【Python机器学习】FP-growth算法——构建FP树
在第二次扫描数据集时会构建一棵FP树。为构建一棵树,需要一个容器来保存树。
创建FP树的数据结构
FP树要比书中其他树更加复杂,因此需要创建一个类来保存树的每一个节点:
class treeNode:def __init__(self,nameValue,numOccur,parentNode):self.name=nameValueself.count=numOccurself.nodeLink=Noneself.parent=parentNodeself.children={}def inc(self,numOccur):self.count=self.count+numOccurdef disp(self,ind=1):print(' '*ind,self.name,' ',self.count)for child in self.children.values():child.disp(ind+1)上面的程序给出了FP树中节点的类定义。类中包含用于存放节点名字的变量和1个计数值,nodeLink变量用于链接相似的元素项。类中还使用了父变量parent来指向当前节点的父节点。通常情况下并不需要这个变量,因为通常是从上向下迭代访问节点的。之后还需要根据给定叶子节点上溯整棵树,这是就需要指向父节点的指针。最后,类中还包括一个空字典变量,用于存放节点的子节点。
上述代码还包括两个方法,其中inc()对count变量增加给定值,另一个方法disp()用于将树以文本形式显示。后者对于树构建来说并不是必要的,但它对调试非常有用。
创建一棵树的一个单节点,之后为其增加一个子节点:
rootNode=treeNode('pyramid',9,None)
rootNode.children['eye']=treeNode('eye',13,None)
print(rootNode.disp())
再添加一个节点看一下两个子节点的展示效果:
rootNode.children['phoenix']=treeNode('phoenix',3,None)
print(rootNode.disp())
现在FP树所需的数据结构已经建好,之后就可以构建FP树了。
构建FP树
FP树中,需要一个头指针来指向给定类型的第一个实例。利用头指针表,可以快速访问FP树中一个给定类型的所有元素,比如:

这里使用一个字典作为数据结构,来保存头指针表。除了存放指针外,头指针表还可以用来保存FP树中每个元素的总数。
第一次遍历数据集会获得每个元素项的出现频率。接下来,去掉不满足最小支持度的元素项。再下一步构建FP树。在构建时,读入每个项集并将其添加到一条已经存在的路径中。如果该路径不存在,则创建一条新路径。每个事务就是一个无序集合。假设有集合{z,x,y}和{y,z,r},那么在FP树中,相同项会只表示一次。为了解决这个问题,在将集合添加到树之前,需要对每个集合进行排序。排序基于元素项的绝对出现频率来进行。使用上图中的头指针节点值,对数据进行过滤、重排序的数据如下:

在对事务记录进行过滤和排序之后,就可以构建FP树了。从空集开始,向其中不断添加频繁项集。过滤、排序后的事务依次添加到树中,如果树中已存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分枝。
对上表前两条事务进行添加的过程:

接下来是代码实现上述过程:
def createTree(dataSet,minSup=1):headerTable={}for trans in dataSet:for item in trans:headerTable[item]=headerTable.get(item,0)+dataSet[trans]#移除不满足最小支持度的元素项#print('keys:',list(headerTable.keys()))for k in list(headerTable.keys()):if headerTable[k]<minSup:del(headerTable[k])freqItemSet=set(headerTable.keys())#如果没有元素项满足要求,退出,返回Noneif len(freqItemSet)==0:return None,Nonefor k in headerTable:headerTable[k]=[headerTable[k],None]retTree=treeNode('Null set',1,None)for tranSet,count in dataSet.items():localD={}for item in tranSet:if item in freqItemSet:localD[item]=headerTable[item][0]if len(localD)>0:orderedItems=[v[0] for v in sorted(localD.items(),key=lambda p:p[1],reverse=True)]#使用排序后的频率项集对树进行填充updateTree(orderedItems,retTree,headerTable,count)return retTree,headerTabledef updateTree(items,inTree,headerTable,count):if items[0] in inTree.children:inTree.children[items[0]].inc(count)else:inTree.children[items[0]]=treeNode(items[0],count,inTree)if headerTable[items[0]][1]==None:headerTable[items[0]][1]=inTree.children[items[0]]else:updateHeader(headerTable[items[0]][1],inTree.children[items[0]])if len(items) > 1:#对剩下的元素迭代调用updateTree函数updateTree(items[1::],inTree.children[items[0]],headerTable,count)
def updateHeader(nodeToTest,targetNode):while (nodeToTest.nodeLink != None):nodeToTest=nodeToTest.nodeLinknodeToTest.nodeLink=targetNode上述代码包含3个函数。第一个函数createTree()使用数据集以及最小支持度作为参数构建FP树。树构建过程中会遍历数据集两次。第一次遍历扫描数据集并统计每个元素项出现的频度。所有所有项都不频繁,就不需要进行下一步处理。接下来,对头指针表稍加扩展以便可以保存计数值及指向每种类型第一个元素项的指针。然后创建只包含空集合的根节点。最后,再一次遍历数据集,这次只考虑哪些频繁项。这些项已经进行了排序,然后调用updateTree()方法。
为了让FP树生长,需调用updateTree,其中的输入参数为一个项集。该函数首先测试事务中的第一个元素项是否作为子节点存在。如果存在的话,则更新该元素项的计数;如果不存在,则创建一个新的treeNode并将其作为一个子节点添加到树中。这是,头指针表也要更新以指向新的节点。更新头指针表需要调用函数updateHeader()。updateTree()完成的最后一件事是不断迭代调用自身,每次调用时会去掉列表中第一个元素。
最后一个函数是updateHeader(),它确保节点链接指向树中该元素项的每一个实例。从头指针的nodeLink开始,一直沿着nodeLink直到到达链表末尾。这就是一个链表。当处理树的时候,一种很自然的反应就是迭代完成每一件事。当以相同方式处理链表时可能会遇到一些问题,原因是如果链表很长可能会遇到迭代调用的次数限制。
下面,创建一个真正的数据集,用来运行上面的函数,查看运行效果:
def loadSimpDat():simpDat=[['r','z','h','j','p'],['z','y','x','w','v','u','t','s'],['z'],['r','x','n','o','s'],['y','r','x','z','q','t','p'],['y','z','x','e','q','s','t','m']]return simpDat
def createInitSet(dataSet):retDict={}for trans in dataSet:retDict[frozenset(trans)]=1return retDict下面,实际运行,首先导入数据库实例,然后对数据进行格式化处理:
simpDat=loadSimpDat()
print(simpDat)
接下来,为了函数createTree,需要对上面的数据进行格式化处理:
initSet=createInitSet(simpDat)
print(initSet)
创建FP树:
myFPtree,myHeaderTab=createTree(initSet,3)
print(myFPtree.disp())
上面给出的是元素项及其对应的频率计数值,其中每个缩进表示所处的数的深度。
相关文章:
【Python机器学习】FP-growth算法——构建FP树
在第二次扫描数据集时会构建一棵FP树。为构建一棵树,需要一个容器来保存树。 创建FP树的数据结构 FP树要比书中其他树更加复杂,因此需要创建一个类来保存树的每一个节点: class treeNode:def __init__(self,nameValue,numOccur,parentNode…...

JAVA itextpdf 段落自动分页指定固定行距打印
JAVA itextpdf 段落自动分页指定固定行距打印 前言:公司有个需求,打印的合同模板左上角要加上logo的图标。但是itext pdf 自动分页会按照默认的顶部高分页打印内容的,导致从第二页开始logo图标就会把合同的内容给覆盖掉了。然后尝试了挺多方法…...

基于SpringBoot+Vue的周边游平台个人管理模块的设计与实现
TOC springboot220基于SpringBootVue的周边游平台个人管理模块的设计与实现 第一章 绪论 1.1 选题背景 目前整个社会发展的速度,严重依赖于互联网,如果没有了互联网的存在,市场可能会一蹶不振,严重影响经济的发展水平…...

开源数据库同步工具monstache
Monstache是一个用Go语言编写的同步工具,主要用于将MongoDB中的数据同步到Elasticsearch中。它支持全量同步和增量同步,并提供了丰富的配置参数以及使用Go、JavaScript编写插件来自定义处理数据的逻辑的能力。Monstache 工作流程如下图: 以下…...

Ubuntu连接GitHub
报错:Please make sure you have the correct access rights and the repository exists.原因:本地没有SSH Key存在解决: 首先为系统设置github的用户名和自己的邮箱 git config --global user.name "****" git config --global us…...

微信支付流程
1. 创建订单 请求创建订单的 API 接口:把 订单金额、收货地址、订单中包含的商品信息 发送到服务器服务器响应的结果:订单编号 2.订单预支付 请求订单预支付的 API 接口:把步骤1得到的 订单编号 发送到服务器服务器响应的结果:…...

LVS理论知识
目录 1.描述以及工作原理 1.什么是LVS 2.LVS调度算法 1.静态调度算法 1.轮询RR 2.加权轮询WRR 3.目标地址hash---DH 4.源地址hash---SH 2.动态调度算法 1.LC最少连接 2.wlc加权最少连接 3.sed最少期望延迟 4.nq不排队调度算法 5.lblc基于本地最少连接 6.lnlcr带…...

uniapp接口请求this.$request
代码示例: createPhoto(url) {this.$request({url: /emp/gallery-photo/create,//后端接口method: post,//请求方法header: {//请求头tenant-id: 1,},data: {//请求参数galleryId: this.albumId,empUserId: this.empUserId,"url": url,}}).then((res) &…...
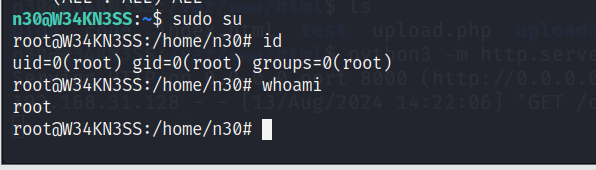
vulnhub靶机 W34KN3SS(渗透测试详解)
一、靶机信息收集 1、靶机下载地址 https://download.vulnhub.com/w34kn3ss/W34KN3SS.ova 2、扫描靶机IP 3、探测靶机端口、主机、服务版本信息 nmap -sS -sV -A -p- 192.168.31.160 4、进行目录扫描 二、web渗透测试 1、访问靶机IP 没什么发现 2、进行目录拼接访问 拼接…...

2024年8月16日嵌入式学习
今日复习信号量的知识点和学习了进程间通信和管道 总结信息量: 共享进程资源 方便 线程 抢占公共资源 带来的问题 1. 互斥访问 需要互斥锁 来保障 原子性操作 使 操作过程 完整 互斥锁: a.初始化 锁 b.加锁 //使用资源之前 …...

vue+ckEditor5 复制粘贴wold文字+图片并保存格式
第一步在vue2项目下安装 npm install --save ckeditor/ckeditor5-build-decoupled-document 第二 项目下新建一个plugins的文件夹将这个包ckeditor5-build-classic放入 (包在页面最上方 有个下载按钮 可以下载) 刚开始时 ckeditor5-build-classic文件…...

redis列表若干记录
2、列表 ziplist ziplist参数 entry结构 entry-data:节点存储的元素prelen:记录前驱节点长度encoding:当前节点编码格式encoding encoding属性 使用多个子节点存储节点元素长度,这种多字节数据存储在计算机内存中或者进行网络传输的时的字节…...

固态硬盘用mbr还是GPT?固态硬盘分区类型用mbr还是GPT分析
固态硬盘用mbr还是GPT?答:固态硬盘分区类型用mbr还是gpt其实取决于你对分区要求及引导模式。我们知道现在的引导模式有uefi和legacy两种引导模式,如果采用的是uefi引导模式,分区类型对应的就是gpt分区(guid),如果引导模…...

http/sse/websocket 三大协议演化历史以及 sse协议下 node.js express 服务实现打字机案例 负载均衡下的广播实现机制
背景 自从2022年底chatgpt上线后,sse就进入了大众的视野,之前是谁知道这玩意是什么?但是打字机的效果看起来是真的很不错,一度吸引了很多人的趋之若鹜,当然了这个东西的确挺好用,而且实现很简单࿰…...

智能时代新宠:2024年录音转文字软件
无论是学生群体记录课堂笔记,职场人士整理会议纪要,还是自媒体创作者捕捉灵感火花,录音转文字软件都以其独特的便利性和高效性赢得了广泛的好评。今天,就让我们一起探索那些深受大家喜爱的录音转文字工具吧。 1.365在线转文字 链…...

【Python机器学习】树回归——使用Python的tkinter库创建GUI
机器学习给我们提供了一些强大的工具,能从未知数据中抽取出有用的信息。因此,能否这些信息以易于人们理解的方式呈现十分重要。如果人们可以直接与算法和数据交互,将可以比较轻松的进行解释。其中一个能够同时支持数据呈现和用户交互的方式就…...

谷歌浏览器网页底图设置为全黑
输入网址:chrome://flags/ 搜索dark,选择Enabled,重启浏览器即可...
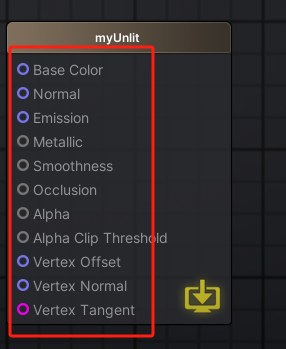
Unity | AmplifyShaderEditor插件基础(第二集:模版说明)
目录 一、前言 二、核心模版和URP模版 1.区别介绍 2.自己的模版 三、输出节点 1.界面 2.打开OutPut 3.ShderType 4.ShaderName 5.Shader大块内容 6.修改内容 四、预告 一、前言 内容全部基于以下链接基础以上讲的。 Unity | Shader基础知识(什么是shader…...

【Linux入门】Linux常见指令
目录 前言 一、Linux基本指令 1.ls指令 2.pwd命令 3.cd 指令 4.touch指令 5.mkdir指令 6.rmdir指令 && rm 指令 7.man指令 8.cp指令 9.mv指令 10.cat 11.date 12.top 13.shutdown-关机 14.重要的几个热键 二、Linux扩展指令 总结 前言 Linux指令是在…...

startData
某音startData 记得加入学习群: python爬虫&js逆向3 714283180...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...