【NLP】文本特征处理:n-gram特征和文本长度规范
文章目录
- 1、本章目标
- 2、n-gram特征
- 2.1、概念
- 2.2、举个例子
- 2.3、代码
- 3、文本长度规范及其作用
- 4、小结
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、本章目标
- 了解文本特征处理的作用.
- 掌握实现常见的文本特征处理的具体方法.
- 文本特征处理的作用:
- 文本特征处理包括为语料添加具有普适性的文本特征,如n-gram特征;
- 以及对加入特征之后的文本语料进行必要的处理,如长度规范;
- 这些特征处理工作能够有效的将重要的文本特征加入模型训练中,增强模型评估指标
- 常见的文本特征处理方法:
- 添加n-gram特征
- 文本长度规范
2、n-gram特征
2.1、概念
给定一段文本序列,其中n个词或字的相邻共现特征即n-gram特征,常用的n-gram特征是bi-gram和tri-gram特征,分别对应n为2和3。

2.2、举个例子
这个示例讲解了如何从词汇列表生成数值特征并扩展到 N-gram 特征
首先,理解 N-gram 特征的一些基本概念:
- 词汇列表:是一个包含文本中所有词的列表。例如,给定一个句子 “是谁 鼓动 我心”,其词汇列表为
["是谁", "鼓动", "我心"]。 - 数值映射列表:通常用于将每个词映射到一个唯一的数字(索引)。例如,可以将
["是谁", "鼓动", "我心"]映射为[1, 34, 21]。
N-gram 特征的意思是将文本中的相邻词对作为特征。例如,Bigram(2-gram)就是由两个相邻的词组成的特征。
假设有一个词汇列表 ["是谁", "鼓动", "我心"],对应的数值映射列表为 [1, 34, 21]。
这些数值可以被视为单个词汇的特征(Unigram),即每个词在序列中的独立存在。
现在,假设你要考虑 Bigram 特征(2-gram),即两个相邻词的组合。
步骤:
- 识别相邻的词对:在列表中,“是谁” 和 “鼓动” 是相邻的,“鼓动” 和 “我心” 也是相邻的。
- 为每个相邻词对生成新的特征值:
- 假设数字
1000代表 “是谁” 和 “鼓动” 的相邻关系。 - 假设数字
1001代表 “鼓动” 和 “我心” 的相邻关系。
- 假设数字
结果:
- 原始的数值映射列表
[1, 34, 21]现在扩展为包含 Bigram 特征的[1, 34, 21, 1000, 1001]。
在这个例子中,N-gram 特征的引入使得特征表示不仅仅是词汇本身,还包括词汇之间的相邻关系(如 “是谁” 和 “鼓动” 的相邻)。通过引入这些特征,模型可以更好地捕捉词汇之间的上下文关系。
具体来说:
- 原来的
[1, 34, 21]仅表示单个词汇。 - 添加了 Bigram 特征后,特征列表变为
[1, 34, 21, 1000, 1001],表示不仅有单个词汇的信息,还有相邻词对的信息。
2.3、代码
提取n-gram特征:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/12 21:51
# TODO 一般n-gram中的n取2或者3, 这里取2为例
def create_ngram_set(input_list):# 使用 zip 和列表推导式生成 n-gram 特征ngram_set = set(zip(*[input_list[i:] for i in range(ngram_range)]))return ngram_setif __name__ == '__main__':ngram_range = 2example_input = [1, 4, 9, 4, 1, 4]print(create_ngram_set(example_input))# Output: {(4, 9), (4, 1), (1, 4), (9, 4)}
输出效果:
# 该输入列表的所有bi-gram特征
{(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)}
3、文本长度规范及其作用
一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,
此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,
对超长文本进行截断,对不足文本进行补齐(一般使用数字0),这个过程就是文本长度规范
文本长度规范的实现:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/12 22:39
# 从 Keras 的 preprocessing 模块中导入 sequence,用于序列处理
from keras.preprocessing import sequence
# 根据数据分析中句子长度的分布,确定覆盖 90% 左右语料的最短长度
# 这里假定 cutlen 为 10,意味着我们将所有的句子统一处理为长度为 10 的序列
cutlen = 10
def padding(x_train):"""description: 对输入文本张量进行长度规范,确保所有文本的长度一致:param x_train: 文本的张量表示, 形如: [[1, 32, 32, 61], [2, 54, 21, 7, 19]]这是一个二维列表,其中每个子列表表示一条文本的词汇索引序列:return: 进行截断补齐后的文本张量表示,输出的形状为 (len(x_train), cutlen)如果文本长度小于 cutlen,则补齐至 cutlen;如果文本长度大于 cutlen,则截断至 cutlen"""# 使用 sequence.pad_sequences 函数对序列进行补齐(或截断)# pad_sequences 会将每个序列截断或补齐到相同的长度 cutlen# 默认情况下,较短的序列会在前面补 0(默认补在序列的左侧),# 较长的序列会从前面截断(即保留序列的最后 cutlen 个元素)return sequence.pad_sequences(x_train, cutlen)if __name__ == '__main__':# 假定 x_train 里面有两条文本,一条长度大于 10,一条长度小于 10x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], # 长度为 12,超过了 cutlen[2, 32, 1, 23, 1] # 长度为 5,少于 cutlen]# 调用 padding 函数,对 x_train 中的序列进行补齐(或截断)res = padding(x_train)# 输出处理后的结果# 预期输出:# array([[ 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], # 第1条序列被截断至长度10# [ 0, 0, 0, 0, 0, 2, 32, 1, 23, 1]]) # 第2条序列前面补5个0至长度10print(res)
输出:
E:\anaconda3\python.exe D:\Python\AI\自然语言处理\7-文本长度规范.py
2024-08-12 22:44:53.195415: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-12 22:44:54.269741: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
[[ 5 32 55 63 2 21 78 32 23 1][ 0 0 0 0 0 2 32 1 23 1]]Process finished with exit code 0
4、小结
- 学习了文本特征处理的作用:
- 文本特征处理包括为语料添加具有普适性的文本特征,如:n-gram特征,以及对加入特征之后的文本语料进行必要的处理,如:长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中,增强模型评估指标
- 学习了常见的文本特征处理方法:
- 添加n-gram特征
- 文本长度规范
- 学习了什么是n-gram特征:
- 给定一段文本序列,其中n个词或字的相邻共现特征即n-gram特征,常用的n-gram特征是bi-gram和tri-gram特征,分别对应n为2和3
- 学习了提取n-gram特征的函数:create_ngram_set
- 学习了文本长度规范及其作用:
- 一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐(一般使用数字0),这个过程就是文本长度规范.
- 学习了文本长度规范的实现函数:padding
相关文章:
【NLP】文本特征处理:n-gram特征和文本长度规范
文章目录 1、本章目标2、n-gram特征2.1、概念2.2、举个例子2.3、代码 3、文本长度规范及其作用4、小结 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法…...
)
ESP32人脸识别开发 ---partitions.csv配置的一些说明(五)
配置的文件在这个位置 esp-who/examples/esp32-s3-eye/partitions.csv factory, app, factory, 0x010000, 4000K, model, data, spiffs, , 3900K, (这个是语音相关的) nvs, data, nvs, , 16K, fr, data, ,…...

【学习笔记】Matlab和python双语言的学习(图论最短路径)
文章目录 前言一、图论基本概念示例 二、代码实现----Matlab三、代码实现----python总结 前言 通过模型算法,熟练对Matlab和python的应用。 学习视频链接: https://www.bilibili.com/video/BV1EK41187QF?p36&vd_source67471d3a1b4f517b7a7964093e6…...

vue.config.js 配置 devserve 配置
在 Vue CLI 项目中,devServer 配置用于设置开发服务器的行为。这包括了开发服务器的端口、主机名、是否开启 HTTPS、自动打开浏览器等设置,以及配置代理规则来解决跨域问题。 devServer 配置详解(version > 4.0.0) host: 设置开发服务器的主机地址&a…...

不入耳耳机什么牌子性价比高?五大年度必选款揭秘
和传统的入耳式耳机相比,开放式耳机采用的是不深入耳道的设计,佩戴舒适度更高,卫生健康,安全性也更高。同时音质表现也更加有空间感。想要体验开放式耳机带来的便利,就需要做好选购攻略,不入耳耳机什么牌子…...

SQL Zoo 6.The JOIN operation
以下数据均来自SQL Zoo 1.Modify it to show the matchid and player name for all goals scored by Germany. To identify German players, check for: teamid GER.(它以显示德国所有进球的比赛和球员名字,识别德国球员) SELECT matchid,player FROM goal where teamid GE…...

视频教程:Vue3移动端抽屉弹层组件实战
本教程演示了vue3的composition api实现的移动端h5抽屉弹层组件,录屏讲解包含了功能演示和具体的源码实现。 笔者相关教程: 使用tailwindcss轻松实现移动端rem适配Vue3.4双向绑定新特性:defineModel好用爱用 学习要点: 自定义…...
)
CSS 的 BFC(块级格式化上下文)
BFC是Block Formatting Context(块级格式化上下文)的缩写,是CSS中一个概念,用于描述页面上如何对元素进行布局。 BFC是一个独立的容器,它内部的元素不会受到外部容器的影响,同时它也会影响其内部元素的表现…...

【2023年】云计算金砖牛刀小试2
A场次题目:Openstack 平台部署与运维 control172.17.31.10compute172.17.31.20 compute任务1 私有云平台环境初始化 1.初始化操作系统 使用提供的用户名密码,登录竞赛云平台。根据表 1 中的 IP 地址规划,设置各服务器节点的 IP 地址,确保网络正常通信,设置控制节点主机名…...

python--将mysql建表语句转换成hive建表语句
1.代码 import json import sys import pymysqldef queryDataBase(tablename):# 连接数据库并查询列信息conn pymysql.connect(userroot, password123456, hosthadoop11)cursor conn.cursor()cursor.execute("SELECT column_name, data_type FROM information_schema.C…...

异步调用实践:Async,Future, TaskExecutor、EventListener
1. 异步调用概述 异步调用允许一个方法调用在不被当前线程阻塞的情况下继续执行,而调用者可以继续执行其他任务,直到异步操作完成。 在Spring Boot中,异步调用常用于提高应用的响应性和吞吐量,尤其是在处理长时间运行的任务时&a…...

Flask 异常处理
Flask 异常处理 使用 app.errorhandler 装饰器使用 app.handle_exception 装饰器使用 register_error_handler调试模式总结 在 Flask 应用中,异常处理是一个非常重要的部分,它可以帮助你管理运行时错误,提供友好的错误页面,以及记…...
【海思SS626 | 内存管理】海思芯片的OS内存、MMZ内存设置
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

linux crontab没有按照规则执行排查
配置了cron规则,但是一段时间后任务没有按预期执行,记录一次修复过程 检查crond服务 systemctl status crond规则正常 crontab -l脚本有执行权限 查看日志 第一种:journalctl journalctl -u crond | grep 03:00 -C 3-u 指定crond.serv…...

Cloudflare的D1使用技巧
总文档:https://developers.cloudflare.com/workers/wrangler/commands/#d1查询某个数据库中哪些命令占用资源最大: To find top 10 queries by execution count: npx wrangler d1 insights <database_name> --sort-typesum --sort-bycount --co…...

解决端口号被占用问题
第一种: 最简单有效的方法,重启一下电脑,占用此端口的程序就会释放端口。 第二种: 使用命令找到占用端口的程序,把它关闭。 1、打开运行窗口输入:CMD ,进入命令窗口。 2、输入:n…...

如何在linux上部署zabbix监控工具
<1>搭建服务机 1)首先我们先执行 sed -i s/SELINUXenforcing/SELINUXdisabled/ /etc/selinux/config #然后我们再把防火墙开机自启关掉 马上生效 systemctl disable --now firewalld 2)我们获得rpm包 rpm -Uvh https://mirrors.aliyun.com/…...
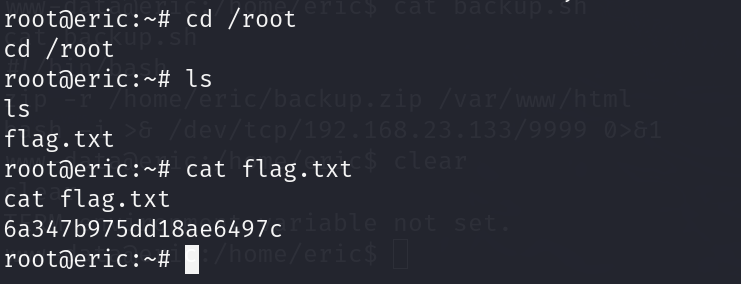
vulnhub系列:sp eric
vulnhub系列:sp eric 靶机下载 一、信息收集 nmap扫描存活,根据mac地址寻找IP nmap 192.168.23.0/24nmap扫描端口,开放端口:22、80 nmap 192.168.23.189 -p- -A -sV -Pndirb 扫描目录,.git 源码,admin…...

JVM二:JVM类加载机制
目录 前言 1.什么是类加载? 2.类加载整体流程 3.一个类什么时候被加载? 4.双亲委派模型 4.1 JVM默认提供了三个类加载器 4.1.1 BootstrapClassLoader 4.1.2 ExtensionClassLoader 4.1.3 ApplicationClassLoader 4.2 破坏双亲委派模型 前言 在上一篇文章中…...

对于springboot无法连接redis解决方案
对于springboot无法连接redis解决方案 一、测试是否能在本地应用上访问到你的redis(如果是部署在linux上的话)1. 开启telnet功能2. 开始测试端口是否能访问到(适用于所有,包括MQ)3. 开放6379端口4. 看spring的配置文件…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...