【扒网络架构】backbone、ccff
backbone






CCFF


还不知道网络连接方式,只是知道了每一层





backbone
- backbone.backbone.conv1.weight torch.Size([64, 3, 7, 7])
- backbone.backbone.layer1.0.conv1.weight torch.Size([64, 64, 1, 1])
- backbone.backbone.layer1.0.conv2.weight torch.Size([64, 64, 3, 3])
- backbone.backbone.layer1.0.conv3.weight torch.Size([256, 64, 1, 1])
- backbone.backbone.layer1.0.downsample.0.weight torch.Size([256, 64, 1, 1])
- backbone.backbone.layer1.1.conv1.weight torch.Size([64, 256, 1, 1])
- backbone.backbone.layer1.1.conv2.weight torch.Size([64, 64, 3, 3])
- backbone.backbone.layer1.1.conv3.weight torch.Size([256, 64, 1, 1])
- backbone.backbone.layer1.2.conv1.weight torch.Size([64, 256, 1, 1])
- backbone.backbone.layer1.2.conv2.weight torch.Size([64, 64, 3, 3])
- backbone.backbone.layer1.2.conv3.weight torch.Size([256, 64, 1, 1])
- backbone.backbone.layer2.0.conv1.weight torch.Size([128, 256, 1, 1])
- backbone.backbone.layer2.0.conv2.weight torch.Size([128, 128, 3, 3])
- backbone.backbone.layer2.0.conv3.weight torch.Size([512, 128, 1, 1])
- backbone.backbone.layer2.0.downsample.0.weight torch.Size([512, 256, 1, 1])
- backbone.backbone.layer2.1.conv1.weight torch.Size([128, 512, 1, 1])
- backbone.backbone.layer2.1.conv2.weight torch.Size([128, 128, 3, 3])
- backbone.backbone.layer2.1.conv3.weight torch.Size([512, 128, 1, 1])
- backbone.backbone.layer2.2.conv1.weight torch.Size([128, 512, 1, 1])
- backbone.backbone.layer2.2.conv2.weight torch.Size([128, 128, 3, 3])
- backbone.backbone.layer2.2.conv3.weight torch.Size([512, 128, 1, 1])
- backbone.backbone.layer2.3.conv1.weight torch.Size([128, 512, 1, 1])
- backbone.backbone.layer2.3.conv2.weight torch.Size([128, 128, 3, 3])
- backbone.backbone.layer2.3.conv3.weight torch.Size([512, 128, 1, 1])
- backbone.backbone.layer3.0.conv1.weight torch.Size([256, 512, 1, 1])
- backbone.backbone.layer3.0.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.0.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer3.0.downsample.0.weight torch.Size([1024, 512, 1, 1])
- backbone.backbone.layer3.1.conv1.weight torch.Size([256, 1024, 1, 1])
- backbone.backbone.layer3.1.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.1.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer3.2.conv1.weight torch.Size([256, 1024, 1, 1])
- backbone.backbone.layer3.2.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.2.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer3.3.conv1.weight torch.Size([256, 1024, 1, 1])
- backbone.backbone.layer3.3.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.3.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer3.4.conv1.weight torch.Size([256, 1024, 1, 1])
- backbone.backbone.layer3.4.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.4.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer3.5.conv1.weight torch.Size([256, 1024, 1, 1])
- backbone.backbone.layer3.5.conv2.weight torch.Size([256, 256, 3, 3])
- backbone.backbone.layer3.5.conv3.weight torch.Size([1024, 256, 1, 1])
- backbone.backbone.layer4.0.conv1.weight torch.Size([512, 1024, 1, 1])
- backbone.backbone.layer4.0.conv2.weight torch.Size([512, 512, 3, 3])
- backbone.backbone.layer4.0.conv3.weight torch.Size([2048, 512, 1, 1])
- backbone.backbone.layer4.0.downsample.0.weight torch.Size([2048, 1024, 1, 1])
- backbone.backbone.layer4.1.conv1.weight torch.Size([512, 2048, 1, 1])
- backbone.backbone.layer4.1.conv2.weight torch.Size([512, 512, 3, 3])
- backbone.backbone.layer4.1.conv3.weight torch.Size([2048, 512, 1, 1])
- backbone.backbone.layer4.2.conv1.weight torch.Size([512, 2048, 1, 1])
- backbone.backbone.layer4.2.conv2.weight torch.Size([512, 512, 3, 3])
- backbone.backbone.layer4.2.conv3.weight torch.Size([2048, 512, 1, 1])
- backbone.backbone.fc.weight torch.Size([1000, 2048])
- backbone.backbone.fc.bias torch.Size([1000])
ccf
- ccff.conv1.conv.weight torch.Size([3584, 3584, 1, 1])
- ccff.conv1.norm.weight torch.Size([3584])
- ccff.conv1.norm.bias torch.Size([3584])
- ccff.conv2.conv.weight torch.Size([3584, 3584, 1, 1])
- ccff.conv2.norm.weight torch.Size([3584])
- ccff.conv2.norm.bias torch.Size([3584])
- ccff.bottlenecks.0.conv1.conv.weight torch.Size([3584, 3584, 3, 3])
- ccff.bottlenecks.0.conv1.norm.weight torch.Size([3584])
- ccff.bottlenecks.0.conv1.norm.bias torch.Size([3584])
- ccff.bottlenecks.0.conv2.conv.weight torch.Size([3584, 3584, 1, 1])
- ccff.bottlenecks.0.conv2.norm.weight torch.Size([3584])
- ccff.bottlenecks.0.conv2.norm.bias torch.Size([3584])
- ccff.bottlenecks.1.conv1.conv.weight torch.Size([3584, 3584, 3, 3])
- ccff.bottlenecks.1.conv1.norm.weight torch.Size([3584])
- ccff.bottlenecks.1.conv1.norm.bias torch.Size([3584])
- ccff.bottlenecks.1.conv2.conv.weight torch.Size([3584, 3584, 1, 1])
- ccff.bottlenecks.1.conv2.norm.weight torch.Size([3584])
- ccff.bottlenecks.1.conv2.norm.bias torch.Size([3584])
- ccff.bottlenecks.2.conv1.conv.weight torch.Size([3584, 3584, 3, 3])
- ccff.bottlenecks.2.conv1.norm.weight torch.Size([3584])
- ccff.bottlenecks.2.conv1.norm.bias torch.Size([3584])
- ccff.bottlenecks.2.conv2.conv.weight torch.Size([3584, 3584, 1, 1])
- ccff.bottlenecks.2.conv2.norm.weight torch.Size([3584])
- ccff.bottlenecks.2.conv2.norm.bias torch.Size([3584])
input_proj
- input_proj.weight torch.Size([256, 3584, 1, 1])
- input_proj.bias torch.Size([256])
encoder
- encoder.layers.0.norm1.weight torch.Size([256])
- encoder.layers.0.norm1.bias torch.Size([256])
- encoder.layers.0.norm2.weight torch.Size([256])
- encoder.layers.0.norm2.bias torch.Size([256])
- encoder.layers.0.self_attn.in_proj_weight torch.Size([768, 256])
- encoder.layers.0.self_attn.in_proj_bias torch.Size([768])
- encoder.layers.0.self_attn.out_proj.weight torch.Size([256, 256])
- encoder.layers.0.self_attn.out_proj.bias torch.Size([256])
- encoder.layers.0.mlp.linear1.weight torch.Size([2048, 256])
- encoder.layers.0.mlp.linear1.bias torch.Size([2048])
- encoder.layers.0.mlp.linear2.weight torch.Size([256, 2048])
- encoder.layers.0.mlp.linear2.bias torch.Size([256])
- encoder.layers.1.norm1.weight torch.Size([256])
- encoder.layers.1.norm1.bias torch.Size([256])
- encoder.layers.1.norm2.weight torch.Size([256])
- encoder.layers.1.norm2.bias torch.Size([256])
- encoder.layers.1.self_attn.in_proj_weight torch.Size([768, 256])
- encoder.layers.1.self_attn.in_proj_bias torch.Size([768])
- encoder.layers.1.self_attn.out_proj.weight torch.Size([256, 256])
- encoder.layers.1.self_attn.out_proj.bias torch.Size([256])
- encoder.layers.1.mlp.linear1.weight torch.Size([2048, 256])
- encoder.layers.1.mlp.linear1.bias torch.Size([2048])
- encoder.layers.1.mlp.linear2.weight torch.Size([256, 2048])
- encoder.layers.1.mlp.linear2.bias torch.Size([256])
- encoder.layers.2.norm1.weight torch.Size([256])
- encoder.layers.2.norm1.bias torch.Size([256])
- encoder.layers.2.norm2.weight torch.Size([256])
- encoder.layers.2.norm2.bias torch.Size([256])
- encoder.layers.2.self_attn.in_proj_weight torch.Size([768, 256])
- encoder.layers.2.self_attn.in_proj_bias torch.Size([768])
- encoder.layers.2.self_attn.out_proj.weight torch.Size([256, 256])
- encoder.layers.2.self_attn.out_proj.bias torch.Size([256])
- encoder.layers.2.mlp.linear1.weight torch.Size([2048, 256])
- encoder.layers.2.mlp.linear1.bias torch.Size([2048])
- encoder.layers.2.mlp.linear2.weight torch.Size([256, 2048])
- encoder.layers.2.mlp.linear2.bias torch.Size([256])
- encoder.norm.weight torch.Size([256])
- encoder.norm.bias torch.Size([256])
ope
- ope.iterative_adaptation.layers.0.norm1.weight torch.Size([256])
- ope.iterative_adaptation.layers.0.norm1.bias torch.Size([256])
- ope.iterative_adaptation.layers.0.norm2.weight torch.Size([256])
- ope.iterative_adaptation.layers.0.norm2.bias torch.Size([256])
- ope.iterative_adaptation.layers.0.norm3.weight torch.Size([256])
- ope.iterative_adaptation.layers.0.norm3.bias torch.Size([256])
- ope.iterative_adaptation.layers.0.self_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.0.self_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.0.self_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.0.self_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.0.enc_dec_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.0.enc_dec_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.0.enc_dec_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.0.enc_dec_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.0.mlp.linear1.weight torch.Size([2048, 256])
- ope.iterative_adaptation.layers.0.mlp.linear1.bias torch.Size([2048])
- ope.iterative_adaptation.layers.0.mlp.linear2.weight torch.Size([256, 2048])
- ope.iterative_adaptation.layers.0.mlp.linear2.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.norm1.weight torch.Size([256])
- ope.iterative_adaptation.layers.1.norm1.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.norm2.weight torch.Size([256])
- ope.iterative_adaptation.layers.1.norm2.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.norm3.weight torch.Size([256])
- ope.iterative_adaptation.layers.1.norm3.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.self_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.1.self_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.1.self_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.1.self_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.enc_dec_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.1.enc_dec_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.1.enc_dec_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.1.enc_dec_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.1.mlp.linear1.weight torch.Size([2048, 256])
- ope.iterative_adaptation.layers.1.mlp.linear1.bias torch.Size([2048])
- ope.iterative_adaptation.layers.1.mlp.linear2.weight torch.Size([256, 2048])
- ope.iterative_adaptation.layers.1.mlp.linear2.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.norm1.weight torch.Size([256])
- ope.iterative_adaptation.layers.2.norm1.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.norm2.weight torch.Size([256])
- ope.iterative_adaptation.layers.2.norm2.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.norm3.weight torch.Size([256])
- ope.iterative_adaptation.layers.2.norm3.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.self_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.2.self_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.2.self_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.2.self_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.enc_dec_attn.in_proj_weight torch.Size([768, 256])
- ope.iterative_adaptation.layers.2.enc_dec_attn.in_proj_bias torch.Size([768])
- ope.iterative_adaptation.layers.2.enc_dec_attn.out_proj.weight torch.Size([256, 256])
- ope.iterative_adaptation.layers.2.enc_dec_attn.out_proj.bias torch.Size([256])
- ope.iterative_adaptation.layers.2.mlp.linear1.weight torch.Size([2048, 256])
- ope.iterative_adaptation.layers.2.mlp.linear1.bias torch.Size([2048])
- ope.iterative_adaptation.layers.2.mlp.linear2.weight torch.Size([256, 2048])
- ope.iterative_adaptation.layers.2.mlp.linear2.bias torch.Size([256])
- ope.iterative_adaptation.norm.weight torch.Size([256])
- ope.iterative_adaptation.norm.bias torch.Size([256])
ope.shape_or_objectness
- ope.shape_or_objectness.0.weight torch.Size([64, 2])
- ope.shape_or_objectness.0.bias torch.Size([64])
- ope.shape_or_objectness.2.weight torch.Size([256, 64])
- ope.shape_or_objectness.2.bias torch.Size([256])
- ope.shape_or_objectness.4.weight torch.Size([2304, 256])
- ope.shape_or_objectness.4.bias torch.Size([2304])
回归头
- regression_head.regressor.0.layer.0.weight torch.Size([128, 256, 3, 3])
- regression_head.regressor.0.layer.0.bias torch.Size([128])
- regression_head.regressor.1.layer.0.weight torch.Size([64, 128, 3, 3])
- regression_head.regressor.1.layer.0.bias torch.Size([64])
- regression_head.regressor.2.layer.0.weight torch.Size([32, 64, 3, 3])
- regression_head.regressor.2.layer.0.bias torch.Size([32])
- regression_head.regressor.3.weight torch.Size([1, 32, 1, 1])
- regression_head.regressor.3.bias torch.Size([1])
辅助头
- aux_heads.0.regressor.0.layer.0.weight torch.Size([128, 256, 3, 3])
- aux_heads.0.regressor.0.layer.0.bias torch.Size([128])
- aux_heads.0.regressor.1.layer.0.weight torch.Size([64, 128, 3, 3])
- aux_heads.0.regressor.1.layer.0.bias torch.Size([64])
- aux_heads.0.regressor.2.layer.0.weight torch.Size([32, 64, 3, 3])
- aux_heads.0.regressor.2.layer.0.bias torch.Size([32])
- aux_heads.0.regressor.3.weight torch.Size([1, 32, 1, 1])
- aux_heads.0.regressor.3.bias torch.Size([1])
- aux_heads.1.regressor.0.layer.0.weight torch.Size([128, 256, 3, 3])
- aux_heads.1.regressor.0.layer.0.bias torch.Size([128])
- aux_heads.1.regressor.1.layer.0.weight torch.Size([64, 128, 3, 3])
- aux_heads.1.regressor.1.layer.0.bias torch.Size([64])
- aux_heads.1.regressor.2.layer.0.weight torch.Size([32, 64, 3, 3])
- aux_heads.1.regressor.2.layer.0.bias torch.Size([32])
- aux_heads.1.regressor.3.weight torch.Size([1, 32, 1, 1])
- aux_heads.1.regressor.3.bias torch.Size([1])
Total number of parameters in LOCA: 447974251
Total number of parameters in CCFF: 411099136(这个模块,参数量好大)
相关文章:
【扒网络架构】backbone、ccff
backbone CCFF 还不知道网络连接方式,只是知道了每一层 backbone backbone.backbone.conv1.weight torch.Size([64, 3, 7, 7])backbone.backbone.layer1.0.conv1.weight torch.Size([64, 64, 1, 1])backbone.backbone.layer1.0.conv2.weight torch.Size([64, 64,…...

linux进程
exit()函数正常结束进程 man ps aux 是在使用 ps 命令时常用的一个选项组合,用于显示系统中所有进程的详细信息。aux 不是 ps 命令的一个正式选项,而是三个选项的组合:a, u, 和 x。这三个选项分别代表不同的含义&#…...
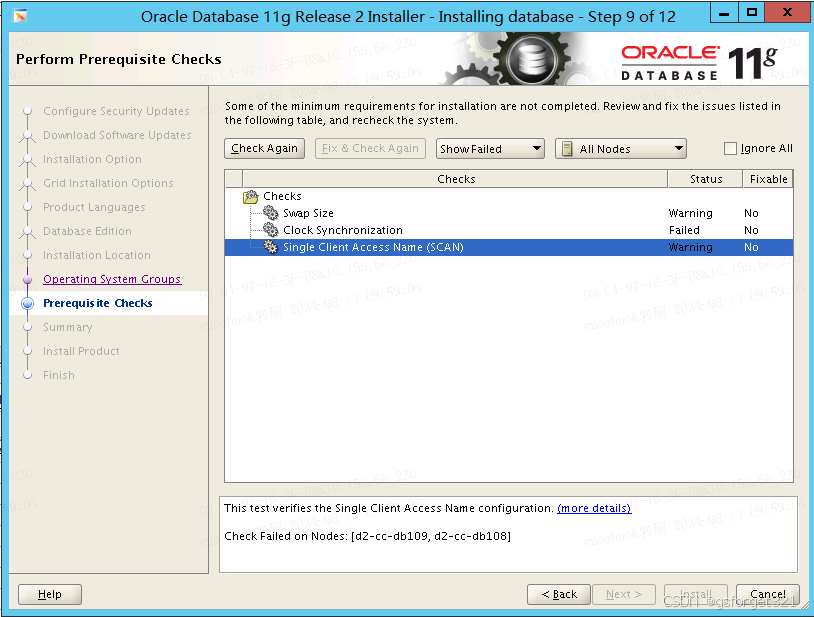
PRVF-4037 : CRS is not installed on any of the nodes
描述:公司要求替换centos,重新安装ORACLE LINUX RAC的数据库做备库,到时候切换成主库,安装Linux7GRID 19C 11G Oracle,顺利安装grid 19c,安装11G数据库软件的时候检测报如题错误:**PRVF-4037 …...

整理 酷炫 Flutter 开源UI框架 FAB
flutter_villains 灵活且易于使用的页面转换。 项目地址:https://github.com/Norbert515/flutter_villains 项目Demo:https://download.csdn.net/download/qq_36040764/89631324...

Unity 编写自己的aar库,接收Android广播(broadcastReceiver)并传递到Unity
编写本文是因为找了很多文章,都比较片段,不容易理解,对于Android新手来说理解起来不友好。我这里写了一个针对比较小白的文章,希望有所帮助。 Android端 首先还是先来写Android端,我们新建一个Android空项目…...

Mysql cast函数、cast用法、字符串转数字、字符串转日期、数据类型转换
文章目录 一、语法二、示例2.1、复杂示例 三、cast与convert的区别 CAST 函数是 SQL 中的一种类型转换函数,它用于将一个数据类型转换为另一个数据类型,这篇文章主要介绍了Mysql中Cast()函数的用法,需要的朋友可以参考下。 Mysql提供了两种将值转换成指…...
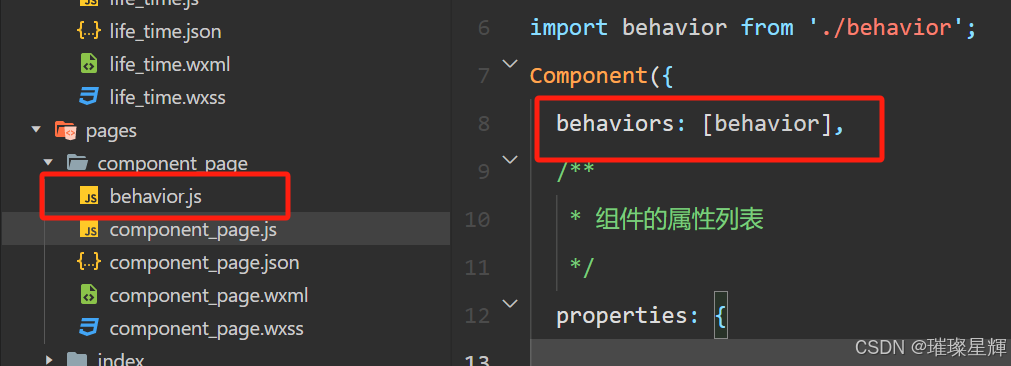
微信小程序开发之组件复用机制
新建复用文件,另外需要注册 behavior 例如: 在behavior.js文件中写入方法,并向外暴露出去 写法一: module.exportsBehavior({data: {num: 1},lifetimes: {created() {console.log(1);}} })写法二: const behavior …...

数据结构--线性表
数据结构分类 集合 线性结构(一对一) 树形结构(一对多) 图结构(多对多) 数据结构三要素 1、逻辑结构 2、数据的运算 3、存储结构(物理结构) 线性表分类 1、顺序表 2、链表 3、栈 4、队列 5、串 线性表--顺序表 顺序表的特点 顺序表的删除和插入…...

深入探针:PHP与DTrace的动态追踪艺术
标题:深入探针:PHP与DTrace的动态追踪艺术 在高性能的PHP应用开发中,深入理解代码的执行流程和性能瓶颈是至关重要的。DTrace,作为一种强大的动态追踪工具,为开发者提供了对PHP脚本运行时行为的深入洞察。本文将详细介…...

黑龙江日报报道第5届中国计算机应用技术大赛,赛氪提供赛事支持
2024年7月17日,黑龙江日报、极光新闻对在哈尔滨市举办的第5届中国计算机应用技术大赛全国总决赛进行了深入报道。此次大赛由中国计算机学会主办,中国计算机学会计算机应用专业委员会与赛氪网共同承办,吸引了来自全国各地的顶尖技术团队和选手…...

【计算机网络】LVS四层负载均衡器
https://mobian.blog.csdn.net/article/details/141093263 https://blog.csdn.net/weixin_42175752/article/details/139966198 《高并发的哲学原理》 (基本来自本书) 《亿级流量系统架构设计与实战》 LVS 章文嵩博士创造 LVS(IPVS) 章⽂嵩发…...
)
Java 守护线程练习 (2024.8.12)
DaemonExercise package DaemonExercise20240812;public class DaemonExercise {public static void main(String[] args) {// 守护线程// 当普通线程执行完毕之后,守护线程没有继续执行的必要,所以说会逐步关闭(并非瞬间关闭)//…...

C#小桌面程序调试出错,如何解决??
🏆本文收录于《CSDN问答解惑-专业版》专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收…...

Seatunnel Mysql数据同步到Mysql
环境 mysql-connector-java-8.0.28.jar、connector-cdc-mysql 配置 env {# You can set SeaTunnel environment configuration hereexecution.parallelism 2job.mode "STREAMING"# 10秒检查一次,可以适当加大这个值checkpoint.interval 10000#execu…...

Java Web —— 第五天(请求响应1)
postman Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件 作用:常用于进行接口测试 简单参数 原始方式 在原始的web程序中,获取请求参数,需要通过HttpServletRequest 对象手动获 http://localhost:8080/simpleParam?nameTom&a…...
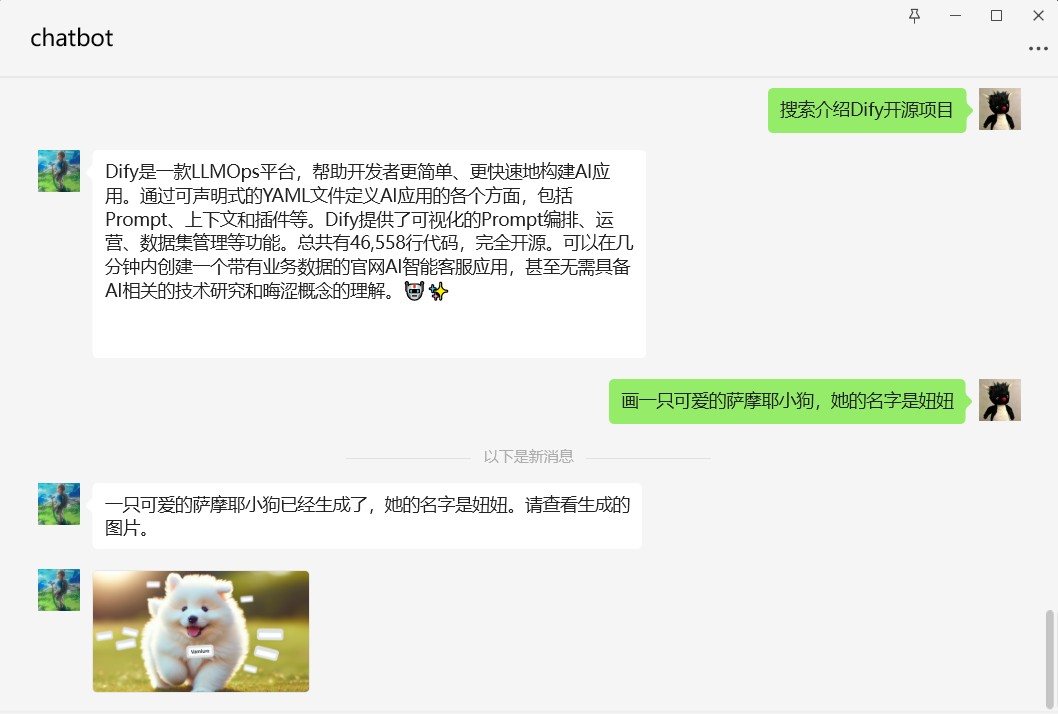
【LLMOps】手摸手教你把 Dify 接入微信生态
作者:韩方圆 "Dify on WeChat"开源项目作者 概述 微信作为最热门即时通信软件,拥有巨大的流量。 微信友好的聊天窗口是天然的AI应用LUI(Language User Interface)/CUI(Conversation User Interface)。 微信不仅有个人微信,同时提供…...
Ftrans文件摆渡方案:重塑文件传输与管控的科技先锋
一、哪些行业会用到文件摆渡相关方案 文件摆渡相关的产品和方案通常用于需要在不同的网络、安全域、网段之间传输数据的场景,主要是一些有核心数据需要保护的行业,做了网络隔离和划分。以下是一些应用比较普遍的行业: 金融行业:…...

LaTeX中的除号表示方法详解
/除号 LaTeX中的除号表示方法详解1. 使用斜杠 / 表示除号优点缺点 2. 使用 \frac{} 表示分数形式的除法优点缺点 3. 使用 \div 表示标准除号优点缺点 4. 使用 \over 表示分数形式的除法优点缺点 5. 使用 \dfrac{} 和 \tfrac{} 表示大型和小型分数优点缺点 总结 LaTeX中的除号表…...

DID、DID文档、VC、VP分别是什么 有什么关系
DID(去中心化身份) 定义:DID 是一种去中心化的唯一标识符,用于表示个体、组织或设备的身份。DID 不依赖于中央管理机构,而是由去中心化网络(如区块链)生成和管理。 用途:DID 允许用…...

网络安全应急响应
前言\n在网络安全领域,有一句广为人知的话:“没有绝对的安全”。这意味着任何系统都有可能被攻破。安全攻击的发生并不可怕,可怕的是从头到尾都毫无察觉。当系统遭遇攻击时,企业的安全人员需要立即进行应急响应,以将影…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...