Apache SeaTunnel基础介绍
一、什么是Apache SeaTunnel?
Apache SeaTunnel(最初名为Waterdrop)是一个开源的分布式数据集成平台,专为大规模数据处理设计。SeaTunnel可以从多种数据源读取数据,进行实时流式处理或批处理,然后将处理后的数据存储到目标系统中。SeaTunnel的设计宗旨是简化复杂的数据集成过程,并提供一种灵活且高效的方式来处理大数据。
SeaTunnel的开发始于应对实际生产环境中大规模数据处理的挑战。如今,它已成为一个稳定且功能丰富的工具,被广泛应用于数据采集、数据清洗、数据转换和数据存储等领域。
为什么需要数据集成工具?
随着企业数字化转型的推进,数据的来源越来越多样化,从传统的关系型数据库到现代的NoSQL数据库、分布式文件系统、消息队列和数据流服务等。这些数据源的数据格式和处理要求各不相同,企业需要一种工具来统一这些数据的处理流程,以实现高效的数据分析、BI报表生成、机器学习训练等任务。
传统的ETL(Extract, Transform, Load)工具虽然能解决部分问题,但面对现代大数据的规模和复杂性,往往力不从心。而SeaTunnel正是为了解决这些问题而生,它提供了一种灵活的配置方式和高度可扩展的插件架构,能够适应各种复杂的数据处理需求。
SeaTunnel的主要特点:
-
支持实时流式和批处理:SeaTunnel同时支持实时流数据处理(例如来自Kafka的消息)和批处理(例如HDFS中的大数据集)。这使得它能够同时满足需要低延迟的实时数据处理任务和需要处理大量历史数据的批处理任务。
-
高扩展性和灵活性:通过插件机制,SeaTunnel可以轻松扩展支持新的数据源、转换操作和数据接收器。无论是简单的数据过滤,还是复杂的数据聚合和转换,SeaTunnel都能提供相应的插件或接口来实现。
-
丰富的数据源和接收器支持:SeaTunnel原生支持各种常见的数据源和接收器,包括关系型数据库(如MySQL、PostgreSQL)、分布式文件系统(如HDFS)、NoSQL数据库(如Elasticsearch、MongoDB)、消息队列(如Kafka、RabbitMQ)等。用户只需简单配置,即可将这些数据源与接收器无缝连接。
-
简洁的配置与管理:SeaTunnel使用YAML格式的配置文件,使得配置过程直观且易于管理。用户无需编写大量代码,即可定义复杂的数据处理逻辑,并通过配置文件进行灵活调整。
二、核心概念
Data Source(数据源)
数据源是SeaTunnel作业的起点,它定义了数据从哪里来以及如何获取。SeaTunnel支持广泛的数据源类型,每种类型的数据源都有其特定的配置选项。例如,Kafka数据源需要指定Kafka集群的bootstrap_servers地址和要订阅的topics。SeaTunnel支持的数据源包括但不限于:
- Kafka:从Kafka主题中读取流数据,常用于实时日志处理、消息队列消费等场景。
- HDFS:从Hadoop分布式文件系统中读取批数据,适用于大规模数据存储与处理。
- JDBC:通过JDBC连接从关系型数据库中读取数据,支持MySQL、PostgreSQL、Oracle等主流数据库。
- File:从本地或分布式文件系统中读取文本、CSV、JSON等格式的文件数据。
- ElasticSearch:从ElasticSearch中读取数据,适用于需要在搜索引擎中处理数据的场景。
例如,一个Kafka数据源的配置可能如下:
source:- plugin_name: kafkabootstrap_servers: "localhost:9092"topics: "log_topic"group_id: "log_processing_group"format: jsonschema:- name: "log_level"type: "string"- name: "message"type: "string"- name: "timestamp"type: "long"
在这个配置中,SeaTunnel将从log_topic中读取JSON格式的日志数据,并将其解析为具有log_level、message和timestamp三个字段的结构化数据。
Transform(转换)
在数据集成过程中,通常需要对原始数据进行多种形式的处理和转换。例如,我们可能需要对数据进行清洗(去除不符合要求的数据)、格式转换(将日期字符串转换为时间戳)、聚合(计算某个字段的总和)等。在SeaTunnel中,这些操作通过“转换”插件实现。
SeaTunnel提供了丰富的转换插件,包括但不限于:
- SQL转换器:允许用户使用SQL语句来对数据进行过滤、选择、聚合等操作。
- 字段映射:可以重命名字段或转换字段类型。
- 聚合转换器:支持对数据进行聚合操作,如SUM、COUNT、AVG等。
- 过滤器:根据特定条件过滤掉不符合要求的数据。
- 脚本转换器:允许用户编写自定义的脚本逻辑来对数据进行复杂处理。
以下是一个SQL转换器的示例配置,它过滤出log_level为ERROR的日志记录:
transform:- plugin_name: sqlquery: "SELECT * FROM input WHERE log_level = 'ERROR'"
该SQL转换器将处理数据流中的每一条记录,并仅保留日志级别为ERROR的记录。
Sink(接收器)
接收器是数据处理流程的终点,它定义了处理后的数据将存储到哪里。SeaTunnel支持多种接收器,能够将数据存储到各种存储系统中,包括但不限于:
- Elasticsearch:将处理后的数据存储到Elasticsearch中,适用于搜索和分析应用场景。
- JDBC:通过JDBC接口将数据写入关系型数据库,如MySQL、PostgreSQL等。
- HDFS:将数据写入HDFS,适用于需要存储大规模批量数据的场景。
- File:将数据写入本地或分布式文件系统,可以支持多种文件格式,如CSV、JSON、Parquet等。
- Kafka:将处理后的数据发送回Kafka,适用于需要进一步处理或传输的场景。
例如,一个Elasticsearch接收器的配置可能如下:
sink:- plugin_name: elasticsearchhosts: ["localhost:9200"]index: "error_logs"document_type: "_doc"bulk_size: 5000flush_interval: 10
在这个配置中,SeaTunnel将处理后的数据以批量方式写入到Elasticsearch中的error_logs索引中,每批最多包含5000条记录,或每10秒刷写一次。
Connector(连接器)
SeaTunnel的连接器插件提供了将数据源、转换器和接收器连接起来的机制。连接器确保数据流能够从源头流向终点,过程中经过所需的各种处理和转换。连接器插件通过定义标准化接口,确保不同的数据源和接收器之间的兼容性,并支持数据流的高效处理。
SeaTunnel支持的连接器类型包括流处理连接器(如Kafka连接器)和批处理连接器(如HDFS连接器)。通过这些连接器,用户可以灵活组合数据处理流水线,从而构建出符合特定业务需求的数据处理解决方案。
三、SeaTunnel的架构
分布式架构
SeaTunnel采用分布式架构设计,能够支持大规模数据处理。其核心是一个分布式数据流处理引擎,能够在多个节点上并行执行数据处理任务,确保在处理大规模数据时依然能够保持高效和稳定。SeaTunnel的架构主要包括以下几个关键组件:
-
调度层:负责SeaTunnel作业的调度与管理,确保作业在集群中高效地执行。调度层通过协调各个节点,分配数据处理任务,监控作业运行状态,并在发生故障时进行容错处理。
-
执行层:负责实际的数据处理工作。每个节点都可以执行数据源读取、数据转换和数据存储操作。执行层通过并行化数据处理任务,提高了数据处理的吞吐量和效率。
-
插件层:通过插件机制,SeaTunnel支持扩展和定制化。用户可以开发自定义插件,实现新的数据源、转换逻辑和接收器。
运行模式
SeaTunnel支持两种主要的运行模式:流处理模式和批处理模式。用户可以根据具体需求选择合适的模式:
- 流处理模式:流处理
模式适用于实时数据处理场景。例如,SeaTunnel可以从Kafka中持续消费消息,并在消费过程中对消息进行实时处理。该模式通常用于低延迟数据处理场景,如实时监控、在线分析等。
- 批处理模式:批处理模式适用于处理静态数据集的场景,如对存储在HDFS中的大规模数据集进行批量处理。该模式适合数据清洗、数据聚合和历史数据分析等场景,通常用于离线数据处理任务。
插件系统
SeaTunnel的插件系统是其灵活性和扩展性的关键。通过插件,用户可以为SeaTunnel添加新的数据源、转换器和接收器,从而扩展其功能以适应各种数据处理需求。插件的配置非常简单,用户只需在配置文件中指定插件名称和相关参数即可。
- 官方插件:SeaTunnel提供了多种官方插件,涵盖了大部分常见的数据源、转换器和接收器。用户可以直接使用这些插件来满足常规的数据处理需求。
- 自定义插件:用户可以根据实际需求开发自定义插件。SeaTunnel为插件开发提供了标准化的接口和开发工具包(SDK),使得开发者可以轻松扩展SeaTunnel的功能。
插件的高可扩展性使得SeaTunnel能够适应快速变化的业务需求,同时也方便了社区和企业用户贡献插件,进一步丰富SeaTunnel的生态系统。
四、安装与配置
环境准备
在安装SeaTunnel之前,确保你的系统环境符合以下要求:
- Java:SeaTunnel基于Java运行时环境,因此需要安装JDK 8或更高版本。Java是SeaTunnel的核心依赖,确保JVM配置合理,以满足大规模数据处理的需求。
- Maven:用于构建和管理SeaTunnel项目。Maven可以帮助你下载并管理SeaTunnel所需的依赖包,以及构建自定义插件或扩展模块。
- 操作系统:SeaTunnel支持在各种操作系统上运行,包括Linux、MacOS和Windows。对于大规模生产环境,推荐在Linux系统上部署。
下载与安装
-
下载SeaTunnel:从Apache官方网站或GitHub仓库下载SeaTunnel的最新版本。你可以选择下载已经编译好的二进制包,或下载源码自行编译。
- 官方下载链接:Apache SeaTunnel下载
- GitHub仓库:GitHub - Apache SeaTunnel
-
解压安装包:将下载的压缩包解压到你选择的目录。推荐将SeaTunnel安装在集群中所有节点的一致路径下,以便于统一管理和调度。
-
配置环境变量:为了方便使用,将SeaTunnel的路径添加到
$SEATUNNEL_HOME环境变量中,并将$SEATUNNEL_HOME/bin添加到$PATH中,这样你可以在命令行中直接使用seatunnel.sh命令启动SeaTunnel作业。 -
测试安装:在命令行中运行
bin/seatunnel.sh --version,检查SeaTunnel是否正确安装。如果一切正常,你将看到SeaTunnel的版本信息和帮助信息。
配置文件
SeaTunnel的配置文件采用YAML格式,用户通过编写配置文件定义数据源、数据转换和数据接收的具体逻辑。配置文件分为三大部分:env、source、transform、sink,分别对应环境配置、数据源配置、转换配置和接收器配置。
以下是一个典型的SeaTunnel配置文件示例,它从Kafka读取数据,进行简单过滤后写入到Elasticsearch:
env:execution.parallelism: 4job.name: "Kafka to Elasticsearch Example"checkpoint.interval: 60fault_tolerance: "exactly_once"source:- plugin_name: kafkabootstrap_servers: "localhost:9092"topics: "log_topic"group_id: "log_processing_group"format: jsonschema:- name: "log_level"type: "string"- name: "message"type: "string"- name: "timestamp"type: "long"transform:- plugin_name: sqlquery: "SELECT * FROM input WHERE log_level = 'ERROR'"sink:- plugin_name: elasticsearchhosts: ["localhost:9200"]index: "error_logs"document_type: "_doc"bulk_size: 5000flush_interval: 10
配置解析:
-
env:定义了作业的全局配置,如并行度(execution.parallelism)、作业名称(job.name)和容错策略(fault_tolerance)。这些参数控制了SeaTunnel作业的整体运行行为。 -
source:定义了数据源,此处为Kafka数据源。它指定了Kafka集群地址、订阅的主题、消费者组ID和数据格式等参数。 -
transform:定义了数据的转换逻辑,此处为SQL转换器。它将过滤出log_level为ERROR的日志记录。 -
sink:定义了数据的接收器,此处为Elasticsearch接收器。它指定了Elasticsearch集群的地址、目标索引名称、文档类型以及数据写入的批量大小和刷新间隔。
五、 SeaTunnel示例
示例1:从Kafka到Elasticsearch的数据处理
场景描述:假设你正在构建一个实时日志处理系统,从Kafka中消费日志数据,过滤出错误日志,并将这些错误日志存储到Elasticsearch中,以便后续查询和分析。
步骤1:配置Kafka数据源
source:- plugin_name: kafkabootstrap_servers: "localhost:9092"topics: "log_topic"group_id: "log_processing_group"format: jsonschema:- name: "log_level"type: "string"- name: "message"type: "string"- name: "timestamp"type: "long"
解释:这个配置定义了从Kafka主题log_topic中读取数据,数据格式为JSON,包含log_level、message和timestamp三个字段。
步骤2:配置SQL转换器
transform:- plugin_name: sqlquery: "SELECT * FROM input WHERE log_level = 'ERROR'"
解释:SQL转换器会过滤出日志级别为ERROR的记录,仅保留这些错误日志。
步骤3:配置Elasticsearch接收器
sink:- plugin_name: elasticsearchhosts: ["localhost:9200"]index: "error_logs"document_type: "_doc"bulk_size: 5000flush_interval: 10
解释:处理后的数据将批量写入Elasticsearch中的error_logs索引,每批最多5000条记录,或每10秒刷新一次。
示例2:批处理HDFS数据
场景描述:你需要处理存储在HDFS中的历史销售数据,将其按类别进行聚合统计,并将结果存储到MySQL数据库中。
步骤1:配置HDFS数据源
source:- plugin_name: hdfspath: "hdfs://namenode:8020/user/hadoop/sales_data"format: parquetschema:- name: "category"type: "string"- name: "sales_amount"type: "double"- name: "date"type: "string"
解释:这个配置定义了从HDFS读取Parquet格式的销售数据,包含category、sales_amount和date三个字段。
步骤2:配置聚合转换器
transform:- plugin_name: aggregategroup_by: ["category"]aggregate_func: "SUM"aggregate_field: "sales_amount"
解释:聚合转换器会按category字段分组,统计每个类别的sales_amount总和。
步骤3:配置MySQL接收器
sink:- plugin_name: jdbcurl: "jdbc:mysql://localhost:3306/analytics"table: "category_sales_summary"username: "root"password: "password"batch_size: 2000
解释:将聚合结果写入MySQL数据库中的category_sales_summary表,每次批量插入2000条记录。
六、常见问题与调优建议
常见问题
-
配置错误:配置文件中的参数错误或遗漏是常见问题。请确保所有必需的配置项都已正确设置,特别是在配置复杂的数据源和接收器时,详细阅读官方文档以避免错误。
-
依赖问题:SeaTunnel依赖于多个开源组件,如Java、Maven以及相关插件库。确保这些依赖已
正确安装并与SeaTunnel版本兼容,尤其是在使用自定义插件时,务必确认依赖库的版本匹配。
- 性能问题:处理大规模数据时,性能瓶颈可能会出现。SeaTunnel提供了多种调优手段,如通过调整并行度(
parallelism)、优化SQL查询、合理配置批处理参数等方式提高处理效率。
性能调优
-
优化并行度:SeaTunnel作业的并行度(
parallelism)直接影响数据处理的速度。根据实际数据规模和集群资源,适当调整并行度可以显著提高处理效率。通过增加并行度,可以利用更多的计算资源来加速数据处理。 -
合理选择插件:根据数据量和处理复杂度选择合适的插件。例如,对于简单的字段映射操作,选择轻量级的转换器可以减少不必要的资源消耗。如果需要处理复杂的转换逻辑,建议使用SQL转换器或自定义脚本转换器,以最大化灵活性。
-
监控与分析:使用监控工具(如Prometheus、Grafana)实时监控SeaTunnel作业的运行状态,分析和定位性能瓶颈。SeaTunnel支持与监控系统集成,通过监控指标(如作业的处理延迟、吞吐量、资源利用率等)来优化性能。
-
调整数据流配置:在流处理模式下,数据的流速和批处理大小(
bulk_size)会影响整体性能。适当调整这些参数,可以避免数据处理中的拥塞和资源浪费。 -
资源分配与隔离:在多租户环境中,合理配置SeaTunnel作业的资源(如CPU、内存)并进行资源隔离,可以避免资源争用导致的性能下降。同时,可以通过容器化技术(如Docker)来实现资源隔离和动态扩展。
-
使用缓存与中间存储:在处理需要多次重复计算或跨批次依赖的数据时,可以考虑使用缓存或中间存储(如Redis、Memcached),以减少重复计算和数据传输的开销。
七、总结
Apache SeaTunnel是一款功能强大且灵活的数据集成工具,特别适用于需要处理多种数据源并进行复杂数据转换的场景。SeaTunnel支持流处理和批处理两种模式,能够满足实时和离线数据处理的多样化需求。通过其插件系统,SeaTunnel能够适应快速变化的业务需求,并轻松扩展以支持新的数据源和处理逻辑。
SeaTunnel在大数据处理生态系统中占据了重要的位置,其简洁的配置与强大的扩展性使得它在数据集成领域具有广泛的应用前景。无论是初创公司还是大型企业,都可以通过SeaTunnel构建高效、可靠的数据处理管道,从而支持业务分析、机器学习和其他数据驱动的应用。
通过本文的详细介绍,你应该已经对SeaTunnel的基本概念、架构及其应用场景有了深入了解。希望这篇文章能帮助你在实际项目中有效地应用SeaTunnel,并解决复杂的数据处理问题。如果你有任何疑问或遇到问题,建议参考SeaTunnel的官方文档和社区资源。
八、参考资料
- Apache SeaTunnel 官方文档
- GitHub 仓库
- SeaTunnel 用户手册
- SeaTunnel 社区讨论
- Elasticsearch 官方文档
- Kafka 官方文档
- HDFS 官方文档
相关文章:

Apache SeaTunnel基础介绍
一、什么是Apache SeaTunnel? Apache SeaTunnel(最初名为Waterdrop)是一个开源的分布式数据集成平台,专为大规模数据处理设计。SeaTunnel可以从多种数据源读取数据,进行实时流式处理或批处理,然后将处理后…...

阿里旗下土耳其电商Trendyol计划进军欧洲市场
阿里旗下土耳其电商Trendyol计划进军欧洲市场 近年来,阿里巴巴集团在全球电商领域的布局持续深化,其旗下土耳其电商巨头Trendyol更是凭借其出色的市场表现和强劲的增长势头,成为了备受瞩目的焦点。近日,Trendyol宣布了一项重要战…...

IBM中国研发裁员与AIGC浪潮下的中国IT产业新篇章:挑战、机遇与未来展望
文章目录 一、跨国公司战略调整与全球IT版图的重构1. 跨国公司的战略考量2. 中国IT产业的应对策略 二、人才市场的深刻变革与应对策略1. 人才流失与再就业压力2. 人才培养与引进策略3. 个人职业规划与发展 三、AIGC浪潮下的中国IT产业新机遇1. AIGC技术的潜力与前景2. 中国IT产…...

基于Python的影视推荐平台的设计与实现--附源码79147
摘要 本论文主要论述了如何基于Python和大数据开发一个影视推荐平台,本系统将严格按照软件开发流程进行各个阶段的工作,面向对象编程思想进行项目开发。在引言中,作者将论述影视推荐平台的当前背景以及系统开发的目的,后续章节将严…...
(C语言))
Baumer工业相机堡盟工业相机如何通过BGAPISDK使用短曝光功能(曝光可设置1微秒)(C语言)
Baumer工业相机堡盟工业相机如何通过BGAPISDK使用短曝光功能(曝光可设置1微秒)(C语言) Baumer工业相机Baumer工业相机BGAPISDK和短曝光功能的技术背景Baumer工业相机通过BGAPISDK使用短曝光功能1.引用合适的头文件2.通过BGAPISDK使…...

Ubuntu 安装PostgreSQL
安装 PostgreSQL 包: 使用 apt-get 命令安装 PostgreSQL 客户端和服务器包:sudo apt update sudo apt install postgresql postgresql-client启动 PostgreSQL 服务: 在 Ubuntu 中,PostgreSQL 服务默认会自动启动。你可以使用以下命…...

sqlalchemy FastAPI 前端实现数据库增删改查
sqlalchemy FastAPI 前端实现数据库增删改查 仅个人学习笔记,感谢点赞关注! 知识点 连接数据库sqlalchemy 创建表结构FastAPI get post put delete操作FastAPI 请求体 路径和修改参数 依赖项 代码 # -*- ecoding: utf-8 -*- # Author: SuperLong # Em…...

QQueue调用dequeue闪退解决方法
QQueue调用dequeque闪退的解决方法 先看一下Qt帮助文档里面的说明 这个函数假设队列不是空的。 那么我们在调用之前,需要先判断队列是不是空的,如果不是空的,就调用该函数。 if (!queue.isEmpty()) {QString info queue.dequeue(); }这样…...

CSP-J算法基础 计数排序
文章目录 前言计数排序计数排序的过程总结 代码实现计数排序总结 前言 计数排序 计数排序(Counting Sort)是一种线性时间复杂度的排序算法,适用于范围有限的整数排序。它通过计数每个值出现的次数,依次排列这些值。该算法不通过比…...

Java泛型类型解析
解析泛型类型 获取字段泛型类型 **java.lang.reflect.Field#getGenericType**: 作用:返回字段的泛型类型。返回类型:Type。如果字段是一个泛型类型,这个方法将返回一个表示这个泛型类型的 Type 对象,比如 ParameterizedType&…...

EasyExcel 学习之 导出 “类型及精度问题”
目录 现象缘由类型问题精度/格式问题精度问题格式问题 解决 现象 Excel 导出时,可能面临几个问题: 类型问题:常见类型转换、URL 转图片等精度/格式问题:数字、日期转换 缘由 类型问题 Excel 常见的 API 有两种,Ea…...

从视频中每隔10帧截取一帧并保存为图片
要从视频中每隔10帧截取一帧并保存为图片,可以使用 OpenCV 库。 import cv2# 视频文件的路径 video_path path/to/your/video.mp4# 创建一个 VideoCapture 对象 cap cv2.VideoCapture(video_path)# 检查是否成功打开视频文件 if not cap.isOpened():print("E…...

防火墙、firewalld指令、更改yum源为阿里云的yum源及常见问题
一、防火墙分类 1、硬件防火墙 2、软件防火墙(咱们昨天学的就属于这个) 3、waf 4、下一代防火墙 二、工作原理 1、通过对进出口数据的(数据、端口、IP等)进行过滤,达到对内网数据的保护。 2、防护危险的一堵墙、…...

5G Multicast/Broadcast Services(MBS) (二) Multicast
这篇是Multicast handling的overview,正文开始。 值得注意的是,对于5MBS multicast,UE只有处于 RRC connected和Inactive时,网络侧才可以 通过MRB将MBS multicast数据传输到 UE;处于Idle态只能进行MBS broadcast过程。 对于multicast涉及的RN...

【计算机方向】中科院二区潜力刊!最快14天accept,还是非OA ,不能错过!
期刊解析 🚩本 期 期 刊 看 点 🚩 非OA 审稿友好,审稿速度快 自引率7.9% 今天小编带来计算机领域SCI快刊的解读! 如有相关领域作者有意投稿,可作为重点关注! 01 期刊信息✦ 期刊名称:Inter…...
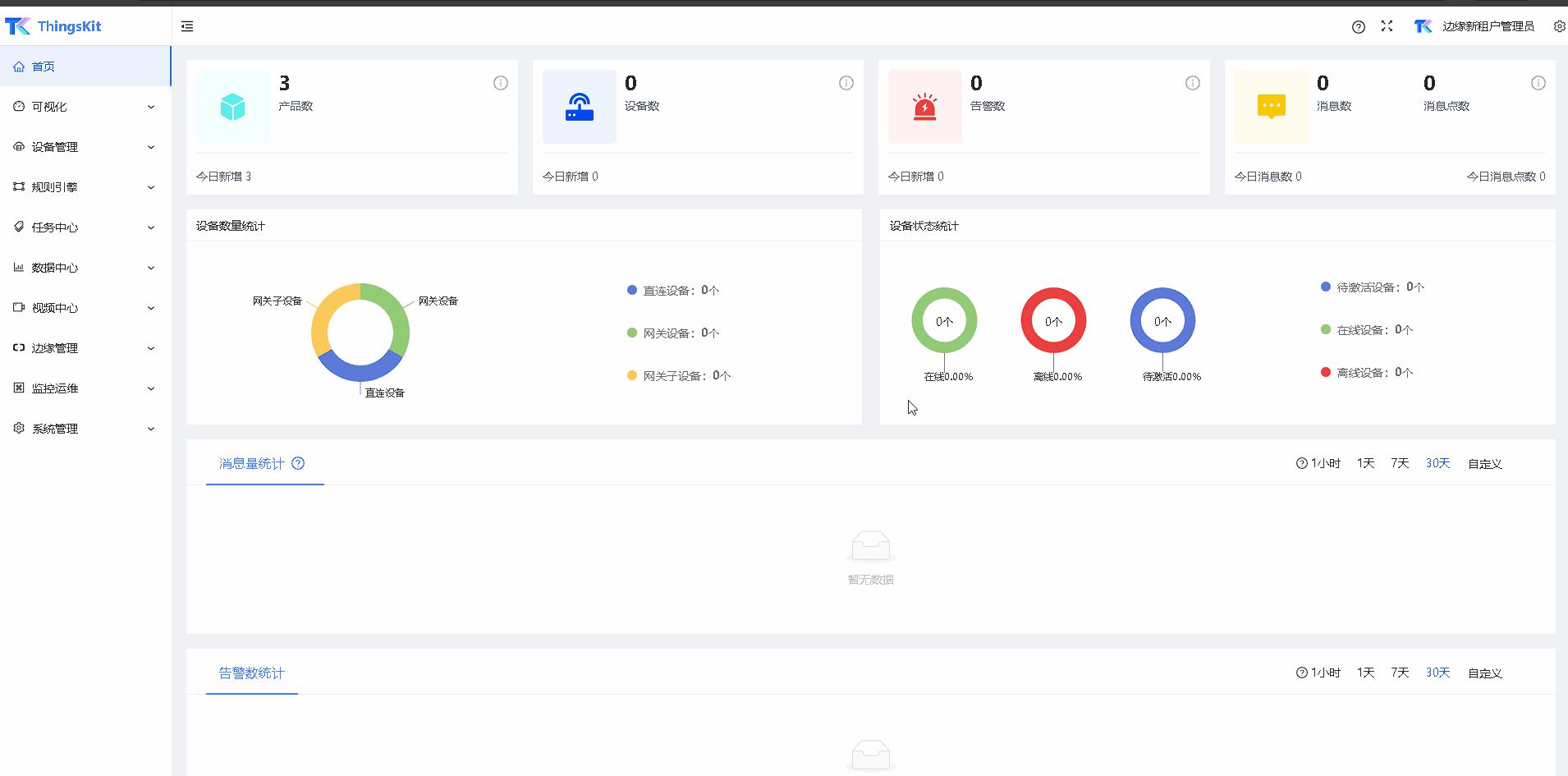
合适做项目交付的物联网平台:ThingsKit
ThingsKit,作为一个专为项目交付设计的物联网平台,凭借其强大的功能和灵活性,成为了众多企业的首选。 一、ThingsKit的核心优势 模块化设计:ThingsKit采用模块化设计,使得用户可以根据自己的需求灵活选择和组合不同的…...

python绘制3D瀑布图
成品: 代码: def line_3d(x, y, z, x_label_indexs):"""在y轴的每个点,向x轴的方向延伸出一个折线面:展示每个变量的时序变化。x: x轴,时间维,右边。y: y轴,变量维,…...

ArcGIS中怎么合并多个点图层并删除重复点?
最近,我接到了一个怎么合并多个点图层并删除其中的重复点的咨询。 下面是我对这个问题的解决思路: 1、合并图层 在地理处理工具里面 选择合并 并设置好要合并的图层即可 2、接下来在 数据管理工具→常规→删除相同项 即可 希望这些建议能对大家有所帮…...

【vue、UI】使用 Vue2 和 Element UI 封装 CSV 文件上传组件,实现csv回显
文章目录 前言组件功能概述实现效果组件模板结构组件的核心逻辑1.数据属性定义2.方法拆解3.CSV 文件解析方法4. 错误处理方法 组件样式完整组件代码总结待优化的地方 前言 在 Vue2 项目中,我们经常需要封装一些可重用的组件来提升开发效率。本文将介绍如何使用 Vue…...

erlang学习: Mnesia Erlang数据库2
Mnesia数据库增加与查询学习 -module(test_mnesia).-record(shop, {item, quantity, cost}). -record(cost, {name, price}). -record(design, {info, plan}). %% API -export([insert/3,select/1,start/0]). start() ->mnesia:start().insert(Name, Quantity, Cost) ->…...

模电数电不再怕:用甘晴void的三本笔记法,搞定HNU电路与电子学课堂测验与作业
模电数电不再怕:用甘晴void的三本笔记法,搞定HNU电路与电子学课堂测验与作业 电路与电子学这门课,对很多计算机专业的学生来说就像一座难以逾越的高山。模电的抽象概念、数电的逻辑设计,加上频繁的课堂测验和课后作业,…...

如何在Windows 11上快速安装Android应用?终极APK安装器完全指南 [特殊字符]
如何在Windows 11上快速安装Android应用?终极APK安装器完全指南 🚀 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装Android…...

告别环境配置烦恼:手把手教你搞定Qualcomm AI Engine Direct在Windows和Linux下的开发环境
高通AI引擎开发环境全攻略:Windows与Linux双平台实战指南 第一次打开Qualcomm AI Engine Direct SDK的压缩包时,你可能会有种面对乐高零件箱的错觉——各种架构的库文件、不同平台的工具链、错综复杂的依赖关系扑面而来。作为曾在多个芯片平台迁移AI模型…...

别再死记硬背了!用Python模拟一个简单的图灵机,帮你彻底搞懂计算理论
用Python构建图灵机:从理论到代码的沉浸式学习 在计算机科学教育中,图灵机常被视为一个抽象难懂的概念——那些状态转移符号和无限长的纸带总让人望而生畏。但当我第一次用代码实现了一个简单的图灵机后,整个计算理论突然变得清晰可见。本文将…...

探索罗技鼠标宏:掌握PUBG压枪技术的完整路径
探索罗技鼠标宏:掌握PUBG压枪技术的完整路径 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技性极强的射击游戏…...

卡尔曼滤波在目标跟踪中的应用:原理、建模与工程调参实战
1. 项目概述:从“猜”到“算”的跟踪艺术在目标跟踪这个领域,无论是自动驾驶中预测前车的轨迹,还是无人机锁定移动的物体,亦或是视频监控里框住一个行走的人,我们核心要解决的都是一个问题:如何在充满噪声和…...

YOLOv8模型家族全解析:P2、P6、标准版到底该选哪个?一张图帮你搞定选择困难症
YOLOv8模型家族全解析:P2、P6、标准版到底该选哪个? 在计算机视觉项目的初期,模型选型往往是最令人头疼的环节。面对GitHub仓库中琳琅满目的YAML配置文件,即便是经验丰富的工程师也难免陷入选择困难。YOLOv8作为当前最先进的目标检…...

不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响
不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响 在模拟集成电路设计中,电阻作为最基本的无源元件之一,其版图实现往往被初学者视为简单的金属连线问题。然而,当设计从原理图转向物理实现时ÿ…...
)
别再手动画路牙了!用SpeedRoad插件5分钟搞定3DMax城市道路建模(含十字路口避坑指南)
3DMax城市道路建模革命:SpeedRoad插件高效工作流全解析 从手动建模到智能生成的效率跃迁 在建筑可视化、游戏场景搭建和城市规划项目中,道路建模往往是耗时又枯燥的环节。传统手动建模方式需要逐个创建路面、路牙、人行道和交通标线,不仅效率…...
)
保姆级教程:在Ubuntu上把YOLOv5的ONNX模型转成RV1126能用的RKNN模型(附完整代码)
从ONNX到RKNN:YOLOv5模型在RV1126平台的完整转换指南 当清晨的第一缕阳光透过窗帘缝隙洒在键盘上,我正盯着终端里那个顽固的ONNX模型发愁——它已经在我的Ubuntu工作站上运行了整整一夜,却依然没能成功转换为RV1126开发板可用的RKNN格式。这…...