为数据仓库构建Zero-ETL无缝集成数据分析方案(下篇)
对于从事数据分析的小伙伴们来说,最头疼的莫过于数据处理的阶段。在我们将数据源的原始数据导入数据仓储进行分析之前,我们通常需要进行ETL流程对数据格式进行统一转换,这个流程需要分配专业数据工程师基于业务情况完成,整个过程十分耗时耗力,而且往往不能获取实时的最新数据。
在本系列的上篇文章中,我们已经介绍可在亚马逊云科技上通过 Aurora zero-ETL 与 Amazon Redshift 的无缝集成的解决方案,将数据库内的交易数据与数据仓储中的的分析功能自动结合在一起,从而简化数据库和数据仓储之间定制化 ETL 管道的搭建与管理工作。架构图如下:

在下篇中我们将介绍利用MySQL客户端对RDS数据中的修改,并在RedShift数据仓库中查看从RDS数据库中经过ETL导入到数据仓库的数据,并对ETL任务进行监控。
方案所需基础知识
什么是 zero-ETL ?
服务之间直接集成,不需要使用额外组件完成数据 ETL 的工作。把各种各样的数据都连接到执行分析所需要的地方,实现数据平滑“无感”的流动。它可以帮助用户最大限度地减少甚至消除构建 ETL 数据管道的复杂性。zero-ETL 的主要优势包括:
- 提高敏捷性。简化了数据架构并减少了数据工程的工作量。它允许增加新的数据源,而无需重新处理大量数据。这种灵活性增强了敏捷性,支持数据驱动的决策和快速创新。
- 成本效益。利用云原生且可扩展的数据集成技术,使企业能够根据实际使用情况和数据处理需求来优化成本。组织可以减少基础设施成本、开发工作和维护费用。
- 实时洞察。传统的 ETL 流程通常涉及定期批量更新,导致数据可用性延迟。另一方面,Zero-ETL 提供实时或近实时的数据访问,确保为分析、AI/ML 和报告提供更新鲜的数据。您可以获得更准确、更及时的用例洞察,例如实时仪表板、优化的游戏体验、数据质量监控和客户行为分析。组织可以更有信心地进行数据驱动的预测,改善客户体验,并在整个企业中推广数据驱动的见解。

什么是 Amazon Redshift Serverless?
Amazon Redshift Serverless 让您可以更轻松地运行和扩展分析,而无需管理数据仓库基础设施。 借助 Amazon Redshift Serverless,数据分析师、开发人员和数据科学家现在可以使用 Amazon Redshift Serverless 在几秒钟内从数据中获取见解,方法是将数据加载到数据仓库中并从中查询记录。Amazon Redshift Serverless 会自动豫园和扩展数据仓库容量,以提供快速的性能,满足苛刻且不可预测的工作负载。你只需为使用的容量付费。你可以从这种简单性中受益,而无需更改现有的分析和商业智能应用程序。Amazon Redshift Serverless 主要优势包括:
- 在几秒内开始分析。通过快速入门并对所有数据进行实时或预测性分析,专注于获得见解,而不必担心管理数据仓库基础设施。
- 体验始终如一的高性能。支持在查询复杂性、频率、ETL (提取、转换、加载) 或控制面板使用模式等维度上智能、主动并自动扩缩动态工作负载,以提供量身定制的性能优化。
- 节省成本并控制预算。只需按每秒的使用量付费,当数据仓库处于空闲状态时不支付任何费用。调整工作负载所需的性价比目标,以保持稳定的性能并控制预算。

什么是 Amazon Aurora Serverless?
Amazon Aurora Serverless 是 Amazon Aurora 的一种按需自动扩展配置版本。Amazon Aurora Serverless 会根据应用程序的需求自动启动、关闭以及扩展或缩减容量。可在云中运行数据库,而无需管理任何数据库实例。还可以在现有或新的数据库集群中将 Aurora Serverless v2 实例与预置实例搭配使用。Amazon Aurora Serverless 其主要优势包括:
- 高度可扩展。只需不到一秒的时间,即可瞬间扩展到数十万个事务。
- 高度可用。提供所有的 Aurora 功能,包括克隆、全球数据库、多可用区部署以及只读副本等,满足业务关键型应用程序的需求。
- 经济高效。以极为精细的横向增量,确保恰好提供所需的数据库资源量,并且仅为使用的容量付费。
- 简单。不再需要进行复杂的数据库容量预置和管理。数据库将会扩展,以匹配应用程序的需求。
- 透明。立即扩展数据库容量,而不中断传入的应用程序请求。
- 持久。使用分布式、容错、自我修复的 Aurora 存储,防止数据丢失,使您的数据在一个区域的三个可用区(AZ)中持久可用。

本实践包括的内容
1. 通过MySQL客户端连接MySQL服务器,并执行数据/表更新DDL、DML操作
2. 在RedShift数据仓库中,查看从MySQL经过ETL导入的数据信息,验证一致性
3. 通过云端控制台监控ETL任务指标、运行状态
项目实操步骤
项目前期准备
1. 我们需要提前在亚马逊云科技控制台中,进入RDS服务主页创建Amazon Aurora Serverless v2数据库

2. 然后进入RedShift服务主页,创建Amazon Redshift Serverless输出仓储

通过 Amazon EC2 控制台创建 EC2 并安装 MySQL 客户端
3. 通过亚马逊云科技控制台,进入EC2服务主页

4.点击左侧菜单栏的实例选项,点击右侧启动新实例

5. 我们进入实例创建页面,我们根据图中所示选择OS类型、CPU架构类型

6. 选择实例大小类型”t2.micro“, 选择SSH登录秘钥,以及配置网络环境

7. 在网络配置选项中,我们选择VPC、子网、为EC2开启公网IP,选择安全组,并为服务器配置磁盘

8. 实例创建成功后,我们点击连接,通过SSH进入服务器的Shell,命令行

9. 在服务器Shell中,我们通过以下命令安装MySQL客户端
sudo yum upgradesudo yum install -y mariadb105.x86_6410. 我们首先获取RDS数据库的读写URL节点

11. 再通过MySQL客户端连接MySQL数据库,需要把"[mysql endpoint here!]"替换成RDS读写URL节点
mysql -h [mysql endpoint here!] -P 3306 -u awsuser -p 在MySQL中更新表/数据并检查下游数据
12. 我们利用MySQL客户端执行如下DDL和DML操作,分别创建数据库”zeroetl“,创建新表”timeseries“和插入一条数据”abcd“
create database zeroetl;
use zeroetl;CREATE TABLE timeseries (id BIGINT AUTO_INCREMENT PRIMARY KEY,timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,random_chars CHAR(5)
);
INSERT INTO timeseries (random_chars) VALUES ('abcd');13. 接下来我们进入RedShift的查询控制台,执行SQL查询语句

14. 我们运行以下SQL命令查询从MySQL中通过ETL同步到RedShift的数据
set search_path to zeroetl;select *, (CURRENT_TIMESTAMP - timestamp) as latency_secs from timeseries order by timestamp desc;15. 我们再通过其他的DML/DDL操作在MySQL中对数据进行修改
use zeroetl;create table schema_evolution(id BIGINT AUTO_INCREMENT PRIMARY KEY, timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP, i integer, c char(5));insert into schema_evolution(i, c) values(1, 'abcde');insert into schema_evolution(i, c) values(2, 'abcde');16. 通过以下命令验证ETL数据同步的一致性,可以看到数据/表已经变成我们刚刚修改的内容了
set search_path to zeroetl;select * from schema_evolution;17. 数据从MySQL到RedShift的同步会有一些延迟,可通过下述 SQL 查看系统表集成同步过程,确定同步是否完成
select * from SVV_INTEGRATION_TABLE_STATE where table_name = 'schema_evolution';通过控制台监控查看ETL任务健康指标和运行状态
18. 在RedShift主页的控制台中,我们在左侧进入” 零ETL集成“功能界面,点击我们在本系列上篇中创建的Zero-ETL任务

19. 进入到任务页面中,我们就可以看到零ETL任务的各项具体参数信息,以及下方的监控指标、运行状态了

以上就是为亚马逊云科技上的RDS数据库创建与数据仓库RedShift Zero-ETL无缝集成方案的下篇内容。欢迎大家关注小李哥和我的亚马逊云科技服务深入调研系列,不要错过未来更多国际前沿的AWS云开发/云架构方案。
相关文章:
为数据仓库构建Zero-ETL无缝集成数据分析方案(下篇)
对于从事数据分析的小伙伴们来说,最头疼的莫过于数据处理的阶段。在我们将数据源的原始数据导入数据仓储进行分析之前,我们通常需要进行ETL流程对数据格式进行统一转换,这个流程需要分配专业数据工程师基于业务情况完成,整个过程十…...

ElMessageBox消息确认框组件在使用时如何设置第三个或多个自定义按钮
ElMessageBox自带两个按钮一个确认一个取消,当还想使用该组件还想再加个功能组件时,就需要自定义个按钮加到组件里 第二种方法可以通过编写自定义弹窗来完成,个人觉得代码量增多过于繁琐,当然也可以实现 先定义方法负责获取dom父节点,创建新的子元素加…...

javaWeb【day04】--(MavenSpringBootWeb入门)
01. Maven课程介绍 1.1 课程安排 学习完前端Web开发技术后,我们即将开始学习后端Web开发技术。做为一名Java开发工程师,后端Web开发技术是我们学习的重点。 1.2 初识Maven 1.2.1 什么是Maven Maven是Apache旗下的一个开源项目,是一款用于…...
[Linux]:文件(下)
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:Linux学习 贝蒂的主页:Betty’s blog 1. 重定向原理 在明确了文件描述符的概念及其分配规则后,我们就可…...

【学习笔记】手写Tomcat 一
目录 HTTP协议请求格式 HTTP协议响应格式 Socket 解读代码 服务端优化 解读代码 作业 1. 响应一个 HTML 页面给客户端,游览器把接收到的内容进行渲染 2. 文件的媒体类型是写死的,肯定不行,怎么变成动态? 昨天作业答案 …...

springboot基础-Druid数据库连接池使用
文章目录 引入Druid组件(maven)配置数据源Druid配置项1. 数据源配置2. 监控配置3. 安全配置4. SQL拦截配置 示例配置相关地址 Druid是阿里巴巴开源的一个高性能的Java数据库连接池组件,它提供了强大的监控统计功能和工具支持。Druid不仅可以作…...

C语言文件操作全攻略:从打开fopen到读写r,w,一网打尽
前言 在C语言中,文件操作是一项基础而强大的功能,它允许程序与存储在硬盘上的数据进行交互。无论是读取配置文件、处理日志文件,还是创建新的数据文件,C语言都提供了丰富的函数库来支持这些操作。本文将整合并详细介绍fopen(), 对…...

【0328】Postgres内核之 “User ID state”
1. User ID state 我们必须追踪与“用户ID(user ID)”概念相关的多个不同值。Postgres内核中有共有以下几个 User ID。 ✔ AuthenticatedUserId ✔ SessionUserId ✔ OuterUserId ✔ CurrentUserId 1.1 User ID 概念相关的不同值 AuthenticatedUserId AuthenticatedUserId…...

VisualStudio环境搭建C++
Visual Studio环境搭建 说明 C程序编写中,经常需要链接头文件(.h/.hpp)和源文件(.c/.cpp)。这样的好处是:控制主文件的篇幅,让代码架构更加清晰。一般来说头文件里放的是类的申明,函数的申明,全局变量的定义等等。源…...

linux 文件压缩并且切割压缩
Linux系统中,split命令是一个非常实用的工具,它可以将一个大文件分割成多个小文件 1、先将文件压缩 tar -cvf access.log.tar.gz access2、将文件压缩为每500mb一个文件,-b 500m 指定了每个分割文件的大小为500MB,-d 表示使用数字…...

支持iPhone 16新品预售,饿了么同步上线专人配送等特色服务
9月10日凌晨,2024年 Apple 秋季新品发布会上正式揭晓iPhone 16新机。9月10日一早,饿了么同步宣布:今年将携手近4000家Apple 授权专营店,支持iPhone 16新品预售及现货的同步开售。新机现货首发当日,饿了么消费者最快半小…...

低光增强效果展示
训练模型给图片加标题...

李诞-2021.8脱口秀工作手册-11-pitch your idea把一个想法扎进别人脑子里;专业,做足准备,给选择option!
17 每个人都该学会卖掉自己的想法 要把一件事办妥,就要有把一个想法扎进别人脑子里的决心。 很早之前,我跟编剧鬼顾达去见一个非常非常不好合作的嘉宾,我们本来带去了一份很好的稿子,他不愿意接受,反复抗议ÿ…...

vue3 自定义指令 directive
1、官方说明:https://cn.vuejs.org/guide/reusability/custom-directives 除了 Vue 内置的一系列指令 (比如 v-model 或 v-show) 之外,Vue 还允许你注册自定义的指令 (Custom Directives)。 我们已经介绍了两种在 Vue 中重用代码的方式:组件和…...

为什么腾讯难以再现《黑神话:悟空》这样的游戏大作?
自《黑神话:悟空》发布以来,它凭借令人惊艳的画面和深入人心的故事情节,迅速在全球范围内收获了大量粉丝。这款游戏的成功,不仅让全球玩家看到了国产游戏的新高度,也让许多人开始好奇:作为中国游戏行业的巨头,腾讯为什么没能推出类似《黑神话:悟空》这样震撼的作品?今…...

C# WPF燃气报警器记录读取串口工具
C# WPF燃气报警器记录读取串口工具 概要串口帧数据布局文件代码文件运行效果源码下载 概要 符合国标文件《GB15322.2-2019.pdf》串口通信协议定义;可读取燃气报警器家用版设备历史记录信息等信息; 串口帧数据 串口通信如何确定一帧数据接收完成是个…...

【IEEE独立出版 | 往届快至会后2个月检索,刊后1个月检索】2024年第四届电子信息工程与计算机科学国际会议(EIECS 2024)
在线投稿:学术会议-学术交流征稿-学术会议在线-艾思科蓝 电子信息的出现与计算机技术、通信技术和高密度存储技术的迅速发展并在各个领域里得到广泛应用有着密切关系。作为高技术领域中重要的前沿技术之一,电子信息工程具有前瞻性、先导性的特点&#x…...
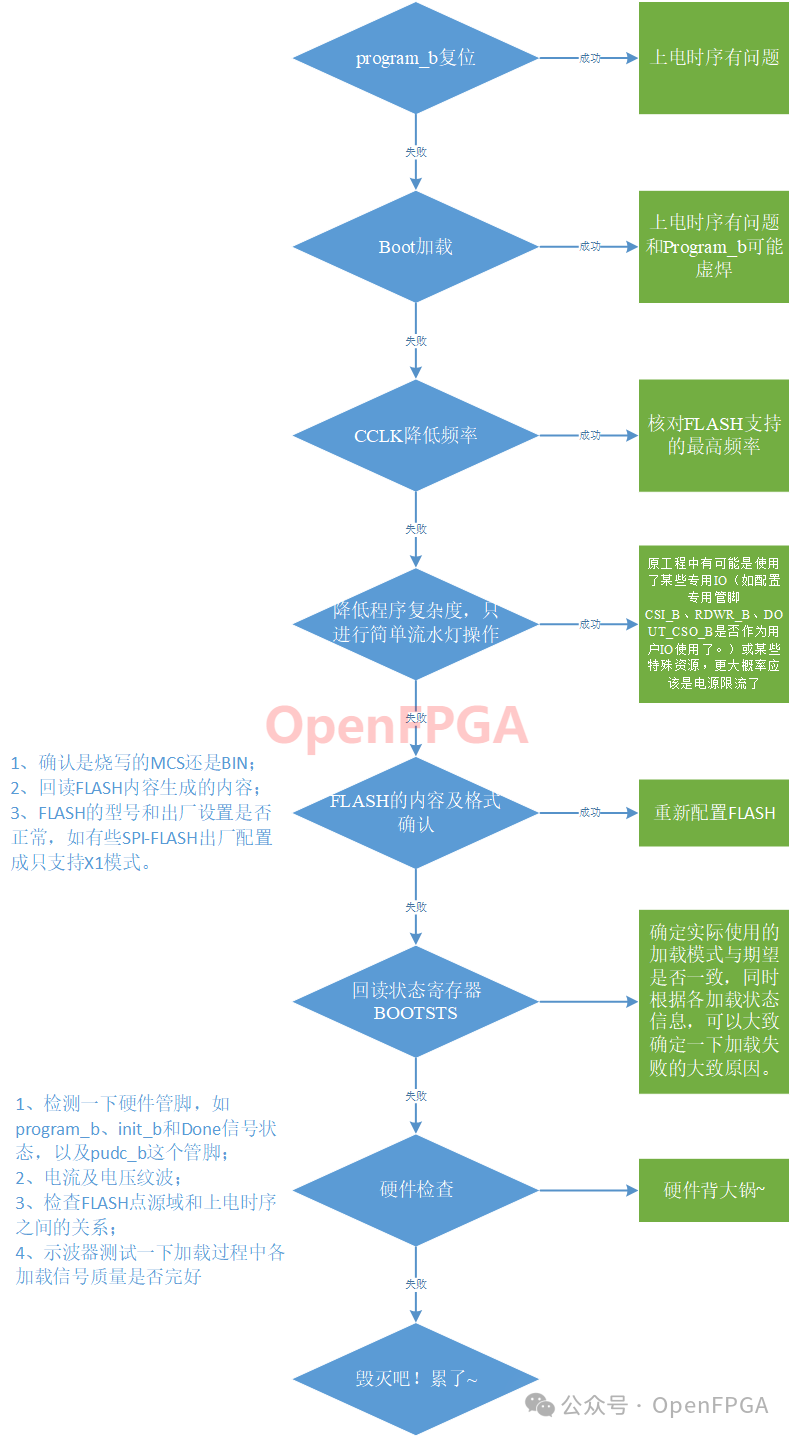
FPGA实现串口升级及MultiBoot(三)FPGA启动加载方式
缩略词索引: K7:Kintex 7V7:Vertex 7A7:Artix 7 上一篇中介绍了FPGA的启动步骤,如图0 所示,今天这篇文章就要在上一篇文章基础上进行分支细化,首先我们先了解FPGA 启动加载的几种方式。同时对于我们设计中常见的几个问题将在文章最…...

Linux驱动(六):Linux2.6驱动编写之平台设备总线
目录 前言一、平台设备总线1.是个啥?2.API函数 二、设备端驱动端1. 匹配机制2. 实现代码 三、设备树驱动端1.匹配机制2.代码实现 前言 本文主要介绍了一下两种驱动编写方法: 1.比较原始的设备端驱动端编写方法。 2.效率较高的设备树驱动端编写方法。 最…...

回溯——11.重新安排行程
力扣题目链接 给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从…...

体验Taotoken多模型聚合在内容生成任务中的效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型聚合在内容生成任务中的效果差异 在实际的开发与创作工作中,我们常常面临一个选择:针对…...

5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性
5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

Yunzai-Bot阴天插件:免费集成百款AI大模型的QQ机器人全能助手
1. 项目概述与核心价值如果你正在寻找一个能让你在QQ机器人上免费、便捷地体验上百种主流AI大模型的解决方案,那么“阴天插件”(Y-Tian-Plugin)绝对值得你花时间深入了解。作为一名长期混迹于机器人开发社区的开发者,我见过太多要…...
)
告别复杂配置:用MobaXterm+网线直连,5分钟让树莓派SSH并上网(Windows环境)
极简主义者的树莓派连接方案:MobaXterm全流程实战指南 树莓派作为一款功能强大的微型计算机,在嵌入式开发、物联网项目和教育领域广受欢迎。然而对于许多初学者甚至有一定经验的开发者来说,如何快速、稳定地连接树莓派始终是个令人头疼的问题…...

单片机开发者如何通过Taotoken调用大模型API优化代码注释
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 单片机开发者如何通过Taotoken调用大模型API优化代码注释 对于单片机开发者而言,编写清晰、准确的代码注释是提升项目可…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...
的配置策略与索引选择)
告别盲选!深入解读5G NR中UCI偏置值(beta_offset)的配置策略与索引选择
5G NR中UCI偏置值配置的工程实践指南 在5G新空口(NR)系统中,上行控制信息(UCI)通过物理上行共享信道(PUSCH)传输时,其资源分配直接影响到系统性能和用户体验。作为网络优化工程师,我们经常需要面对各种复杂的配置场景,而UCI偏置值…...

3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器
3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE SRWE(Simple Runtime Window Editor)是一款革命性的实时窗口编辑器&…...

peaqOS 给机器发了一份穆迪式评级,机器经济缺的最后一块零件被补上了
作者:PaperMoon团队 “It’s time for blockchain to live up to its full potential。” 这种句子在 2026 年的 Web3 推文里已经少见了,大部分项目方学会了克制。peaq 这次不克制,而且把"全新资产类别"这种 2017 年级别的措辞重新…...
)
Cadence 17.4导出Gerber文件保姆级避坑指南(附TMC2300电机驱动板实战)
Cadence 17.4导出Gerber文件保姆级避坑指南(附TMC2300电机驱动板实战) 第一次用Cadence Allegro 17.4导出Gerber文件的新手,大概率会在某个环节卡住——要么是钻孔文件莫名报错,要么是板厂反馈光绘层对不齐。这种挫败感我太熟悉了…...