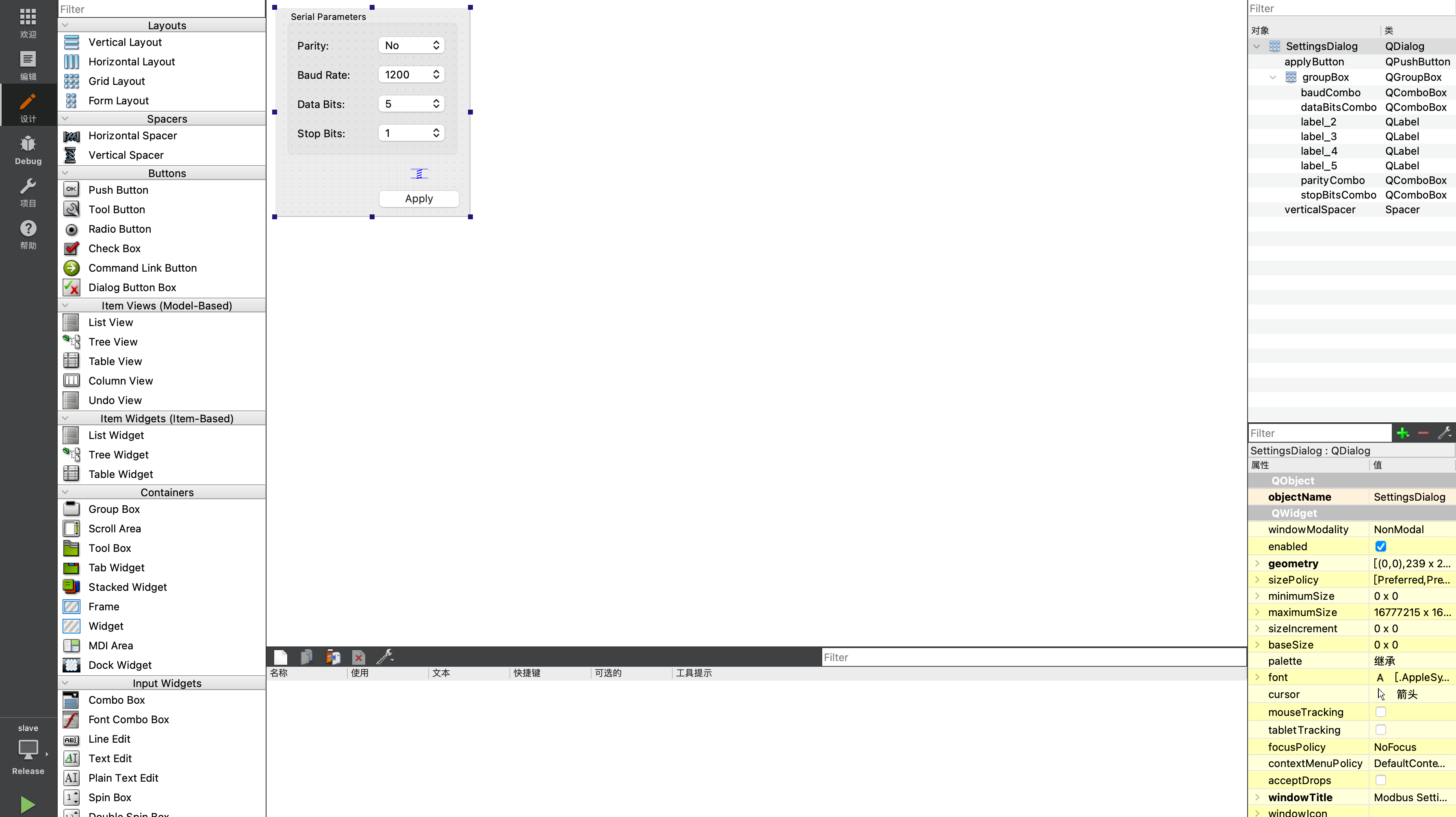
QModbus例程分析
由于有一个Modebus上位机的需要,分析一下QModbus Slave的源代码,方便后面的开发。 什么是Modbus Modbus是一种常用的串行通信协议,被广泛应用于工业自动化领域。它最初由Modicon(目前属于施耐德电气公司)于1979年开发…...

Vue万字学习笔记(入门1)
目录 简介 Vue是什么 渐进式框架 单文件组件 API 风格 选项式 API (Options API) 组合式 API (Composition API) 创建一个 Vue 应用 挂载应用 DOM 中的根组件模板 应用配置 多个应用实例 模板语法 文本插值 原始 HTML Attribute 绑定 简写…...

Cesium手动建模模型用Cesiumlab转3D Tiles模型位置不对,调整模型位置至指定经纬度
Cesium加载3Dtiles模型的平移和旋转_3dtiles先旋转再平移示例-CSDN博客 Cesium 平移cesiumlab生产的3Dtiles切片模型到目标经纬度-CSDN博客 【ArcGISCityEngine】自行制作Lod1城市大尺度白膜数据_cityengine 生成指定坐标集指定区域的白模-CSDN博客 以上次ArcGISCityEngine制…...

学习C语言第23天(程序环境和预处理)
1. 程序的翻译环境和执行环境 在ANSIC的任何一种实现中,存在两个不同的环境 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。 第2种是执行环境,它用于实际执行代码。 2. 详解编译链接 2.1 翻译环境 每个源文件单独经过编…...

Ubuntu22.04安装
使用Vmware安装好后 首先执行下面命令,不然每次打开终端会出现To run a command as administrator (user root)… touch ~/.sudo_as_admin_successful换源 参考 sudo cp /etc/apt/sources.list /etc/apt/sources.list.baksudo gedit /etc/apt/sources.list清空…...

从入门到自动化:一篇文章掌握Python的80%
Python作为一种高级编程语言,以其简洁明了的语法和强大的功能性,在全球编程社区内享有极高的声誉。本文将带领你从Python的基础语法入手,介绍其常用库的应用,以及如何将Python用于数据分析、网络爬虫和简单的自动化任务࿰…...

开源的主流机器学习框架
主流的开源机器学习框架包括: 1. TensorFlow:由Google开发和维护的深度学习框架,广泛用于生产环境和研究。支持多种平台,并具有丰富的工具和库支持。 2. PyTorch:由Facebook开发的深度学习框架,以其动态计…...

RabbitMQ:发送者的可靠性之配置发送者重试机制
文章目录 为什么需要重试机制?如何配置重试机制?测试重试机制使用重试机制的注意事项 在使用消息队列(MQ)系统时,网络故障是不可避免的问题,尤其是在与RabbitMQ等服务交互时。如果生产者在发送消息时遇到网…...

基于深度学习的大规模MIMO信道状态信息反馈
MIMO系统 MIMO系统利用多个天线在发送端和接收端之间建立多条独立的信道,从而使得同一时间可以传输多个数据流,从而使得同一之间可以传输多个数据流,提高数据传输速率。 优势 增加传输速率和容量,提高信号覆盖范围和抗干扰能力…...

在Docker中部署Rasa NLU服务
最近因为项目需要将rasa nlu配置到docker容器中供系统调用,本篇主要整理该服务的docker配置过程。 本篇的重点在于docker的使用,不在Rasa NLU。 系统环境:Ubuntu 18.04.6 1. Rasa介绍 Rasa是一个开源的机器学习框架,专为构建基于文…...

SQL语句创建数据库(增删查改)
SQL语句 一.数据库的基础1.1 什么是数据库1.2 基本使用1.2.1 连接服务器1.2.2 使用案例 1.2 SQL分类 二.库的操作2.1 创建数据库2.2 创建数据库示例2.3 字符集和校验规则2.3.1 查看系统默认字符集以及校验规则2.3.2查看数据库支持的字符集2.3.3查看数据库支持的字符集校验规则2…...

微信小程序-Vant组件库的使用
一. 在app.json里面删除style:v2 为了避免使用Vant组件库和微信小程序组件样式的相互影响 二.在app.json里面usingComponents注册Vant组件库的自定义组件 "usingComponents": {"van-icon": "./miniprogram_npm/vant-weapp/icon/index&qu…...

为什么企业需要进行能源体系认证?
通过能源体系认证,企业可以向公众和利益相关方展示其在节能减排方面的承诺和成就。这不仅提升了企业的社会责任形象,还增强了品牌的信誉度。在当今消费者更加关注环境问题的背景下,绿色企业形象有助于赢得市场和客户的认可与信任。 能源体系认…...

【日常记录-MySQL】EVENT
Author:赵志乾 Date:2024-08-07 Declaration:All Right Reserved!!! 1. 简介 在MySQL中,EVENT是一种数据库对象,其用于设定数据库任务自动执行。这些任务可以是任意有效的SQL语句&a…...

嵌入式学习day12(LinuxC高级)
由于C高级部分比较零碎,各部分之间没有联系,所以学起来比较累,多练习就好了 一丶Linux起源 寻科普|第二期:聊聊Linux的前世今生 UNIX和linux的区别: (1)linux是开发源代码的自由软件.而unix是…...

pytorch中的hook机制register_forward_hook
上篇文章主要介绍了hook钩子函数的大致使用流程,本篇文章主要介绍pytorch中的hook机制register_forward_hook,手动在forward之前注册hook,hook在forward执行以后被自动执行。 1、hook背景 Hook被成为钩子机制,pytorch中包含forwa…...

使用Gin框架返回JSON、XML和HTML数据
简介 Gin是一个高性能的Go语言Web框架,它不仅提供了简洁的API,还支持快速的路由和中间件处理。在Web开发中,返回JSON、XML和HTML数据是非常常见的需求。本文将介绍如何使用Gin框架来返回这三种类型的数据。 环境准备 在开始之前࿰…...

网工内推 | 国企运维工程师,华为认证优先,最高年薪20w
01 上海陆家嘴物业管理有限公司 🔷招聘岗位:IT运维工程师 🔷岗位职责: 1、负责对公司软、硬件系统、周边设备、桌面系统、服务器、网络基础环境运行维护、故障排除。 2、负责对各部门软件操作、网络安全进行检查、指导。 3、负责…...

OpenClaw技能开发入门:为Qwen3-32B定制专属文件分类器
OpenClaw技能开发入门:为Qwen3-32B定制专属文件分类器 1. 为什么需要文件分类技能 上周我的桌面又变成了"数字垃圾场"——下载文件夹里混杂着PDF报告、会议录音、临时截图和一堆未命名的压缩包。当我第三次因为找不到客户合同而错过deadline时ÿ…...

Linux内核中的虚拟化技术
Linux内核中的虚拟化技术 引言 虚拟化技术是一种将物理资源抽象为虚拟资源的技术,它允许多个操作系统或应用程序在同一物理硬件上运行。Linux内核提供了丰富的虚拟化支持,包括KVM、容器、虚拟内存等。本文将深入探讨Linux内核中的虚拟化技术,…...

终极游戏模组管理器:XXMI启动器让模组管理变得前所未有的简单
终极游戏模组管理器:XXMI启动器让模组管理变得前所未有的简单 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一个开源的多游戏模组管理平台,…...

如何快速创建专业作品集:awesome-portfolio-websites完全指南
如何快速创建专业作品集:awesome-portfolio-websites完全指南 【免费下载链接】awesome-portfolio-websites A community maintained open source project aimed at making a personal portfolio for researchers, developers, and analysts simple, fast, and less…...

保姆级教程:用Python和Paho-MQTT库5分钟搭建你的第一个物联网通信Demo
5分钟实战:用PythonPaho-MQTT构建物联网通信原型 在智能家居设备突然向你手机推送报警消息时,在共享单车锁车后立即完成计费时,背后都是MQTT协议在高效运作。作为物联网领域的"HTTP协议",MQTT凭借其轻量级和发布/订阅模…...

体验ai辅助开发:在快马平台与ai协作构建智能任务管理应用
最近尝试用AI辅助开发了一个任务管理应用,整个过程就像有个经验丰富的编程伙伴在旁边随时提供建议。在InsCode(快马)平台上,这种协作体验特别流畅,分享下具体实现过程: 初始框架搭建 输入"创建一个Vue3任务列表应用ÿ…...

突破暗黑破坏神2单机限制:PlugY全方位增强工具深度指南
突破暗黑破坏神2单机限制:PlugY全方位增强工具深度指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 暗黑破坏神2作为ARPG游戏的经典之作,其…...
)
告别Frida注入:手把手教你用IDA和010 Editor修改TikTok的libsscronet.so实现抓包(Android 30.8.4)
静态逆向实战:不依赖Frida修改TikTok核心通信模块实现抓包 在移动安全研究领域,动态注入工具如Frida一直是分析应用协议的主流选择。但当面对TikTok这类采用自研通信协议的应用时,频繁的版本更新会导致动态注入方案需要持续维护。本文将展示一…...

2026.4.5
线段树+lazy标记#include<bits/stdc.h> using namespace std; #define int long long #define N 100004 int num[N],tree[4*N],n,q,ans; int len[4*N],lazy[4*N]; char op; int a1,a2,a3; void updata(int xx) {tree[xx]tree[xx*2]tree[xx*21];len[xx]len[xx*…...

nunif iw3-desktop:实时将PC桌面转换为3D流媒体的完整教程
nunif iw3-desktop:实时将PC桌面转换为3D流媒体的完整教程 【免费下载链接】nunif Misc; latest version of waifu2x; 2D video to stereo 3D video conversion 项目地址: https://gitcode.com/gh_mirrors/nu/nunif 想要将你的普通PC桌面实时转换为沉浸式3D立…...