了解 K-Means 聚类的工作原理(详细指南)

一、说明
K-means 的目标是将一组观测值划分为 k 个聚类,每个观测值分配给均值(聚类中心或质心)最接近的聚类,从而充当该聚类的代表。
在本文中,我们将全面介绍 k 均值聚类(最常用的聚类方法之一)及其组成部分的所有内容。我们将了解聚类,为什么它很重要,以及它的应用。
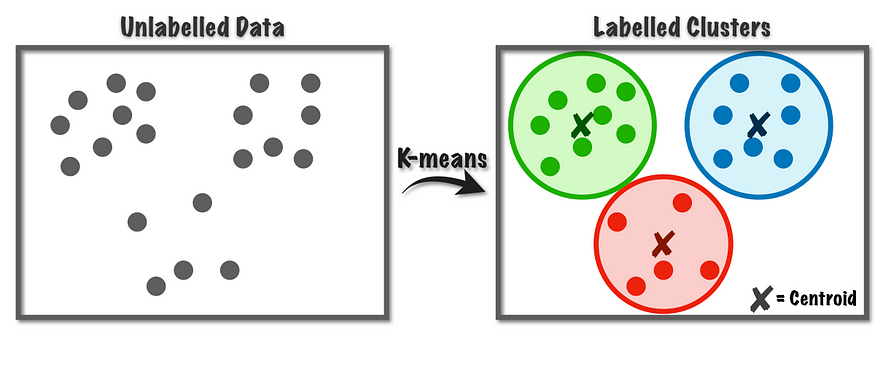
二、什么是 K-means 聚类?
K-Means 聚类是一种流行的无监督机器学习算法,用于将数据集划分为一组不同的、不重叠的组或聚类。目标是以这样一种方式对数据点进行分组,即同一聚类中的点彼此之间比与其他聚类中的点更相似。该技术广泛应用于数据挖掘、市场细分、图像压缩以及其他需要模式识别的领域。
2.1 K-means 中使用的数学概念
在我们开始计算 k 均值之前,我们将讨论 K 均值中使用的数学概念。
- 质心:这些是聚类的中心点,在每次迭代中都会重新计算,以作为分配给聚类的点的平均值。
- 欧几里得距离:这是 K-Means 中最常用的距离度量。它计算欧几里得空间中两点之间的直线距离。
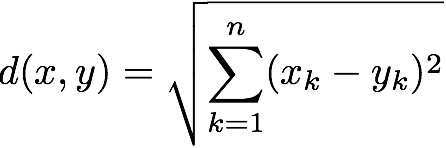
对于 n 维的 X(x1,x2,...,xn) 和 Y(y1,y2,...,yn) 2 个点,使用此公式测量欧几里得距离。
- 惯性:它衡量集群的分布程度。它是每个数据点与其分配的质心之间的平方距离之和。目标是将惯性降至最低。
WCSS = d1² + d2²+ d3² + ...........+ dn²
2.2 K-means是如何工作的?
# Generating Data
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# Parameters
n_samples = 300
n_features = 2
centers = 4# Generate data
X, y = make_blobs(n_samples=n_samples, n_features=n_features, centers=centers, cluster_std=3, random_state=42)# Visualize the data
plt.scatter(X[:, 0], X[:, 1], s=50, cmap='viridis')
plt.title("Initial Data")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
from sklearn.cluster import KMeanskmeans = KMeans(n_init = 10, n_clusters = 4, verbose=100)
kmeans.fit(X)y_kmeans = kmeans.predict(X)plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 60, c = 'red', label = 'Cluster1')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 60, c = 'blue', label = 'Cluster2')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 60, c = 'green', label = 'Cluster3')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 60, c = 'yellow', label = 'Cluster4')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 100, c = 'black', label = 'Centroids')plt.legend()plt.show()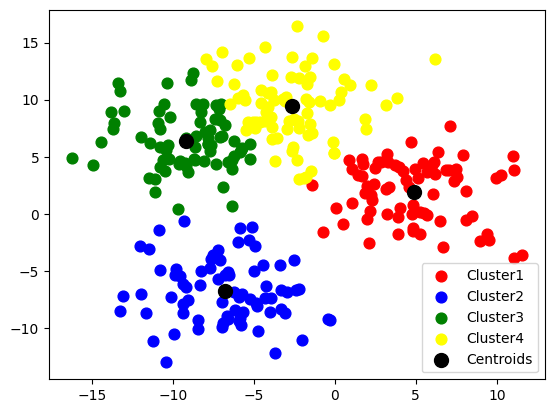
- 初始化:
- 选择簇数 K。
- 随机初始化 K 个质心,它们是数据集中表示每个聚类中心的点。
2. 分配步骤:
- 根据欧几里得距离将每个数据点分配给最近的质心。这将创建 K 个聚类。
我们计算一个点到每个质心的欧几里得距离,并将其放入距离最小的聚类中。
3. 更新步骤:
- 通过取分配给每个聚类的所有数据点的平均值来计算新的质心。
我们计算聚类中所有点的平均值,以获得新的质心。

4.重复:
- 使用新的质心重复分配和更新步骤,直到质心不再更改或更改低于预定义的阈值。

生成上述图像的代码在此处。
三、如何确定质心的数量?
3.1 弯头法
肘部方法是一种用于确定 K-Means 聚类中最佳聚类数的技术。这个想法是对 K 的值范围运行 K-Means,并计算从每个点到其分配的质心的距离平方和(称为惯性或簇内平方和)。随着 K 的增加,惯性减小,因为点更接近它们的质心。
目标是找到“肘点”,其中下降速度急剧减慢,表明随着 K 的增加,回报递减,即在肘点之后增加 K 的值没有多大好处。
WCSS = d1² + d2² + d3² + ...........+ dn²
我们通常计算前 10 个聚类的惯性。对于 K = 数据点数,惯性将为零。
from sklearn.cluster import KMeanswcss = []
for i in range(1, 11):kmeans = KMeans(n_init = 10, n_clusters = i)kmeans.fit(X)wcss.append(kmeans.inertia_)plt.title("Elbow Method")
plt.xlabel("Number of Clusters(k)")
plt.ylabel("WCSS")
plt.plot(range(1,11),wcss)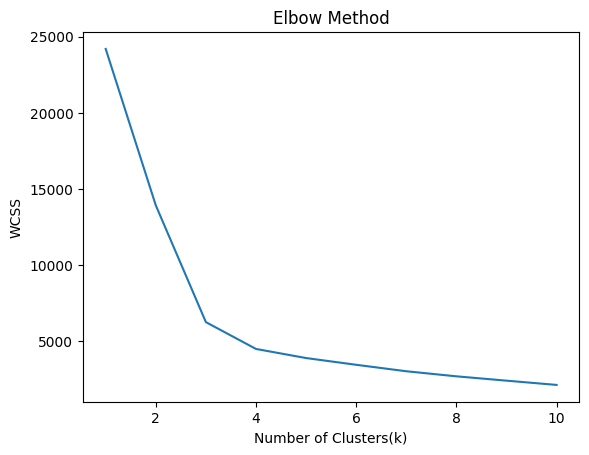
因此,集群的数量可以是 3 个或 4 个。
肘部方法有一些限制,例如:
- 肘点的选择是主观的。
- 它不适用于所有数据集,例如当聚类具有不规则形状或大量特征时。
3.2 剪影分数
Silhouette 分数是一个指标,用于量化集群的质量。它适用于任何聚类算法。
剪影分数的值从 -1 到 +1 不等。
- +1 : 良好(集群分离良好)
- 0 : 集群彼此靠近
- -1 : 错误(错误的聚类)
内聚力: 同一聚类中元素彼此接近的程度。(它衡量集群的紧凑性。
分离: 它指的是不同的集群彼此之间有多么不同或分辨得多么好。
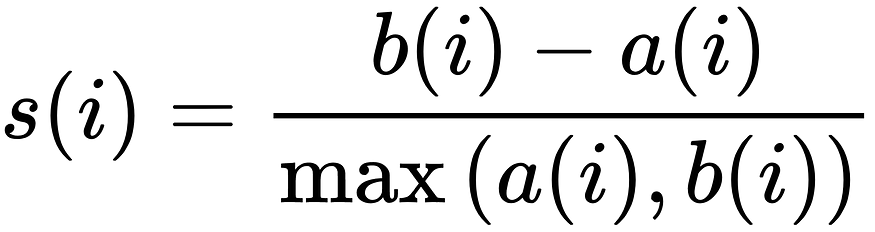
S(i) 是剪影分数。
a(i) 是所取点与其自身聚类中所有点的平均距离。它代表着凝聚力。
b(i) 是所取点与剩余最近聚类的所有点之间的平均聚类距离。它代表分离。

from sklearn.metrics import silhouette_score
sil = []
for i in range(2, 11):kmeans = KMeans(n_clusters=i)cluster_labels = kmeans.fit_predict(X)silhouette_avg = silhouette_score(X, cluster_labels)sil.append(silhouette_avg)plt.xlabel("Number of Clusters(k)")
plt.ylabel("Silhouette Score")
plt.plot(range(2,11),sil)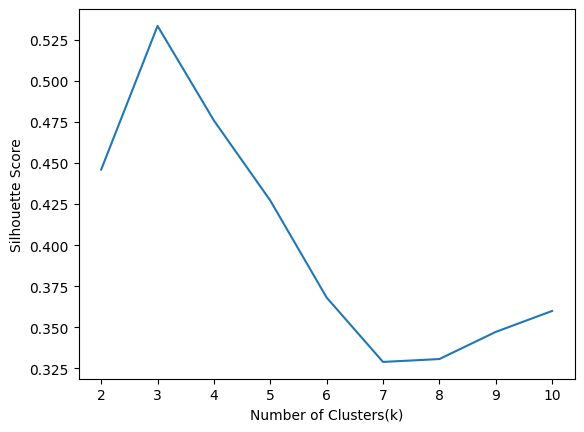
根据轮廓分数,我们应该假设 k=3,因为对于 3 个聚类,分数是最大的。
四、如何初始化质心?
4.1 K-均值++
K-Means++ 是 K-Means 聚类算法的高级版本,它改进了质心的初始选择,旨在提高聚类结果和收敛速度。标准的 K-Means 算法对质心的初始放置很敏感,初始化不良会导致聚类次优和收敛速度变慢。K-Means++ 通过使用更智能的初始化策略来解决这个问题。
4.2 K-Means++ 初始化的步骤
1. 选择第一个质心:
• 从数据集中随机选择第一个质心。
2. 选择后续质心:
• 对于每个后续质心,计算从每个
数据点 x 到最近的已选质心的距离 D(x)。
• 从数据点中选择下一个质心,其概率与 D(x)² 成正比。概率最大的点作为质心。(我们采用概率而不是距离本身来减少异常值的影响。
3. 重复:
• 重复该过程,直到选择 K 个质心。
4. 继续使用标准 K-Means:
• 使用这些 K 质心作为初始起点,并运行标准 K-Means 算法


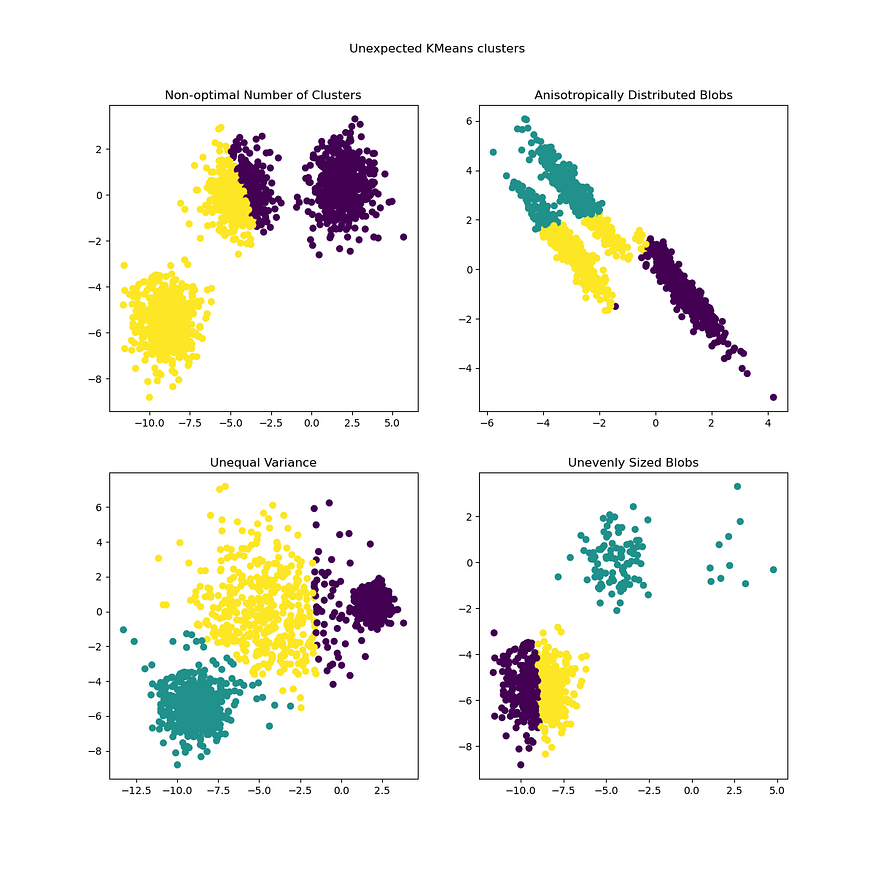
五、K-means的假设和局限性
- 假设簇是球形和各向同性(不是不规则形状)。
- 假定聚类具有相似的大小。
- 假设所有聚类都具有相似的方差。
- 集群的数量是预定义的。
- 当聚类分离良好时,此算法效果最佳。
- K 均值不能在存在异常值的情况下应用(因为质心会移动太多并且无法正确分配)
六、结论
K-Means 简单性和效率使其成为各种应用的热门选择,包括图像分割、市场分割和模式识别。尽管它很简单,但它为各个领域的许多应用程序提供了坚实的基础。但是,它对质心的初始放置很敏感,这可能导致次优聚类。尽管存在一些局限性,例如对 K 选择的敏感性以及卡在局部最小值中的可能性,但 K-Means 仍然是数据分析和机器学习中一种基本且高效的聚类技术。
K-Means 有其局限性,其他聚类算法(如 DBSCAN 和 GMM)可以克服这些局限性。
相关文章:
了解 K-Means 聚类的工作原理(详细指南)
一、说明 K-means 的目标是将一组观测值划分为 k 个聚类,每个观测值分配给均值(聚类中心或质心)最接近的聚类,从而充当该聚类的代表。 在本文中,我们将全面介绍 k 均值聚类(最常用的聚类方法之一࿰…...

预警先行,弯道哨兵让行车更安全
预警先行,弯道哨兵让行车更安全”这句话深刻体现了现代交通安全理念中预防为主、科技赋能的重要性。在道路交通中,尤其是复杂多变的弯道区域,交通事故的发生率往往较高,因此,采取有效的预警措施和引入先进的交通辅助设…...

预约咨询小程序搭建开发,uniapp前端,PHP语言开发
目录 前言: 一、预约小程序搭建功能介绍 二、示例代码片段 前言: 预约咨询小程序适合需付费咨询和交流的场景:比如讲师,摄影,婚庆,美发,律师,心理等等支持商家入驻支持视频、图文、线下、电话等方式在线支付咨询。 一、预约小程…...

极速文件预览!轻松部署 kkFileView 于 Docker 中!
大家好,这几天闲的难受,决定给自己找点事做。博主的项目中有个文件预览的小需求,原有方案是想将文件转换成 PDF 进行预览。本着能借鉴就绝对不自己写的原则。今天就让我们简单试用一下 kkFileView 文件预览服务,一起探索它的强大功…...

某验九宫格分类识别
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 如有侵犯,请联系作者下架 九宫格分类如下 这种就是最简单的分类识别了,用迁移学习resnet训练即可,下面来看成品 训练代码查看往期文章中就有,部分代码如下: DEVICE = torch.device(…...

未来展望:观测云技术的发展与企业业务的融合
随着技术的不断进步,观测云作为企业数据监控和分析的关键工具,其发展与企业业务的融合趋势显得尤为重要。在未来,观测云技术将如何演进,以及它将如何更深层次地与企业业务相融合,是值得我们深入探讨的问题。 首先&…...

day6JS-DOM(文档对象模型)
DOM树 DOM 操作 1. 获取元素 1.1 根据id名获取元素 document.getElementById("id名"); 案例: <body><div id"box">div盒子</div><h1>一级标题</h1><script>console.log(document.getElementById(&quo…...

MySQL列表分区分区表
什么是列表分区分区表? 列表分区是一种根据某个列的离散值将表数据分割成多个分区的分区方式。在列表分区中,每个分区都有自己的离散值集合,当插入数据时,MySQL会根据指定的列值将数据分配到相应的分区中。这种分区方式可以使得表…...

qt打包程序方法(非常好用)
1.下载 Index of /official_releases/qt-installer-framework/4.6.1 bi...

IP地址管理:优化网络布局与提升效率
在日益复杂的网络环境中,IP地址管理成为了网络管理员日常工作中不可或缺的一部分。有效的IP地址管理不仅能够优化网络布局,提升网络运行效率,还能确保网络安全和稳定性。本文将探讨IP地址管理的重要性、实施策略以及最佳实践。 一、IP地址管…...

老古董Lisp实用主义入门教程(5):好奇先生用Lisp探索Lisp
鲁莽先生什么都不管 鲁莽先生打开电脑,安装一堆东西,噼里啪啦敲了一堆代码,叽里呱啦说了一堆话,然后累了就回家睡觉了。 这可把好奇先生的兴趣勾起来,他怎么也睡不着。好奇先生打开电脑,看了看鲁莽先生留…...

linux文件——用户缓冲区——概念深度理解、IO模拟实现
前言:本篇文章主要讲解文件缓冲区。 讲解的方式是通过抛出问题, 然后通过分析问题, 将缓冲区的概念与原理一步一步地讲解。同时, 本节内容在最后一部分还会带友友们模拟实现一下c语言的printf, fprintf接口,…...

Selenium模拟鼠标滚动页面:实现自动化测试中的页面交互
Selenium模拟鼠标滚动页面:实现自动化测试中的页面交互 在进行网页自动化测试时,经常需要模拟用户的滚动行为来加载更多内容或触发页面上的某些交互。Selenium WebDriver提供了强大的工具来模拟这些用户行为,包括鼠标滚动。本文将介绍如何使…...

Eureka原理与实践:构建高效的微服务架构
Eureka原理与实践:构建高效的微服务架构 Eureka的核心原理Eureka Server:服务注册中心Eureka Client:服务提供者与服务消费者 Eureka的实践应用集成Eureka到Spring Cloud项目中创建Eureka Server创建Eureka Client(服务提供者&…...

OpenJDK 和 OracleJDK 的区别、下载方式
OpenJDK 和 OracleJDK 都是 Java 开发套件 (JDK),用于开发和运行 Java 应用程序。它们之间的主要区别如下: 许可证和使用限制: OpenJDK:由 OpenJDK 社区开发和维护,基于 GPL v2 with Classpath Exception 许可证&#…...

arthas源码刨析:arthas-core (2)
文章目录 attach JVMagent**ArthasBootstrap** arthas-core的启动可以从上一篇做参考 参考 pom,即启动是调用的 Arthas 的 main 方法 attach JVM JVM提供了 Java Attach 功能,能够让客户端与目标JVM进行通讯从而获取JVM运行时的数据,甚至可以…...

【分享】格力手机色界G0245D 刷REC、root、 救砖、第三方rom教程和资源
开门见山 帮别人弄了一台 格力G0245D,把找到的资源和教程分享一下 教程 这个写的很详细了格力手机色界G0245D-Root-最简指南 不过教程里刷rec这一步漏了加上电源键,加上就行了。 附加参考:格力手机2刷机 格力手机二代刷机 GREE G0215D刷机…...

开学必备清单来啦!大学好物合集推荐!每一个都能帮你提升幸福感
随着开学季的到来,好多学生都在忙着准备各类学习与生活必需品,以迎接新的大学生活到来。以下是一些开学季必备的好物推荐,每一个都很实用,可以帮你提升学习和生活的幸福感! 1、西圣电容笔 一句话推荐:公认…...
已解决:javax.xml.transform.TransformerFactoryConfigurationError 异常的正确解决方法,亲测有效!!!
1. 问题描述 javax.xml.transform.TransformerFactoryConfigurationError 是在使用 Java 的 XML 处理库时,配置 TransformerFactory 出错时抛出的异常。通常,这个异常发生在应用程序试图创建一个 TransformerFactory 实例时,由于无法找到合适…...

商品价格与优惠信息在API返回值中的位置
在API返回值中,商品价格与优惠信息的具体位置可能因不同的电商平台和API设计而有所不同。然而,一般来说,这些信息会以结构化的方式呈现,通常包含在一个包含多个字段的JSON对象或XML文档中。以下是根据多个电商平台(如阿…...

MogFace模型Python入门实战:调用API完成第一个人脸检测程序
MogFace模型Python入门实战:调用API完成第一个人脸检测程序 你是不是也对AI人脸检测感到好奇,想亲手写个程序试试?今天,我们就来一起动手,用Python写一个最简单的程序,调用MogFace模型来检测图片里的人脸。…...

STM32红外遥控器设计与多协议控制实现
基于STM32的万能红外遥控器设计与实现1. 项目概述1.1 系统架构本设计采用STM32F103RCT6作为主控芯片,构建了一个多功能红外遥控系统。系统架构包含以下核心模块:主控模块:STM32F103RCT6微控制器人机交互模块:1.44寸LCD显示屏 4x4…...

人形机器人强化学习实战:从奖励设计到PPO算法优化
1. 人形机器人强化学习入门:为什么奖励设计是关键 第一次接触人形机器人强化学习时,我被一个简单问题困扰了很久:为什么同样的算法,换个任务就要重新调参?后来发现问题的核心在于奖励函数设计。就像教小孩学走路&#…...

【具身智能实战】从零部署LeRobot-ALOHA:仿真环境搭建、机械臂标定与GPU高效训练避坑指南
1. 环境准备与基础配置 第一次接触LeRobot-ALOHA项目时,最头疼的就是环境配置。这个开源项目依赖的库版本非常新,和很多现有环境存在兼容性问题。我花了三天时间反复折腾,总结出一套稳定可靠的配置方案。 首先需要准备Ubuntu 20.04或22.04系统…...

基于Go + gin+gorm+ rag+千问大模型 + pgvector 构建市场监管智能问答智能体
基于Go 千问大模型 pgvector构建市场监管智能问答智能体 一、项目背景 随着"放管服"改革的深入推进,市场监管领域政策法规不断更新,企业和公众对政策咨询的需求日益增长。传统的政策咨询模式存在响应慢、效率低、准确性差等问题,…...

如何高效获取网页媒体资源:猫抓插件的全方位技术指南
如何高效获取网页媒体资源:猫抓插件的全方位技术指南 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆炸的时代,我们每天都会遇到想要保存的视频、音频和图片资源。…...

轻量NAS整合:OpenClaw+nanobot自动同步群晖文件的配置方法
轻量NAS整合:OpenClawnanobot自动同步群晖文件的配置方法 1. 为什么需要自动化文件管理 作为一个长期使用群晖NAS的用户,我经常遇到这样的困扰:下载文件夹里堆满了各种文件,手动分类整理耗时耗力;重要文档的版本管理…...

如何从零开始掌握Metasploitable3?安全测试入门到实践指南
如何从零开始掌握Metasploitable3?安全测试入门到实践指南 【免费下载链接】metasploitable3 Metasploitable3 is a VM that is built from the ground up with a large amount of security vulnerabilities. 项目地址: https://gitcode.com/gh_mirrors/me/metasp…...
验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商()
**发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商(
发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务 在Web3.0时代,用户不再依赖中心化的身份提供商(如Google、微信登录),而是通过去中心化身份(Decentralized Identity, DID&…...

SPIRAN ART SUMMONER对比评测:与传统图像生成算法的效果差异
SPIRAN ART SUMMONER对比评测:与传统图像生成算法的效果差异 本文通过实际测试对比,展示SPIRAN ART SUMMONER与传统图像生成算法在效果、速度、易用性等方面的真实差异,用数据和案例说话。 1. 评测背景与方法 图像生成技术近年来发展迅猛&am…...