从TiDB迁移到OceanBase的实践分享
本文来自OceanBase热心用户的分享
近期,我们计划将业务数据库从TiDB迁移到OceanBase,但面临的一个主要挑战是如何更平滑的完成这一迁移过程。经过研究,了解到OceanBase提供的OMS数据迁移工具能够支持从TiDB到OceanBase的迁移,并且它还具有数据增量同步的功能,不过需要依赖Kafka的支持。为了确保迁移的顺利进行,我们提前进行了全面的测试,以验证整个数据同步的可行性。以下是我们的测试记录,供大家参考和讨论。
环境介绍
以下各种组件安装过程不详细说明,具体安装过程在各产品官方网站都有详细说明,后面只介绍具体的配置过程
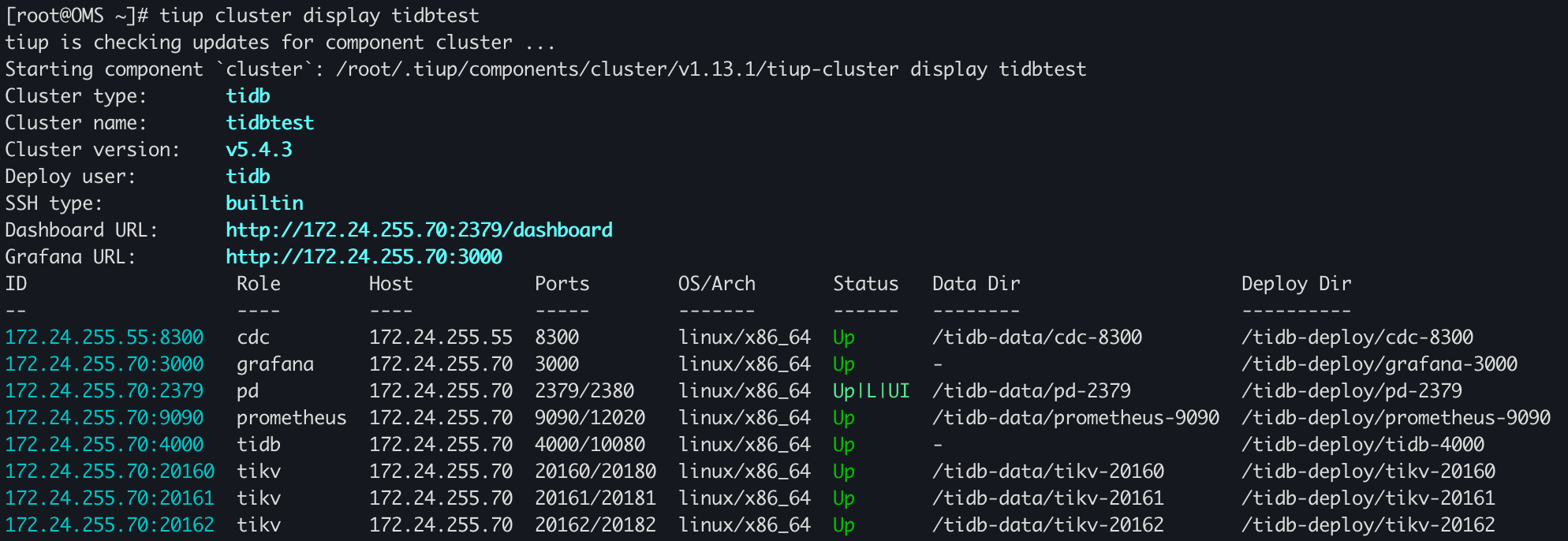
TiDB环境
TiDB版本:v5.4.3
TiDB的部署是在一台单机上混部了TiDB Server、TiKV以及PD,TiCDC单节点部署在另外一台机器上
| 角色 | 机器 | 端口 |
| TiDB Server | 172.24.255.70 | 4000 |
| TiKV | 172.24.255.70 | 20160 |
| TiKV | 172.24.255.70 | 20161 |
| TiKV | 172.24.255.70 | 20162 |
| PD | 172.24.255.70 | 2379 |
| TiCDC | 172.24.255.55 | 8300 |
[root@OB3 bin]# ./cdc cli capture list --pd=http://172.24.255.70:2379
[{"id": "c0769fd8-78fa-4841-8103-586099d8fcf6","is-owner": true,"address": "172.24.255.55:8300"}
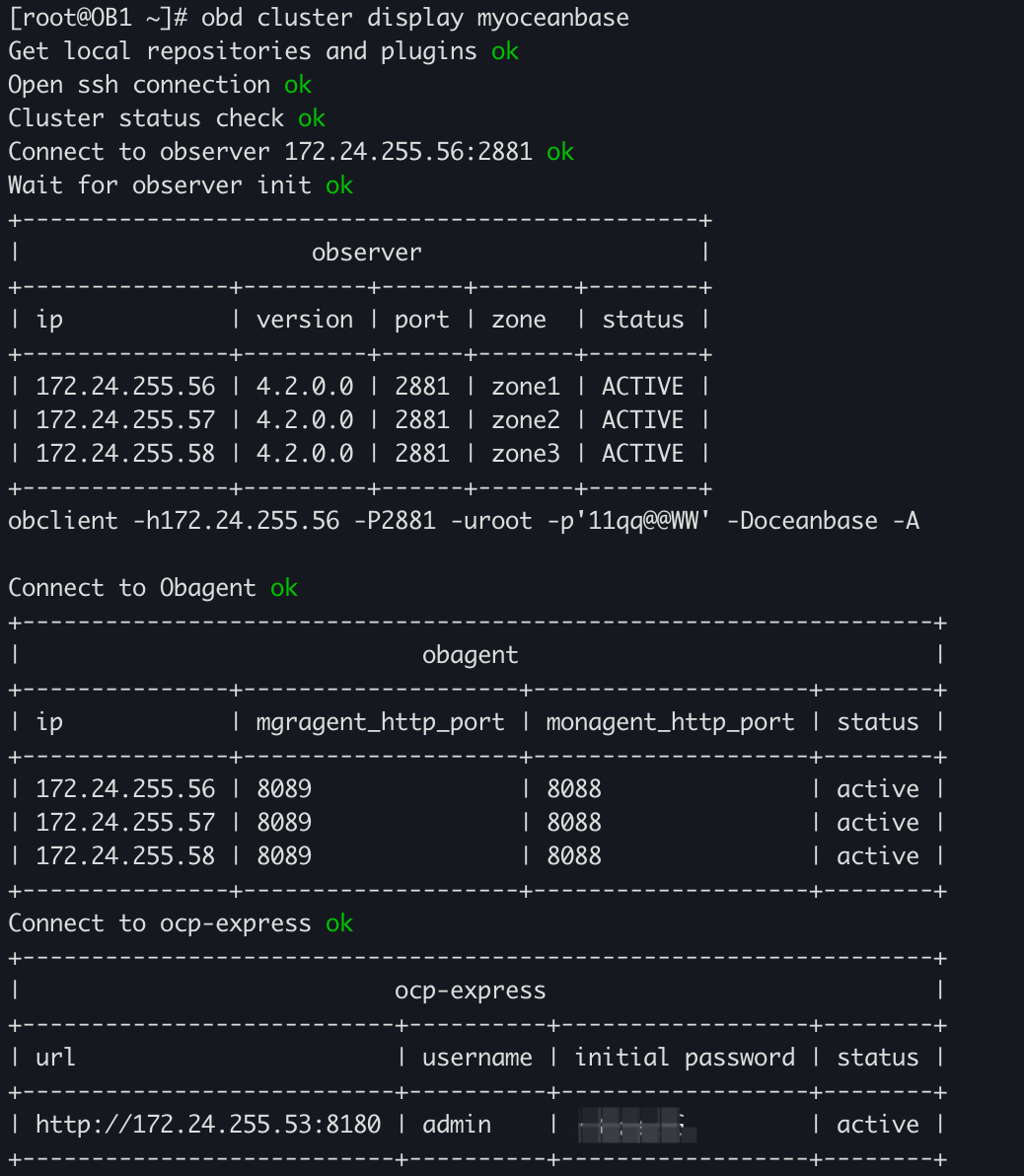
]OceanBase环境
OceanBase版本:V4.2.0_CE
| 角色 | 机器 | 端口 |
| OBServer | 172.24.255.56 | 2881 |
| OBServer | 172.24.255.57 | 2881 |
| OBServer | 172.24.255.58 | 2881 |
| OBProxy | 172.24.255.56 | 2883 |
| OBProxy | 172.24.255.57 | 2883 |
Kafka环境
Kafka版本:3.1.0(TiCDC目前支持的最高版本是3.1.0版本)
Zookeeper版本:3.6.3
这里做测试,所以Kafka和zookeeper都是单机部署,没有采用集群部署,zookeeper用的是3.1.0版本自带的zookeeper,实际效果是一样的。
| 角色 | 机器 | 端口 |
| Kafka:broker | 172.24.255.55 | 9092 |
| zookeeper | 172.24.255.55 | 2181 |
[root@OB3 kafka]# ./bin/kafka-broker-api-versions.sh --bootstrap-server 172.24.255.55:9092 --version
3.1.0 (Commit:37edeed0777bacb3)[root@OB3 bin]# ./zookeeper-shell.sh 172.24.255.55:2181 version
Connecting to 172.24.255.55:2181
ZooKeeper CLI version: 3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMTOMS环境
OMS版本:V4.1.1_CE
OMS采用的单节点部署
| 角色 | 机器 |
| OMS | 172.24.255.70 |
配置过程
创建TiCDC同步任务
TiCDC支持向mysql兼容、tidb以及Kafka中同步数据,这里因为需要OMS同步TiDB的增量数据,而增量数据是从Kafka中获取,因此需要创建TiCDC到Kafka的同步任务,创建示例如下:
./cdc cli changefeed create --pd=http://172.24.255.70:2379 \
--sink-uri="kafka://172.24.255.55:9092/test-topic?protocol=open-protocol&kafka-version=3.1.0&partition-num=1&max-message-bytes=67108864&replication-factor=1" \
--changefeed-id="simple-replication-task" --sort-engine="unified"这条命令会在TiCDC中创建一个名字为simple-replication-task的同步任务,并且会在Kafka中创建一个名字为test-topic的topic。创建完成之后,会收到如下信息
Create changefeed successfully!
ID: simple-replication-task
Info: {"sink-uri":"kafka://172.24.255.55:9092/test-topic?protocol=open-protocol\u0026kafka-version=3.1.0\u0026partition-num=1\u0026max-message-bytes=67108864\u0026replication-factor=1","opts":{"max-message-bytes":"1048588"},"create-time":"2023-10-09T15:41:57.1669333+08:00","start-ts":444815721665658881,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["*.*"],"ignore-txn-start-ts":null},"mounter":{"worker-num":16},"sink":{"dispatchers":null,"protocol":"open-protocol","column-selectors":null},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"scheduler":{"type":"table-number","polling-time":-1},"consistent":{"level":"none","max-log-size":64,"flush-interval":1000,"storage":""}},"state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v5.4.3"}在Kafka中查看topic
[root@OB3 kafka]# bin/kafka-topics.sh --bootstrap-server 172.24.255.55:9092 --list
__consumer_offsets
test-topic这里有的参数简单说明下:
- --pd:指定TiCDC任务同步源端TiDC集群的pd信息
- --changefeed-id:指定同步任务的ID,如果不指定会自动生成
- --sink-uri:同步任务下游地址,需按照下面格式配置,目前 scheme 支持 mysql/tidb/kafka/pulsar:
- [scheme]://[userinfo@][host]:[port][/path]?[query_parameters]
- --sort-engine:指定 changefeed 使用的排序引擎。因 TiDB 和 TiKV 使用分布式架构,TiCDC 需要对数据变更记录进行排序后才能输出。该项支持 unified(默认)/memory/file:
- unified:优先使用内存排序,内存不足时则自动使用硬盘暂存数据。该选项默认开启。
- memory:在内存中进行排序。 不建议使用,同步大量数据时易引发 OOM。
- file:完全使用磁盘暂存数据。已经弃用,不建议在任何情况使用。
- 其他包括:--start-ts、--target-ts、--config配置,具体可参考官网,这里不过多介绍,本次同步任务也未用到。
实际同步到下游配置,是通过sink-uri决定,这里再简单说明下sink-uri中参数含义,在这次创建的任务中--sink-uri参数内容如下:
--sink-uri="kafka://172.24.255.55:9092/test-topic?protocol=open-protocol&kafka-version=3.1.0&partition-num=1&max-message-bytes=67108864&replication-factor=1"
| 参数 | 解析 |
| 172.24.255.55 | 下游 Kafka 对外提供服务的 IP |
| 9092 | 下游 Kafka 的连接端口 |
| topic-name | 变量,使用的 Kafka topic 名字,这里使用test-topic |
| kafka-version | 下游 Kafka 版本号(可选,默认值 2.4.0,目前支持的最低版本为 0.11.0.2,最高版本为 3.1.0) |
| partition-num | 下游 Kafka partition 数量 |
| max-message-bytes | 每次向 Kafka broker 发送消息的最大数据量(可选,默认值 10MB) |
| replication-factor | Kafka 消息保存副本数(可选,默认值 1) |
| protocol | 输出到 Kafka 的消息协议,可选值有 canal-json、open-protocol、canal、avro、maxwell |
- 除了上面这些配置,另外还有加密等配置,这里没有使用加密方式。
另外,OMS 社区版仅支持 TiCDC Open Protocol,不支持其它协议,因此在sink-uri中指定protocol时,必须制定protocol=open-protocol
在以上创建完成之后,在TiDB中创建表并插入数据
MySQL [test]> create table test_table(id int primary key, name varchar(20));
Query OK, 0 rows affected (0.08 sec)MySQL [test]> show tables;
+----------------+
| Tables_in_test |
+----------------+
| test_table |
+----------------+
1 row in set (0.00 sec)MySQL [test]> insert into test_table values(1,'OceanBase');
Query OK, 1 row affected (0.00 sec)可以在Kafka中看到增量信息
[root@OB3 kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server 172.24.255.55:9092 --topic test-topic
Q{"q":"CREATE TABLE `test_table` (`id` INT PRIMARY KEY,`name` VARCHAR(20))","t":3}
Q{"u":{"id":{"t":3,"h":true,"f":11,"v":1},"name":{"t":15,"f":64,"v":"OceanBase"}}}OMS创建数据源
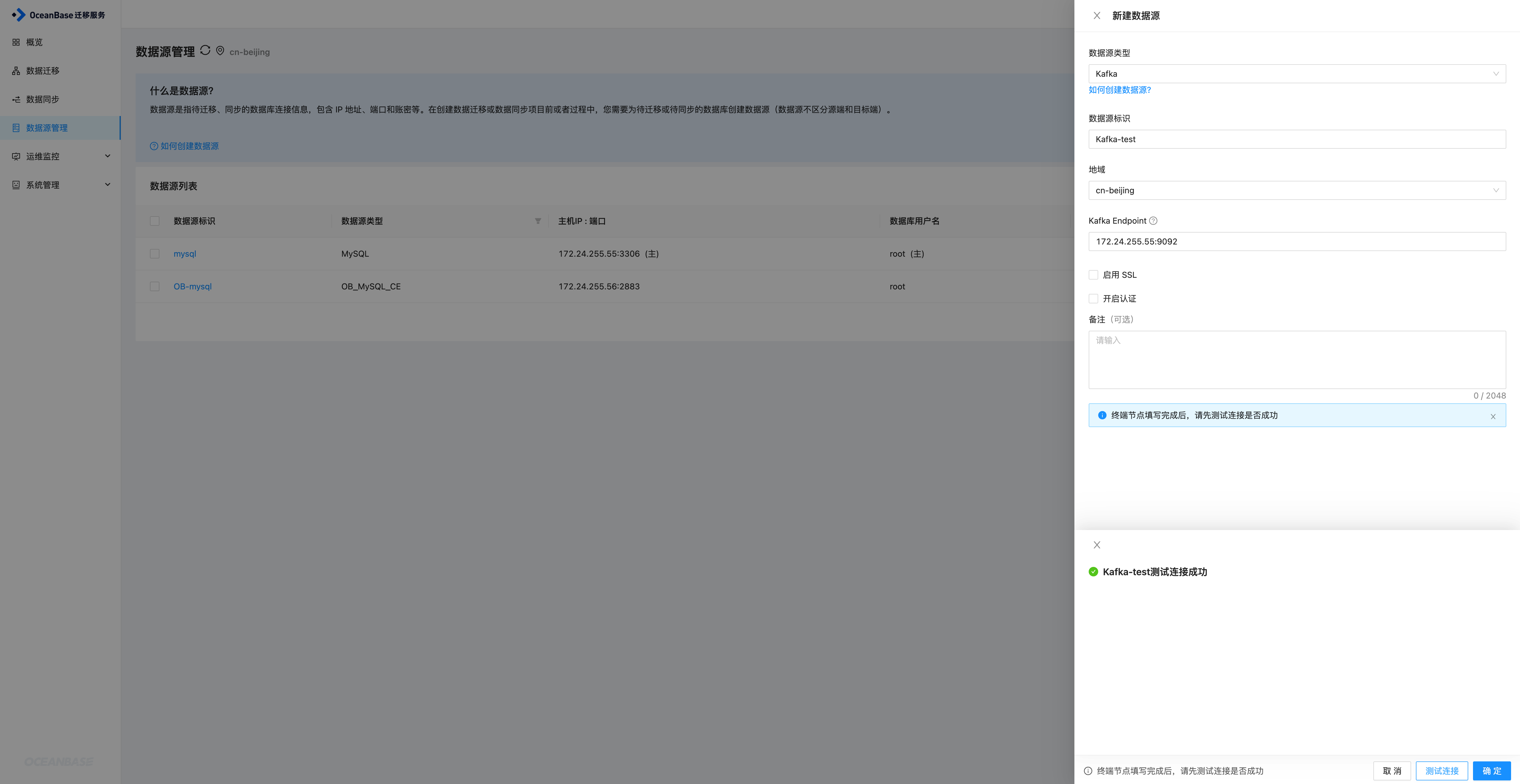
OMS上创建数据源时,需要创建两个数据源,一个是Kafka的,一个是TiDB的,在配置TiDB数据源时,需要关联Kafka数据源,因此这里先创建Kafka数据源。
Kafka数据源
进入到OMS数据源管理页面,新建数据源,选择Kakfa数据源,因为这里未使用SSL和认证,所以取消勾选,填写完成之后测试连接,连接成功之后确定即可添加成功。
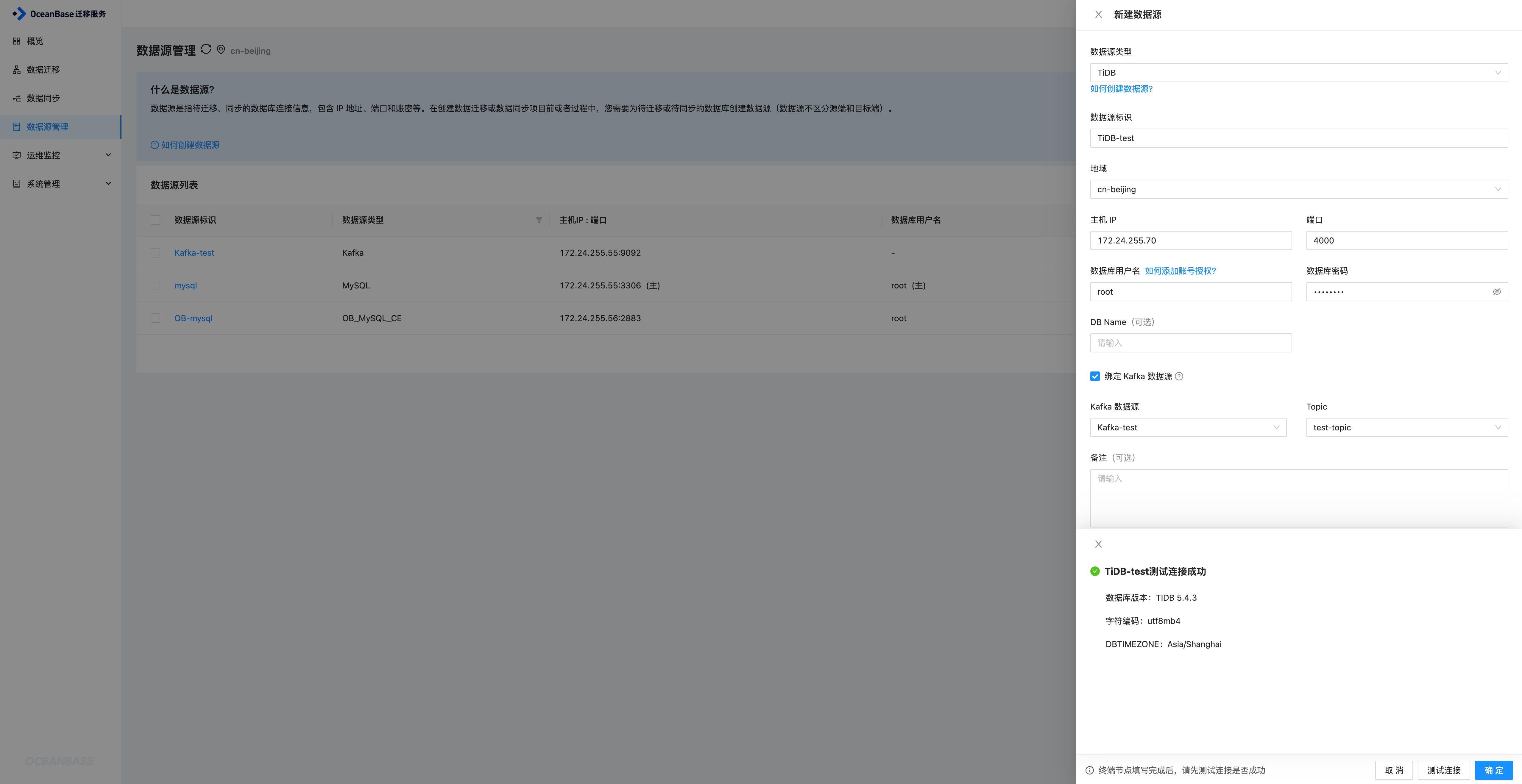
TiDB数据源
同样进入到新建数据源页面,选择TiDB数据源,填写对应的信息,同时绑定Kafka,然后关联上一步创建的Kafka即可,选择创建好的test-topic,然后进行连接测试,测试成功之后确定即可添加TiDB数据源
OceanBase数据源
方式基本相同
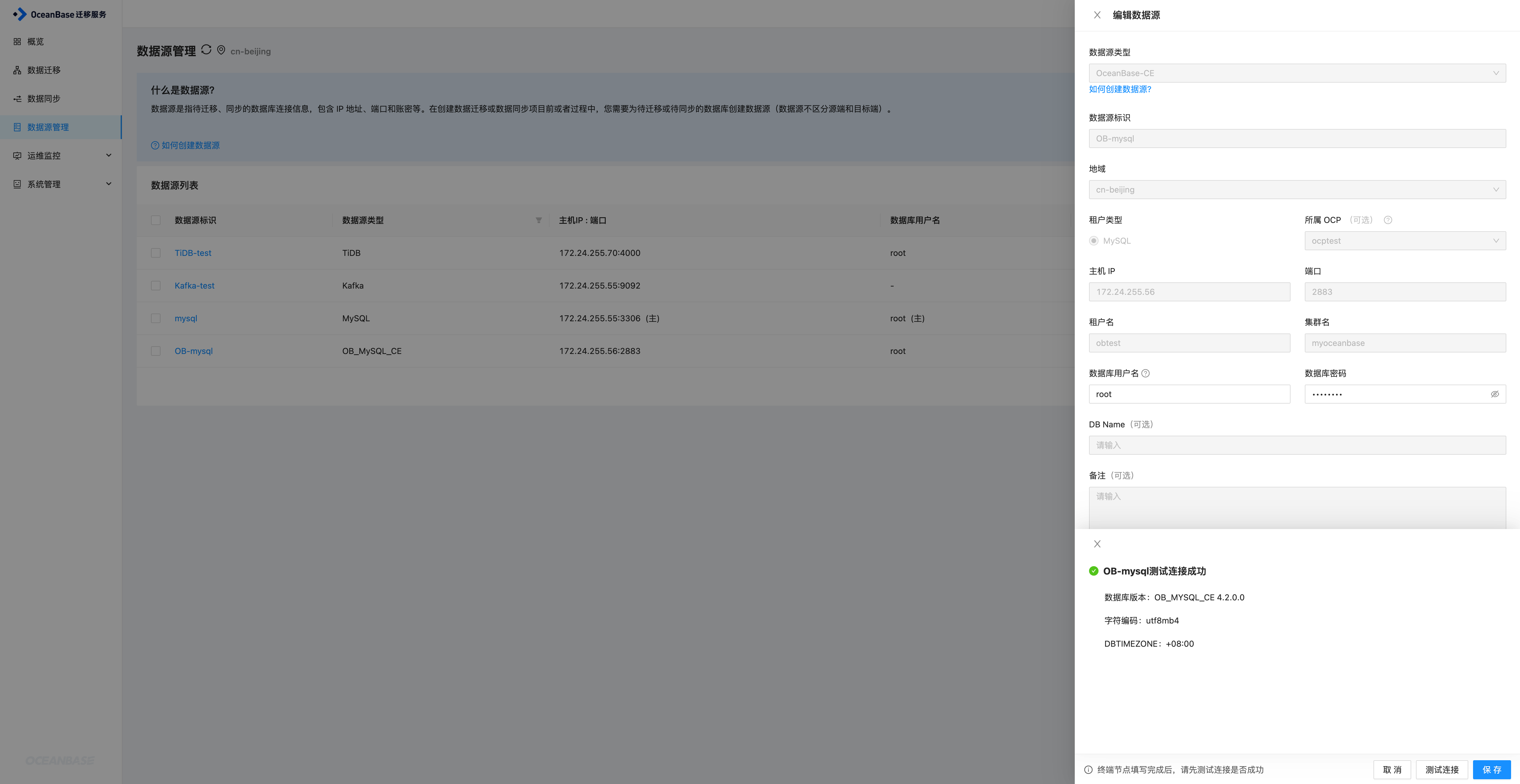
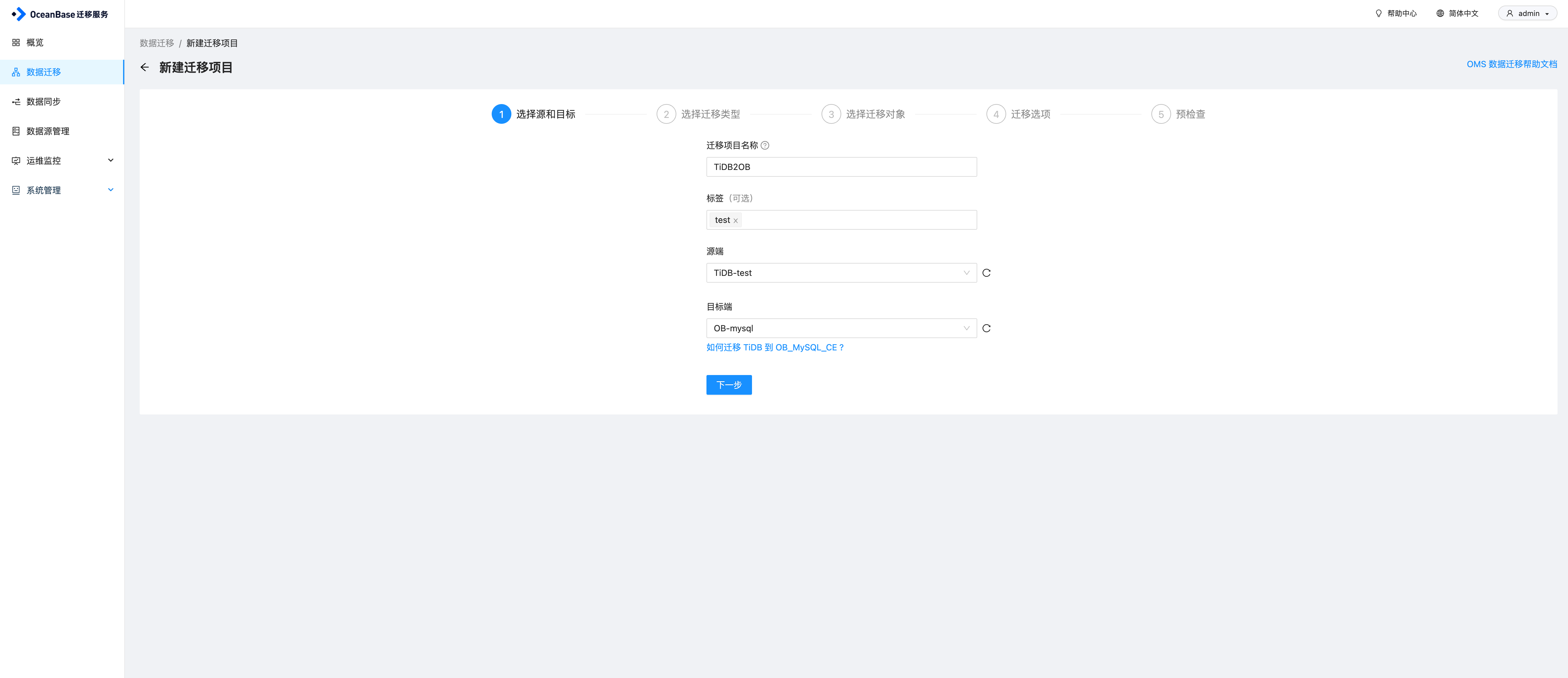
OMS创建迁移任务
在OMS数据迁移页面,点击创建迁移项目,输入项目名称,源和目标之后,点击下一步
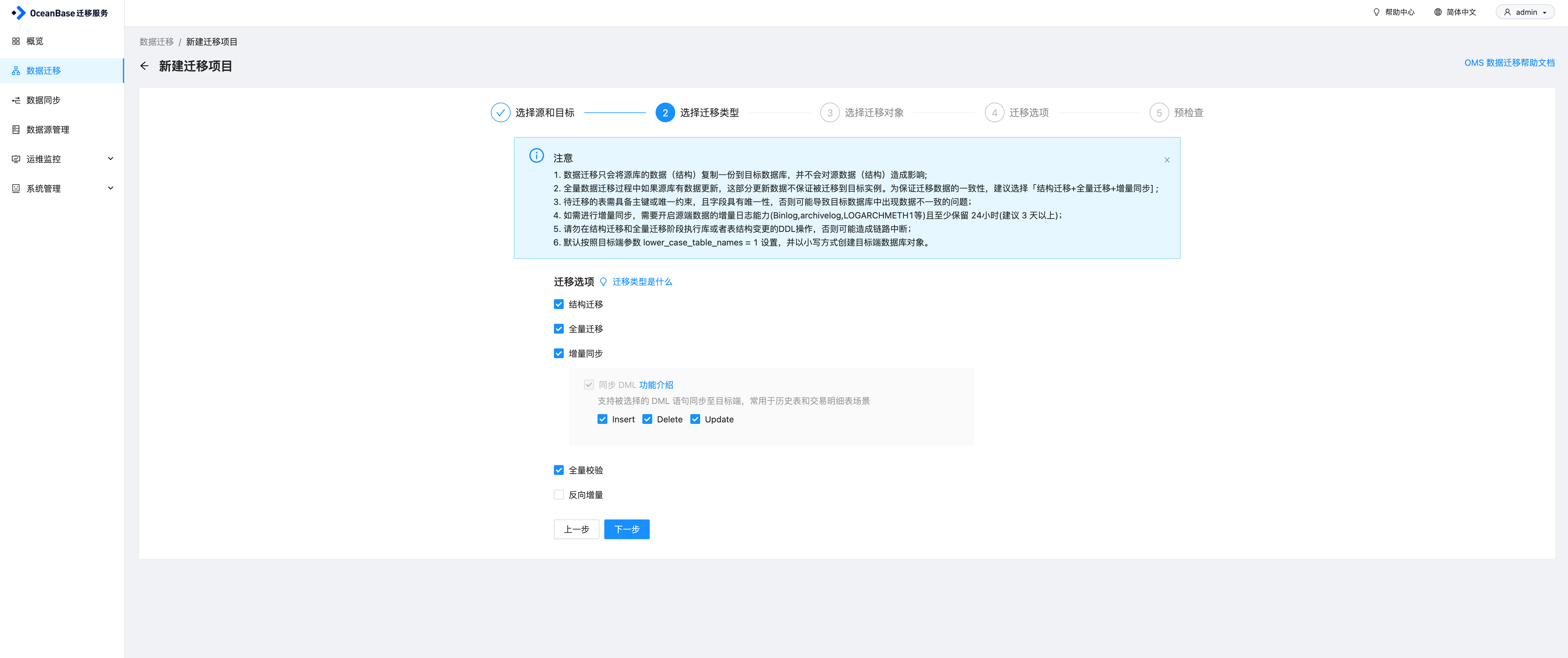
根据需求选择同步任务配置,这里勾选结构迁移、全量迁移、增量同步(Insert、Update、Delete)以及全量校验,注意这里不支持DDL同步,然后点击下一步
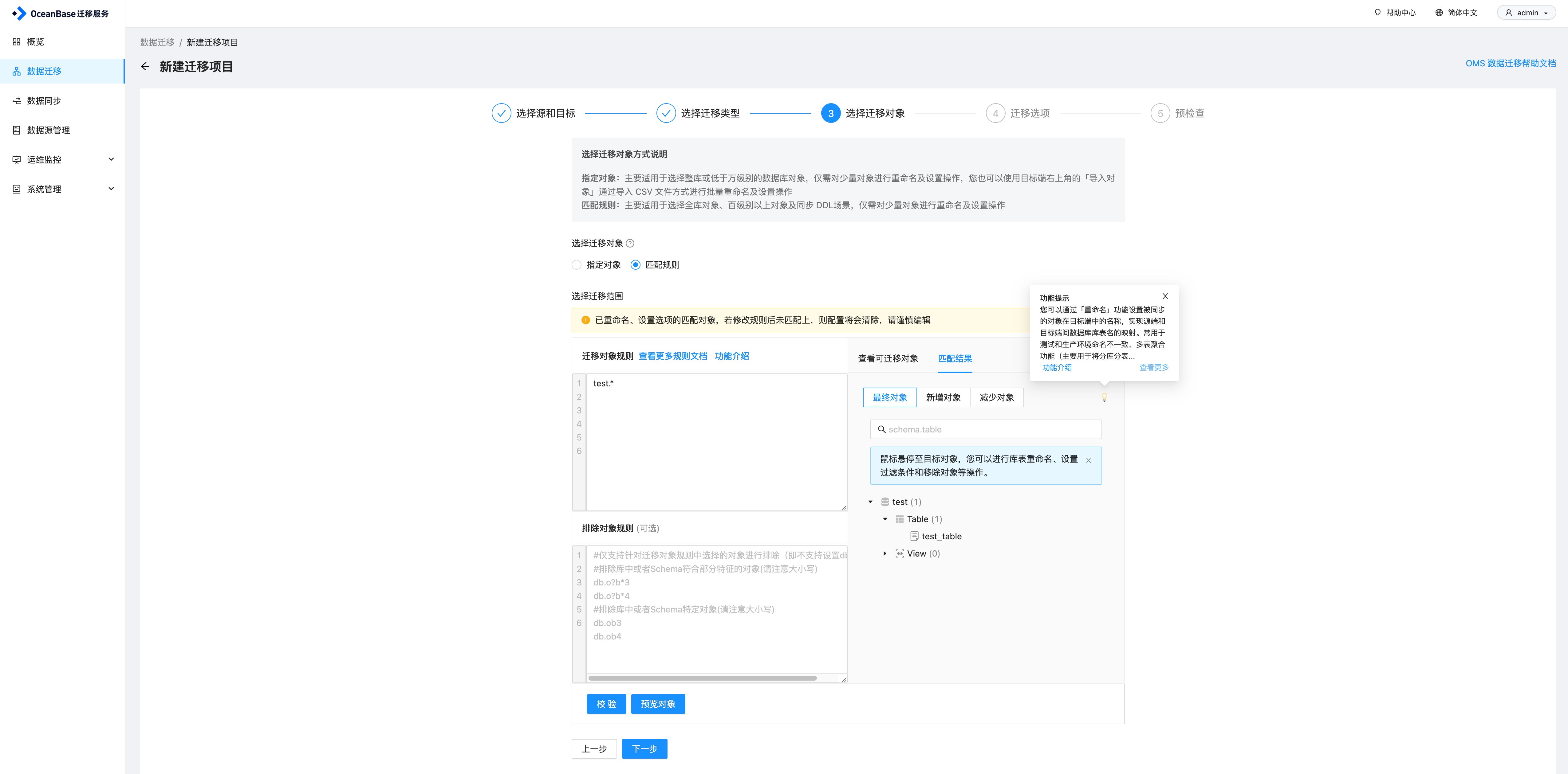
选择要同步的对象,这里可以直接指定对象,也可以选择匹配规则。我直接用了匹配规则,test库下所有对象都同步,然后点击校验,预览对象,因为目前TiDB的test库下只有test_table这张表,因此可以看到最终对象这里只显示了test_table,然后继续点击下一步
配置迁移选项,这里选择同步和校验的速率,速率越高,对资源的消耗越大。另外有高级配置中,目标端表对象存在记录时处理策略,以及是否允许索引后置,索引后置指OMS在完成对应表全量数据迁移、同步后创建非唯一键的索引,配置完成之后,进行预检查
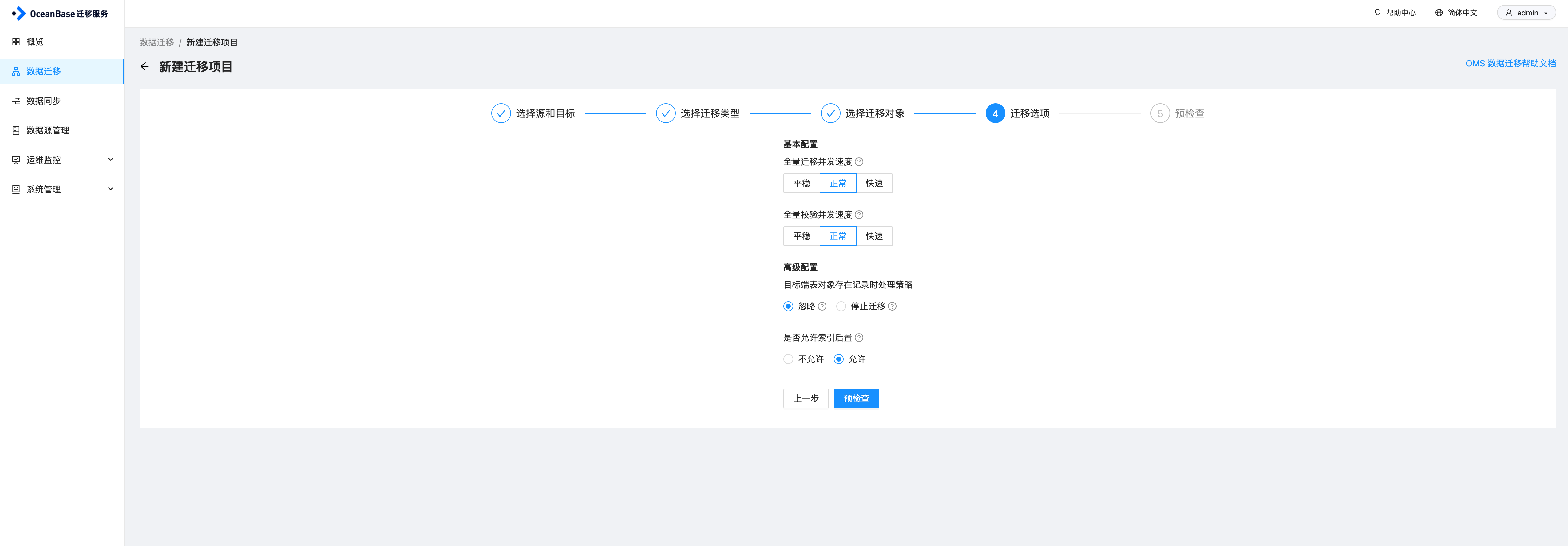
预检查如果失败,需要检查失败原因,另外对于一些告警,也建议进行修复下,然后再开始同步任务。确认无误之后启动项目即可。

任务启动之后,会先进行全量迁移,即将原表中已有数据先迁移过来,完成之后会继续执行增量同步任务。
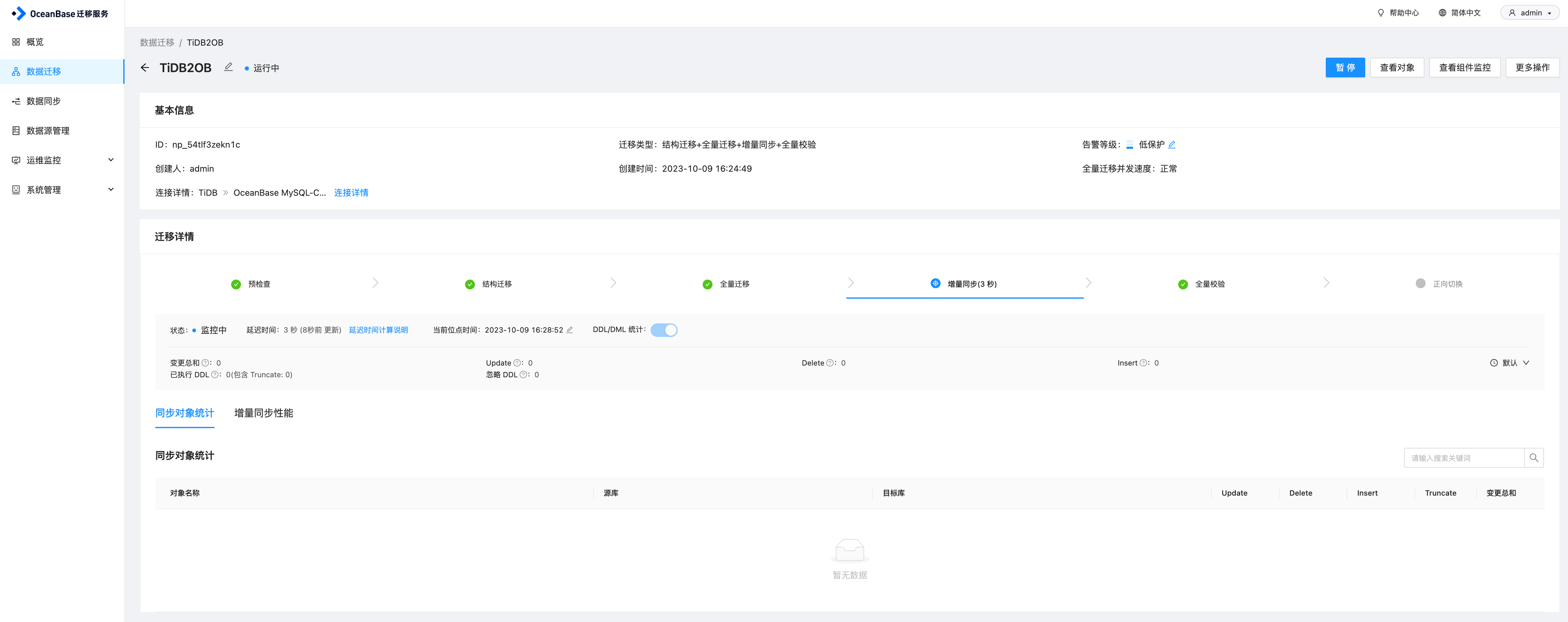
同步测试
在TiDB端执行insert、update、delete操作,可以看到在OceanBase端同步成功。
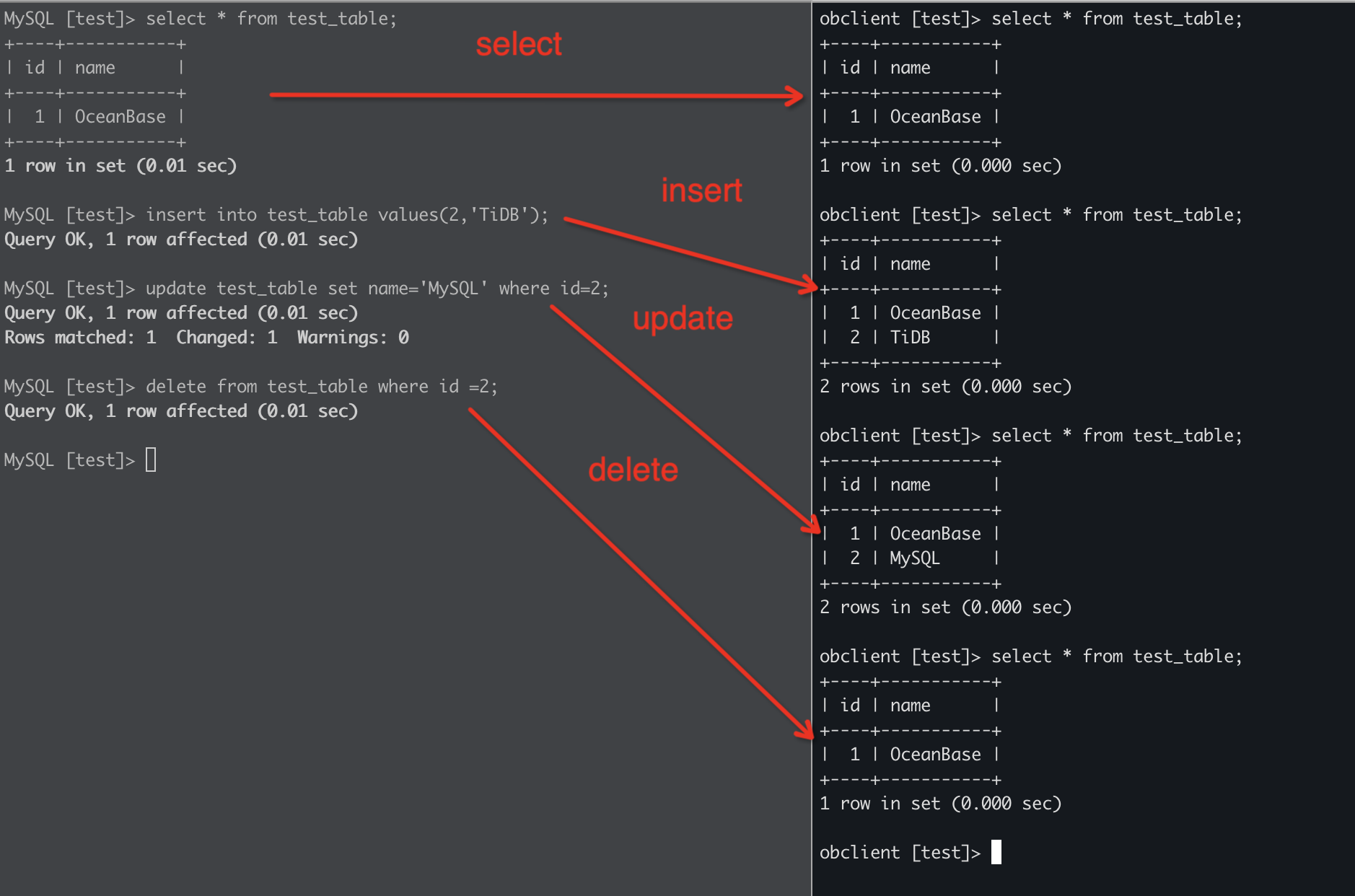
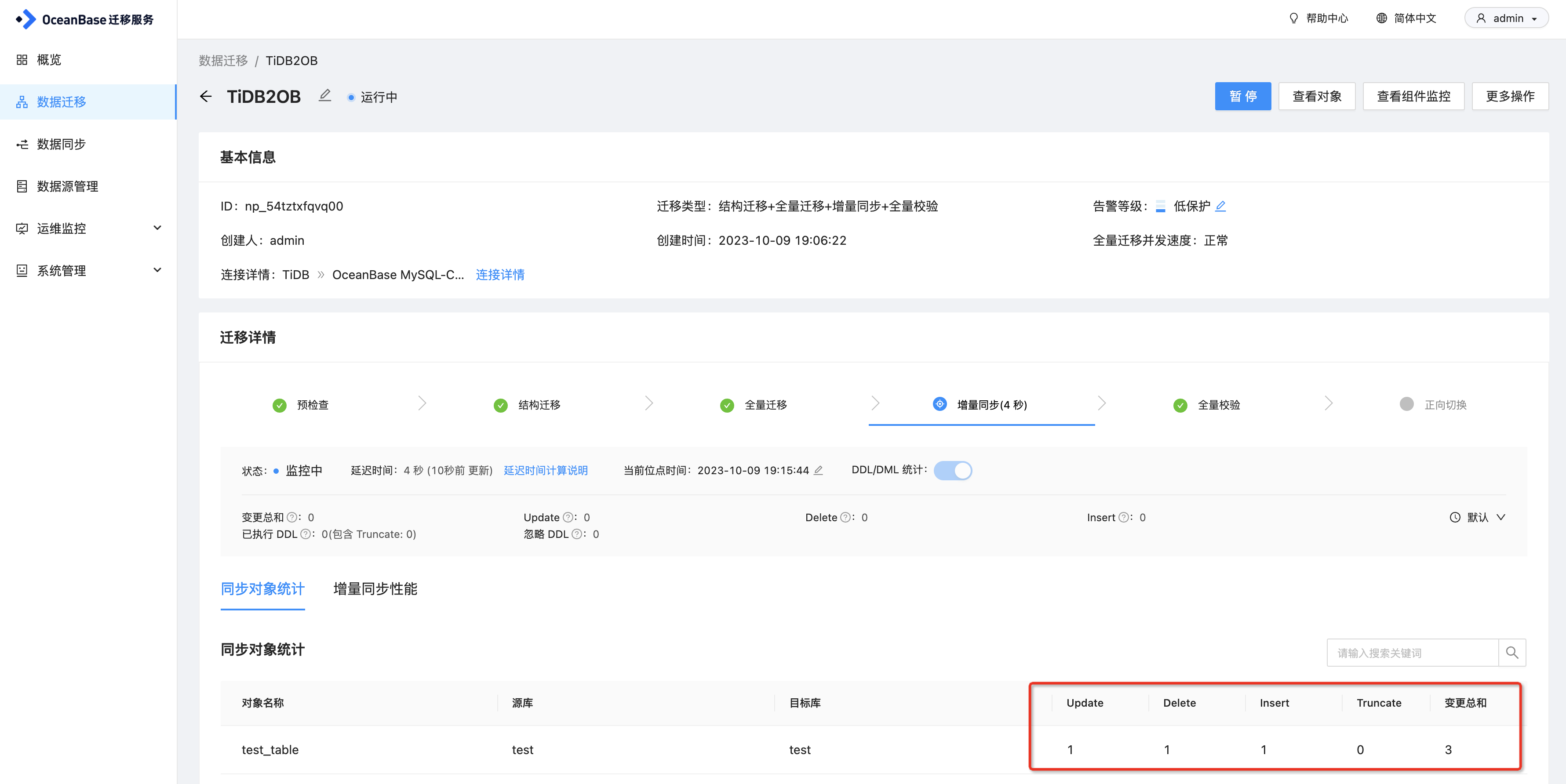
另外在OMS上可以看到变更的统计信息
相关文章:
从TiDB迁移到OceanBase的实践分享
本文来自OceanBase热心用户的分享 近期,我们计划将业务数据库从TiDB迁移到OceanBase,但面临的一个主要挑战是如何更平滑的完成这一迁移过程。经过研究,了解到OceanBase提供的OMS数据迁移工具能够支持从TiDB到OceanBase的迁移,并且…...

DL00765-光伏故障检测高分辨率无人机热红外图像细粒度含数据集4000+张
光伏发电作为清洁能源的重要组成部分,近年来得到了广泛应用。然而,随着光伏电站规模的扩大,光伏组件在运行过程中可能会出现各种故障,如热斑、遮挡、接线盒故障等。这些故障不仅会影响光伏电站的发电效率,还可能导致更…...

CICD流水线
一、CICD流水线简介 CICD概念 CI/CD流水线是现代软件开发的一个核心概念,它涉及自动化和管理软件从开发到部署的整个生命周期 概念定义 具体有三点:持续集成、持续交付、持续部署 流水线组成为:代码提交、测试、构建、部署、结果通知 二…...

Sass/Scss基础
安装sass npm install -g sass Sass/Scss释义 ASS版本3.0之前的后缀名为.sass,而版本3.0之后的后缀名.scss。 Sass (Syntactically Awesome Stylesheets) 是一个最初由 Hampton Catlin 设计并由 Natalie Weizenbaum 开发的层叠样式表语言。 Sass 是一个由buby语言编…...

【sx sb sz】Centos/Linux sx、sb、sz命令详细介绍
简介 系统版本:Centos7.6 软件版本:lrzsz 0.12.20 sx、sb、sz命令属于lrzsz程序的内容,是使用纠错协议(ZMODEM、YMODEM、XMODEM)通过拨号串行端口将一个或多个文件发送到在 PC-DOS、CP/M、Unix、VMS 及其他操作系统下运…...

【网络层】IP报文解析和网段划分
文章目录 网络层的作用IP协议协议报头格式网段划分DHCPCIDR划分方案 IP地址的数量限制私有IP地址和公网IP地址LAN和WAN 路由 网络层的作用 前面学习了应用层和传输层,应用层的作用是为用户和应用程序提供网络服务,传输层的作用是提供端口到端口的通信服…...

[GXYCTF2019]禁止套娃1
打开题目 进行常规的检测漏洞,扫描目录发现存在.git文件夹下的文件存在 <?php include "flag.php"; echo "flag在哪里呢?<br>"; if(isset($_GET[exp])) { if (!preg_match(/data:\/\/|filter:\/\/|php:\/\/|phar:\/\…...

人工智能时代,数字化工厂如何改革?提升竞争力?
在人工智能时代,数字化工厂通过数据驱动的决策、智能制造、柔性生产、物联网整合以及人机协作,实现生产效率和产品质量的全面提升,并不断创新以保持竞争力。 --题记 在人工智能时代,数字化工厂的改革…...

气膜建筑的抗风与防火性能:保障仓储的安全—轻空间
气膜建筑以其独特的结构和材料优势,为仓储设施提供了可靠的安全保障。在应对自然灾害特别是强风和火灾时,气膜建筑展示了优异的抗风和防火性能。轻空间将详细探讨这些性能及其在实际应用中的表现。 气膜建筑的抗风能力源于其特殊的结构设计和高性能材料。…...

【秋招笔试】2024-08-07-YT游戏(研发岗)-三语言题解(CPP/Python/Java)
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 编程一对一辅导 ✨ 本系列打算持续跟新 秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 本次的题目比较典,…...

【Python知识】m.inplace = inplace 《==》是否执行原地操作
# 如果激活层模块有 inplace 属性,则设置该属性 if hasattr(m, inplace): m.inplace inplace inplace 属性是什么? 在 PyTorch 中,inplace 属性是一个布尔值,用于指示某个操作是否可以以原地(in-place)模式…...

Go语言fmt包中print相关方法
Go语言的fmt包提供了多种打印相关的函数,主要用于在控制台或其他输出目标上格式化并输出数据。下面是一些常用的print相关方法的用途和区别: 1.fmt.Print() 功能: fmt.Print() 将参数的内容按默认格式输出到标准输出(通常是控制台ÿ…...

图片转为pdf怎么弄?亲测有效的8个pdf转换方法安利
图片转PDF怎么弄?在日常的办公生活中,我们经常会需要处理一些文档格式转换难题,图片转成PDF格式就是其中一个,图片转换成PDF格式的话,方便我们传输分享,毕竟现在PDF格式凭借着自身的稳定性和可移植性已经成…...

贪吃蛇(使用QT)
贪吃蛇小游戏 一.项目介绍**[贪吃蛇项目地址](https://gitee.com/strandingzy/QT/tree/zyy/snake)**界面一:游戏大厅界面二:关卡选择界面界面三:游戏界面 二.项目实现2.1 游戏大厅2.2关卡选择界面2.3 游戏房间2.3.1 封装贪吃蛇数据结构2.3.2 …...

【案例40】Apache中mod_proxy模块的使用
NC中间件 应用场景:配置了apache的情况,包括uap集群,配置https等场景下均适用;如果是单机(NC单结点情况不存在问题,则不用配置这项; was环境也不用配置此项。) 解决方案:按如下两…...

简单安装Android Studio并使用
在Windows上安装Android Studio的步骤如下: ### 1. 检查系统要求 确保你的计算机符合Android Studio的系统要求,通常包括: - Windows 8/10/11 - 64位处理器 - 最少4 GB RAM(推荐8 GB) - 最少2 GB可用硬盘空间ÿ…...
和包(Package))
在Python中,模块(Module)和包(Package)
在Python中,模块(Module)和包(Package)是组织代码、提高代码复用性、促进代码维护的两种重要机制。它们各自扮演着不同的角色,但又紧密相连,共同构成了Python程序架构的基础。以下将详细阐述Pyt…...

Node版本管理工具
一、nvm 安装 二、常用命令 nvm v //查看nvm 版本号nvm install latest // 下载最新的 node 版本 nvm install 版本号 //安装node对应的版本nvm uninstall 版本号 //卸载对应的版本nvm list // 查看下载的所有版本的nodenvm use 版本号 // 只有引入了才能使用…...

创建并发布NPM模块
创建模块项目 $ mkdir my-npm-package $ cd my-npm-package $ npm init添加模块代码 创建新文件 index.js,内容如下 function helloworld() {console.log(Hello World!); }module.exports helloworld;测试模块 在模块目录(my-npm-package࿰…...

20240807软考架构-------软考31-35答案解析
每日打卡题31-35答案 31、【2015年真题】 难度:一般 对于遗留系统的评价框架如下图所示,那么处于“高水平、低价值”区的遗留系统适合于采用的演化策略为 ( )。 A.淘汰B.继承C.改造D.集成 答案…...

毕业党速看:这款 AI 论文神器太疯狂,输入标题直接生成万字长文
赶 due 党、论文特困生直接狂喜!谁懂啊家人们,以前写论文从选题到憋出万字初稿,至少得熬半个月,现在输入一个论文标题,短短 20 分钟就能自动生成结构完整、逻辑通顺、带真实参考文献的万字长文,从摘要、引言…...

SeaTunnel Web安装踩坑记:从MySQL驱动到Hazelcast配置,我都经历了什么
SeaTunnel Web安装踩坑记:从MySQL驱动到Hazelcast配置,我都经历了什么 那天下午,当我第一次尝试在Linux服务器上部署SeaTunnel Web时,完全没想到会开启一段长达6小时的"排雷之旅"。作为一款强大的数据集成平台ÿ…...

从频谱仪读数到测试报告:深入理解dBμV/m、dBm这些单位在EMC辐射发射测试中的真实含义
从频谱仪读数到测试报告:深入理解dBμV/m、dBm这些单位在EMC辐射发射测试中的真实含义 在电磁兼容(EMC)测试实验室里,工程师们每天都要面对频谱分析仪上跳动的数字——那些以dBμV/m、dBm为单位的读数,直接决定着产品能…...

4大维度构建高可靠性加密货币自动交易系统
4大维度构建高可靠性加密货币自动交易系统 【免费下载链接】binance-trade-bot Automated cryptocurrency trading bot 项目地址: https://gitcode.com/gh_mirrors/bi/binance-trade-bot 一、价值定位:为什么专业交易者都在用自动化交易工具? 为…...

res-downloader:全平台网络资源下载工具的高效使用指南
res-downloader:全平台网络资源下载工具的高效使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 当你在微信…...

效率倍增:用快马平台一键生成带反爬优化策略的clawx脚本
提升爬虫效率的实战心得:用clawx应对反爬机制 最近在做一个数据采集项目时,遇到了不少反爬问题。目标网站不仅会检测请求频率,还会检查请求头信息,甚至有些页面会根据访问行为动态调整返回内容。经过一番摸索,我发现通…...

ai辅助开发:在快马平台用自然语言生成集成kimi apikey的代码模块
最近在尝试用AI辅助开发,发现了一个特别高效的组合:用InsCode(快马)平台的自然语言生成功能,直接创建调用Kimi API的代码模块。整个过程就像和懂技术的同事对话一样简单,分享下具体操作和心得。 明确需求场景 我需要一个Python函数…...

3步快速找回加密压缩包密码:ArchivePasswordTestTool终极指南
3步快速找回加密压缩包密码:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因为忘…...

AI辅助开发:让快马AI生成能自适应Instagram页面改版的下载脚本
最近在做一个Instagram媒体下载工具时,遇到了一个很头疼的问题:每次Instagram更新页面结构,我的脚本就会失效。后来尝试用InsCode(快马)平台的AI辅助功能,发现可以很好地解决这个问题。今天就来分享一下如何利用AI生成一个能自适应…...

FieldTrip脑电分析工具箱:从数据混乱到科学洞察的专业解决方案
FieldTrip脑电分析工具箱:从数据混乱到科学洞察的专业解决方案 【免费下载链接】fieldtrip The MATLAB toolbox for MEG, EEG and iEEG analysis 项目地址: https://gitcode.com/gh_mirrors/fi/fieldtrip 作为MATLAB平台上最强大的开源脑电信号分析工具&…...