RuntimeError: CUDA out of memory
今天在训练模型的时候突然报了显存不够的问题,然后分析了一下,找到了解决的办法,这里记录一下,方便以后查阅。
注:以下的解决方案是在模型测试而不是模型训练时出现这个报错的!
RuntimeError: CUDA out of memory
完整的报错信息:
Traceback (most recent call last):File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 420, in <module>main()File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 414, in maintrain_with_cross_validate(training_epochs, kfolds, train_indices, eval_indices, X_train, Y_train, model, losser, optimizer)File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 77, in train_with_cross_validateval_probs = model(inputs)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 235, in forwardx = self.camlp_mixer(x) # (batch_size, F, C, L)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forwardinput = module(input)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 202, in forwardx = self.time_mixing_unit(x)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 186, in forwardx = self.mixing_unit(x)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 147, in forwardx = self.activate(x)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_implreturn forward_call(*input, **kwargs)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/activation.py", line 772, in forwardreturn F.leaky_relu(input, self.negative_slope, self.inplace)File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/functional.py", line 1633, in leaky_reluresult = torch._C._nn.leaky_relu(input, negative_slope)
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
因为自己写的程序训练完成一轮会有输出,所以这些信息是在模型预测过程中发生的。
关键的报错信息:
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
大体意思就是显存不够了。
通过下面的代码查看程序运行过程中显卡的状态:
nvidia-smi -l 1
模型加载完成后,此时的显卡状态:

模型训练过程中显卡的状态:

模型训练完成,开始模型预测阶段,并且是数据输入模型之后,紧接着出现如下的显卡状态,并且这个状态持续时间很短,在显示过程中,只有一次输出结果是这样的:

紧接着程序报错,显卡内存被释放,显卡的任务栏中,运行的程序也没有了:

然后,就感觉很奇怪,觉得是梯度的问题,因为在训练的时候很正常,然后模型预测就出现问题了,然后模型训练需要梯度信息,模型预测不需要梯度信息,就尝试着解决梯度的问题:
就是在模型训练代码的前面加入下面这句话:
with torch.no_grad():
更改后的代码如下所示:
with torch.no_grad():# validationmodel.eval()inputs = x_eval.to(device)val_probs = model(inputs)val_acc = (val_probs.argmax(dim=1) == y_eval.to(device)).float().mean()# print(f"Eval : Epoch : {iter} - kfold : {kfold+1} - acc: {val_acc:.4f}\n")epoch_val_acc += val_acc
更改之后模型预测阶段显卡的状态如下所示:
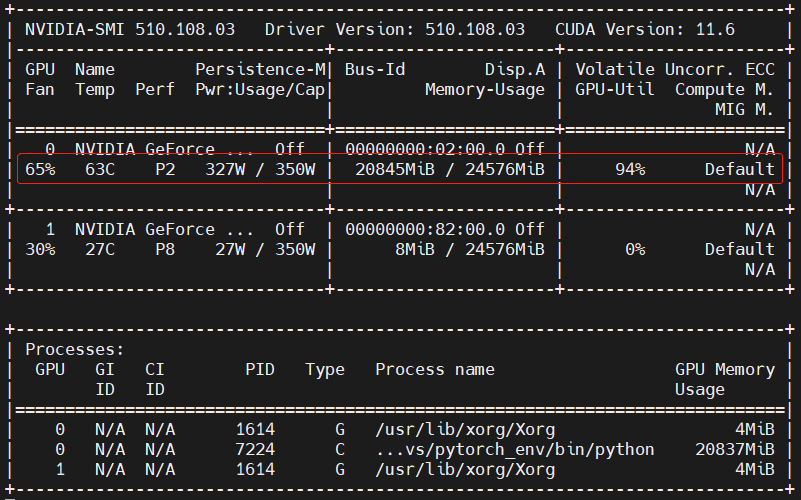
然后开始新一轮的训练过程,显卡的显存占用情况也没有再发生变化。
这样就不再报错了!!!
相关文章:
RuntimeError: CUDA out of memory
今天在训练模型的时候突然报了显存不够的问题,然后分析了一下,找到了解决的办法,这里记录一下,方便以后查阅。 注:以下的解决方案是在模型测试而不是模型训练时出现这个报错的! RuntimeError: CUDA out of…...

Kubernetes1.25中Redis集群部署实例
1、概述我们知道在 Kubernetes 容器编排平台中, 我们可以非常方便的进行应用的扩容缩, 同时也能非常方便的进行业务的迭代,本章主要讲解在Kubernetes1.25搭建Redis单实例和Redis集群主从同步的环境流程步骤, 如果是高频访问重要的线上业务我们最好是部署在物理机器上…...
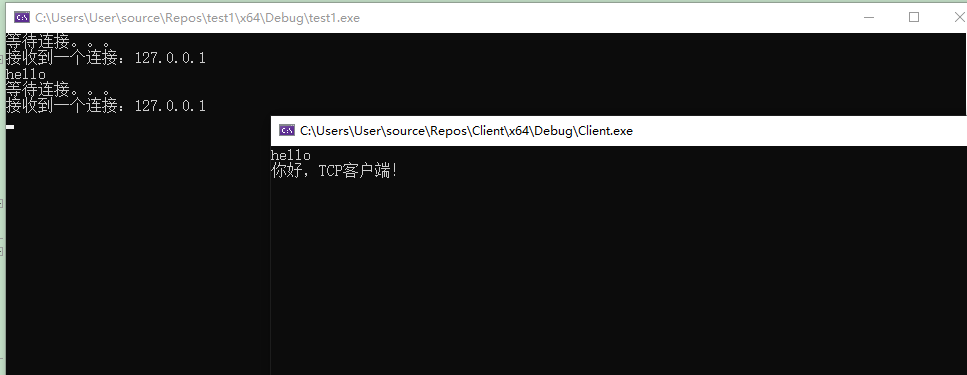
C++11实现计算机网络中的TCP/IP连接(Windows端)
目录引言1、TCP2、IP2.1 IP路由器3、TCP/IP4、TCP/IP协议C11实现参考文献引言 TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol)。[1] 在TCP/IP协议簇中主要包含以下内容: TCP (传输控制协议) - 应用程序…...

Spring框架自定义实现IOC基础功能/IDEA如何手动实现IOC功能
继续整理记录这段时间来的收获,详细代码可在我的Gitee仓库Java设计模式克隆下载学习使用! 7.4 自定义Spring IOC 创建新模块,结构如图![[Pasted image 20230210173222.png]] 7.4.1 定义bean相关POJO类 7.4.1.1 定义propertyValue类 /** …...
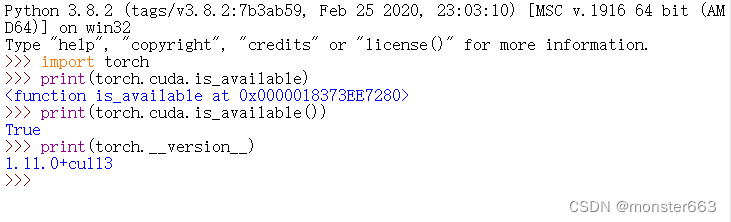
pip离线安装windows版torch
文章目录前言conda创建虚拟环境安装torchtorch官网在线安装离线手动安装测试是否安装成功后记前言 学习的时候遇到几个机器学习相关的项目,由于不同的项目之间用到的依赖库不太一样,于是想利用conda为不同的项目创建不同的环境方便管理和运行࿰…...

Redis核心知识点
Redis核心知识点Redis核心知识点大全五种数据类型redis整合SpringBoot序列化问题渐进式扫描慢查询缓存相关问题数据库和缓存谁先更新缓存穿透缓存雪崩缓存击穿实际应用超卖问题分布式锁全局唯一ID充当消息队列Feed流附近商户签到HyperLogLog实现UV统计持久化RDBAOF持久化小结事…...

14. 最长公共前缀
14. 最长公共前缀 一、题目描述: 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: …...
SignalR注册成Windows后台服务,并实现web前端断线重连
注意下文里面的 SignalR 不是 Core 版本,而是 Framework 下的 本文使用的方式是把 SignalR 写在控制台项目里,再用 Topshelf 注册成 Windows 服务 这样做有两点好处 传统 Window 服务项目调试时需要“附加到进程”,开发体验比较差…...
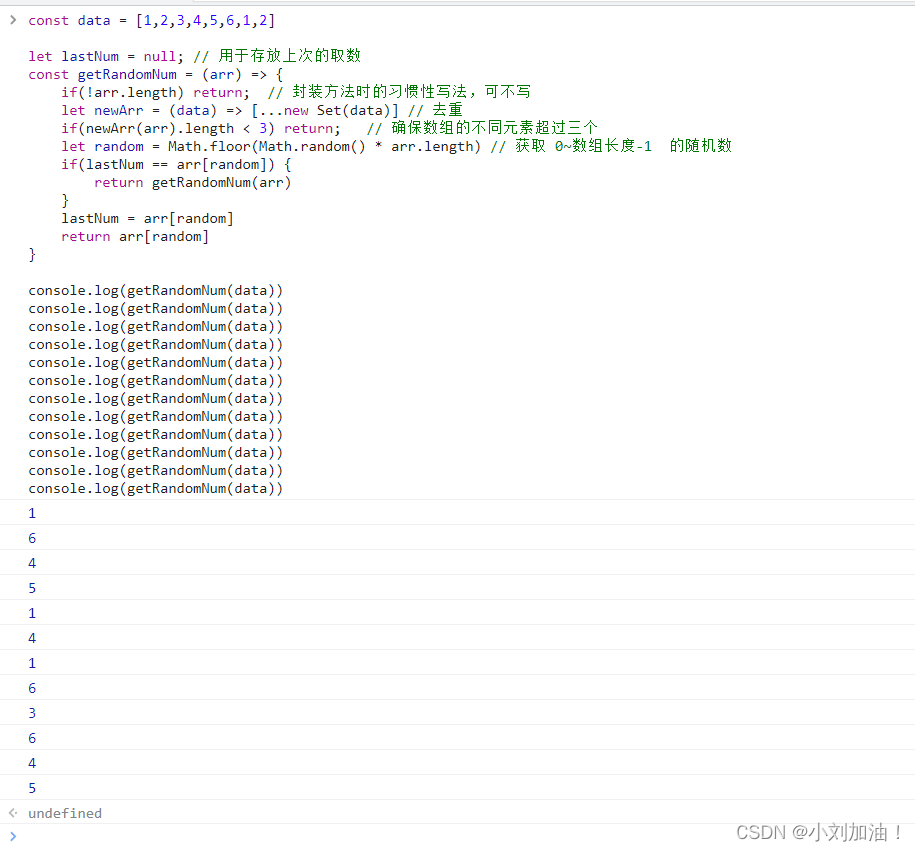
【前端笔试题二】从一个指定数组中,每次随机取一个数,且不能与上次取数相同,即避免相邻取数重复
前言 本篇文章记录下我在笔试过程中遇到的真实题目,供大家参考。 1、题目 系统给定一个数组,需要我们编写一个函数,该函数每次调用,随机从该数组中获取一个数,且不能与上一次的取数相同。 2、思路解析 数组已经有了…...

专栏关注学习
Node学习专栏(全网最细的教程) 【spring系列】 SpringCloud 前端框架Vue java学习过程 RocketMQ Spring Tomcat websocket 从头开始学Redisson 从头开始学Oracle 跟着大宇学Shiro 吃透Shiro源代码 Git基础与进阶 Java并发编程 Spring系列 手写…...
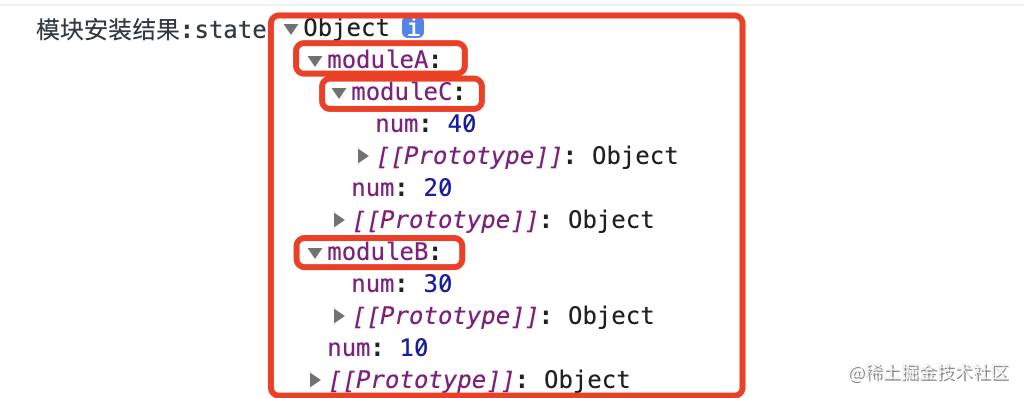
【手写 Vuex 源码】第八篇 - Vuex 的 State 状态安装
一,前言 上一篇,主要介绍了 Vuex 模块安装的实现,针对 action、mutation、getter 的收集与处理,主要涉及以下几个点: Vuex 模块安装的逻辑;Vuex 代码优化;Vuex 模块安装的实现;Vue…...
Mac下拉式终端的安装与配置 (iTerm2)
Mac下拉式终端的安装与配置 使用效果如图所示 安装前置软件 iTerm2 很可惜,如此炫酷的功能在原终端中并不能实现,我们需要借助iTerm2这个软件来实现。 官网链接:iTerm2 - macOS Terminal Replacement 我们点击download下载即可 配置 当我…...

使用 Spring 框架结合阿里云 OSS 实现文件上传的代码示例
使用 Spring 框架结合阿里云 OSS 实现文件上传的代码示例POM文件配置文件上传工具类控制层使用yaml配置文件(第二种用法,看公司要求)注入 OSSClient 对象及工具类(第二种用法,看公司要求)使用 Vue 前端代码…...
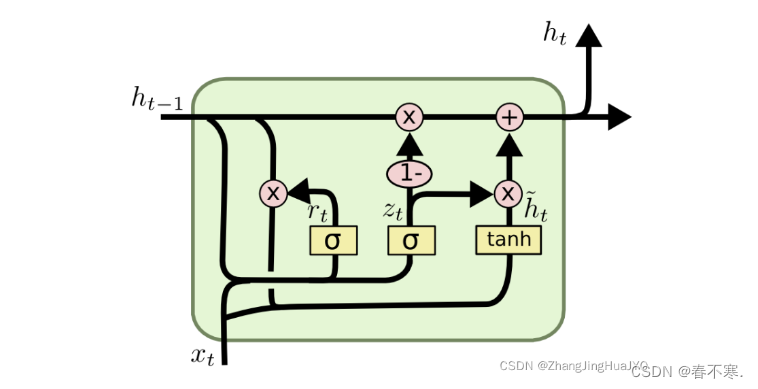
神经网络基础知识
神经网络基础知识 文章目录神经网络基础知识一、人工神经网络1.激活函数sigmod函数Tanh函数Leaky Relu函数分析2.过拟合和欠拟合二、学习与感知机1.损失函数与代价函数2. 线性回归和逻辑回归3. 监督学习与无监督学习三、优化1.梯度下降法2.随机梯度下降法(SGD)3. 批量梯度下降法…...
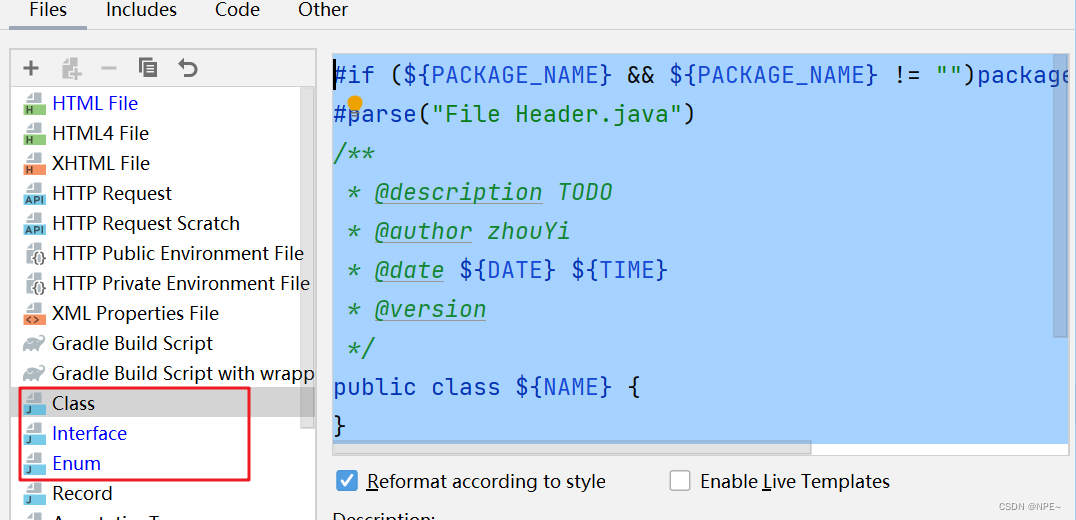
SpringBoot开发规范部分通用模板+idea配置【项目通用-1】
SpringBoot开发规范通用模板 1 分页插件使用 通过MybatisPlus配置分页插件拦截器 Configuration MapperScan("com.xuecheng.content.mapper") //拦截的mapper层 public class MybatisPlusConfig {//定义分页的拦截器Beanpublic MybatisPlusInterceptor getMybatisPl…...

程序的机器级表示part3——算术和逻辑操作
目录 1.加载有效地址 2. 整数运算指令 2.1 INC 和 DEC 2.2 NEG 2.3 ADD、SUB 和 IMUL 3. 布尔指令 3.1 AND 3.2 OR 3.3 XOR 3.4 NOT 4. 移位操作 4.1 算术左移和逻辑左移 4.2 算术右移和逻辑右移 5. 特殊的算术操作 1.加载有效地址 指令效果描述leaq S, DD…...

基于YOLOV5的钢材缺陷检测
数据和源码见文末 1.任务概述 数据集使用的是东北大学收集的一个钢材缺陷检测数据集,需要检测出钢材表面的6种划痕。同时,数据集格式是VOC格式,需要进行转化,上传的源码中的数据集是经过转换格式的版本。 2.数据与标签配置方法 在数据集目录下,train文件夹下有训练集数据…...
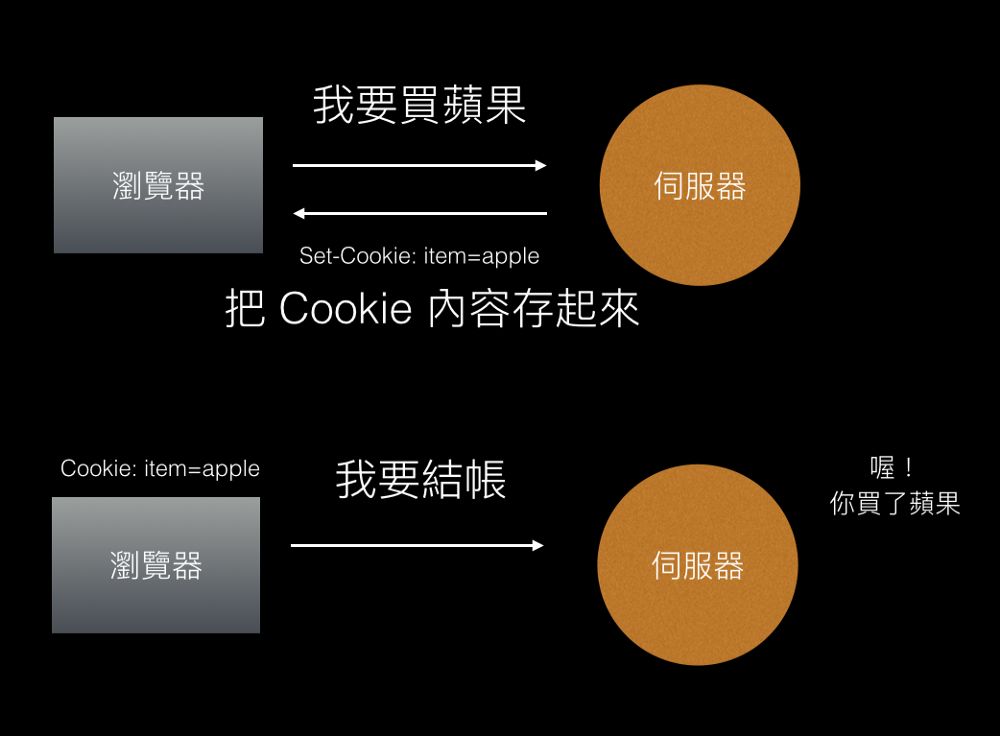
Session与Cookie的区别(三)
中场休息 让我们先从比喻回到网络世界里,HTTP 是无状态的,所以每一个 Request 都是不相关的,就像是对小明来说每一位客人都是新的客人一样,他根本不知道谁是谁。 既然你没办法把他们关联,就代表状态这件事情也不存在。…...
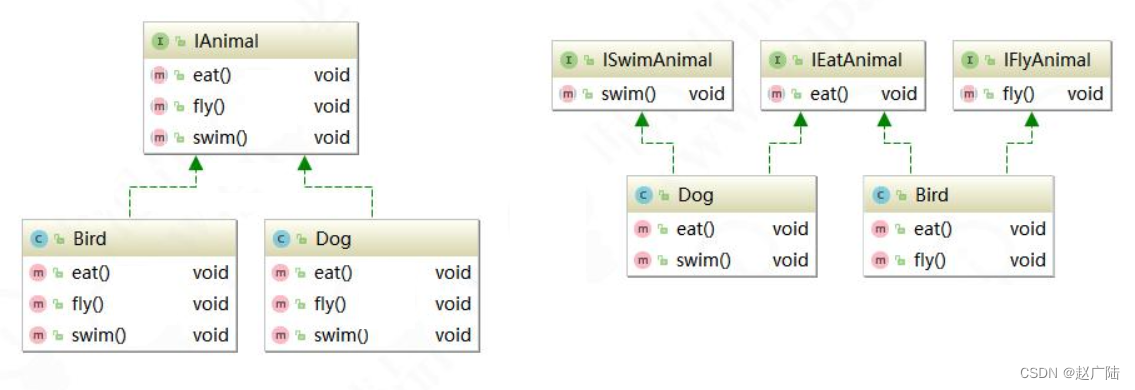
七大设计原则之接口隔离原则应用
目录1 接口隔离原则介绍2 接口隔离原则应用1 接口隔离原则介绍 接口隔离原则(Interface Segregation Principle, ISP)是指用多个专门的接口,而不使用单一的总接口,客户端不应该依赖它不需要的接口。这个原则指导我们在设计接口时…...
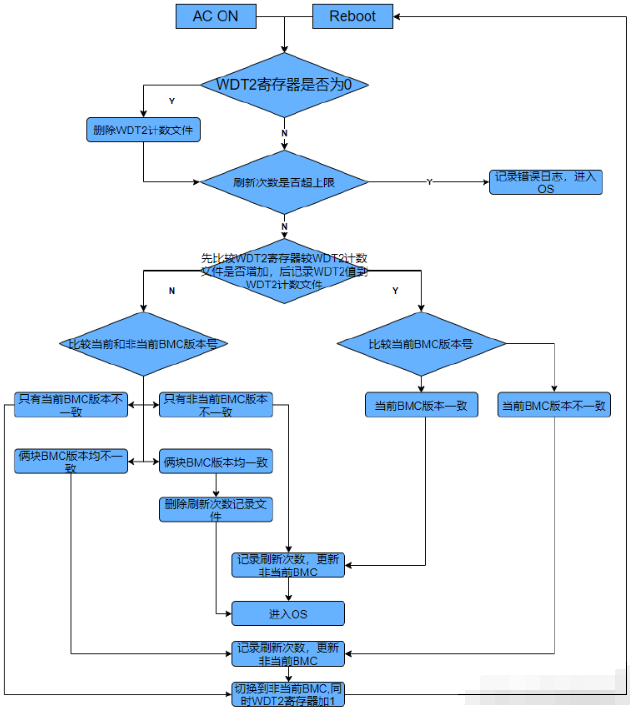
【Shell1】shell语法,ssh/build/scp/upgrade,环境变量,自动升级bmc
文章目录1.shell语法:shell是用C语言编写的程序,是用户使用Linux的桥梁,硬件>内核(os)>shell>文件系统1.1 变量:readonly定义只读变量,unset删除变量1.2 函数:shell脚本传递的参数中包含空格&…...

【实战篇】Nginx反向代理负载均衡:从轮询到权重的策略演进
1. 反向代理与负载均衡基础认知 第一次接触Nginx的反向代理功能时,我盯着配置文件里的proxy_pass参数看了半天。这行看似简单的配置,背后其实隐藏着现代分布式系统的核心设计思想。想象一下这样的场景:当你在电商网站点击"立即购买"…...

实战部署Funannotate基因组注释工具:3种高效配置方案指南
实战部署Funannotate基因组注释工具:3种高效配置方案指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate是一款专业的真核生物基因组注释工具,特别针…...

Claude API代理网关:开源项目newaiproxy/claude-api架构解析与部署实战
1. 项目概述:一个连接Claude的API代理网关如果你正在尝试将Claude的对话能力集成到自己的应用里,或者想绕过官方Web界面的一些限制,那么你很可能已经听说过或者正在寻找一个可靠的API代理方案。newaiproxy/claude-api这个项目,本质…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

Keep架构深度解析:企业级AIOps告警管理平台的设计与实践
Keep架构深度解析:企业级AIOps告警管理平台的设计与实践 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep Keep作为开源AIOps告警管理平台,采用现代化的微服…...

APK Installer终极指南:如何在Windows上快速安装安卓应用?
APK Installer终极指南:如何在Windows上快速安装安卓应用? 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装安卓应用而烦恼吗…...

python网上书店系统vue
目录技术栈选择前端模块划分后端API设计关键实现细节开发流程示例代码片段项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 前端采用Vue 3(Composition API) TypeScript Vite构建工具&#…...

Cursor编辑器集成OpenAPI Agent:让AI编程助手具备真实API调用能力
1. 项目概述:当你的代码编辑器学会“思考”最近在开发者社区里,一个名为neordinary/cursor-openapi-agent的项目引起了我的注意。乍一看,这名字有点长,但拆解一下就能明白它的野心:cursor是那款风头正劲的、集成了AI能…...

CTF出题人视角:我是如何设计ctfshow F5杯那些“脑洞大开”的MISC题的
CTF出题人视角:如何设计令人拍案叫绝的MISC赛题 在CTF竞赛中,MISC(杂项)题目往往是最能体现创意与思维碰撞的领域。作为F5杯的核心出题人之一,我想分享几个设计"脑洞题"的底层逻辑——这些题目后来被参赛选手…...

德尔·考德威尔:从微波校准到计量标准,塑造现代精密测量的隐形基石
1. 一位计量学巨匠的遗产:从德尔考德威尔看精密测量的基石在电子工程与测试测量这个庞大而精密的领域里,我们常常关注的是最新的示波器带宽、最前沿的矢量网络分析技术,或是某个芯片的测试方案。然而,支撑起整个现代工业测量体系可…...