代码随想录训练营 Day57打卡 图论part07 53. 寻宝(prim,kruskal算法)
代码随想录训练营 Day57打卡 图论part07
卡码53. 寻宝
题目描述
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以 以最短的总公路距离 将所有岛屿联通起来(注意:这是一个无向图)。
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
输入描述
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
输出描述
输出联通所有岛屿的最小路径总距离
输入示例
7 11
1 2 1
1 3 1
1 5 2
2 6 1
2 4 2
2 3 2
3 4 1
4 5 1
5 6 2
5 7 1
6 7 1
输出示例
6
提示信息
数据范围:
2 <= V <= 10000;
1 <= E <= 100000;
0 <= val <= 10000;
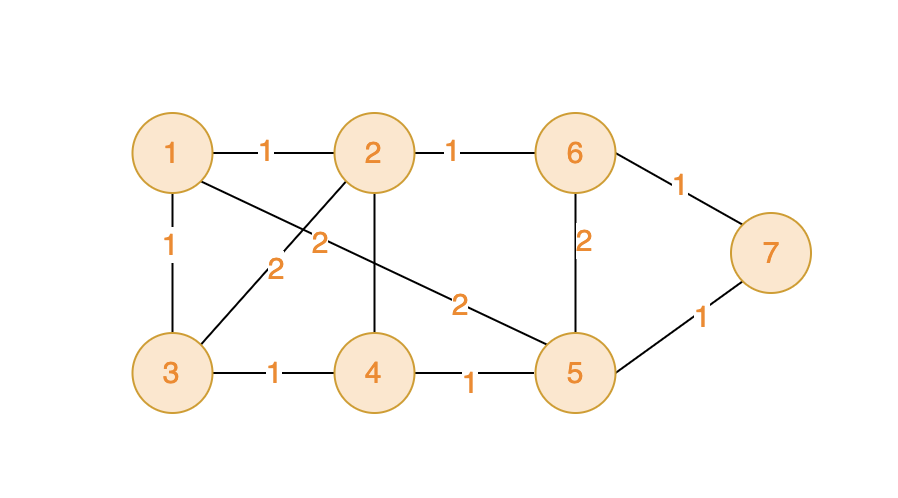
如下图,可见将所有的顶点都访问一遍,总距离最低是6.
版本一 prim算法
这是一个典型的 Prim算法 问题,目的是找到图的最小生成树(MST),即连接所有节点的总边权值最小的树。
def prim(v, e, edges):# 初始化一个 v+1 * v+1 的邻接矩阵,初始值为一个很大的数grid = [[float('inf')] * (v + 1) for _ in range(v + 1)]# 读取所有边的信息,构建邻接矩阵for x, y, k in edges:grid[x][y] = kgrid[y][x] = k# 最小生成树中每个节点与其他树节点的最小距离minDist = [float('inf')] * (v + 1)# 标记节点是否在最小生成树中isInTree = [False] * (v + 1)# 从第一个节点开始,设定它的初始距离为0minDist[1] = 0# 最小生成树的权值总和result = 0# Prim算法,执行 v-1 次,选择 v-1 条边构造最小生成树for _ in range(1, v): # v-1次cur = -1 # 当前选中要加入树的节点minVal = float('inf')# 第一步:选择离生成树最近的节点for j in range(1, v + 1):if not isInTree[j] and minDist[j] < minVal:minVal = minDist[j]cur = j# 第二步:将选中的节点加入最小生成树isInTree[cur] = Trueresult += minVal# 第三步:更新所有非生成树节点到生成树的最小距离for j in range(1, v + 1):if not isInTree[j] and grid[cur][j] < minDist[j]:minDist[j] = grid[cur][j]return result# 读取输入
v, e = map(int, input().split()) # v 为节点数,e 为边数
edges = []
for _ in range(e):x, y, k = map(int, input().split())edges.append((x, y, k))# 调用 Prim 算法并输出结果
print(prim(v, e, edges))- 邻接矩阵:我们用 grid 来表示邻接矩阵,初始值为 float(‘inf’),表示两个节点之间没有边连接。对于每个输入的边 (x,
y, k),我们设置 grid[x][y] = k 和 grid[y][x] = k,因为这是一个无向图。 - minDist 数组:该数组用于存储每个节点到已加入最小生成树的最近距离,初始值为 float(‘inf’),表示未与最小生成树相连。
- isInTree 数组:该数组用于记录每个节点是否已经被加入最小生成树。
- Prim算法:我们进行 v-1次迭代,每次选择一个离当前生成树最近的节点,加入最小生成树,并更新所有未加入树的节点与当前生成树的最小距离。
- 结果计算:在每次迭代时,将选中的边的权值加到最终结果 result 中,最后返回最小生成树的权值总和。
时间复杂度:
- 构建邻接矩阵:时间复杂度是 O(v^2),因为我们存储了所有节点对之间的边。
- 主循环:由于每次我们都需要遍历 v 个节点,寻找最近的节点,因此每次循环的复杂度为 O(v),总的时间复杂度为 O(v^2)。
版本二 kruskal算法
Kruskal算法是一种贪心算法,它的目标是通过选择最小的边来构建最小生成树。Kruskal算法的核心思想是维护边的集合,而不是像Prim算法那样维护节点的集合。
Kruskal算法的步骤:
- 边权排序:首先对所有的边按权值从小到大排序,因为我们要优先选择权值最小的边。
- 并查集判断:遍历每条边,判断它连接的两个节点是否已经属于同一个集合(即是否已经连通)。如果两个节点属于同一个集合,添加这条边将形成环路,应该跳过这条边;如果两个节点不属于同一个集合,就可以添加这条边,并将两个节点合并到同一个集合。
- 结束条件:当我们选择了 n-1 条边时(其中 n 是图中的节点数),生成树构建完毕。
Kruskal算法的关键数据结构是并查集(Union-Find),并查集可以帮助我们高效地判断两个节点是否已经连通。
Kruskal算法的关键点:
-
并查集:用于维护节点的集合关系,主要支持两个操作:
Find:查找某个节点所在集合的根节点,使用路径压缩加速查找。
Union:将两个节点所在的集合合并。 -
边权排序:对所有的边按权值从小到大排序,以贪心策略构建最小生成树。
class Edge:def __init__(self, l, r, val):self.l = l # 边的左端点self.r = r # 边的右端点self.val = val # 边的权值# 节点的最大数量假设为 10001
n = 10001
father = list(range(n)) # 并查集的父节点数组,初始时每个节点的父节点都是它自己# 初始化并查集
def init():global fatherfather = list(range(n))# 并查集的查找操作,使用路径压缩优化
def find(u):if u != father[u]:father[u] = find(father[u]) # 路径压缩,将节点 u 直接指向根节点return father[u]# 并查集的合并操作,将节点 u 和节点 v 所在的集合合并
def join(u, v):u = find(u)v = find(v)if u != v:father[v] = u # 将 v 的根节点指向 u 的根节点# Kruskal算法,求最小生成树的权值总和
def kruskal(v, edges):edges.sort(key=lambda edge: edge.val) # 将边按权值从小到大排序init() # 初始化并查集result_val = 0 # 最小生成树的权值总和edge_count = 0 # 记录已经加入生成树的边数# 遍历排序后的边for edge in edges:if edge_count == v - 1: # 如果已经选择了 v-1 条边,生成树构建完毕break# 查找边的两个端点的根节点x = find(edge.l)y = find(edge.r)# 如果两个端点不属于同一个集合,说明可以加入最小生成树if x != y:result_val += edge.val # 累加边的权值join(x, y) # 合并这两个端点的集合edge_count += 1 # 增加已加入的边数return result_val # 返回最小生成树的权值总和# 主函数,处理输入并输出结果
if __name__ == "__main__":import sysinput = sys.stdin.read # 读取标准输入data = input().split()v = int(data[0]) # 节点数量e = int(data[1]) # 边的数量edges = [] # 存储所有边index = 2for _ in range(e):v1 = int(data[index]) # 边的左端点v2 = int(data[index + 1]) # 边的右端点val = int(data[index + 2]) # 边的权值edges.append(Edge(v1, v2, val)) # 将边加入到列表中index += 3# 调用 Kruskal 算法求解最小生成树的权值总和result_val = kruskal(v, edges)# 输出最小生成树的总权值print(result_val)卡码题目链接
题目文章讲解
总结
Prim算法和Kruskal算法都是用于求解 最小生成树(MST) 的经典贪心算法。尽管它们的目标相同,但它们的实现方式和使用的数据结构有所不同。
-
思路与操作对象的区别
Prim算法:
节点为中心:Prim算法从一个起始节点开始,不断向已连接的生成树中添加最小边。它通过逐步扩展树的节点来构建最小生成树。
局部贪心策略:每次选择的都是与已构建的生成树相连的最小边。
Kruskal算法:
边为中心:Kruskal算法从所有边中选择权值最小的边开始,逐步将未连通的部分通过边连接起来。
全局贪心策略:Kruskal算法直接对所有边进行排序,然后逐步选择不会形成环的最小边。 -
使用的数据结构
Prim算法:
邻接矩阵或邻接表:通常使用邻接矩阵或邻接表来表示图,逐步更新已连接节点与其他未连接节点之间的最小权值。
优先队列(可选):使用优先队列(堆)优化查找最小边的操作,复杂度可以优化为 O(E log V)。
Kruskal算法:
边列表:Kruskal算法将所有边按权值排序,然后依次选择边,因此直接使用边的列表。
并查集(Union-Find):Kruskal算法需要并查集来判断两个节点是否已经在同一集合中,用于检测是否形成环路。 -
适用的图类型
Prim算法:
适用于稠密图:由于 Prim算法逐步扩展已连接的节点集合,因此在边数较多的稠密图中表现较好。
时间复杂度为 O(V^2)(邻接矩阵)或 O(E log V)(使用优先队列的邻接表)。
Kruskal算法:
适用于稀疏图:Kruskal算法对边进行排序并依次选择最小边,在边数较少的稀疏图中表现较好。
时间复杂度为 O(E log E),其中 E 是边数。 -
执行流程
Prim算法:
从任意起始节点开始,将该节点标记为已访问。
每次选择已访问节点集合中与未访问节点集合之间的最小边,将新节点加入最小生成树。
重复该过程,直到所有节点都被访问。
Kruskal算法:
将所有边按权值从小到大排序。
依次选择最小的边,如果该边连接的两个节点不在同一集合中,则将它们加入最小生成树,并使用并查集进行合并。
重复该过程,直到树中包含 n-1 条边。 -
结束条件
Prim算法:
当所有节点都已加入生成树时,算法结束。
Kruskal算法:
当选中的边数达到 n-1 条时,算法结束(其中 n 是节点数)。
相关文章:
代码随想录训练营 Day57打卡 图论part07 53. 寻宝(prim,kruskal算法)
代码随想录训练营 Day57打卡 图论part07 卡码53. 寻宝 题目描述 在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。 不同岛屿之间,路途距离不同,…...

Hibernate QueryPlanCache 查询计划缓存引发的内存溢出
目录 1.排查方式2.结论3.解决办法 前言:在生产环境中有一个后端程序多次报oom然后导致程序中断。 1.排查方式 通过下载后端程序产生的oom文件,将oom文件导入MemoryAnalyzer程序分析程序堆内存使用情况。 1、将oom文件导入MemoryAnalyzer后可以看到概览信…...

前端开发的观察者模式
什么是观察者设计模式 观察者模式(Observer Pattern)是前端开发中常用的一种设计模式。它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,其所有依赖对象都能收到通知并自动更新。观察者模式广泛应用于事件驱动的系…...

Pycharm 输入三个引号没有自动生成函数(方法)注释
配置项路径:pycharm–>Settins–>Tools–>Python Integrated Tools–>Docstrings–>Docstrings format选择对应的工程,如果有多个工程的话将 Docstrings format 的值从 Plain 换成 reStructuredText...

lammps后处理:多帧孔洞体积和孔隙率的计算
本文介绍lammps后处理技巧:多帧孔洞体积和孔隙率的计算方法。 在前面的专栏中,已经介绍了单帧孔洞体积的计算方法,有不少粉丝朋友咨询多帧孔洞体积的计算方法。 在上一次案例代码的基础上,稍加修改,添加一个for循环遍历所有的帧即可实现多帧孔洞体积的计算。 计算的结果…...

免费且实用:UI设计常用的颜色参考网站和一些Icon设计网站
用心去分享!请给我点个关注和点赞收藏!谢谢各位努力的人才! 1.在UI设计的时候,没有灵感,怎么办?可以参考这个网站(需要魔法能量) 网址如下: Color Hunt - Color Palette…...
log4j日志封装说明—slf4j对于log4j的日志封装-正确获取调用堆栈
日志是项目中必用的东西,日志产品里最普及应该就是log4j了。(logback这里暂不讨论。) 先看一下常用的log4j的用法,一般来说log4j都会配合slf4j或者common-logging使用,这里已slf4j为例。添加gradle依赖: dependencies { compile(l…...

JVM面试真题总结(六)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 解释GC的标记-整理算法及其优点 GC(垃圾收集ÿ…...

C语言代码练习(第十八天)
今日练习: 48、猴子吃桃问题。猴子第1天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第2天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第10天早上想再吃时&…...

linux上使用rpm的方式安装mysql
1.从mysql官网上下载需要的版本,根据操作系统版本,CPU架构,下载让rpm bundle,这个版本是个完整版,包含其他所有版本 上传到服务器的一个目录,进行解压 执行tar -xvf mysql*.tar tar -xvf mysql*.tar 2.卸载老版本m…...

html 中如何使用 uniapp 的部分方法
示例代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><…...

Samtec连接器小课堂 | 连接器电镀常识QA
【摘要/前言】 像大多数电子元件一样,无数子元件和工艺的质量直接影响到成品的质量和性能。对于PCB级连接器,这些因素包括针脚材料、塑料类型、模制塑料体的质量、尾部的共面性、表面处理(电镀)的质量、选择正确的连接器电镀、制…...

大模型备案全网最详细流程解读(附附件+重点解读)
文章目录 一、语料安全评估 二、黑盒测试 三、模型安全措施评估 四、性能评估 五、性能评估 六、安全性评估 七、可解释性评估 八、法律和合规性评估 九、应急管理措施 十、材料准备 十一、【线下流程】大模型备案线下详细步骤说明 十二、【线上流程】算法备案填报…...

基于2143规则编码的uint8_t如何转换成float
2143格式存储的float类型数据在解码时,需要将1和2互换,3和4互换,然后 通过数组转float,进行转换 uint8_t data[] {0x72, 0x02, 0xc8, 0x42}; // 字节数组 float bytesToFloat(uint8_t data[]) { uint32_t x; memcpy(&x, da…...

[项目][WebServer][整体框架设计]详细讲解
目录 0.框架 && 前言1.TcpServer类1.功能2.类设计 2.HttpServer类1.功能2.类设计 3.Request类 && Response类1.功能2.Request类设计3.Response类设计 4.EndPoint类1.功能2.类设计 5.Task类1.功能2.类设计 6.ThreadPool类1.功能2.类设计 0.框架 && 前言…...

SprinBoot+Vue网上购物商城的设计与实现
目录 1 项目介绍2 项目截图3 核心代码3.1 Controller3.2 Service3.3 Dao3.4 application.yml3.5 SpringbootApplication3.5 Vue 4 数据库表设计5 文档参考6 计算机毕设选题推荐7 源码获取 1 项目介绍 博主个人介绍:CSDN认证博客专家,CSDN平台Java领域优质…...

【数据结构】2——二叉树遍历
数据结构2——二叉树遍历 单纯记录 文章目录 数据结构2——二叉树遍历一、二叉树遍历1,先序遍历:根左右递归实现非递归实现(栈) 2.中序遍历:左根右递归非递归 3 .后序遍历:左右根递归非递归(两…...
——关键路径)
数据结构应用实例(五)——关键路径
Content: 一、问题描述二、算法思想三、代码实现四、小结 一、问题描述 设计实现 AOE 网的关键活动与关键路径问题; 二、算法思想 获取拓扑序列;计算节点的最早开始时间 v e [ i ] ve[i] ve[i];计算节点的最晚开始时间 v l [ j ] vl[j] v…...

组播 2024 9 11
PIM(Protocol Independent Multicast)是一种常用的组播路由协议,其独立于底层的单播路由协议,能够在多种网络环境中有效地实现多播路由功能。PIM主要有两种模式:PIM Sparse Mode (PIM-SM) 和 PIM Dense Mode (PIM-DM)&…...

揭秘开发者的效率倍增器:编程工具的选择与应用
文章目录 每日一句正能量前言工具介绍功能特点:使用场景:提高工作效率的方式: 效率对比未来趋势后记 每日一句正能量 这推开心窗之人,可以是亲朋好友,也可以是陌客路人,可以是德高望重的哲人名流࿰…...
)
别再死记硬背公式了!用Excel+Python搞定数学建模三大评价模型(附代码)
用ExcelPython玩转数学建模三大评价模型:告别公式恐惧症 数学建模竞赛中,评价模型是绕不开的核心工具。但面对满屏的数学符号和抽象公式,很多同学的第一反应是头皮发麻——"这些矩阵运算到底怎么落地?""一致性检验…...

HCCL 集合通信:昇腾集群的参数同步引擎
大模型训练的本质是将一个超大矩阵乘法拆到多张 NPU 上并行计算,每张卡算完自己的分片后把梯度合并。合并操作就是集合通信。 HCCL(Huawei Collective Communication Library)是 CANN 的集合通信库,对应 NVIDIA NCCL。它不参与模…...

GD32 RISC-V BSP框架设计:从硬件抽象到跨平台移植实战
1. 项目概述:为什么我们需要一个专属的BSP框架?如果你正在使用GD32的RISC-V内核MCU,比如GD32VF103系列,并且是从STM32或者其他ARM Cortex-M平台转过来的,那你大概率踩过这样的坑:官方提供的固件库ÿ…...

仓库盘点、物流交接?用UniApp+PDA扫码提升效率的实战配置与避坑指南
UniAppPDA扫码在仓储物流中的实战配置与效率提升指南 当仓储管理员小李第一次使用传统扫码枪配合PC系统进行月度盘点时,他需要反复核对Excel表格与实物位置,8小时的工作量常常延长到深夜。而现在,通过UniApp开发的移动端应用配合工业级PDA设备…...
)
别再只会用RC了!手把手教你用运放搭建一个75Hz低通滤波器(附Multisim仿真文件)
从RC到运放:实战75Hz低通滤波器设计与Multisim验证 在电子信号处理领域,滤波器设计是每个工程师必须掌握的硬核技能。当你需要从嘈杂的传感器信号中提取有效信息,或者在音频系统中消除恼人的高频噪声时,一个性能优异的低通滤波器往…...

AI插件深度对比 | Copilot、Tabnine、Codeium谁是王者
Copilot 的代码补全能力确实厉害,我试过在写 Python 函数的时候,只要输入注释,它就能自动生成函数体。比如写 “# 计算斐波那契数列”,它能直接给出递归和迭代两种实现方式。不过有时候生成的代码有点冗长,需要手动精简…...

CANN/asc-devkit:int64转half精度函数
__ll2half_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...

c#软件开发学习笔记--数据类型
c#软件开发学习笔记 一、 数据类型1.基本类型(值类型) 值类型存储在栈中,变量保存的值的本身,赋值是拷贝一份新数据 byte(字节) bit(位) 1byte 8bit byte(1字节) byte b 10; //0 - 255short(2字节) short s 100;…...

COMSOL电磁超声仿真避坑指南:从‘域不适用’报错到结果收敛的完整调试流程
COMSOL电磁超声仿真避坑指南:从‘域不适用’报错到结果收敛的完整调试流程 电磁超声仿真作为多物理场耦合的典型应用场景,其复杂性往往让即使有一定COMSOL基础的用户也频频"踩坑"。当你在深夜盯着屏幕上鲜红的"域不适用"报错&#x…...

HTTPS握手失败?别慌!手把手教你用OpenSSL和Wireshark排查TLS与Cipher Suites问题
HTTPS握手失败?别慌!手把手教你用OpenSSL和Wireshark排查TLS与Cipher Suites问题 当你面对浏览器中那个刺眼的"SSL Handshake Failed"错误时,是否感到无从下手?作为经历过数百次HTTPS故障排查的老兵,我深知这…...