生物研究新范式!AI语言模型在生物研究中的应用

–https://doi.org/10.1038/s41592-024-02354-y
留意更多内容,欢迎关注微信公众号:组学之心
Language models for biological research: a primer
研究团队及研究单位
James Zou–Department of Biomedical Data Science, Stanford University, Stanford, USA

Kyle Swanson–Department of Computer Science, Stanford University, Stanford, USA

一、语言模型在多领域序列数据分析中的应用与优势
近年来,由于大规模、可公开访问的文本生成模型的发展,语言模型越来越受欢迎。由于这些模型是在大量异构序列集合上训练的,因此它们可以学习灵活的模式,并可以适应解决各种特定问题。
例如,ChatGPT 被训练来填补文本中缺失的单词,但这种训练过程使其能够推理语言并解决从总结论文到编写生物信息学代码等各种问题。
此外,语言模型可以适应解决它们最初没有被设计用于解决的问题,其表现优于专门针对这些问题进行训练的模型。由于这种灵活性,语言模型通常是实现广泛下游应用的基础模型。语言模型不仅限于自然语言,它们还可以处理由生物实体序列(例如氨基酸或基因)组成的生物语言。
1.基于Transformer架构的语言模型
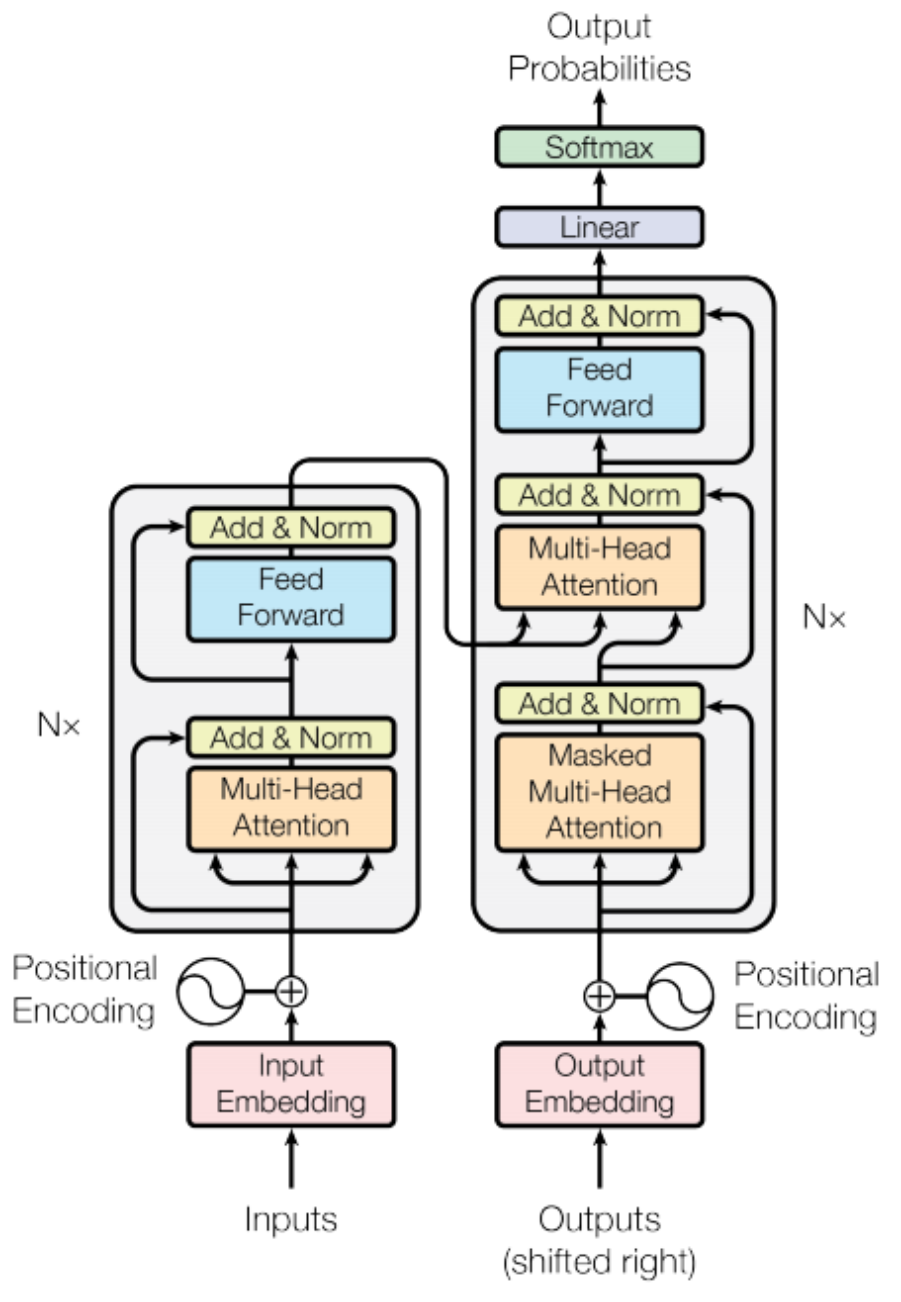
Transformer这是一种可以捕获长序列模式的人工神经网络。它的相关专业术语如下:
-
1.语言模型:一种学习根据训练数据预测序列中项的可能性的人工智能模型。
-
2.自然语言模型:一种训练于人类语言文本序列上的语言模型。
-
3.生物语言模型:一种训练于生物实体序列(如氨基酸或基因)上的语言模型,这些生物实体被视为语言。
-
4.基础模型:一种可以灵活适应多种不同应用的人工智能模型。
-
5.Transformer:一种通过称为注意力的机制处理序列数据的模型,该机制动态地权衡输入数据不同部分的重要性。
-
6.Token:序列的基本单位,如单词、氨基酸或基因,作为语言模型的基本输入单位。
-
7.Embedding: 一种通过模型学习的输入的数值表示(数字列表),用于捕捉其语义或功能属性。
-
8.迁移学习:一种机器学习方法,其中在一个任务上训练的模型被调整以执行不同但相关的任务,通常需要较少的数据和训练时间。
-
9.预训练:迁移学习的第一步,机器学习模型在大型数据集上进行训练以学习通用特征。
-
10.微调:迁移学习的第二步,在此步骤中,预训练模型被调整以适应特定任务,通过在与预期目标相关的新数据上进行训练实现。这可能包括进一步训练原始模型或在新模型上训练语言模型中的嵌入。
-
11.多模态模型:一种可以处理和集成多种类型输入数据的模型,如文本和图像。
-
12.生成模型:一种训练生成与其训练数据相似的新数据的模型。
-
13.无监督学习:一种机器学习类型,学习从没有明确标签的数据集中的数据,通常用于在数据中找到模式或结构。
-
14.幻觉:生成看似合理但事实上不正确或不一致的语言模型输出。
-
15.降维:一种减少高维数据中特征数量的技术,同时保留其本质结构。通常使用降维技术将模型嵌入物减少到两个维度以便可视化。
-
16.掩码: 一种用于替换输入序列部分的特殊标记,模型通过预测围绕上下文来学习这些标记。
例如,它可以学习到一篇论文的摘要总结了后续文本,并且可以学习到蛋白质序列中氨基酸之间的物理接触,即使它们相距很远。这些模型通常以无监督的生成方式进行训练,这意味着训练序列没有特定的标签供模型预测(无监督);相反,它学习重新生成训练输入序列(生成)。通过这个生成过程,模型学习控制数据形式的底层规则。为了针对其他目标定制这些模型,已经在数据上训练过(预训练)的模型通常会在新数据上进一步训练(微调)。这个过程称为迁移学习,其中在更大的数据集上进行预训练为模型提供了对数据的基本理解,从而能够在微调过程中更有效地学习新目标。
2.语言模型在生物数据中的应用
语言模型可以应用于任何序列数据,无论序列的基本单位(称为Token)是句子中的单词还是蛋白质中的氨基酸。尽管句子和蛋白质是自然序列的,但其他类型的生物数据也可以表示为序列。
例如,单细胞基因表达数据通常不以序列表示,可以通过创建基因按其在细胞中的 RNA 表达水平顺序出现的序列来按顺序表示。通过将每个单细胞视为基因序列,生物语言模型可以使用这些序列作为输入来模拟细胞之间的单细胞 RNA 表达水平。当语言模型处理输入序列时,它会在内部计算嵌入,这是输入的数值表示,可以简洁地捕捉其语义或功能属性。
3.预训练语言模型的三种应用方法
预训练语言模型可通过三种常见方法用于解决许多研究问题:(1)直接预测、(2)嵌入分析和(3)迁移学习。
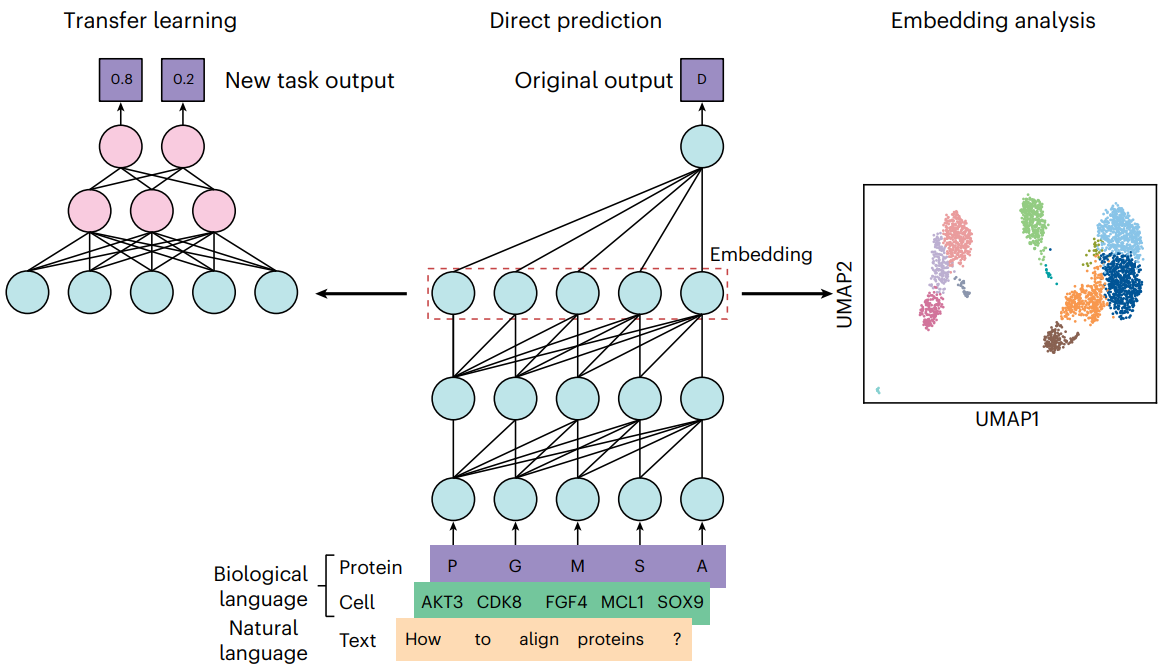
直接预测方法最简单;语言模型被赋予某些输入并按原样用于进行预测。Embedding 分析计算输入序列的 embeddings,以用于数据分析和可视化。在迁移学习方法中,对与期望目标相关的新数据进行额外训练。根据特定任务数据和计算资源的可用性,这可能涉及微调原始语言模型或使用语言模型中的嵌入训练新模型(这也可以被视为一种微调形式)。
二、自然语言模型
1.生物学自然语言模型简介
尽管生物学从根本上依赖于物理实体(蛋白质、基因和细胞)的特性,但我们对该领域的理解是通过科学论文、教科书、网页等以自然语言记录的。因此,人们越来越有兴趣使用自然语言模型,让生物学研究人员可以轻松访问这些书面资源中包含的大量生物学信息。
此外,自然语言模型可以通过来自其他模态(例如图像或基因序列)的数据进行扩充,以形成多模态模型,从而可以洞察各种形式的生物实体。
2.生物学的“通用”与“专用”自然语言模型
自然语言模型可以训练为通用模型(例如 ChatGPT 或 Claude),这些模型在包括 PubMed 等生物学来源的广泛文本语料库上进行训练。

或者,它们也可以设计为专用模型(例如 BioBERT 或 Med-PaLM 2),这些模型专门针对生物学文本进行训练或微调。由于知识广博,当前的专用模型在生物医学任务(例如回答医学考试问题)上的表现可以优于通用模型。
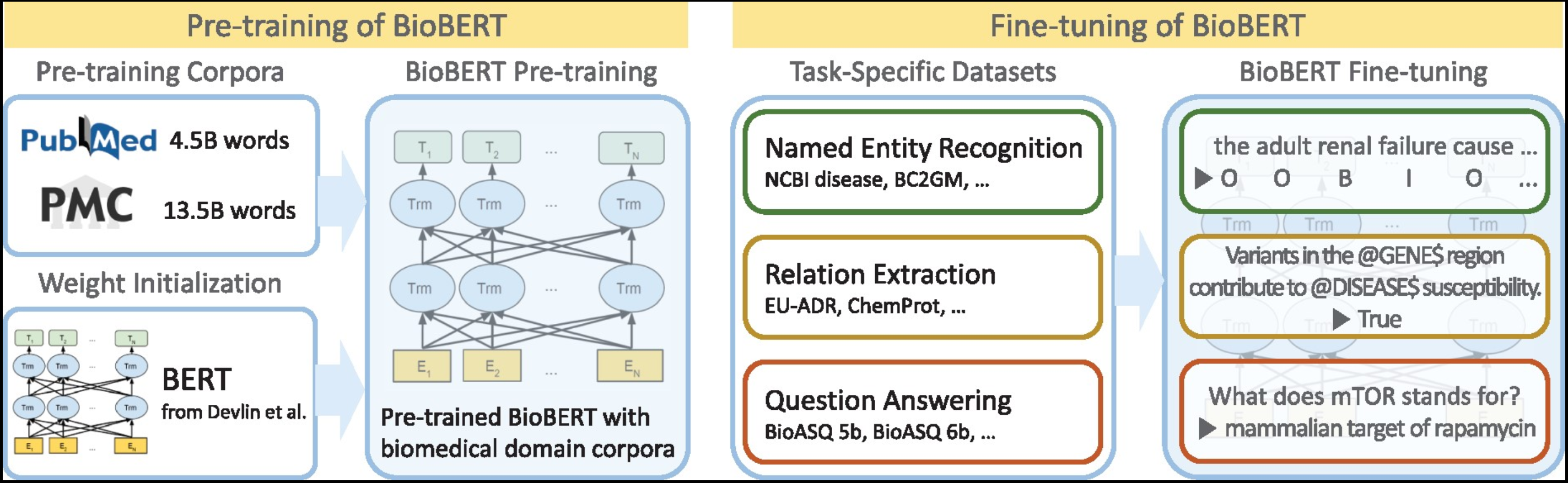
BioBERT—https://doi.org/10.1093/bioinformatics/btz682
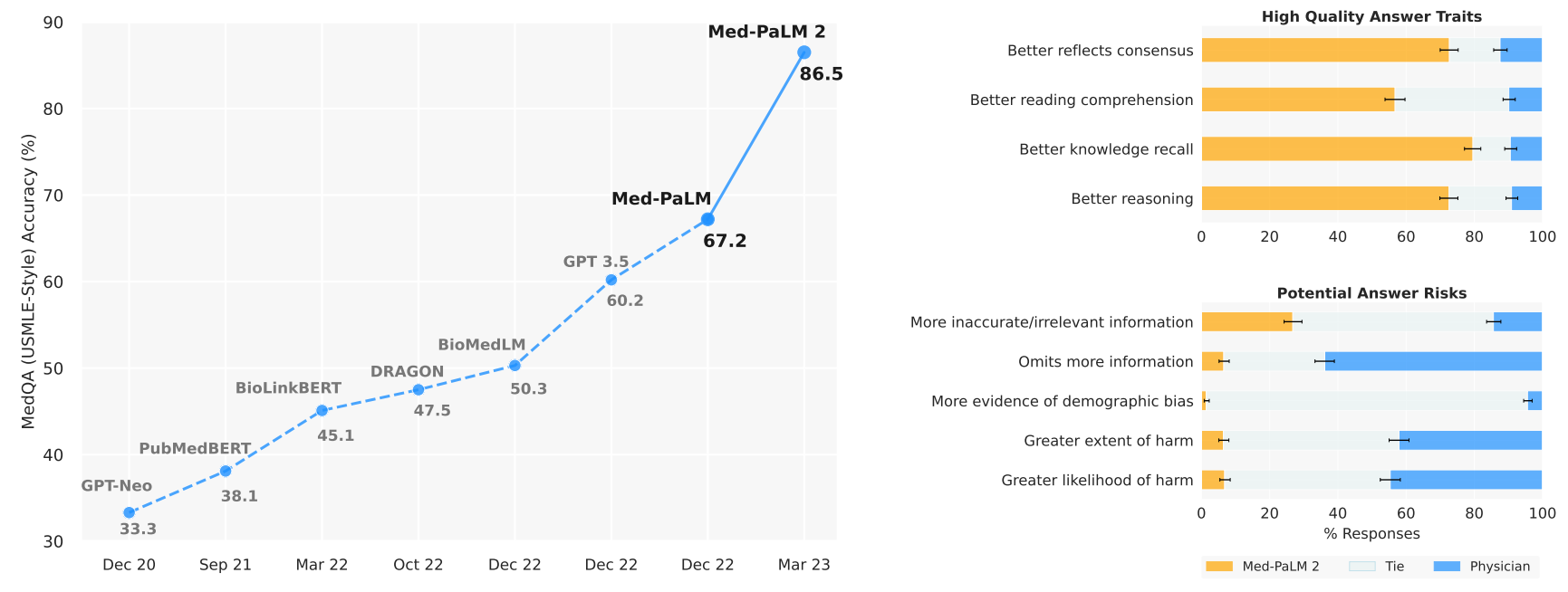
Med-PaLM 2—https://arxiv.org/pdf/2305.09617
3.用于理解生物学文献的自然语言模型
自然语言模型的主要优势在于它们能够推理大量生物学文献并将信息提炼为易于理解的答案。例如,如果研究人员遇到不熟悉的技术概念(例如多序列比对),他们可以让语言模型用简洁的段落解释该概念,而无需花时间查找参考文献。此外,研究人员可以根据他们的背景修改输入,以获得适合他们的答案(例如,“向具有生物学入门背景的人解释多序列比对”)。
除了总结生物学概念外,自然语言模型还可以帮助研究人员快速理解新的科学内容。例如,科学家可以为语言模型提供新科学论文的链接,并要求模型总结内容或回答有关其方法论的特定技术问题。

自然语言模型甚至可以根据现有研究文献提出新的生物医学研究思路(例如,使用 AI 处理多序列比对的新方法)。
尽管自然语言模型是理解生物学文献的有力工具,但一个众所周知的局限性是它们倾向于“产生幻觉”,或生成包含事实错误的连贯文本。此外,这些模型可能不会批判性地评估它们处理的内容,可能会反映作者的解释,而不质疑这些解释是否得到数据的支持。因此,对自然语言模型的输出进行事实核查以确保其准确性,并批判性地评估模型得出的任何结论至关重要。
4.用于与软件交互的自然语言模型
除了理解科学文献之外,自然语言模型还可以通过帮助科学家与软件交互(包括编写和调试代码)来加速研究。自然语言模型包含有关生物信息学分析的重要知识,因此可以帮助研究人员编写用于数据处理、结果分析、绘图等的代码。当研究人员不熟悉特定领域的软件包(例如,用于单细胞分析的 Scanpy)时,这些模型特别有用,因为模型既知道这些包何时合适,又知道如何与每个包的各个组件交互。

自然语言模型也是出色的调试工具,可以为其提供损坏的代码和/或错误消息,并要求其编写更正的代码。此外,这些模型可以为软件工具提供自然语言界面,否则这些工具需要领域专业知识才能使用。例如,ChemCrow 允许用户以自然语言提出问题(例如,“设计可溶分子”),并修改用户的查询以使 ChatGPT 能够运行化学专用软件工具(例如,分子合成规划)。这种能力使得更广泛的科学受众能够使用这些工具。
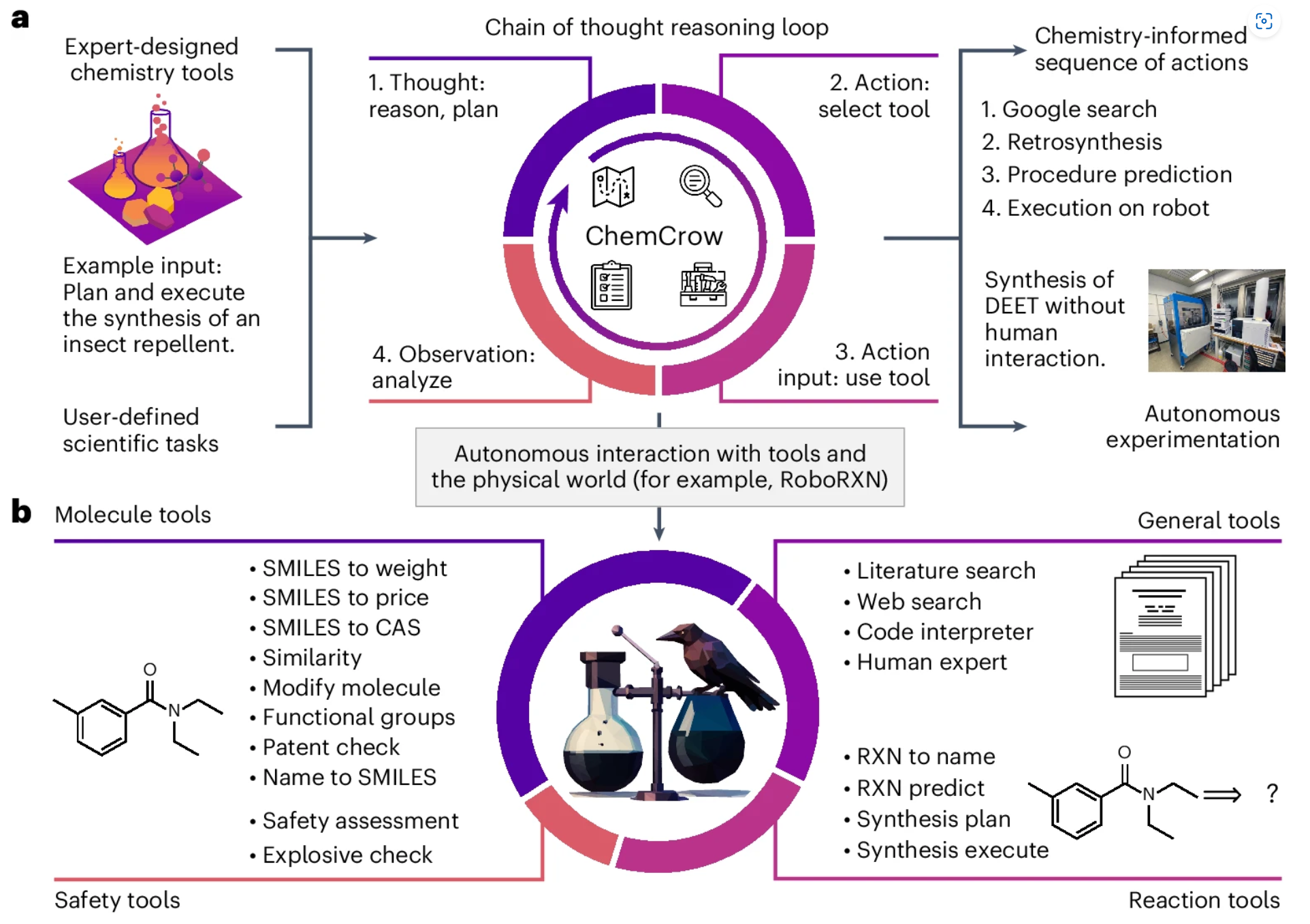
ChemCrow—https://doi.org/10.1038/s42256-024-00832-8
三、生物语言模型
1.蛋白质语言模型
为什么大规模的预训练有用?在大型蛋白质序列数据集上预训练的蛋白质语言模型可以学习捕获蛋白质的进化约束和关键属性的表示。随后在较小的标记数据集上对这些模型进行微调,可以准确预测下游任务,例如稳定性、相互作用,甚至具有指定结构的序列设计。
1.1 蛋白质语言模型例子:ESM-2
这是一个 Transformer 神经网络,通过预测周围环境中随机屏蔽的氨基酸,对超过 2.5 亿个蛋白质序列进行训练。
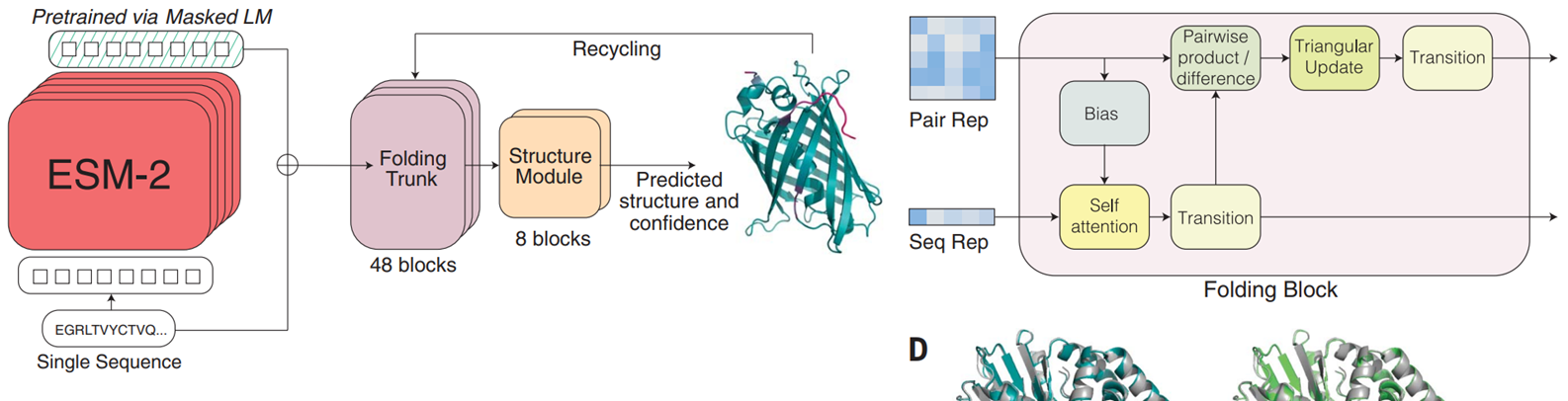
ESM-2—https://www.science.org/doi/10.1126/science.ade2574
在训练过程中,每个序列中的随机氨基酸子集被假的“屏蔽”氨基酸替换,模型会预测被屏蔽的原始氨基酸。通过学习准确预测哪些氨基酸适合给定的序列环境,模型可以学习控制蛋白质结构和功能的模式和约束。正如自然语言模型种类繁多一样,也有各种蛋白质语言模型,它们的训练方式略有不同。例如,一些蛋白质语言模型可能使用专注于单个蛋白质家族的数据进行训练,或者它们可能按顺序预测氨基酸,更类似于自然语言模型,而不是随机屏蔽氨基酸。
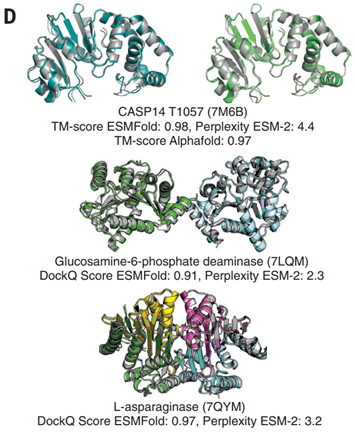
ESM-2预测效果(左)和 AlphaFold2(右)比较
1.2 应用:直接预测
这些模型可以按照其最初的训练目标直接用于预测每种氨基酸出现在序列中给定位置的概率。由于训练数据涵盖了已知功能性蛋白质序列的全部范围,因此这些模型可以有效地学习蛋白质进化的模式。无需对突变的影响进行实验测量,该模型就可以隐式地了解哪些突变会对蛋白质功能有害,因为根据在整个进化过程中经验观察到的突变,这些突变不太可能发生。因此,这些预测可以开箱即用,用于估计蛋白质编码突变的影响。
可以通过在给定位置处特异性地屏蔽野生型氨基酸并要求模型根据其余序列推断屏蔽位置来获得突变的可能性。如果根据语言模型,突变的可能性低于野生型氨基酸,则表明该突变可能有害。评估突变致病性的实验研究已根据模型可能性验证了这些估计。
将蛋白质序列建模为语言的一个好处是这些序列不需要事先对齐或注释;其他方法需要进化对齐的蛋白质序列来预测突变的影响。语言模型对蛋白质序列可能性的估计也可用于估计蛋白质序列是否可能形成功能结构,这使得蛋白质语言模型能够评估和设计新的序列。
1.3 应用:embedding 分析
除了输出之外,蛋白质语言模型还提供有用的蛋白质嵌入。具体而言,当蛋白质序列通过模型运行时,可以提取该蛋白质中每种氨基酸的模型内部表示(嵌入)。然后可以单独使用每种氨基酸的嵌入,也可以将其组合成单个蛋白质表示。
例如,先前的研究发现,聚类蛋白质序列嵌入可以识别同源蛋白质。然后可以根据每种蛋白质中各个氨基酸嵌入之间的相似性将这些同源蛋白质构造成多序列比对(vcMSA)。

vcMSA–10.1101/gr.277675.123
1.4 应用:迁移学习
从这些模型中学习到的表示可用于解决更具体的任务。由于微调蛋白质语言模型的成本可能很高,因此许多应用程序使用来自模型的嵌入作为另一个在下游任务上训练的更小模型的输入。例如,这些嵌入已用于预测蛋白质稳定性、病毒抗原突变的免疫逃逸,以及使用少量标记数据预测错义变体的致病性。或者,有更新、更有效的微调技术,使研究人员能够使用更少的计算资源完全微调大型蛋白质语言模型(PEFT)。
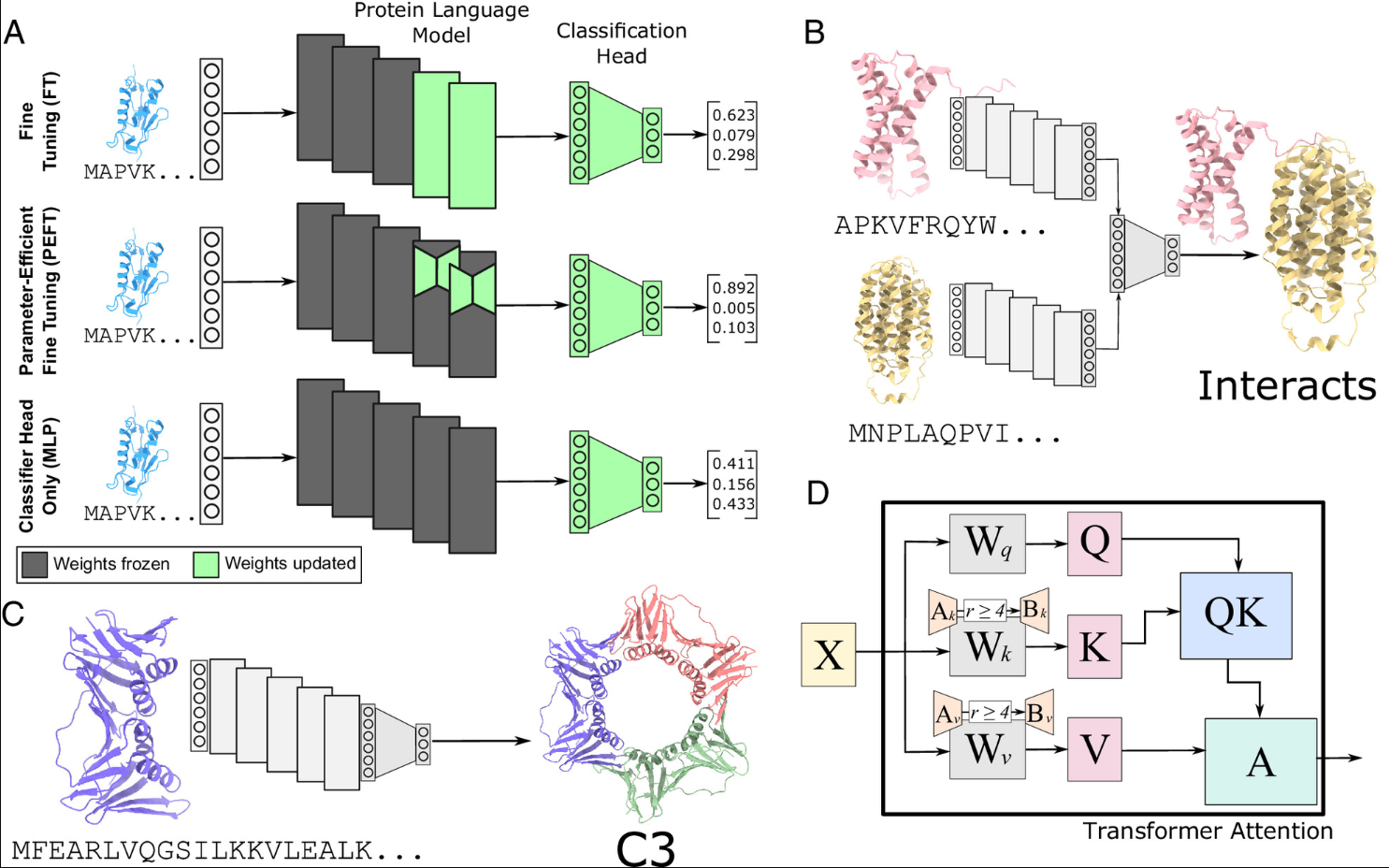
PEFT–https://www.pnas.org/doi/full/10.1073/pnas.2405840121
1.5 蛋白质结构模型
蛋白质结构预测的模型,如AlphaFold2和ESMFold,将结构信息与蛋白质序列相结合来训练模型,就像在蛋白质结构预测模型中所做的那样,可以改善各种下游任务的蛋白质表示。蛋白质结构预测模型与语言模型一样,已被证明可以通过直接预测、嵌入分析和迁移学习广泛适用于各种下游应用。


2.单细胞语言模型
2.1 单细胞语言模型例子:Geneformer
Geneformer 与许多其他生物语言模型一样,它具有经过训练的转换器架构,可为许多下游应用提供基因和细胞的表示。Geneformer 将每个细胞表示为细胞中表达的前 2,048 个基因的列表,并根据 RNA 表达水平排序。训练过程类似于前面描述的蛋白质语言模型,其中基因子集被屏蔽,并且模型经过训练以预测缺失基因。为了正确预测缺失基因的表达水平顺序,模型必须了解各种基因表达水平之间的相互作用,并隐式学习特定于细胞类型的模式和上下文。Geneformer 在涵盖 40 种组织类型的 3000 万个单细胞转录组上进行了训练,这有助于它学习不同的表达模式。
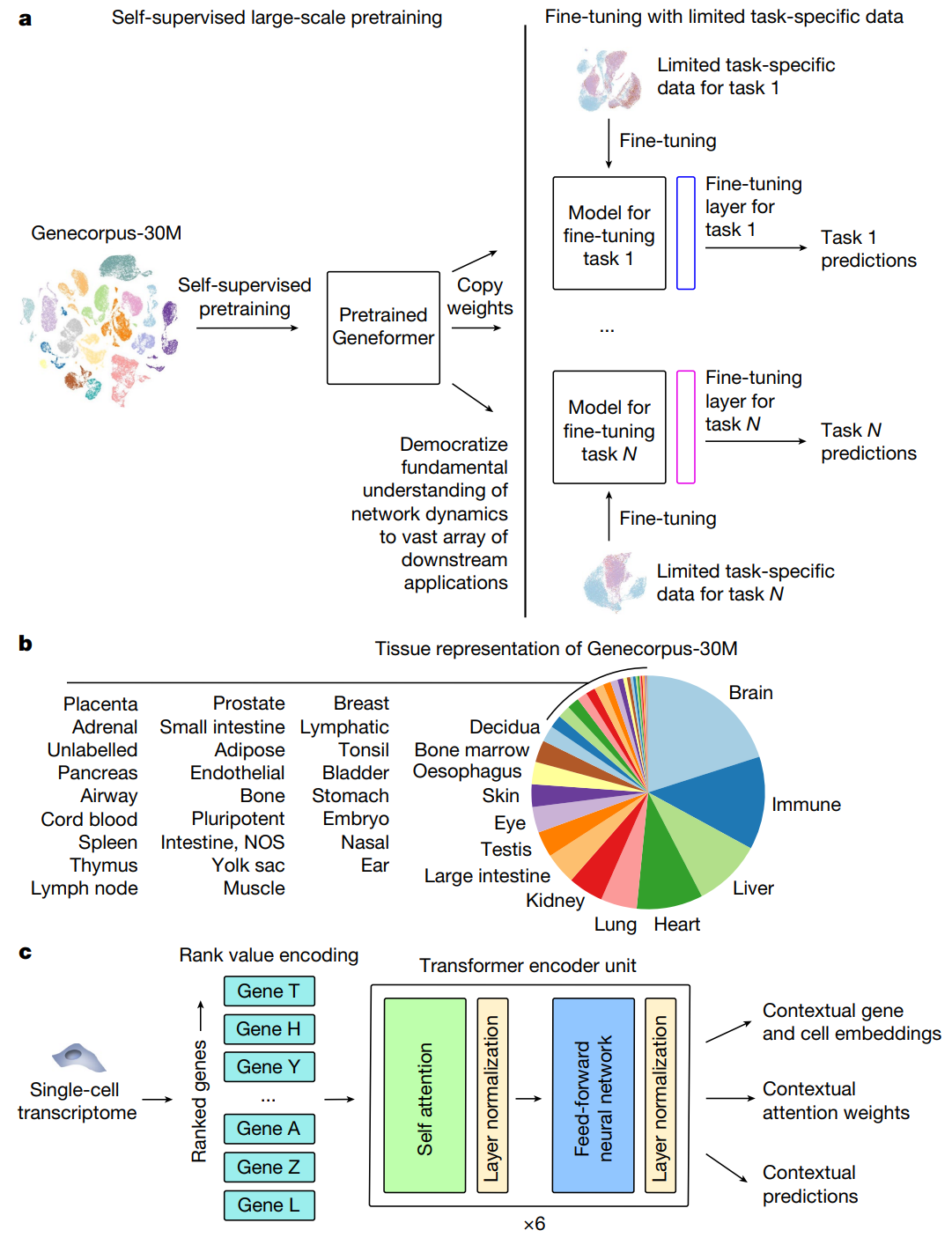
Geneformer–https://doi.org/10.1038/s41586-023-06139-9
Geneformer 专注于每个基因的相对表达水平,而其他单细胞语言模型使用了其他方式。例如,scGPT 是在定量表达值上进行预训练的,从而支持不同的下游应用。scGPT 还可以包括实验meta数据,例如模态、批次和扰动条件。
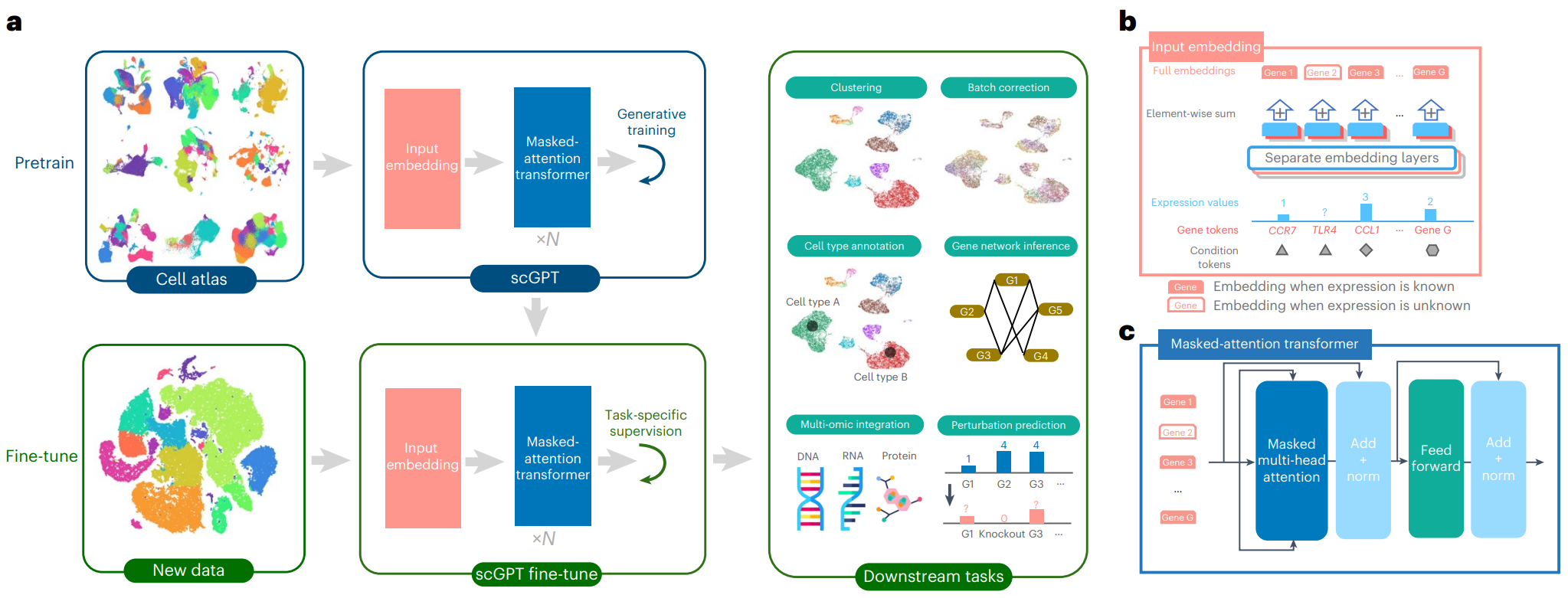
scGPT–https://doi.org/10.1038/s41592-024-02201-0
2.2 应用:直接预测
单细胞语言模型的直接输出使各种创造性的计算机实验成为可能。该模型可以通过获取按表达排序的单个细胞中的原始基因列表,修改基因顺序并量化这如何改变输出来估计遗传扰动对细胞的影响。
例如,Geneformer 通过人工将 POU5F1、SOX2、KLF4 和 MYC 添加到细胞基因排名的顶部来模拟成纤维细胞的重编程,从而通过计算将细胞转向诱导多能干细胞状态。同样,单细胞语言模型可以通过人工从细胞的排序列表中删除基因并检查对细胞嵌入的影响来预测细胞对基因移除的敏感性。
2.3 应用:embedding 分析
单细胞语言模型包含每个基因的嵌入,这些嵌入可以组合(例如,取平均值)以为每个细胞创建一个表示。这些细胞嵌入可用于聚类、可视化和细胞类型标记。由于训练数据的多样性和数量,这些模型可以隐式地减少批次效应,同时保持生物变异性,从而使它们能够从包含许多实验批次的数据集中识别细微的细胞亚型(Geneformer)。
2.4 应用:迁移学习
虽然有意义的集群(例如细胞类型)可以出现在这些嵌入中,但模型也可以进行微调以预测单个细胞的特性。例如,单细胞语言模型可以进行微调以整合跨实验条件的数据并预测细胞类型标签和细胞状态。它们甚至可以支持基因的多模态表示。例如,scGPT 可以进行微调以包括染色质可及性和蛋白质丰度以及基因表达水平,从而实现跨模态的数据集集成。
四、生物学的多模态语言模型
多模态模型可以跨多种数据模态(例如文本和图像)进行推理,从而使这些模型能够解决本质上涉及多种类型数据的任务。例如,病理语言图像预训练 (PLIP) 在 Twitter 数据上进行训练,以将病理图像与其标题相匹配,使用户能够获取给定图像的标题或查找给定文本描述的图像。
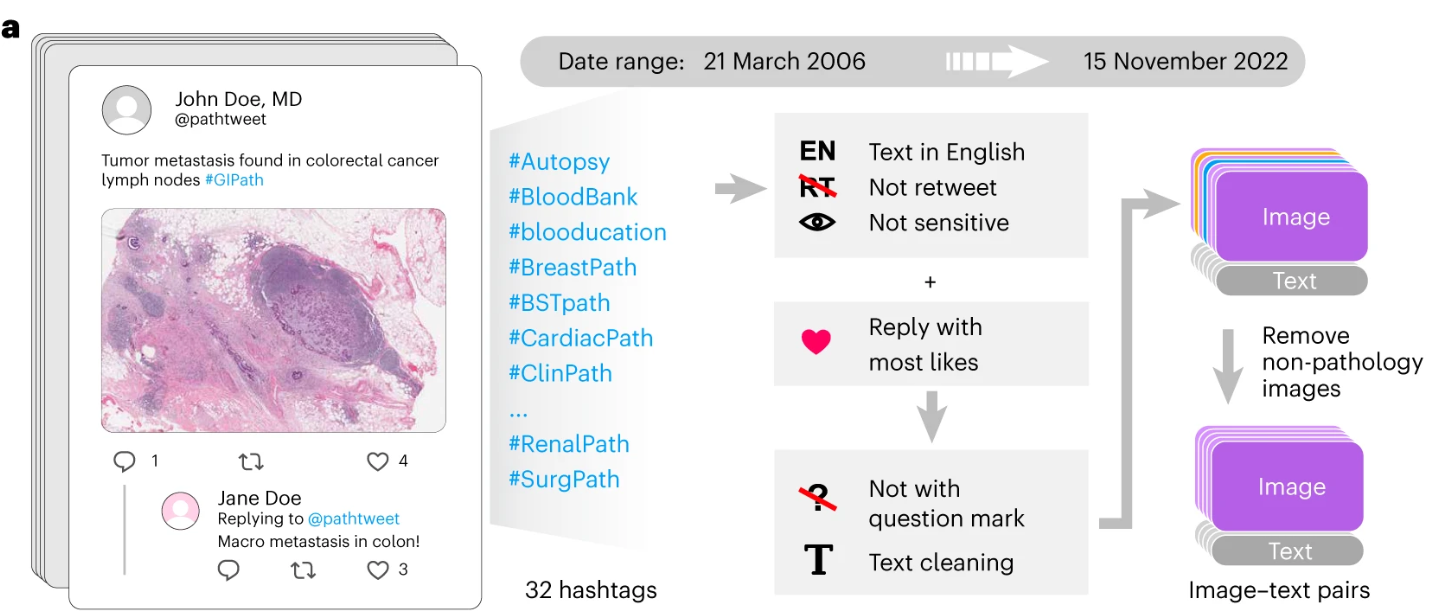
PLIP–https://doi.org/10.1038/s41591-023-02504-3
同样,Med-PaLM Multimodal 经过训练以根据生物医学图像回答问题,而 MolT5 经过训练以根据分子结构用自然语言描述分子,包括有关其潜在生物学功能的信息。
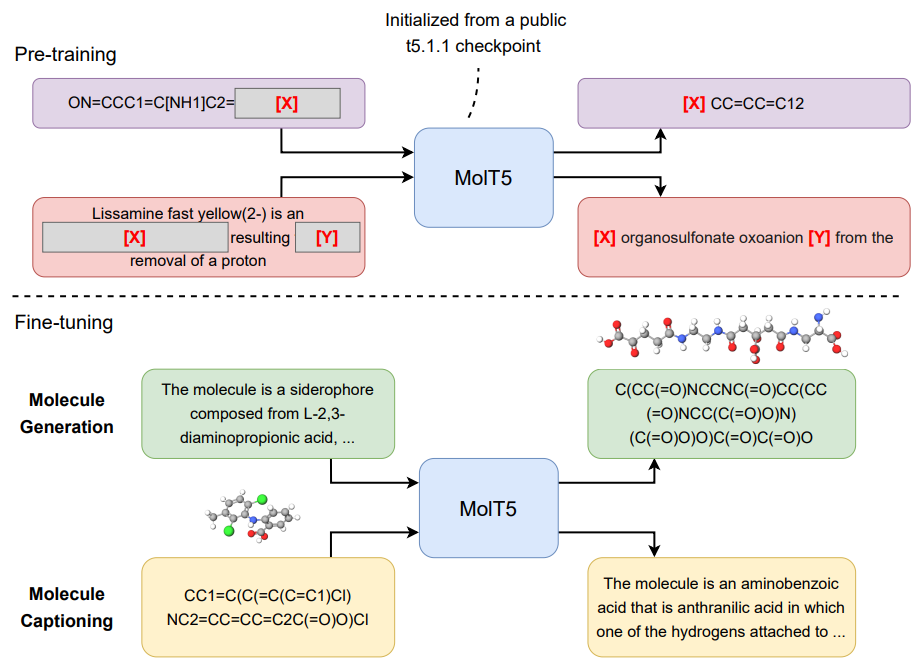
MolT5–https://arxiv.org/pdf/2204.11817
有了足够的具有多种模态的数据点示例,研究人员也可以为其他类型的生物数据训练多模态模型。通过将生物文本的固定语言模型嵌入与其他领域的数据相结合,自然语言模型也可以应用于多模态设置,而无需额外的训练。例如,GenePT 首先使用 ChatGPT 嵌入来自 NCBI 的基因文本描述,然后通过平均基于文本的基因嵌入(按单细胞表达加权)来创建单细胞嵌入。
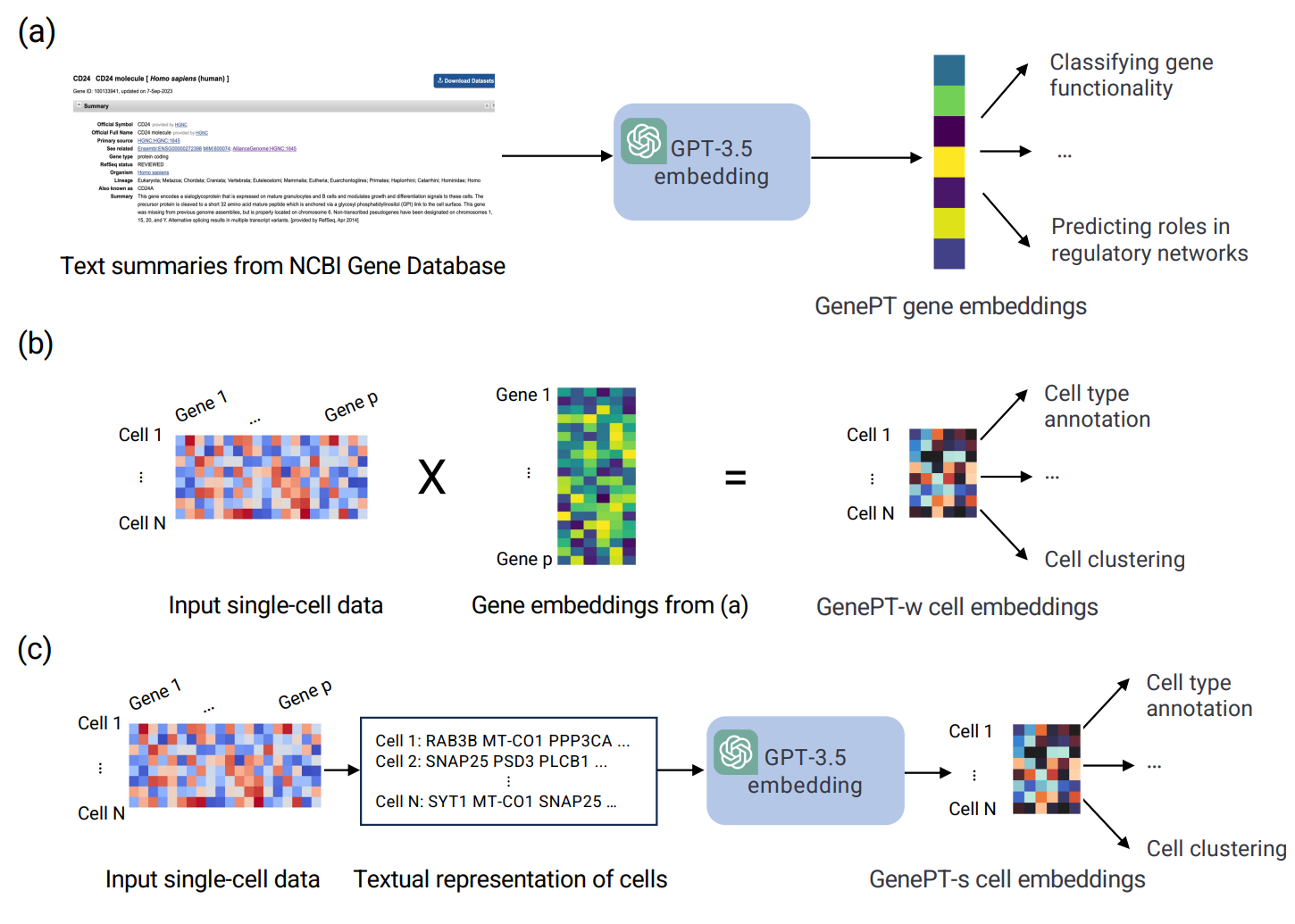
GENEPT–https://doi.org/10.1101/2023.10.16.562533
在某些应用中,这些来自自然语言模型的嵌入与来自生物语言模型(如 Geneformer)的嵌入相匹配或优于后者。类似的想法可以应用于生物学的其他领域;固定语言模型嵌入可以与来自替代模态的数据或模型合并,而无需额外的训练。
五、使用生物学语言模型实践
自然语言和生物语言模型在生物学研究中有众多应用。我们讨论了将这些模型应用于下游研究问题的三种方法:直接预测、嵌入分析和迁移学习。在这里,我们概述了决定哪些方法适合给定研究问题的过程。最佳方法取决于研究问题以及可用的数据和计算资源。
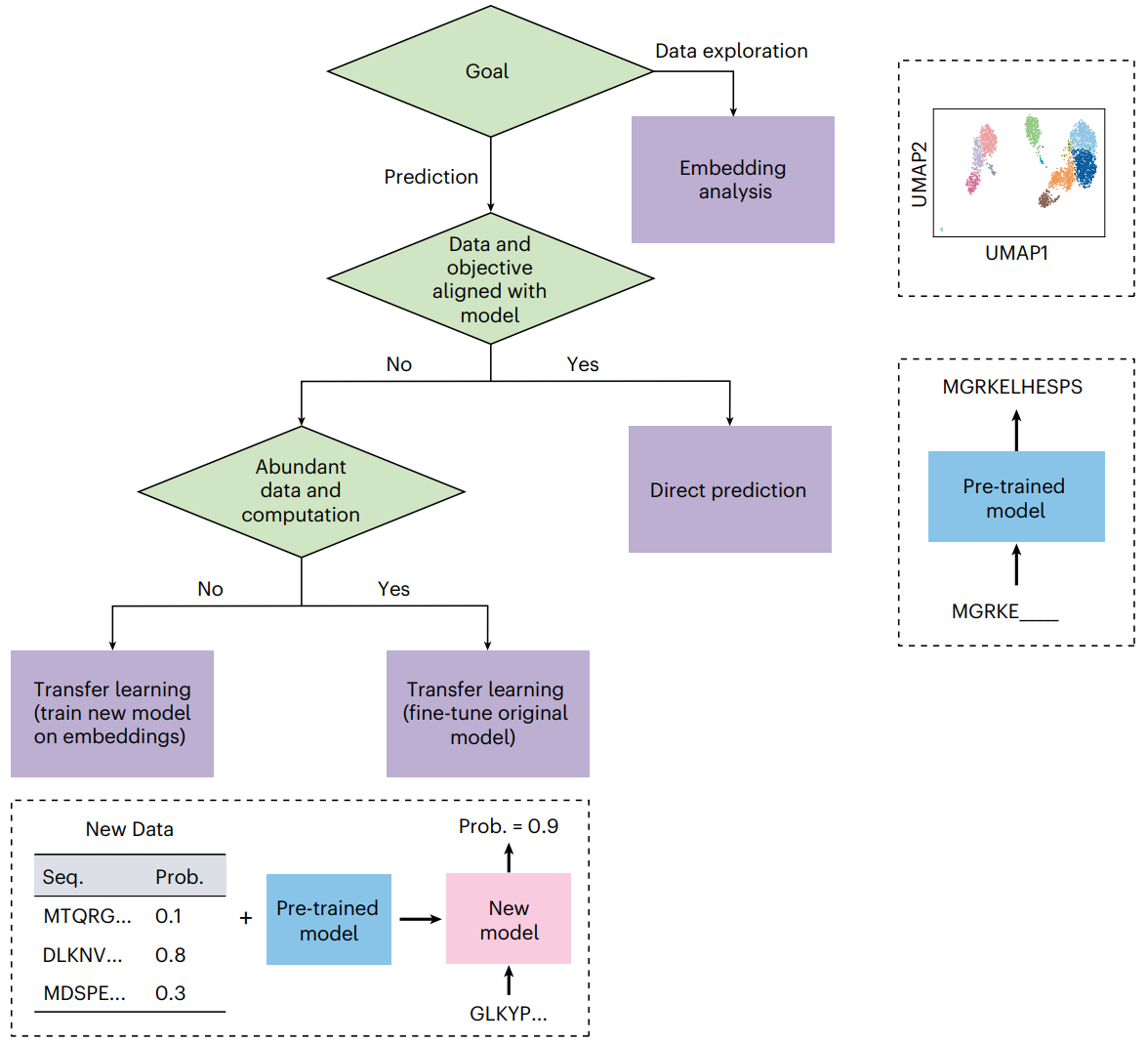
上图显示了一个简单的工作流程,总结了确定如何使用语言模型的主要决策点。
1.确定研究问题的目标
如果目的是数据探索,那么嵌入分析方法以及降维和聚类等技术可用于揭示数据中的结构。但是,如果目标是根据数据进行预测,那么直接预测和迁移学习方法往往更有用。
如果问题与模型的固有能力相匹配(基于其训练数据和目标),则直接预测方法是合适的,可能根据目标修改输入。如果项目目标与模型的能力有很大偏差,或者如果有更特定于感兴趣任务的数据,那么迁移学习可能会很有用。当有足够的数据和计算资源时,最好的方法可能是微调部分或全部语言模型。但是,如果数据或计算资源有限,另一种方法是使用语言模型计算新数据点的嵌入,并使用这些嵌入作为输入来训练单独的、通常较小的模型。
此外,一些模型仅作为 Web 界面或应用程序编程接口 (API) 提供,这可能会限制它们只能用于直接预测。具有开源代码和训练有素的模型参数的其他模型可用于嵌入分析或迁移学习。一些模型具有用户友好的 Web 界面,可以在其中进行预测。在其他情况下,可以从 Hugging Face 或 GitHub 下载代码和训练好的模型。一些模型附带 Jupyter 笔记本或 Google Colab 笔记本,演示如何将预训练模型用于各种应用。当不存在此类笔记本时,包含模型代码的 GitHub 存储库通常会提供文档或示例代码供参考。
2.局限性
它们可能无法学习控制训练数据的所有模式,以及训练数据的限制。
训练数据可能过时或嘈杂,并且它们可能存在某些类型的数据代表性不足的空白。
例如,自然语言模型仅包含训练数据中包含的生物学知识,因此它们不会意识到训练后发现的结果。蛋白质语言模型通常在标准氨基酸上进行训练,因此无法反映输入表示中任何翻译后修饰的重要性。单细胞表达数据可能很嘈杂,样本优先顺序可能会使数据量偏向特定组织类型和疾病状态,这两者都是影响模型性能的因素。
此外,针对特定生物应用量身定制的模型有时仍能胜过生物语言模型,特别是当先前知识可以为模型设计提供信息时。例如 AlphaMissense 和 LM-GVP 模型,已证明包含有关蛋白质结构的信息的方法优于使用在蛋白质序列上训练的语言模型的方法。
最后,评估适用于其他任务的语言模型的性能也需要谨慎。语言模型是在大量可能不公开共享的数据上进行训练的,因此确保语言模型的训练数据和下游任务的测试数据之间没有数据泄漏是比较困难的。

相关文章:
生物研究新范式!AI语言模型在生物研究中的应用
–https://doi.org/10.1038/s41592-024-02354-y 留意更多内容,欢迎关注微信公众号:组学之心 Language models for biological research: a primer 研究团队及研究单位 James Zou–Department of Biomedical Data Science, Stanford University, Stan…...

python语言day08 属性装饰器和property函数 异常关键字 约束
属性装饰器: 三个装饰器实现对私有化属性_creat_time的get,set,del方法; 三个装饰器下的方法名都一样,通过message.creat_time的不同操作实现调用get,set,del方法。 __inti__: 创建并…...

day01JS-数据类型-01
1. 浏览器内核 通常所谓的浏览器内核也就是浏览器所采用的渲染引擎,渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解释也有不同,因此同一网页在不同的内核的浏览器里的渲染(显示)…...

MATLAB 手动实现一种高度覆盖值提取建筑物点云的方法(74)
专栏往期文章,包含本章 MATLAB 手动实现一种高度覆盖值提取建筑物点云的方法(74) 一、算法介绍二、算法实现1.代码2.效果总结一、算法介绍 手动实现一种基于高度覆盖值的建筑物点云提取方法,适用于高大的城市建筑物,比只利用高度提取建筑物的方法更加稳定和具有价值,主要…...

git的下载与安装(Windows)
Git是一个开源的分布式版本控制系统(Distributed Version Control System,简称DVCS),它以其高效、灵活和强大的功能,在现代软件开发中扮演着至关重要的角色。 git官网:Git (git-scm.com) 1.进入git官网 2…...

腾讯云AI代码助手 —— 编程新体验,智能编码新纪元
阅读导航 引言一、开发环境介绍1. 支持的编程语言2. 支持的集成开发环境(IDE) 二、腾讯云AI代码助手使用实例1. 开发环境配置2. 代码补全功能使用💻自动生成单句代码💻自动生成整个代码块 3. 技术对话3. 规范/修复错误代码4. 智能…...

使用 ESP32 和 TFT 屏幕显示实时天气信息 —— 基于 OpenWeatherMap API
实时监测环境数据是一个非常常见的应用场景,例如气象站、智能家居等。这篇博客将带你使用 ESP32 微控制器和一个 TFT 屏幕,实时显示当前城市的天气信息。通过 OpenWeatherMap API,我们能够获取诸如温度、天气情况以及经纬度等详细的天气数据&…...

高阶数据结构——B树
1. 常见的搜索结构 以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景。如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上࿰…...

Vue2中watch与Vue3中watch对比和踩坑
上一节说到了 computed计算属性对比 ,虽然计算属性在大多数情况下更合适,但有时也需要一个自定义的侦听器。这就是为什么 Vue 通过 watch 选项提供了一个更通用的方法,来响应数据的变化。当需要在数据变化时执行异步或开销较大的操作时&#…...

在Java程序中执行Linux命令
在Java中执行Linux命令通常涉及到使用Java的运行时类 (java.lang.Runtime) 或者 ProcessBuilder 类来启动一个外部进程 1. 使用 Runtime.exec() Runtime.exec() 方法可以用来执行一个外部程序。它返回一个 Process 对象,可以通过这个对象与外部程序交互࿰…...

微信小程序在不同移动设备上的差异导致原因
在写小程序的时候用了rpx自适应单位,但是还是出现了在不同机型上布局不统一的问题,在此记录一下在首页做一个输入框,在测试的时候,这个输入框在不同的机型上到处跑,后来排查了很久都不知道为什么会这样 解决办法是后 …...

快速体验fastllm安装部署并支持AMD ROCm推理加速
序言 fastllm是纯c实现,无第三方依赖的高性能大模型推理库。 本文以国产海光DCU为例,在AMD ROCm平台下编译部署fastllm以实现LLMs模型推理加速。 测试平台:曙光超算互联网平台SCNet GPU/DCU:异构加速卡AI 显存64GB PCIE&#…...

报错:java: javacTask: 源发行版 8 需要目标发行版 1.8
程序报错: Executing pre-compile tasks... Loading Ant configuration... Running Ant tasks... Running before tasks Checking sources Copying resources... [gulimail-coupon] Copying resources... [gulimail-common] Parsing java… [gulimail-common] java…...

【数据结构篇】~单链表(附源码)
【数据结构篇】~链表 链表前言链表的实现1.头文件2.源文件 链表前言 链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。 1、链式机构在逻辑上是连续的,在物理结构上不一定连续 2、结点一般是从…...
)
旋转图像(LeetCode)
题目 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 解题 def rotate(matrix):n len(matrix)# 矩阵转置for i in range(n):for…...

入门 - vue中v-model的实现原理和完整用法详解
v-model介绍 v-model是vue的双向绑定的指令,能将页面上控件输入的值同步更新到相关绑定的data属性,也会在更新data绑定属性时候,更新页面上输入控件的值。在view层,model层相互需要数据交互,即可使用v-model。 双向绑…...

【区块链+金融服务】港融区域股权服务平台 | FISCO BCOS应用案例
中国证监会在 2020 年启动了区块链建设试点工作,提出建设基于区块链的场外市场登记系统和交易报告库,利 用区块链去中心化、不易篡改、安全稳定等技术特点,构建区域性股权市场数字化信任机制,为区域性股权市场 提供基础支撑设施。…...

Nginx反向代理和前后端分离项目打包部署
Nginx反向代理 Nginx的定位:主要用于做反向代理,一般都是用它来做前端页面的服务器,动态资源代理到后端服务器。这样做的好处是可以避免跨域请求带来的不便。 使用Nginx主要是对Nginx中的nginx.conf文件进行配置: 虚拟主机配置…...

Spring 中ApplicationContext
ApplicationContext 是 Spring 框架中最重要的接口之一,用于提供 Spring IoC 容器的功能。它是一个比 BeanFactory 更高级的容器,负责管理 Spring bean 的生命周期,同时提供对各种企业服务的集成,例如事件传播、国际化、弱引用等。…...

python之时间 datetime、date、time、timedelta、dateutil
在 Python 中,处理日期和时间的常用库是 datetime。此外,还有一些第三方库如 pytz 和 dateutil 可以帮助处理时区和日期解析。 1. 使用 datetime 模块 导入模块 from datetime import datetime, date, time, timedelta获取当前日期和时间 now datet…...

知识管理工具选型指南:从Confluence、语雀到Notion、Sward的深度场景适配
1. 知识管理工具的核心价值与选型逻辑 第一次搭建团队知识库时,我犯了个典型错误——直接选了当时最火的工具。结果三个月后,技术团队抱怨Markdown支持太弱,产品团队嫌弃界面太复杂,最终这个价值十几万的系统成了摆设。这个教训让…...
)
从Gridworld到吃豆人:用Python拆解强化学习三大核心算法(值迭代、策略调参、Q学习)
从Gridworld到吃豆人:Python实战强化学习三大核心算法 1. 强化学习基础与马尔可夫决策过程 想象一下,你正在训练一只小狗完成障碍赛跑。每次它正确跳过障碍,你会给予零食奖励;如果撞到障碍,则没有任何奖励。经过多次尝…...

5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南
5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

Windows 11/10扩展属性冲突:输入法与UAC的隐藏关联
1. Windows扩展属性冲突的典型表现 最近在帮同事调试一个自动化脚本时,遇到了一个奇怪的问题。每次运行那个bat文件,系统就会弹出"扩展属性不一致"的错误提示。这个bat脚本本身很简单,就是用来启动一个内部工具的可执行文件。但无…...

tao-8k在AI应用开发中的价值:为LangChain+LlamaIndex提供高质量向量底座
tao-8k在AI应用开发中的价值:为LangChainLlamaIndex提供高质量向量底座 1. 为什么需要高质量的文本嵌入模型 在构建AI应用时,我们经常需要将文本转换为计算机能够理解的数值表示,这就是文本嵌入(embedding)的核心任务…...

告别目标跟丢!手把手教你用BoT-SORT和OpenCV GMC搞定复杂场景下的多目标跟踪
告别目标跟丢!手把手教你用BoT-SORT和OpenCV GMC搞定复杂场景下的多目标跟踪 在智能监控和自动驾驶等实际应用中,多目标跟踪(MOT)技术常常面临动态相机和目标快速移动带来的挑战。传统算法在目标遮挡、镜头晃动等复杂场景下容易出…...

保姆级教程:深求·墨鉴Podman部署全流程,小白也能轻松搞定
保姆级教程:深求墨鉴Podman部署全流程,小白也能轻松搞定 1. 为什么选择Podman部署深求墨鉴? 传统Docker部署方式虽然常见,但对于深求墨鉴这样的轻量级OCR工具来说,Podman提供了更优雅的解决方案。Podman是一款无需守…...

在Windows 11上用VirtualBox搞定WRF-Hydro 5.2.0:一个水文模型小白的Ubuntu 22.04虚拟机避坑实录
在Windows 11上用VirtualBox搞定WRF-Hydro 5.2.0:一个水文模型小白的Ubuntu 22.04虚拟机避坑实录 第一次接触WRF-Hydro时,我盯着满屏的命令行代码和复杂的依赖关系,感觉像在破解某种外星密码。作为一名水文专业的研究生,我的Linux…...

5分钟部署清华TurboDiffusion,视频生成加速100倍,小白也能玩转AI视频
5分钟部署清华TurboDiffusion,视频生成加速100倍,小白也能玩转AI视频 1. TurboDiffusion技术背景与核心价值 1.1 技术发展历程 TurboDiffusion是由清华大学等机构联合推出的视频生成加速框架。该框架解决了传统扩散模型在视频生成过程中存在的计算效率…...

Fish Speech-1.5语音合成企业标准:WAV采样率/比特率/声道数配置指南
Fish Speech-1.5语音合成企业标准:WAV采样率/比特率/声道数配置指南 如何在企业级应用中配置Fish Speech-1.5的音频输出参数,获得最佳语音合成效果 语音合成技术在企业应用中越来越重要,从智能客服到有声内容制作,都需要高质量的语…...