白骑士的PyCharm教学实战项目篇 4.4 大数据处理与分析
系列目录
上一篇:白骑士的PyCharm教学实战项目篇 4.3 自动化测试与持续集成
随着数据量的爆炸性增长,大数据处理与分析成为现代数据科学的重要课题。PyCharm提供了强大的功能,可以帮助开发者高效地进行大数据环境的配置与连接,并实现数据处理与分析的各种实践。本文将详细介绍如何在PyCharm中配置大数据环境,并通过实际案例展示如何进行大数据处理与分析。
大数据环境配置与连接
大数据环境通常包括分布式计算框架和大数据存储系统,如Apache Hadoop、Apache Spark、HDFS等。PyCharm支持通过插件和外部工具连接到这些大数据环境。
配置Apache Spark环境
安装Apache Spark
- 下载并安装Apache Spark,可以从Spark官网下载最新版本。
- 解压下载的文件,并配置环境变量,将Spark的'bin'目录添加到系统的'PATH'中。
配置PyCharm项目
- 打开PyCharm,选择 “File” -> “New Project”,创建一个新的Python项目。
- 在创建项目时,选择使用虚拟环境,以便隔离项目依赖。
安装PySpark库
- 在PyCharm的终端或通过 “File” -> “Settings” -> “Project: <project_name>” -> “Python Interpreter” 添加PySpark库:
pip install pyspark配置Hadoop环境(可选)
- 如果需要使用HDFS进行数据存储,需要安装并配置Hadoop。可以从Hadoop官网下载并安装。
- 配置Hadoop的环境变量,将Hadoop的'bin'目录添加到系统的 'PATH' 中,并配置HDFS的相关参数。
连接到大数据环境
创建SparkSession
- 在PyCharm中编写Python脚本,创建SparkSession以连接到Spark集群:
from pyspark.sql import SparkSessionspark = SparkSession.builder \.appName("PySpark Big Data Analysis") \.master("local[*]") \.getOrCreate()连接到HDFS(可选)
- 如果使用HDFS进行数据存储,可以在SparkSession中配置HDFS连接参数:
hdfs_url = "hdfs://localhost:9000"
spark._jsc.hadoopConfiguration().set("fs.defaultFS", hdfs_url)数据处理与分析实践
在配置好大数据环境并连接成功后,可以开始进行大数据的处理与分析。本文将通过实际案例展示如何在PyCharm中使用Spark进行数据处理和分析。
数据导入与预处理
导入数据
- 使用Spark读取数据,可以读取多种格式的数据,如CSV、JSON、Parquet等。例如,读取CSV文件:
df = spark.read.csv("data.csv", header=True, inferSchema=True)数据预处理
- 对导入的数据进行预处理,包括清洗、转换、过滤等操作。例如,删除缺失值:
df_cleaned = df.na.drop()数据分析与计算
基本统计分析
- 使用Spark的DataFrame API进行基本的统计分析,例如,计算数据的描述统计信息:
df_cleaned.describe().show()数据分组与聚合
- 使用Spark的分组与聚合操作,进行复杂的数据分析和计算。例如,按某列分组并计算平均值:
df_grouped = df_cleaned.groupBy("category").avg("value")
df_grouped.show()数据透视与分析
- 使用Spark进行数据透视和复杂的分析操作。例如,计算某列的频率分布:
df_pivot = df_cleaned.groupBy("category").count()
df_pivot.show()数据可视化
安装可视化库
- 使用PyCharm安装常用的数据可视化库,如Matplotlib、Seaborn等:
pip install matplotlib seaborn绘制图表
- 将Spark DataFrame转换为Pandas DataFrame,以便使用可视化库进行数据绘图:
import matplotlib.pyplot as plt
import seaborn as snspandas_df = df_grouped.toPandas()sns.barplot(x="category", y="avg(value)", data=pandas_df)plt.show()总结
本文介绍了如何在PyCharm中配置和连接大数据环境,包括安装和配置Apache Spark,连接HDFS,以及使用PySpark进行大数据的处理与分析。通过实际案例展示了如何进行数据导入、预处理、分析和可视化操作。希望本文能够帮助你掌握在PyCharm中进行大数据处理与分析的基本方法和实践,提高你的数据处理效率和分析能力。无论是在学术研究还是工业应用中,掌握大数据处理与分析的技能,都是一项非常有价值的能力。
下一篇:暂无
相关文章:

白骑士的PyCharm教学实战项目篇 4.4 大数据处理与分析
系列目录 上一篇:白骑士的PyCharm教学实战项目篇 4.3 自动化测试与持续集成 随着数据量的爆炸性增长,大数据处理与分析成为现代数据科学的重要课题。PyCharm提供了强大的功能,可以帮助开发者高效地进行大数据环境的配置与连接…...

无人机之民用无人机用途分类篇
一、航拍无人机 用于航拍摄影和电影制作,提供空中视角的拍摄服务。可用于电影制作、广告拍摄、房地产销售等。 二、物流无人机 用于快递和货物运输,提高物流效率,可以到达传统配送方式难以覆盖的地区,在突发事件如自然灾害、疫…...

Android10 修改设备名称
A10和A12的设备名称修改是不同的,A10设备名称修改分好几个位置 修改wifi默认名称 在framework/base模块下 diff --git a/core/res/res/values/strings.xml b/core/res/res/values/strings.xml index 9041a7c3a14..7a1e63688c4 100644 --- a/core/res/res/values/…...

go testing 包
Go语言的testing包提供了一套丰富的测试工具,用于编写和运行测试用例。以下是testing包中一些常用的函数和类型: func TestMain(m *testing.M): 这是一个特殊的函数,用于执行测试的主函数。如果定义了TestMain,那么在运行go test时…...

基于phpstudy的靶场搭建和github加速
微软商店下载 watt toolkit,然后在侧边栏选择网络加速,勾选 github,就可以快速访问 github 1、下载搭建 sqlilabs github 找到 sqlilabs 靶场,点击 code,下载 zip解压之后,整体移动到 phpstudy_pro 文件夹…...

【数据结构】Map与Set
前言 前两篇文章我们研究了二叉搜索树与哈希表的结构与特点,他们二者是Map与Set这两个接口实现的底层结构,他们利用了搜索树与哈希表查找效率高这一特点,是一种专门用来进行搜索操作的容器或数据结构。本篇文章就让我们一起来梳理这两个接口的…...

Flamingo: a Visual Language Model for Few-Shot Learning
发表时间:NeurIPS 2022 论文链接:https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf 作者单位:DeepMind Motivation:仅使用少量注释示例可以快速适应新任务…...

flume性能调优
作者:南墨 1.Source性能调优 1.1 Spooldir Source 使用Spooldir Source采集日志数据时,若每行日志数据<100bp,可以通过将多行合并传输来提升传输性能 建议合并时根据数据长度来确定多少行合并为一个单位进行传输,合并后的长…...

mysql 字符串转数组
在 MySQL 中,可以使用内置的字符串函数 SUBSTRING_INDEX() 和 REPLACE() 来实现将字符串转换为数组。 首先,使用 REPLACE() 函数将字符串中的分隔符替换为空格,然后使用 SUBSTRING_INDEX() 函数将字符串按空格分割成多个子字符串。最后&…...

UE基础 —— 术语
目录 Project Blueprint Class Object Actor Casting Component Pawn Character Player Controller AI Controller Player State Game Mode Game State Brush Volume Level World Project 项目(Project)包含游戏的所有内容,…...

kubernets学习笔记——使用kubeadm构建kubernets集群及排错
使用kubeadm构建kubernets集群 一、准备工作1、repo源配置:阿里巴巴开源镜像源2、更新软件包并安装必要的系统工具3、同步时间4、禁用selinux5、禁用交换分区swap6、关闭防火墙 二、安装docker-ce、docker、cri-docker1、安装docker-ce2、开启内核转发,转…...

简述MYSQL聚簇索引、二级索引、索引下推
一丶聚簇索引 InnoDB的索引分为两种: 聚簇索引:一般创建表时的主键就会被mysql作为聚簇索引,如果没有主键则选择非空唯一索引作为聚簇索引,都没有则隐式创建一个索引作为聚簇索引;辅助索引:也就是非聚簇索…...
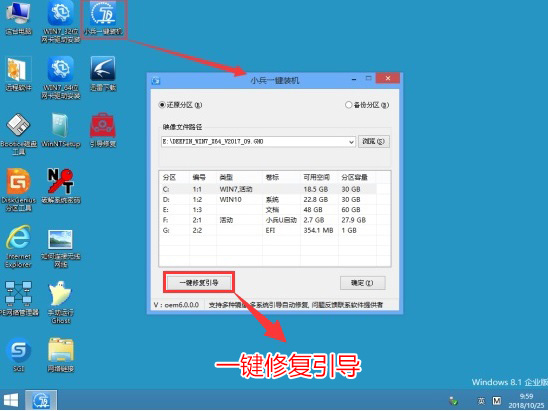
电脑开机后出现bootmgr is missing原因及解决方法
最近有网友问我为什么我电脑开机后出现bootmgr is missing,这个提示意思是:意思是启动管理器丢失,说明bootmgr损坏或者丢失,系统无法读取到这个必要的启动信息导致无法启动。原因有很多,比如我们采用的是uefi引导,而第…...
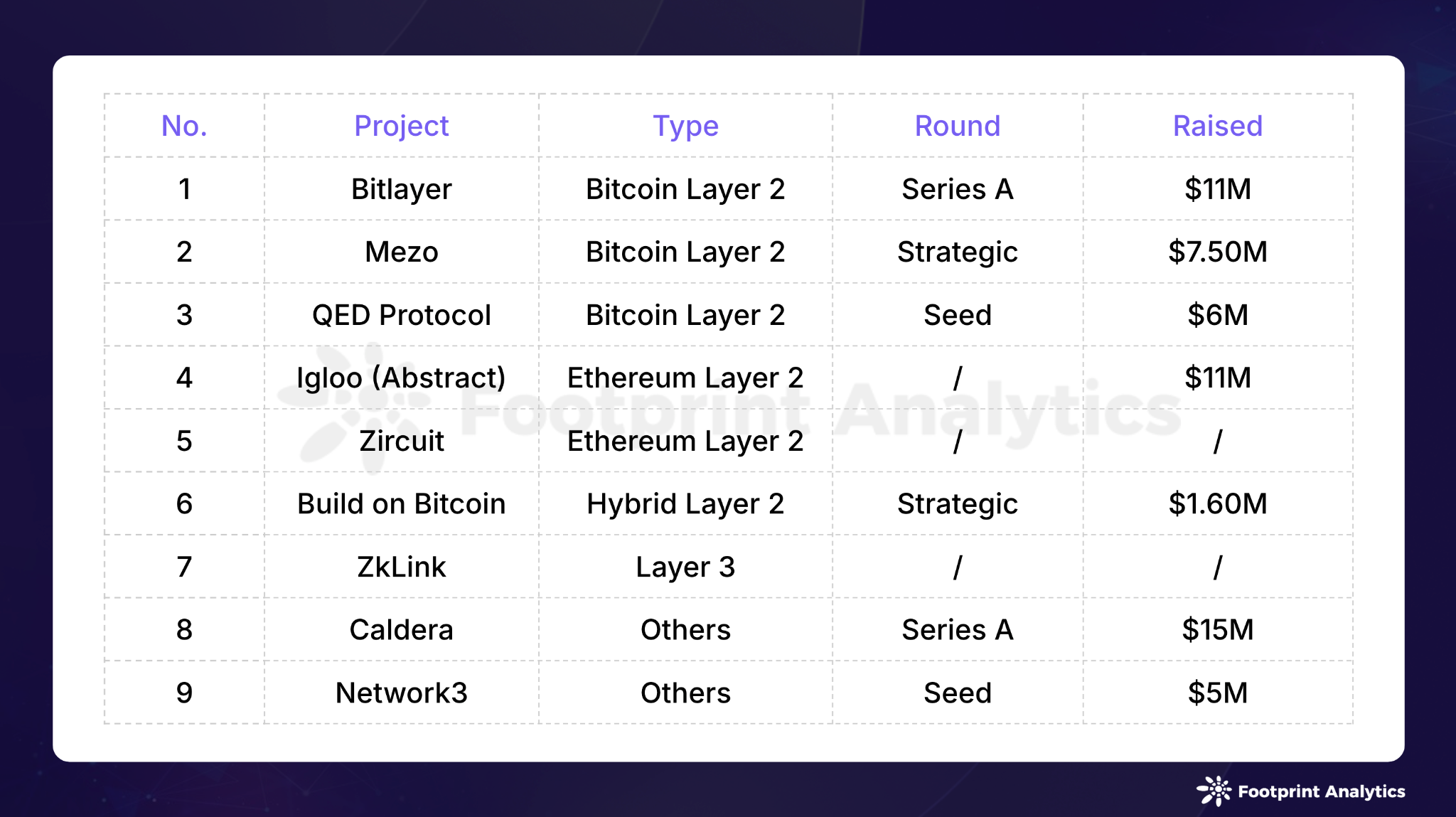
2024 年 7 月公链行业研报:市场波动中 Solana 表现抢眼,Layer 2 竞争白热化
作者:Stella L (stellafootprint.network) 数据来源:Footprint Analytics 公链 Research 页面 7 月份,加密货币市场表现活跃,波动幅度较大,这一现象映射了全球金融市场的整体趋势。现货以太坊 ETP 在美国的上市&…...

Python查缺補漏
一、 json.load(s)与json.dump(s)区别 json.loads()将str类型的数据转换为dict类型 json.dumps()将dict类型的数据转成str json.load()从json文件中读取数据 json.dump()将数据以json的数据类型写入文件中 二、json内部要使用双引号 data """{ "fruit&qu…...

c++的类和对象(中):默认成员函数与运算符重载(重难点!!)
前言 Hello, 小伙伴们,我们今天继续c的学习,我们上期有介绍到c的部分特性,以及一些区别于c语言的地方,今天我们将继续深入了解c的类和对象,探索c的奥秘。 好,废话不多说,开始我们今天的学习。…...

Android .kl按键布局文件
1.介绍 一个硬件按键的处理流程大致为:当用户按下或释放一个键时,键盘硬件会生成一个扫描码scan code,然后操作系统读取这个scan code,并将scan code扫描码映射到虚拟键码key code,最后操作系统根据映射的keycode生成…...

Java每日一练_模拟面试题6(JVM的GC过程)
一、JVM虚拟机组成 JVM五大内存区域:程序计数器,Java虚拟机栈,本地方法栈,java堆,方法区。 堆被划分为两个区域:年轻代(Young)、老年代(Tenured)。年轻代又被划分为三个区域:Eden、From Surviv…...

数据防泄密软件推荐|(6大数据防泄密软件推荐!)
很多朋友在后台私信,什么是数据防泄密软件,有哪些数据防泄密软件推荐。 今天小编将从定义出发,深入浅出地介绍这一技术的工作原理、应用场景以及实现方式。 一、什么是文档透明加密? 文档透明加密是一种在用户无感知的情况下对文…...

Codeforces 874 div3 A-G
A. Musical Puzzle 分析 每两个相邻的字母都要录制一段,开个set记录一下,然后输出set的大小 C代码: #include<iostream> #include<set> using namespace std; void solve(){int n;string s;cin>>n>>s;set<strin…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...