Vision Transformer(ViT)模型原理及PyTorch逐行实现
Vision Transformer(ViT)模型原理及PyTorch逐行实现
一、TRM模型结构
1.Encoder
- Position Embedding 注入位置信息
- Multi-head Self-attention 对各个位置的embedding融合(空间融合)
- LayerNorm & Residual
- Feedforward Neural Network 对每个位置上单独仿射变换(通道融合)
- Linear1(large)
- Linear2(d_model)
- LayerNorm & Residual
2.Decoder
- Position Embedding
- Casual Multi-head Self-attention
- LayerNorm & Residual
- Memory-base Multi-head Cross-attention
- LayerNorm & Residual
- Feedforward Neural Network
- Linear1(large)
- Linear2(d_model)
- LayerNorm & Residual
二、TRM使用类型
- Encoder only 【 ViT 所使用的】
- BERT、分类任务、非流式任务
- Decoder only
- GPT系列、语言建模、自回归生成任务、流式任务
- Encoder-Decoder
- 机器翻译、语音识别
三、TRM特点
- 无先验假设(例如:局部关联性、有序建模性)
- 核心计算在于自注意力机制,平方复杂度
- 数据量的要求与归纳偏置【人类通过归纳法得到的经验,把这些经验带入到模型中,很多事物的共性】的引入成反比
四、Vision Transformer(ViT)
- DNN perspective 图像的信息量主要还是聚集在一块区域上
- image2patch 将图片切分成很多个块
- patch2embedding 将每个块转换为向量
- CNN perspective 从卷积的角度得到向量
- 2D convolution over image 二维卷积
- flatten the output feature map 把输出的卷积图拉直
- class token embedding 占位符
- position embedding
- interpolation when inference
- Transformer Encoder 只使用的Encoder
- classification head 最后分类
五、ViT论文讲解
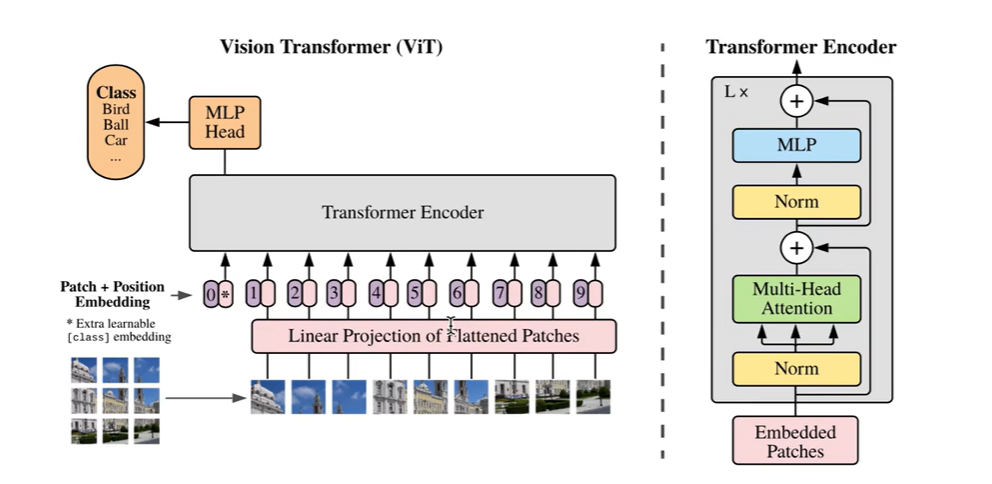
首先将一副图片分为很多个块,每个块的大小都是不会变化的,图片即使大一点,只是序列更长一点。先左到右,再上到下,把图片拉直成一个序列的形状。把每个块中的像素点进行归一化,范围变为0到1之间,再把块里面的所有值通过一个线性变换映射到模型的维度,得到patchembedding,得到以后,我们为了做分类任务,还需要在序列的开头加上一个可训练的embedding,这个是随机初始化的。这样就构造出了一个n+1长度的序列,然后我们再加入position embedding,加上后的这个序列的表征就可以送入到TRM的encoder当中,最后取出结果中的我们加入的可训练的embedding位置上的值(输出状态),经过一个MLP,得到各个类别的概率分布,再通过一个交叉熵函数算出分类的loss,这样就完成了一个ViT模型的搭建。
六、代码实现
1.convert image to embedding vector sequence
1.通过DNN实现
import torch
import torch.nn as nn
import torch.nn.functional as Fdef image2emb_naive(image,patch_size,weight):# image shape: bs*channel*h*wpatch = F.unfold(image,kernel_size=patch_size,stride=patch_size).transpose(-1,-2)patch_embedding = patch @ weightreturn patch_embedding# test code for image2emb
bs,ic,image_h,image_w=1,3,8,8
patch_size=4 # 每个块的大小为4*4(自定义)
model_dim=8 #将每个块映射成长度为8的向量(自定义)
patch_depth=patch_size*patch_size*ic
image=torch.randn(bs,ic,image_h,image_w) #初始化
weight=torch.randn(patch_depth,model_dim)#初始化patch_embedding_navie=image2emb_navie(image,patch_size,weight)
print(patch_embedding_naive.shape) # [1,4,8],分成四块了,每块对应一个长度为8的向量
2.通过CNN实现
import torch
import torch.nn as nn
import torch.nn.functional as Fdef image2emb_conv(image,kernel,stride):conv_output=F.conv2d(image,kernel,stride=stride) # bs*oc*oh*owbs,oc,oh,ow=conv_output.shapepatch_embedding=conv_output.reshape((bs,oc,oh*ow)).transpose(-1,-2)return patch_embedding# test code for image2emb
bs,ic,image_h,image_w=1,3,8,8
patch_size=4
model_dim=8
patch_depth=patch_size*patch_size*ic
image=torch.randn(bs,ic,image_h,image_w)
weight=torch.randn(patch_depth,model_dim) #model_dim是输出通道数目,patch_depth是卷积核的面积乘以输入通道数kernel=weight.transpose(0,1).reshape((-1,ic,patch_size,patch_size)) # oc*ic*kh*kw
patch_embedding_conv=image2emb_conv(image,kernel,patch_size) # 二维卷积的方法得到embedding
2.prepend CLS token embedding
cls_token_embedding = torch.randn(1,model_dim,requires_grad=True)
token_embedding = torch.cat([[bs,cls_token_embedding],patch_embedding_conv],dim=1)
提问:本身cls_token_embedding没有和任何样本矩阵有乘法联系,最后训练出来的也是一张确定的表,在做inference的时候,完全是一个常数的作用。送入transformer后,又与其他矩阵做了MHA,没搞懂用意何在啊?
答:有联系啊,就是与其他时刻的sample做MHSA。这个token其实是取代了avg pool的作用,也就是说,你可以用avg pool得到分类的logits,也可以用采用cls token来得到分类的logits
注意:cls_token_embedding作为batch_size中每一个序列的开始,应该对于每一个序列的开始都torch.cat同样的一个cls_token_embedding,然后都是对这同一个cls_token_embedding进行训练,所以这里的cls token embedding应该是二维的,1*model_dim,与batchsize无关。
3.add position embedding
max_num_token=16 #自定义
position_embedding_table = torch.randn(max_num_token,model_dim,requires_grad=True)
seq_len=token_embedding.shape[1] # 刚刚的1+4
position_embedding=torch.tile(position_embedding_table[:seq_len],[token_embedding.shape[0],1,1]) # 5,bs,1,1
token_embedding += position_embedding
4.pass embedding to Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim,nhead=8)
transformer_encoder=nn.TransformerEncoder(encoder_layer,num_layers=6)
encoder_output=transformer_encoder(token_embedding)
5.do classification
cls_token_output=encoder_output[:,0,:] #拿到TRM的输出值
num_classes=10 # 自定义的类别数目
label=torch.randint(10,(bs,)) # 自定义的生成的label
linear_layer = nn.Linear(model_dim,num_classes)
logits = linear_layer(cls_token_output)
loss_fn=nn.CrossEntropyLoss()
loss=loss_fn(logits,label)
print(loss)
相关文章:
Vision Transformer(ViT)模型原理及PyTorch逐行实现
Vision Transformer(ViT)模型原理及PyTorch逐行实现 一、TRM模型结构 1.Encoder Position Embedding 注入位置信息Multi-head Self-attention 对各个位置的embedding融合(空间融合)LayerNorm & ResidualFeedforward Neural Network 对每个位置上单…...

828华为云征文 | Flexus X实例CPU、内存及磁盘性能实测与分析
引言 随着云计算的普及,企业对于云资源的需求日益增加,而选择一款性能强劲、稳定性高的云实例成为了关键。华为云Flexus X实例作为华为云最新推出的高性能实例,旨在为用户提供更强的计算能力和更高的网络带宽支持。最近华为云828 B2B企业节正…...
队列)
FreeRTOS学习笔记(六)队列
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、队列的基本内容1.1 队列的引入1.2 FreeRTOS 队列的功能与作用1.3 队列的结构体1.4 队列的使用流程 二、相关API详解2.1 xQueueCreate2.2 xQueueSend2.3 xQu…...

【Python篇】PyQt5 超详细教程——由入门到精通(中篇一)
文章目录 PyQt5入门级超详细教程前言第4部分:事件处理与信号槽机制4.1 什么是信号与槽?4.2 信号与槽的基本用法4.3 信号与槽的基础示例代码详解: 4.4 处理不同的信号代码详解: 4.5 自定义信号与槽代码详解: 4.6 信号槽…...

LinuxQt下的一些坑之一
我们在使用Qt开发时,经常会遇到Windows上应用正常,但到Linux嵌入式下就会出现莫名奇妙的问题。这篇文章就举例分析下: 1.QPushButton按钮外侧虚线框问题 Windows下QPushButton按钮设置样式正常,但到了Linux下就会有一个虚线边框。…...

Statement batch
我们可以看到 Statement 和 PreparedStatement 为我们提供的批次执行 sql 操作 JDBC 引入上述 batch 功能的主要目的,是加快对客户端SQL的执行和响应速度,并进而提高数据库整体并发度,而 jdbc batch 能够提高对客户端SQL的执行和响应速度,其…...

PPP 、PPPoE 浅析和配置示例
一、名词: PPP: Point to Point Protocol 点到点协议 LCP:Link Control Protocol 链路控制协议 NCP:Network Control Protocol 网络控制协议,对于上层协议的支持,N 可以为IPv4、IPv6…...

【Python机器学习】词向量推理——词向量
目录 面向向量的推理 使用词向量的更多原因 如何计算Word2vec表示 skip-gram方法 什么是softmax 神经网络如何学习向量表示 用线性代数检索词向量 连续词袋方法 skip-gram和CBOW:什么时候用哪种方法 word2vec计算技巧 高频2-gram 高频词条降采样 负采样…...
)
Python 语法糖:让编程更简单(续二)
Python 语法糖:让编程更简单(续) 10. Type hints Type hints 是 Python 中的一种语法糖,用于指定函数或变量的类型。例如: def greet(name: str) -> None:print(f"Hello, {name}!")这段代码将定义一个…...

6 - Shell编程之sed与awk编辑器
目录 一、sed 1.概述 2.sed命令格式 3.常用操作的语法演示 3.1 输出符合条件的文本 3.2 删除符合条件的文本 3.3 替换符合条件的文本 3.4 插入新行 二、awk 1.概述 2. awk命令格式 3.awk工作过程 4.awk内置变量 5.awk用法示例 5.1 按行输出文本 5.2 按字段输出文…...

什么是XML文件,以及如何打开和转换为其他文件格式
本文描述了什么是XML文件以及它们在哪里使用,哪些程序可以打开XML文件,以及如何将XML文件转换为另一种基于文本的格式,如JSON、PDF或CSV。 什么是XML文件 XML文件是一种可扩展标记语言文件。它们是纯文本文件,除了描述数据的传输、结构和存储外,本身什么也不做。 RSS提…...

海外直播对网速、带宽、安全的要求
要满足海外直播的要求,需要拥有合适的网络配置。在全球化的浪潮下,海外直播正逐渐成为企业、个人和各类组织的重要工具。不论是用于市场推广、品牌宣传,还是与观众互动,海外直播都为参与者带来了丰富的机会。然而,确保…...

UWB定位室外基站
定位基站,型号SW,是一款基于无线脉冲技术开发的UWB定位基站,基站可用于人员、车辆、物资的精确定位, 该基站专为恶劣环境使用而设计,防尘、防水等级IP67,工业级标准支持365天连续运行,本安防爆可…...

高斯平面直角坐标讲解,以及地理坐标转换高斯平面直角坐标
高斯平面直角坐标系(Gauss-Krger 坐标系)是基于 高斯-克吕格投影 的一种常见的平面坐标系统,主要用于地理信息系统 (GIS)、测绘和工程等领域。该坐标系将地球表面的经纬度(地理坐标)通过一种投影方式转换为平面直角坐标,以便在二维平面中进行距离、面积和角度的计算。 一…...

C++入门(06)安装QT并快速测试体验一个简单的C++GUI项目
文章目录 1. 清华镜像源下载2. 安装3. 开始菜单上的 QT 工具4. 打开 Qt Creator5. 简单的 GUI C 项目5.1 打开 Qt Creator 并创建新项目5.2 设计界面5.3 添加按钮的点击事件5.4 编译并运行项目 6. 信号和槽(Signals and Slots) 这里用到了C类与对象的很多…...

一篇文章告诉你小程序为什么最近这么火?
微信小程序之所以最近这么火,主要得益于其低成本获取高流量、线上线下流量互换、社交裂变引爆流量以及封闭商业生态闭环等优势。下面将详细探讨小程序火爆的多个原因: 一篇文章告诉你小程序为什么这么火爆? 低成本获取高流量 无需安装注册&…...
Qt-常用控件(3)-多元素控件、容器类控件和布局管理器
1. 多元素控件 Qt 中提供的多元素控件有: QListWidgetQListViewQTableWidgetQTableViewQTreeWidgetQTreeView xxWidget 和 xxView 之间的区别,以 QTableWidget 和 QTableView 为例. QTableView 是基于 MVC 设计的控件.QTableView 自身不持有数据,使用 QTableView 的…...
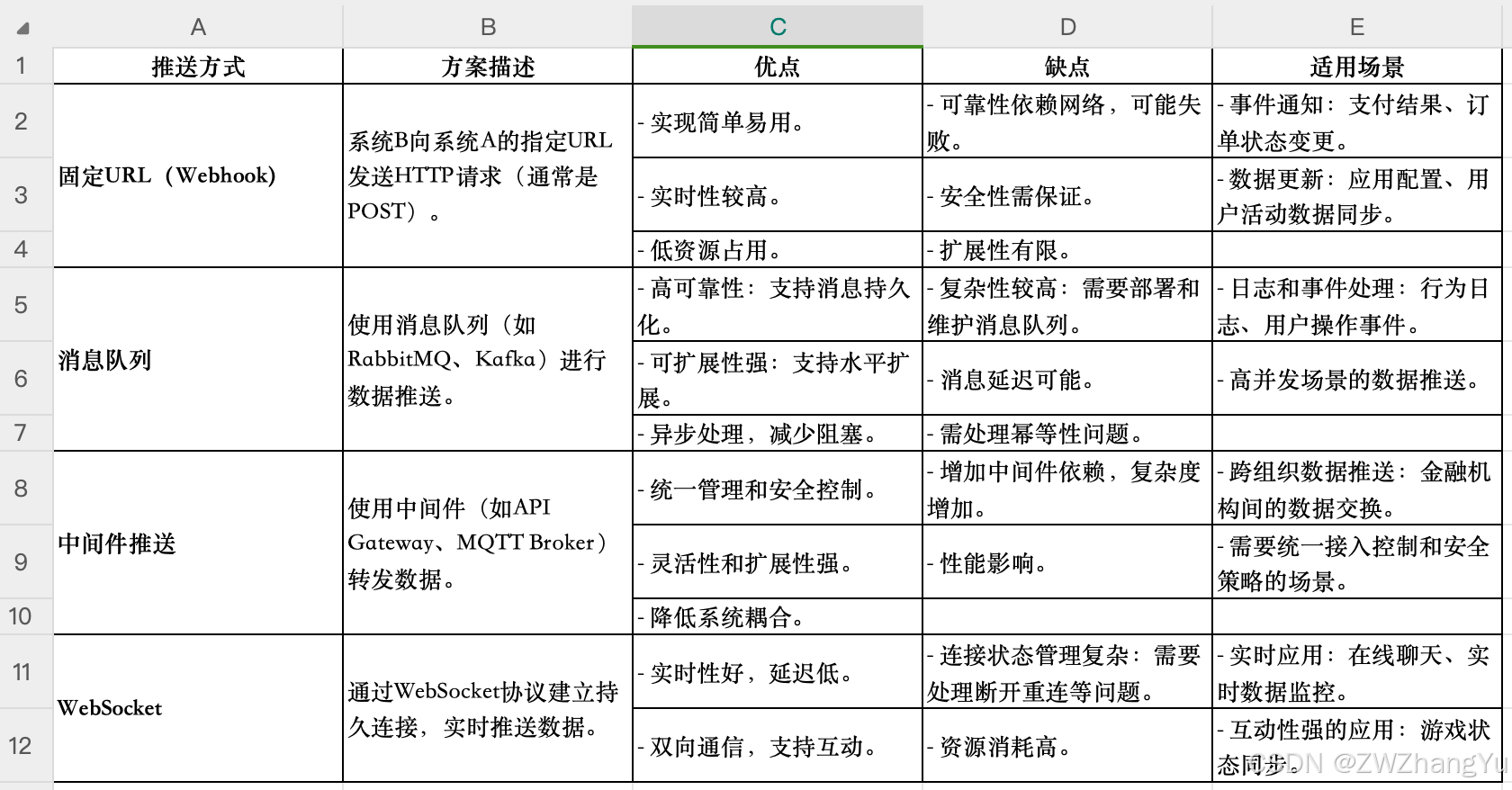
【系统设计】主动查询与主动推送:如何选择合适的数据传输策略
基本描述总结 主动查询机制:系统A主动向系统B请求数据,采用严格的权限控制和身份认证,防止未授权的数据访问。数据在传输过程中使用TLS加密,并通过动态脱敏处理隐藏敏感信息。 推送机制:系统B在数据更新时主动向系统…...

mac 安装brew并配置国内源
前置条件 - Xcode 命令行工具 一行代码安装Homebrew 添加到路径(PATH) - zsh shell为例 背景介绍 最近重装了我的MAC mini (m1 芯片), 很多软件都需要重新安装,因为后续还需要安装一些软件,所以想着安装个包管理软件 什么…...

Temu官方宣导务必将所有的点位材料进行检测-RSL资质检测
关于饰品类产品合规问题宣导: 产品法规RSL要求 RSL测试是根据REACH法规及附录17的要求进行测试。REACH法规是欧洲一项重要的法规,其中包含许多对化学物质进行限制的规定和高度关注物质。 为了确保珠宝首饰的安全性,欧盟REACH法规规定&#…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置
Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 还在为Redis环境配置而烦恼吗?还在为测试一个…...