【经验分享】ShardingSphere+Springboot-04:自定义分片算法(COMPLEX/STANDARD)
文章目录
- 3.4 CLASS_BASED 自定义类分片算法
- 3.4.1 复杂分片自定义算法(strategy=COMPLEX )
- 3.4.2 STANDARD 标准分片自定义算法
- ## 进阶:star: 自定义算法+范围查询优化
3.4 CLASS_BASED 自定义类分片算法
3.4.1 复杂分片自定义算法(strategy=COMPLEX )
通过配置分片策略类型和算法类名,实现自定义扩展。 掌握自定义类算法就算法完全掌握了分片算法的精髓,可以根据业务需求灵活配置分片规则。
类型:CLASS_BASED
可配置属性:
| 属性名称 | 数据类型 | 说明 |
|---|---|---|
| strategy | String | 分片策略类型,支持 STANDARD、COMPLEX 或 HINT(不区分大小写) |
| algorithmClassName | String | 分片算法全限定名 |
官方文档给出了一个参考案例如下,没有太多的说明,这尝试用自定义分片算法重新实现[3.3.1]中的行表达式分表规则
package org.apache.shardingsphere.sharding.fixture;import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue; import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;import java.util.Collection;public final class ClassBasedStandardShardingAlgorithmFixture implements StandardShardingAlgorithm<Integer> {@Override public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Integer> shardingValue) {for (String each : availableTargetNames) {if (each.endsWith(String.valueOf(shardingValue.getValue() % 4))) {return each;}}return null; }@Override public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Integer> shardingValue) {return availableTargetNames; } }
实现目标:根据用户类型user_type和部门dep_id进行复杂分库分表
编写分片算法类:
-
根据分片策略类型( STANDARD、COMPLEX 或 HINT)实现对应的算法接口,这里需要用到的复杂算法的接口
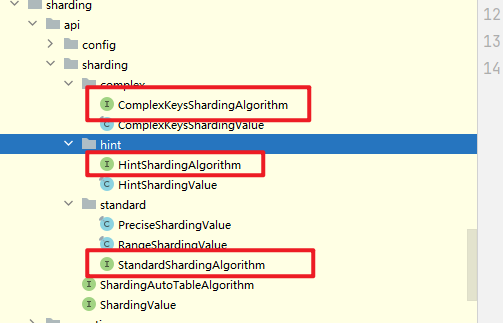
-
实现必须的方法,这里核心关注doSharding方法,编写思路记录如下
- 获取列名和分片值的映射(必备的,获取了才能根据分片键值计算数据源嘛
- (可选)获取逻辑表名、范围值映射
- 获取分片键值,并计算得到真实数据源
完整算法类:
package com.zhc.shard.algo;import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;import java.util.*;/*** @Author zhuhuacong* @Date: 2024/08/09/ 11:07* @description*/
@Slf4j
public class UserTypeDepIdAlgorithm implements ComplexKeysShardingAlgorithm<String> {// 定义列名常量private static final String col1 = "user_type";private static final String col2 = "dep_id";/*** 实现分片逻辑* 当分片条件存在时,根据给定的分片键计算出特定的数据源* 如果无法计算出合适的分片结果,则抛出异常** @param collection 数据源集合(这里是分表策略,所以这里是真实表集合* @param complexKeysShardingValue 分片条件对象* @return 分片后的数据源名称列表* @throws RuntimeException 当无法得到合适的分片结果时*/@Overridepublic Collection<String> doSharding(Collection collection, ComplexKeysShardingValue complexKeysShardingValue) {// 获取逻辑表名String logicTableName = complexKeysShardingValue.getLogicTableName();// 获取列名和分片值的映射Map columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();// 获取列名和范围值的映射(未用到)Map columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap();// 获取分片键值List c1UserType = (List) columnNameAndShardingValuesMap.get(col1);List c2DepId = (List) columnNameAndShardingValuesMap.get(col2);// 如果任一分片键存在,则进行分片计算if (Optional.ofNullable(c1UserType).isPresent() || Optional.ofNullable(c2DepId).isPresent()) {// 【算法核心】 根据分片键值计算数据源索引long userType = c1UserType.get(0) != null ? Long.parseLong(c1UserType.get(0).toString()) : 0;long depId = c2DepId.get(0) != null ? Long.parseLong(c2DepId.get(0).toString()) : 0;long shardingId = ((userType + depId) % 2);String tableName = logicTableName + "_" + shardingId;log.info("userType:{};shardingId:{};余数{};真是表名{}", userType, depId, shardingId , tableName);// 返回计算后的数据源名称return Collections.singletonList(tableName);}// 如果无法得到合适的分片结果,则记录日志并抛出异常log.info("没有得到合适的分片结果=:表名{},参数:{}", collection, columnNameAndShardingValuesMap);throw new RuntimeException("没有得到合适的分片结果");}@Overridepublic Properties getProps() {return null;}@Overridepublic void init(Properties properties) {}
}进行测试:
分表策略运行正确

3.4.2 STANDARD 标准分片自定义算法
快速实现,表结构还是参考前面的打卡表。要求根据早中晚三个时段的打卡时间进行分表,分别存入
stu_clock_am、stu_clock_noon、stu_clock_eve;
yaml配置如下
spring:shardingsphere:rules:sharding:tables:# 打卡表stu_clock:actual-data-nodes: dsmain.stu_clock_am,dsmain.stu_clock_noon,dsmain.stu_clock_evekey-generate-strategy:column: idkey-generator-name: snowflaketable-strategy:standard:sharding-column: clockin_timesharding-algorithm-name: stu_clock_class_algo# 配置分片算法sharding-algorithms:stu_clock_class_algo:type: CLASS_BASEDprops:#分片策略类型,支持 STANDARD、COMPLEX 或 HINT(不区分大小写)strategy: STANDARD# 分片算法全限定名algorithmClassName: com.zhc.shard.algo.StuClockClassAlgorithm
算法代码:
package com.zhc.shard.algo;import cn.hutool.core.date.DateUtil;
import com.google.common.collect.Range;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;import java.time.LocalDateTime;
import java.util.Collection;
import java.util.Collections;
import java.util.Date;
import java.util.Properties;/*** @Author zhuhuacong* @Date: 2024/08/09/ 14:56* @description StuClockClassAlgorithm*/
@Slf4j
public class StuClockClassAlgorithm implements StandardShardingAlgorithm<Date> {@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {String logicTableName = shardingValue.getLogicTableName();Date date = shardingValue.getValue();LocalDateTime localDateTime = DateUtil.toLocalDateTime(date);int hour = localDateTime.getHour();log.info("logicTableName: {} value: {} hour {}", logicTableName, date, hour);String actualTableName =null;if (hour > 15){actualTableName = logicTableName + "_eve";} else if (hour > 10 ){actualTableName = logicTableName + "_noon";} else {actualTableName = logicTableName + "_am";}if (availableTargetNames.contains(actualTableName)){return actualTableName;}// 如果无法得到合适的分片结果,则记录日志并抛出异常log.info("没有得到合适的分片结果:表名{},参数:{}", shardingValue, shardingValue);throw new RuntimeException("没有得到合适的分片结果");}@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> shardingValue) {return availableTargetNames;}@Overridepublic Properties getProps() {return null;}@Overridepublic void init(Properties properties) {}
}
结果测试,
生成随机打卡时间,观察是否正确入库
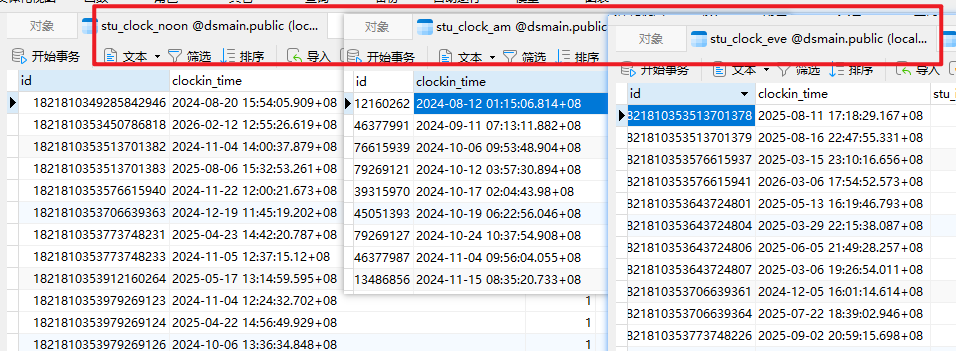
结果符合预期
## 进阶⭐️ 自定义算法+范围查询优化
可以发现,StandardShardingAlgorithm接口还有一个同样叫doSharding的接口,
/*** Sharding.** @param availableTargetNames available data sources or table names* @param shardingValue sharding value* @return sharding results for data sources or table names*/Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<T> shardingValue);
传入的参数是一个带有范围(上下界限)shardingValue,一个是可用的真实表集合availableTargetNames,返回参数就是需要查询的目标表列表。
只要根据实际业务逻辑实现方法体内容即可。
相关文章:
【经验分享】ShardingSphere+Springboot-04:自定义分片算法(COMPLEX/STANDARD)
文章目录 3.4 CLASS_BASED 自定义类分片算法3.4.1 复杂分片自定义算法(strategyCOMPLEX )3.4.2 STANDARD 标准分片自定义算法## 进阶:star: 自定义算法范围查询优化 3.4 CLASS_BASED 自定义类分片算法 3.4.1 复杂分片自定义算法(strategyCOM…...

如何设置RabbitMQ和Redis消息队列系统
设置RabbitMQ和Redis作为消息队列系统时,需要分别进行安装、配置和测试,以确保它们能够正常工作并满足你的应用需求。以下是一个基于这两个系统的设置指南: RabbitMQ的设置 1. 安装Erlang 由于RabbitMQ是用Erlang语言编写的,因…...

白骑士的Matlab教学高级篇 3.3 工具箱与扩展
MATLAB 提供了丰富的工具箱(Toolbox)和扩展功能,这些工具箱涵盖了各个领域的专业计算需求,如信号处理、图像处理、统计与机器学习等。利用工具箱,用户可以快速实现复杂的计算和分析任务。本文将介绍常用的工具箱及其使…...

bug: 配置flyway.locations多个脚本位置不生效
文章目录 业务场景场景一场景二 业务场景 随着项目版本迭代,数据库结构也会变动。如果一个项目引用其他项目的jar包,并且需要执行对应jar包的flyway脚本,就需要配置flyway.locations 场景一 正常情况下,在一个项目中可以在yml文件…...

8月5日SpringBoot学习笔记
今日内容:搭建mybatis ORM 配置数据源 $#的区别 增删改查 搭建mybatis 在原有maven项目基础配置上进行: pom文件添加依赖 <!-- Mybatis --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-…...

Java学习笔记(二十):反射、动态代理、日志、类加载器、xml、单元测试Junit、注解
目录 一、反射 1.1 反射的概述: 1.2 学习反射到底学什么? 1.3 获取字节码文件对象的三种方式 1.4 字节码文件和字节码文件对象 1.5 获取构造方法 1.6 获取构造方法并创建对象 1.7 获取成员变量 1.8 获取成员变量并获取值和修改值 1.9 获取成员…...

如何快速从文本中找到需要的信息,字典和正则灵活运用
import re #打开文本文件 f open("stock_data.txt",encoding"utf-8") #单独读取第一行数据处理进行分割,末尾换行符去掉 headers f.readline().strip().split(,) print(headers) #定义一个字典,以股标代码做为KEY,每个行做为值 st…...

springboot3整合redis
来源于https://www.bilibili.com/video/BV1UC41187PR/?spm_id_from333.1007.top_right_bar_window_history.content.click&vd_source865f32e12aef524afb83863069b036aa 一、整合redis 1.创建项目文件 2.添加依赖 <dependencies><dependency><groupId>…...

VUE基础快速入门
VUE 和 VUE-Cli VUE 是一种流行的渐进式JavaScript框架,用于构建Web用户界面它具有易学、轻量级、灵活性强、高效率等特点,并且可以与其他库和项目集成是目前最流行的前端框架之一VUE-Cli 称为“VUE脚手架”,它是由VUE官方提供的客户端,专门为…...

用Python实现特征工程之特征提取——数值特征提取、类别特征提取、文本特征提取、时间特征提取
特征提取是特征工程中的关键步骤,它从原始数据中提取有意义的特征,以便机器学习模型能够更好地理解和学习数据。根据数据类型,特征提取可以分为数值特征提取、类别特征提取、文本特征提取和时间特征提取。下面详细讲解每种特征提取方法&#…...

按图搜索新体验:阿里巴巴拍立淘API返回值详解
阿里巴巴拍立淘API是一项基于图片搜索的商品搜索服务,它允许用户通过上传商品图片,系统自动识别图片中的商品信息,并返回与之相关的搜索结果。以下是对阿里巴巴拍立淘API返回值的详细解析: 一、主要返回值内容 商品信息 商品列表…...

vue跨域问题
本地调试 可以通过在vue.config.js中配置devServer来实现跨域请求。 module.exports {publicPath: ./,productionSourceMap: false, // 生产环境是否生成 sourceMap 文件devServer: {proxy: {/bi: {target: http://1.11.113.20:1234/bi, // 后台接口域名ws: false, //…...
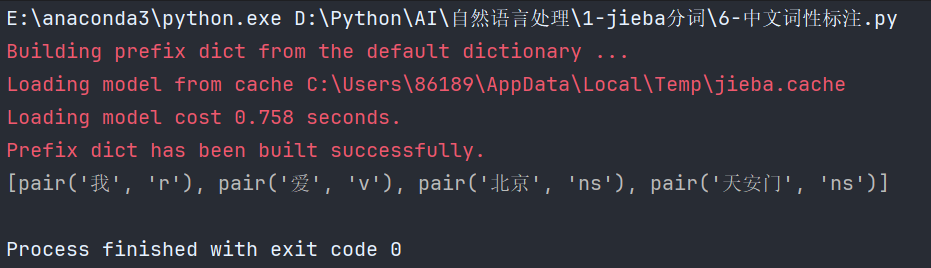
【NLP】文本处理的基本方法【jieba分词、命名实体、词性标注】
文章目录 1、本章目标2、什么是分词3、jieba的使用3.1、精确模式分词3.2、全模式分词3.3、搜索引擎模式分词3.4、中文繁体分词3.5、使用用户自定义词典 4、什么是命名实体识别5、什么是词性标注6、小结7、jieba词性对照表⭐ 🍃作者介绍:双非本科大三网络…...

unity 本地使用Json(全套)
提示:文章有错误的地方,还望诸位大神不吝指教! 文章目录 前言一、Json是什么?二、创建Json文件1.在线编辑并转实体类(C#)2.Json文件 三、解析Json并使用四、报错:JsonError:JsonExce…...

java消息队列ActiveMQ
安装 前置条件 activemq的运行依赖于jdk,需要提前安装jdk如果已经安装了jdk,需要根据jdk的版本来选择对应的版本进行安装activemq版本对应在官网上,使用java -version 看jdk的版本注意:jdk和mq的版本不一致会报错,电脑…...
)
Android SurfaceFlinger——信号同步原理(五十一)
经过前面系列文章的学习,我们的已经理解了 SurfaceFlinger 运行机制以及同步机制,但是SurfaceFlinger 又是以什么方法是把需要刷新的信号发送给 App 进程的。 一、VSync简介 垂直同步(Vertical Synchronization,简称 VSync)是一种用于同步视频信号和显示设备刷新率的技术…...

html+css网页制作 博云丝网5个页面 无js ui还原度100%
htmlcss网页制作 博云丝网5个页面 无js ui还原度100% 网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 获取…...

Docker Hub 镜像代理加速
因为未知原因,docker hub 已经不能正常拉取镜像,可以使用以下代理服务来进行: "https://docker.m.daocloud.io", "https://noohub.ru", "https://huecker.io", "https://dockerhub.timeweb.cloud"…...

矩阵:消除冗余
矩阵 基本概念 矩阵(Matrix)是一个按照行和列排列的元素的二维数组。具体来说,一个 ( m \times n ) 的矩阵有 ( m ) 行和 ( n ) 列,表示为: A ( a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯…...

【AWS账号解绑关联】Linker账号解绑重新关联注意事项
文章目录 一、来自客户疑问二、提交工单获取帮助三、最佳操作说明四、最佳操作步骤五、参考资料活动上新 一、来自客户疑问 将Linker账号,从一个组织中退出,重新关联到新的组织中,这解绑到重新完成新的关联绑定期间会在Linker账号中的账单中…...

LTE CDRX配置优化与日志解析实战
1. LTE CDRX功能基础与核心参数解析 CDRX(Connected Mode DRX)是LTE网络中终端设备在连接状态下实现节能的关键技术。想象一下你的手机就像个熬夜加班的程序员,如果一直盯着电脑屏幕(持续监听网络信号),电量…...

从新手小白到资深开发者:GISBox与QGIS如何适配你的成长路径?
随着地理信息技术的加速演进,工具选型已成为提升空间数据处理效率的关键环节。本文立足于产品定位、功能体系与目标用户三大核心维度,系统梳理GISBox与QGIS的差异化特征,旨在为教育、科研、企业及个人开发者提供清晰、务实的工具决策依据。 …...

06_Cursor之上下文管理与代码库理解
关键字:上下文管理, 代码库理解, 符号引用, Git集成, 图像上下文, Cursor 06_Cursor之上下文管理与代码库理解 Cursor知识体系 Cursor知识体系(续) | -- 上下文管理层 | -- 代码库级理解 | | -- 项目结构分析 | | -- 依赖关系追…...

Python 3.14 JIT性能调优进入倒计时:CPython核心组已宣布v3.15将移除--enable-jit-experimental标志,现在不掌握就永久错过
第一章:Python 3.14 JIT编译器的演进脉络与战略意义Python 3.14 并非官方发布的正式版本——截至 2024 年,CPython 最新稳定版为 3.12,3.13 处于预发布阶段,而 3.14 尚未进入开发路线图。因此,“Python 3.14 JIT 编译器…...
:37处关键宏定义、12个GC阈值参数、8类对象内存布局差异)
【独家首发】CPython内存管理策略白皮书(基于v3.9–v3.13源码比对):37处关键宏定义、12个GC阈值参数、8类对象内存布局差异
第一章:CPython内存管理策略全景概览CPython 作为 Python 官方解释器,其内存管理机制融合了引用计数、循环垃圾回收(GC)与分代回收策略,形成一套兼顾实时性与鲁棒性的综合体系。理解该机制对诊断内存泄漏、优化对象生命…...

RailSAM:驯 服 SAM与 适 配 器 的 铁 路 分 割精读
一、整体总结研究领域: 基于视觉基础模型的铁路场景语义分割(轨道分割)解决问题: 解决传统铁路分割方法依赖大量标注数据、泛化能力差、计算开销大的问题,同时探索如何将通用大模型(SAM)有效迁移…...

为什么你的C++量子模拟器总在2^10后崩溃?内存优化、张量压缩与SIMD加速三重方案揭秘
第一章:量子模拟器崩溃现象与2^10内存临界点的本质剖析当量子模拟器在经典硬件上运行含10个量子比特的电路时,常在初始化或状态演化阶段发生静默崩溃——进程异常终止、无堆栈回溯、仅返回 SIGSEGV 或 OOM Killer 日志。这一现象并非随机故障,…...

从“能用”到“好用”:给你的GoLand 2022.2.3装上这些插件,开发体验大不同
从“能用”到“好用”:给你的GoLand 2022.2.3装上这些插件,开发体验大不同 每天面对代码编辑器的时间可能比面对家人还长——这不是玩笑,而是许多开发者的真实写照。当GoLand从单纯的代码工具转变为你的"数字工作台",插…...

GKD规则冲突检测:自动化识别并提示重叠规则问题
GKD规则冲突检测:自动化识别并提示重叠规则问题 在GKD自动化工具的使用过程中,规则冲突检测是一个至关重要的功能。当多个订阅规则同时作用于同一个应用时,可能会出现规则重叠或相互干扰的情况。GKD的智能冲突检测机制能够自动识别这些问题&…...

Ubuntu22.04部署Cartographer:从一键安装到参数调优全解析
1. 环境准备:Ubuntu 22.04与ROS2 Humble基础配置 在开始部署Cartographer之前,确保你的Ubuntu 22.04系统已经完成基础环境配置。我遇到过不少开发者因为跳过这一步,导致后续安装出现各种依赖问题。这里分享几个关键检查点: 首先…...