LlamaIndex 使用 RouterOutputAgentWorkflow
LlamaIndex 中提供了一个 RouterOutputAgentWorkflow 功能,可以集成多个 QueryTool,根据用户的输入判断使用那个 QueryEngine,在做查询的时候,可以从不同的数据源进行查询,例如确定的数据从数据库查询,如果是语义查询可以从向量数据库进行查询。本文将实现两个搜索引擎,根据不同 Query 使用不同 QueryEngine。
安装 MySQL 依赖
pip install mysql-connector-python
搜索引擎
定义搜索引擎,初始两个数据源
- 使用 MySQL 作为数据库的数据源
- 使用 VectorIndex 作为语义搜索数据源
from pathlib import Path
from llama_index.core.tools import QueryEngineTool
from llama_index.core import VectorStoreIndex
import llm
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.query_engine import NLSQLTableQueryEngine
from llama_index.core import Settings
from llama_index.core import SQLDatabasefrom sqlalchemy import create_engine, MetaData, Table, Column, String, Integer, select
Settings.llm = llm.get_ollama("mistral-nemo")
Settings.embed_model = llm.get_ollama_embbeding()engine = create_engine('mysql+mysqlconnector://root:123456@localhost:13306/db_llama', echo=True
)def init_db():# 初始化数据库metadata_obj = MetaData()table_name = "city_stats"city_stats_table = Table(table_name,metadata_obj,Column("city_name", String(16), primary_key=True),Column("population", Integer, ),Column("state", String(16), nullable=False),)metadata_obj.create_all(engine)sql_database = SQLDatabase(engine, include_tables=["city_stats"])from sqlalchemy import insertrows = [{"city_name": "New York City", "population": 8336000, "state": "New York"},{"city_name": "Los Angeles", "population": 3822000, "state": "California"},{"city_name": "Chicago", "population": 2665000, "state": "Illinois"},{"city_name": "Houston", "population": 2303000, "state": "Texas"},{"city_name": "Miami", "population": 449514, "state": "Florida"},{"city_name": "Seattle", "population": 749256, "state": "Washington"},]for row in rows:stmt = insert(city_stats_table).values(**row)with engine.begin() as connection:cursor = connection.execute(stmt)from llama_index.core.query_engine import NLSQLTableQueryEnginesql_database = SQLDatabase(engine, include_tables=["city_stats"])
sql_query_engine = NLSQLTableQueryEngine(sql_database=sql_database,tables=["city_stats"]
)def get_doc_index()-> VectorStoreIndex:'''解析 words'''# 创建 OllamaEmbedding 实例,用于指定嵌入模型和服务的基本 URLollama_embedding = llm.get_ollama_embbeding()# 读取 "./data" 目录中的数据并加载为文档对象documents = SimpleDirectoryReader(input_files=[Path(__file__).parent / "data" / "LA.pdf"]).load_data()# 从文档中创建 VectorStoreIndex,并使用 OllamaEmbedding 作为嵌入模型vector_index = VectorStoreIndex.from_documents(documents, embed_model=ollama_embedding, transformations=[SentenceSplitter(chunk_size=1000, chunk_overlap=20)],)vector_index.set_index_id("vector_index") # 设置索引 IDvector_index.storage_context.persist("./storage") # 将索引持久化到 "./storage"return vector_indexllama_index_query_engine = get_doc_index().as_query_engine()sql_tool = QueryEngineTool.from_defaults(query_engine=sql_query_engine,description=("Useful for translating a natural language query into a SQL query over"" a table containing: city_stats, containing the population/state of"" each city located in the USA."),name="sql_tool"
)llama_cloud_tool = QueryEngineTool.from_defaults(query_engine=llama_index_query_engine,description=(f"Useful for answering semantic questions about certain cities in the US."),name="llama_cloud_tool"
)创建工作流
下图中显示了工作流的节点,绿色背景节点是工作流的动作,例如大模型返回 ToolEvent,ToolEvent 节点执行并返回结果。

工作流定义代码:
from typing import Dict, List, Any, Optionalfrom llama_index.core.tools import BaseTool
from llama_index.core.llms import ChatMessage
from llama_index.core.llms.llm import ToolSelection, LLM
from llama_index.core.workflow import (Workflow,Event,StartEvent,StopEvent,step,Context
)
from llama_index.core.base.response.schema import Response
from llama_index.core.tools import FunctionTool
from llama_index.utils.workflow import draw_all_possible_flows
from llm import get_ollamafrom docs import enable_traceenable_trace()class InputEvent(Event):"""Input event."""class GatherToolsEvent(Event):"""Gather Tools Event"""tool_calls: Anyclass ToolCallEvent(Event):"""Tool Call event"""tool_call: ToolSelectionclass ToolCallEventResult(Event):"""Tool call event result."""msg: ChatMessageclass RouterOutputAgentWorkflow(Workflow):"""Custom router output agent workflow."""def __init__(self,tools: List[BaseTool],timeout: Optional[float] = 10.0,disable_validation: bool = False,verbose: bool = False,llm: Optional[LLM] = None,chat_history: Optional[List[ChatMessage]] = None,):"""Constructor."""super().__init__(timeout=timeout, disable_validation=disable_validation, verbose=verbose)self.tools: List[BaseTool] = toolsself.tools_dict: Optional[Dict[str, BaseTool]] = {tool.metadata.name: tool for tool in self.tools}self.llm: LLM = llmself.chat_history: List[ChatMessage] = chat_history or []def reset(self) -> None:"""Resets Chat History"""self.chat_history = []@step()async def prepare_chat(self, ev: StartEvent) -> InputEvent:message = ev.get("message")if message is None:raise ValueError("'message' field is required.")# add msg to chat historychat_history = self.chat_historychat_history.append(ChatMessage(role="user", content=message))return InputEvent()@step()async def chat(self, ev: InputEvent) -> GatherToolsEvent | StopEvent:"""Appends msg to chat history, then gets tool calls."""# Put msg into LLM with tools includedchat_res = await self.llm.achat_with_tools(self.tools,chat_history=self.chat_history,verbose=self._verbose,allow_parallel_tool_calls=True)tool_calls = self.llm.get_tool_calls_from_response(chat_res, error_on_no_tool_call=False)ai_message = chat_res.messageself.chat_history.append(ai_message)if self._verbose:print(f"Chat message: {ai_message.content}")# no tool calls, return chat message.if not tool_calls:return StopEvent(result=ai_message.content)return GatherToolsEvent(tool_calls=tool_calls)@step(pass_context=True)async def dispatch_calls(self, ctx: Context, ev: GatherToolsEvent) -> ToolCallEvent:"""Dispatches calls."""tool_calls = ev.tool_callsawait ctx.set("num_tool_calls", len(tool_calls))# trigger tool call eventsfor tool_call in tool_calls:ctx.send_event(ToolCallEvent(tool_call=tool_call))return None@step()async def call_tool(self, ev: ToolCallEvent) -> ToolCallEventResult:"""Calls tool."""tool_call = ev.tool_call# get tool ID and function callid_ = tool_call.tool_idif self._verbose:print(f"Calling function {tool_call.tool_name} with msg {tool_call.tool_kwargs}")# call function and put result into a chat messagetool = self.tools_dict[tool_call.tool_name]output = await tool.acall(**tool_call.tool_kwargs)msg = ChatMessage(name=tool_call.tool_name,content=str(output),role="tool",additional_kwargs={"tool_call_id": id_,"name": tool_call.tool_name})return ToolCallEventResult(msg=msg)@step(pass_context=True)async def gather(self, ctx: Context, ev: ToolCallEventResult) -> StopEvent | None:"""Gathers tool calls."""# wait for all tool call events to finish.tool_events = ctx.collect_events(ev, [ToolCallEventResult] * await ctx.get("num_tool_calls"))if not tool_events:return Nonefor tool_event in tool_events:# append tool call chat messages to historyself.chat_history.append(tool_event.msg)# # after all tool calls finish, pass input event back, restart agent loopreturn InputEvent()from muti_agent import sql_tool, llama_cloud_tool
wf = RouterOutputAgentWorkflow(tools=[sql_tool, llama_cloud_tool], verbose=True, timeout=120, llm=get_ollama("mistral-nemo"))async def main():result = await wf.run(message="Which city has the highest population?")print("RSULT ===============", result)# if __name__ == "__main__":
# import asyncio# asyncio.run(main())import gradio as grasync def random_response(message, history):wf.reset()result = await wf.run(message=message)print("RSULT ===============", result)return resultdemo = gr.ChatInterface(random_response, clear_btn=None, title="Qwen2")demo.launch()
输入问题是 “What are five popular travel spots in Los Angeles?”,自动路由到 VectorIndex 进行查询。

输入问题为 “which city has the most population” 时,调用数据库进行搜索。

总结
LlamaIndex 中搜索引擎自动路由,根据用户的输入型自动选择所需的搜索引擎,这里有一个需要注意的点,模型需要支持 Function Call。如果 Ollama 本地模型进行推理,不是所有的本地模型都支持Function Call,Llama3.1 和 mistral-nemo 是支持 Function Call 的,可以使用。
相关文章:
LlamaIndex 使用 RouterOutputAgentWorkflow
LlamaIndex 中提供了一个 RouterOutputAgentWorkflow 功能,可以集成多个 QueryTool,根据用户的输入判断使用那个 QueryEngine,在做查询的时候,可以从不同的数据源进行查询,例如确定的数据从数据库查询,如果…...

设计模式学习-责任链模式
概念 使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止. 代码编写 using UnityEngine; using System.Collections; public class ChainOfResp…...

【全网最全】2024年数学建模国赛B题31页完整建模过程+成品论文+matlab/python代码等(后续会更新
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片,那是获取资料的入口! 2024数学建模国赛B题 【全网最全】2024年数学建模国赛B题31页完整建模过程成品论文matlab/python代码等(后续会更新「首先来看看目前已有的资料…...
第二十一届华为杯数学建模经验分享之资料分享篇
今天给大家分享一些数学建模的资料,通过这些资料的学习相信你们一定在比赛中获得好的成绩。今天分享的资料包括美赛和国赛的优秀论文集、研赛的优秀论文集、推荐数学建模的相关书籍、智能算法的学习PPT、python机器学习的书籍和数学建模经验分享与总结,其…...

使用 OpenSSL 创建自签名证书
mkdir -p /etc/nginx/conf.d/cert #2、创建私钥 openssl genrsa -des3 -out https.key 1024 提示输入字符: 输入字符:rancher [rootocean-app-1a-01 cert]# openssl genrsa -des3 -out https.key 1024 Generating RSA private key, 1024 bit long modulu…...

EmguCV学习笔记 VB.Net 9.1 VideoCapture类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV是一个基于OpenCV的开源免费的跨平台计算机视觉库,它向C#和VB.NET开发者提供了OpenCV库的大部分功能。 教程VB.net版本请访问…...
Rspack 1.0 发布了!
文章来源|Rspack Team 项目地址|https://github.com/web-infra-dev/rspack Rspack 是基于 Rust 编写的下一代 JavaScript 打包工具, 兼容 webpack 的 API 和生态,并提供 10 倍于 webpack 的构建性能。 在 18 个月前,我…...

【全网最全】2024年数学建模国赛E题超详细保奖思路+可视化图表+成品论文+matlab/python代码等(后续会更新
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片,那是获取资料的入口! 【全网最全】2024年数学建模国赛E题成品论文超详细保奖思路可视化图表matlab/python代码等(后续会更新「首先来看看目前已有的资料,还…...

数智转型,看JNPF如何成为企业的必备工具
随着数字化转型的浪潮席卷全球,企业面临着前所未有的挑战与机遇。在这一过程中,低代码开发平台作为一种创新的软件开发方式,正逐渐成为企业实现快速迭代和敏捷开发的关键工具。JNPF作为一款领先的低代码开发平台,凭借其强大的功能…...

ArcGIS Pro 发布松散型切片
使用ArcGIS Pro发布松散型切片问题,有时候会出现切片方案写了松散型,但是自动切片完成后依然是紧凑型的问题,这时候可以采用手动修改然后再切片的方式。 1. 发布切片服务 选择手动切片方式 2. 手动修改服务的切片方案文件 修改cache服务…...
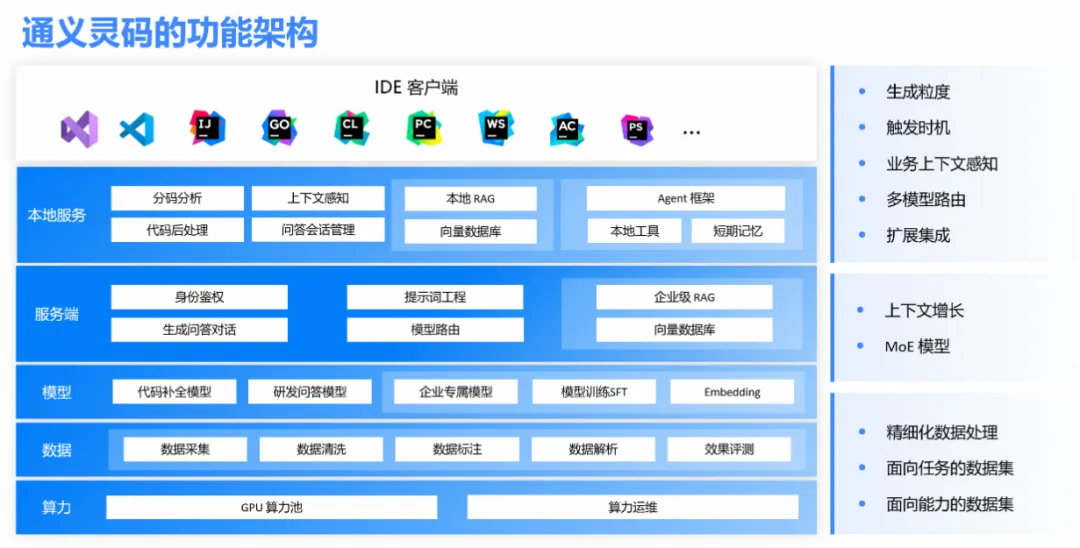
奖项再+1!通义灵码智能编码助手通过可信 AI 智能编码工具评估,获当前最高等级
阿里云的通义灵码智能编码助手参与中国信通院组织的可信AI智能编码工具首轮评估,最终获得 4 级评级,成为国内首批通过该项评估并获得当前最高评级的企业之一。 此次评估以《智能化软件工程技术和应用要求 第 2 部分:智能开发能力》为依据&…...

如何使用 yum 在 CentOS 6 上安装 nginx
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 状态 状态: 已弃用 本文涵盖的 CentOS 版本已不再受支持。如果您目前正在运行 CentOS 6 服务器,我们强烈建议升…...
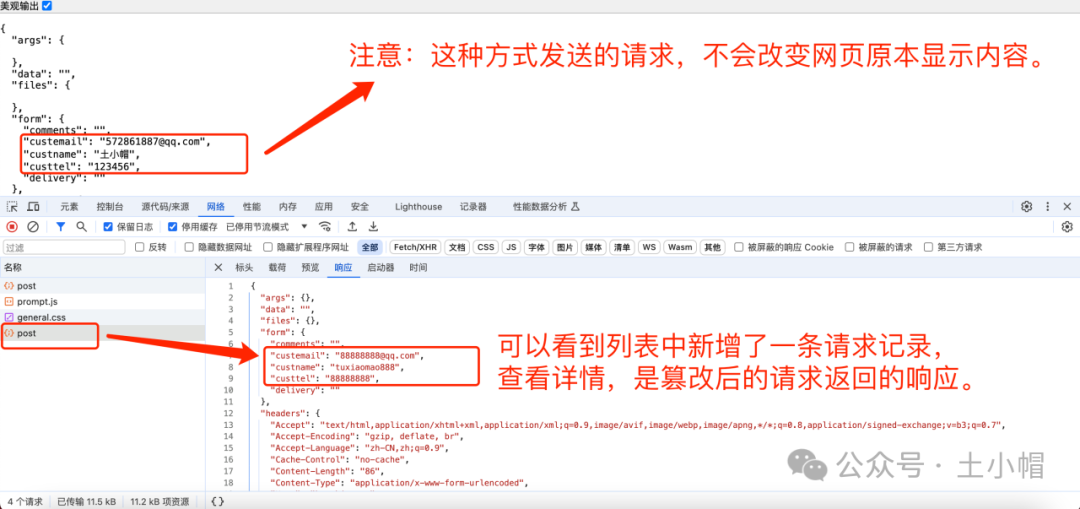
F12抓包05:Network接口测试(抓包篡改请求)
课程大纲 使用线上接口测试网站演示操作,浏览器F12检查工具如何进行简单的接口测试:抓包、复制请求、篡改数据、发送新请求。 测试地址:https://httpbin.org/forms/post ① 抓包:鼠标右键打开“检查”工具(F12…...
计算一个旋转矩形的四个顶点的函数boxPoints()的使用)
OPenCV结构分析与形状描述符(4)计算一个旋转矩形的四个顶点的函数boxPoints()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 找到一个旋转矩形的四个顶点。对于绘制旋转矩形很有用。 该函数找到一个旋转矩形的四个顶点。这个函数对于绘制矩形很有帮助。在C中,…...

【Matplotlib】利用Python进行绘图!(python数据分析与可视化)
文章开始前打个小广告——分享一份Python学习大礼包(激活码安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程)点击领取,100%免费! 【Matplotlib】 教程&…...

第二百二十节 JPA教程 - JPA 实体管理器删除示例
JPA教程 - JPA 实体管理器删除示例 我们可以使用JPA中的EntityManager来删除一个实体。 在下面的代码中,我们首先通过使用EntityManager中的find方法从数据库获取person对象,然后调用remove方法并传递person对象引用。 Person emp em.find(Person.cla…...

[TypeError] {message: “Cannot read property ‘‘ of undefined“}
11:11:25.500 [TypeError] {message: “Cannot read property ‘’ of undefined”} 11:11:25.586 [Vue warn]: Unhandled error during execution of render function \n at \nat \nat \nat \nat \nat \nat <V uniapp 使用报错 解决方法 页面加 v-if 来判断这个字…...

NIFI汉化_替换logo_二次开发_Idea编译NIFI最新源码_详细过程记录_全解析_Maven编译NIFI避坑指南001
由于需要对NFI进行汉化,以及二次开发,首先要下载源码以后编辑通过,NIFI的源码,项目非常多,编译过程中需要编译超过570个jar包,同时编译过程很慢需要30多分钟. 1.首先下载NIFI源码,根据需要下载对应版本: https://github.com/kemixkoo/orchsym-runtime/ 首先介绍一下,这个是一…...

项目在运行时,浏览器控制台出现 Uncaught ReferenceError: globalThis is not defined
项目场景: 背景: 项目在运行时,QQ浏览器控制台出现 Uncaught ReferenceError: globalThis is not defined … 错误信息 问题描述 问题: 错误信息如下所示: Uncaught ReferenceError: globalThis is not definedat r…...

图中点的层次
给定一个 nn 个点 mm 条边的有向图,图中可能存在重边和自环。 所有边的长度都是 11,点的编号为 1∼n1∼n。 请你求出 11 号点到 nn 号点的最短距离,如果从 11 号点无法走到 nn 号点,输出 −1−1。 输入格式 第一行包含两个整数…...

OpenClaw多模态研究助手:千问3.5-35B-A3B-FP8实现论文图表解析与笔记生成
OpenClaw多模态研究助手:千问3.5-35B-A3B-FP8实现论文图表解析与笔记生成 1. 为什么需要多模态研究助手 作为一名经常需要阅读前沿论文的研究者,我长期被两个问题困扰:一是PDF论文中的图表数据提取费时费力,二是阅读过程中的碎片…...

《高效能人士的七个习惯》:从内圣到外王的完整方法论
这本书在全世界卖了千万册,斯蒂芬柯维用七个习惯构建了一套从自我管理到影响他人的完整体系。一、前言:比七个习惯更重要的两件事 很多人读这本书只关注七个习惯本身,却忽略了前言中两个至关重要的前提: 1. 积极乐观是一切的起点 …...

告别假阳性!用TAGS多模态提示策略,精准提升你的医学影像分割模型性能
告别假阳性!用TAGS多模态提示策略,精准提升你的医学影像分割模型性能 医学影像分割一直是计算机辅助诊断中的核心挑战,尤其是肿瘤这类边界模糊、形态多变的病灶。传统方法依赖大量标注数据和复杂的后处理,而基础模型直接迁移又面临…...
技术情报报告)
双蒙皮声纳导流罩(Sonar Domes)技术情报报告
1. 概述 声纳导流罩(Sonar Dome)是安装在舰艇艏部或潜艇前端的流线型外壳,用于保护声纳换能器阵列,同时确保声学性能和水动力性能。现代声纳导流罩采用双蒙皮结构(Double-Skin Design),兼顾结构强度、轻量化、声学透明性和维护便捷性。 2. 双蒙皮结构设计特点 2.1 柯蒂…...

模力方舟:国内AI开发者的全流程加速平台
模力方舟:国内AI开发者的全流程加速平台 在AI技术快速发展的当下,如何让开发者更高效地将创意转化为实际应用成为行业关键命题。由Gitee推出的模力方舟(MoArk)平台,通过整合模型体验、微调训练、推理部署到应用变现的全流程能力,为…...

【自动驾驶C++部署黄金法则】:20年老司机亲授5大避坑指南,90%团队在第3步就翻车?
第一章:自动驾驶C部署的底层逻辑与行业现状 自动驾驶系统在量产落地过程中,C因其零成本抽象、确定性内存管理、硬实时支持能力及与硬件驱动/传感器SDK的天然兼容性,成为感知、规划、控制等核心模块部署的首选语言。其底层逻辑根植于对计算资源…...

避坑!这些毕设太好抄了,3000+毕设案例推荐第1038期
381、基于Java的对外公告智慧管理系统的设计与实现(论文+代码+PPT)对外公告智慧管理系统主要功能包括:会员管理、公告管理、审核任务、审核节点、审核日志、回复管理、通知管理、通知接收者、工作流管理、组织机构、消息推送、消息推送接收者…...

网络和并发 第五节:Python中的多线程
一、线程的相关概念 在Python中,想要实现多任务除了使用进程,还可以使用线程来完成,线程是实现多任务的另外一种方式。 1、什么是线程 线程是进程中执行代码的一个分支,每个执行分支(线程)要想工作执行代码需要cpu进行调度 ,也就是说线程是cpu调度的基本单位,每个进…...

解锁3大网页设计黑科技:从像素到原型的无缝转换
解锁3大网页设计黑科技:从像素到原型的无缝转换 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 作为设计师,你是否曾为获取网页设计灵感而频繁截图&#x…...

揭秘银行核心系统C++内存池配置:如何将GC停顿从200ms压至8μs?
第一章:银行核心系统内存管理的金融级挑战银行核心系统是金融基础设施的中枢,其内存管理不仅关乎性能,更直系交易一致性、资金安全与监管合规。毫秒级延迟抖动可能引发跨行清算超时,未释放的内存泄漏可在高并发批量代发场景下数小…...