YOLO知识点总结:
分类:
即是将图像结构化为某一类别的信息,用事先确定好的类别(category)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
检测:
分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息(classification + localization)。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
先来回顾下分类原理,这是一个常见的CNN组成图,输入一张图片,经过其中的卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果。

目标定位的简单实现:
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
回归位置:
增加一个全连接层,即为FC1、FC2
1)FC1:作为类别的输出
2)FC2:作为整个物体位置数值的输出


分割:
分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
目标检测的基本思路:
同时解决定位(localization) + 识别(Recognition)。
多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。详细结构如下图所示:

什么是位置(位置的定义):
目标检测的位置信息一般有2种格式(以图片左上角为原点(0,0)):
极坐标表示:(xmin,ymin,xmax,ymax)
xmin,ymin:x,y坐标的最小值
xmax,ymax:x,y坐标的最大值
中心点坐标:(x_center,y_center,w,h)
x_center,y_center:目标检测框的中心点坐标
w,h:目标检测框的宽,高
传统目标检测(缺点、弊端)
1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
2)手工设计的特征对于多样性的变化没有很好的鲁棒性

传统的目标检测框架,主要包括三个步骤:
(1)利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
(2)提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
(3)利用分类器进行识别,比如常用的SVM模型。
目前目标检测领域的深度学习方法主要分为两类:两阶段(Two Stages)的目标检测算法;一阶段(One Stage)目标检测算法。
两阶段(Two Stages):首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。
阶段(One Stage ):不需要产生候选框,直接将目标框定位的问题转化为回归(Regression)问题处理(Process)。
基于候选区域(Region Proposal)的,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN;
基于端到端(End-to-End),无需候选区域(Region Proposal)的,如YOLO、SSD。
对于上述两种方式,基于候选区域(Region Proposal)的方法在检测准确率和定位精度上占优,基于端到端(End-to-End)的算法速度占优。相对于R-CNN系列的“看两眼”(候选框提取和分类),YOLO只需要“看一眼”。总之,目前来说,基于候选区域(Region Proposal)的方法依然占据上风,但端到端的方法速度上优势明显,至于后续的发展让我们拭目以待。
目标检测的候选框是如何产生的?
如今深度学习发展如日中天,RCNN/SPP-Net/Fast-RCNN等文章都会谈及候选边界框(Bounding boxes)的生成与筛选策略。那么候选框是如何产生的?又是如何进行筛选的呢?其实物体候选框获取当前主要使用图像分割与区域生长技术。区域生长(合并)主要由于检测图像中存在的物体具有局部区域相似性(颜色、纹理等)。目标识别与图像分割技术的发展进一步推动有效提取图像中信息。
根据目标候选区域的提取方式不同,传统目标检测算法可以分为基于滑动窗口的目标检测算法和基于选择性搜索的目标检测算法。滑窗法(Sliding Window)作为一种经典的物体检测方法,个人认为不同大小的窗口在图像上进行滑动时候,进行卷积运算后的结果与已经训练好的分类器判别存在物体的概率。选择性搜索(Selective Search)是主要运用图像分割技术来进行物体检测。
(1) 滑动窗口(Sliding Window)
采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。

通过滑窗法流程图分析具体步骤:首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体。对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选。最终,经过NMS筛选后获得检测到的物体。
滑窗法简单易于理解,但是不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。所以,对于实时性要求较高的分类器,不推荐使用滑窗法。
(2) 选择性搜索(Selective Search)
滑窗法类似穷举进行图像子区域搜索,但是一般情况下图像中大部分子区域是没有物体的。学者们自然而然想到只对图像中最有可能包含物体的区域进行搜索以此来提高计算效率。选择搜索方法是当下最为熟知的图像bouding boxes提取算法,其目标检测的流程图如下图所示。

选择搜索算法的主要观点:图像中物体可能存在的区域应该是有某些相似性或者连续性区域的。因此,选择搜索基于上面这一想法采用子区域合并的方法进行提取候选边界框(bounding boxes)。首先,对输入图像进行分割算法产生许多小的子区域(大约2000个子区域)。其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。每次迭代过程中对这些合并的子区域做外切矩形(bounding boxes),这些子区域外切矩形就是通常所说的候选框。
选择搜索优点:
(a)计算效率优于滑窗法。
(b)由于采用子区域合并策略,所以可以包含各种大小的疑似物体框。
(c)合并区域相似的指标多样性,提高了检测物体的概率。
(3) 什么是NMS—非极大值抑制(Non-Maximun Suppression)?
学习R-CNN算法必然要了解一个重要的概念——非极大值抑制(NMS)。比如,我们会从一张图片中找出N多个可能包含物体的Bounding-box,然后为每个矩形框计算其所属类别的概率。

正如上面的图片所示,假如我们想定位一个车辆,最后算法就找出了一堆的方框,每个方框都对应一个属于汽车类别的概率。我们需要判别哪些矩形框是没用的。采用的方法是非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
如此循环往复知道没有剩余的矩形框,然后找到所有被保留下来的矩形框,就是我们认为最可能包含汽车的矩形框。
YOLOv8 目标检测中的 Anchor-Free 机制
锚框(Anchor)
Anchor 指有固定中心位置和大小(通常由宽度和高度决定)的框。Anchor 思想最早在论文 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
(2015.06,Microsoft) 中提出。在此之前,目标检测算法通常使用滑动窗口或 Selective Search 等方法来生成候选区域。而 Faster R-CNN 中的 RPN(Region Proposal Network)网络通过引入 Anchor 机制,解决了目标检测算法中目标大小和长宽比的变化问题。
Faster R-CNN 中的 Anchor 设计如下:

注意锚框和 GT 框的区别:
- 锚框是机器学习过程中模型预测(或者预设)的,而 GT 框是指人工标记的图片框。
- 锚框是基于特征图,而 GT 框基于图片的像素(当然两者可以非常粗略地对应上,但表示的含义是不一样的)。
通常在训练过程中,通过和 GT 框的比对,把锚框定义为正样本和负样本(详见后面的标签分配章节)。
Anchor-Based 和 Anchor-Free
Two-stage(两阶段)指目标检测过程分成两个主要步骤:
- 生成候选区域(Region Proposals),来确定图像中可能包含对象的区域。
- 对第 1 阶段生成的候选区域进行分类和边界框细化。
Anchor-based(基于锚框)指在目标检测中使用一组预定义的、不同尺寸和比例的候选区域(anchors),用于引导检测模型学习到真实的对象边界框。
Anchor-Free 并不是没有使用锚点,而是指无先验锚框,直接通过预测具体的点得到锚框。Anchor-Free 不需要手动设计 anchor(长宽比、尺度大小、anchor的数量),从而避免了针对不同数据集进行繁琐的设计。
正样本和负样本
正样本(positive sample)和负样本(negative sample)是用于训练分类模型的两种基本类型的数据点。
在目标检测中,正样本是指锚框中恰当地包含我们希望检测的目标对象的样本。例如,在行人检测任务中,如果锚框中确实有行人,且框大小合适,那么这个框就是一个正样本。负样本指锚框中可能没有目标检测对象,或者框大小不合适。
在目标检测任务中,负样本的引入也是至关重要的。在真实世界的图像中,目标往往只占图像的一小部分区域,而大部分区域都是背景(即负样本)。如果模型仅使用正样本来训练,它可能会过度拟合到这些有限的目标样本,而无法正确地区分目标和背景。通过引入负样本,模型能够学习到目标的边界,并理解哪些区域不包含目标。
通常,目标检测任务使用锚点(anchor boxes)而不是直接使用真实目标(ground truth boxes,人工标记的物体框选)作为正负样本,有几个重要原因:
- 正负样本平衡:直接使用真实目标作为目标值可能导致训练过程中的样本不平衡问题,因为背景区域通常远多于目标区域。通过使用锚点,可以更有效地分配正样本(匹配真实目标的锚点)和负样本(不匹配任何真实目标的锚点),从而帮助模型更好地学习。
- 泛化能力:如果直接使用真实目标作为目标值,模型可能过于依赖于训练数据中的具体实例,从而降低其泛化到新数据的能力。使用锚点可以帮助模型学习到更一般化的目标表示。
- 边界框回归:在训练过程中,模型需要学习如何调整预测的边界框以更好地匹配真实目标。如果直接使用真实目标作为目标值,模型将无法学习到如何进行这种调整。锚点提供了一个起点,模型可以学习从这个起点调整边界框以适应真实目标。
任务对齐(Task Alignment)
目标检测旨在从自然图像中定位和识别感兴趣的对象,它通常被表述为一个多任务学习问题,通过同时优化对象分类和定位来实现。分类任务旨在学习对象的关键区分性特征,而定位任务则致力于精确定位整个对象及其边界。由于分类和定位任务的学习机制存在差异,这两个任务所学到的特征的空间分布可能不同,当使用两个独立分支进行预测时,可能会导致一定程度的错位。
YOLOv8 目标检测的 Anchor 处理
训练阶段的主要处理逻辑如下:
- 在 Head 部分(参考 YOLOv8 架构图),会输出三个特征图(以 YOLOv8 L 为例,特征图大小分别为:80 x 80 x 256,40 x 40 x 512,1. 20 x 20 x 512)。
- 每个特征图上的每个点,会定义为 1 个锚框(anchor),模型的输出预测值中包括每个锚框的分类和定位信息。
- 标签分配算法:根据人工标记的 GT,将每个 anchor 对应为正、负样本。
- 依据损失函数,计算正、负样本的损失,反向传播更新网络参数。
尽管 YOLOv8 在检测(推理)阶段被归类为无锚点模型,因为它不依赖于预定义的锚框。
- 在训练阶段,它仍然使用了锚点的概念。这些“锚点”作为边界框的尺度和长宽比的初始估计或参考。在训练过程中,模型根据训练图像中对象的真实边界框来调整和优化这些估计。
- 在检测阶段,模型并不严格依赖预定义的锚框来提出候选对象位置,最终的对象检测是直接基于检测到的特征进行的,因此 YOLOv8 被归类为无锚点(anchor-free)模型。
YOLOv8 将输入图像分割成单元格网格,其中每个单元格负责预测位于其中的对象。对于每个单元格,YOLOv8 预测对象得分(objectness scores)、类别概率(class probabilities)和几何偏移量(geometrical offsets),以便估计对象的边界框。
预测框的设计及损失函数(DFL)
YOLOv8详解:损失函数、Anchor-Free、样本分配策略;以及与v5的对比_yolov8的损失函数为什么大于1-CSDN博客
参考链接:
目标检测从入门到精通—概述(一) - 我的明天不是梦 - 博客园 (cnblogs.com)
【目标检测】方法概述_如何判断检测到目标物的方法-CSDN博客
YOLOv8 目标检测中的 Anchor-Free 机制:图示 + 代码 (vectorexplore.com)
相关文章:
YOLO知识点总结:
分类: 即是将图像结构化为某一类别的信息,用事先确定好的类别(category)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集&…...

合宙LuatOS AIR700 IPV6 TCP 客户端向NodeRed发送数据
为了验证 AIR700 IPV6 ,特别新建向NodeRed Tcp发送的工程。 Air700发送TCP数据源码如下: --[[ IPv6客户端演示, 仅EC618系列支持, 例如Air780E/Air600E/Air780UG/Air700E ]]-- LuaTools需要PROJECT和VERSION这两个信息 PROJECT "IPV6_SendDate_N…...

git 如何生成sshkey公钥
打开git客户端 输入 ssh-keygen -t rsa -b 4096 -C "xxxxxxexample.com" 然后根据提示按enter 或者y 直到出现下图所示 打开 c盘的路径下的文件,/c/Users/18159/.ssh/id_rsa.pub 将id_rsa.pub中的公钥贴到git 网站上的SSH keys即可...

python从入门到精通:函数
目录 1、函数介绍 2、函数的定义 3、函数的传入参数 4、函数的返回值 5、函数说明文档 6、函数的嵌套调用 7、变量的作用域 1、函数介绍 函数是组织好的,可重复使用的,用来实现特定功能的代码段。 name "zhangsan"; length len(nam…...

【Android性能篇】如何分析 dumpsys meminfo 信息
一、dumpsys meminfo是什么 dumpsys meminfo 是一个用于分析Android设备内存使用情况的强大命令。 二、dumpsys meminfo的关键信息 要分析其输出信息,我们需要注意以下几个关键点: Total PSS by OOM adjustment:这个值表示每个进程的总比…...

c++进阶——继承的定义,复杂的菱形继承及菱形虚拟继承
目录 前言: 1.继承的概念及定义 1.1继承的概念 1.2 继承定义 1.2.2继承关系和访问限定符 1.2.3继承基类成员访问方式的变化 2.基类和派生类对象赋值转换 3.继承中的作用域 4.派生类的默认成员函数 5.继承与友元 6. 继承与静态成员 7.复杂的菱形继承及菱…...

计算机网络:DNS、子网掩码、网关
参考: https://blog.csdn.net/weixin_55255438/article/details/123074896 https://zhuanlan.zhihu.com/p/65226634 在计算机网络中,DNS(Domain Name System,域名系统)、子网掩码(Subnet Mask)…...

程序员如何学习开源项目
程序员如何学习开源项目 豆包MarsCode使用豆包MarsCode学习开源项目步骤导入git上开源的项目 豆包MarsCode https://www.marscode.cn/home 使用豆包MarsCode学习开源项目 步骤 https://www.marscode.cn/dashboard 导入git上开源的项目 找到项目的README.md文件,使…...
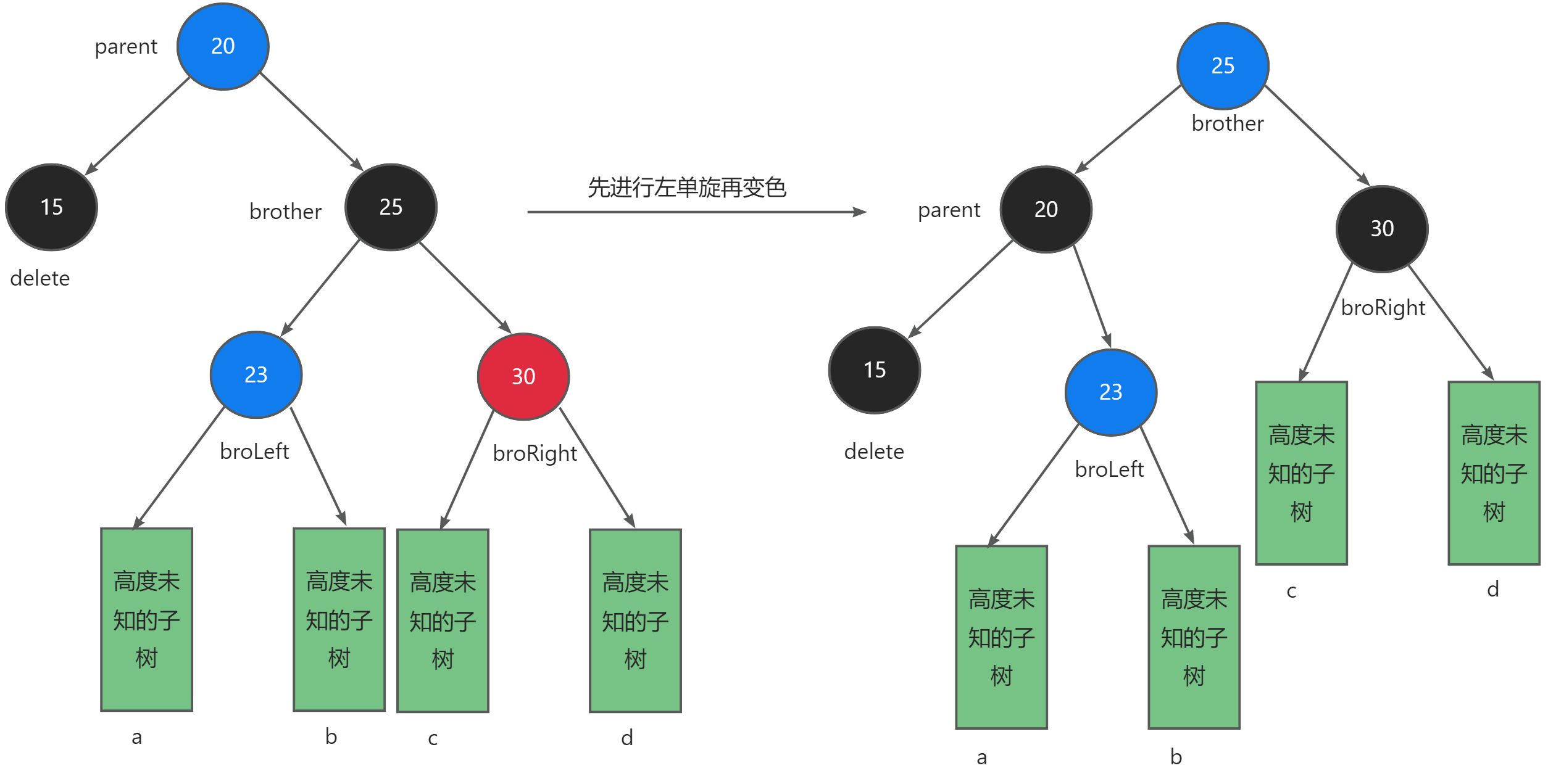
探索数据结构:红黑树的分析与实现
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:数据结构与算法 贝蒂的主页:Betty’s blog 1. 红黑树的介绍 1.1. 红黑树的引入 我们前面学习了AVL树,…...

【设计模式】装饰器模式和适配模式
装饰器模式 装饰器模式能够很好的对已有功能进行拓展,这样不会更改原有的代码,对其他的业务产生影响,这方便我们在较少的改动下对软件功能进行拓展。 类似于 router 的前置守卫和后置守卫。 Function.prototype.before function (beforeFn)…...
Visual Studio VS 插件之 ReSharper
集成在VS2022上的ReSharper暂无找到汉化方式,如果有大神可以汉化,请指导下。 首先ReSharper 是IDE 下的插件 主要是基于C# 语句优化的这么一个插件。 使用ReSharper可以使开发效率大大提高,但是也是比较吃电脑的配置。所以说如果配置低的小…...

【二分查找】--- 进阶题目赏析
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: 算法Journey 本篇博客我们继续来了解一些有关二分查找算法的进阶题目。 🏠 寻找峰值 📌 题目内容 162. 寻找峰值 - 力扣&#…...

CSS 对齐
CSS 对齐 在网页设计中,CSS(层叠样式表)对齐是一种基本而重要的技术,它决定了网页元素的位置和布局。CSS 提供了多种对齐方法,可以精确控制元素的水平、垂直对齐,以及相对于其父元素或整个页面的位置。本文…...

暑假算法刷题日记 Day 10
目录 重点整理 054、 拼数 题目描述 输入格式 输出格式 输入输出样例 核心思路 代码 055、 求第k小的数 题目描述 输入格式 输出格式 输入输出样例 核心思路 代码 总结 这几天我们主要刷了洛谷上排序算法对应的一些题目,相对来说比较简单 一共是13道…...

【Midjourney】AI作画提示词工程:精细化技巧与高效实践指南
文章目录 💯AI作画提示词基础结构1 图片链接1.1 上传流程 2 文字描述3 后置参数 💯AI作画提示词的文字描述结构1 主体主体细节描述2 环境背景2.1 环境2.2 光线2.3 色彩2.4 氛围 3 视角4 景别构图5 艺术风格6 图片制作方法7 作品质量万能词 💯…...

C语言——文件
文件操作 概念 文件是指存储在外存储器上(一般代指磁盘,也可以是U盘,移动硬盘等)的数据的集合。 文件操作体现在哪几个方面 1.文件内容的读取 2.文件内容的写入 数据的读取和写入可被视为针对文件进行输入和输出的操作…...

视频孪生技术在智慧水利(水务)场景中的典型应用展示
一、智慧水利建设规划 根据水利部编制《“十四五”智慧水利建设规划》,建设数字孪生流域、“2N”水利智能业务应用体系、安全可控水利网络安全防护体系、优化健全水利网信保障体系,建成七大江河数字孪生流域,推进水利工程智能化改造…...

使用kubekey快速搭建k8s集群
项目仓库地址 https://github.com/kubesphere/kubekey/ 支持的Kubernetes Versions https://github.com/kubesphere/kubekey/blob/master/docs/kubernetes-versions.md 安装 选择自己想要下载的版本 https://github.com/kubesphere/kubekey/releases 复制下载链接并下载 示…...

C++——入门基础(上)
目录 一、C参考文档 二、C在工作领域的应用 三、C学习书籍 四、C的第一个程序 五、命名空间 (1)namespace的定义 (2)命名空间的使用 六、C的输入和输出 七、缺省函数 八、函数重载 九、写在最后 一、C参考文档 (1)虽…...

Spring事务失效
类内部访问导致事务不生效原因: 注解Transaction的底层实现是Spring AOP技术,而Spring AOP技术使用的是动态代理。spring事务失效的原因就是动态代理失效的原因: 对于static方法和非public方法,注解Transactional是失效的,因为不…...

Llama-3.2V-11B-cot入门必看:Streamlit会话状态管理保障多用户隔离
Llama-3.2V-11B-cot入门必看:Streamlit会话状态管理保障多用户隔离 1. 项目概述 Llama-3.2V-11B-cot是基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具,专为双卡4090环境深度优化。该工具通过Streamlit框架构建了宽屏友好的交互界面…...

从Flatten到Hierarchy:数字IC后端工程师必须掌握的时序收敛技巧
从Flatten到Hierarchy:数字IC后端工程师必须掌握的时序收敛技巧 在22nm以下工艺节点,单芯片晶体管数量已突破10亿大关。面对如此庞大的设计规模,传统扁平化(Flatten)流程如同试图用绣花针建造摩天大楼——理论上可行&a…...

TPCH dbgen数据生成工具在Linux环境下的配置与实战
1. 环境准备:从零搭建TPCH测试环境 第一次接触TPCH dbgen工具时,我花了整整两天时间才搞明白所有依赖关系。这个工具虽然功能强大,但官方文档确实不够友好。下面把我踩过的坑都总结出来,让你能快速上手。 系统要求方面,…...

OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战
OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战 【免费下载链接】openclaw-channel-dingtalk Dingtalk channel plugin for OpenClaw 项目地址: https://gitcode.com/gh_mirrors/op/openclaw-channel-dingtalk OpenClaw-DingTalk是一款专为O…...

学习神经网络
一、神经网络概述:人工智能的核心基石(一)神经网络的定义与起源神经网络,全称为人工神经网络(Artificial Neural Network,ANN),是一种模仿生物神经网络(动物大脑神经元网…...

Univer全栈框架实战指南:3步构建企业级AI原生表格应用
Univer全栈框架实战指南:3步构建企业级AI原生表格应用 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is d…...

项目管理和技术管理的区别
在单位从事管理岗快2年了,负责单位内的研发项目管理和技术管理工作。感觉这是两个不同的管理赛道。其中项目管理侧重进度、资源、风险、责任人、排期等要素推进和汇报。技术管理则侧重研发环节的技术深度、技术方向、技术领先性、技术栈,以及项目产出的质…...

Super IO:Blender文件操作效率革命,实现300%工作流提速
Super IO:Blender文件操作效率革命,实现300%工作流提速 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 在3D设计领域,文件导入导出的繁琐操作常常成…...

5个步骤搞定苹果设备Windows连接:从无法识别到无缝协作
5个步骤搞定苹果设备Windows连接:从无法识别到无缝协作 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mi…...

大数据领域 OLAP 技术的发展趋势展望
大数据领域OLAP技术的发展趋势展望 关键词:OLAP、大数据分析、实时决策、云原生、AI融合 摘要:本文从超市老板的"销售密码"故事出发,用通俗易懂的语言拆解OLAP(在线分析处理)技术的核心逻辑,结合当前大数据技术演进趋势,深入探讨OLAP在实时化、云原生化、AI融…...