时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
文章目录
- 前言
- 时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
- 一、VMD-TCN-BiLSTM-Attention模型
- 1. **变分模态分解(VMD)**
- 2. **时间卷积网络(TCN)**
- 3. **双向长短期记忆网络(BiLSTM)**
- 4. **注意力机制(Attention)**
- **VMD-TCN-BiLSTM-Attention模型的流程**
- **总结**
- 二、实验结果
- 三、核心代码
- 四、代码获取
- 五、总结
前言
时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
一、VMD-TCN-BiLSTM-Attention模型
Matlab版本要求:2023a以上
基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
本文提出了一种多变量时间序列预测方法,包括变分模态分解(VMD)、时域卷积(TCN)、双向长短期记忆(BiLSTM)和注意力机制。该方法可以应用于多种领域,例如气象、金融和医疗。首先,VMD可以将原始时间序列分解成多个局部振荡模态,并提取出不同频带的信号。然后,使用TCN模型进行特征提取和时间序列建模。接着,BiLSTM结构可以提高模型的预测精度和泛化能力。最后,引入了注意力机制来加强模型对重要特征的关注,提高预测效果。在各自领域的实验中,本文提出的方法都取得了优异的预测效果,证明了其在多变量时间序列预测中的可行性和有效性。
VMD-TCN-BiLSTM-Attention模型是一个多层次的时间序列预测模型,融合了变分模态分解(VMD)、时间卷积网络(TCN)、双向长短期记忆网络(BiLSTM)和注意力机制(Attention)。这个模型结合了多种技术来处理复杂的时间序列数据,下面详细解释其原理和流程。
1. 变分模态分解(VMD)
**变分模态分解(VMD)**是一种信号处理技术,用于将复杂的时间序列分解为多个模态(IMF,Intrinsic Mode Functions),每个模态包含了信号的不同频率成分。其主要步骤如下:
- 信号分解:将原始时间序列分解为若干个模态分量。这些分量在时间上具有不同的频率。
- 优化目标:通过变分方法优化模态分解过程,使得每个模态的频率成分尽可能纯净。
- 分解输出:得到一组模态分量和一个残差项,这些模态分量可以单独用于进一步建模。
2. 时间卷积网络(TCN)
**时间卷积网络(TCN)**是处理时间序列数据的深度学习模型,基于卷积神经网络(CNN)进行时间序列建模。其主要特点包括:
- 因果卷积:确保模型不会泄露未来信息,通过卷积层只利用过去的信息进行预测。
- 膨胀卷积:通过膨胀卷积扩展卷积核的感受野,从而捕获更长时间范围的依赖。
- 残差连接:增加残差连接以缓解梯度消失问题,并提高模型的训练效率。
3. 双向长短期记忆网络(BiLSTM)
**双向长短期记忆网络(BiLSTM)**是一种改进的LSTM模型,通过双向处理时间序列数据,捕获更多上下文信息。其主要特点包括:
- 双向结构:使用两个LSTM网络,一个从过去到现在,另一个从现在到过去,捕获前后信息。
- 长期依赖:通过LSTM单元记忆长期依赖关系,适应时间序列中的复杂模式。
4. 注意力机制(Attention)
**注意力机制(Attention)**用于提高模型对重要信息的关注能力,尤其是在处理长序列数据时。其主要流程包括:
- 计算注意力权重:根据输入序列计算每个时间步的权重,权重表示该时间步对当前预测的重要性。
- 加权求和:根据计算得到的权重,对序列进行加权求和,从而聚焦于对预测最重要的部分。
- 融合信息:将加权后的信息与其他特征融合,提高模型的预测准确性。
VMD-TCN-BiLSTM-Attention模型的流程
-
信号分解:
- 对输入时间序列数据应用VMD,将其分解为多个模态分量。
-
特征提取:
- 对每个模态分量分别使用TCN进行处理,提取时间序列特征。
- 使用TCN的因果卷积和膨胀卷积处理时间序列数据,以捕获不同时间范围的依赖关系。
-
序列建模:
- 将TCN提取的特征输入到BiLSTM中,捕获时间序列中的双向依赖关系。
-
注意力机制应用:
- 在BiLSTM输出的特征上应用注意力机制,计算每个时间步的重要性。
- 对特征进行加权求和,强调对预测最有用的信息。
-
预测输出:
- 将注意力机制的加权输出输入到最终的预测层(例如全连接层)进行预测。
-
训练与优化:
- 通过损失函数(如均方误差)训练模型,优化所有网络参数(VMD参数、TCN参数、BiLSTM参数和Attention权重)。
总结
VMD-TCN-BiLSTM-Attention模型通过将VMD用于信号分解,TCN用于特征提取,BiLSTM用于序列建模,以及Attention机制用于信息加权,综合利用了各类技术来处理复杂的时间序列数据。这样结合多种方法的模型能够更好地捕捉时间序列中的复杂模式,提高预测精度。
二、实验结果




三、核心代码
%% 数据分析
num_samples = length(X); % 样本个数
or_dim = size(X, 2); % 原始特征+输出数目
kim = 12; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测%% 数据分析
outdim = 1; % 最后一列为输出
num_size = 0.8; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度%% 划分数据集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);%% 格式转换
for i = 1 : M vp_train{i, 1} = p_train(:, i);vt_train{i, 1} = t_train(:, i);
endfor i = 1 : N vp_test{i, 1} = p_test(:, i);vt_test{i, 1} = t_test(:, i);
end%% 创建BiLSTM网络,
layers = [ ...sequenceInputLayer(f_) % 输入层bilstmLayer(64) % BiLSTM层dropoutLayer(0.2) % 丢弃层reluLayer % relu层fullyConnectedLayer(outdim) % 回归层regressionLayer];% 画出曲线四、代码获取
私信即可
五、总结
包括但不限于
优化BP神经网络,深度神经网络DNN,极限学习机ELM,鲁棒极限学习机RELM,核极限学习机KELM,混合核极限学习机HKELM,支持向量机SVR,相关向量机RVM,最小二乘回归PLS,最小二乘支持向量机LSSVM,LightGBM,Xgboost,RBF径向基神经网络,概率神经网络PNN,GRNN,Elman,随机森林RF,卷积神经网络CNN,长短期记忆网络LSTM,BiLSTM,GRU,BiGRU,TCN,BiTCN,CNN-LSTM,TCN-LSTM,BiTCN-BiGRU,LSTM–Attention,VMD–LSTM,PCA–BP等等
用于数据的分类,时序,回归预测。
多特征输入,单输出,多输出
相关文章:
时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention
时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention 文章目录 前言时序预测|基于变分模态分解-时域卷积-双向长短期记忆-注意力机制多变量时间序列预测VMD-TCN-BiLSTM-Attention 一、VMD-TCN-BiLSTM-Attention模型1. **…...

Python知识点:如何使用Godot与Python进行游戏脚本编写
在Godot中使用Python进行游戏脚本编写,你需要通过一个插件来实现,因为Godot原生支持的脚本语言是GDScript、VisualScript和C#。这个插件被称为Godot-Python,它允许你在Godot引擎中使用Python编写脚本。以下是详细的步骤指导你如何配置和使用G…...

Spring MVC数据绑定和响应学习笔记
学习视频:12001 数据绑定_哔哩哔哩_bilibili 目录 1.数据绑定 简单数据绑定 默认类型数据绑定 简单数据类型绑定的概念 参数别名的设置 PathVariable注解的两个常用属性 POJO绑定 自定义类型转换器 xml方式 注解方式 数组绑定 集合绑定 复杂POJO绑定 属性为对象类…...
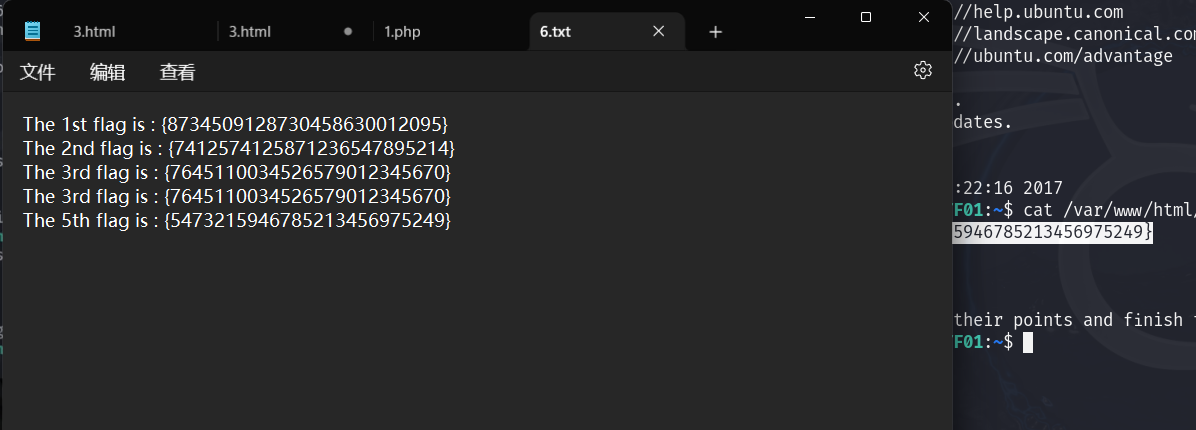
Vulnhub JIS-CTF靶机详解
项目地址 https://www.vulnhub.com/entry/jis-ctf-vulnupload,228/https://www.vulnhub.com/entry/jis-ctf-vulnupload,228/ 修改靶机的网卡 开机时长按shift,进入此页面 选择root模式进入 将只读模式改为读写模式 mount -o remount,rw / 查看本机的网卡名称 …...

FPGA资源评估
FPGA资源评估 文章目录 FPGA资源评估前言一、资源评估1.1 资源有哪些1.2 资源统计 二、 FPGA 的基本结构三、 更为复杂的 FPGA 架构 前言 一、资源评估 大家在项目中一般会要遇到需要资源评估的情况,例如立了新项目,前期需要确定使用什么FPGA片子&…...

REST framework中Views API学习
REST framework提供了一个APIView类,它是Django的View类的子类。 APIView类和一般的View类有以下不同: 被传入到处理方法的请求不会是Django的HttpRequest类的实例,而是REST framework的Request类的实例。处理方法可以返回REST framework的…...
——总结)
Vue(四)——总结
渐进式JavaScript框架 Vue.js是一套构建用户界面(UI)的渐进式JavaScript框架。 1、库和框架的区别? 库:库是提供给开发者的一个封装好的特定于某一方面的集合(方法和函数),库没有控制权&…...

计算机毕业设计 招生宣传管理系统 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

练习题PHP5.6+变长参数 ⇒ usort回调后门 ⇒ 任意代码执行
突破长度限制 使用usort上传后门 usort — 使用用户自定义的比较函数对数组中的值进行排序 paramusort(...$GET); ...为php设置可变长参数 在url地址栏中输入[]test&1[]phpinfo();&2assert 包含了phpiinfo()命令执行 结合usort使用 assert…...

EPLAN关于PLC的输入输出模块绘制
EPLAN关于PLC的输入输出模块绘制 总览图上的PLC绘制原理图上的PLC绘制编辑IO注释显示总览界面IO注释自动关联总览IO地址 总览图上的PLC绘制 右键项目【新建】 页类型选择【总览】,描述可以自由编辑,之后确认即可。 由于我们需要绘制PLC的输入输出&#x…...

【Linux】sersync 实时同步
原理 rsync 是不支持实时同步的,通常我们借助于 inotify 这个软件来实时监控文件变化,一旦inotify 监控到文件变化,则立即调用 rsync 进行同步,推送到 rsync 服务端。 环境准备 步骤1:获取数据包 获取 sersync 的包…...

Unity 资源分享 之 恐龙Ceratosaurus资源模型携 82 个动画来袭
Unity 资源分享 之 恐龙Ceratosaurus资源模型携 82 个动画来袭 一、前言二,资源包内容三、免费获取资源包 一、前言 亲爱的 Unity 开发者和爱好者们,大家好!今天要为大家分享一份超级酷炫的 Unity 资源——恐龙资源模型,而且它还…...

【AI绘画】 学习内容简介
AI绘画-学习内容简介 1. 效果展示 本次测试主要结果展示如下: 卡通手办定制1 卡通手办定制2 艺术写真定制 2. 主要目录 AI 绘画- 文生图,图生图及lora使用(基于diffusers) AI 绘画- 模型转换与快速生图(基于diffus…...

树形结构查找(B树、B+树)
平衡树结构的树高为 O(logn) ,平衡树结构包括两种平衡二叉树结构(分别为 AVL 树和 RBT)以及一种树结构(B-Tree,又称 B 树,它的度大于 2 )。AVL 树和 RBT 适合内部存储的应用,而 B 树…...

网络通信(TCP/UDP协议 三次握手四次挥手 )
三、TCP协议与UDP协议 1、TCP/IP、TCP、 UDP是什么 TCP/IP协议是一个协议簇,里面包括很多协议的, UDP只是其中的一个, 之所以命名为TCP/IP协议, 因为TCP、 IP协议是两个很重要的协议,就用他两命名了,而TCP…...

C# ADO.Net 通用按月建表插入数据
原理是获取原表表结构以及索引动态拼接建表SQL,如果月表存在则不创建,不存在则创建表结构 代码如下 /// <summary>/// 根据指定的表名和时间按月进行建表插入(如果不存在对应的月表)/// </summary>/// <param nam…...

19-ESP32-C3加大固件储存区
1默认编译情况。 2、改flash4M。ESP-IDF Partition Table Editor修改。 3、设置输入Partition Table 改自定义.CSV。保存。 4、查看命令输入Partition Table Editor打开-分区表编辑器UI。按图片增加。 nvs,data,nvs,0x9000,0x6000,, phy_init,data,phy,0xF000,0x1000,, factory…...

【STL】stack/queue 容器适配器 deque
1.stack的介绍和使用 1.1.stack的介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容…...

(回溯) LeetCode 17. 电话号码的组合
原题链接 一. 题目描述 17. 电话号码的字母组合 已解答 中等 相关标签 相关企业 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对…...

Ghidra:开源软件逆向工程框架
Ghidra 是一个软件逆向工程 (SRE) 框架 Ghidra 是一种尖端的开源软件逆向工程 (SRE) 框架,是美国国家安全局 (NSA) 研究局的产品。 Ghidra 该框架具有高端软件分析工具,使用户能够分析跨各种平台(包括 Windows、macOS 和 Linux)…...

3个技巧让NoFences重塑你的Windows桌面工作流
3个技巧让NoFences重塑你的Windows桌面工作流 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 每天打开电脑,面对满屏杂乱的图标和文件,是不是感觉工作…...
)
跟着 MDN 学 HTML day_35:(深入解析 CharacterData 抽象接口)
在 DOM 的庞大体系中,并非所有节点都以可见的标签形式存在。当我们操作一段文本、一条注释甚至一条处理指令时,背后都有一个共同的基类在默默提供支持。这个基类就是 CharacterData。它是一个抽象接口,意味着你不会在代码中直接创建 Characte…...

C语言老鸟的私藏:Doxygen注释模板这样写,团队协作效率翻倍
C语言团队协作的Doxygen注释实战指南:从规范到自动化 在嵌入式开发领域,代码注释的混乱程度往往与团队规模成正比。当项目从单人开发扩展到5人以上的协作时,你会发现:同样的功能模块,A工程师用//写单行注释࿰…...

AI教材编写工具实测:低查重效果显著,让教材生成更轻松!
教材编写的合规挑战与 AI 工具的解决方案 在教材编写的过程中,原创性与合规性之间的平衡是一个重要的问题。在借鉴优质教材内容的同时,创作者们往往担心查重率过高;而在尝试自主原创知识点时,又可能面临逻辑不严谨或内容不准确的…...
开源APP与小程序双端控制C51单片机,基于ESP8266与MQTT)
(可云端)开源APP与小程序双端控制C51单片机,基于ESP8266与MQTT
1. 项目效果与核心原理 想象一下,你躺在沙发上用手机APP就能控制书桌上的单片机小灯,或者在外出时通过微信小程序查看家里的温湿度数据。这个基于ESP8266和MQTT协议的开源方案,就能帮你实现这些酷炫的功能。我去年给自家花盆做的自动浇水系统…...
)
机械工程师的Gazebo捷径:用SolidWorks建模,5步搞定你的仿真世界(.world文件生成)
机械工程师的Gazebo捷径:用SolidWorks建模,5步搞定你的仿真世界 作为一名机械工程师,你可能已经习惯了SolidWorks精确的建模环境,但当需要将设计转移到机器人仿真平台Gazebo时,却常常感到束手无策。本文将为你揭示一条…...

CANopen设备配置实战:手把手教你用Python-canopen库读写EDS文件中的对象字典
CANopen设备配置实战:Python-canopen库深度应用指南 在工业自动化领域,CANopen协议因其高可靠性和灵活性成为众多设备厂商的首选。但对于开发者而言,手动配置每个节点的对象字典(Object Dictionary)不仅耗时耗力,还容易出错。这正…...

Diablo Edit2:暗黑破坏神II角色编辑器的完全指南
Diablo Edit2:暗黑破坏神II角色编辑器的完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神II中花费数百小时刷装备、练级,却发现距离理想角色…...

2026届必备的五大AI辅助论文工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作的进程当中,恰当地运用论文AI工具,能够明显地提高文献检索…...

8大网盘直链下载助手终极指南:告别限速,实现高速下载自由
8大网盘直链下载助手终极指南:告别限速,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...