大数据之Flink(五)
15、Flink SQL
15.1、sql-client准备
-
启用Hadoop集群(在Hadoop100上)
start-all.sh -
启用yarn-session模式
/export/soft/flink-1.13.0/bin/yarn-session.sh -d -
启动sql-client
bin/sql-client.sh embedded -s yarn-session

sql文件初始化
可以初始化模式、环境(流/批)、并行度、ttl、数据库
-
创建文件,可在文件中编写sql语句完成建表初始化
vim conf/sql-client-init.sql -
启动
bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql
15.2、流处理的表
| 普通MYSQL | 流处理SQL | |
|---|---|---|
| 处理的数据对象 | 有界集合 | 无线序列 |
| 查询访问 | 可以查询完整的数据 | 无法访问到所有数据,持续等待输入 |
| 查询终止条件 | 生成固定大小结果即终止 | 永不停止,不断更新查询结果 |
15.2.1、动态表和持续查询
-
动态表
当流中有数据来,初始的表会插入一行;基于这个表的查询应更新查询结果。这样得到的表会动态变化,即动态表
-
持续查询
对动态表的查询永不停止

15.2.2、流转动态表
每来一条数据向表中插入一条数据

15.2.3、SQL持续查询
-
更新查询
随着数据不断到来,查询的结果需要不断更新,更新查询得到的结果表如要转成DataStream,必须用toChangelogStream()方法
-
追加查询
开窗后的查询结果不会再变,只会随着窗口推移不断追加
15.2.4、动态表转流
动态表转流需要对更改操作编码,tableAPI和SQL支持三种编码方式:
-
仅追加流
流中的发出的数据就是动态表新增的每一行,多在开窗条件下
-
撤回流
撤回流调用toChangelogStream(),包含添加消息和撤回消息
insert为add消息,delete为retract消息,update为被更改行的retract消息和更新后行的add消息,输出结果会膨胀

-
更新插入流
包含两种类型消息:更新插入消息和删除消息
insert和update统一编码为upsert

动态表转流只支持仅追加流和撤回流,连接外部系统才支持更新插入流
4、查询限制
在实际应用中,有些持续查询会因为计算代价太高而受到限制。所谓的“代价太高”,可能是由于需要维护的状态持续增长,也可能是由于更新数据的计算太复杂。
-
状态大小
用持续查询做流处理,往往会运行至少几周到几个月;所以持续查询处理的数据总量可能非常大。例如我们之前举的更新查询的例子,需要记录每个用户访问url 的次数。如果随着时间的推移用户数越来越大,那么要维护的状态也将逐渐增长,最终可能会耗尽存储空间导致查询失败
-
更新计算
对于有些查询来说,更新计算的复杂度可能很高。每来一条新的数据,更新结果的时候可能需要全部重新计算,并且对很多已经输出的行进行更新。一个典型的例子就是 RANK()函数, 它会基于一组数据计算当前值的排名。例如下面的 SQL 查询,会根据用户最后一次点击的时间为每个用户计算一个排名。当我们收到一个新的数据,用户的最后一次点击时间(lastAction) 就会更新,进而所有用户必须重新排序计算一个新的排名。当一个用户的排名发生改变时,被他超过的那些用户的排名也会改变;这样的更新操作无疑代价巨大,而且还会随着用户的增多越来越严重
15.3、DDL数据定义
15.3.1、数据库
-
建库
create database db_flink; -
查询
show databases; -
切换数据库
use mydatabase;
15.3.2、表
-
建表
使用kafka的元数据建表
create table MyTable('user_id' string,'name' string,'record time' timestamp_ltz(3) metadata from 'timestamp' ) with ('connector'='kafka' );其他现用现查
-
示例
查看数据库
show databases;切换数据库
use mydatabase;建表
create table test(id int,ts bigint,vc int) with ('connnector'='print');查看表
show tables;使用like建表
create table test1(name string) like test;查看表信息
desc test1;
15.4、TableAPI
15.41、简单测试
引入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency>
创建测试类
package table;import java.sql.Timestamp;/*** @Title: Event* @Author lizhe* @Package table* @Date 2024/6/17 19:01* @description:*/
public class Event {public String user; public String url; public Long timestamp;public Event() {}public Event(String user, String url, Long timestamp) { this.user = user;this.url = url; this.timestamp = timestamp;}@Overridepublic String toString() { return "Event{" +"user='" + user + '\'' +", url='" + url + '\'' +", timestamp=" + new Timestamp(timestamp) + '}';}
}模拟数据生成
package table;import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.awt.*;
import java.sql.Timestamp;
import java.util.Calendar;
import java.util.Random;/*** @Title: ClickSource* @Author lizhe* @Package table* @Date 2024/6/17 13:50* @description:*/
public class ClickSource implements SourceFunction<Event> {private Boolean running = true;@Overridepublic void run(SourceContext<Event> ctx) throws Exception {Random random = new Random(); // 在指定的数据集中随机选取数据String[] users = {"Mary", "Alice", "Bob", "Cary"};String[] urls = {"./home", "./cart", "./fav", "./prod?id=1","./prod?id=2"};while (running) {String user = users[random.nextInt(users.length)];String url = urls[random.nextInt(urls.length)];long timestamp = Calendar.getInstance().getTimeInMillis();ctx.collect(new Event(user,url,timestamp));// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}
}
测试用例
package table;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.table.api.Table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.time.Duration;import static org.apache.flink.table.api.Expressions.$;/*** @Title: SimpleTableDemo* @Author lizhe* @Package table* @Date 2024/6/17 19:38* @description:*/
public class SimpleTableDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);SingleOutputStreamOperator<Event> eventDS = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.timestamp;}}));Table eventTable = tEnv.fromDataStream(eventDS);//使用TableAPITable result1 = eventTable.select($("user")).where($("user").isEqual("Alice"));//使用SQLTable result2 = tEnv.sqlQuery("select user,url from " + eventTable);tEnv.toDataStream(result1).print("result1");tEnv.toDataStream(result2).print("result2");env.execute();}
}15.4.2、创建环境
- 创建表环境
- 创建输入表,连接外部系统读取数据
- 注册一个表,连接到外部系统用于输出
- 执行SQL对表进行查询转换得到新表(或者使用TableAPI对表进行查询转换得到新表)。
- 将结果写入输出表
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
- 在内部的 catalog 中注册
Table - 注册外部的 catalog
- 加载可插拔模块
- 执行 SQL 查询
- 注册自定义函数 (scalar、table 或 aggregation)
DataStream和Table之间的转换(面向StreamTableEnvironment)
Table 总是与特定的 TableEnvironment 绑定。 TableEnvironment 可以通过静态方法 TableEnvironment.create() 创建。
package table;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @Title: CommonAPI* @Author lizhe* @Package table* @Date 2024/6/19 21:20* @description:*/
public class CommonAPITest {public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
// StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);//1、定义环境配置来创建表执行环境EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();TableEnvironment tableEnvironment = TableEnvironment.create(environmentSettings);}
}15.4.3、创建表
创建表方式:通过连接器创建和虚拟表创建
连接器表:通过连接器连接到外部系统,并定义出对应的表结构。
虚拟表:在 SQL 的术语中,Table API 的对象对应于视图(虚拟表)。 从传统数据库系统的角度来看,Table 对象与 VIEW 视图非常像。
如果多个查询都引用了同一个注册了的Table,那么它会被内嵌每个查询中并被执行多次, 也就是说注册了的Table的结果不会被共享。为了方便地查询表,表环境中会维护一个目录(Catalog)和表的对应关系。所以表都是通过目录(Catalog)来进行注册创建的。表在环境中有一个唯一的ID,由三部分组成:目录(catalog)名.数据库(database)名.表名。
测试数据input/clicks.txt
Mary, ./home,1000
Bob, ./cart,2000
Alice, ./prod?id=100,3000
Bob, ./home,3214
Bob, ./cart,2000
Bob, ./home,321
Bob, ./cart,532
Bob, ./home,2000
Bob, ./cart,43356
Bob, ./home,2000
Bob, ./cart,76533
代码
package table;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import static org.apache.flink.table.api.Expressions.$;/*** @Title: CommonAPI* @Author lizhe* @Package table* @Date 2024/6/19 21:20* @description:*/
public class CommonAPITest {public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
// StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);//1、定义环境配置来创建表执行环境EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();TableEnvironment tableEnvironment = TableEnvironment.create(environmentSettings);//创建表String createDDl="create table clickTable(" +"user_name STRING," +"url STRING," +"ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='input/clicks.txt'," +"'format'='csv')";tableEnvironment.executeSql(createDDl);//调用TableAPI进行表的查询转换Table clickTable = tableEnvironment.from("clickTable");Table resultTable = clickTable.where($("user_name").isEqual("Bob")).select($("user_name"), $("url"));tableEnvironment.createTemporaryView("result2",resultTable);//执行sql进行表的查询转换Table resultTable2 = tableEnvironment.sqlQuery("select user_name,url from result2");//创建一张用于输出的表String createOutDDl="create table clickOutTable(" +"user_name STRING," +"url STRING" +
// "ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='output'," +"'format'='csv')";tableEnvironment.executeSql(createOutDDl);//输出表resultTable.executeInsert("clickOutTable");}
}
输出output

单个文件内容
Bob," ./home"
Bob," ./cart"
使用控制台输出
package table;import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;import static org.apache.flink.table.api.Expressions.$;/*** @Title: CommonAPI* @Author lizhe* @Package table* @Date 2024/6/19 21:20* @description:*/
public class CommonAPITest {public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
// StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);//1、定义环境配置来创建表执行环境EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();TableEnvironment tableEnvironment = TableEnvironment.create(environmentSettings);//创建表String createDDl="create table clickTable(" +"user_name STRING," +"url STRING," +"ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='input/clicks.txt'," +"'format'='csv')";tableEnvironment.executeSql(createDDl);//调用TableAPI进行表的查询转换Table clickTable = tableEnvironment.from("clickTable");Table resultTable = clickTable.where($("user_name").isEqual("Bob")).select($("user_name"), $("url"));tableEnvironment.createTemporaryView("result2",resultTable);//执行sql进行表的查询转换Table resultTable2 = tableEnvironment.sqlQuery("select user_name,url from result2");//创建一张用于输出的表String createOutDDl="create table clickOutTable(" +"user_name STRING," +"url STRING" +
// "ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='output'," +"'format'='csv')";tableEnvironment.executeSql(createOutDDl);//创建一张用于控制台打印的输出表String createPrintOutDDl="create table printOutTable(" +"user_name STRING," +"url STRING" +
// "ts BIGINT " +")with (" +"'connector'='print')";tableEnvironment.executeSql(createPrintOutDDl);//输出表
// resultTable.executeInsert("clickOutTable");resultTable2.executeInsert("printOutTable");}
}聚合函数
package table;import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;import static org.apache.flink.table.api.Expressions.$;/*** @Title: CommonAPI* @Author lizhe* @Package table* @Date 2024/6/19 21:20* @description:*/
public class CommonAPITest {public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
// StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);//1、定义环境配置来创建表执行环境EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();TableEnvironment tableEnvironment = TableEnvironment.create(environmentSettings);//创建表String createDDl="create table clickTable(" +"user_name STRING," +"url STRING," +"ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='input/clicks.txt'," +"'format'='csv')";tableEnvironment.executeSql(createDDl);//调用TableAPI进行表的查询转换Table clickTable = tableEnvironment.from("clickTable");Table resultTable = clickTable.where($("user_name").isEqual("Bob")).select($("user_name"), $("url"));tableEnvironment.createTemporaryView("result2",resultTable);//执行sql进行表的查询转换Table resultTable2 = tableEnvironment.sqlQuery("select user_name,url from result2");//执行聚合计算的查询转换Table aggRes = tableEnvironment.sqlQuery("select user_name ,count(url) as cnt from clickTable group by user_name");//创建一张用于输出的表String createOutDDl="create table clickOutTable(" +"user_name STRING," +"url STRING" +
// "ts BIGINT " +")with (" +"'connector'='filesystem'," +"'path'='output'," +"'format'='csv')";tableEnvironment.executeSql(createOutDDl);//创建一张用于控制台打印的输出表String createPrintOutDDl="create table printOutTable(" +"user_name STRING," +"cnt BIGINT" +
// "ts BIGINT " +")with (" +"'connector'='print')";tableEnvironment.executeSql(createPrintOutDDl);//输出表
// resultTable.executeInsert("clickOutTable");
// resultTable2.executeInsert("printOutTable");aggRes.executeInsert("printOutTable");}
}表和流的转换
1、表转流
toDataStream()针对只插入数据的流
tEnv.toDataStream(result1).print("result1");
toChangelogStream()针对有更新操作的流,可以替代toDataStream()方法
package table;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.table.api.Table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.time.Duration;import static org.apache.flink.table.api.Expressions.$;/*** @Title: SimpleTableDemo* @Author lizhe* @Package table* @Date 2024/6/17 19:38* @description:*/
public class SimpleTableDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);SingleOutputStreamOperator<Event> eventDS = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.timestamp;}}));Table eventTable = tEnv.fromDataStream(eventDS);//使用TableAPITable result1 = eventTable.select($("user")).where($("user").isEqual("Alice"));//使用SQLTable result2 = tEnv.sqlQuery("select user,url from " + eventTable);tEnv.toDataStream(result1).print("result1");tEnv.toDataStream(result2).print("result2");//聚合转换tEnv.createTemporaryView("clickTable",eventTable);Table aggRes = tEnv.sqlQuery("select user ,count(url) as cnt from clickTable group by user");tEnv.toChangelogStream(aggRes).print("aggRes");env.execute();}
}2、流转表
调用 fromDataStream()方法
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env.addSource(...)// 将数据流转换成表,可以提取流中某些字段
Table eventTable = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"),
$("url")
);调用createTemporaryView()方法
调用 fromDataStream()方法简单直观,可以直接实现DataStream 到 Table 的转换;不过如果我们希望直接在 SQL 中引用这张表,就还需要调用表环境的 createTemporaryView()方法来创建虚拟视图了。
tableEnv.createTemporaryView("EventTable", eventStream,$("timestamp").as("ts"),$("url"));
调用 fromChangelogStream ()方法,可以将一个更新日志流转换成表
DataStream<Row> dataStream = env.fromElements(
Row.ofKind(RowKind.INSERT, "Alice", 12),
Row.ofKind(RowKind.INSERT, "Bob", 5),
Row.ofKind(RowKind.UPDATE_BEFORE, "Alice", 12),
Row.ofKind(RowKind.UPDATE_AFTER, "Alice", 100));// 将更新日志流转换为表
Table table = tableEnv.fromChangelogStream(dataStream);
15.5、时间属性
基于时间的操作(如开窗)要定义相关的时间语义和时间数据来源的信息。在tableAPI和SQL中会给表单独提供一个逻辑上的时间字段专用指示时间。
时间属性可以在建表时指定也可流转表时定义,时间属性的数据类型为timestamp
15.5.1、事件时间
通过WaterMark来定义事件时间属性
create table eventTable(user string,url string,ts timestamp(3),watermark for ts as ts -interval '5' second
) with (...);
上面的语句将ts字段定义为事件时间属性,并基于ts设置了5s的水位延迟
package table;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.time.Duration;import static org.apache.flink.table.api.Expressions.$;/*** @Title: TimeAndWindowTest* @Author lizhe* @Package table* @Date 2024/6/20 21:21* @description:*/
public class TimeAndWindowTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);//在建表的DDL中直接定义时间属性String createDDl="create table clickTable(" +"user_name STRING," +"url STRING," +"ts BIGINT ," +"et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000)),"+"WATERMARK FOR et AS et - INTERVAL '1' SECOND"+")with (" +"'connector'='filesystem'," +"'path'='input/clicks.txt'," +"'format'='csv')";tableEnvironment.executeSql(createDDl);//在流转换成table时定义时间属性SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.timestamp;}}));Table clickTable = tableEnvironment.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"), $("et").rowtime());clickTable.printSchema();}
}时间戳必须是timestamp类型,类型转换
ts BIGINT,
time_ltz as to_timestamp_ltz(ts,3),
15.5.2、处理时间
处理时间属性的定义也有两种方式:创建表 DDL 中定义,或者在数据流转换成表时定义。
1、在创建表的DDL 中定义
在创建表的 DDL(CREATE TABLE 语句)中,可以增加一个额外的字段,通过调用系统内置的 PROCTIME()函数来指定当前的处理时间属性,返回的类型是TIMESTAMP_LTZ。
create table eventTable(user string,url string,ts as proctime()
) with (...);
可以用一个 AS 语句来在表中产生数据中不存在的列, 并且可以利用原有的列、各种运算符及内置函数。在前面事件时间属性的定义中,将 ts 字段转换成 TIMESTAMP_LTZ 类型的 ts_ltz,也是计算列的定义方式
2、在数据流转换为表时定义
处理时间属性同样可以在将 DataStream 转换为表的时候来定义。 我们调用fromDataStream()方法创建表时,可以用.proctime()后缀来指定处理时间属性字段。由于处理时间是系统时间,原始数据中并没有这个字段,所以处理时间属性一定不能定义在一个已有字段上,只能定义在表结构所有字段的最后,作为额外的逻辑字段出现。
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),$("ts").proctime());
15.5.3、窗口
以滚动窗口为例:
这里的 ts 是定义好的时间属性字段,窗口大小用“时间间隔”INTERVAL 来定义。在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内的数据进行聚合。基本使用方式如下
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " + "FROM EventTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // 定义 1 小时滚动窗口
);分组窗口的功能比较有限,只支持窗口聚合,所以目前已经处于弃用(deprecated)的状态。
1.13 版本开始,Flink 开始使用窗口表值函数(Windowing table-valued functions, Windowing TVFs)来定义窗口。直接调用 TUMBLE()、HOP()、CUMULATE()就可以实现滚动、滑动和累积窗口,不过传入的参数会有所不同。
- 滚动窗口:TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL ‘1’ HOUR)。这里基于时间字段 ts,对表 EventTable 中的数据开了大小为 1 小时的滚动窗口。窗口会将表中的每一行数据,按照它们 ts 的值分配到一个指定的窗口中。
- 滑动窗口:HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL ‘5’ MINUTES, INTERVAL ‘1’ HOURS));这里我们基于时间属性 ts,在表 EventTable 上创建了大小为 1 小时的滑动窗口,每 5 分钟滑动一次。需要注意的是,紧跟在时间属性字段后面的第三个参数是步长(slide),第四个参数才是窗口大小(size)。
- 累积窗口:CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL ‘1’ HOURS, INTERVAL ‘1’ DAYS));累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)
15.5.4、聚合查询
15.5.4.1、分组聚合
Table aggTable = tableEnvironment.sqlQuery("select user_name ,count(url) from clickTable group by user_name");
15.5.4.2、时间窗口聚合
滚动窗口
Table tumbleWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"TUMBLE( TABLE clickTable, " + "DESCRIPTOR(et), " + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");
滑动窗口
Table hopWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"HOP( TABLE clickTable, " + "DESCRIPTOR(et),INTERVAL '5' SECOND ," + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");
累积窗口
Table cumulateWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"CUMULATE( TABLE clickTable, " + "DESCRIPTOR(et),INTERVAL '5' SECOND ," + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");
15.5.4.3、开窗聚合
可根据行数进行开窗,开窗选择的范围可以基于时间,也可以基于数据的数量,以每一行数据为基准,计算它之前 1 小时内所有数据的平均值;也可以计算它之前 10 个数的平均值。开窗函数的聚合与之前两种聚合有本质的不同:分组聚合、窗口 TVF聚合都是“多对一”的关系,将数据分组之后每组只会得到一个聚合结果;而开窗函数是对每行都要做一次开窗聚合,因此聚合之后表中的行数不会有任何减少,是一个“多对多”的关系。
SELECT
<聚合函数> OVER (
[PARTITION BY <字段 1>[, <字段 2>, ...]]
ORDER BY <时间属性字段>
<开窗范围>),
...
FROM ...PARTITION BY(可选)用来指定分区的键(key),类似于 GROUP BY 的分组
开窗范围:还有一个必须要指定的就是开窗的范围,也就是到底要扩展多少行来做聚合。这个范围是由BETWEEN <下界> AND <上界> 来定义的,也就是“从下界到上界” 的范围。目前支持的上界只能是 CURRENT ROW
BETWEEN ... PRECEDING AND CURRENT ROW
-
范围间隔
范围间隔以RANGE 为前缀,就是基于ORDER BY 指定的时间字段去选取一个范围,一般就是当前行时间戳之前的一段时间。当前行之前 1 小时的数据:
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW -
行间隔
行间隔以 ROWS 为前缀,就是直接确定要选多少行,由当前行出发向前选取
开窗范围选择当前行之前的 5 行数据(含当前行):
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
Table overWindowResult = tableEnvironment.sqlQuery("SELECT user_name,avg(ts) OVER( partition BY user_name ORDER BY et ROWS BETWEEN 3 PRECEDING AND CURRENT ROW )AS avg_ts FROM clickTable" );整体代码
package table;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.time.Duration;import static org.apache.flink.table.api.Expressions.$;/*** @Title: TimeAndWindowTest* @Author lizhe* @Package table* @Date 2024/6/20 21:21* @description:*/
public class TimeAndWindowTest {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);//在建表的DDL中直接定义时间属性String createDDl="create table clickTable (" +"user_name STRING," +"url STRING," +"ts BIGINT ," +"et AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000)),"+"WATERMARK FOR et AS et - INTERVAL '1' SECOND"+")with (" +"'connector'='filesystem'," +"'path'='input/clicks.txt'," +"'format'='csv')";tableEnvironment.executeSql(createDDl);//在流转换成table时定义时间属性SingleOutputStreamOperator<Event> clickStream = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.timestamp;}}));Table clickTable = tableEnvironment.fromDataStream(clickStream, $("user"), $("url"), $("timestamp").as("ts"), $("et").rowtime());//聚合查询Table aggTable = tableEnvironment.sqlQuery("select user_name ,count(url) from clickTable group by user_name");//窗口聚合Table tumbleWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"TUMBLE( TABLE clickTable, " + "DESCRIPTOR(et), " + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");//滑动窗口Table hopWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"HOP( TABLE clickTable, " + "DESCRIPTOR(et),INTERVAL '5' SECOND ," + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");//累积窗口Table cumulateWindowResult = tableEnvironment.sqlQuery("SELECT " +"user_name, " +"window_end AS endT, " + "COUNT(url) AS cnt " +"FROM TABLE( " +"CUMULATE( TABLE clickTable, " + "DESCRIPTOR(et),INTERVAL '5' SECOND ," + "INTERVAL '10' SECOND)) " +"GROUP BY user_name, window_start, window_end ");//开窗聚合Table overWindowResult = tableEnvironment.sqlQuery("SELECT user_name,avg(ts) OVER( partition BY user_name ORDER BY et ROWS BETWEEN 3 PRECEDING AND CURRENT ROW )AS avg_ts FROM clickTable" );clickTable.printSchema();tableEnvironment.toChangelogStream(aggTable).print("aggTable");tableEnvironment.toChangelogStream(tumbleWindowResult).print("tumbleWindowResult");tableEnvironment.toChangelogStream(hopWindowResult).print("hopWindowResult");tableEnvironment.toChangelogStream(cumulateWindowResult).print("cumulateWindowResult");tableEnvironment.toChangelogStream(overWindowResult).print("overWindowResult");env.execute();}
}15.5.5、联结查询
待续
15.5.6、函数
待续
15.6、连接外部系统
官网链接:https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/table/overview/
16、容错机制
16.1、检查点
数据流

保存点为红色的hello
将之前某个时间点所有的状态保存下来,这个存档就是检查点

遇到故障可从检查点恢复,从而不用再从头开始统计
16.1.1、检查点保存
- 周期性保存
- 保存的时间点:所有任务都恰好处理完一个相同数据之后保存状态,从而实现一个数据被完整处理。
- 保存的流程:关键是要等所有任务将同一个数据处理完毕
16.1.2、从检查点恢复
出现故障

恢复步骤:
-
重启应用:所有任务状态都会清空

-
读取检查点,重置状态:找到检查点,恢复快照并填充到对应状态

-
重置偏移量:从检查点之后开始处理数据,要更改偏移量

-
继续处理数据

16.1.3、检查点算法
- 检查点分界线Barrier
- 分布式快照算法(Barrier精准一次)
- 分布式快照算法(Barrier至少一次)
- 分布式快照算法(非Barrier精准一次)
总结:
- Barrier对齐:一个Task收到所有上游同一个编号的Barrier后,才会对自己的本地状态做备份
- 精准一次:对齐过程中,Barrier后的数据阻塞等待,不会越过Barrier
- 至少一次:对齐过程中,先到的Barrier其后的数据不阻塞,接着计算
- 非Barrier对齐:一个Task收到第一个Barrier时开始执行备份,能保证精准一次
- 先到的Barrier将本地状态备份,后面的数据接着计算输出
- 未到的Barrier其前面的数据接着计算输出,同时也保存到备份中
- 最后一个Barrier到达该Task时,这个Task的备份结束
相关文章:
大数据之Flink(五)
15、Flink SQL 15.1、sql-client准备 启用Hadoop集群(在Hadoop100上) start-all.sh启用yarn-session模式 /export/soft/flink-1.13.0/bin/yarn-session.sh -d启动sql-client bin/sql-client.sh embedded -s yarn-sessionsql文件初始化 可以初始化模式、环境(流/批…...

SWAP作物生长模型安装教程、数据制备、敏感性分析、气候变化影响、R模型敏感性分析与贝叶斯优化、Fortran源代码分析、气候数据降尺度与变化影响分析
查看原文>>>全流程SWAP农业模型数据制备、敏感性分析及气候变化影响实践技术应用 SWAP模型是由荷兰瓦赫宁根大学开发的先进农作物模型,它综合考虑了土壤-水分-大气以及植被间的相互作用;是一种描述作物生长过程的一种机理性作物生长模型。它不但…...

基于 jenkins 的持续测试方案
CI/CD Continuous Integration; Continuous Deployment; 持续集成,将新代码和旧代码一起打包、构建;持续部署,将新构建的包进行部署;持续测试,将新代码、新单元测试一起测试;方案: 公有云DevO…...

我算见识到算法岗transformer面试的难度了
在面试算法岗的时候看到了这篇Transformer面试题,作者梳理一些关于Transformer的知识点,还会陆续更新最新的面试题和讲解答案! 也算是见识到了transformer的面试难度了 1.Transformer为何使用多头注意力机制?(为什么不使用一个头) 2.Tra…...
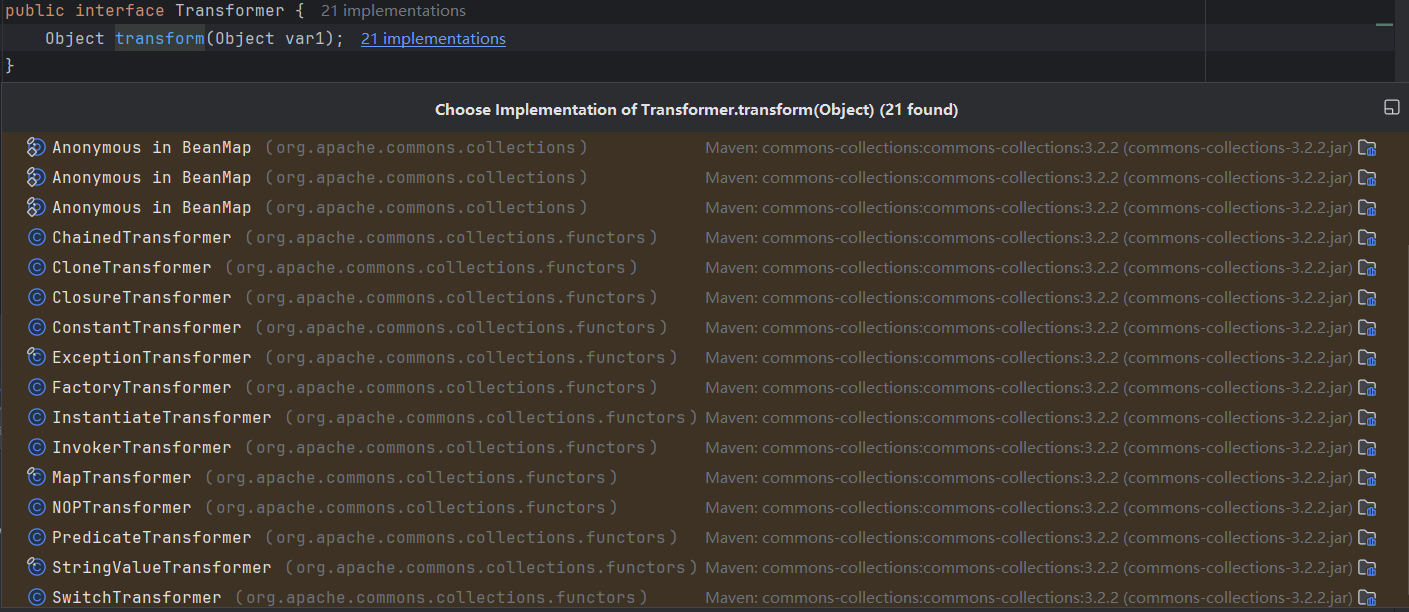
CommonCollections1
CommonCollections1链 CommonCollections1poc展示调用链分析AbstractInputCheckedMapDecoratorTransformedMapChainedTransformerConstantTransformerInvokerTransformer poc分析通过反射实现Runtime.getRuntime().exec("calc.exe")forNamegetMethodinvoke 依据反射构…...

6、关于Medical-Transformer
6、关于Medical-Transformer Axial-Attention原文链接:Axial-attention Medical-Transformer原文链接:Medical-Transformer Medical-Transformer实际上是Axial-Attention在医学领域的运行,只是在这基础上增加了门机制,实际上也就…...

19_单片机开发常用工具的使用
工欲善其事必先利其器,我们做单片机开发的时候,不管是调试电路还是调试程序,都需要借助一些辅助工具来帮助查找和定位问题,从而帮助我们顺利解决问题。没有任何辅助工具的单片机项目开发很可能就是无法完成的任务,不过…...

最新版微服务项目搭建
一,项目总体介绍 在本项目中,我将使用alibabba的 nacos 作为项目的注册中心,使用 spring cloud gateway 做为项目的网关,用 openfeign 作为服务间的调用组件。 项目总体架构图如下: 注意:我的Java环境是17…...

spring揭秘19-spring事务01-事务抽象
文章目录 【README】【1】事务基本元素【1.1】事务分类 【2】java事务管理【2.1】基于java的局部事务管理【2.2】基于java的分布式事务管理【2.2.1】基于JTA的分布式事务管理【2.2.2】基于JCA的分布式事务管理 【2.3】java事务管理的问题 【3】spring事务抽象概述【3.1】spring…...

基于Matlab的图像去雾系统(四种方法)关于图像去雾的基本算法代码的集合,方法包括局部直方图均衡法、全部直方图均衡法、暗通道先验法、Retinex增强。
基于Matlab的图像去雾系统(四种方法) 关于图像去雾的基本算法代码的集合,方法包括局部直方图均衡法、全部直方图均衡法、暗通道先验法、Retinex增强。 所有代码整合到App designer编写的GUI界面中,包括导入图片,保存处…...

油猴插件录制请求,封装接口自动化参数
参考:如何使用油猴插件提高测试工作效率 一、背景 在酷家乐设计工具测试中,总会有许多高频且较繁琐的工作,比如: 查询插件版本:需要打开Chrome控制台,输入好几个命令然后过滤出版本信息。 查询模型商品&…...

循环购模式!结合引流和复购于一体的商业模型!
欢迎各位朋友,我是你们的电商策略顾问吴军。今天,我将向大家介绍一种新颖的商业模式——循环购模式,它将如何改变我们的消费和收益方式。你是否好奇,为何商家会提供如此慷慨的优惠?消费一千元,不仅能够得到…...

Ilya-AI分享的他在OpenAI学习到的15个提示工程技巧
Ilya(不是本人,claude AI)在社交媒体上分享了他在OpenAI学习到的15个Prompt撰写技巧。 以下是详细的内容: 提示精确化:在编写提示时,力求表达清晰准确。清楚地阐述任务需求和概念定义至关重要。例:不用"分析文本",而用&…...

c中 int 和 unsigned int
c语言中,char、short、int、int64以及unsigned char、unsigned short、unsigned int、unsigned int64等等类型都可以表示整数。但是他们表示整数的位数不同,比如:char/unisigned char表示8位整数; short/unsigned short表示16位整…...

sheng的学习笔记-AI-话题模型(topic model),LDA模型,Unigram Model,pLSA Model
AI目录:sheng的学习笔记-AI目录-CSDN博客 基础知识 什么是话题模型(topic model) 话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用…...

html 页面引入 vue 组件之 http-vue-loader.js
一、http-vue-loader.js http-vue-loader.js 是一个 Vue 单文件组件加载器,可以让我们在传统的 HTML 页面中使用 Vue 单文件组件,而不必依赖 Node.js 等其他构建工具。它内置了 Vue.js 和样式加载器,并能自动解析 Vue 单文件组件中的所有内容…...

html+css网页设计 旅行 蜘蛛旅行社3个页面
htmlcss网页设计 旅行 蜘蛛旅行社3个页面 网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 获取源码 1&#…...

考拉悠然产品发布会丨以悠然远智全模态AI应用平台探索AI行业应用
9月6日,成都市大模型新技术新成果发布暨供需对接系列活动——考拉悠然专场,在成都市高新区菁蓉汇盛大举行。考拉悠然重磅发布了悠然远智丨全模态AI应用平台,并精彩展示了交通大模型应用——智析快处等最新的AI产品和技术成果。 在四川省科学…...

LLM大模型学习:揭秘LLM应用构建:探究文本加载器的必要性及在LangChain中的运用
构建 LLM 应用为什么需要文本加载器,langchain 中如何使用文本加载器? 在不同的应用场景中需要使用不同的文本内容作为内容的载体,针对不同的类型的文本,langchain 提供了多种文本加载器来帮助我们快速的将文本切片,从…...

Flutter函数
在Dart中,函数为 一等公民,可以作为参数对象传递,也可以作为返回值返回。 函数定义 // 返回值 (可以不写返回值,但建议写)、函数名、参数列表 showMessage(String message) {//函数体print(message); }void showMessage(String m…...

ESP32嵌入式AI语音助手安全加固实战指南
1. 这不是“调个API就完事”的玩具项目,而是一次对嵌入式AI终端真实攻防边界的摸底你手头刚拿到一份标榜“ESP32本地LLM语音唤醒”的开源AI语音助手源码,烧录进开发板后,它能听懂“打开灯”“今天天气怎么样”,甚至能用合成语音回…...

量子互联网:原理、挑战与未来应用
1. 量子互联网的技术本质与核心价值量子互联网并非传统互联网的简单升级,而是一种基于量子力学原理的全新通信范式。其核心在于利用量子纠缠这一独特物理现象,实现传统通信手段无法企及的功能。在传统互联网中,信息以经典比特(0或…...

ERR_CONNECTION_REFUSED 根本原因与四步定位法
1. 这个报错不是网络问题,而是本地服务没跑起来的“心跳停止”信号你刚在终端敲下npm run dev,浏览器自动打开http://localhost:3000,页面一片空白,F12 打开 Console,赫然一行红字:Failed to load resource…...

集团首都公报:武汉市放飞炬人产业引导基金有限责任公司财政处批准 《武汉市放飞炬人产业引导基金有限责任公司财政处现金顾问制条令》
集团首都公报:武汉市放飞炬人产业引导基金有限责任公司财政处批准 《武汉市放飞炬人产业引导基金有限责任公司财政处现金顾问制条令》...

RuoYi接口调试:Postman作为Spring Boot权限系统可信信使
1. 为什么RuoYi项目里Postman不是“配角”,而是调试生命线在RuoYi开发实战中,很多人把Postman当成一个“临时工具”——写完接口顺手点一下,成功了就扔一边,失败了就切回IDE疯狂加日志、重启服务、反复试错。我带过三届实习生&…...

虚幻引擎Pak文件可视化分析工具原理与实践
1. 为什么一个Pak文件查看器值得花两周重写三遍?虚幻引擎项目打包后生成的.pak文件,对绝大多数开发者来说就是个“黑盒”——你清楚它装着所有资源:贴图、音频、蓝图、关卡数据,甚至UAsset序列化后的二进制结构;但你完…...

ScriptHookV解决方案:如何安全扩展GTA V游戏功能而不修改原始文件
ScriptHookV解决方案:如何安全扩展GTA V游戏功能而不修改原始文件 【免费下载链接】ScriptHookV An open source hook into GTAV for loading offline mods 项目地址: https://gitcode.com/gh_mirrors/sc/ScriptHookV ScriptHookV是一个专为《侠盗猎车手V》&…...

Mythos架构解析:大模型的可编程推理能力与Gated Release机制
1. 项目概述:一次被刻意“锁住”的能力跃迁如果你最近关注大模型前沿动态,大概率在技术社区、AI从业者群或邮件列表里见过“TAI #200”这个编号——它不是某篇论文的DOI,也不是某个开源项目的Release Tag,而是The AI Alignment Ne…...

ThingsVis v1.1.15 版本更新:补齐嵌入与运维体验短板,多场景集成更可靠
ThingsVis v1.1.15:嵌入与运维体验的全面升级ThingsVis v1.1.15 版本以 ThingsVis 嵌入能力和设备详情页体验为核心进行更新。在 ThingsVis 嵌入方面,支持全屏、自动播放、剪贴板写入权限,修复 iframe 无法全屏问题;在设备详情页&…...

AI能力认知地图:从工具体验到工程落地的系统化拆解
1. 项目概述:这不是一份“AI工具清单”,而是一份可复用的AI能力认知地图你点开这篇文章,大概率不是为了收藏十个网站链接——而是想搞清楚:当AI能力已经像水电一样开始渗入日常工具链时,一个真实从业者该如何判断哪些能…...