多线程(4)——单例模式、阻塞队列、线程池、定时器
1. 多线程案例
1.1 单例模式
单例模式能保证某个类在程序中只存在唯一一份实例,不会创建出多个实例(这一点在很多场景上都需要,比如 JDBC 中的 DataSource 实例就只需要一个
tip:设计模式就是编写代码过程中的 “软性约束”,不是强制的;框架就是编写代码过程中的 “硬性约束”,针对一些特定的场景问题,基本的代码逻辑是固定的
单例模式具体的实现方式有很多,最常见的是 “饿汉” 和 “懒汉” 两种
1.1.2 饿汉模式
//创建一个单例的类,饿汉方式实现
//饿 的意思是 “迫切”
//在类被加载的时候,就会创建出这个单例的实例
class Singleton {private static Singleton instance = new Singleton();public static Singleton getInstance() {return instance;}//单例模式的最关键部分private Singleton() { }
}
public class Demo24 {public static void main(String[] args) {Singleton s1 = Singleton.getInstance();Singleton s2 = Singleton.getInstance();System.out.println(s1 == s2);}
}

其中的构造方法用 private 修饰,意味着在类的外面就无法调用构造方法,也就无法创建实例了
只要不在其他代码中 new 这个类,每次使用都通过 getInstance 来获取实例,这个类就是单例的了
单例主要解决的问题就是防止别人不小心 new 了对象
tip:
单例模式只能避免失误,不能应对 “故意攻击”,如:使用 反射 或 序列化反序列化 能打破上述单例模式
单例模式的前提是 “一个进程中”,如果有多个 Java 进程,自然是每个进程中都可以有一个实例了
1.1.3 懒汉模式
//懒汉模式实现的单例模式
class SingletonLazy {//此处先把这个实例的引用设为 null,不着急创建实例private static SingletonLazy instance = null;public static SingletonLazy getInstance() {if (instance == null) {instance = new SingletonLazy();}return instance;}private SingletonLazy() { }
}
public class Demo25 {public static void main(String[] args) {SingletonLazy s1 = SingletonLazy.getInstance();SingletonLazy s2 = SingletonLazy.getInstance();System.out.println(s1 == s2);}
}
计算机中谈到的 “懒” 是褒义词,意思是,效率会更高,懒汉模式推迟了创建实例的时机,第一次使用的时候才会创建实例
上述代码中,当首次调用 getInstance,由于此时引用为 null,就会进入 if 分支创建实例,后续再重复调用 getInstance 就不会创建实例了,直接返回
1.1.4 饿汉模式和懒汉模式的线程安全问题
观察饿汉模式的代码,发现其只有读操作,不涉及到修改操作,所以没有线程安全问题
而懒汉模式中有 if 判定和其中的修改操作,这种代码模式是典型的线程不安全代码,因为判定和修改之间可能涉及到线程的切换,如下图:

上述例子中就创建了两个实例,虽然第二次创建覆盖了第一次的值,使得第一次创建的实例没有引用指向,很快就会被垃圾回收机制给消除掉,但是仍然认为上述代码是存在 bug 的
tip:在实际场景中,构造方法内部可能会执行很多逻辑,假设现有 100G 数据,加载到内存中需要 10 分钟,若是上述代码构造实例来管理加载数据到内存中,耗时就会翻倍成 20 分钟
1.1.5 通过加锁来解决懒汉模式中的线程安全问题
问题一:

上面加锁之后确实解决了线程安全问题,但是当已经 new 完对象后,if 分支就再也进不去了,后续的代码就应该是单纯的读操作,此时 getInstance 不加锁也是线程安全的
问题二:
但是当前代码的写法只要调用 getInstance 都会触发加锁操作,虽然没有线程安全问题了,但是会因为加锁产生阻塞,影响到性能
通过加一个条件判断,改进该问题:

tip:
创建的局部变量,处于 JVM 内存的 “栈” 区域中;new 出来的对象,处于 JVM 内存的 “堆” 区域中
对于整个 JVM 进程来说,堆是只有一份,线程之间公用的;栈则是每个线程有自己独立的(这是 Java 语法的限制,t1 无法访问 t2 栈上的变量,C++、系统原生 API 中不存在这样的限制,任何一个变量都是可以给其他线程用的)
正是因为变量的共享是常态,所以就容易触发多个线程修改同一个变量,从而引起线程安全问题
问题三:

该代码还可能会因为指令重排序,引起线程安全问题(指令重排序也是一种编译器的优化方式)
编译器可能会按照 1 2 3 的顺序来执行,也可能按照 1 3 2 的顺序来执行,对于单线程来说,先执行 2 和先执行 3 本质上是一样的,但是在多线程的环境下,按照 1 3 2 的顺序来执行可能会出现问题:

为解决该问题,引入关键字 volatile,编译器就发现 instance 是易失的,围绕这个变量的优化就会非常克制,不仅在读取变量的优化上克制,也会在修改变量的优化上克制,上述的 1 2 3 操作不会再成为 1 3 2 了

tip:Java 中的 voiatile 两个功能
1) 保证内存可见性
2) 禁止指令重排序(针对赋值操作)
1.2 阻塞队列
1.2.1 概念
阻塞队列是一种特殊的队列,也遵循 “先进先出” 原则,是一种线程安全的数据结构(标准库中原有的队列 Queue 和其子类默认都是线程不安全的),并且具有以下特性:
- 当队列满的时候,继续入队列就会阻塞,直到有其他线程从队列中取走元素
- 当队列空的时候,继续出队列就会阻塞,直到有其他线程往队列中插入元素
阻塞队列的一个典型应用场景就是 “生产者消费者模型”,是一种非常典型的开发模型
1.2.2 生产者消费者模型
生产者消费者模型就是通过一个容器来解决生产者和消费者的强耦合问题
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列中取
优点一:阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力(削峰填谷)
比如:在“双十一秒杀”的场景下,服务器同一时刻可能会收到大量的支付请求,如果直接处理这些支付请求,服务器可能扛不住(每个支付请求的处理都需要比较复杂的流程),这时就可以把这些请求放到一个阻塞队列中,然后再由消费者线程慢慢处理每个支付请求,有效进行“削峰”,防止服务器被突然到来的一波请求直接冲垮

如上图,A 中请求突然激增,若是没有阻塞队列,B 很可能就挂了;若有阻塞队列在,A 往队列中写入数据变快了,但是 B 仍然可以按照原有速度来消费数据
优点二:阻塞队列能使生产者和消费者之间解耦
比如:过年一家人一起包饺子,一般都是有明确分工,一人负责擀皮,其他人负责包,擀饺子皮的人就是“生产者”,包饺子的人就是“消费者”,擀饺子皮的人不关心包饺子的是谁(能包就行,无论是手工包,还是机器包),包饺子的人也不关心擀饺子皮的人是谁(有饺子皮就行,无论是用擀面杖擀的,还是从超市买的)

如上图,“直接调用”的关系,编写 A 代码中会出现很多 B 服务器相关的代码;编写 B 代码中也会出现很多 A 服务器相关的代码,若 B 服务器挂了,可能 A 服务器也会直接受到影响,若后续想继续增加一个 C 服务器,对 A 的改动就很大

如上图,A 只和队列通信,B 也只和队列通信,A 不知道 B 的存在,代码中更没有 B 的影子,B 同理
这样看起来 AB 之间是解耦合了,但 A 和队列,B 和队列之间是否引入了新的耦合呢?
我们之所以害怕耦合,是因为耦合的代码,在后续变更的过程中,比较复杂,容易出现 bug
消息队列,是成熟稳定的产品,代码不会频繁修改,A 和队列,B 和队列之间的交互逻辑基本写一次就固定下来了
tip:
1. 消息队列
通常谈到的 “阻塞队列” 是代码中的一个数据结构,但是由于其实用性很强,就把这个数据结构单独封装成一个服务器程序,并且在单独的服务器上进行部署,称其为 “消息队列”(Message Queue,MQ)
2. 为什么一个服务器收到请求变多可能会挂(崩溃)?
一台服务器就是一台“电脑”,上面提供了一些硬件资源(包括不限于 CPU、内存、硬盘、网络带宽...),就算机器配置再好,硬件资源也是有限的,而服务器每次收到一个请求,处理这个请求的过程需要执行一系列的代码,在执行这些代码的过程中,需要消耗一定的硬件资源(CPU、内存、硬盘、网络带宽...),这些请求消耗的总的硬件资源量超出了机器能提供的上限,机器就会出现问题(卡死、程序崩溃等...)
3. 在请求激增的时候 A 为什么不会挂?队列为什么不会挂?
A 的角色是一个“网关服务器”,收到客户端请求,再把请求转发给其他的服务器,这样的服务器中的代码做的工作比较简单(单纯的数据转发),消耗的硬件资源通常更少,处理一个请求消耗的资源更少,同配置下,就能支持更多的请求处理;同理,队列也是如此。
像 MySQL 这样的数据库,处理每个请求的时候,做的工作就比较多,消耗的硬件资源也是比较多的,因此 MySQL 也是后端系统中容易挂的部分
像 Redis 这样的内存数据库,处理请求做的工作远远少于 MySQL 做的工作,消耗的资源更少,Redis 就不容易挂
生产者消费者模型的缺点:
1) 需要更多的机器来部署这样的消息队列
2) A 和 B 之间通信的延时会边长(如果对于 A 和 B 之间的调用要求响应时间比较短,就不适合了;若是“转账”这样的场景,宁愿慢点,也要稳)
1.2.3 Java 标准库中的阻塞队列
- BlockingQueue 是一个接口,真正实现的类是 LinkedBlockingQueue
- put 方法用于阻塞式的入队列,take 方法用于阻塞式的出队列,其可以被 Interrupt 方法所唤醒(是线程安全的)
- 因为 BlockingQueue 继承于 Queue ,所以其也有 offer、poll、peek 等方法,但是这些方法不具有阻塞特性
示例代码:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;public class Demo27 {public static void main(String[] args) {BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(1000);//生产者线程Thread t1 = new Thread(() -> {int i = 1;while (true) {try {queue.put(i);System.out.println("生产元素 " + i);i++;//给生产操作加上 sleep,生产慢点,消费快点//Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}});//消费者线程Thread t2 = new Thread(() -> {while (true) {try {Integer i = queue.take();System.out.println("消费元素 " + i);//给消费操作加上 sleep,生产快点,消费慢点Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();t2.start();}
}
当给消费者操作加上 sleep 时运行结果:

当给生产者操作加上 sleep 时运行结果:

模拟实现基于数组的阻塞队列
//此处不考虑泛型参数,只是基于 String 进行存储
class MyBlockingQueue {private String[] data = null;private volatile int head = 0;//标记头节点private volatile int tail = 0;//标记尾节点private volatile int size = 0;//记录有效数据个数public MyBlockingQueue(int capacity) {data = new String[capacity];}public void put(String s) throws InterruptedException {//加锁的对象,可以单独定义一个 locker,也可以直接使用 thissynchronized (this) {if (size == data.length) { //此处使用 while 是最稳妥的//队列满了,此处的 wait 由 take 操作this.wait();}data[tail] = s;tail++;if (tail >= data.length) {tail = 0;}size++;this.notify();}}public String take() throws InterruptedException {String ret = "";synchronized (this) {if (size == 0) { //此处使用 while 是最稳妥的//队列为空,此处的 wait 由 put 操作this.wait();}ret = data[head];head++;if (head > data.length) {head = 0;}size--;this.notify();}return ret;}
}
tip1:上述两种写法优劣分析:(针对写法方面,功能上是一样的)
1) 方法一的可读性更高,更直观,更简单;方法二求余运算,需要程序员非常熟悉求余是什么样的效果(无形中提高了要求)
2) 方法一的效率也高于方法二,因为对于计算机来说,% 就是算除法,除非是针对 2 的 N 次方进行乘除运算(会被编译器优化成移位运算),速度会非常快,否则 CPU 计算乘除法是一个比较慢的操作(特别是除法);而方法一的写法是 “判定”,往往是一个非常简单快速的 cmp 指令(比乘除法快很多)
tip2:

1.3 线程池
最初引入线程,就是因为进程太重了,频繁创建销毁进程开销比较大(大/小 是相对的)
而随着业务上对于性能要求越来越高,线程创建/销毁的频次越来越多,这时线程创建销毁的开销变得比较明显,无法忽视了
线程池就是解决上述问题的常见方案,线程池就是把线程提前从系统中申请好,放到一个地方,后面需要使用线程的时候,直接从这个地方来取,而不是从系统重新申请,线程用完之后,也是回到刚才的地方(资源是进程申请好了的,创建线程本身不需要资源分配)
1.3.1 内核态 & 用户态
操作系统 = 操作系统内核(操作系统的核心功能部分,负责完成一个操作系统的核心工作 “管理”) + 操作系统配套的应用程序
执行很多代码逻辑是需要用户态和内核态的代码配合完成的,实际场景中,应用程序有很多,其都是由内核统一负责管理和服务的,内核中非常繁忙
假设场景:让同学帮忙带饭,和自己去买饭
从系统创建线程,就相当于让同学帮忙带饭,这样的逻辑就是调用系统 api,由系统内核执行一系列逻辑来完成这个过程(同学不光给你带饭,还要买自己的,可能他还想去买个饮料,整个过程不可控)
直接从线程池里取,就相当于自己去买饭,整个过程都是纯用户态代码,整个过程更可控,效率更高
因此通常认为,纯用户态操作就比经过内核的操作效率更高
1.3.2 Java 标准库中的线程池
标准库提供了类 ThreadPoolExecutor(构造方法)

经典面试题:上面红框中构造方法的参数含义
1) int corePoolSize(核心线程数), int maximumPoolSize(最大线程数)
此线程池中支持 ”线程扩容“,某个线程池初始状态下可能有 M 个线程,实际使用中发现 M 不够用,就会自动增加 M 个数
tip:在 Java 标准库的线程中的线程分为两类
a) 核心线程(也可理解成最少有多少个线程,相当于正式员工,一旦录用,不会轻易辞掉)
b) 非核心线程(线程扩容过程中新增的,相当于临时工,一段时间不干活就被辞退)
出现上述线程分类的原因是:cpu 上的核心数目是有限的
最大线程数 = 核心线程数 + 非核心线程数
2) long keepAliveTime(数值),TimeUnit unit(单位 秒、分钟、小时、天...)
非核心线程会在线程空闲的时候被销毁,该参数就是允许非核心线程摸鱼的最大时间
3) BlockingQueue<Runnable> workQueue(工作队列)
线程池的工作过程是典型的“生产者消费者模型”,程序员使用的时候,通过形如 “submit” 这样的方法把要执行的任务设定到线程池里,线程池内部的工作线程负责执行这些任务
Runnable 接口本身的含义就是一段可以执行的任务
此处的阻塞队列由我们自行指定:a) 队列的容量 capacity;b) 队列的类型
4) ThreadFactory threadFactory(线程工厂)
就是 Thread 类的工厂类,通过整个类完成 Thread 实例的创建和初始化操作,此处的 ThreadFactory 就可以针对线程池里的线程进行批量的设置数据(一般使用标准库提供的 ThreadFactory 的默认值)
tip:“工厂” 指的是 “工厂设计模式”,是一种常见的设计模式,是在创建类的实例时使用的设计模式,因为构造方法有 “坑”,所以通过工厂模式来 “填坑”
详细分析:
构造方法是一个特殊的方法,必须和类名一样,要想实现多个版本的构造方法,必须通过 “重载”(overload),如下在一个平面描述一个点,可以通过平面坐标 “x y”,也可以通过极坐标 “α r” 两种构造方法来实例化:
class Point {public Point (double x, double y) {...}public Point (double α, double r) {...}
}发现这两个构造方法无法构成重载,这就是构造方法的 “坑”(局限性)
为解决以上问题,引入了 “工厂设计模式”。通过 “普通方法”(通常是静态方法)完成对象构造和初始化的操作,如下:
class Point {}class PointFactory {public static Point makePointByXY (double x, double y) {Point p;p.setX(x);p.setY(y);return p;}public static Point makePointByRA (double r, double α) {Point p;p.setR(r);p.setA(α);return p;}
}此处用来创建对象的 static 方法就称为 “工厂方法”,有时工厂方法也会放到单独的类里实现,该类成为 “工厂类”
5) RejectedExecutionHandler handler(拒绝策略)(最重要!)
如果线程池的任务队列满了,还要继续给这个队列添加任务的话,不会阻塞,而是直接拒绝
Java 标准库给出了四种不同的拒绝策略:

ThreadPoolExecutor 的功能很强大,使用也很麻烦,所以 Java 标准库对这个类进一步封装了一下,Executors 提供了一些工厂方法,可以更方便的构造出线程池,如下:

如下线程池的示例代码:

发生了变量捕获,只需要再创建一个变量来接收 i 即可,如下:

运行结果:

执行这个代码,虽然 100 个任务都执行完毕了,但是整个进程并没有结束,这是因为此处线程创建出来的线程,默认都是 “前台线程”,虽然 main 线程结束了,但是这些线程池里的前台线程仍然存在
此时就需要使用 shutdown() 方法手动结束线程池里的线程,如下:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class thread {public static void main(String[] args) throws InterruptedException {ExecutorService service = Executors.newFixedThreadPool(4);for (int i = 0; i < 100; i++) {int id = i;service.submit(() -> {Thread current = Thread.currentThread();System.out.println("hello thread" + id + ", " + current.getName());});}//最好不要立即就终止,可能使任务还没执行完呢,线程就被终止了Thread.sleep(2000);//把线程池里所有的线程都终止掉service.shutdown();System.out.println("程序退出!");}
}
运行结果:

指定线程个数
使用线程池的时候需要指定线程个数,因为
1) 一台主机上,并不只是运行这一个程序
2) 这个程序也不是 100% 每个线程都跑满 cpu,线程工作过程中可能会涉及到一些 IO 操作/阻塞操作,而主动放弃 cpu(如果线程代码里都是算数运算,确实能跑满 cpu,如果代码中包含了 sleep、wait、加锁、打印、网络通信、读写硬盘等等操作,就会使线程主动放弃 cpu 一会)
在实际开发中更建议通过 “实验” 的方式找到一个合适的线程个数值(给线程池设置不同的线程数,分别进行性能测试,关注响应时间/消耗资源,挑选一个比较合适的数值)
模拟实现线程池
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;class MyThreadPool {private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1000);//此处 n 表示创建几个线程public MyThreadPool(int n) {//先创建出 n 个线程for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {//循环的从队列中取任务while (true) {Runnable runnable = null;try {runnable = queue.take();runnable.run();} catch (InterruptedException e) {throw new RuntimeException(e);}}});t.start();}}//添加任务public void submit(Runnable runnable) {try {queue.put(runnable);} catch (InterruptedException e) {throw new RuntimeException(e);}}
}public class Demo {public static void main(String[] args) {MyThreadPool pool = new MyThreadPool(4);for (int i = 0; i < 1000; i++) {int id = i;pool.submit(() -> {System.out.println("执行任务" + id + ", " + Thread.currentThread().getName());});}}
}
1.4 实例:定时器
定时器相当于一个 “闹钟”,像网络通信中就经常需要设定一个 “超时时间”,此时就需要用到这个 “闹钟”机制
1.4.1 Java标准库中也提供了定时器实现:
import java.util.Timer;
import java.util.TimerTask;public class Demo32 {public static void main(String[] args) {Timer timer = new Timer();timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello");}}, 3000);System.out.println("程序开始运行!");}
}
运行结果:

从运行结果可以看出,当我们传入第二个参数 3000ms 之后,它就会等待 3s,然后再执行打印操作
而且 Timer 也支持管理多个任务:
import java.util.Timer;
import java.util.TimerTask;public class Demo32 {public static void main(String[] args) {Timer timer = new Timer();timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello3");}}, 3000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello2");}}, 2000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello1");}}, 1000);System.out.println("程序开始运行!");}
}
运行结果:

tip:

1.4.2 模拟实现定时器
对于定时器来说,其核心主要有:
1) 创建类,描述一个要执行的任务(任务的内容,任务的时间)
//表示一个任务
class MyTimerTask {private Runnable runnable; //任务的具体实现//此处的 time 通过毫秒时间戳来表示这个任务具体什么时候执行//意思是:此时是 9:00,时间设为 一小时,就是 10:00 执行(绝对时间)//而不是像 Demo32 中一样,只是 3000ms 之后执行(相对时间),没有具体时间private long time;public MyTimerTask(Runnable runnable, long delay) {this.runnable = runnable;this.time = System.currentTimeMillis() + delay;}public void run() {runnable.run();}public long getTime() {return time;}
}2) 管理多个任务,通过某个数据结构,把多个任务存起来
若使用 List:

因为这里的 MyTimerTask 是按照时间来执行任务的,只要能够确定所有任务中,时间最小的任务,判定它是否到时间该执行即可(时间最小的任务还没到时间的话,其他任务就不必考虑了)
所以使用 堆 来保存任务是更好的选择,能够很方便的找到“最小值/第二小/第三小”
![]()
采用这个优先级队列来实现,但是 MyTimerTask 不能直接传入,需要指定明确的比较规则(方式一:实现 Comparable 接口;方式二:指定 Comparator 传入),下面实现一个 Comparable:
//表示一个任务
class MyTimerTask implements Comparable<MyTimerTask> {private Runnable runnable; //任务的具体实现//此处的 time 通过毫秒时间戳来表示这个任务具体什么时候执行//意思是:此时是 9:00,时间设为 一小时,就是 10:00 执行(绝对时间)//而不是像 Demo32 中一样,只是 3000ms 之后执行(相对时间),没有具体时间private long time;public MyTimerTask(Runnable runnable, long delay) {this.runnable = runnable;this.time = System.currentTimeMillis() + delay;}public void run() {runnable.run();}public long getTime() {return time;}@Overridepublic int compareTo(MyTimerTask o) {//此处的 - 的顺序,决定了是大堆还是小堆//本代码实现中需要小堆//这里 - 的顺序,不要背,通过“实验”的方式来确认return (int) (this.time - o.time);}
}//表示自己实现定时器
class MyTimer {//private List<MyTimerTask> list = new ArrayList<>(); //不是最优选private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();
}3) 有专门的线程,执行这里的任务
//表示自己实现定时器
class MyTimer {//private List<MyTimerTask> list = new ArrayList<>(); //不是最优选private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();public MyTimer() {//创建线程,负责执行上述队列中的内容Thread t = new Thread(() -> {while (true) {if (queue.isEmpty()) {continue;}MyTimerTask current = queue.peek();//查看栈顶元素//比较当前时间与需执行时间,若当前为12:00,需执行时间为11:55,则应该执行if (System.currentTimeMillis() >= current.getTime()) {//要执行任务current.run();//把执行过的任务从队列中删除queue.poll();} else {//时间未到,不执行任务continue;}}});t.start();}//创建任务到队列中public void schedule(Runnable runnable, long delay) {MyTimerTask myTimerTask = new MyTimerTask(runnable, delay);queue.offer(myTimerTask);}
}1.4.3 当前代码的线程安全问题
PriorityQueue 这个类本身不带线程安全的控制能力,并且代码中又是多个线程来进行操作,所以一定会存在线程安全问题的风险
将代码中两个线程操作都加锁:

运行结果:

确实能够正常运行了,但依旧有问题未解决:
1) 初始情况下,如果队列中没有任何元素

改进:使用 wait 方法进行阻塞等待

2) 假设队列中已经包含元素了
当前时间是 10:45,任务时间 12:00

改进:(此处 wait 不能等着别人唤醒,而是设定一个具体时间,该时间为 任务时间 - 当前时间)

使用 wait 的时候,线程阻塞,就可以释放 cpu 资源给其他线程使用了
tip:
1) 不使用 sleep 的原因

sleep 休眠的时候不会释放锁,所以当 sleep 1h 15min 的过程中,来了一个时间更早的任务 11:30 要执行,那么这个任务根本就添加不进来

如果使用 wait,每次来新的任务,都会把 wait 唤醒,重新设定等待时间
2) 不使用 PriorityBlockingQueue 的原因

若使用 PriorityBlockingQueue :

代码就变成 两把锁 多个线程了,容易出现死锁的情况(并非 100% 出现),需要精心控制这里的加锁顺序,代码的编写复杂程度提高不少
此处不适用阻塞队列的话,整个代码只需要一把锁 locker 就可以解决所有问题了
除了可以基于优先级队列来实现定时器外,还可以根据 “时间轮(也是一个巧妙的数据结构)” 的方式实现,做了解不展开
相关文章:
多线程(4)——单例模式、阻塞队列、线程池、定时器
1. 多线程案例 1.1 单例模式 单例模式能保证某个类在程序中只存在唯一一份实例,不会创建出多个实例(这一点在很多场景上都需要,比如 JDBC 中的 DataSource 实例就只需要一个 tip:设计模式就是编写代码过程中的 “软性约束”&am…...
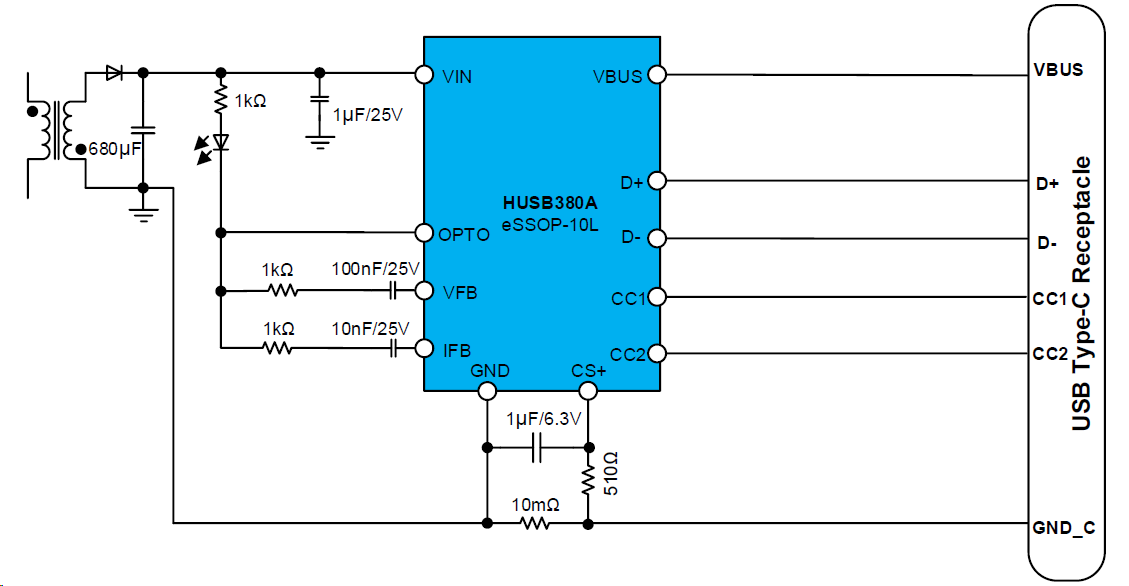
告别电量焦虑,高性能65W PD快充芯片HUSB380A打造梦中情【头】
市面上的充电器越来越卷,让人眼花缭乱。压力同样也给到了快充芯片行业,要在激烈的市场竞争中脱颖而出,快充芯片必须集高功率、高性价比与广泛的兼容性等于一身。 基于此,慧能泰推出了新一代高性能PD Source产品——HUSB380A。 图…...
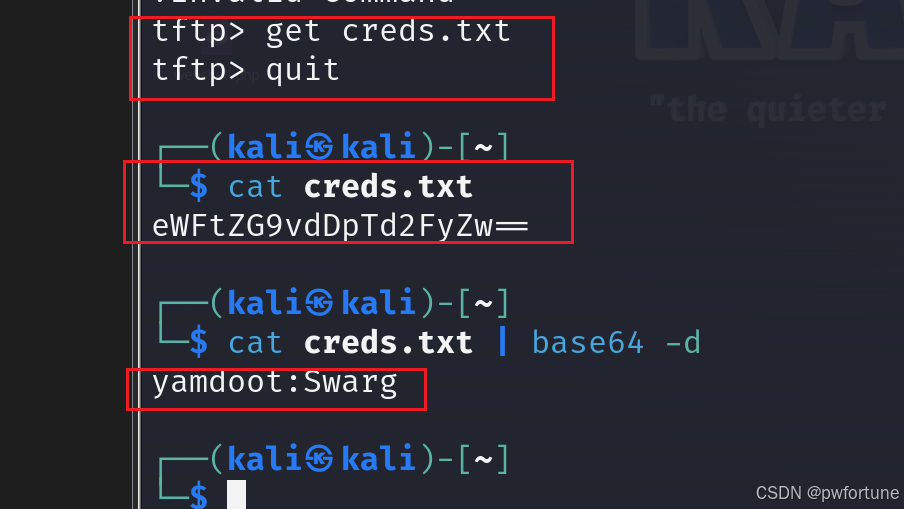
vulnhub靶场 — NARAK
下载地址:https://download.vulnhub.com/ha/narak.ova Description:Narak is the Hindu equivalent of Hell. You are in the pit with the Lord of Hell himself. Can you use your hacking skills to get out of the Narak? Burning walls and demons are around every cor…...
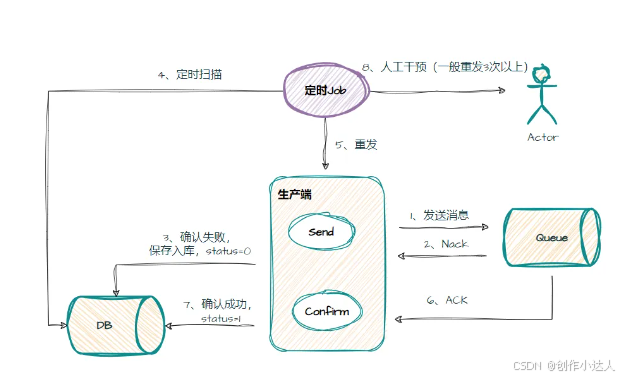
RabbitMQ如何保证消息不丢失
RabbitMQ消息丢失的三种情况 第一种:生产者弄丢了数据。生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。 第二种:RabbitMQ 弄丢了数据。MQ还没有持久化自己挂了。 第三种…...

(亲测有效)SpringBoot项目集成腾讯云COS对象存储(1)
目录 一、腾讯云对象存储使用 1、创建Bucket 2、使用web控制台上传和浏览文件 3、创建API秘钥 二、代码对接腾讯云COS(以Java为例) 1、初始化客户端 2、填写配置文件 3、通用能力类 文件上传 测试 一、腾讯云对象存储使用 1、创建Bucket &am…...

无人机之故障排除篇
一、识别故障 掌握基本的无人机系统知识,遵循“先易后难、先外后内、先软件后硬件”的原则进行故障识别。一旦发现故障,立即停止飞行,避免进一步损坏。 二、机械部件维修 对于机身裂痕、螺旋桨损坏等情况,根据损坏程度更换相应部…...

深入理解Python常见数据类型处理
目录 概述数字类型 整数(int)浮点数(float)复数(complex) 字符串(str) 字符串基本操作字符串方法 列表(list) 列表基本操作列表方法列表推导式 元组…...
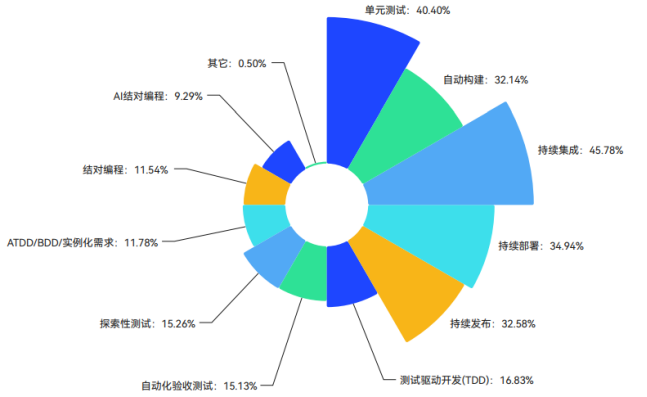
最佳实践:CI/CD交付模式下的运维展望丨IDCF
李洪锋 启迪万众数字技术(广州)有限公司 ,产品研发中心-系统运维部、研发效能(DevOps)工程师(中级)课程学员 一、DevOps现状 据云计算产业联盟《中国DevOps现状调查报告2023》显示,国内DevOps 落地成熟度…...

Flat Ads:开发者如何应对全球手游市场的洗牌与转型
2023年下半年至2024年上半年,中国手游的海外市场表现经历了显著变化,开发者要如何应对全球手游市场的洗牌与转型?本篇文章我们将结合相关行业白皮书的最新数据对中国手游出海表现进行分析与洞察。 一、中国手游海外市场表现 根据Sensor Tower《2024年海外手游市场洞察》最新…...

ai取名软件上哪找?一文揭秘5大ai取名生成器
在这个世界上,每一个新生命的到来都是一份奇迹,无论是一个新生儿的第一声啼哭,还是一只宠物的第一次摇尾巴,都充满了无限的希望和喜悦。 然而,给这个小生命起一个响亮、独特且富有意义的名字,往往让人煞费…...

ppt转换成pdf文件,这5个方法一键搞定!小白也能上手~
不管是工作上还是学习上,我们都会遇到转换文档格式的问题。比如常见的pdf转word,ppt转pdf,图片转pdf等。 很多软件都有自带的转换功能可以实现,但是需要保证转换后不乱码,且清晰度足够的方法还是少见的。本文整理了几个…...

中国每个软件创业者都是这个时代的“黑悟空”
作者 | 白鲸开源CEO 郭炜 我作为一个具有30游龄而20年都不碰游戏的游戏玩家,最近为了《黑神话:悟空》(简称,黑悟空),不但花重金更新了显卡,还第一次下载了Steam并绑定了支付,为的就是支持这个第…...

解决Qt多线程中fromRawData函数生成的QByteArray数据不一致问题
解决Qt多线程中fromRawData函数生成的QByteArray数据不一致问题 目录 🔔 问题背景📄 问题代码❓ 问题描述🩺 问题分析✔ 解决方案 🔔 问题背景 在开发一个使用Qt框架的多线程应用程序时,我们遇到了一个棘手的问题&…...

datax关于postsql数据增量迁移的问题
看官方文档是不支持的 数据源及同步方案_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心 (aliyun.com) 看了下源码有个postsqlwriter 看了下也就拼接sql 将 PostgresqlWriter中的不允许更新先注释了 让他过去先 然后看到 WriterUtil中的对应方法 getWriteTemplat…...

【Go】实现字符切片零拷贝开销转为字符串
package mainimport ("fmt""unsafe" )func main() {bytes : []byte("hello world")s : *(*string)(unsafe.Pointer(&bytes))fmt.Println(s)bytes[0] Hfmt.Println(s) }slice的底层结构是底层数组、len字段、cap字段。string的底层结构是底层…...

[sqlserver][sql]sqlserver查询执行过的历史sql
SQL是一个针对SQL Server数据库的查询执行过的历史 select * from (SELECT *FROM sys.dm_exec_query_stats QS CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) ST ) a where a.creation_time >2018-07-18 17:00:00 and charindex(delete from ckcdlist ,text)>0 an…...

python中n次方怎么表示
Python中的n次方用pow()方法来表示,pow()方法返回 xy(x的y次方)的值。 语法 以下是 math 模块 pow() 方法的语法: import math math.pow( x, y ) 内置的 pow() 方法 pow(x, y[, z]) 函数是计算x的y次方,如果z在存在&…...

Java数组怎么转List,Stream的基本方法使用教程
Stream流 Java 的 Stream 流操作是一种简洁而强大的处理集合数据的方式,允许对数据进行高效的操作,如过滤、映射、排序和聚合。Stream API 于 Java 8 引入,极大地简化了对集合(如 List、Set)等数据的处理。 一、创建 Stream 从集合创建: List<String> list = Ar…...

2024-07-12 - 基于 sealos 部署高可用 K8S 管理系统
摘要 Sealos 是一款以 Kubernetes 为内核的云操作系统发行版。它以云原生的方式,抛弃了传统的云计算架构,转向以 Kubernetes 为云内核的新架构,使企业能够像使用个人电脑一样简单地使用云。 操作实践 1、服务器规划 kubernetes集群大体上…...

Ps:首选项 - 单位与标尺
Ps菜单:编辑/首选项 Edit/Preferences 快捷键:Ctrl K Photoshop 首选项中的“单位与标尺” Units & Rulers选项卡允许用户根据工作需求定制 Photoshop 的测量单位和标尺显示方式。这对于保持工作的一致性和精确性,尤其是在跨设备或跨平台…...

别再手动调参了!用Simulink系统辨识工具箱,5分钟搞定Buck电路的PID控制器设计
电力电子工程师的效率革命:用Simulink系统辨识工具箱5步完成Buck电路PID设计 在电力电子领域,Buck电路作为最基础的DC-DC降压拓扑,其控制器设计一直是工程师的必修课。传统的手工计算和试错调参方法不仅耗时费力,还难以达到理想的…...

ROFL-Player:英雄联盟回放文件解析与管理的技术实践
ROFL-Player:英雄联盟回放文件解析与管理的技术实践 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 在电子竞技数据分析领域…...

跨镜追踪技术・十大核心应用场景
镜像视界浙江科技有限公司以无感空间重构 全域跨镜追踪为核心,依托全栈自研引擎与权威资质背书,构建自成体系、无同类对标、无可替代的空间智能应用矩阵。技术原生适配复杂实景,在无 GPS、无标签、无穿戴、无基站条件下,实现厘米…...

联想刃7000k BIOS深度解锁技术实现与性能优化指南
联想刃7000k BIOS深度解锁技术实现与性能优化指南 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 联想刃7000k作为一款高性能游戏主…...

RISC-V开发踩坑实录:从编译错误‘csrr a5,mhartid’到GDB报错‘E14’的完整排错指南
RISC-V开发实战:从编译到调试的完整排错手册 在嵌入式开发领域,RISC-V架构正以惊人的速度改变着行业格局。作为一名长期从事ARM架构开发的工程师,当我第一次接触RISC-V时,本以为凭借多年的嵌入式经验可以轻松上手,却没…...
)
烟草叶部病害-目标检测数据集(包括VOC格式、YOLO格式)
烟草叶部病害-目标检测数据集(包括VOC格式、YOLO格式) 数据集(文章最后关注公众号获取数据集): 链接: https://pan.baidu.com/s/1-4LCiMULEf7OT9JHzL38BQ?pwdytbu 提取码: ytbu 数据集信息介绍: 共有 156…...
Flutter Shimmer高级用法:创建复杂的多方向闪烁效果
Flutter Shimmer高级用法:创建复杂的多方向闪烁效果 【免费下载链接】flutter_shimmer A package provides an easy way to add shimmer effect in Flutter project 项目地址: https://gitcode.com/gh_mirrors/fl/flutter_shimmer Flutter Shimmer是一款强大…...

Codex 杀进 Chrome!接管了我的浏览器后,我在摸鱼
家人们,Codex 这次真的往普通电脑工作流里钻了。 OpenAI 已经宣布,Codex 现在可以直接在 macOS 和 Windows 的 Chrome 中运行。 它可以和 Chrome 里的应用、网站配合得更好,还能在后台标签页之间并行运行,不会一直占用你的键盘鼠标…...

FanControl终极指南:让你的Windows风扇控制变得智能又安静
FanControl终极指南:让你的Windows风扇控制变得智能又安静 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

非标设备集成指南:如何用德创V+平台统一管理相机、PLC和视觉算法
非标设备集成实战:基于V平台的视觉系统协同管理方案 在工业自动化领域,非标设备集成往往面临多品牌硬件兼容性差、通讯协议复杂、调试周期长等痛点。传统解决方案需要工程师编写大量底层代码来桥接不同设备,不仅效率低下,后期维护…...