C++第一讲:开篇
C++第一讲:开篇
- 1.C++历史背景
- 1.1C++创世主--本贾尼
- 1.2C++版本更新
- 1.3C++的重要性
- 1.4C++书籍推荐
- 2.C++的第一个程序
- 3.命名空间
- 3.1namespace是什么
- 3.2namespace的使用
- 3.3namespace使用注意事项
- 3.4命名空间的使用
- 4.C++输入和输出
- 5.缺省参数
- 6.函数重载
- 7.引用
- 7.1什么是引用
- 7.2引用的定义
- 7.3引用的使用
- 7.4引用注意事项
- 7.5const引用
- 7.5.1示例1--权力扩大问题
- 7.5.2示例2--权力缩小
- 7.5.3示例3
- 7.6指针与引用之间的关系
- 8.inline
- 8.1define定义宏的劣势
- 8.2inline函数的使用
- 8.3inline函数使用注意事项
- 9.nullptr
这一讲是学习C++的第一讲,以后会一直学习C++,后序所写的算法题也将会使用C++来写,所以这一讲叫做开篇,讲述的是C++的基础知识
1.C++历史背景
关于C++的历史背景,了解与否其实无关紧要,但是这里还是稍微讲讲有意思的事情吧,毕竟学习语言首先还是要先了解一下它的历史
1.1C++创世主–本贾尼
C++的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼·斯特劳斯特卢普,这个翻译的名字不同的地⽅可能有差异)在⻉尔实验室从事计算机科学和软件⼯程的研究⼯作。他在实现项目的开发工作时,感受到了C语言在一些方面的不足,1983年,于是他在C语言之上添加了面向对象的特性,也是在这一年该语言被命名为C++
仰望大佬:

1.2C++版本更新

1.3C++的重要性
C++的重要性想必也不用过多赘述了,学习C++的人应该都能够体会到C++的重要性,无论是在工作中、学习中
1.4C++书籍推荐
下面的三本书是大佬推荐的书,至于怎么样,我相信,到后边我会看的!

2.C++的第一个程序
//第一个C++程序
#include <iostream>
using namespace std;int main()
{cout << "hello world!" << endl;return 0;
}
这里我们是不是还看不懂这些代码?没关系,我们往下看
3.命名空间
3.1namespace是什么
在C语言中,我们不能使用同一个名称定义多个变量:
#include <stdio.h>
//在只引用stdio这一个头文件的情况下,这串代码是正确的
int rand = 10;int main()
{printf("%d ", rand);return 0;
}
那么下面我们改一下:
#include <stdio.h>
#include <stdlib.h>
//在引用stdlib头文件之后,就发生了报错:rand重定义,以前的定义是"函数"
//原因:引用头文件其实就是在链接过程将头文件内容拿过来,而stdlib这一头文件中
// 也包含rand,而且它还是一个函数,所以这里就报错了
int rand = 10;int main()
{printf("%d ", rand);return 0;
}
这在以后多人项目中是非常拉跨的,因为我们不能保证整个团队定义的变量都是不同的名称,所以C++中就引入了namespace来解决这个问题
3.2namespace的使用
总结:
1.namespace是定义命名空间的关键字,命名空间中可以包含变量、函数、结构体等
2.在C++中,两个冒号::被称为是作用域解析运算符,它用来指定某个实体(变量、函数、类)属于哪个作用域或命名空间
3.namespace本质就是定义了一个命名空间,这个域跟全局域相互独立,不同的域可以定义同名变量,所以这里的rand就不会报错了
4.C++中有函数局部域、全局域、命名空间域、类域,编译器在编译时会先在局部域中寻找变量,然后再在全局域中寻找变量。局部域和全局域除了会影响编译查找逻辑,还会影响变量的声明周期,命名空间域和类域不会影响变量声明周期
1.namespace是定义命名空间的关键字,命名空间中可以包含变量、函数、结构体等:
#include <stdio.h>
#include <stdlib.h>
//namespace定义命名空间,定义方法如下:
//namespace+命名空间名称--自己起--BCNR--爆炒脑仁
namespace BCNR
{//定义变量int rand = 10;//定义函数int ADD(int x, int y){return x + y;}//定义结构体struct Stack{int* arr;int capacity;int top;};
}int main()
{printf("%p\n", rand);//使用命名空间中对象的方法:命名空间名称 + :: + 对象名称//提取变量printf("%d\n", BCNR::rand);//使用空间中的函数int c = BCNR::ADD(10, 20);printf("%d\n", c);//使用结构体BCNR::Stack st1;return 0;
}
2.在C++中,两个冒号::被称为是作用域解析运算符,它用来指定某个实体(变量、函数、类)属于哪个作用域或命名空间
3.namespace本质就是定义了一个命名空间,这个域跟全局域相互独立,不同的域可以定义同名变量,所以这里的rand就不会报错了
4.C++中有函数局部域、全局域、命名空间域、类域,编译器在编译时会先在局部域中寻找变量,然后再在全局域中寻找变量。局部域和全局域除了会影响编译查找逻辑,还会影响变量的声明周期,命名空间域和类域不会影响变量声明周期
#include <stdio.h>
//定义在全局域
int a = 10;namespace BCNR
{//定义在命名空间域int a = 20;
}//函数局部域
int ADD(int x, int y)
{return x + y;
}int main()
{//定义在函数局部域int a = 30;printf("%d\n", a);//main函数局部域中,30printf("%d\n", BCNR::a);//命名空间域中,20printf("%d\n", ::a);//像这样只有两个冒号,就是访问全局域中的变量,10return 0;
}
3.3namespace使用注意事项
总结:
1.namespace可以嵌套使用
2.namespace只能定义在全局
3.项目工程中定义的多个同名namespace会认为是一个namespace,不会冲突
4.C++标准库都放在一个叫std(standard)的命名空间中
5.namespace创建的命名空间中的对象其实都是全局的,因为这个变量能够在非命名空间域中被访问
1.namespace可以嵌套使用:
#include <stdio.h>
//假设此时张三和李四要实现一个项目:Game
namespace Game
{//张三namespace ZhangSan{int a = 10;int ADD(int x, int y){return x + y;}}//李四namespace LiSi{int a = 20;int ADD(int x, int y){return x + y * 10;}}
}int main()
{int ret;//张三printf("%d\n", Game::ZhangSan::a);//10ret = Game::ZhangSan::ADD(10, 10);printf("%d\n", ret);//10+10=20//李四printf("%d\n", Game::LiSi::a);//20ret = Game::LiSi::ADD(10, 10);printf("%d\n", ret);//10+10*10=110return 0;
}
2.namespace只能定义在全局
3.项目工程中定义的多个同名namespace会认为是一个namespace,不会冲突
//同名namespace会合并在一起
//Stack.h
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
namespace bit
{typedef int STDataType;typedef struct Stack{STDataType* a;int top;int capacity;}ST;void STInit(ST* ps, int n);void STDestroy(ST* ps);void STPush(ST* ps, STDataType x);void STPop(ST* ps);STDataType STTop(ST* ps);int STSize(ST* ps);bool STEmpty(ST* ps);
}// Stack.cpp
#include"Stack.h"
namespace bit
{void STInit(ST* ps, int n){assert(ps);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;}// 栈顶void STPush(ST* ps, STDataType x){assert(ps);// 满了, 扩容if (ps->top == ps->capacity){printf("扩容\n");int newcapacity = ps->capacity == 0 ? 4 : ps->capacity* 2;STDataType* tmp = (STDataType*)realloc(ps->a,newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}ps->a = tmp;ps->capacity = newcapacity;}ps->a[ps->top] = x;ps->top++;}
}
4.C++标准库都放在一个叫std(standard)的命名空间中
#include <iostream>int main()
{//既然C++标准库都放在了std这一命名空间中,那么我们在引用了//头文件之后就可以对其中的对象进行使用了:std::cout << "hello world!" << std::endl;return 0;
}
5.namespace创建的命名空间中的对象其实都是全局的,因为这个变量能够在非命名空间域中被访问
3.4命名空间的使用
上述我们已经了解到,双冒号可以拿出指定命名空间中的变量来使用,如果我们要一直拿出某个变量的话,敲代码是一件很麻烦的事,所以我们这样做:
#include <stdio.h>
#include <stdlib.h>
namespace BCNR
{//定义变量int a = 10;//定义函数int ADD(int x, int y){return x + y;}
}//如果我们要像下面多次使用a的话,是很麻烦的,那么我们加上这个:
//此时代表着展开BCNR这一命名空间中的a变量,将a变量暴漏在全局
using BCNR::a;
//这样代表着将命名空间中所有的对象暴漏在全局中
using namespace BCNR;int main()
{printf("%d\n", a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);printf("%d\n", BCNR::a);return 0;
}
现在我们就可以理解C++的第一个代码中的using namespace std是什么意思了
4.C++输入和输出
1.iostream是标准输入流和标准输出流的一部分,它提供了对标准输入和标准输出的访问,是istream和ostream的组合,istream表示输入流,用于从输入流(如键盘)中读取数据,ostream为输出流,用于向输出流(如屏幕)中输出数据
2.std::cin,是istream类的对象,用于从标准输入流中读取数据
3.std::cout,是ostream类的对象,用于向标准输出流发送数据
4.std::enl,它是一个函数,而且是一个较为复杂的函数,相当于插入一个换行符并刷新缓冲区
5.<<是流插入运算符,>>是流提取运算符
6.与C语言不同的是,C++中的输入输出可以自动识别数据类型,不需要使用%d、%c来格式化输入、输出
7.IO流中设计很多类和对象、重载中的知识,后边会详细阐述
8.cout、cin、endl等都属于C++标准库,C++标准库都放在一个叫std的命名空间中,所以要通过命名空间的使用方法来使用它们
9.日常练习中,我们可以用using namespace std,在项目中万不可这样使用
10.仅仅包含iostream,我们也可以使用printf、scanf,可能是在iostream中间接包含了,VS没有报错,其他编译器可能会报错,这也说明了IO流不仅仅是各司其职的,在IO需求较高的情况下,比如竞赛中,可能会因为IO流之间的关系处理而浪费时间,解决方式如下:
#include <iostream>
int main()
{int a = 0;double b = 0.1;char c = 'x';//会自动识别数据类型进行打印//如果想要保留小数的话,建议使用printf来实现小数的保留std::cout << a << " " << b << " " << c << std::endl;//可以⾃动识别变量的类型std::cin >> a;std::cin >> b >> c;std::cout << a << std::endl;std::cout << b << " " << c << std::endl;return 0;
}#include<iostream>
using namespace std;
int main()
{//在IO需求⽐较⾼的地⽅,如部分⼤量输入的竞赛题中,加上以下3⾏代码//可以提⾼C++IO效率ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);return 0;
}
5.缺省参数
缺省参数其实就是在函数声明时,为函数参数定义一个缺省值,如果传入的数据没有值的话,就会使用缺省值:
#include <iostream>
using namespace std;void Func(int a = 0)
{cout << a << endl;
}int main()
{Func(); //没有传参时,使⽤参数的默认值,输出0Func(10); //传参时,使⽤指定的实参,输出10return 0;
}
缺省分为全缺省和半缺省
#include <iostream>
using namespace std;// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}// 半缺省
//半缺省中的参数必须从右向左进行赋值
//void Func2(int a = 10, int b, int c = 20)//err,缺少实参2的默认实参
void Func2(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func1();Func1(1);Func1(1, 2);//在传参时也不能跳跃着传参//Func1(, 1, );//err,语法错误Func1(1, 2, 3);Func2(100);Func2(100, 200);Func2(100, 200, 300);return 0;
}
需要注意的是,缺省参数不能声明和函数同时给值,只能够在声明中确定缺省值
//Stack.h
#include <iostream>
#include <assert.h>
using namespace std;
typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;//只能在这里给缺省值
void STInit(ST* ps, int n = 4);//Stack.cpp
#include"Stack.h"
//缺省参数不能声明和定义同时给,这里就不能给缺省值了
void STInit(ST* ps, int n)
{assert(ps && n > 0);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;
}
6.函数重载
C++支持在同一作用域中出现同名函数,但是这要求函数的形参不同,可以是形参的个数不同,也可以是形参的类型不同:
#include<iostream>
using namespace std;
//1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}
//2、参数个数不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}
//3、参数类型顺序不同(本质上也是形参类型不同)
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}
返回值不同不能作为重载条件,因为调用时也无法区分
//返回值不同不能作为重载条件,因为调⽤时也⽆法区分
void fxx()
{}int fxx()
{return 0;
}
注意点:
//下⾯两个函数构成重载
//但是调⽤时,会报错,存在歧义,编译器不知道调⽤谁
void f1()
{cout << "f()" << endl;
}void f1(int a = 10)
{cout << "f(int a)" << endl;
}int main()
{//err,对重载函数的调用不明确f1();return 0;
}
7.引用
7.1什么是引用
引用其实就是给变量起别名,引用并不是新定义了一个变量,编译器不会给引用变量开辟空间
7.2引用的定义
//引用的定义
类型& + 引用别名 = 引用对象
引用的使用如下:
//类型 & +引用别名 = 引用对象
int main()
{//定义一个整形变量int a = 10;//为整形变量起别名int& ra = a;//为别名起别名int& rra = ra;//为同一个整形变量起多个别名int& rb = a;//它们指向的地址相同,说明并没有为它们单独开辟空间cout << &a << endl;cout << &ra << endl;cout << &rra << endl;cout << &rb << endl;return 0;
}
而引用的原理为:

对变量赋值和对变量引用的区别:

7.3引用的使用
因为引用对象和原对象指向的空间相同,所以说,对引用对象进行修改,原对象也会被修改,引用的底层实现其实是指针,所以我们可以这样写代码:
//引用的使用
//对引用对象的修改会直接影响到原来的对象
//所以这里交换就会成功
void Swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}int main()
{int x = 10;int y = 20;//10 20cout << x << " " << y << endl;Swap(x, y);//20 10cout << x << " " << y << endl;return 0;
}
Swap函数之前使用指针也能够完成,那么有了指针,引用是不是多余了呢?肯定不是,我们看下边的一个例子:
//假设此时我们已经创建了一个栈
//void STInit(ST& rs, int n = 4);栈的初始化
//void STPush(ST& rs, STDataType x);入栈
//int& STTop(ST& rs);//获取栈顶元素
int main()
{ST st1;STInit(st1);STPush(st1, 1);STPush(st1, 2);//此时我们要获取栈顶元素:2cout << STTop(st1) << endl;return 0;
}
获取栈顶元素比较简单,但是这时我们想要对栈顶元素进行修改,方法如下:
// int STTop(ST& rs)
//如果要对栈顶元素进行修改,只需要将返回类型改为引用即可
//此时返回的是对原始对象的引用,而不是对象的副本(如果返回值的话,返回时需要将值先存储到一个临时空间中,所以是对象的副本)
int& STTop(ST& rs)
{return rs.a[rs.top-1];
}//假设此时我们已经创建了一个栈
//void STInit(ST& rs, int n = 4);栈的初始化
//void STPush(ST& rs, STDataType x);入栈
//int& STTop(ST& rs);//获取栈顶元素
int main()
{ST st1;STInit(st1);STPush(st1, 1);STPush(st1, 2);//此时我们要获取栈顶元素:2cout << STTop(st1) << endl;//此时我们要读栈顶元素进行修改:STTop(st1)++;cout << STTop(st1) << endl;//输出3return 0;
}
这时如果要用指针来实现的话是非常麻烦的,感兴趣的可以实现一下!
7.4引用注意事项
1.由于引用作为返回值或传参不需要开辟临时变量,所以可以提效,而且还可以通过引用直接修改到原变量,所以能够用引用的地方使用引用比指针更加方便
2.引用和指针在实践中是相辅相成的,功能有重叠性,各有特点,互相不可替代,但是与Java中的引用不同,C++中的引用不能够改变指向
3.引用可以简化程序,比如使用引用代替指针传参,可以避免复杂的指针,更容易理解
4.引用必须初始化
5.引用一旦引用一个实体,就不能引用其他实体
6.引用时如果引用临时变量,就可能出现野引用的情况
int main()
{int a = 10;int b = 20;//5.引用一旦引用一个实体,就不能引用其他实体:int& ra = a;//&ra = b; err:无法从int转换成int*ra = b;//这里是赋值,此时a = ra = b = 20//4.引用必须初始化//int& rb; err:必须初始化引用return 0;
}
//野引用
int& f()
{int a = 10;return a;
}
7.5const引用
总的来说,说的其实就是权力的问题,权力可以缩小,但是不能扩大
7.5.1示例1–权力扩大问题
//const引用示例1
int main()
{const int a = 10;//此时a为const类型//int& ra = a;//err,权限不能扩大,不能从const int转换为int&const int& ra = a;//√,const int&和const int权限相同return 0;
}
7.5.2示例2–权力缩小
//const引用示例2
int main()
{int a = 10;const int& ra = a;//权力可以缩小int& rb = a;//正确int& rra = ra;//err,无法从const转换成int&return 0;
}
7.5.3示例3
int main()
{int a = 10;int& rb = 30;//err,因为30是常数const int& rrb = 30;//这个才是正确的写法int& ra = a*3;//err,因为a*3是常数const int& rra = a*3;//这样也是正确的,表示a*3被rra引用,可以通过rra找到a*3,但是不能改变a*3的值rra = 20;//err,不能给常量赋值double c = 1.2;const int& rc = c;//虽然是int类型,但是这样也是对的,涉及到整形提升//这里就是先将1.2传到一个int类型的临时变量中,然后再让rc进行指向return 0;
}
7.6指针与引用之间的关系
C++中的指针和引用就像两个性格不同的亲兄弟,指针是哥哥,引用为弟弟,它们在实践中相辅相成,但各自有各自的特点,互相不可替代
1.语法概念上,引用是为变量起别名,不需要开辟空间,指针存储的是一个变量的地址,需要开辟空间
2.sizeof引用的大小是引用对象的类型发=大小,而sizeof指针始终是4/8个字节
3.引用在定义时必须初始化,指针只是建议初始化
4.引用在引用一个对象后,就不能引用其它对象,而指针可以不停地改变指向
5.引用可以直接访问引用对象,而指针需要解引用
6.指针很容易出现野指针情况,而引用比较难以出现野引用的情乱
8.inline
8.1define定义宏的劣势
之前我们就已经讲过,define定义的宏具有很大的劣势,比如我们要定义一个宏函数:
//错误写法1:
#define ADD(int x,, int y) return x+y
//错误写法2:
#define ADD(int x, int y) (x+y)
//错误写法3:
#define ADD(x, y) (x+y)
//正确写法:
#define ADD(x, y) ((x) + (y))
//1.形参中不用追加类型
//2.必须加上合适的小括号
//3.最后边不能加;因为是宏替换
//4.外面不加括号:x=1+2, y=2+3形成错误
//5.里边不加括号:x=1|2,y=2^3形成错误,位移运算符优先级低于+
为了解决这一个问题,C++中设计了一个inline函数:
8.2inline函数的使用
//inline函数的使用
//直接在函数前加上关键词inline即可
inline int ADD(int x, int y)
{return x + y;
}int main()
{cout << ADD(10, 20) << endl;//输出30return 0;
}
8.3inline函数使用注意事项
总结:
1.inline修饰的函数被称为内联函数,在使用内联函数时,不需要为改函数创建栈帧,可以提高效率
2.inline对于编译器来说只是建议,也就是说,内敛函数的展开与否取决于编译器,一般内联函数短小时就会展开,内联函数较大时就不会展开
3.inline不建议声明和定义分离到两个文件,分离会导致链接错误,因为inline被展开,是没有函数的地址的,链接时就会报错
4.VS中debug版本下是默认不展开的,想要展开可以搜索着改动一下编译器
9.nullptr
NULL其实是一个宏,在传统的C头文件中,可以看到:
#ifndef NULL#ifdef __cplusplus#define NULL 0#else#define NULL ((void *)0)#endif
#endif
也就是说,C++中,NULL可能被定义为字面量0,或者在C中被定义为(void*)的常量,这样在使用重载的函数时,就会遇到问题:
//两个重载函数:
void f(int x)
{cout << "f(int x)" << endl;
}void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}int main()
{f(0);f(NULL); //这里调用的也是f(int x)函数,因为NULL被解析成了0f((int*)NULL); //编译报错:error C2665: “f”: 2 个重载中没有⼀个可以转换所有参数类型f((void*)NULL);return 0;
}
既然有着这样的问题,那么就设计出一个新的东西:nullptr
nullptr是一个特殊的关键字,是一种特殊类型的字面量,它可以转换成其它任意类型的指针类型,nullptr只能被转换成指针类型,而不能被转换成整数类型,所以以后用nullptr千万不要陌生!
相关文章:
C++第一讲:开篇
C第一讲:开篇 1.C历史背景1.1C创世主--本贾尼1.2C版本更新1.3C的重要性1.4C书籍推荐 2.C的第一个程序3.命名空间3.1namespace是什么3.2namespace的使用3.3namespace使用注意事项3.4命名空间的使用 4.C输入和输出5.缺省参数6.函数重载7.引用7.1什么是引用7.2引用的定…...

OceanBase V4.2特性解析:MySQL模式下GIS空间表达式的场景及能力解析
1. 背景 1.1. OceanBase Mysql gis空间表达式的应用场景及能力 在OceanBase 4.1版本中,mysql模式下支持了gis数据类型以及部分空间对象相关的表达式,随着客户使用空间数据的需求日益增长,需要快速地补齐空间数据存储和计算分析的能力&#…...

HSL模型和HSB模型,和懒人配色的Color Hunt
色彩不仅仅是视觉上的享受,它在数据可视化中也扮演着关键角色。通过合理运用色彩模型,我们可以使数据更具可读性和解释性。在这篇文章将探讨HSL(Hue, Saturation, Lightness)和HSB(Hue, Saturation, Brightness&#x…...

什么是云原生?(二)
1. 云原生的定义 云原生指构建和运行应用以充分利用通过云技术交付模式交付的分布式计算。云原生应用旨在充分利用云技术平台特有的可扩展性、弹性和灵活性优势。 根据云原生计算基金会 (CNCF) 的定义,云原生技术可帮助企业在公有云、私有云和混合云环境中构建和…...

pytorch 47 模型剪枝实战|基于torch-pruning库代码对yolov10n模型进行剪枝
torch-pruning官方提供了基于yolov8的剪枝代码,基于此代码改进博主实现了对yolov10n模型的剪枝。虽然实现了对yolov10n模型的剪枝,剪枝目标为移除60%的通道,然而实验是失败的,针对coco数据集进行操作,剪枝前的模型map时37,剪枝后只能恢复到22,比预计下降了15个点,剪枝后…...

LeetCode_sql_day15(262.行程与用户)
描述:262. 行程和用户 - 力扣(LeetCode) 取消率 的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。 编写解决方案找出 "2013-10-01" 至 "2013-10-03" 期间非禁止…...

【MySQL】详解数据库约束、聚合查询和联合查询
数据库约束 约束类型 数据库的约束类型主要包括以下几种: 主键约束(Primary Key Constraint):确保表中的每一行都有唯一的标识,且不能为NULL。 外键约束(Foreign Key Constraint):…...

bug积累
1.只写 int p[len1 len2]; 时,实际上是在使用 C99 标准中引入的变长数组(VLA, Variable Length Array)的特性。变长数组允许在栈上分配其大小在运行时确定的数组。这意味着 len1 和 len2 的值可以在程序运行时确定,但仍然可以用来…...
)
版本控制案例:全球虚拟制片领导者Dimension借助Perforce Helix Core简化多供应商协作,控制访问权限,确保数据资产安全(下)
创建虚拟世界和人物角色需要一系列的软件工具。但最终愿景很少是由单一工作室独立完成的。对于大型项目,工作室需要通力合作,将全球的团队成员和数字资产联合起来。 Dimension Studio——体积内容捕捉和虚拟制片领域的领导者——不断将新技术和新方法融…...
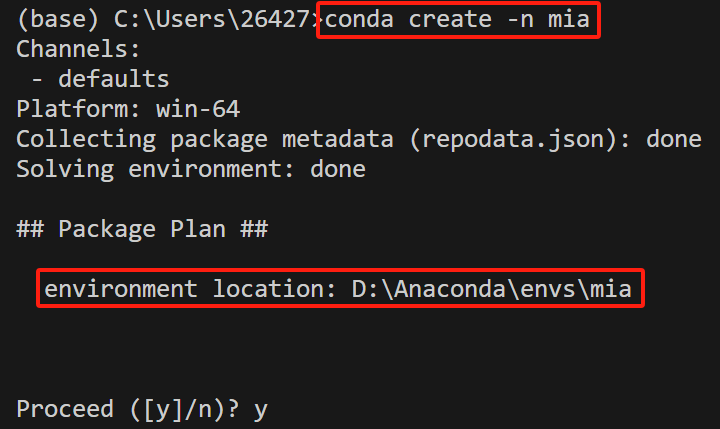
Anaconda配置envs和pcks路径
问题 原先Anaconda安装在C盘,安装很多包后只剩几个G了,为了给C盘腾空间,卸载后重新安装在了D盘,但是创建了新环境后发现环境位置依旧在C盘,安装新的包仍然会占用C盘空间。 解决办法 查看conda的配置信息 执行如下命…...

推荐10个在线搭建框架平台
前言 在开发项目的时候,首先就是要搭建一个框架。这个框架可以是纯技术框架,也可以具备一定功能的开源框架。但是在搭建框架的时候,版本的冲突,环境的配置等是新手们一直头痛的问题,在构建开源框架的时候,…...

Linux Shell--函数
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 一、简介 Shell 函数是一段可以重复使用的代码块,通过定义函数可以避免代码重复,提高脚本的可读性和可维护性。 二、定义函数…...

漏洞复现-CVE-2023-42442:JumpServer未授权访问漏洞
概述 JumpServer存在一个未授权访问漏洞。具体来说,/api/v1/terminal/sessions/ API端点的权限控制存在逻辑错误,允许攻击者匿名访问。未经身份验证的远程攻击者可以利用此漏洞下载SSH日志,并可能借此远程窃取敏感信息。值得注意的是&#x…...

【数据结构之带头双向循环链表的实现】
1.链表的分类 链表的结构有多种多样,以下情况组合起来就有8种(2x2x2)链表结构: 虽然有这么多的链表结构,但是我们实际中最常用的还是两种结构:单链表和双向带头循环链表。 无头单向非循环链表:结…...

【docker】docker数据卷与网络部署服务
Docker 网络模式 选择网络模式 Host Mode (主机模式) 特点: 容器与宿主机共享网络命名空间操作: docker run --nethost ... Container Mode (容器模式) 特点: 容器与指定容器共享网络命名空间操作: docker run --netcontainer:<container-id-or-name> ... None Mode (无…...

Spring MVC框架学习笔记
学习视频:10001 Spring MVC概述_哔哩哔哩_bilibili~11005 请求映射方式_哔哩哔哩_bilibili 目录 1.概述 Java EE三层架构 Spring MVC在三层架构中的位置 编辑 Spring MVC在表现层的作用 Spring MVC的特点 2.Spring MVC入门程序 代码实现 Spring MVC工作原理 Spring …...

LeetCode 100道题目和答案(面试必备)(一)
1.两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按…...

OpenGL投影矩阵
OpenGL Projection Matrix OpenGL投影矩阵...

Linux中的`make`与`Makefile`:项目自动化构建工具
Linux中的make与Makefile:项目自动化构建工具 在Linux及类Unix系统中,make是一种广泛使用的自动化构建工具,它通过读取和执行Makefile(或makefile,文件名不区分大小写)中的指令来自动化编译和构建程序。Ma…...

GitHub开源项目精选:轻量级预约/预订日历组件,用React和TypeScript构建
在日常开发中,我们经常需要在项目中添加预约或预订功能。今天给大家推荐一个超级轻量级的预约/预订日历组件,它是用React和TypeScript构建的,非常适合那些需要简单易用的日历解决方案的开发者。 安装方法: 你可以选择使用npm或者y…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

13456
12356...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...