2024 年高教社杯全国大学生数学建模竞赛B题4小问解题思路(第二版)
原文链接:https://www.cnblogs.com/qimoxuan/articles/18399415
问题 1:抽样检测方案设计
详细解题思路:
-
确定抽样检测目标:企业需要确定一个可接受的次品率上限(标称值),以及在该次品率下,企业愿意接受或拒绝零配件的信度水平(置信度)。
-
选择抽样方案:根据信度要求,选择合适的抽样方案。常见的抽样方案包括简单随机抽样和分层抽样。
-
计算抽样大小:根据次品率的标称值、信度水平和风险水平,计算所需的最小抽样大小。
-
确定接受/拒绝标准:根据抽样结果,确定一个阈值,如果抽样中发现的次品数量超过这个阈值,则拒绝整批零配件。
-
模拟和验证:通过模拟抽样过程,验证所设计的抽样方案是否满足企业的要求。
数学模型和公式:
-
二项分布:假设零配件的次品率 p 是已知的,那么抽样中发现次品的数量 XX 服从二项分布 X∼B(n,p),其中 n 是抽样大小。
- 抽样大小计算:可以使用以下公式来估计抽样大小 n:
其中,Zα/2 是正态分布的分位数,E 是可接受的误差范围。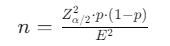
-
接受/拒绝标准:设定一个临界值 cc,如果 X>cX>c,则拒绝零配件。临界值可以通过以下公式计算: c=max{k:P(X≤k)≥1−β} 其中,ββ 是犯第一类错误的概率(即错误地接受不合格的零配件)。
示例代码:
from scipy.stats import binom# 参数设置
p_nominal = 0.10 # 标称次品率
confidence_level = 0.95 # 信度水平
risk_level = 0.10 # 风险水平
error_margin = 0.05 # 可接受的误差范围# 计算Z值
Z = abs((1 - confidence_level) ** 0.5)# 计算抽样大小
n = (Z**2 * p_nominal * (1 - p_nominal)) / (error_margin**2)# 计算接受/拒绝标准
c = binom.ppf(1 - risk_level, n, p_nominal)# 输出结果
print(f"抽样大小: {int(n)}")
print(f"接受/拒绝标准: {int(c)}")# 模拟抽样过程
sample_size = int(n)
defective_rate = p_nominal
samples = binom.rvs(n=sample_size, p=defective_rate, size=1000)
accept = samples <= c# 计算接受率
accept_rate = accept.mean()
print(f"在标称次品率下,接受率: {accept_rate:.2f}")问题 2:生产过程决策
详细解题思路:
-
定义决策变量:
- D1 和 D2:是否对零配件1和零配件2进行检测。
- T:是否对装配好的成品进行检测。
- R:是否对检测出的不合格成品进行拆解。
-
成本和收益分析:
- 计算每个决策变量的成本和收益,包括检测成本、装配成本、市场售价、调换损失和拆解费用。
-
建立目标函数:
- 最大化利润或最小化成本。
-
约束条件:
- 零配件和成品的次品率。
- 检测和拆解的可行性。
-
模型求解:
- 使用线性规划、动态规划或决策树来求解模型。
数学模型和公式:
-
目标函数: Maximize Profit=Revenue−Cost 其中,Revenue 是销售合格成品的收入,Cost 包括购买成本、检测成本、装配成本、市场售价、调换损失和拆解费用。
-
约束条件:
- 零配件合格率约束: P1≥(1−Defective Rate of Component 1)P2≥(1−Defective Rate of Component 2)
- 成品合格率约束: P≥(1−Defective Rate of Final Product)
-
决策变量:
- D1,D2∈{0,1}:是否检测零配件。
- T∈{0,1}:是否检测成品。
- R∈{0,1}:是否拆解不合格成品。
示例代码:
import pulp# 定义问题
prob = pulp.LpProblem("Production_Decision", pulp.LpMaximize)# 定义决策变量
D1 = pulp.LpVariable("D1", cat='Binary')
D2 = pulp.LpVariable("D2", cat='Binary')
T = pulp.LpVariable("T", cat='Binary')
R = pulp.LpVariable("R", cat='Binary')# 参数设置
cost_component1 = 4
cost_component2 = 18
cost_assembly = 6
cost_test_component1 = 2
cost_test_component2 = 3
cost_test_final = 3
cost_disassembly = 5
market_price = 56
replacement_loss = 6# 成本函数
cost = cost_component1 * (1 - D1) + cost_component2 * (1 - D2) + cost_assembly + \(D1 * cost_test_component1) + (D2 * cost_test_component2) + (T * cost_test_final) + \(R * cost_disassembly)# 收益函数
revenue = market_price * (1 - 0.1) * (1 - 0.1) * (1 - T)# 目标函数
prob += revenue - cost# 约束条件
prob += D1 + D2 + T + R <= 4, "Total_Tests"# 求解问题
prob.solve()# 输出结果
print("Status:", pulp.LpStatus[prob.status])
print("Optimal Decision Variables:")
print("D1 (Test Component 1) =", D1.varValue)
print("D2 (Test Component 2) =", D2.varValue)
print("T (Test Final Product) =", T.varValue)
print("R (Disassemble Rejected Products) =", R.varValue)
print("Maximum Profit =", pulp.value(prob.objective))问题 3:多道工序决策
详细解题思路:
-
定义决策变量:
- 对于每个零配件 i,定义 Di 为是否检测该零配件。
- 对于每个半成品 j,定义 Aj 为是否检测该半成品。
- 对于成品,定义 T 为是否检测成品。
-
成本和收益分析:
- 计算每个决策变量的成本和收益,包括购买成本、检测成本、装配成本、市场售价、调换损失和拆解费用。
-
建立目标函数:
- 最大化利润或最小化成本。
-
约束条件:
- 零配件和半成品的次品率。
- 检测和拆解的可行性。
-
模型求解:
- 使用多阶段决策过程或网络流模型来求解模型。
数学模型和公式:
-
目标函数: Maximize Profit=Revenue−Cost 其中,Revenue 是销售合格成品的收入,Cost 包括购买成本、检测成本、装配成本、市场售价、调换损失和拆解费用。
-
约束条件:
- 零配件合格率约束: Pi≥(1−Defective Rate of Component i)
- 半成品合格率约束: Qj≥(1−Defective Rate of Semi-finished Product j)
- 成品合格率约束: P≥(1−Defective Rate of Final Product)
-
决策变量:
- Di,Aj,T∈{0,1}:是否检测相应的零配件、半成品或成品。
示例代码:
import pulp# 定义问题
prob = pulp.LpProblem("Multistage_Production_Decision", pulp.LpMaximize)# 定义决策变量
components = ['1', '2', '3', '4', '5', '6', '7', '8']
D = pulp.LpVariable.dicts("D", components, cat='Binary')
A = pulp.LpVariable.dicts("A", components[0:4], cat='Binary') # 假设只有前4个组件形成半成品
T = pulp.LpVariable("T", cat='Binary')# 参数设置
cost_component = {i: 2 for i in components} # 假设所有组件购买成本为2
cost_assembly = 8
cost_test = {i: 1 for i in components} # 假设所有组件检测成本为1
cost_test_final = 6
cost_disassembly = 4
market_price = 200
replacement_loss = 40# 成本函数
cost = sum(cost_component[i] * (1 - D[i]) for i in components) + \sum(cost_test[i] * D[i] for i in components) + \sum(cost_test[i] * A[i] for i in components[0:4]) + \cost_test_final * T + cost_disassembly * T# 收益函数
revenue = market_price * (1 - 0.1) # 假设成品次品率为10%# 目标函数
prob += revenue - cost# 约束条件
for i in components:prob += D[i] + A[i] + T <= 4, f"Total_Tests_{i}"# 求解问题
prob.solve()# 输出结果
print("Status:", pulp.LpStatus[prob.status])
print("Optimal Decision Variables:")
for i in components:print(f"D_{i} (Test Component {i}) =", D[i].varValue)
for i in components[0:4]:print(f"A_{i} (Test Semi-finished Product {i}) =", A[i].varValue)
print("T (Test Final Product) =", T.varValue)
print("Maximum Profit =", pulp.value(prob.objective))问题 4:考虑抽样误差的决策
详细解题思路:
-
考虑抽样误差:
- 抽样误差会影响对零配件、半成品和成品次品率的估计。
- 需要考虑抽样误差对决策的影响,包括对检测和拆解决策的影响。
-
建立概率模型:
- 使用概率模型来描述次品率的不确定性,例如使用贝叶斯方法或置信区间。
-
优化模型:
- 建立一个优化模型,考虑不确定性下的决策,以最大化期望利润或最小化期望成本。
-
鲁棒性分析:
- 评估在不确定性下,决策方案的鲁棒性,确保在最坏情况下仍能保持合理的性能。
-
模型求解:
- 使用蒙特卡洛模拟或其他随机优化方法来求解模型。
数学模型和公式:
-
概率模型:
- 假设次品率 p 是一个随机变量,可以使用贝叶斯方法来更新其后验分布。
-
优化模型:
- 建立一个期望值模型,最大化期望利润: Maximize E[Profit]=E[Revenue]−E[Cost]
- 其中,E[Revenue] 和 E[Cost] 分别是收入和成本的期望值。
-
鲁棒性分析:
- 使用最坏情况分析或敏感性分析来评估决策方案在不确定性下的表现。
示例代码:
import numpy as np
import pulp# 定义问题
prob = pulp.LpProblem("Robust_Production_Decision", pulp.LpMaximize)# 定义决策变量
D = pulp.LpVariable.dicts("D", [1, 2], cat='Binary')
T = pulp.LpVariable("T", cat='Binary')# 参数设置
cost_component = [4, 18]
cost_test = [2, 3]
cost_assembly = 6
cost_test_final = 3
cost_disassembly = 5
market_price = 56
replacement_loss = 6# 次品率和抽样误差
defective_rates = [0.1, 0.2] # 真实次品率
sample_sizes = [50, 50] # 抽样大小
sampling_error = 0.05 # 抽样误差# 模拟抽样过程
np.random.seed(0)
sampled_defective_rates = np.random.normal(defective_rates, sampling_error, (2, 2))# 成本函数
cost = (cost_component[0] * (1 - D[1]) + cost_test[0] * D[1] +cost_component[1] * (1 - D[2]) + cost_test[1] * D[2] +cost_assembly + cost_test_final * T)# 收益函数
revenue = market_price * (1 - np.mean(sampled_defective_rates[:, 0])) * (1 - np.mean(sampled_defective_rates[:, 1]))# 目标函数
prob += revenue - cost# 约束条件
prob += D[1] + D[2] + T <= 3, "Total_Tests"# 求解问题
prob.solve()# 输出结果
print("Status:", pulp.LpStatus[prob.status])
print("Optimal Decision Variables:")
print("D1 (Test Component 1) =", D[1].varValue)
print("D2 (Test Component 2) =", D[2].varValue)
print("T (Test Final Product) =", T.varValue)
print("Maximum Profit =", pulp.value(prob.objective))相关文章:
2024 年高教社杯全国大学生数学建模竞赛B题4小问解题思路(第二版)
原文链接:https://www.cnblogs.com/qimoxuan/articles/18399415 问题 1:抽样检测方案设计 详细解题思路: 确定抽样检测目标:企业需要确定一个可接受的次品率上限(标称值),以及在该次品率下&am…...

docker-nginx数据卷挂载
一、案例1-利用Nginx容器部署静态资源 1.1、需求: 创建Nginx容器, 修改nginx容器内的html目录下的index.html文件,查看变化将静态资源部署到nginx的html目录 1.2、修改html目录下的index.html文件,查看变化 因为docker运用得最小化系统环境,解决办法就…...
---优化(2)---查询逻辑层优化)
项目实战 ---- 商用落地视频搜索系统(8)---优化(2)---查询逻辑层优化
目录 背景 技术衡量与方案 一种可实现方案 可实现方案及设计描述 可能存在的问题 一种创新实现方案 方案的改良设计 策略公式 优化的实现 完整代码 代码解释 异常场景的考量 处理方式 运行注意事项 运行结果 结果优化对比与解释 背景 在项目实战 ---- 商用落地…...

山东大学机试试题合集
🍰🍰🍰高分篇已经涵盖了绝大多数的机试考点,由于临近预推免,各校的机试蜂拥而至,我们接下来先更一些各高校机试题合集,算是对前边学习成果的深入学习,也是对我们代码能力的锻炼。加油…...
餐厅食品留样管理系统小程序的设计
管理员账户功能包括:系统首页,个人中心,窗口负责人管理,窗口员工管理,冰柜管理,排班信息管理,留样食品管理,教育宣传管理,系统管理 微信端账号功能包括:系统…...

亚马逊运营:如何提高亚马逊销量和运营效率?
不少亚马逊卖家们为了扩大业务规模和提高销量,会创建多个卖家账户来同时运营多个亚马逊店铺。问题是,这种多店铺运营模式并非没有风险——亚马逊运营的一个重要方面就是账户的健康管理。一旦某个账户出现问题,亚马逊的算法就可能会启动关联检…...

设计模式背后的设计原则和思想
设计模式背后的设计原则和思想是一套指导我们如何设计高质量软件系统的准则和方法论。这些原则和思想不仅有助于提升软件的可维护性、可扩展性和可复用性,还能帮助开发团队更好地应对复杂多变的需求。以下是一些核心的设计原则和思想: 1. 设计原则 设计…...

项目总体框架
一.后端(包装servlet) 使用BaseServlet进行请求的初步处理(利用继承进行执行这个) 在BaseServlet中 处理请求的类型找到对象的方法,并使用注解找到参数名,执行参数自动注入。 package com.csdn.controlle…...

k8s Prometheus
一、部署 Prometheus kubectl create ns kube-ops# 创建 prometheus-cm.yaml apiVersion: v1 kind: ConfigMap metadata:name: prometheus-confignamespace: kube-ops data:prometheus.yml: |global:scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默…...

glsl着色器学习(九)屏幕像素空间和设置颜色
在上一篇文章中,使用的是裁剪空间进行绘制,这篇文章使用屏幕像素空间的坐标进行绘制。 上一篇的顶点着色器大概是这样子的 回归一下顶点着色的主要任务: 通常情况下,顶点着色器会进行一系列的矩阵变换操作,将输入的顶…...

前端框架有哪些?
前言 用户体验是每个开发网站的企业中的重中之重。无论后台有多方面的操作和功能,用户的视图和体验都必须是无缝的最友好的。这需要使用前端框架来简化交互式、以用户为中心的网站的开发。 前端框架是一种用于简化Web开发的工具,它提供了一套预定义的代…...

分类预测|基于黑翅鸢优化轻量级梯度提升机算法数据预测Matlab程序BKA-LightGBM多特征输入多类别输出 含对比
分类预测|基于黑翅鸢优化轻量级梯度提升机算法数据预测Matlab程序BKA-LightGBM多特征输入多类别输出 含对比 文章目录 一、基本原理BKA(Black Kite Algorithm)的原理LightGBM分类预测模型的原理BKA与LightGBM的模型流程总结 二、实验结果三、核心代码四、…...

利用大模型实时提取和检索多模态数据探索-利用 Indexify 进行文档分析
概览 传统的文本提取方法常常无法理解非结构化内容,因此提取数据的数据往往是错误的。本文将探讨使用 Indexify,一个用于实时多模态数据提取的开源框架,来更好地分析pdf等非结构化文件。我将介绍如何设置 Indexify,包括服务器设置…...

函数式接口实现策略模式
函数式接口实现策略模式 1.案例背景 我们在日常开发中,大多会写if、else if、else 这样的代码,但条件太多时,往往嵌套无数层if else,阅读性很差,比如如下案例,统计学生的数学课程的成绩: 90-100分&#…...

鸿蒙Next-拉起支付宝的三种方式——教程
鸿蒙Next-拉起支付宝的三种方式——教程 鸿蒙Next系统即将上线,应用市场逐渐丰富、很多APP都准备接入支付宝做支付功能,目前来说有三种方式拉起支付宝:通过支付宝SDK拉起、使用OpenLink拉起、传入支付宝包名使用startAbility拉起。以上的三种…...

Vue.js 组件化开发:父子组件通信与组件注册详解
Vue.js 组件化开发:父子组件通信与组件注册详解 简介: 在 Vue.js 的开发中,组件是构建应用的重要基础。掌握组件的创建与使用,尤其是父子组件的通信和组件的注册与命名,是开发中不可或缺的技能。本文将详细探讨这些内容…...

【HTTP、Web常用协议等等】前端八股文面试题
HTTP、Web常用协议等等 更新日志 2024年9月5日 —— 什么情况下会导致浏览器内存泄漏? 文章目录 HTTP、Web常用协议等等更新日志1. 网络请求的状态码有哪些?1)1xx 信息性状态码2)2xx 成功状态码3)3xx 重定向状态码4&…...

Datawhale x李宏毅苹果书AI夏令营深度学习详解进阶Task03
在深度学习中,批量归一化(Batch Normalization,BN)技术是一种重要的优化方法,它可以有效地改善模型的训练效果。本文将详细讨论批量归一化的原理、实现方式、在神经网络中的应用,以及如何选择合适的损失函数…...

【机器学习】任务三:基于逻辑回归与线性回归的鸢尾花分类与波士顿房价预测分析
目录 1.目的和要求 1.1 掌握回归分析的概念和使用场景 1.2 掌握机器学习回归分析进行数据预测的有效方法 1.3 掌握特征重要性分析、特征选择和模型优化的方法 2.波士顿房价预测与特征分析 2.1第一步:导入所需的模块和包 2.2 第二步:加载波士顿房价…...

【操作系统存储篇】Linux文件基本操作
目录 一、Linux目录 二、Linux文件的常用操作 三、Linux文件类型 一、Linux目录 Linux有很多目录,Linux一切皆是文件,包括进程、设备等。 相对路径:相对于当前的操作目录,文件位于哪个目录。 绝对路径 :从根目录开…...

Testsigma自动化测试平台深度解析:AI协同测试架构设计与实践指南
Testsigma自动化测试平台深度解析:AI协同测试架构设计与实践指南 【免费下载链接】testsigma Testsigma is an agentic test automation platform powered by AI-coworkers that work alongside QA teams to simplify testing, accelerate releases and improve qua…...

构建个人数字图书馆:用fanqienovel-downloader实现小说永久保存与跨设备阅读
构建个人数字图书馆:用fanqienovel-downloader实现小说永久保存与跨设备阅读 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 在数字阅读日益普及的今天,如何突破网络…...

微信聊天记录永久保存的3种方法:WeChatMsg完整指南与实战技巧
微信聊天记录永久保存的3种方法:WeChatMsg完整指南与实战技巧 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/w…...

一个简单到尴尬却有效的SFT实验
卷友们好,我是rumor。上周Apple有篇论文做了一个简单到有点尴尬的实验:从模型自己采样一批代码答案,不过滤对错,不执行验证,直接拿去SFT。结果Qwen3-30B在LiveCodeBench v6上,pass1从42.4%涨到55.3%&#x…...

3个核心突破:科研工作者的文献获取难题终极解决方案
3个核心突破:科研工作者的文献获取难题终极解决方案 【免费下载链接】zotero-scipdf Download PDF from Sci-Hub automatically For Zotero7 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-scipdf 作为科研工作者,你是否经常遇到这些困扰&…...

告别C盘空间焦虑:手把手教你将MySQL和PATSTAT专利库完整部署到移动硬盘
告别C盘空间焦虑:手把手教你将MySQL和PATSTAT专利库完整部署到移动硬盘 当你的研究项目需要处理数百GB的专利数据,而笔记本电脑的C盘只剩下可怜的几GB空间时,那种焦虑感堪比论文截止日期前夜的打印机卡纸。PATSTAT这样的专利数据库就像知识宝…...

第三部分:第3章_OpenStack所需RabbitMQ消息队列安装并配置
第三部分:第3章_OpenStack所需RabbitMQ消息队列安装并配置 //控制节点执行,本案例中node1节点// 3.1、安装并配置RabbitMQ消息队列服务 [root@openstack ~]# yum install -y rabbitmq-server[root@openstack ~]# systemctl enable rabbitmq-server.service [root@openstac…...

告别云端!用Ollama本地运行Yi-Coder-1.5B,保护代码隐私的终极方案
告别云端!用Ollama本地运行Yi-Coder-1.5B,保护代码隐私的终极方案 1. 为什么选择本地代码生成模型? 在软件开发过程中,我们经常需要快速生成代码片段、解决编程问题或理解复杂逻辑。传统做法是使用云端代码生成服务,…...

OpenClaw隐私保护方案:Qwen3-14B镜像+本地NAS存储配置
OpenClaw隐私保护方案:Qwen3-14B镜像本地NAS存储配置 1. 为什么需要全链路隐私保护? 去年我帮一位律师朋友配置自动化文档处理流程时,遇到一个棘手问题:他的工作涉及大量客户隐私数据,而市面上多数AI工具都需要将文件…...

Pip生成requirements.txt文件
在Python开发中,requirements.txt文件是一个非常重要的文件,它列出了项目所需的所有外部Python库及其版本号。这对于项目的部署和版本控制非常有帮助,因为它确保了所有开发者和部署环境都能使用相同版本的库。 如何生成requirements.txt文件 …...