Pyspark下操作dataframe方法(1)
文章目录
- Pyspark dataframe
- 创建DataFrame
- 使用Row对象
- 使用元组与scheam
- 使用字典与scheam
- 注意
- agg 聚合操作
- alias 设置别名
- 字段设置别名
- 设置dataframe别名
- cache 缓存
- checkpoint RDD持久化到外部存储
- coalesce 设置dataframe分区数量
- collect 拉取数据
- columns 获取dataframe列
Pyspark dataframe
创建DataFrame
from pyspark.sql import SparkSession,Row
from pyspark.sql.types import *def init_spark():spark = SparkSession.builder.appName('LDSX_TEST_DATAFrame') \.config('hive.metastore.uris', 'thrift://hadoop01:9083') \.config('spark.master', "local[2]") \.enableHiveSupport().getOrCreate()return spark
spark = init_spark()# 设置字段类型
schema = StructType([StructField("name", StringType(), True),StructField("age", StringType(), True),StructField("id", StringType(), True),StructField("gender", StringType(), True),
])
使用Row对象
cs = Row('name','age','id','gender')
row_list = [ cs('ldsx','12','1','男'),cs('test1','20','1','女'),cs('test2','26','1','男'),cs('test3','19','1','女'),cs('test4','51','1','女'),cs('test5','13','1','男')]
data = spark.createDataFrame(row_list)
data.show()+-----+---+---+---+
| name|age| id|gender|
+-----+---+---+---+
| ldsx| 12| 1| 男|
|test1| 20| 1| 女|
|test2| 26| 1| 男|
|test3| 19| 1| 女|
|test4| 51| 1| 女|
|test5| 13| 1| 男|
+-----+---+---+---+
data.printSchema()
root|-- name: string (nullable = true)|-- age: string (nullable = true)|-- id: string (nullable = true)|-- gender: string (nullable = true)
使用元组与scheam
park.createDataFrame([('ldsx1','12','1','男'),('ldsx2','12','1','男')],schema).show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
|ldsx1| 12| 1| 男|
|ldsx2| 12| 1| 男|
+-----+---+---+------+
使用字典与scheam
spark.createDataFrame([{'name':'ldsx','age':'12','id':'1','gender':'女'}]).show()
+---+------+---+----+
|age|gender| id|name|
+---+------+---+----+
| 12| 女| 1|ldsx|
+---+------+---+----+
注意
scheam设置优先级高于row设置,dict设置的key
schema = StructType([StructField("name", StringType(), True),StructField("age", StringType(), True),StructField("id", StringType(), True),StructField("测试", StringType(), True),
])
spark.createDataFrame([{'name':'ldsx','age':'12','id':'1','gender':'女'}],schema).show()
+----+---+---+----+
|name|age| id|测试|
+----+---+---+----+
|ldsx| 12| 1|null|
+----+---+---+----+
agg 聚合操作
在 PySpark 中,agg(aggregate)函数用于对 DataFrame 进行聚合操作。它允许你在一个或多个列上应用一个或多个聚合函数,并返回计算后的结果。可以结合groupby使用。
from pyspark.sql import functions as sf
data.show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
| ldsx| 12| 1| 男|
|test1| 20| 1| 女|
|test2| 26| 1| 男|
|test3| 19| 1| 女|
|test4| 51| 1| 女|
|test5| 13| 1| 男|
+-----+---+---+------+
data.agg({'age':'max'}).show()
+--------+
|max(age)|
+--------+
| 51|
+--------+
data.agg({'age':'max','gender':"max"}).show()
+-----------+--------+
|max(gender)|max(age)|
+-----------+--------+
| 男| 51|
+-----------+--------+data.agg(sf.min(data.age)).show()
+--------+
|min(age)|
+--------+
| 12|
+--------+
data.agg(sf.min(data.age),sf.min(data.name)).show()
+--------+---------+
|min(age)|min(name)|
+--------+---------+
| 12| ldsx|
+--------+---------+结合groupby使用
data.groupBy('gender').agg(sf.min('age')).show()+------+--------+
|gender|min(age)|
+------+--------+
| 女| 19|
| 男| 12|
+------+--------+
data.groupBy('gender').agg(sf.min('age'),sf.max('name')).show()
+------+--------+---------+
|gender|min(age)|max(name)|
+------+--------+---------+
| 女| 19| test4|
| 男| 12| test5|
+------+--------+---------+alias 设置别名
字段设置别名
#字段设置别名
data.select(data['name'].alias('rename_name')).show()
+-----------+
|rename_name|
+-----------+
| ldsx|
| test1|
| test2|
| test3|
| test4|
| test5|
+-----------+
设置dataframe别名
d1 = data.alias('ldsx1')
d2 = data2.alias('ldsx2')
d1.show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
| ldsx| 12| 1| 男|
|test1| 20| 1| 女|
|test2| 26| 1| 男|
|test3| 19| 1| 女|
|test4| 51| 1| 女|
|test5| 13| 1| 男|
+-----+---+---+------+
d2.show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
|测试1| 12| 1| 男|
|测试2| 20| 1| 男|
+-----+---+---+------+d3 = d1.join(d2,col('ldsx1.gender')==col('ldsx2.gender'),'inner')
d3.show()
+-----+---+---+------+-----+---+---+------+
| name|age| id|gender| name|age| id|gender|
+-----+---+---+------+-----+---+---+------+
| ldsx| 12| 1| 男|测试1| 12| 1| 男|
| ldsx| 12| 1| 男|测试2| 20| 1| 男|
|test2| 26| 1| 男|测试1| 12| 1| 男|
|test2| 26| 1| 男|测试2| 20| 1| 男|
|test5| 13| 1| 男|测试1| 12| 1| 男|
|test5| 13| 1| 男|测试2| 20| 1| 男|
+-----+---+---+------+-----+---+---+------+d3[['name']].show()
#报错提示
pyspark.errors.exceptions.captured.AnalysisException: [AMBIGUOUS_REFERENCE] Reference `name` is ambiguous, could be: [`ldsx1`.`name`, `ldsx2`.`name`].
# 使用别名前缀获取
d3[['ldsx1.name']].show()
+-----+
| name|
+-----+
| ldsx|
| ldsx|
|test2|
|test2|
|test5|
|test5|
+-----+
>>> d3[['ldsx2.name']].show()
+-----+
| name|
+-----+
|测试1|
|测试2|
|测试1|
|测试2|
|测试1|
|测试2|
+-----+
d3.select('ldsx1.name','ldsx2.name').show()
+-----+-----+
| name| name|
+-----+-----+
| ldsx|测试1|
| ldsx|测试2|
|test2|测试1|
|test2|测试2|
|test5|测试1|
|test5|测试2|
+-----+-----+cache 缓存
dataframe缓存默认缓存级别MEMORY_AND_DISK_DESER
df.cache()
# 查看逻辑计划和物理计划
df.explain()
checkpoint RDD持久化到外部存储
Checkpoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,我们采用Checkpoint比较合适,或者数据量很大的时候,采用Checkpoint比较合适。如果数据量小,或者RDD重新计算也是非常快的,直接使用缓存即可。
CheckPoint支持写入HDFS。CheckPoint被认为是安全的
sc = spark.sparkContext
# 设置检查存储目录
sc.setCheckpointDir('hdfs:///ldsx_checkpoint')
d3.count()
# 保存会在hdfs上进行存储
d3.checkpoint()
# 从hdfs读取
d3.count()

coalesce 设置dataframe分区数量
# 设置dataframe分区数量
d3 = d3.coalesce(3)
# 获取分区数量
d3.rdd.getNumPartitions()
collect 拉取数据
当任务提交到集群的时候collect()操作是用来将所有结点中的数据收集到dirver节点,数据量很大慎用防止dirver炸掉。
d3.collect()
[Row(name='ldsx', age='12', id='1', gender='男', name='测试1', age='12', id='1', gender='男'), Row(name='ldsx', age='12', id='1', gender='男', name='测试2', age='20', id='1', gender='男'), Row(name='test2', age='26', id='1', gender='男', name='测试1', age='12', id='1', gender='男'), Row(name='test2', age='26', id='1', gender='男', name='测试2', age='20', id='1', gender='男'), Row(name='test5', age='13', id='1', gender='男', name='测试1', age='12', id='1', gender='男'), Row(name='test5', age='13', id='1', gender='男', name='测试2', age='20', id='1', gender='男')]
columns 获取dataframe列
>>> d3.columns
['name', 'age', 'id', 'gender', 'name', 'age', 'id', 'gender']d3.withColumn('ldsx1.name_1',col('ldsx1.name')).show()
+-----+---+---+------+-----+---+---+------+------------+
| name|age| id|gender| name|age| id|gender|ldsx1.name_1|
+-----+---+---+------+-----+---+---+------+------------+
| ldsx| 12| 1| 男|测试1| 12| 1| 男| ldsx|
| ldsx| 12| 1| 男|测试2| 20| 1| 男| ldsx|
|test2| 26| 1| 男|测试1| 12| 1| 男| test2|
|test2| 26| 1| 男|测试2| 20| 1| 男| test2|
|test5| 13| 1| 男|测试1| 12| 1| 男| test5|
|test5| 13| 1| 男|测试2| 20| 1| 男| test5|
+-----+---+---+------+-----+---+---+------+------------+# 重命名列名
d3.withColumnRenamed('ldsx1.name_1',col('ldsx1.name')).show()
相关文章:
Pyspark下操作dataframe方法(1)
文章目录 Pyspark dataframe创建DataFrame使用Row对象使用元组与scheam使用字典与scheam注意 agg 聚合操作alias 设置别名字段设置别名设置dataframe别名 cache 缓存checkpoint RDD持久化到外部存储coalesce 设置dataframe分区数量collect 拉取数据columns 获取dataframe列 Pys…...

注解实现json序列化的时候自动进行数据脱敏
最近在进行开发的时候遇到一个问题,需要对用户信息进行脱敏处理,原有的方式是写一个util类,在需要脱敏的字段查出数据后,显示掉用方法处理后再set回去,觉得这种方式能实现功能,但是不是特别优雅,…...

使用Python下载文件的简易指南
在日常的数据处理、自动化任务或软件开发中,经常需要从网络上下载文件。Python作为一门功能强大的编程语言,提供了多种方法来实现文件的下载。本文将介绍几种常用的方法来使用Python下载文件,包括使用requests库和urllib库。 准备工作 在开…...
中秋国庆双节长假,景区迎来客流高峰,如何保障景区安全管理?
一、方案背景 近年来,国内旅游市场持续升温,节假日期间景区游客数量激增,给景区安全管理带来了巨大挑战。然而,景区安全风险意识不足、防护措施不完善、游客安全意识欠缺等问题依然存在,导致景区安全事故频发。随着中秋…...

多维数组转一维数组:探索 JavaScript 中的数组扁平化
在 JavaScript 编程中,我们经常会遇到需要将多维数组转换为一维数组的情况。无论是处理复杂的数据结构还是进行数据的进一步操作,数组扁平化都是一个常见且有用的技术。本文将介绍几种在 JavaScript 中将多维数组转换为一维数组的方法。 什么是数组扁平…...

配环境时的一些记录
连centos:正常连就好(密码验证码)连rocky:需要在centos上连,终端里直接ssh [rocky_ip];在vscode中需要: 修改配置文件:打开命令面板(ctrlshiftp) -> 输入并…...

如何解析域名到网站?
在现代互联网中,域名解析是用户访问网站的关键过程。用户通过输入易于记忆的域名来访问网站,而背后则是复杂的域名解析机制将域名转换为服务器的IP地址,使得浏览器能够找到并加载目标网站。聚名网详细介绍域名解析的过程及其相关技术。 一、…...

【F172】基于Springboot+vue实现的智能菜谱系统
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 项目描述 近些年,随着中国经济发展,人民的…...

Spring-AOP核心源码、原理详解前篇
本文主要分4部分 Aop原理介绍介绍aop相关的一些类通过源码详解aop代理的创建过程通过源码详解aop代理的调用过程Aop代理一些特性的使用案例 Spring AOP原理 原理比较简单,主要就是使用jdk动态代理和cglib代理来创建代理对象,通过代理对象来访问目标对象…...

Reflection反射——Class类
概述 在Java中,除了int等基本类型外,Java的其他类型全部都是class(包括interface)。例如: String、Object、Runnable、Exception…… Java反射机制是Java语言的一个重要特性。在学习Java反射机制前,需要了…...

王朝兴替的因果
天道好轮 回,苍天饶过谁。王朝兴亡,天道无情。 而其因果循环,天道之森严,让人敬畏。 王朝创业帝王造下什么业,后世子孙在兴替之时,往往要承担何种果 报。 中国几千年的王朝史,因 果循环&…...

损坏SD数据恢复的8种有效方法
SD卡被用于许多不同的产品来存储重要数据,如图片和重要的商业文件。如果您的SD卡坏了,您需要SD数据恢复来获取您的信息。通过从损坏的SD卡中取回数据,您可以确保重要文件不会永远丢失,这对于工作或个人原因是非常重要的。 有许多…...

好评如潮的年度黑马韩剧,惊喜从一上线就开始
韩剧一直以来都以细腻的情感和紧凑的剧情打动观众,而最近播出的一部作品更是掀起了不小的风波-《法官大人》。孙贤周与金明民两大演技派领衔主演,凭借他们的深沉演技和复杂的角色关系,让这部剧集迅速成为热议焦点。故事围绕着一起交通事故展开…...
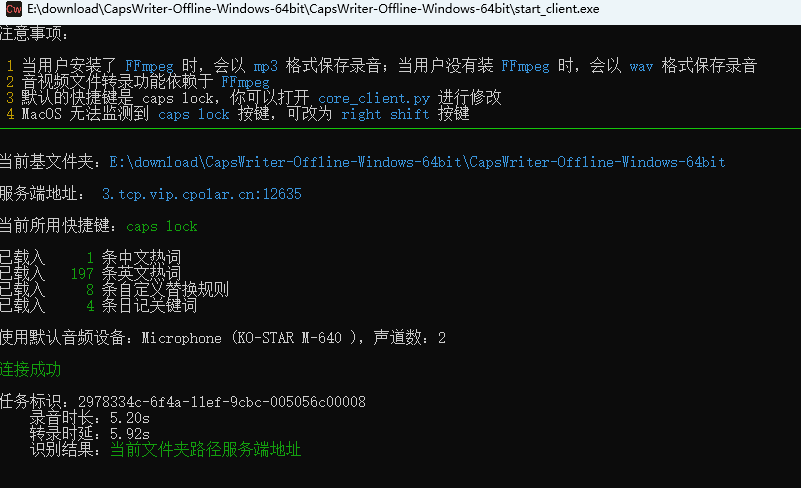
超好用的PC端语音转文字工具CapsWriter-Offline结合内网穿透实现远程使用
文章目录 前言1. 软件与模型下载2. 本地使用测试3. 异地远程使用3.1 内网穿透工具下载安装3.2 配置公网地址3.3 修改config文件3.4 异地远程访问服务端 4. 配置固定公网地址4.1 修改config文件 5. 固定tcp公网地址远程访问服务端 前言 本文主要介绍如何在Windows系统电脑端使用…...

1、https的全过程
目录 一、概述二、SSL过程如何获取会话秘钥1、首先认识几个概念:2、没有CA机构的SSL过程:3、没有CA机构下的安全问题4、有CA机构下的SSL过程 一、概述 https是非对称加密和对称加密的过程,首先建立https链接需要经过两轮握手: T…...
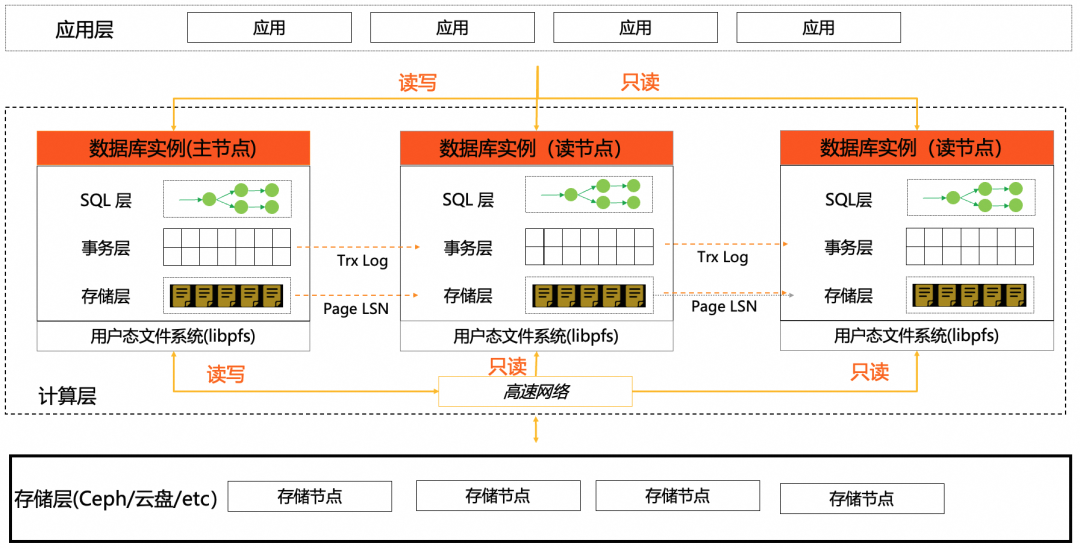
抢鲜体验 PolarDB PG 15 开源版
unsetunsetPolarDB 商业版unsetunset 8 月,PolarDB PostgreSQL 版兼容 PostgreSQL 15 版本(商业版)正式发布上线。 当前版本主要增强优化了以下方面: 改进排序功能:改进内存和磁盘排序算法。 增强SQL功能:支…...

UEFI——使用标准C库
一、C标准库 C标准库是ANSL C标准为C语言定义的标准库。C标准库包含15个头文件:assert.h ctype.h error.h float.h limits.h locale.h math.h setjmp.h signal.h stdarg.h stddef.h stdio.h stdlib.h string.h time.h。标准库函数与C语言的紧密结合给我们开发程序带…...

[全网首发]怎么让国行版iPhone使用苹果Apple Intelligence
全文共分为两个部分:第一让苹果手机接入AI,第二是让苹果手机接入ChatGPT 4o功能。 一、国行版iPhone开通 Apple Intelligence教程 打破限制:让国行版苹果手机也能接入AI 此次发布会上,虽然国行 iPhone16 系列不支持 GPT-4o&…...

C语言-综合案例:通讯录
传送门:C语言-第九章-加餐:文件位置指示器与二进制读写 目录 第一节:思路整理 第二节:代码编写 2-1.通讯录初始化 2-2.功能选择 2-3.增加 和 扩容 2-4.查看 2-5.查找 2-6.删除 2-7.修改 2-8.退出 第三节:测试 下期…...

XWiki中添加 html 二次编辑失效
如果直接在 XWiki 中添加 html, 例如 修改颜色, 新窗口打开主页面等功能, 首次保存是生效的. 如果再次编辑, 则失效, 原因是被转换成了 Markdown 的代码, 而 Markdown 不支持. 解决这个问题可以使用 HTML 宏. 在 XWiki 中使用 Markdown 1.2 语法时,默认 Markdown …...

终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势
终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势 【免费下载链接】gerbv Maintained fork of gerbv, carrying mostly bugfixes 项目地址: https://gitcode.com/gh_mirrors/ge/gerbv 还在为PCB设计文件的查看和验证而烦恼吗?Gerbv这款强…...

别再死磕官网了!用Docker Compose 5分钟搞定Weaviate向量数据库本地部署
5分钟极速部署Weaviate:Docker Compose避坑指南 当开发者第一次接触Weaviate时,往往会被官网复杂的配置选项和冗长的文档吓退。作为一款开源的向量数据库,Weaviate确实提供了强大的语义搜索和AI原生功能,但官方安装流程却像迷宫一…...

15分钟搞定国标视频监控平台部署,wvp-GB28181-pro让安防系统搭建如此简单!
15分钟搞定国标视频监控平台部署,wvp-GB28181-pro让安防系统搭建如此简单! 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、…...

ComfyUI-VideoHelperSuite:AI视频工作流的专业解决方案
ComfyUI-VideoHelperSuite:AI视频工作流的专业解决方案 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 你是否在ComfyUI中处理视频时感到困扰…...

蓝桥杯备赛:那些教科书里没写的“潜规则”与实战优化
1. 那些容易被忽视的编译细节 参加过蓝桥杯的同学都知道,比赛中最让人崩溃的不是题目有多难,而是明明本地运行好好的代码,提交后却莫名其妙地编译失败。这些坑我在第一次参赛时几乎全踩过,现在回想起来都是血泪教训。 首先是main函…...

Python plt.imshow参数实战:从数据可视化到图像处理
1. 从零认识plt.imshow:你的图像处理瑞士军刀 第一次接触plt.imshow时,我完全被它强大的功能震撼到了。这个看似简单的函数,实际上就像一把瑞士军刀,能搞定从数据可视化到专业图像处理的各类任务。简单来说,plt.imshow…...

基于MCP协议构建AI Agent与Atlassian生态的智能集成实践
1. 项目概述与核心价值最近在折腾AI Agent的生态,特别是如何让它们更好地融入我们日常的开发与项目管理流程。一个绕不开的话题就是MCP(Model Context Protocol),它本质上为AI模型提供了一个标准化的方式来发现、调用和使用外部工…...

EvoAgentX智能体开发框架:模块化架构与进化引擎解析
1. 项目概述:一个面向未来的智能体开发框架最近在探索智能体(Agent)开发领域时,我遇到了一个名为“EvoAgentX”的项目。这个名字本身就很有意思,“Evo”暗示着进化,“AgentX”则指向了智能体及其无限的可能…...

Python 簡單的 股市資料 API 呼叫範例
前言 假如我們想從某個外部服務取得股市資料,藉由Python API 呼叫,可以讓我們從雅虎財經的API下載市場數據。以下簡單得介紹一個API , yfinance 一個 Python 開源函式庫,使用者可以輕鬆地取得股票、指數、貨幣、ETF、基金以及期貨…...

如何在浏览器中实现专业级Markdown文档实时渲染:完整配置指南
如何在浏览器中实现专业级Markdown文档实时渲染:完整配置指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展,…...