MySQL中的EXPLAIN的详解
一、介绍
官网介绍:
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
explain(执行计划),使用explain关键字可以模拟优化器执行sql查询语句,从而知道MySQL是如何处理sql语句。
explain主要用于分析查询语句或表结构的性能瓶颈。
通过explain命令可以得到:
- – 表的读取顺序
- – 数据读取操作的操作类型
- – 哪些索引可以使用
- – 哪些索引被实际使用
- – 表之间的引用
- – 每张表有多少行被优化器查询
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
版本情况
- MySQL 5.6.3以前只能EXPLAIN SELECT ;MYSQL 5.6.3以后就可以EXPLAIN SELECT,UPDATE,DELETE
- 在5.7以前的版本中,想要显示partitions 需要使用explain partitions 命令;想要显示filtered 需要使用explain extended 命令。在5.7版本后,默认explain直接显示partitions和filtered中的信息。

基本语法
EXPLAIN 或 DESCRIBE语句的语法形式如下:
EXPLAIN SELECT select_options
或者
DESCRIBE SELECT select_options
环境准备:
CREATE DATABASE testexplain CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
use testexplain;
CREATE TABLE L1(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L2(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L3(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L4(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
INSERT INTO L1(title) VALUES('test001'),('test002'),('test003');
INSERT INTO L2(title) VALUES('test004'),('test005'),('test006');
INSERT INTO L3(title) VALUES('test007'),('test008'),('test009');
INSERT INTO L4(title) VALUES('test010'),('test011'),('test012');
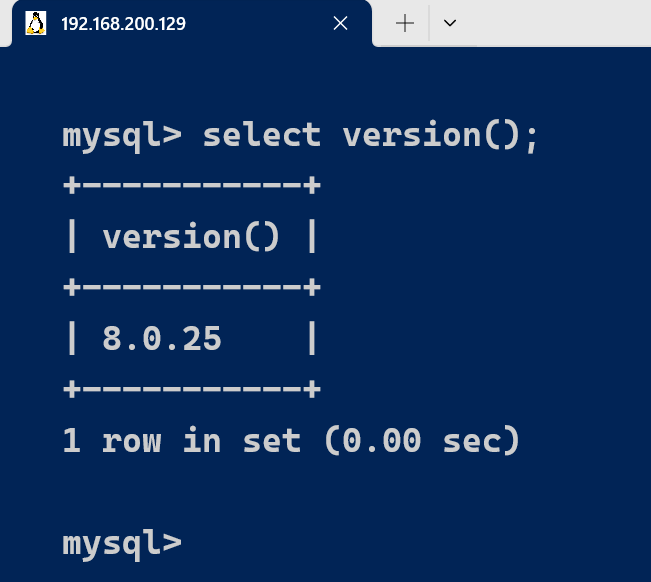
二、基本的使用
explain使用:explain/desc+sql语句,通过执行explain可以获得sql语句执行的相关信息。
EXPLAIN SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id;
DESC SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id;
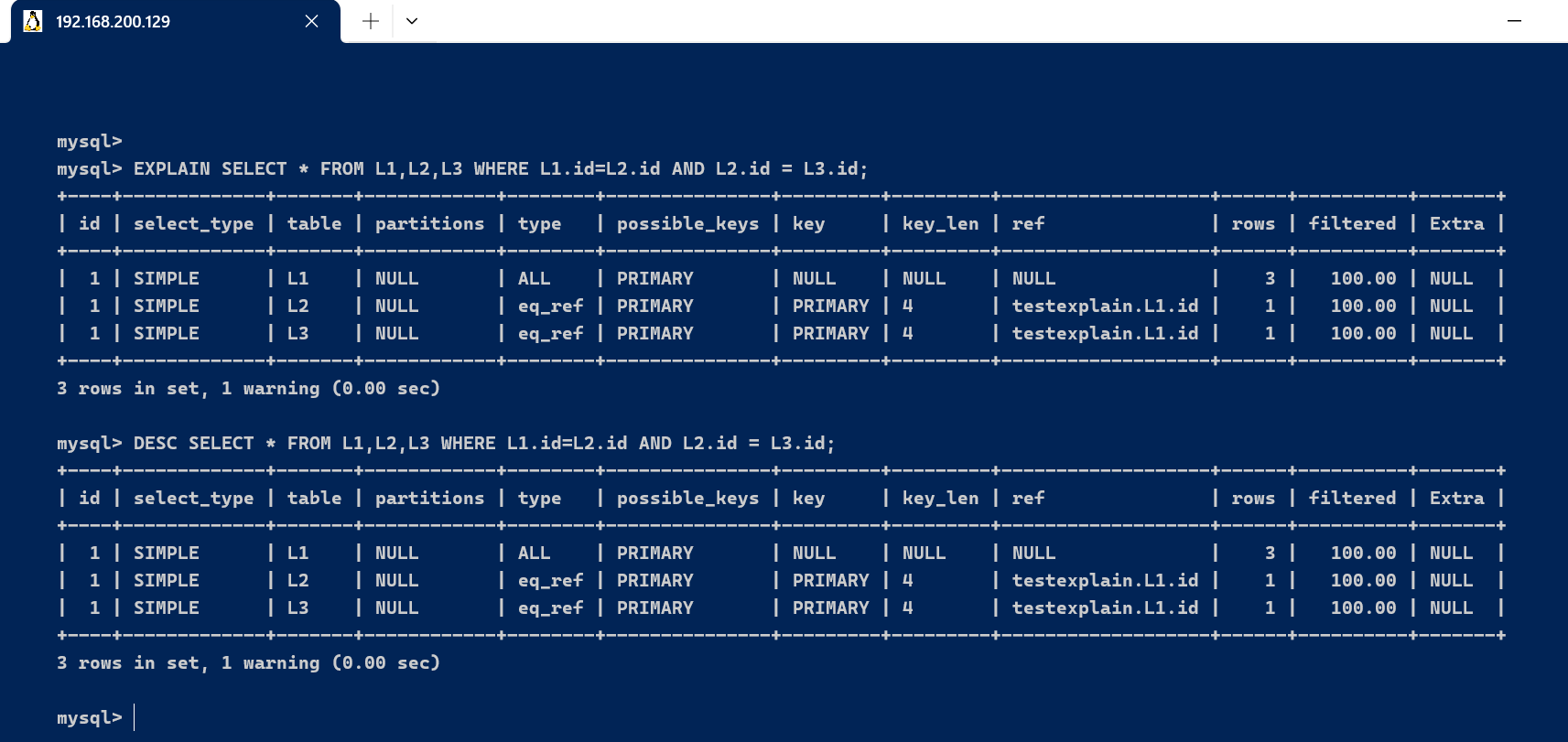
| 序号 | 字段 | 含义 |
|---|---|---|
| 1 | id | 查询的序列号,是一组数字,表示查询中执行 SELECT 子句或操作表的顺序。 |
| 2 | select_type | 表示 SELECT 的类型。常见取值有 SIMPLE(简单查询,不包含子查询或联合查询)、PRIMARY(主查询,即最外层的查询)、UNION(联合查询中的第二个或后续查询)、SUBQUERY(子查询)等。 |
| 3 | table | 表示正在访问的表。 |
| 4 | partitions | 显示匹配的分区信息,如果是非分区表则为 NULL。 |
| 5 | type | 表示表的访问类型,性能由好到差的顺序为 system → const → eq_ref → ref → ref_or_null → index_merge → unique_subquery → index_subquery → range → index → ALL。访问类型越靠前,性能越好。 |
| 6 | possible_keys | 表示查询时可能使用的索引。 |
| 7 | key | 实际使用的索引。如果没有使用索引,则显示为 NULL。 |
| 8 | key_len | 表示使用的索引的字节数。这个值越大,表示查询中使用的索引字段越多。 |
| 9 | ref | 显示索引的哪一列被用到,并且如果可能的话,是哪些列或常量被用于查找索引列中的值。 |
| 10 | rows | 估计要读取的行数,这个数字是一个估计值,不一定是精确的。 |
| 11 | filtered | 表示服务器根据查询条件过滤的行百分比。 |
| 12 | Extra | 包含执行查询的额外信息,比如是否使用临时表、是否进行文件排序等。常见值有 Using index(使用了覆盖索引)、Using where(使用了 WHERE 过滤条件)、Using temporary(使用了临时表)和 Using filesort(使用了文件排序)等。 |
三、字段详解
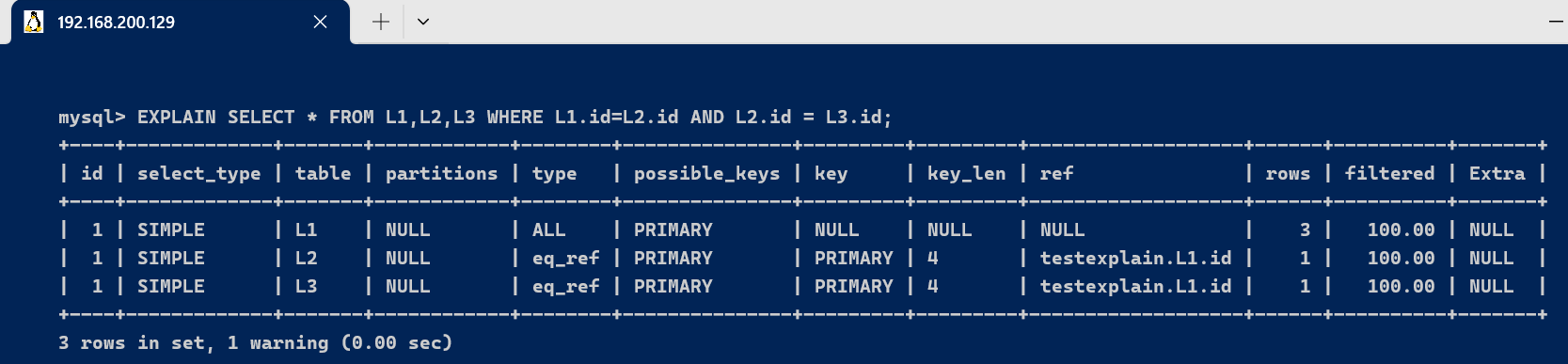
3.1、id字段
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- id相同,执行顺序由上至下
EXPLAIN SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id;
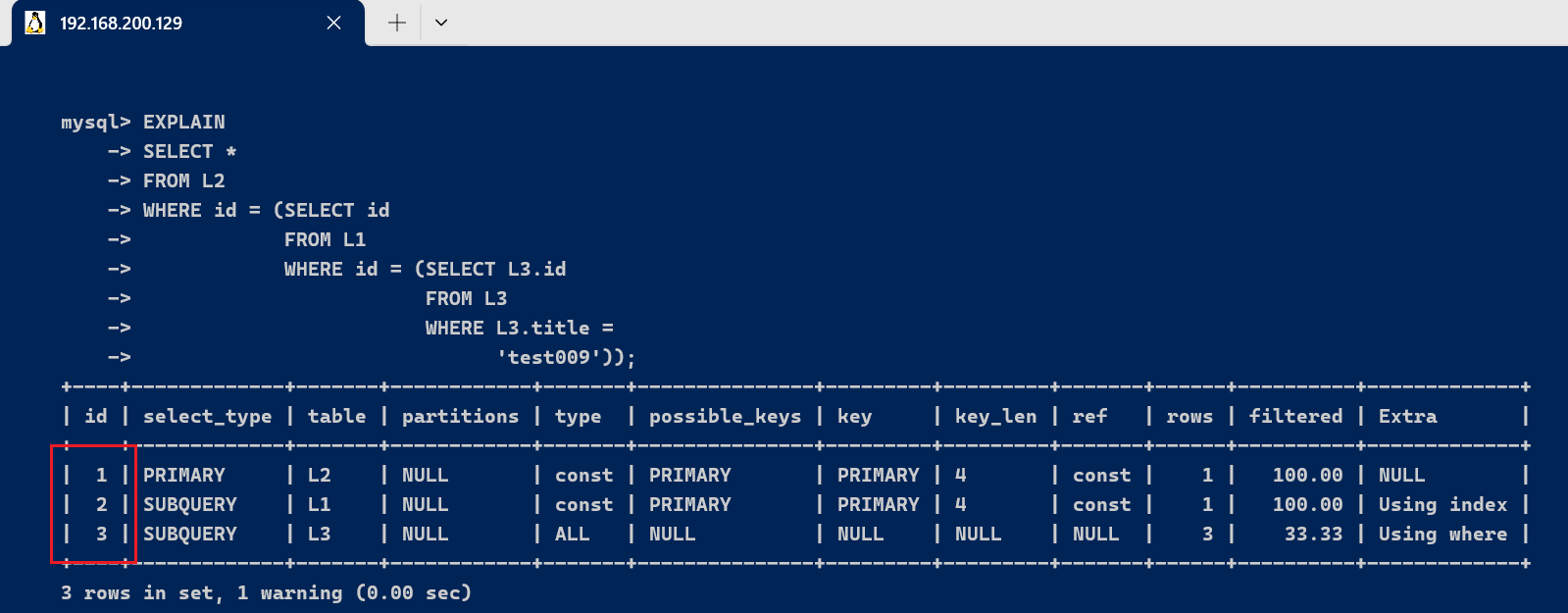
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
EXPLAIN
SELECT *
FROM L2
WHERE id = (SELECT idFROM L1WHERE id = (SELECT L3.idFROM L3WHERE L3.title ='test009'));
3.2、select_type 与 table字段
查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询
- simple : 简单的select查询,查询中不包含子查询或者UNION
EXPLAIN SELECT * FROM L1;
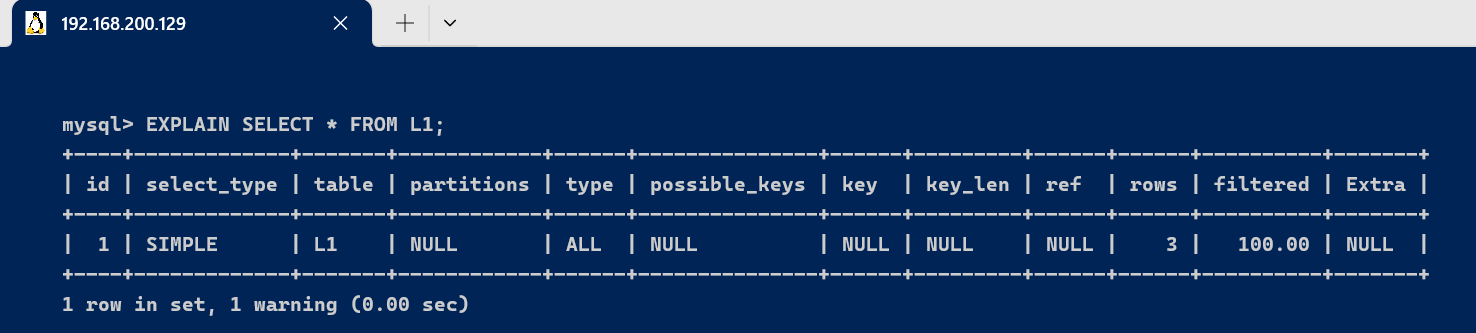
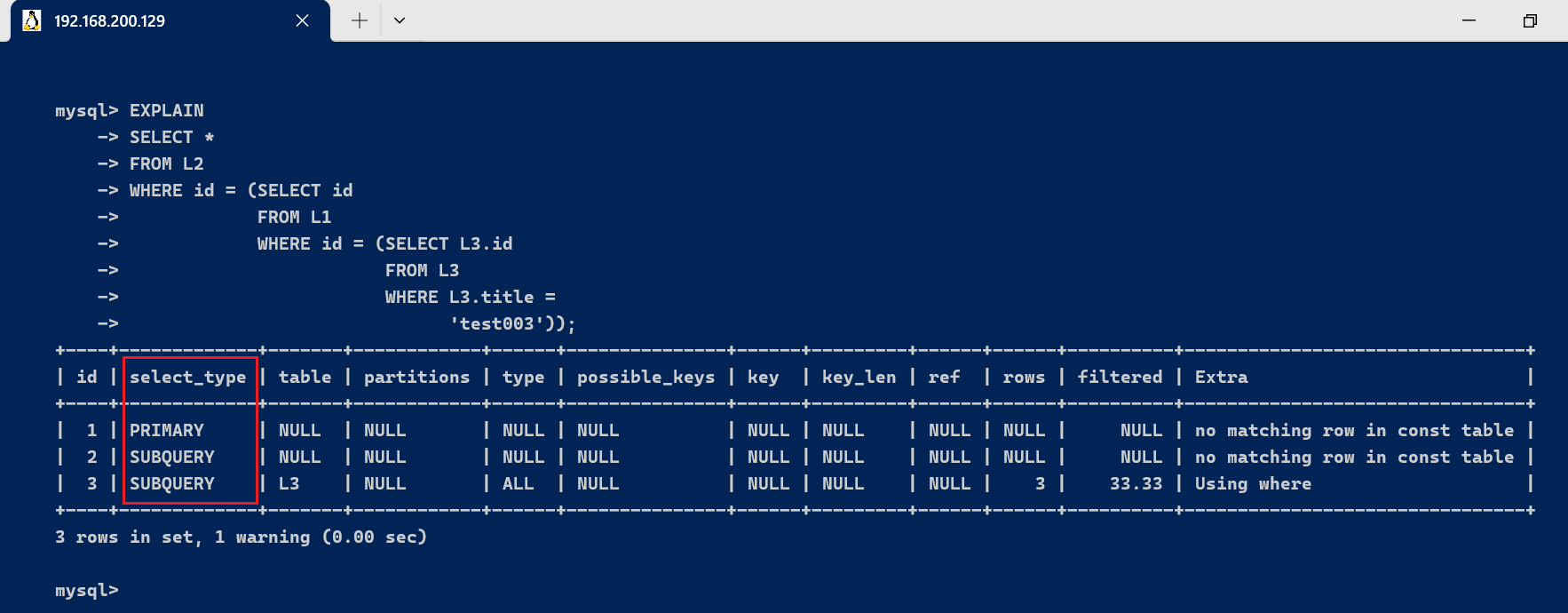
- primary : 查询中若包含任何复杂的子部分,最外层查询被标记
EXPLAIN
SELECT *
FROM L2
WHERE id = (SELECT idFROM L1WHERE id = (SELECT L3.idFROM L3WHERE L3.title ='test003'));
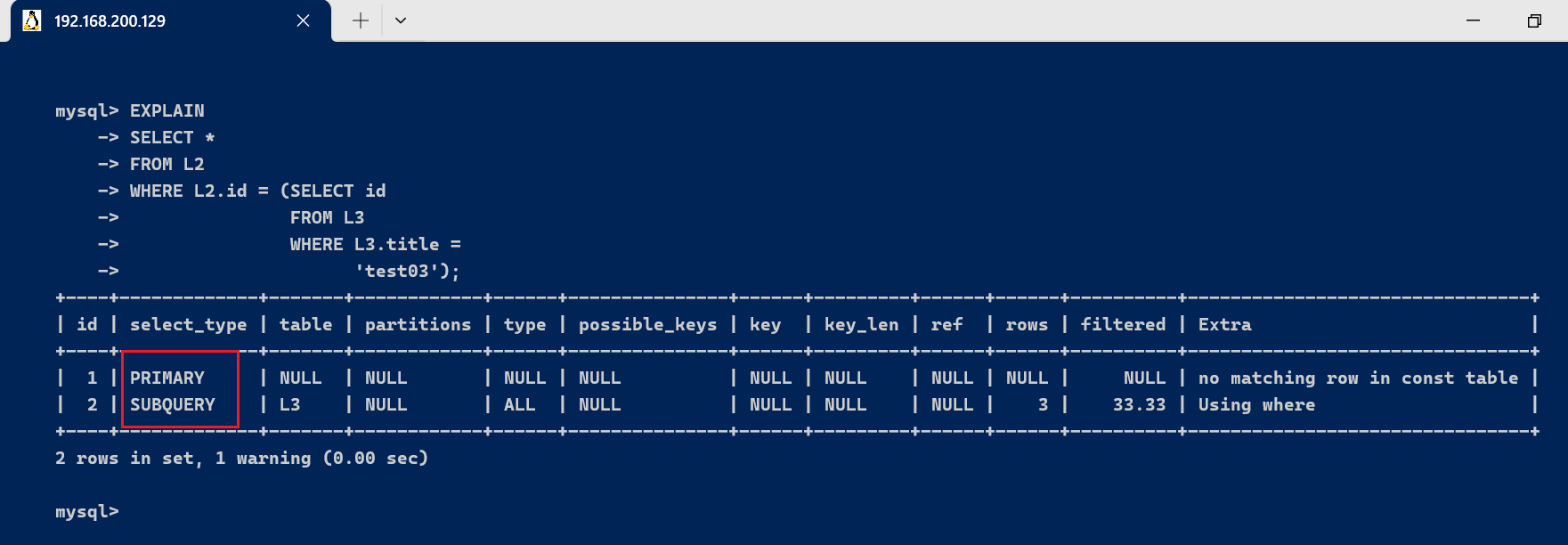
- subquery : 在select或where列表中包含了子查询
EXPLAIN
SELECT *
FROM L2
WHERE L2.id = (SELECT idFROM L3WHERE L3.title ='test03');
- derived : 在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中
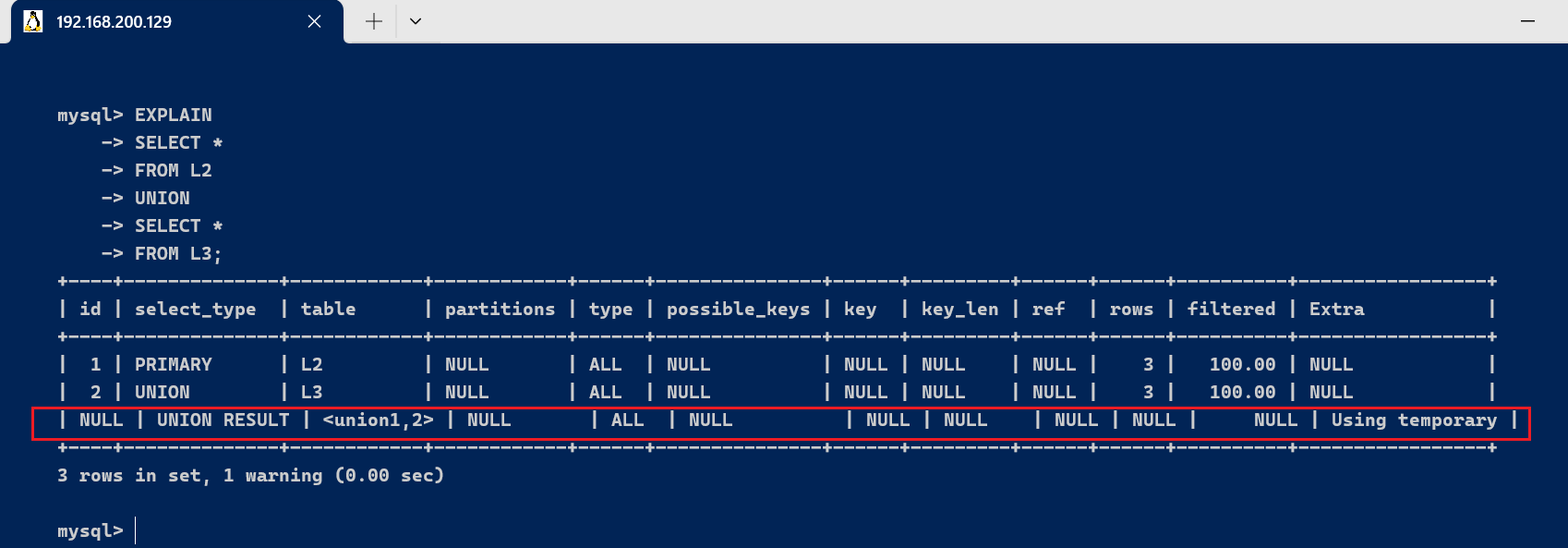
- union : 如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived
- union result : UNION 的结果
EXPLAIN
SELECT *
FROM L2
UNION
SELECT *
FROM L3;
3.3、partitions
分区表是将一个表的数据根据某个字段的值分成多个分区来存储的,这样查询时可以提高效率。
查询时匹配到的分区信息,对于非分区表值为NULL ,当查询的是分区表时, partitions 显示分区表命中的分区情况。
对于非分区表(例如原始的 L1 表),partitions 字段会显示 NULL:
EXPLAIN SELECT * FROM L1 WHERE id = 1;
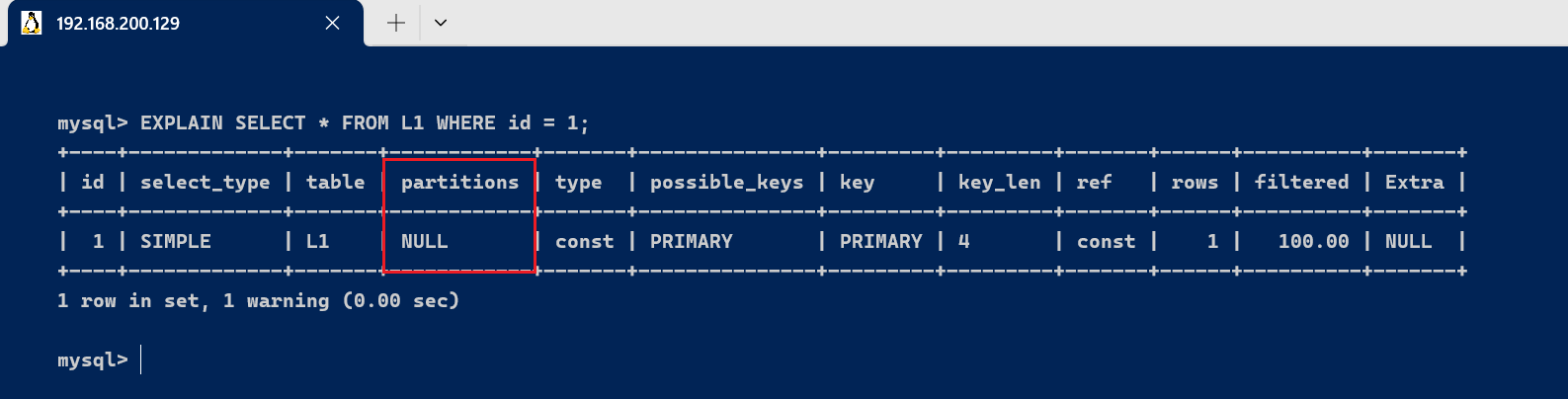
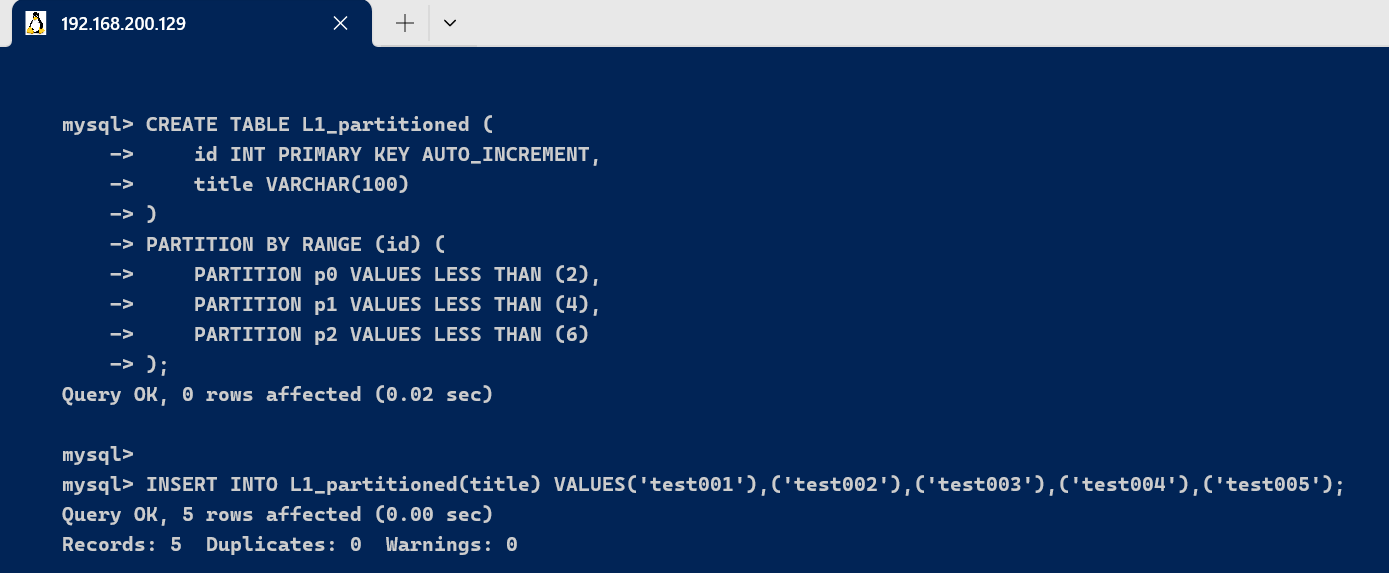
我们以 L1 表为例,将它根据 id 字段进行分区:
CREATE TABLE L1_partitioned (id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100)
)
PARTITION BY RANGE (id) (PARTITION p0 VALUES LESS THAN (2),PARTITION p1 VALUES LESS THAN (4),PARTITION p2 VALUES LESS THAN (6)
);
INSERT INTO L1_partitioned(title) VALUES('test001'),('test002'),('test003'),('test004'),('test005');
这个表会根据 id 的值分成 3 个分区:
p0分区存储id小于 2 的数据p1分区存储id小于 4 的数据p2分区存储id小于 6 的数据
使用 EXPLAIN 查看查询的分区命中情况:
EXPLAIN SELECT * FROM L1_partitioned WHERE id = 1;
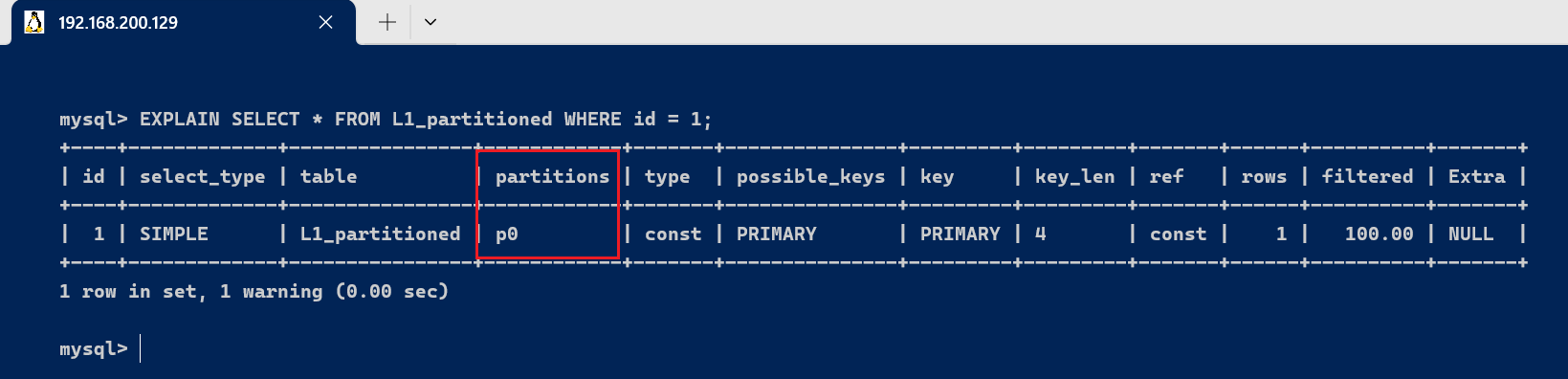
此查询会显示 partitions 字段的值为 p0,因为 id=1 的记录被存储在 p0 分区中。
EXPLAIN SELECT * FROM L1_partitioned WHERE id = 3;
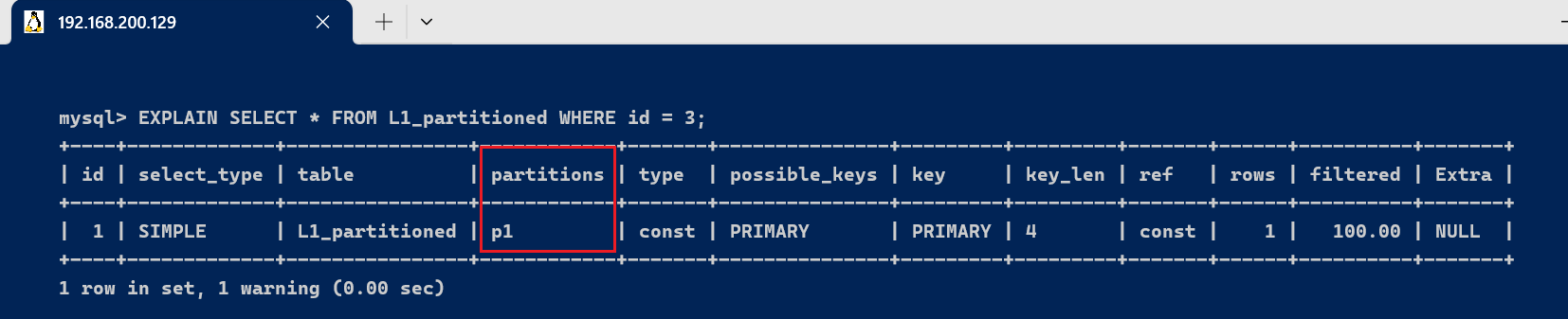
此查询会显示 partitions 字段的值为 p1,因为 id=3 的记录被存储在 p1 分区中。
当查询条件跨越多个分区时,EXPLAIN 会显示命中的多个分区:
EXPLAIN SELECT * FROM L1_partitioned WHERE id BETWEEN 1 AND 5;

3.4、type字段
type显示的是连接类型,是较为重要的一个指标。下面给出各种连接类型,按照从最佳类型到最坏类型进行排序:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL
-- 简化
system > const > eq_ref > ref > range > index > ALL
- system : 表仅有一行 (等于系统表)。这是const连接类型的一个特例,很少出现。
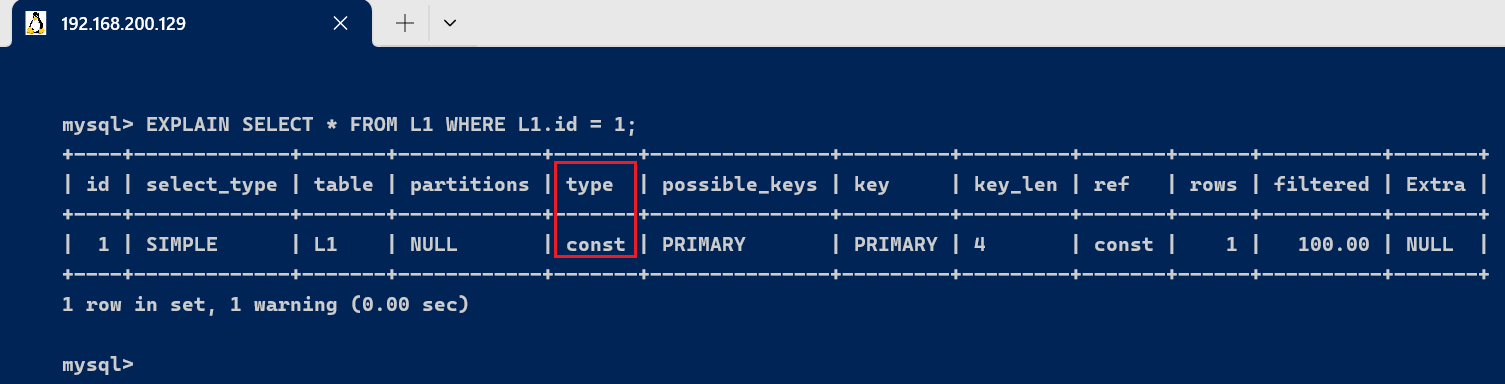
- const : 表示通过索引 一次就找到了, const用于比较 primary key 或者 unique 索引. 因为只匹配一行数据,所以如果将主键 放在 where条件中, MySQL就能将该查询转换为一个常量
EXPLAIN SELECT * FROM L1 WHERE L1.id = 1;
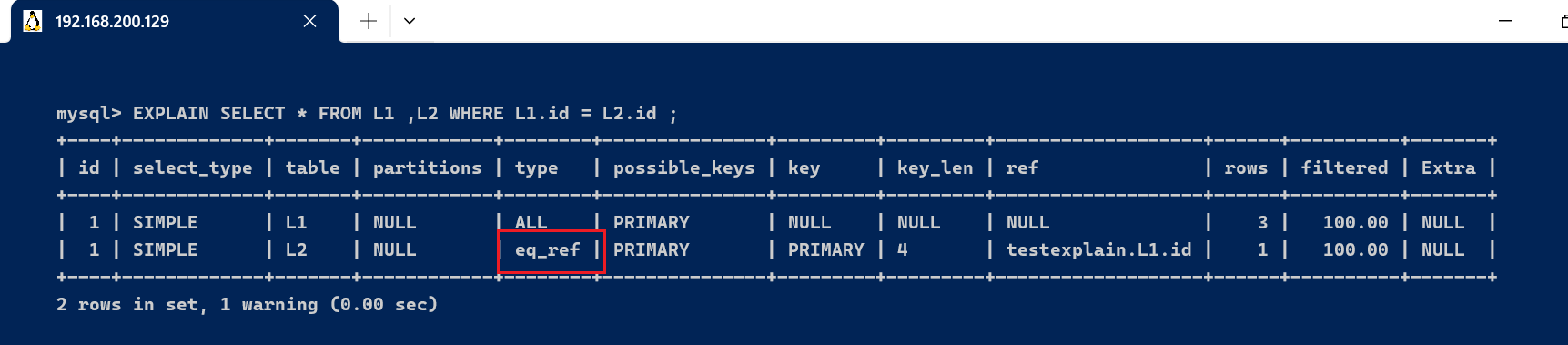
- eq_ref : 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配. 常见与主键或唯一索引扫描
EXPLAIN SELECT * FROM L1 ,L2 WHERE L1.id = L2.id ;
-
ref : 非唯一性索引扫描, 返回匹配某个单独值的所有行, 本质上也是一种索引访问, 它返回所有匹配某个单独值的行, 这是比较常见连接类型.
-
未加索引之前
EXPLAIN SELECT * FROM L1 ,L2 WHERE L1.title = L2.title ;
-
加索引之后
CREATE INDEX idx_title ON L2(title);EXPLAIN SELECT * FROM L1 ,L2 WHERE L1.title = L2.title ;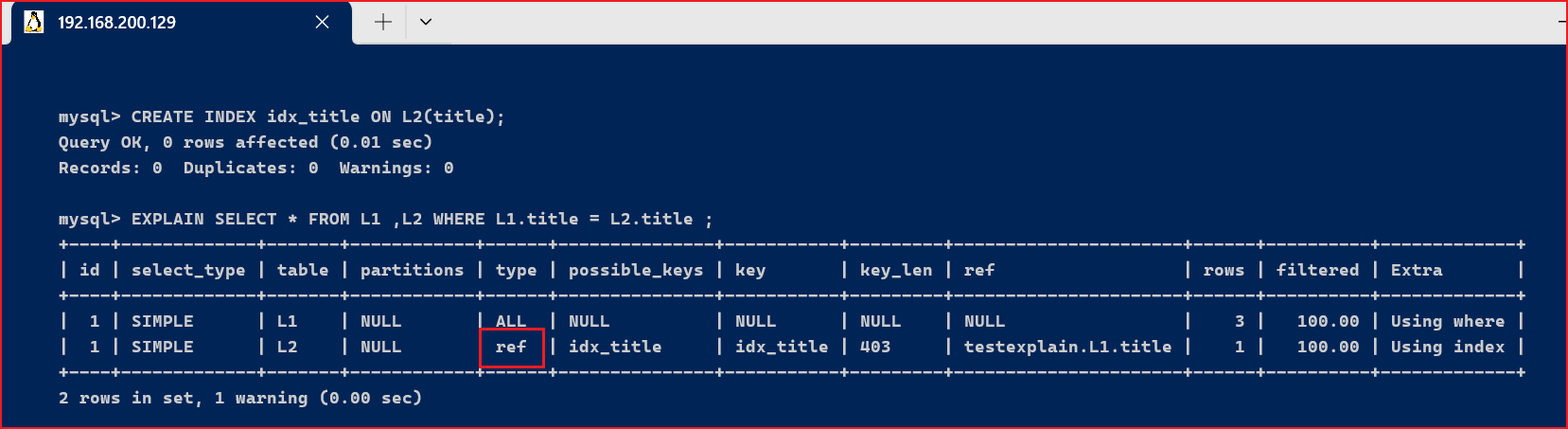
-
-
range : 只检索给定范围的行,使用一个索引来选择行。
EXPLAIN SELECT * FROM L1 WHERE L1.id > 10;EXPLAIN SELECT * FROM L1 WHERE L1.id IN (1,2);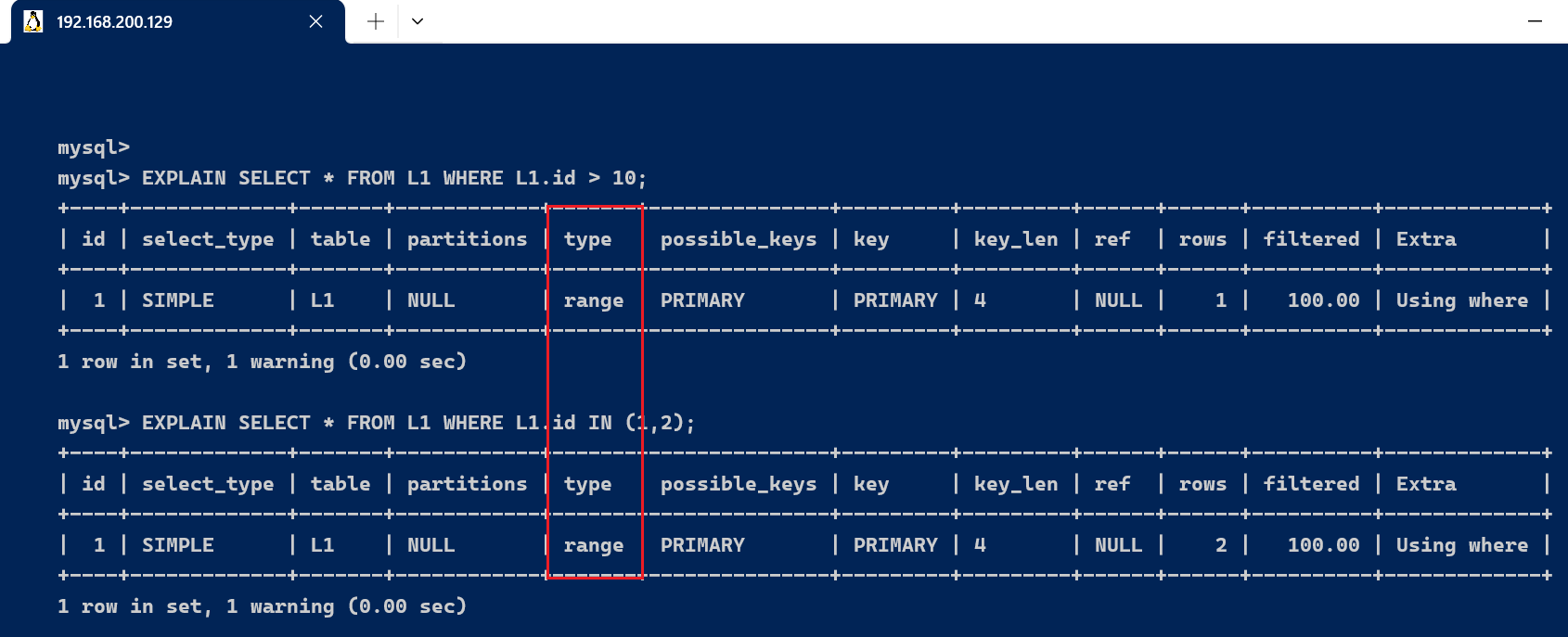
key显示使用了哪个索引. where 子句后面 使用 between 、< 、> 、in 等查询, 这种范围查询要比全表扫描好
-
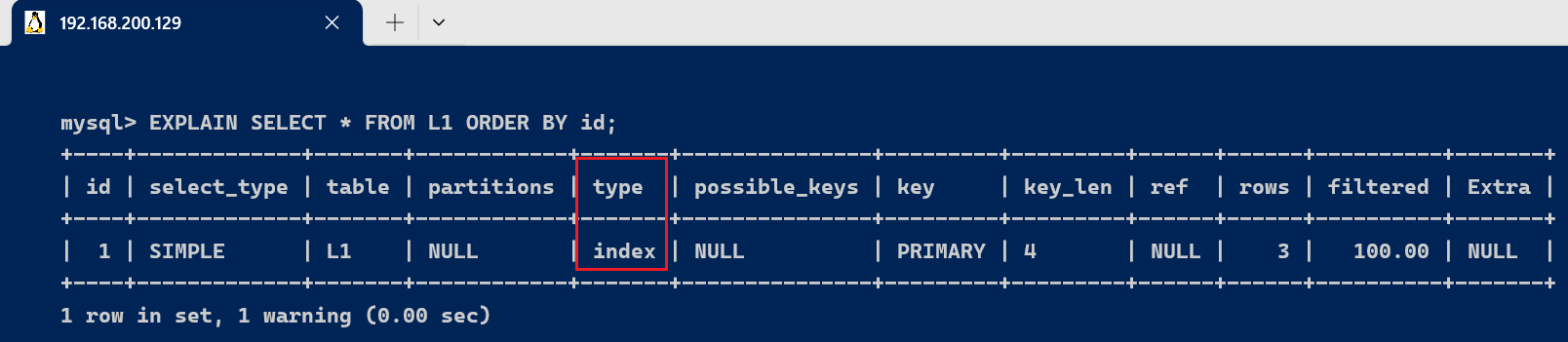
index : 出现index 是 SQL 使用了索引, 但是没有通过索引进行过滤,一般是使用了索引进行排序分组
EXPLAIN SELECT * FROM L1 ORDER BY id;
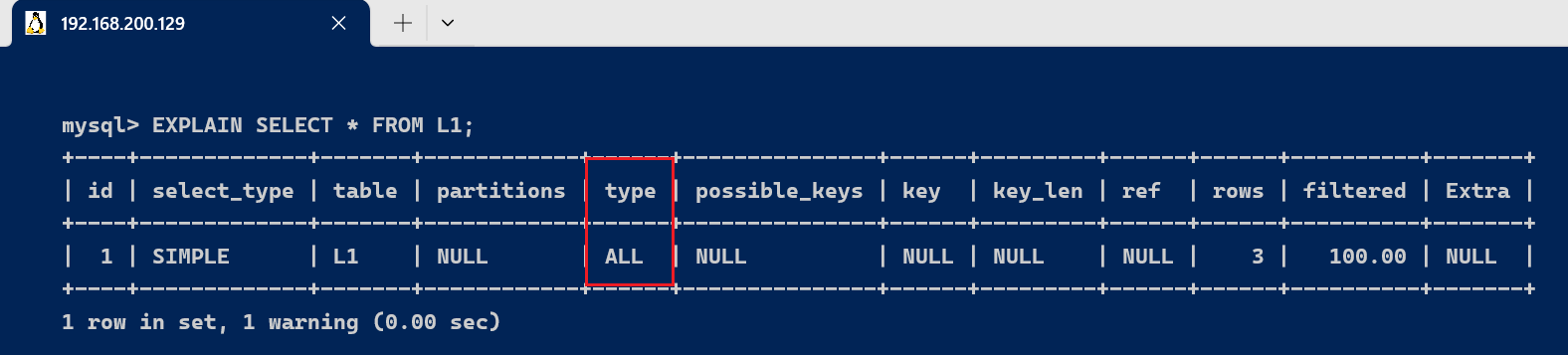
- ALL : 对于每个来自于先前的表的行组合,进行完整的表扫描。
EXPLAIN SELECT * FROM L1;
一般来说,需要保证查询至少达到 range级别,最好能到ref
3.5、possible_keys 与 key字段
- possible_keys
- 显示可能应用到这张表上的索引, 一个或者多个. 查询涉及到的字段上若存在索引, 则该索引将被列出, 但不一定被查询实际使用.
- 实际使用的索引,若为null,则没有使用到索引。(两种可能,1.没建立索引, 2.建立索引,但索引失效)。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
- key
- 实际使用的索引,若为null,则没有使用到索引。(两种可能,1.没建立索引, 2.建立索引,但索引失效)。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
- 覆盖索引:一个索引包含(或覆盖)所有需要查询的字段的值,通过查询索引就可以获取到字段值
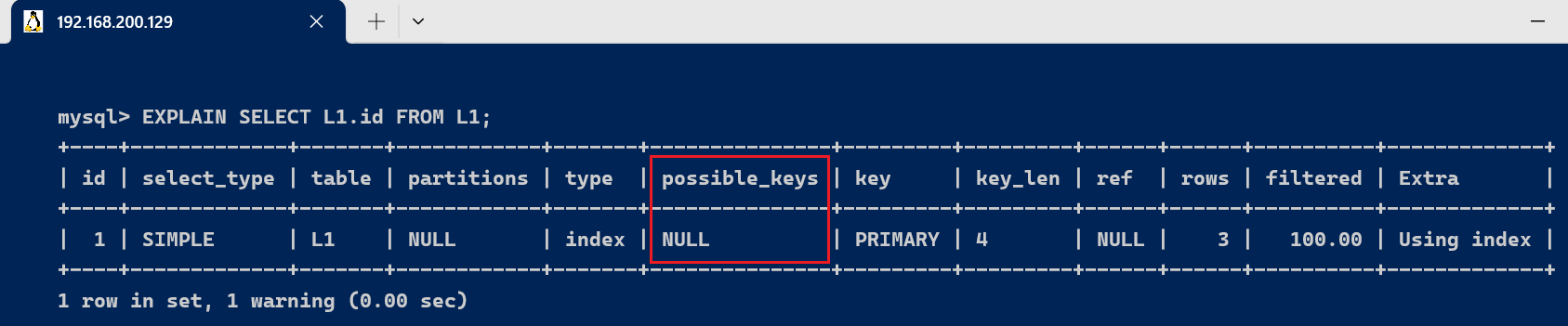
- 理论上没有使用索引,但实际上使用了
EXPLAIN SELECT L1.id FROM L1;
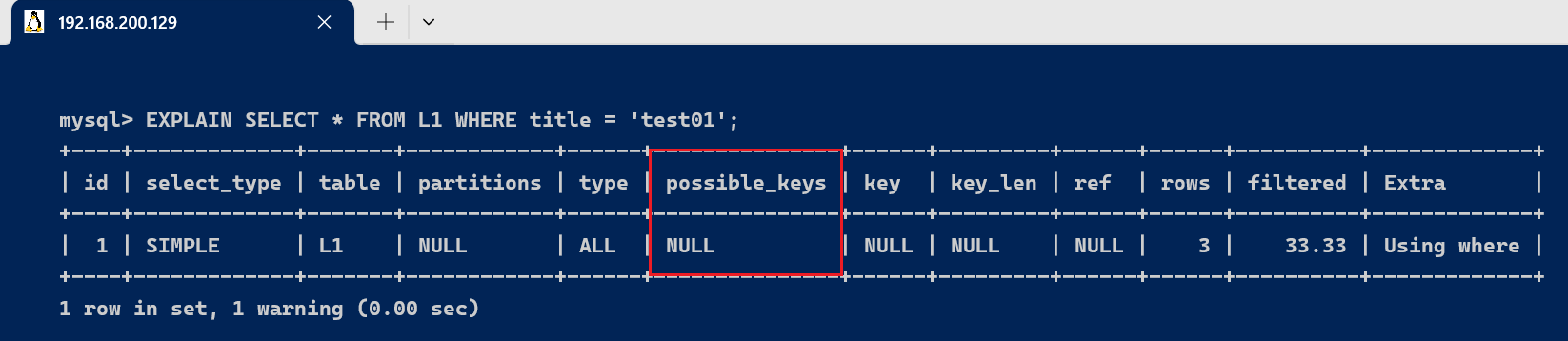
- 理论和实际上都没有使用索引
EXPLAIN SELECT * FROM L1 WHERE title = 'test01';
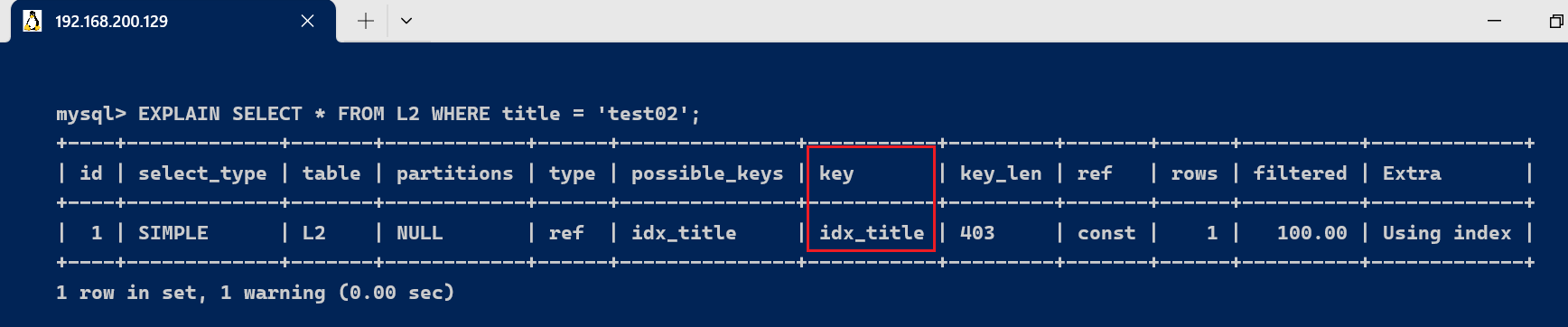
- 理论和实际上都使用了索引
EXPLAIN SELECT * FROM L2 WHERE title = 'test02';
3.6、key_len字段
表示索引中使用的字节数, 可以通过该列计算查询中使用索引的长度.
key_len 字段能够帮你检查是否充分利用了索引 ken_len 越长, 说明索引使用的越充分
key_len表示使用的索引长度,key_len可以衡量索引的好坏,key_len越小 索引效果越好
上述的这两句话是否存在矛盾呢,我们该怎么理解呢?
第一句:
key_len越长,说明索引使用得越充分解释:
key_len表示在查询中使用的索引字节数。它反映了查询条件中实际使用了索引的多少。例如,假设有一个复合索引(例如
index_a_b_c),它包含三个字段a, b, c。如果你执行的查询只使用了a字段进行筛选,那么key_len可能只包含字段a的长度。如果查询使用了a和b两个字段进行筛选,key_len会增加,以反映更多的索引字段被使用。因此,当
key_len较长时,意味着查询充分利用了索引的多个部分,这通常可以提高查询效率。第二句:
key_len越小,索引效果越好解释:
这句话强调了索引的选择性和效率。
key_len越小,表示查询使用的索引部分越少,也可能意味着查询的目标更加精准,过滤的行数越少。如果一个查询只需使用索引的前几列(即
key_len较小),并且可以快速过滤掉大部分不相关的行,那么该查询的效率通常会更高。在某些情况下,使用较小的
key_len可能会比使用较大的key_len更有效,因为这减少了不必要的索引扫描(特别是当大部分行都匹配前面的字段时)。如何综合理解这两句话
这两句话并不矛盾,而是从不同的角度解释了
key_len的作用:
充分利用索引:当你希望尽可能利用复合索引的多个字段时,较大的
key_len是有利的,因为它表明查询条件使用了索引的多个部分,从而可能减少全表扫描的需求。索引的效率:另一方面,较小的
key_len可能意味着查询条件已经足够过滤掉大多数不匹配的行,从而更快地找到所需的记录。实际应用中的考量
- 复合索引:如果你的查询经常使用复合索引的前几个字段,而不使用全部字段,那么你可能希望
key_len较小,这样查询效率可能更高,因为数据库引擎不需要扫描索引的所有部分。- 单字段索引:如果你有一个单字段索引,那么
key_len的大小主要取决于这个字段的类型。对于简单的查询,key_len较小可能是好事。总结来说,
key_len并不是越大或越小越好,而是要根据查询的具体情况来衡量。当key_len充分利用了索引的关键字段,并且有效过滤数据时,这通常是一个高效的查询设计。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`id` bigint NOT NULL AUTO_INCREMENT,`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`age` int NULL DEFAULT NULL,`sex` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`create_time` datetime NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_name`(`name` ASC) USING BTREE,INDEX `idx_age`(`age` ASC) USING BTREE,INDEX `idx_sex`(`sex` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;INSERT INTO `user` VALUES (1, 'tom', 18, '男', '2024-08-17 10:09:00');
INSERT INTO `user` VALUES (2, 'zimu', 18, '男', '2024-08-07 10:09:30');
- 使用explain 进行测试
| 列类型 | 是否为空 | 长度 | key_len | 备注 |
|---|---|---|---|---|
| tinyint | 允许Null | 1 | key_len = 1 + 1 | 允许NULL,key_len长度加1 |
| tinyint not null | 不允许Null | 1 | key_len = 1 | 不允许NULL |
| int | 允许Null | 4 | key_len = 4 + 1 | 允许NULL,key_len长度加1 |
| int not null | 不允许Null | 4 | key_len = 4 | 不允许NULL |
| bigint | 允许Null | 8 | key_len = 8 + 1 | 允许NULL,key_len长度加1 |
| bigint not null | 不允许Null | 8 | key_len = 8 | 不允许NULL |
| char(1) | 允许Null | utf8mb4=4, utf8=3, gbk=2 | key_len = 1*3 + 1 | 允许NULL,字符集utf8,key_len长度加1 |
| char(1) not null | 不允许Null | utf8mb4=4, utf8=3, gbk=2 | key_len = 1*3 | 不允许NULL,字符集utf8 |
| varchar(10) | 允许Null | utf8mb4=4, utf8=3, gbk=2 | key_len = 10*3 + 2 + 1 | 动态列类型,key_len长度加2,允许NULL,key_len长度加1 |
| varchar(10) not null | 不允许Null | utf8mb4=4, utf8=3, gbk=2 | key_len = 10*3 + 2 | 动态列类型,key_len长度加2 |
-
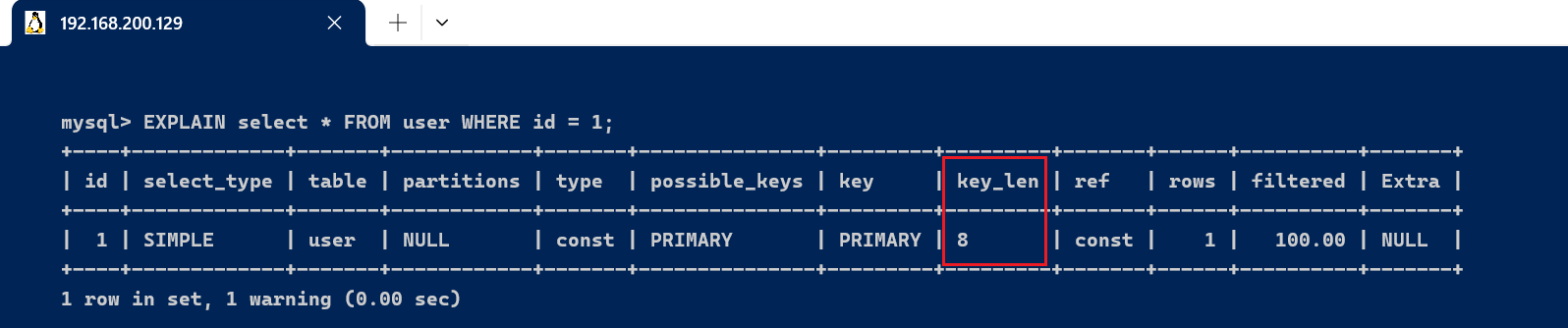
id字段类型为bigint,长度为8,id为主键,不允许Null ,key_len = 8 。
EXPLAIN select * FROM user WHERE id = 1;
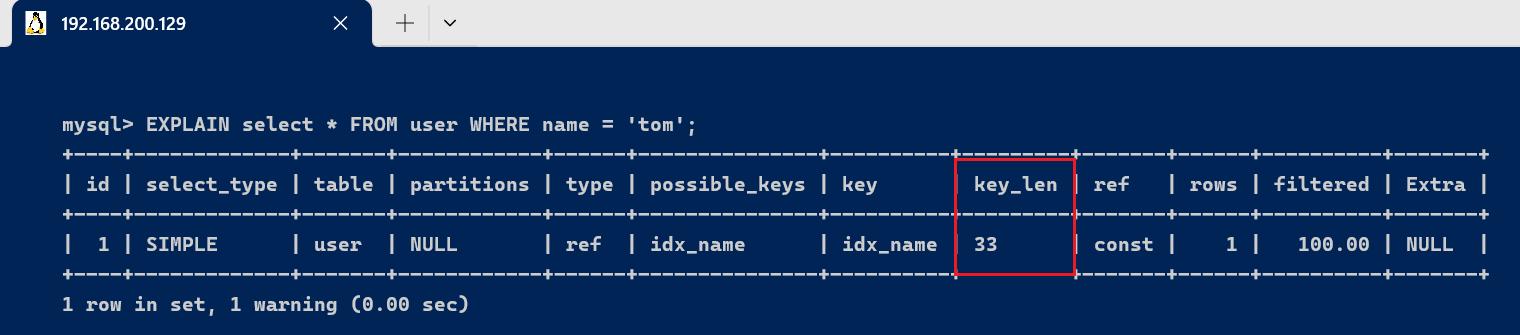
- name的字段类型是varchar(10),允许Null,字符编码是utf8,一个字符占用3个字节,varchar为动态类型,key长度加2,key_len = 10 * 3 + 2 + 1 = 33 。
EXPLAIN select * FROM user WHERE name = 'tom';
联合索引key_len计算
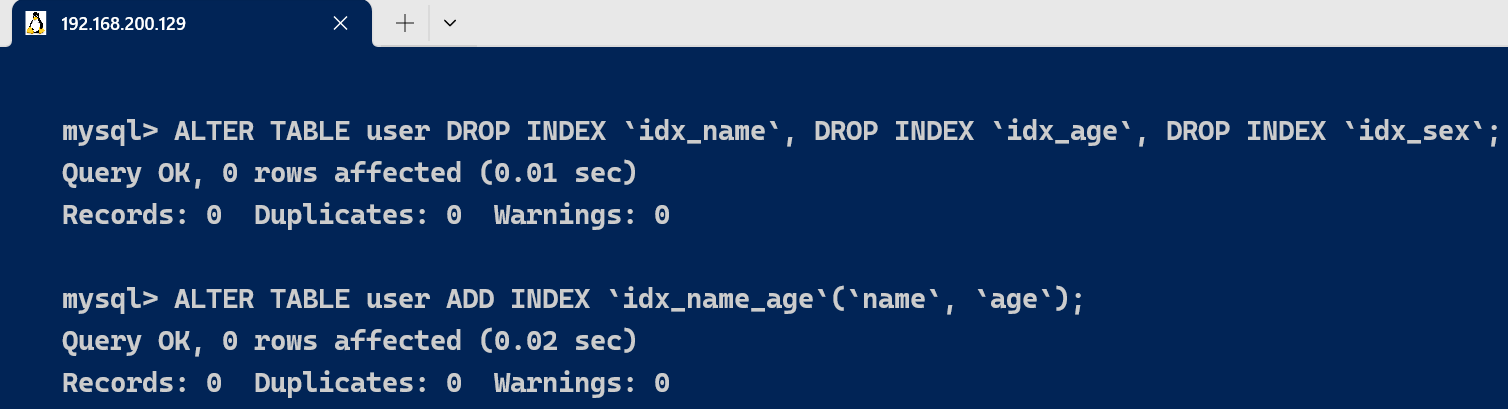
我们删除user表其他辅助索引,建立一个联合索引
ALTER TABLE user DROP INDEX `idx_name`, DROP INDEX `idx_age`, DROP INDEX `idx_sex`;
ALTER TABLE user ADD INDEX `idx_name_age`(`name`, `age`);
1、部分索引生效的情况
我们使用name进行查询
EXPLAIN select * FROM user WHERE name = 'tom';
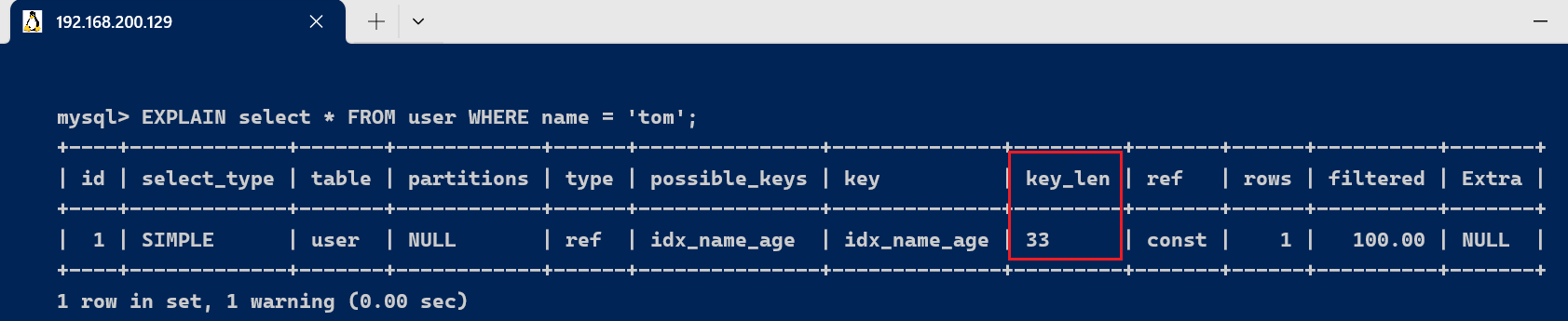
由于联合索引,根据最左匹配原则,使用到索引只有name这一列,name的字段类型是varchar(10),允许Null,字符编码是utf8,一个字符占用3个字节,varchar为动态类型,key长度加2,key_len = 10 * 3+2 + 1 = 33 。
2、联合索引完全使用索引的情况
EXPLAIN select * FROM user WHERE name = '张三' AND age = 19;
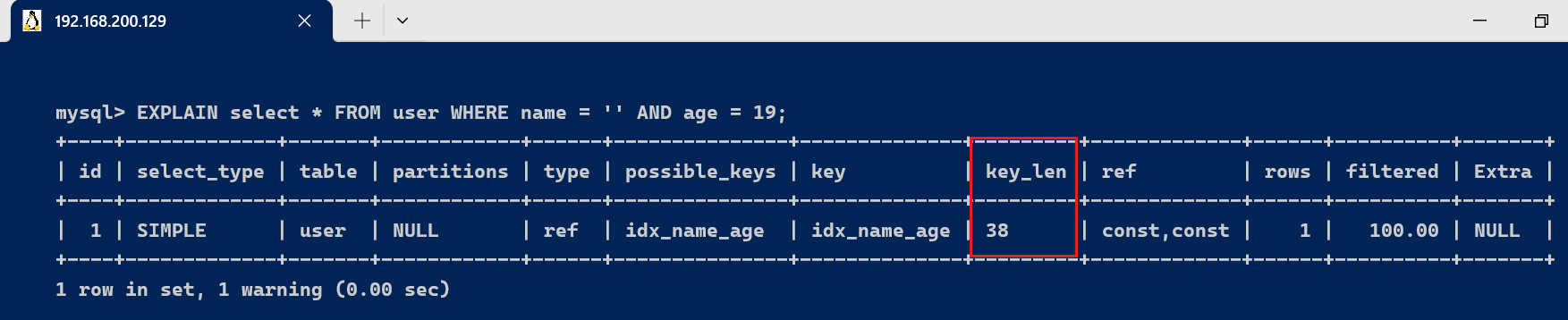
由于联合索引,使用到(name,age)联合索引,name的字段类型是varchar(10),允许Null,字符编码是utf8,一个字符占用3个字节,varchar为动态类型,key长度加2,key_len = 10 * 3 + 2 + 1 = 33 ,age的字段类型是int,长度为4,允许Null ,key_len = 4 + 1 = 5 。联合索引的key_len 为 key_len = 33+5 = 38。
3.7、ref 字段
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
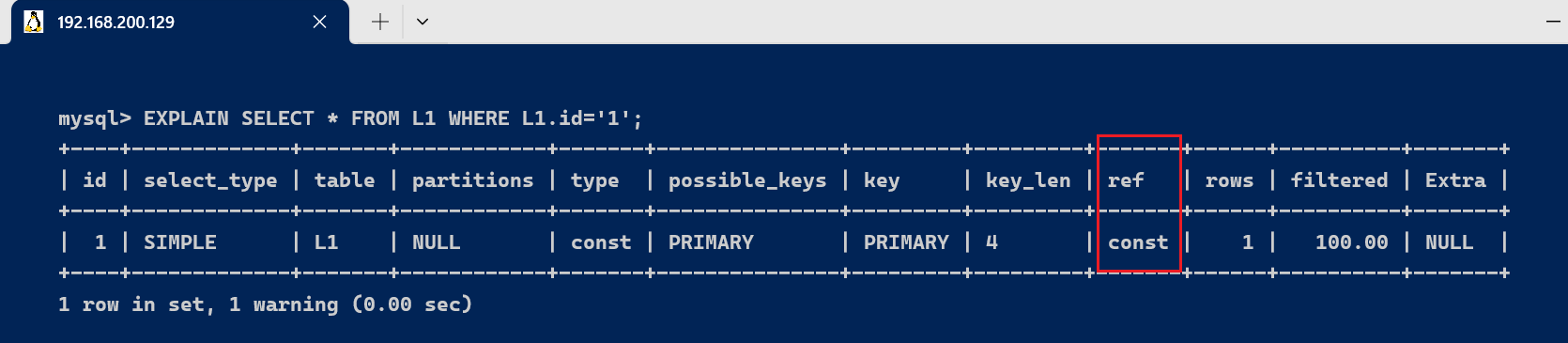
- L1.id=‘1’; 1是常量 , ref = const
EXPLAIN SELECT * FROM L1 WHERE L1.id='1';
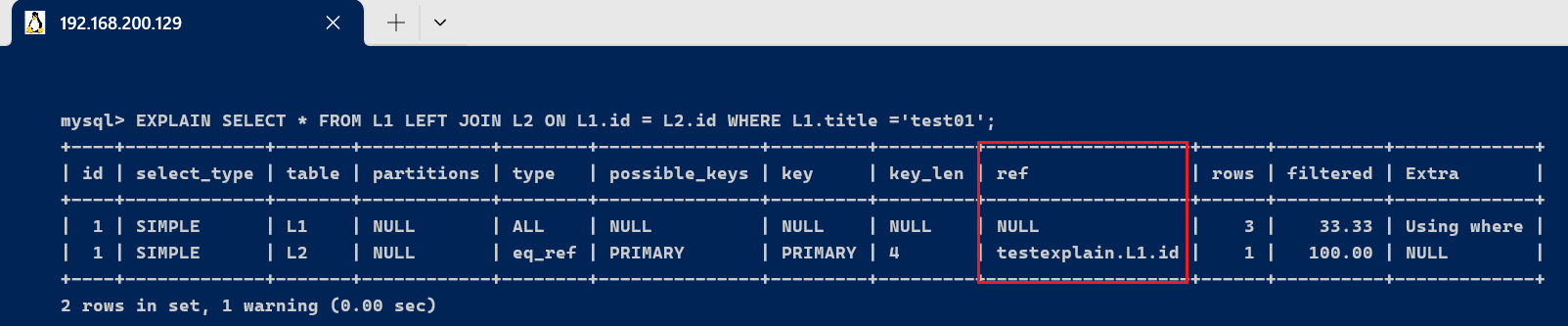
- L2表被关联查询的时候,使用了主键索引, 而值使用的是驱动表(执行计划中靠前的表是驱动表)L1表的ID, 所以 ref = test_explain.L1.id
EXPLAIN SELECT * FROM L1 LEFT JOIN L2 ON L1.id = L2.id WHERE L1.title ='test01';
什么是驱动表 ?
- 多表关联查询时,第一个被处理的表就是驱动表,使用驱动表去关联其他表.
- 驱动表的确定非常的关键,会直接影响多表关联的顺序,也决定后续关联查询的性能
驱动表的选择要遵循一个规则:
在对最终的结果集没有影响的前提下,优先选择结果集最小的那张表作为驱动表
3.8、rows 字段
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数;越少越好
- 使用like 查询,会产生全表扫描, L2中有3条记录,就需要读取3条记录进行查找
EXPLAIN SELECT * FROM L1,L2 WHERE L1.id = L2.id AND L2.title LIKE '%tes%';
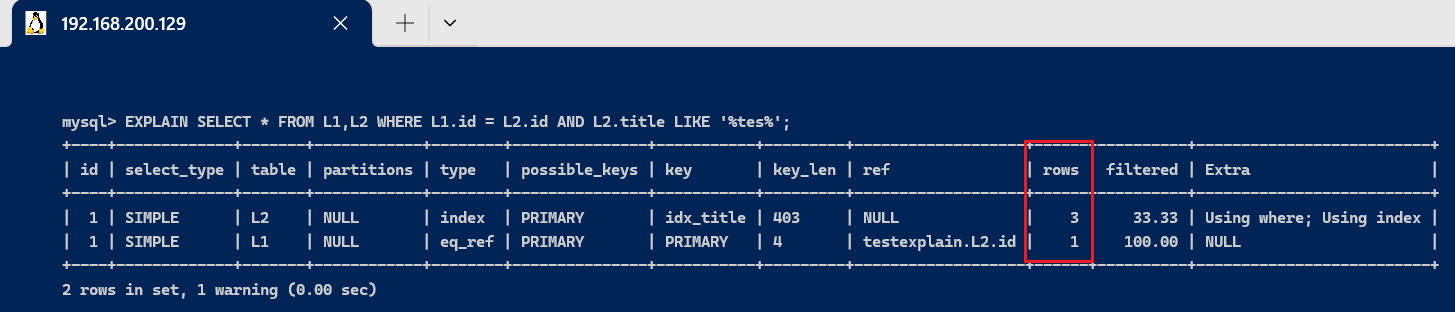
- 如果使用等值查询, 则可以直接找到要查询的记录,返回即可,所以只需要读取一条
EXPLAIN SELECT * FROM L1,L2 WHERE L1.id = L2.id AND L2.title = 'test03';
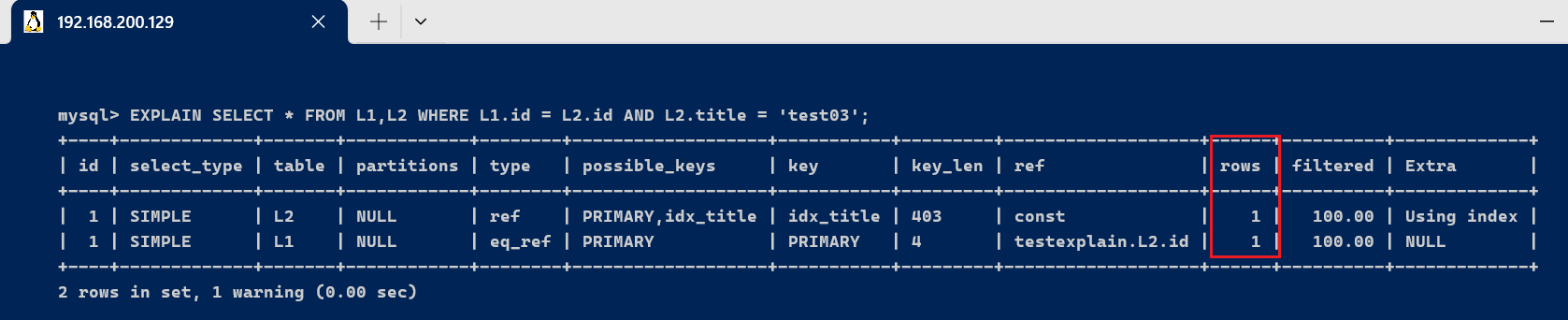
总结: 当我们需要优化一个SQL语句的时候,我们需要知道该SQL的执行计划,比如是全表扫描,还是索引扫描; 使用explain 关键字可以模拟优化器执行sql 语句,从而知道mysql 是如何处理sql 语句的,方便我们开发人员有针对性的对SQL进行优化.
-
表的读取顺序。(对应id)
-
数据读取操作的操作类型。(对应select_type)
-
哪些索引可以使用。(对应possible_keys)
-
哪些索引被实际使用。(对应key)
-
每张表有多少行被优化器查询。(对应rows)
-
评估sql的质量与效率 (对应type)
3.9、filtered 字段
它指返回结果的行占需要读到的行(rows列的值)的百分比
3.9、extra 字段
Extra 是 EXPLAIN 输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息
CREATE TABLE users (
uid INT PRIMARY KEY AUTO_INCREMENT,
uname VARCHAR(20),
age INT(11)
);
INSERT INTO users VALUES(NULL, 'lisa',10);
INSERT INTO users VALUES(NULL, 'lisa',10);
INSERT INTO users VALUES(NULL, 'rose',11);
INSERT INTO users VALUES(NULL, 'jack', 12);
INSERT INTO users VALUES(NULL, 'sam', 13);
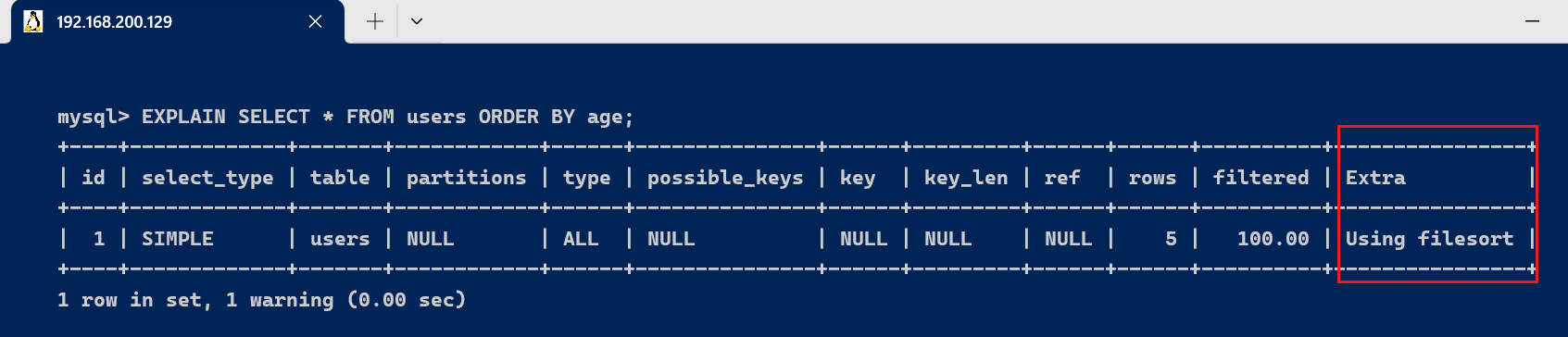
- Using filesort
EXPLAIN SELECT * FROM users ORDER BY age;
执行结果Extra为Using filesort ,这说明,得到所需结果集,需要对所有记录进行文件排序。这类SQL语句性能极差,需要进行优化。
典型的,在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
filtered 它指返回结果的行占需要读到的行(rows列的值)的百分比
- Using temporary
EXPLAIN SELECT COUNT(*),uname FROM users WHERE uid > 2 GROUP BY uname;

执行结果Extra为Using temporary ,这说明需要建立临时表 (temporary table) 来暂存中间结果。性能消耗大, 需要创建一张临时表, 常见于group by语句中. 需配合SQL执行过程来解释, 如果group by和where索引条件不同, 那么group by中的字段需要创建临时表分组后再回到原查询表中.如果查询条件where和group by是相同索引字段, 那么就不需要临时表.
- Using where
EXPLAIN SELECT * FROM users WHERE age=10;
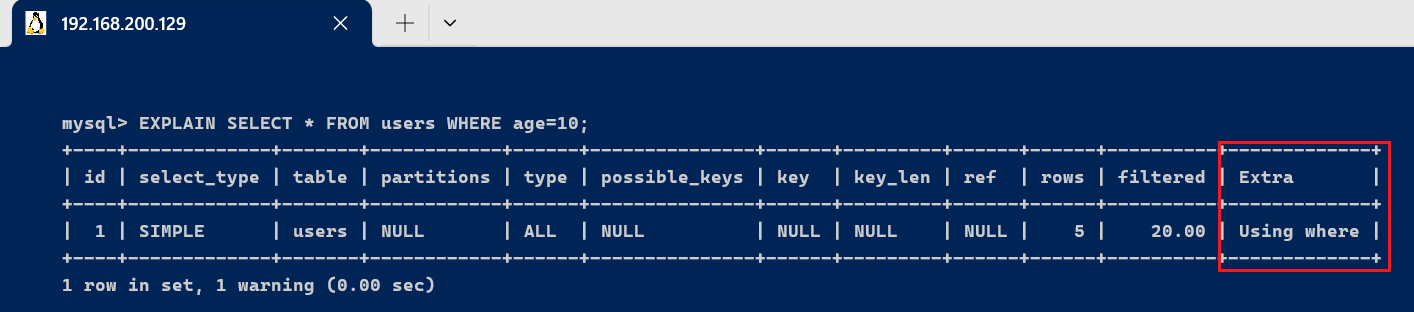
此语句的执行结果Extra为Using where,表示使用了where条件过滤数据。需要注意的是:
- 返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,对于这类SQL往往需要进行优化;
- 使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断。例如本例查询的 age 未设置索引,所以返回的type为ALL,仍有优化空间,可以建立索引优化查询。
- Using index
表示直接访问索引就能够获取到所需要的数据(覆盖索引) , 不需要通过索引回表.
-- 为uname创建索引
alter table users add index idx_uname(uname);
EXPLAIN SELECT uid,uname FROM users WHERE uname='lisa';
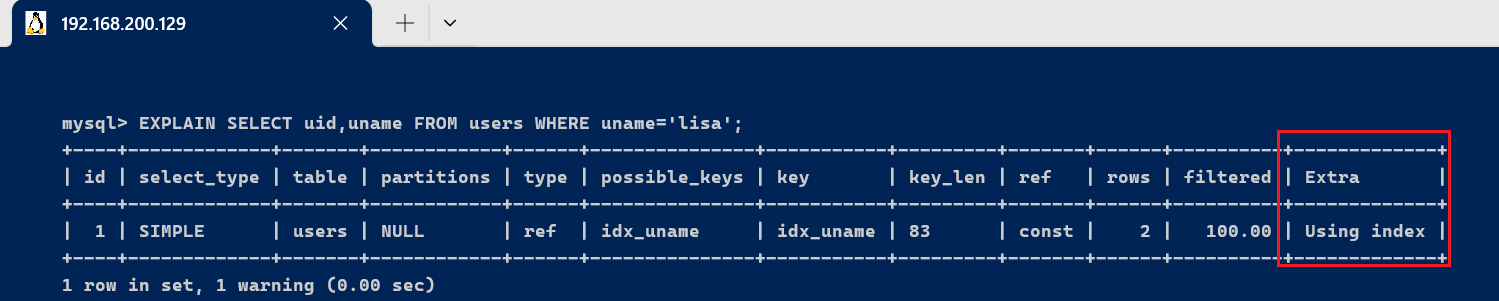
此句执行结果为Extra为Using index,说明sql所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。
- Using join buffer (Block Nested Loop):
- 这个
Extra字段的值表明 MySQL 在执行嵌套循环连接时使用了连接缓冲区。这通常发生在没有可用的合适索引时,MySQL 会将一个表的数据加载到内存中的缓冲区,然后逐一扫描另一个表,以找到满足连接条件的行。 - Block Nested Loop 是指 MySQL 会将外部表(在本例中是
u1)的部分数据块加载到缓冲区,然后与内部表(在本例中是子查询派生表u2)进行匹配。这样可以减少对磁盘的访问次数,提高查询效率。
- 这个
需要进行嵌套循环计算.
ALTER TABLE users ADD COLUMN sex CHAR(1);
UPDATE users SET sex = '0' WHERE uname IN ('lisa', 'rose');
UPDATE users SET sex = '1' WHERE uname IN ('jack', 'sam');
EXPLAIN SELECT *
FROM users u1
LEFT JOIN (SELECT * FROM users WHERE sex = '0') u2
ON u1.uname = u2.uname;

没有显示 Using join buffer,可能是因为查询优化器在这个具体的场景下能够有效地使用索引,因此不需要使用连接缓冲区。在这种情况下,MySQL 直接使用了 ref 类型的连接(通过索引进行连接),而不是需要缓冲区的嵌套循环连接。
可以删除或修改表上的索引,以便让 MySQL 在执行查询时无法使用现有的索引,从而被迫使用连接缓冲区。
ALTER TABLE users DROP INDEX idx_uname;
EXPLAIN SELECT *
FROM users u1
LEFT JOIN (SELECT * FROM users WHERE sex = '0') u2
ON u1.uname = u2.uname;
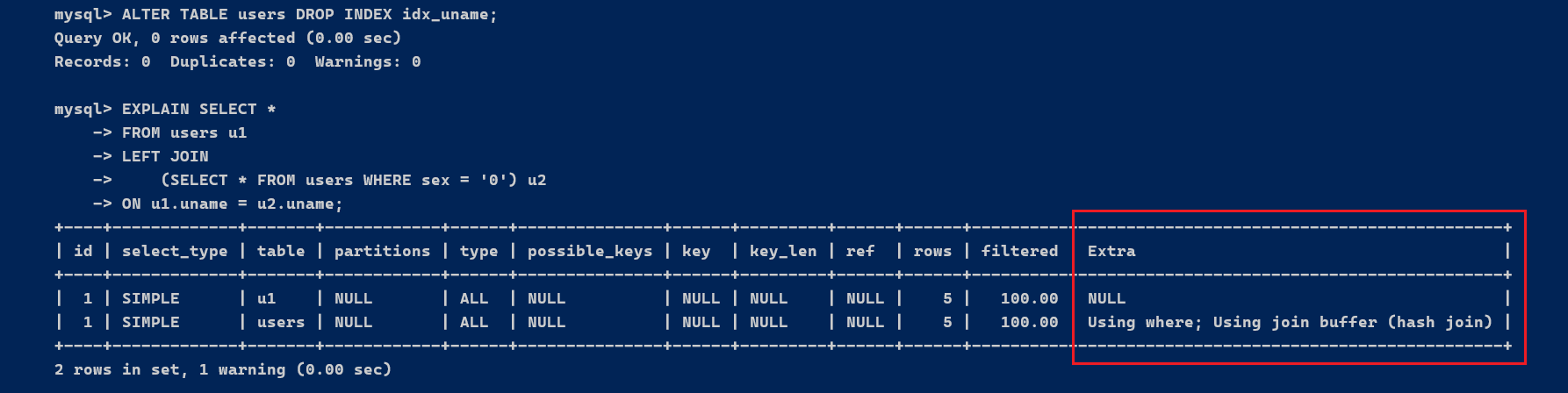
执行结果Extra为Using join buffer (Block Nested Loop) 说明,需要进行嵌套循环计算, 这里每个表都有五条记录,内外表查询的type都为ALL。
问题在于 两个关联表join 使用 uname,关联字段均未建立索引,就会出现这种情况。
常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
- Using index condition
搜索条件中虽然出现了索引列,但是有部分条件无法使用索引,会根据能用索引的条件先搜索一遍再匹配无法使用索引的条件。
Using index condition 叫作 Index Condition Pushdown Optimization (索引下推优化)。Index Condition Pushdown (ICP)是MySQL使用索引从表中检索行的一种优化。如果没有ICP,存储引擎将遍历索引以定位表中的行,并将它们返回给MySQL服务器,服务器将判断行的WHERE条件。在启用ICP的情况下,如果可以只使用索引中的列来计算WHERE条件的一部分,MySQL服务器就会将WHERE条件的这一部分推到存储引擎中。然后,存储引擎通过使用索引条目来评估推入的索引条件,只有当满足该条件时,才从表中读取行。ICP可以减少存储引擎必须访问基表的次数和MySQL服务器必须访问存储引擎的次数。
CREATE TABLE employees (id INT PRIMARY KEY AUTO_INCREMENT,first_name VARCHAR(50),last_name VARCHAR(50),age INT,department_id INT,salary DECIMAL(10, 2),hire_date DATE
);INSERT INTO employees (first_name, last_name, age, department_id, salary, hire_date) VALUES
('John', 'Doe', 30, 1, 60000.00, '2015-03-01'),
('Jane', 'Doe', 28, 2, 65000.00, '2016-07-15'),
('Mike', 'Smith', 45, 3, 75000.00, '2010-10-22'),
('Sara', 'Jones', 32, 1, 55000.00, '2018-01-12'),
('Tom', 'Brown', 29, 2, 58000.00, '2017-05-18');
接着,我们在 last_name 和 age 字段上创建复合索引:
CREATE INDEX idx_lastname_age ON employees(last_name, age);
编写一个查询,包含部分能利用索引的条件和部分不能利用索引的条件:
EXPLAIN SELECT * FROM employees WHERE last_name = 'Doe' AND age > 25 AND salary > 60000;

这一行表明 MySQL 在查询中使用了 Index Condition Pushdown 优化。
在这个例子中,last_name = 'Doe' 和 age > 25 可以利用复合索引 idx_lastname_age,因此 MySQL 使用索引条件下推技术,在存储引擎层面尽量减少访问行数据的次数。
salary > 60000 是不能利用索引的条件,但由于使用了 ICP,存储引擎会先根据 last_name 和 age 进行初步过滤,然后再把符合条件的行返回给 MySQL 服务器,服务器进一步应用 salary > 60000 的过滤。
总结:
Index Condition Pushdown (ICP) 是一种优化技术,允许 MySQL 在存储引擎层面应用部分 WHERE 条件,从而减少需要从表中读取的行数。这可以提高查询性能,尤其是在涉及复合索引时。
Using index condition 提示表示 MySQL 已经应用了 ICP 优化。通过使用复合索引和带有多条件的查询,可以显式地观察到这个优化技术的作用。
https://mp.weixin.qq.com/s?__biz=MzkwOTczNzUxMQ==&mid=2247484180&idx=1&sn=2cfeba47a57b0d27d297de2037928080&chksm=c137685cf640e14abf7215d3a063e199b1d9aabf5e659b5113230bfea3a5a79ec84479545682#rd

相关文章:
MySQL中的EXPLAIN的详解
一、介绍 官网介绍: https://dev.mysql.com/doc/refman/5.7/en/explain-output.htmlhttps://dev.mysql.com/doc/refman/8.0/en/explain-output.htmlexplain(执行计划),使用explain关键字可以模拟优化器执行sql查询语句ÿ…...

LearnOpenGL——SSAO学习笔记
LearnOpenGL——SSAO学习笔记 SSAO一、基本概念二、样本缓冲三、法向半球四、随机核心转动五、SSAO着色器六、环境遮蔽模糊七、应用SSAO遮蔽因子 SSAO 一、基本概念 环境光照是我们加入场景总体光照中的一个固定光照常量,它被用来模拟光的散射(Scattering)。散射应…...

[C语言]-基础知识点梳理-文件管理
前言 各位师傅们好,我是qmx_07,今天给大家讲解文件管理的相关知识,也就是常见的 读取,删除一类的操作 文件 为什么要使用文件? 程序的数据是存储在电脑的内存中,如果程序退出,内存回收&…...
pcdn闲置带宽被动收入必看教程。第五讲:光猫更换和基础设置
PCDN闲置带宽被动收入必看教程 —— 第五讲:光猫更换和基础设置 为了从闲置带宽中获得被动收入,高效的网络设备至关重要。运营商提供的光猫通常能满足日常家用需求,但对于PCDN应用来说,它们可能不足以提供所需的高性能和稳定性。…...

工业数据采集网关简介-天拓四方
随着工业4.0和物联网(IoT)技术的深入发展,工业数据采集网关作为连接现场设备与上层管理系统的关键节点,其在智能工厂中的作用愈发凸显。本文将深入探讨工业数据采集网关的功能、特点、应用场景及其实操性,以期为读者提…...

Java 调整字符串,验证码生成
package text7;public class ZiFanz {public static void main(String[] args) {//1.定义两个字符串String strA "abcde";String strB "deabc";//2.abcde->bcdea->cdeab->deabc旋转字符串//旋转并比较boolean result cheak(strA, strB);System…...

【专题】全球商用服务机器人市场研究(2023)报告合集PDF分享(附原数据表)
原文链接:https://tecdat.cn/?p37366 近年来,随着人工智能、物联网和自动化技术的不断进步,商用服务机器人行业迅速崛起,展现出广阔的发展前景。从最初的实验室研发到如今的规模化应用,商用服务机器人已逐渐成为各行…...

SQL UA注入 (injection 第十八关)
简介 SQL注入(SQL Injection)是一种常见的网络攻击方式,通过向SQL查询中插入恶意的SQL代码,攻击者可以操控数据库,SQL注入是一种代码注入攻击,其中攻击者将恶意的SQL代码插入到应用程序的输入字段中&a…...

初阶数据结构之计数排序
非比较排序 计数排序 计数排序⼜称为鸽巢原理,是对哈希直接定址法的变形应⽤。 操作步骤: 1)统计相同元素出现次数 2)根据统计的结果将序列回收到原来的序列中 #include "CountSort.h" void Count(int* arr, int n)…...

【开端】记一次诡异的接口排查过程
一、绪论 最近碰到这么一个情况,接口请求超时。前提是两台服务器间的网络是畅通的,端口也是通,应用代码也是通。意思是在应用上,接口没有任何报错,能正常返回数据。客户端到服务端接口也能通,但是接收不到服…...

jenkins最佳实践(二):Pipeline流水线部署springCloud微服务项目
各位小伙伴们大家好呀,我是小金,本篇文章我们将介绍如何使用Pipeline流水线部署我们自己的微服务项目,之前没怎么搞过部署相关的,以至于构建流水线的过程中中也遇到了很多自己以前没有考虑过的问题,特写此篇࿰…...

第2章 C语言基础知识
第2章 C语言基础知识 1.printf()函数 在控制台输出数据,需要使用输出函数,C语言常用的输出函数为printf()。 printf()函数为格式化输出函数,其功能是按照用户指定的格式将数据输出到屏幕上。 printf(“格式控制字符串”,[输出列表]); 格式控…...

鹭鹰优化算法SBOA优化RBF神经网络的扩散速度实现多数入多输出数据预测,可以更改数据集(MATLAB代码)
一、鹭鹰优化算法介绍 鹭鹰优化算法(Secretary Bird Optimization Algorithm, SBOA)是一种新型的元启发式算法,它于2024年4月由Youfa Fu等人提出,并发表在SCI人工智能二区顶刊《Artificial Intelligence Review》上。该算法的灵感…...

MySQL基础练习题48-连续出现的数字
目录 题目 准备数据 分析数据 题目 找出所有至少连续出现三次的数字。 准备数据 ## 创建库 create database db; use db;## 创建表 Create table If Not Exists Logs (id int, num int)## 向表中插入数据 Truncate table Logs insert into Logs (id, num) values (1, 1) i…...

webrtc学习笔记2
音视频采集和播放 打开摄像头并将画面显示到页面 1. 初始化button、video控件 2. 绑定“打开摄像头”响应事件onOpenCamera 3. 如果要打开摄像头则点击 “打开摄像头”按钮,以触发onOpenCamera事件的调用 4. 当触发onOpenCamera调用时 a. 设置约束条件,…...

Simple RPC - 06 从零开始设计一个服务端(上)_注册中心的实现
文章目录 Pre核心内容服务端结构概述注册中心的实现1. 注册中心的架构2. 面向接口编程的设计3. 注册中心的接口设计4. SPI机制的应用 小结 Pre Simple RPC - 01 框架原理及总体架构初探 Simple RPC - 02 通用高性能序列化和反序列化设计与实现 Simple RPC - 03 借助Netty实现…...
【深度学习】基于Transformers的大模型推理框架
本文旨在介绍基于transformers的decoder-only语言模型的推理框架。与开源推理框架不同的是: 本框架没有利用额外的开源推理仓库,仅基于huggingface,transformers,pytorch等原生工具进行推理,适合新手学习大模型推理流…...

电脑监控怎样看回放视频?一键解锁电脑监控回放,守护安全不留死角!高效员工电脑监控,回放视频随时查!
你是否曾好奇那些键盘敲击背后的秘密?电脑监控不仅是守护企业安全的隐形盾牌,更是揭秘高效与合规的魔法镜!一键解锁安企神监控回放,就像打开时间宝盒,让过去的工作瞬间跃然眼前。无论是精彩瞬间还是潜在风险࿰…...

【一起学Rust | 框架篇 | Tauri2.0框架】tauri中rust和前端的相互调用(rust调用前端)
文章目录 前言1. rust中调用前端2. 如何向前端发送事件3. 前端监听事件4. 执行js代码 前言 近期Tauri 2.0 rc版本发布,2.0版本迎来第一个稳定版本,同时官方文档也进行了更新。Tauri是一个使用Rust构建的框架,可以让你使用前端技术来构建桌面…...

deque容器
deque容器的基本概念 deque 是 C 标准库中的双端队列(double-ended queue)容器,提供了在两端进行插入和删除操作的功能。 deque与vector区别: vector对于头部的插入删除效率低,数据量越大效率越低。deque相对而言&am…...

AI驱动GitHub仓库分析:从数据到洞察的工程实践
1. 项目概述:一个面向开发者的AI驱动GitHub分析工具最近在GitHub上发现一个挺有意思的项目,叫instagit,来自InstalabsAI这个组织。乍一看名字,可能会联想到Instagram或者某种社交工具,但实际上,它是一个完全…...

FakeLocation:安卓应用级位置模拟终极解决方案
FakeLocation:安卓应用级位置模拟终极解决方案 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在数字时代,位置隐私已成为每个Android用户必须面对的重要问…...

别再傻傻分不清了!数字IC面试必问的Latch与Flip-Flop,我用Verilog代码给你讲明白
数字IC面试突围:Latch与Flip-Flop的Verilog避坑指南 1. 从门电路到时序逻辑:存储单元的本质差异 在数字电路设计中,存储单元如同城市交通的信号灯系统。锁存器(Latch)就像持续亮着的红灯——只要信号有效(电…...

Adafruit Bluefruit LE模块AT命令实战:从BLE透传到Eddystone信标与HID设备开发
1. 项目概述与核心价值如果你正在开发一个需要无线连接功能的物联网设备、可穿戴设备或者创意交互项目,那么蓝牙低功耗(BLE)技术几乎是一个绕不开的选择。它功耗低、连接快,并且被现代智能手机和电脑广泛支持。然而,直…...

Simics在网络转型与SDN迁移中的核心价值与应用
1. Simics在网络转型与SDN迁移中的核心价值解析网络架构正经历从传统硬件设备向软件定义网络(SDN)和网络功能虚拟化(NFV)的深刻变革。这场变革的核心挑战在于:如何在保持网络高性能的同时,实现控制平面与数据平面的解耦,以及如何将传统网络功…...

为什么92%的AIGC剪辑师仍在用手动导出?揭秘Sora 2直连Premiere的7大底层优化与3个避坑红线
更多请点击: https://intelliparadigm.com 第一章:Sora 2与Premiere直连整合的行业悖论与破局起点 当OpenAI正式释放Sora 2的API文档并开放有限开发者预览时,Adobe Premiere Pro团队内部立即启动了“Project Lumen”——一项旨在实现双向帧级…...

LabVIEW触发采集实战:从原理到多通道同步实现
1. 项目概述:为什么我们需要触发采集?在数据采集领域,尤其是自动化测试、设备监控和信号分析等场景,我们常常会遇到一个核心痛点:如何精准地捕捉到我们真正关心的那一段信号?想象一下,你正在监测…...

终极指南:如何在Jetson/Raspberry Pi上快速部署CLIP-as-service边缘AI搜索服务 [特殊字符]
终极指南:如何在Jetson/Raspberry Pi上快速部署CLIP-as-service边缘AI搜索服务 🚀 【免费下载链接】clip-as-service 🏄 Scalable embedding, reasoning, ranking for images and sentences with CLIP 项目地址: https://gitcode.com/gh_mi…...

如何快速上手网易游戏NPK文件解包工具:新手3步完整教程
如何快速上手网易游戏NPK文件解包工具:新手3步完整教程 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否对网易游戏如《阴阳师》、《魔法禁书目录》中的…...

科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏
科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏 一句话导读:今晚更值得看的,不是哪家模型榜单又变了,而是几家平台同时在补 AI 代理真正进生产前最缺的三块能力:跨 IDE 共享状态、团队级可观测&…...