论文解析一: SuperPoint 一种自监督网络框架,能够同时提取特征点的位置以及描述子
目录
- SuperPoint:一种自监督网络框架,能够同时提取特征点的位置以及描述子
- 1.特征点预训练
- 2.自监督标签
- 3.整体网络结构
- 3.1 先对图像进行卷积
- 3.2 特征点提取部分(Interest Point Decoder)
- 3.3 特征描述子提取部分(Descriptor Decoder)
- 3.4 损失函数
- 4.实验结果对比 和 不足
- 5.整体代码详解
SuperPoint:一种自监督网络框架,能够同时提取特征点的位置以及描述子
**传统方法的问题:**基于图像块的算法导致特征点位置精度不够准确;特征点与描述子分开进行训练导致运算资源的浪费,网络不够精简,实时性不足;仅仅训练特征点或者描述子的一种,不能用同一个网络进行联合训练。
如下图整个训练流程分为三部分:
(a)Inter Point Pre-Training(特征点预训练)
(b)Interest Point Self-Labeling(自监督标签)
(c)Joint Training (联合训练)

1.特征点预训练
创建合成数据集 Synthetic Shapes(Labeled Interest Point Images ) 利用合成数据集训练的检测器成MagicPoint(Base Detector)虽然是在合成的数据集上进行训练的,但是论文中提到MagicPoint在Corner-Like Structure(角点类似结构)的现实场景也具备一定的泛化能力,而面对更加普遍的场景,MagicPoint的效果就会下降,为此作者增加了第二步,即Homographic Adaption,第二步 自监督标签。
2.自监督标签


3.整体网络结构
SuperPoint的网络结构如下图所示:

3.1 先对图像进行卷积
图像特征通常包括两部分,特征点和特征描述子,上图中两个分支即分别同时提取特征点和特征描述子。网络首先使用了VGG-Style的Encoder用于降低图像尺寸提取特征,Encoder部分由卷积层、Max-Pooling层和非线性激活层组成,通过三个Max-Pooling层将图像尺寸变为输出的1/8,代码如下:
# Shared Encoder
x = self.relu(self.conv1a(data['image']))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x)) # x的输出维度是(N,128,W/8, H/8)
# N代表样本数量
# 128 表示特征图的通道数 代表输出 x 中包含了 128 个不同的特征图,每个特征图都捕获了输入数据中的不同特征信息
# W/8, H/8 特征图的宽度和高度相对于初始输入图片的尺寸已经缩小了 8 倍。
3.2 特征点提取部分(Interest Point Decoder)
对于特征点提取部分,网络先将维度( W / 8 , H / 8 , 128 )的特征处理为( W / 8 , H / 8 , 65 )大小,这里的65的含义是特征图的每一个像素表示原图8 × 8 的局部区域加上一个当局部区域不存在特征点时用于输出的Dustbin通道,通过Softmax以及Reshape的操作,最终特征会恢复为原图大小。
其中65 是 = 64 +1 先把128通道数 变为64通道数 ,再加一个参数层(Dustbin通道),这一层是为了8×8的局部区域内没有特征点时,经过Softmax后64维的特征势必还是会有一个相对较大的值输出,但加入Dustbin通道后就可以避免这个问题。
然后对得到的特征图,进行**归一化(Softmax)和纬度变化(Reshape)**操作。
具体代码如下:
# 计算密集关键点分数cPa = self.relu(self.convPa(x)) # x维度是(N,128,W/8, H/8)scores = self.convPb(cPa) # scores维度是(N,65,W/8, H/8)#下面这为什么由65 变为 64 了,是因为对 scores 进行 softmax(归一化操作)操作,得到概率分布,并且去掉最后一个通道#这样最后一个参数层便可以去掉了scores = torch.nn.functional.softmax(scores, 1)[:, :-1] # scores维度是(N,64,W/8, H/8)#获取 scores 的形状信息,在这里,scores 是一个四维张量,表示为(batch_size(数据的批量大小), channels, height, width)b, _, h, w = scores.shapescores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8) # 进行纬度变化 scores维度是(N,W/8, H/8, 8, 8)scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8) # 再次进行纬度变化 scores维度是(N,W/8, H/8)#对 scores 进行非极大值抑制(NMS)处理,为了进一步提取关键点或者去除冗余信息,并得到关键点分数scores = simple_nms(scores, self.config['nms_radius'])
3.3 特征描述子提取部分(Descriptor Decoder)
对于特征描述子提取部分,同理,我们还是使用encoder层的输出(H,W,128)。经过卷积解码器得到(H,W,256),双线性插值扩大尺寸(H,W,256),最后对每一个像素的描述子(256维)进行L2归一化。

双三次插值(Bicubic Interpolation)是一种常用的图像处理和计算机图形学中的插值方法,用于在离散网格上对图像进行平滑的插值,它可以用于放大或缩小图像,并且相比线性插值更能保持图像细节和平滑度。
3.4 损失函数
首先我们看下基于特征点和特征向量是如何建立损失函数的,损失函数公式如下:

4.实验结果对比 和 不足

可以看到第四行SuperPoint的表现其实很差,我们知道单应变化成立的前提条件是场景中存在平面,而第四行的场景很显然不太满足这种条件,因此效果也会比较差,这也体现了SuperPoint在自监督训练下的一些不足之处。
5.整体代码详解
from pathlib import Path
import torch
from torch import nn#非极大值抑制(Non-maximum Suppression,NMS)算法,用于移除邻近的点以实现特征点的稀疏化
def simple_nms(scores, nms_radius: int):""" Fast Non-maximum suppression to remove nearby points """assert(nms_radius >= 0)def max_pool(x):return torch.nn.functional.max_pool2d(x, kernel_size=nms_radius*2+1, stride=1, padding=nms_radius)zeros = torch.zeros_like(scores)max_mask = scores == max_pool(scores)for _ in range(2):supp_mask = max_pool(max_mask.float()) > 0supp_scores = torch.where(supp_mask, zeros, scores)new_max_mask = supp_scores == max_pool(supp_scores)max_mask = max_mask | (new_max_mask & (~supp_mask))return torch.where(max_mask, scores, zeros)#用于移除位于图像边界附近的关键点
def remove_borders(keypoints, scores, border: int, height: int, width: int):""" Removes keypoints too close to the border """mask_h = (keypoints[:, 0] >= border) & (keypoints[:, 0] < (height - border))mask_w = (keypoints[:, 1] >= border) & (keypoints[:, 1] < (width - border))mask = mask_h & mask_wreturn keypoints[mask], scores[mask]#从关键点集合中选择具有最高分数的前 k 个关键点
def top_k_keypoints(keypoints, scores, k: int):if k >= len(keypoints):return keypoints, scoresscores, indices = torch.topk(scores, k, dim=0)return keypoints[indices], scores#在关键点位置对描述子进行插值采样 双线性差值
def sample_descriptors(keypoints, descriptors, s: int = 8):""" Interpolate descriptors at keypoint locations """b, c, h, w = descriptors.shapekeypoints = keypoints - s / 2 + 0.5keypoints /= torch.tensor([(w*s - s/2 - 0.5), (h*s - s/2 - 0.5)],).to(keypoints)[None]keypoints = keypoints*2 - 1 # normalize to (-1, 1)args = {'align_corners': True} if int(torch.__version__[2]) > 2 else {}descriptors = torch.nn.functional.grid_sample(descriptors, keypoints.view(b, 1, -1, 2), mode='bilinear', **args)descriptors = torch.nn.functional.normalize(descriptors.reshape(b, c, -1), p=2, dim=1)return descriptorsclass DetectNet(nn.Module):default_config = {'descriptor_dim': 256,'nms_radius': 4,'keypoint_threshold': 0.005,'max_keypoints': -1,'remove_borders': 4,}def __init__(self, config):super().__init__()#根据默认配置和传入的配置参数合并生成最终的配置self.config = {**self.default_config, **config}self.relu = nn.ReLU(inplace=True)# 定义一个使用inplace操作的ReLU激活函数self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 定义一个最大池化层,kernel_size为卷积核大小,stride为步长c1, c2, c3, c4, c5 = 64, 64, 128, 128, 256 # 定义了5个通道数变量# 定义一系列的卷积层self.conv1a = nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)#输入数据的通道数,输出数据的通道数,即卷积核的数量self.conv1b = nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)self.conv2a = nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)self.conv2b = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)self.conv3a = nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)self.conv3b = nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)self.conv4a = nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)self.conv4b = nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)# 定义两个卷积层,用于处理像素位置(P)和描述子(D)self.convPa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)self.convPb = nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)self.convDa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)self.convDb = nn.Conv2d(c5, self.config['descriptor_dim'],kernel_size=1, stride=1, padding=0)#声明全连接层# self.fc = nn.Linear(128 * 64 * 64, 128 * 64 * 64) # 输入特征维度为 128*64*64,输出维度为 128 * 64 * 64#声明卷积层self.conv5a = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, padding=0)path = self.config['weights'] #从模型配置中获取预训练权重文件的路径pretrained_dict = torch.load(str(path))#使用torch.load 函数加载预训练模型的权重参数,将其存储在 pretrained_dict 中。model_dict = self.state_dict()#获取当前模型的状态字典,即当前模型的权重参数。#遍历预训练模型的权重参数,只保留那些在当前模型状态字典中存在的键值对,生成一个新的字典 pretrained_dict,用于更新当前模型的参数。pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}# 更新字典model_dict.update(pretrained_dict)#pretrained_dict 中的权重参数更新到当前模型的状态字典 model_dict 中。self.load_state_dict(model_dict, strict=False)mk = self.config['max_keypoints']#获取配置中的最大关键点数if mk == 0 or mk < -1:#如果最大关键点数为 0 或者小于 -1,则抛出值错误。raise ValueError('\"max_keypoints\" must be positive or \"-1\"')print('Loaded DetectNet model')def forward(self, data):""" Compute keypoints, scores, descriptors for image """# Shared Encoder 共享编码器# x = self.relu(self.conv1a(data['image']))x = self.relu(self.conv1a(data))x = self.relu(self.conv1b(x))x = self.pool(x)x = self.relu(self.conv2a(x))x = self.relu(self.conv2b(x))x = self.pool(x)x = self.relu(self.conv3a(x))x = self.relu(self.conv3b(x))x = self.pool(x)x = self.relu(self.conv4a(x))x = self.relu(self.conv4b(x))#(1,128,64,64)x = self.relu(self.conv5a(x)) # (1,128,64,64)# # 将 x 展平为一维向量,以便作为全连接层的输入# x = x.view(x.size(0), -1)# #全连接层的输入# x = self.fc(x)# # 将 x 展开为(1, 128, 64, 64)的维度# x = x.view(1, 128, 64, 64)# Compute the dense keypoint scores 计算稠密关键点分数 Interest Point Decoder(特征点提取部分)cPa = self.relu(self.convPa(x))#(1,256,64,64)scores = self.convPb(cPa)#(1,65,64,64)scores = torch.nn.functional.softmax(scores, 1)[:, :-1]#(1,64,64,64) #Softmax函数将分数转换为概率,然后删除最后一个通道,即无效通道b, _, h, w = scores.shape #scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8)scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8)scores = simple_nms(scores, self.config['nms_radius'])#对 scores 进行非极大值抑制(NMS)处理,为了进一步提取关键点或者去除冗余信息,并得到关键点分数# Extract keypoints 提取关键点keypoints = [torch.nonzero(s > self.config['keypoint_threshold'])for s in scores]scores = [s[tuple(k.t())] for s, k in zip(scores, keypoints)]# Discard keypoints near the image borders 丢弃靠近图像边界的关键点keypoints, scores = list(zip(*[remove_borders(k, s, self.config['remove_borders'], h*8, w*8)for k, s in zip(keypoints, scores)]))# Keep the k keypoints with highest score 保留得分最高的 k 个关键点if self.config['max_keypoints'] >= 0:keypoints, scores = list(zip(*[top_k_keypoints(k, s, self.config['max_keypoints'])for k, s in zip(keypoints, scores)]))# Convert (h, w) to (x, y) 将 (h, w) 转换为 (x, y)keypoints = [torch.flip(k, [1]).float() for k in keypoints]# Compute the dense descriptors 计算稠密描述符 Descriptor Decoder 特征描述子提取部分cDa = self.relu(self.convDa(x))#(1,256,64,64)descriptors = self.convDb(cDa)#(1,256,64,64)descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1)#(1,256,64,64) #对描述子进行 L2 归一化# Extract descriptors 提取描述符 从关键点位置对描述子进行插值采样descriptors = [sample_descriptors(k[None], d[None], 8)[0]for k, d in zip(keypoints, descriptors)]return {'keypoints': keypoints,'scores': scores,'descriptors': descriptors,}
相关文章:
论文解析一: SuperPoint 一种自监督网络框架,能够同时提取特征点的位置以及描述子
目录 SuperPoint:一种自监督网络框架,能够同时提取特征点的位置以及描述子1.特征点预训练2.自监督标签3.整体网络结构3.1 先对图像进行卷积3.2 特征点提取部分(Interest Point Decoder)3.3 特征描述子提取部分(Descrip…...

【评估指标】Fβ-score
1. Fβ-score 概述 Fβ-score 是一种综合考量精确率(precision)和召回率(recall)的分类评估指标。其公式为: 1.1 Precision(精确率):预测为正类的样本中,实际为正类的比…...

1963Springboot个性化音乐推荐管理系统idea开发mysql数据库web结构java编程计算机网页源码maven项目
博主介绍:专注于Java .net php phython 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找不到哟 我的博客空间发布了1000毕设题目 方便大家学习使用 感兴趣的可以…...
)
solidity从入门到精通(持续更新)
我一度觉得自己不知何时变成了一个浮躁的人,一度不想受外界干扰的我被干扰了,再无法平静的去看一本书,但我仍旧希望我能够克服这些,压抑着自己直到所有的冲动和奇怪的思想都无法再左右我行动。 自律会让你更加自律,放纵…...
:edk2项目编译流程)
UEFI入门(二):edk2项目编译流程
UEFI入门(二):edk2项目编译流程 一、编译构建流程:1. 安装依赖工具2. 初始化构建环境3. 配置工具链和目标4. 定义平台配置5. 构建并编译 二、uefi-tools编译edk2实践:1. 克隆EDK2 项目2. 构建并编译 参考文章ÿ…...
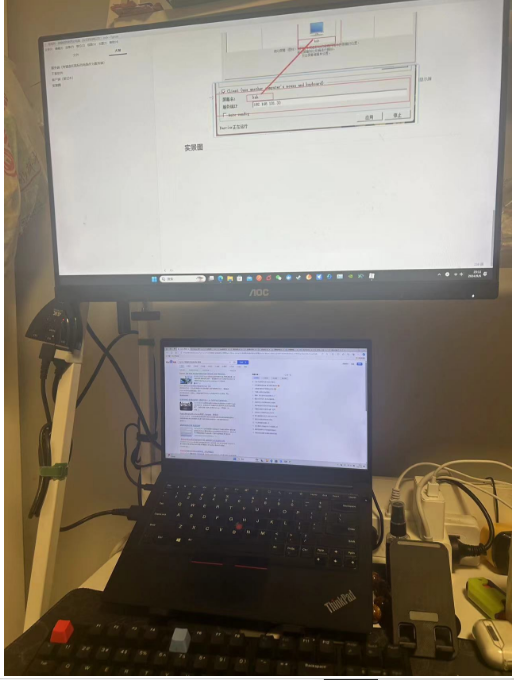
局域网一套键鼠控制两台电脑(台式机和笔记本)
服务端(有键盘和鼠标的电脑作为服务端) 下载软件 分享文件:BarrierSetup-2.3.3.exe 链接:https://pan.xunlei.com/s/VO66rAZkzxTxVm-0QRCJ33mMA1?pwd4jde# 配置服务端 一, 二, 客户端屏幕名称一定要和…...

最新Nessus2024.9.8版本主机漏洞扫描/探测工具下载Windows版
Nessus号称是世界上最流行的漏洞扫描程序,全世界有超过75000个组织在使用它。该工具提供完整的电脑漏洞扫描服务,并随时更新其漏洞数据库。Nessus不同于传统的漏洞扫描软件,Nessus可同时在本机或远端上遥控,进行系统的漏洞分析扫描…...

关于使用 @iconify/vue2图标库组件的离线使用
Iconify 是最通用的图标框架,将各种图标库的图标集中在这里的一个组件库,例如ant-design,element-ui等 网站地址如下 https://iconify.design/getting-started/ 1.安装依赖 这两个包提供了图标组件和离线图标数据的支持。 npm install iconify/vue2 i…...

pdfmake生成pdf的使用
实际项目中有时会有根据填写的表单数据或者其他格式的数据,将数据自动填充到pdf文件中根据固定模板生成pdf文件的需求 文章目录 利用pdfmake生成pdf文件1.下载安装pdfmake第三方包2.封装生成pdf文件的共用配置3.生成pdf文件的文件模板内容4.调用方法生成pdf 利用pdf…...

PLM系统有哪些品牌推荐?国内不错的PLM厂商有哪些?
在当今快速变化的商业环境中,产品生命周期管理PLM系统已成为企业技术创新和管理创新的重要工具。PLM系统涵盖了产品从概念设计到市场推出、使用维护直至最终报废的整个生命周期,通过整合与产品相关的所有信息,助力企业实现高效、协同的产品开…...
)
Linux网络:网络套接字-TCP回显服务器——多进程/线程池(生产者消费者模型)
1.多进程版本 这里选择创建子进程,让子进程再创建子进程。父进程等待子进程,子进程的子进程处理业务逻辑。因为子进程是直接退出,子进程的子进程变成孤儿进程被系统管理,所以父进程在等待的时候不是阻塞等待的,所以可…...

Redis 篇-深入了解基于 Redis 实现消息队列(比较基于 List 实现消息队列、基于 PubSub 发布订阅模型之间的区别)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 消息队列的认识 2.0 基于 List 实现消息队列 2.1 基于 List 实现消息队列的优缺点 3.0 基于 PubSub 实现消息队列 3.1 基于 PubSub 的消息队列优缺点 4.0 基于 St…...

python 学习一张图
python学习一张图,python的特点的是学的快,一段时间不用,忘记的也快,弄一张图及一些入门案例吧。 写一个简单的测试: #!/usr/bin/python # -*- coding: UTF-8 -*- import osdef add_num(a, b):return a bif __name__…...

通过Docker部署 MongoDB 服务器
今天我们将在三丰云的免费服务器上进行 MongoDB 的部署测试。这款不错的免费服务器提供了很好的性能,1核CPU、1G内存、10G硬盘和5M带宽,足以满足我们的基本需求。三丰云的服务稳定,操作简单,真是一个值得推荐的选择,特…...

无人机避障雷达技术详解
随着无人机技术的飞速发展,其应用领域已经从最初的军事领域扩展到商业、农业、建筑巡检、应急救援、物流运输等多个领域。在这些多样化的应用场景中,无人机的安全性和稳定性显得尤为重要。无人机避障技术作为保障无人机安全飞行的核心技术之一࿰…...

2009-2023年上市公司华证esg评级评分数据(年度+季度)(含细分项)
2009-2023年上市公司华证esg评级评分数据(年度季度)(含细分项) 1、时间:2009-2023年 2、来源:整理自wind 3、指标:证券代码、年份、证券简称、评级日期、综合评级、综合得分、E评级、E得分、…...

C++ 模板进阶知识——stdenable_if
目录 C 模板进阶知识——std::enable_if1. 简介和背景基本语法使用场景 2. std::enable_if 的基本用法示例:限制函数模板只接受整数类型 3. SFINAE 和 std::enable_if示例:使用 SFINAE 进行函数重载SFINAE 的优点应用场景 4. 在类模板中使用 std::enable…...

国内外ChatGPT网站集合,无限制使用【2024-09最新】~
经过我一年多以来,使用各种AI工具的体验,我收集了一批AI工具和站点 这些工具都是使用的最强最主流的模型,也都在各个领域里都独领风骚的产品。 而且,这些工具你都可以无限制地使用。 无论你是打工人、科研工作者、学生、文案写…...

如何在VUE3中使用函数式组件
在Vue 3中,函数式组件的概念与Vue 2相似,但实现方式有所不同。函数式组件是一种无状态、无实例的组件,它们只根据传入的props和context来渲染输出。在Vue 3中,你可以通过定义一个函数并返回一个渲染函数来使用函数式组件。但是&am…...

linux访问外网的设置
Ubuntu | LUCKFOX WIKI 开发板配置 添加路由信息 sudo route add default gw 172.32.0.100添加 DNS servers 打开文件 sudo vi /etc/resolv.conf添加以下内容: nameserver 8.8.8.8联网测试 ping www.baidu.com开机自动配置 路由信息和 DNS servers 重启后会被清除,我们创建…...

量子退火与经典优化算法性能对比研究
1. 量子退火与经典优化算法的性能对比研究在计算科学领域,量子计算一直被视为可能带来革命性突破的技术。其中,量子退火(Quantum Annealing)作为一种专门用于解决组合优化问题的方法,近年来备受关注。然而,…...

基于taotoken多模型能力在ubuntu构建智能客服路由系统
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于taotoken多模型能力在ubuntu构建智能客服路由系统 在构建智能客服系统时,一个常见的挑战是如何平衡响应质量与成本…...

SABIC工程塑料创新材料解决方案与发展前景分析
SABIC工程塑料凭借其卓越的耐高温性、机械强度及化学稳定性,成为高端制造领域不可或缺的创新材料解决方案。其未来发展将深度契合汽车轻量化、5G通信及新能源产业升级需求,市场前景广阔。工程塑料作为高端制造业的核心基础材料,其性能直接决定…...

王炸!史上最强的智慧园区管理系统,java最新技术栈,支持信创!
一、项目简介本软件是一款面向智慧园区与智慧楼宇的综合管理系统,采用先进的微服务架构(SpringCloud)、JDK 17、Spring Boot 3.2、MySQL、Vue3、Vite 和 UniApp 技术栈,支持小程序、H5、公众号、App 多端适配,前后端分…...

别再瞎找了!盘点2026年碾压级的的降AIGC网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AIGC网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...

Unity AI工作流实战指南:从Editor到运行时的稳定集成
1. 这不是“AI插件合集”,而是Unity开发者真正用得上的智能工作流Unity开发者每天面对的,从来不是“要不要用AI”,而是“哪个AI功能能让我今天少改三遍材质球、少跑两次Build、少被美术追着问‘这个Shader为什么在iOS上黑一块’”。我做Unity…...

Go Web中间件机制深度剖析与实战
Go Web中间件机制深度剖析与实战 引言 中间件(Middleware)是Web开发中的核心概念,它在请求处理链路中扮演着至关重要的角色。本文将深入探讨Go语言中中间件的实现机制,并通过实战案例展示如何构建可复用的中间件系统。 一、中间件…...

Python数据库迁移实战:从SQLAlchemy到Alembic的完整指南
Python数据库迁移实战:从SQLAlchemy到Alembic的完整指南 引言 数据库迁移是后端开发中不可或缺的一部分。作为从Python转向Rust的后端开发者,我发现Python的数据库迁移工具非常成熟,尤其是Alembic配合SQLAlchemy的组合。本文将从实战角度出发…...
:状态管理选型)
React 从入门到生产(五):状态管理选型
创作者: Yardon | GitHub: github.com/YardonYan | 版本: v1.0 什么时候需要状态管理 先泼一盆冷水:大多数 React 应用不需要 Redux。 这句话不是我说的,是 Redux 的作者 Dan Abramov 本人说的。他在 2020 年就公…...

书匠策AI实测揭秘:毕业论文全流程竟然能这样“偷懒“?
各位同学,我是一个专门教别人写论文的博主。说实话,每次看到评论区有人问"论文到底怎么开头",我都想穿越屏幕去帮他敲键盘。 但今天不一样,我要给你们安利一个我自己偷偷用了好几次的工具——书匠策AI。注意࿰…...