NVIDIA A100 和 H100 硬件架构学习
-
目前位置NV各种架构代号:
NVIDIA GPU 有多个代号和架构,这些架构对应不同的世代和硬件特性。以下是 NVIDIA 主要 GPU 架构及其计算能力(Compute Capability)代号的简要概述:
-
Tesla 架构
-
G80、GT200
-
Compute Capability:
sm_10,sm_11,sm_12,sm_13
-
Fermi 架构
-
GF100, GF104, GF110
-
Compute Capability:
sm_20,sm_21
-
Kepler 架构
-
GK104, GK110
-
Compute Capability:
sm_30,sm_32,sm_35,sm_37
-
4. Maxwell 架构
-
GM107, GM204, GM206
-
Compute Capability:
sm_50,sm_52
-
Pascal 架构
-
GP100, GP102, GP104, GP106
-
Compute Capability:
sm_60,sm_61,sm_62
-
Volta 架构
-
GV100
-
Compute Capability:
sm_70,sm_72
-
Turing 架构
-
TU102, TU104, TU106
-
Compute Capability:
sm_75
-
Ampere 架构
-
GA100, GA102, GA104, GA106
-
Compute Capability:
sm_80,sm_86
-
Hopper 架构
-
H100
-
Compute Capability:
sm_90,sm_90a
这只是一个简要概述,具体的 GPU 型号可能会包含多种不同的子配置和强化特性,例如更多的 CUDA 核心、更高的内存带宽、更强的 NVLink 支持等。详细的功能和特性可以通过 NVIDIA 的最新文档和白皮书来获得。
举例说明
-
Tesla G80 和 GT200: 最早的 GPU 架构,主要用在基础的并行计算。
-
Fermi: 引入了新的指令集架构和硬件功能,例如 ECC 内存支持。
-
Kepler: 提升了能效,广泛应用于高性能计算和科学计算。
-
Maxwell: 进一步优化了能效并改善了执行效率。
-
Pascal: 引入了 NVLink 和统一内存,显著提高了深度学习的性能。
-
Volta: 包含全新的 Tensor Cores,用于加速深度学习任务。
-
Turing: 包含了 Ray Tracing Cores 和改进的 Tensor Cores,针对实时渲染和深度学习进行了优化。
-
Ampere: 进一步增强了 Tensor Cores 性能,改善的 memory 和计算效率。
-
Hopper: 最新的架构,进一步提升 AI 和数据中心计算的效率。
编译 CUDA 程序
编译 CUDA 程序时,可以选择适合你的 NVIDIA GPU 架构的 -arch 参数。例如,如果你有一块 Volta GPU,你可以这样编译程序:
nvcc -arch=sm_70 your_program.cu -o your_program
-
Hopper 相比 Ampere 新增硬件特性
了解FlashAttentionV3的优化需要先了解Hopper的主要技术(Hopper White Paper概述)
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/

-
新的第四代的Tensor Core,整体加速了6x,单SM上的加速,SM数量的增加,频率升高,在同等数据类型上,张量内核的 MMA(矩阵乘积)计算速度是 A100 SM 的 2 倍;同时支持了fp8的数据类型,与A100 fp16数据类型相比 tensor core 性能提升了 4 倍;
-
新的DPX指令,相比A100在动态规划算法上加速7x @黄明晓 应用场景调研;
-
IEEE FP64和F32相比A100加速3x,其中硬件计算单元提升2x,SM数量增加,频率升高;
-
新增Thread block cluster的特性,编程层次变为:threads,thread blocks,thread block clusters, and grids。clusters 使多个thread blocks能够在多个 SMs 上并发运行,同步,协同获取和交换数据;

-
Distributed shared memory,实现SM-to-SM的通信,用于跨多个 SM 共享内存块的加载、存储和原子操作。


-
新的异步执行的特性,包括Tensor Memory Accelerator(TMA)单元。可以将大的数据块从GMEM高效的传输到SMEM,同时支持同一个cluster内不同的Thread blocks间,异步copy数据。
-
新的Transformer Engine(硬件+软件), 可以实现Fp16和Fp8的自动切换,训练加速9x,推理加速30x。
-
HBM3 memory subsystem提升2x的bandwidth。
-
50MB的L2 cache的架构。
-
第二代MIG(Multi-Instance GPU)每个GPU Instance增加3x的计算能力和2x的bandwidth;
-
可信计算支持,保护用户数据;
-
第四代NVIDIA NVLink,3x bandwidth 在 allreduce操作上。和50%的通用bandwidth提升的支持;
-
第三代NVSwitch,总的switch throughput从7.2Tbits/sec提升到13.6Tbits/sec;
-
新的NVLink Switch system;
-
PCIe Gen5支持128GB/sec的双向bandwidth(64GB/sec的单向带宽)。


疑问:TF32 并没有增加芯片的峰值算力,为什么不直接将tensor core 设计成支持fp32的类型?(降低能耗?)
-
Hopper 更优的pipeline效果
核心思想:减少data_load、cuda core、tensor core对寄存器资源的竞争关系,加大pipeline hide latency效果


疑问:根据register file大小,理论上每个thread 最多可以访问到512*32bit 的registers(为什么文档说最多是256个registers? Flash attention3中register分配数量超过了256,达到264个)
-
TMA 硬件单元
TMA的引入解放了load 数据 和 计算,TMA 不再和计算单元抢占register/thread资源,hide load 数据的latency;
(类似biren br104 TDA硬件单元)
说明:
(1)通过copy descriptor的方式只需一次issue就可以完成global memory 到share memory之间的async copy;

(2) TMA(只用到一个thread)解放了thread和register资源,去做其他independent工作;

(3) 支持一种全新的更高效的异步事务屏障(asynchronous transaction barrier)来处理数据copy和exchange,cluster 内不同SM之间的数据通信也是基于这种新特性。


-
WGMMA 指令
WGMMA指令的引入,合并SM里面的4个tensor core 效果类似于一个大的tensor core,减少load tensor次数(A/B tensor 共用),同时支持Tcore core 的inputs 来源于share memory(A100架构及之前的架构,inputs 必须from registers),具体的WGMMA指令inputA from registers or share memory,inputB must from share memory PTX ISA 8.5;减少了register的抢占,更有利于cuda core pipeline 并行计算,hide cuda core 计算的latency;
(类似biren br104 cwarps/Tmode 概念)
-
setmaxnreg指令
setmaxnreg指令的引入,支持动态重新分配每个warp group 可用register数量(from register pool);
说明:Hopper架构新特性的指令大部分都是在PTX ISA version 8.0引入的 PTX ISA 8.5
(类似biren br104 cwarps/Tmode下手都分配register用法)
-
fp8 tensor core
Hopper 整体上支持FP8, FP16, BF16, TF32, FP64这些dtype类型的tensor core的计算,相比Ampere,fp8是新增加的数据类型:
FP8 Tensor Core支持FP32 and FP16 两种类型的累加器, 并且支持两种FP8的输入类型:
-
E4M3 with 4 exponent bits, 3 mantissa bits, and 1 sign bit(范围较小,精度较高)
-
E5M2, with 5 exponent bits, 2 mantissa bits, and 1 sign bit(范围较大,精度较低)

flash attention3 论文上也提到两点关于FP8在flash attention3上使能的工程细节:
(1)A,B tensor 必须在K维度连续(V in-kernel transpose);
(2)FP32 accumulator register layout is different from operand A FP8 operand register layout(QK 结果permute)
H100 FP8 相比 A100 FP16 提升了6x的吞吐量

横向对比tensor core计算,H100 相比 A100 都有3x吞吐量的提升

相关文章:
NVIDIA A100 和 H100 硬件架构学习
目前位置NV各种架构代号: NVIDIA GPU 有多个代号和架构,这些架构对应不同的世代和硬件特性。以下是 NVIDIA 主要 GPU 架构及其计算能力(Compute Capability)代号的简要概述: Tesla 架构 G80、GT200 Compute Capabi…...

企业研发设计协同解决方案
新迪三维设计,20年深耕三维CAD 全球工业软件研发不可小觑的中国力量 2003-2014 年 新迪数字先后成为达 索SolidWorks、 ANSYS Spaceclaim、MSC等三维CAD/CAE 软件厂商的中国研发中心,深度参与国际 一流工业软件的研发过程,积累了丰富的 技术经…...

iOS 18(macOS 15)Vision 中新增的任意图片智能评分功能试玩
概述 在 WWDC 24 中库克“大厨”除了为 iOS 18 等平台重磅新增了 Apple Intelligence 以外,苹果也利用愈发成熟的机器学习引擎扩展了诸多内置框架,其中就包括 Vision。 想用本机人工智能自动为我们心仪的图片打一个“观赏分”吗?“如意如意&…...

如何实现若干子任务一损俱损--浅谈errgroup
errgroup 是 Go 语言官方扩展库 x/sync 中的一个包,它提供了一种方式来并行运行多个 goroutine,并在所有 goroutine 都完成时返回第一个发生的错误(如果有的话)。这对于需要并行处理多个任务并等待它们全部完成,同时需…...

并查集的基础题
## 洛谷p1196 绿 35m 点到祖先的距离 代码: #include<bits/stdc.h> using namespace std; const int N3e510; int f[N],dist[N],num[N];//num计算祖先有多少儿子 ,dist计算距离祖先有几个 int zx(int x){ if(f[x]x)return x;//x没爸爸 e…...
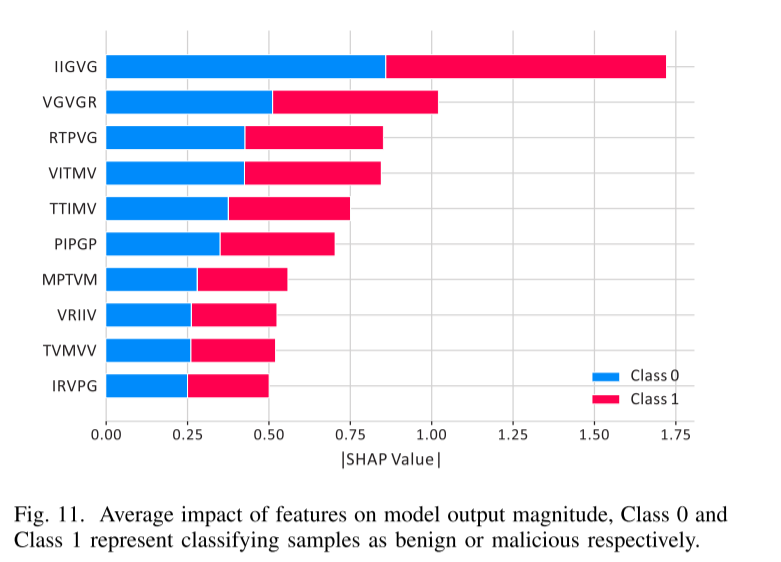
[论文翻译] LTAChecker:利用注意力时态网络基于 Dalvik 操作码序列的轻量级安卓恶意软件检测
LTAChecker: Lightweight Android Malware Detection Based on Dalvik Opcode Sequences using Attention Temporal Networks 摘要: Android 应用程序已成为黑客攻击的主要目标。安卓恶意软件检测是一项关键技术,对保障网络安全和阻止异常情况至关重要。…...

HTTPS链接建立的过程
HTTPS(HyperText Transfer Protocol Secure)建立链接的过程主要是通过TLS(Transport Layer Security)协议来实现的。HTTPS的链接建立过程可以分为以下几个步骤: 1. **客户端发起请求** - 客户端向服务器发送一个请求&…...

文档控件DevExpress Office File API v24.1 - 支持基于Unix系统的打印
DevExpress Office File API是一个专为C#, VB.NET 和 ASP.NET等开发人员提供的非可视化.NET库。有了这个库,不用安装Microsoft Office,就可以完全自动处理Excel、Word等文档。开发人员使用一个非常易于操作的API就可以生成XLS, XLSx, DOC, DOCx, RTF, CS…...

IP地址封装类(InetAddress类)
文章目录 前言一、IP地址是什么?二、IP地址封装类 1.常用方法2.实操展示总结 前言 当我们想要获取到通信对方的IP地址、主机地址等信息时,我们可以使用InetAddress类。InetAddress类在java的net包中。 一、IP地址是什么? IP地址 (Internet Pr…...

数据库设计规范化
在数据库设计中,尤其是在关系型数据库管理系统中,规范化(Normalization)是一种通过减少数据冗余和依赖关系来优化数据库表结构的过程。规范化可以确保数据的完整性和减少数据更新时的问题。规范化的过程通常遵循一系列标准或范式&…...

预约咨询小程序搭建教程,源码获取,从0到1完成开发并部署上线
目录 一、明确需求与规划功能 二、选择开发工具与模板 三、编辑小程序内容 四、发布与运营 五、部分代码展示 制作一个预约咨询小程序,主要可以分为以下几个步骤: 一、明确需求与规划功能 明确需求: 1.确定小程序的服务对象…...

leetcode217. 存在重复元素,哈希表秒解
leetcode217. 存在重复元素 给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。 示例 1: 输入:nums [1,2,3,1] 输出:true 示例 2&#x…...

QT:QString 支持 UTF-8 编码吗?
在 Qt 中,字符串的处理主要依赖于 QString 类。QString 内部并不是直接使用 UTF-8 编码来存储数据的。相反,QString 使用 Unicode(特别是 UTF-16)来存储文本,以支持多语言环境的国际化应用。这种设计使得 QString 能够…...

我主编的电子技术实验手册(13)——电磁元件之继电器
本专栏是笔者主编教材(图0所示)的电子版,依托简易的元器件和仪表安排了30多个实验,主要面向经费不太充足的中高职院校。每个实验都安排了必不可少的【预习知识】,精心设计的【实验步骤】,全面丰富的【思考习…...

odoo from样式更新
.xodoo_form {.o_form_sheet {padding-bottom: 0 !important;border-style: solid !important;border-color: white;}.o_inner_group {/* 线框的样式 *//*--line-box-border: 1px solid #666;*//*box-shadow: 0 1px 0 #e6e6e6;*/margin: 0;}.grid {display: grid;gap: 0;}.row …...
分区表有哪些类型?)
Oracle(52)分区表有哪些类型?
分区表在Oracle数据库中主要分为以下几种类型: 范围分区(Range Partitioning)列表分区(List Partitioning)哈希分区(Hash Partitioning)组合分区(Composite Partitioning࿰…...

大黄蜂能飞的起来吗?
Bumblebee argument 虽然早期的空气动力学证明大黄蜂不能飞行——因为体重太重,翅膀太薄,但大黄蜂并不知道,所以照飞不误。 背景 在20世纪初,科学家们通过研究发现,大黄蜂的身体与翼展的比例失调,按照…...

虹科新品 | PDF记录仪新增蓝牙®接口型号HK-LIBERO CL-Y
新品发布!HK-LIBERO CE / CH / CL产品家族新增蓝牙接口型号HK-LIBERO CL-Y! PDF记录仪系列新增蓝牙接口型号 HK-LIBERO CL-Y HK-LIBERO CE、HK-LIBERO CH和HK-LIBERO CL,虹科ELPRO提供了一系列高品质的蓝牙(BLE)多用途…...

Bytebase 2.22.1 - SQL 编辑器展示更丰富的 Schema 信息
🚀 新功能 SQL 编辑器直接展示表,视图,函数,存储过程等各种 Schema 详情。OpenAI 功能进入社区版(免费),现在您可以通过配置自有 OpenAI key 在 SQL 编辑器中启用自然语言转 SQL 功能。支持在 …...

SQL Server Management Studio的使用
之前在 https://blog.csdn.net/fengbingchun/article/details/140961550 介绍了在Windows10上安装SQL Server 2022 Express和SSMS,这里整理下SSMS的简单使用: SQL Server Management Studio(SSMS)是一种集成环境,提供用于配置、监视和管理SQL…...

健身私教AI:OpenClaw+Qwen3.5-9B定制个人训练计划与饮食建议
健身私教AI:OpenClawQwen3.5-9B定制个人训练计划与饮食建议 1. 为什么需要AI健身私教? 去年冬天体检报告上的"轻度脂肪肝"三个字,成了我决定认真健身的最后一根稻草。作为程序员,我试过各种健身APP,但总感…...

安卓跑步打卡项目App源码分享:内含完整源码与简易开发文档
安卓源码,安卓开发,跑步打卡项目app源码,包括源码和简单文档跑步打卡 App 技术白皮书——从传感器到云端轨迹的完整数据链路一、定位:一款“轻量级、端侧优先”的运动健康产品本 App 面向青少年及日常健身人群,在“零账…...

RAG系统提示词重构核心要点,深度拆解核心问题架构与应对方案,实战演练
将针对企业级应用优化的Prompt工程方法论迁移至RAG(检索增强生成)系统时,需要进行系统性的范式重构。这并非简单的指令复用,而是涉及从单体模型指令到“检索-生成”双阶段协同的体系升级。 问题解构与核心挑战 企业级RAG系统引入…...

最新扫码点餐外卖配送餐饮小程序系统源码
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示一、详细介绍 最新扫码点餐外卖配送餐饮小程序系统源码 系统功能: 1.支持多平台:微信小程序,支付宝小程序,和H5平台,页面可以后台DIY管理。 2.小程序页面支…...

抢救你的数字青春:QQ空间记忆永久保存全攻略
抢救你的数字青春:QQ空间记忆永久保存全攻略 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 当你在整理旧物时偶然翻到泛黄的毕业照,是否会想起QQ空间里那些更鲜…...

020驱动模型与sysfs:当你的驱动需要“见人”时
最近在调试一个车载CAN设备时遇到个怪现象:驱动能正常收发数据,但每次系统休眠唤醒后设备就丢了。查了半天发现,原来设备电源管理回调根本没被调用。老张路过我工位瞟了一眼,扔下一句话:“你这驱动没‘上户口’吧&…...
)
企业内网开发必备:VS2022离线安装NuGet包全流程(附Newtonsoft.Json示例)
企业内网开发实战:VS2022离线NuGet包部署指南与Newtonsoft.Json案例解析 在企业级开发环境中,网络隔离是常见的安全策略。最近接手的一个金融项目让我深刻体会到,当开发机被限制外网访问时,如何高效管理NuGet包依赖成了团队协作的…...

AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手
AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手 最近在做一个谷歌账号注册教程项目时,发现传统的图文教程存在几个痛点:用户容易迷失在步骤中、遇到错误时不知道如何解决、非英语用户理解困难。正好接触到InsCode(快马)平台的AI辅助开…...
)
告别DataGridView!用ReoGrid在C#中打造Excel级表格编辑功能(支持粘贴/样式保留)
告别DataGridView!用ReoGrid在C#中打造Excel级表格编辑功能(支持粘贴/样式保留) 在传统C#桌面应用开发中,DataGridView一直是表格数据显示的默认选择。但当我们面对制造业成本核算、财务报表生成等需要处理复杂Excel数据的场景时&…...

ZYNQMP平台下arm64架构的82599ES万兆网驱动移植实战指南
1. 环境准备与驱动源码获取 在ZYNQMP平台上折腾万兆网卡驱动移植,第一步得把开发环境搭好。我用的是一台Ubuntu 20.04的主机作为开发机,交叉编译工具链用的是Xilinx官方提供的Vitis工具链。这里有个坑要注意:必须确认你的工具链版本和ZYNQMP内…...