Python 全栈系列266 Kafka服务的Docker搭建
说明
在大量数据处理任务下的缓存与分发
这个算是来自顾同学的助攻+1,我有点java绝缘体的体质,碰到和java相关的安装部署总会碰到点奇怪的问题,不过现在已经搞定了。测试也接近了kafka官方标称的性能。考虑到网络、消息的大小等因素,可以简单认为kafka的速度是10万/秒级的。
本次文章的目的是:
- 1 搭建一个平时工作中常用的队列服务
- 2 方便自己或者其他同事再次搭建
内容
1 搭建过程
共要搭建两个服务:zookeeper和kafka。
1.1 创建zookeeper
这个是基础服务,必须要最先启动
docker run -d --name zookeeper -e \
ZOOKEEPER_CLIENT_PORT=2181 -e \
ZOOKEEPER_TICK_TIME=2000 -p 2181:2181 \
registry.cn-hangzhou.aliyuncs.com/andy08008/zookeeper0718:v100
通常来说,这个服务启动后就不用管了,但是偶尔如果需要debug的时候:
docker exec -it zookeeper bash
bin/zkCli.sh -server 127.0.0.1:2181
ls /brokers/ids
1.2 创建持久化路径
这个会实际保存kafka的消息
mkdir -p /data/kafka-logs
1.3 创建kafka
一种场景是只监听外网IP(WAN_IP),另一种场景是同时监听内外网(LAN_IP)。
只监听外网的比较简单
WAN_IP=111
LAN_IP=222
docker run -it --rm --name kafka \-p 24666:24666 \--link zookeeper:zk \-e HOST_IP=localhost \-e KAFKA_BROKER_ID=1 \-e KAFKA_ZOOKEEPER_CONNECT=zk:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://${WAN_IP}:24666 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:24666 \-e KAFKA_LOG_DIRS=/data/kafka-logs \-v /data/kafka-logs:/data/kafka-logs \registry.cn-hangzhou.aliyuncs.com/andy08008/kafka0718:v100同时监听内外网的比较麻烦(且要求端口不同)
WAN_IP=111
LAN_IP=222
docker run -d --name kafka \-p 24666:24666 \-p 9092:9092 \--link zookeeper:zk \-e HOST_IP=localhost \-e KAFKA_BROKER_ID=1 \-e KAFKA_ZOOKEEPER_CONNECT=zk:2181 \-e KAFKA_ADVERTISED_LISTENERS=INTERNAL://${LAN_IP}:9092,EXTERNAL://${WAN_IP}:24666 \-e KAFKA_LISTENERS=INTERNAL://0.0.0.0:9092,EXTERNAL://0.0.0.0:24666 \-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT \-e KAFKA_LISTENER_NAME=INTERNAL \-e KAFKA_LISTENER_NAME=EXTERNAL \-e KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL \-e KAFKA_LOG_DIRS=/data/kafka-logs \-v /data/kafka-logs:/data/kafka-logs \registry.cn-hangzhou.aliyuncs.com/andy08008/kafka0718:v100
配置解释
KAFKA_LISTENERS:
-
INTERNAL://0.0.0.0:9092 用于所有网络接口监听。
-
EXTERNAL://0.0.0.0:24666 用于所有网络接口监听。
-
KAFKA_ADVERTISED_LISTENERS:
-
INTERNAL://IP:9092 用于内网客户端。
-
EXTERNAL://IP:24666 用于外网客户端。
-
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:
-
INTERNAL:PLAINTEXT 和 EXTERNAL:PLAINTEXT 映射了每个监听器名称和协议类型。
注释
• docker run -d --name kafka:启动一个名为 kafka 的容器,并在后台运行。
• -p 9092:9092:将主机的 9092 端口映射到容器的 9092 端口,这是 Kafka 的默认端口。
• --link zookeeper:zk:将名为 zookeeper 的容器链接到当前容器,并在当前容器中以 zk 作为别名进行访问。
• -e HOST_IP=localhost:设置环境变量 HOST_IP 为 localhost。
• -e KAFKA_BROKER_ID=1:设置 Kafka 的 broker ID 为 1。【如果有多个,应该在这里区分】
• -e KAFKA_ZOOKEEPER_CONNECT=zk:2181:指定 Zookeeper 的连接地址。
• -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://xxx:9092:设置 Kafka 的广告监听器地址。【这个是实际上Consumer一定会用的。】
• -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092:设置 Kafka 的监听地址。
• -e KAFKA_LOG_DIRS=/data/kafka-logs:指定 Kafka 日志存储目录。
• -v /data/kafka-logs:/data/kafka-logs:将主机的 /data/kafka-logs 目录挂载到容器的 /data/kafka-logs 目录,以持久化存储 Kafka 日志。
2 测试
2.1 生产者测试
from pydantic import BaseModel, field_validator
import json
import pandas as pd
class KafkaJsonMsgList(BaseModel):json_list : list@propertydef msg_list(self):return pd.Series(self.json_list).apply(json.loads).to_list()from func_timeout import func_set_timeout,FunctionTimedOutimport json
from confluent_kafka import Producer
# @func_set_timeout(60)def send_messages(bootstrap_servers = None, topic= None, messages= None):"""发送消息到 Kafka 主题:param bootstrap_servers: Kafka 服务器地址:param topic: Kafka 主题:param messages: 要发送的消息列表"""# 创建 Producer 实例producer = Producer(**{'bootstrap.servers': bootstrap_servers,'acks': 1 })for msg in messages:try:producer.produce(topic, msg)except BufferError:# 如果队列已满,等待队列空出空间producer.poll(1)# 定期调用poll以确保消息传递producer.poll(0)# 确保所有消息都被发送producer.flush()msg_list = [json.dumps({'id':i ,'value':'aaa','aa':'''this is test'''}) for i in range(3)]
topic = 'my_test6'
# 外网
## bootstrap_servers = 'WAN_IP:24666'
# 内网
bootstrap_servers = 'LAN_IP:9092'send_messages(bootstrap_servers=bootstrap_servers,topic=topic,messages = msg_list)
2.2 消费者测试
from confluent_kafka import Consumer# 如果是非json的,直接拿到就可以了
# @func_set_timeout(60)def consume_messages(config = None, topic = None, max_messages = 3):# Create Consumer instanceconsumer = Consumer(config)# Subscribe to topicconsumer.subscribe([topic])consumed_count = 0res_list = []try:while consumed_count < max_messages:msg = consumer.poll(1.0)if msg is None:print('Empty Q')break else:res_list.append(msg.value().decode('utf-8'))consumed_count += 1if consumed_count >= max_messages:breakexcept KeyboardInterrupt:passfinally:# Leave group and commit final offsetsconsumer.close()return res_list # 外网
config = {
# User-specific properties that you must set
'bootstrap.servers': 'WAN_IP:24666',
'group.id':'group1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': True
}
# 内网
config = {
# User-specific properties that you must set
'bootstrap.servers': 'LAN_IP:9092',
'group.id':'group1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': True
}
topic = 'my_test6'
import time
tick1 = time.time()
max_messages = 100 # 这里设置要消费的消息数量
json_list = consume_messages(config, topic, max_messages)
tick2 = time.time()
kj = KafkaJsonMsgList(json_list = json_list)
msg_list = kj.msg_list
tick3 = time.time()
2.3 性能测试
发送端,1.48秒发送10万条消息,稍微弱了点,不过考虑这个是一台仅仅4核8G且繁忙的机器,那就还好(我默认的方式是需要json序列化的)。
tick1 = time.time()
msg_list_10w = [json.dumps({'id':i ,'value':'aaa','aa':'''this is test'''}) for i in range(100000)]
topic = 'my_test6'
send_messages(bootstrap_servers=bootstrap_servers,topic=topic,messages = msg_list_10w)
tick2 = time.time()
print('takes %.2f to send 100000' % (tick2-tick1))
takes 1.48 to send 100000
```接收端
````python
topic = 'my_test6'
import time
tick1 = time.time()
max_messages = 100000 # 这里设置要消费的消息数量
json_list = consume_messages(config, topic, max_messages)
tick2 = time.time()
kj = KafkaJsonMsgList(json_list = json_list)
msg_list = kj.msg_list
tick3 = time.time()
print(tick2-tick1, 'get_time')
print(tick3-tick2, 'parse-time')1.3391587734222412 get_time
0.24841904640197754 parse-time
```总体上还是满意的,可以了。
相关文章:

Python 全栈系列266 Kafka服务的Docker搭建
说明 在大量数据处理任务下的缓存与分发 这个算是来自顾同学的助攻1,我有点java绝缘体的体质,碰到和java相关的安装部署总会碰到点奇怪的问题,不过现在已经搞定了。测试也接近了kafka官方标称的性能。考虑到网络、消息的大小等因素࿰…...

集合框架,List常用API,栈和队列初识
回顾 集合框架 两个重点——ArrayList和HashSet. Vector/ArraysList/LinkedList区别 VectorArraysListLinkedList底层实现数组数组链表线程安全安全不安全不安全增删效率较低较低高扩容*2*1.5-------- (>>)运算级最低,记得加括号。 常…...
构建全景式智慧文旅生态:EasyCVR视频汇聚平台与AR/VR技术的深度融合实践
在科技日新月异的今天,AR(增强现实)和VR(虚拟现实)技术正以前所未有的速度改变着我们的生活方式和工作模式。而EasyCVR视频汇聚平台,作为一款基于云-边-端一体化架构的视频融合AI智能分析平台,可…...

C++结构体声明时初始化
提示:文章 文章目录 前言一、背景二、 2.1 2.2 总结 前言 前期疑问: 本文目标: 一、背景 最近 二、 2.1 c 结构体默认初始化 在C中,结构体的默认成员初始化可以通过构造函数来完成。如果没有为结构体提供构造函数&#x…...

基于微信的热门景点推荐小程序的设计与实现(论文+源码)_kaic
摘 要 近些年来互联网迅速发展人们生活水平也稳步提升,人们也越来越热衷于旅游来提高生活品质。互联网的应用与发展也使得人们获取旅游信息的方法也更加丰富,以前的景点推荐系统现在已经不足以满足用户的要求了,也不能满足不同用户自身的个…...

9、设计模式
设计模式 1、工厂模式 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。工厂模式作为一种创建模式,一般在创建复杂对象时,考虑使用;在创建简单对象时&…...

数学专题.
数论 1.判断质数 定义:在大于1的整数中,如果只包含1和本身这两个约数,就称为质数or素数 Acwing 866.试除法判断质数 2.预处理质数(筛质数) Acwing 868.筛质数 3.质因数分解 Acwing 867.分解质因数 4.阶乘分解 5.因…...
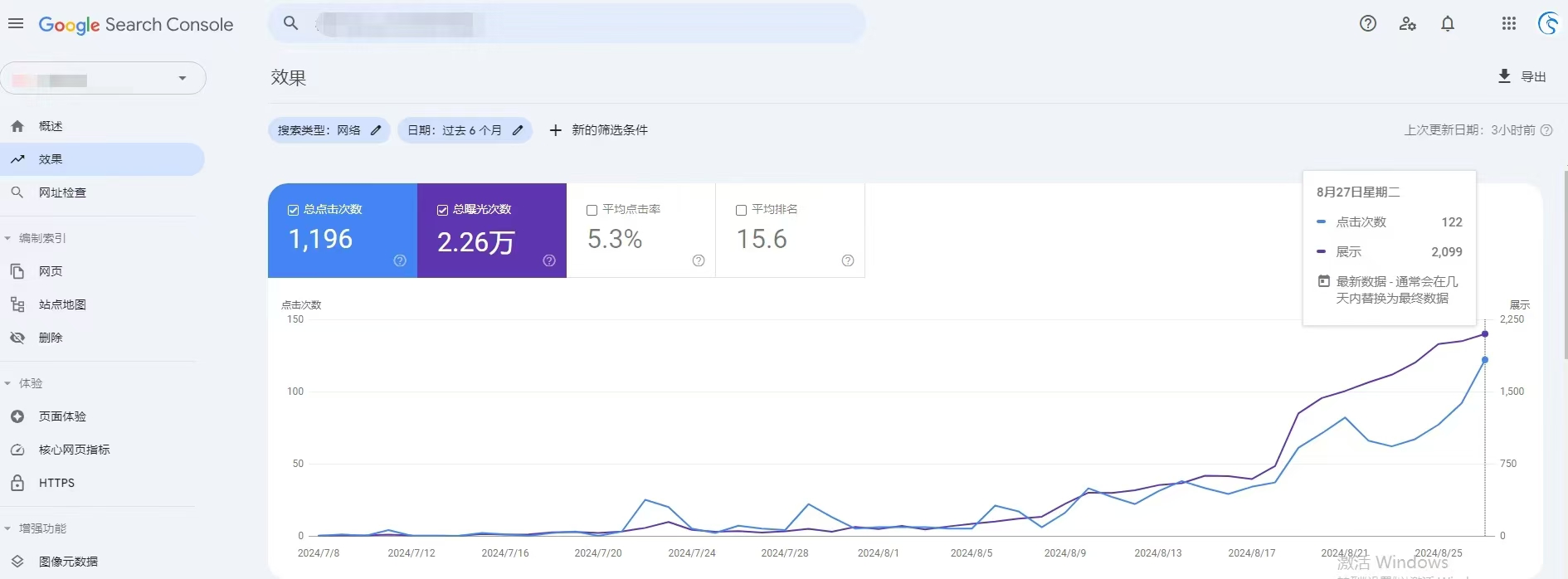
如何提升网站的收录率?
要提升网站的收录率,其中一个特别有效的工具就是GPC爬虫池,这个工具通过深度研究谷歌SEO算法,吸引谷歌爬虫。 GPC爬虫池的基本原理是构建一个庞大的站群系统,并创建复杂的内链和外链结构,以吸引并留住谷歌蜘蛛 使用GP…...

HALCON根据需要创建自定义函数
在HALCON中,根据需要创建自定义函数是扩展其图像处理和分析功能的有效方式。HALCON支持通过其高级编程接口(HDevelop和C/C、C#、Python等)来创建自定义函数。这里将主要讨论在HDevelop环境中如何创建自定义函数,因为HDevelop是HAL…...
)
力扣SQL仅数据库(196~569)
196. 删除重复的电子邮箱 题目:编写解决方案 删除 所有重复的电子邮件,只保留一个具有最小 id 的唯一电子邮件。 (对于 SQL 用户,请注意你应该编写一个 DELETE 语句而不是 SELECT 语句。) (对于 Pandas …...

网络基础:理解IP地址、默认网关与网段(IP地址是什么,默认网关是什么,网段是什么,IP地址、默认网关与网段)
前言 在计算机网络中,IP地址、默认网关和网段(也称为子网)之间有着密切的关系。它们是网络通信中的至关重要的概念,但它们并不相同。这里来介绍一下它们之间的关系,简单记录一下 一. IP地址 1. 介绍 IP 地址…...

windows安装php7.4
windows安装php7.4 1.通过官网下载所需的php版本 首先从PHP官网(https://www.php.net/downloads.php)或者Windows下的PHP官网(http://windows.php.net/download/)下载Windows版本的PHP安装包。下载后解压到一个路径下。 2.配…...

【代码随想录|图论part03之后】
代码随想录|数组 704. 二分查找,27. 移除元素 一、part031、101. 孤岛的总面积1.1 dfs版本1.2 BFS版本2.102. 沉没孤岛3、103. 水流问题4、104.建造最大岛屿二、part041、110. 字符串接龙2、105.有向图的完全可达性3、106. 岛屿的周长三、part05-06 并查集理论1、107. 寻找存在…...

【项目一】基于pytest的自动化测试框架day1
day1不涉及编写代码,只简单梳理接口测试相关的概念。 day1接口测试的本质:功能测试的一部分测试用例的设计与实现接口调试与自动化:从postman到持续集成补充概念 day1 接口测试的本质:功能测试的一部分 接口测试是功能测试的一部…...

如何下载和安装 Notepad++
Notepad 是一款功能强大的开源文本编辑器,广泛用于代码编写和文本编辑。以下是 Notepad 的下载安装教程: 下载 Notepad 访问官方网站 打开你的网络浏览器,访问 Notepad 的官方网站:https://notepad-plus-plus.org/ 选择下载选项…...

笔记:如何使用Process Explorer分析句柄泄露溢出问题
一、目的:如何使用Process Explorer分析句柄泄露溢出问题 使用 Process Explorer 分析句柄泄漏问题是一个非常有效的方法。句柄泄漏通常是由于应用程序在创建系统资源(如文件、注册表项、GDI 对象等)后没有正确释放这些资源。以下是使用 二、…...

HTTP/2
http相关知识点 HTTP/2是超文本传输协议(HTTP)的第二个主要版本,旨在解决HTTP/1.x版本中存在的一些性能限制和效率问题。HTTP/2由互联网工程任务组(IETF)的HTTP工作组开发,最终在2015年作为RFC 7540正式发…...

如何在算家云搭建ComfyUI(AI绘画)
一、ComfyUI简介 ComfyUI 是一个强大的、模块化的 Stable Diffusion 界面与后端项目。该用户界面将允许用户使用基于图形/节点/流程图的界面设计和执行高级稳定的扩散管道。该项目部分其它特点如下: 全面支持 SD1.x,SD2.x,SDXL,…...
公司的企业画册如何制作?
企业画册是公司形象和产品服务展示的重要载体,一个制作精良的企业画册不仅能展示公司的实力,也能提升客户对公司专业度的认可。以下是制作企业画册的步骤和要点,帮助你的公司画册既美观又实用。 1.要制作电子杂志,首先需要选择一款适合自己的…...

13、Django Admin创建两个独立的管理站点
admin文件 from .models import Epic, Event, EventHero, EventVillain from django.contrib.admin import AdminSiteclass EventAdminSite(AdminSite):site_header "Events管理"site_title "欢迎您!"index_title "管理员"even…...
)
FFmpeg swresample库进阶:除了基础转换,swr_alloc_set_opts2还能这样玩(含滤波器与精度设置)
FFmpeg swresample库进阶:解锁swr_alloc_set_opts2的隐藏潜力 在专业音频处理领域,采样率转换的质量直接影响最终输出的听感表现。许多开发者满足于基础参数配置,却忽略了FFmpeg的swresample库中那些能显著提升音质的"隐藏开关"。本…...

sysinfo 安全部署指南:在 macOS/iOS 沙盒环境中的正确使用方法
sysinfo 安全部署指南:在 macOS/iOS 沙盒环境中的正确使用方法 【免费下载链接】sysinfo Cross-platform library to fetch system information 项目地址: https://gitcode.com/gh_mirrors/sy/sysinfo sysinfo 是一款跨平台系统信息获取库,能够帮…...

如何快速完整备份QQ空间历史说说?GetQzonehistory终极解决方案
如何快速完整备份QQ空间历史说说?GetQzonehistory终极解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆日益珍贵的今天,QQ空间作为承载无数人青…...
)
创新实训个人工作-初步搭建(二)
一、思考在完成 AI 问答页的基础搭建后,我开始思考:如果这个页面真的面向用户使用,它应该像什么?我觉得他的回答必须要更加专业,可以在生活中可以真实可用。所以后续打磨,我主要围绕两条线展开:…...

GLM-4V-9B功能全解析:从图像描述到视觉推理,一站式体验
GLM-4V-9B功能全解析:从图像描述到视觉推理,一站式体验 1. 认识GLM-4V-9B:你的多模态AI助手 想象一下,你正在翻阅一本满是图表的外文杂志,突然遇到一张复杂的流程图,旁边配着你看不懂的文字说明。这时如果…...

给你的Windows来一次“数字瘦身“:告别卡顿与干扰,重获流畅体验
给你的Windows来一次"数字瘦身":告别卡顿与干扰,重获流畅体验 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other…...

AI时代新型的项目管理应该是什么样的?侣
AI训练存储选型的演进路线 第一阶段:单机直连时代 早期的深度学习数据集较小,模型训练通常在单台服务器或单张GPU卡上完成。此时直接将数据存储在训练机器的本地NVMe SSD/HDD上。 其优势在于IO延迟最低,吞吐量极高,也就是“数据离…...

无人机APM实战:从串口调试到多协议通信配置
1. 无人机APM串口通信基础入门 第一次接触APM飞控的串口通信时,我完全被各种专业术语搞懵了。后来才发现,串口其实就是飞控与外部设备"对话"的通道,就像两个人用对讲机交流一样简单。以Nora飞控为例,它的每个串口都有特…...

Salt Player:Android本地音乐播放器的专业选择与深度体验
Salt Player:Android本地音乐播放器的专业选择与深度体验 【免费下载链接】SaltPlayerSource Salt Player (A local music player trusted and chosen by hundreds of thousands of users) for Android Release, Feedback. 项目地址: https://gitcode.com/GitHub_…...

Multisim仿真NE555驱动NMOS总报错?手把手教你修改仿真参数搞定PWM调光电路
Multisim仿真NE555驱动NMOS报错全解析:从参数调优到实战调光 当你在Multisim中搭建NE555 PWM调光电路时,是否遇到过一接上NMOS就仿真崩溃的尴尬?那个刺眼的"瞬态分析无法收敛"报错窗口,仿佛在嘲笑你连基础电路都搞不定。…...