Spark的介绍
一、分布式的思想
不管是数据也好,计算也好,都没有最大的电脑,而是多个小电脑组合而成。
存储:将3T的文件拆分成若干个小文件,例如每500M一个小文件,将这些小文件存储在不同的机器上 。 -- HDFS
计算:
分:将一个大的任务拆分成多个小的任务,每台机器处理一 个小的任务,并行处理
合:将多个小任务的结果最终再合并生成最终的结果进行返 回问题解决 。
--MapReduce (Hive)
Spark 解决不了存储的问题,spark是搞计算的。你学习了spark,以前的计算引擎都可以作废了。Spark可以做离线的计算可以做准实时(实时计算目前使用Flink比较多)
发展 :计算引擎 ---存储还得是hdfs
第一代计算引擎:MapReduce:用廉价机器实现分布式大数据处理
第二代计算引擎:Tez:基于MR优化了DAG,性能比MR快一些
第三代计算引擎:Spark:优先使用内存式计算引擎 ,国内目前主要应用的离线计算引擎
第四代计算引擎:Flink:实时流式计算引擎 , 国内目前最主流实时计算引擎
二、Spark简介 [火花]
1、发展历程
DataBricks官网:https://databricks.com/spark/about
spark的诞生其实是因为MR计算引擎太慢了。
MR计算是基于磁盘的,Spark计算是基于内存的。
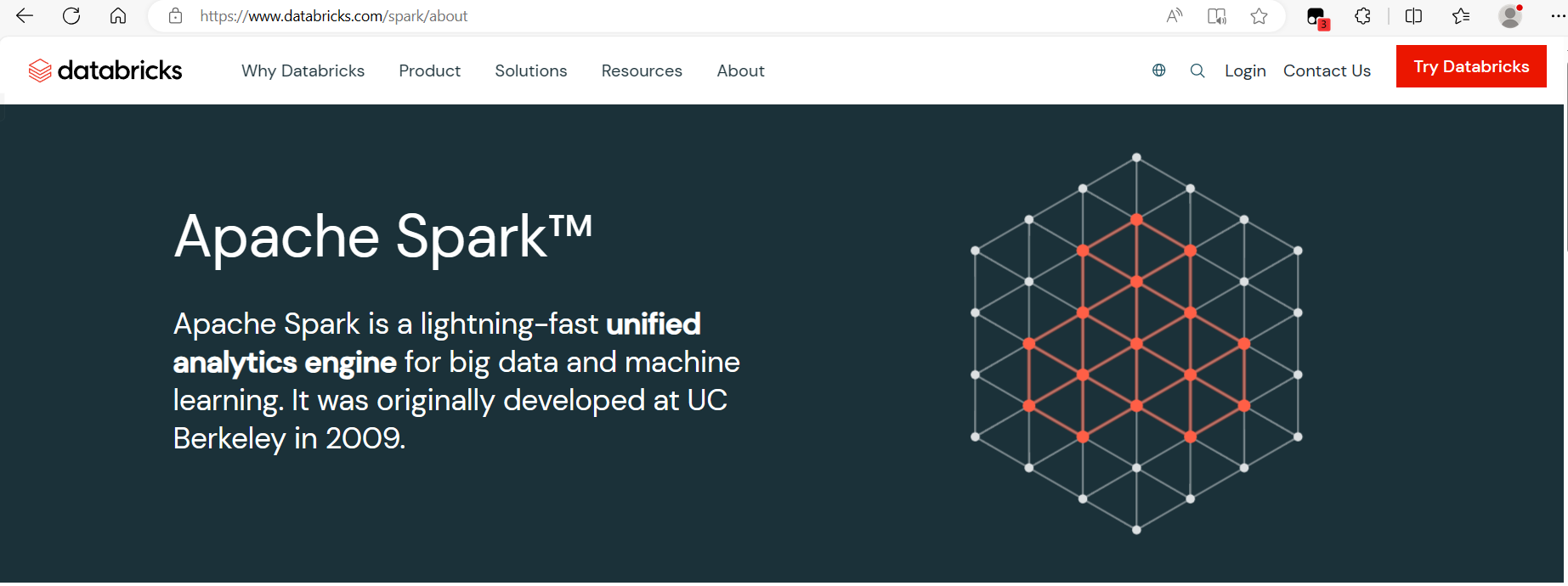
spark的发展历程:
2009年,Spark诞生于伯克利AMPLab,伯克利大学的研究性项目。
2014年2月成为Apache顶级项目,同年5月发布Spark 1.0正式版本
2018年Spark2.4.0发布,成为全球最大的开源项目,目前是Apache中的顶级项目之一。
2020年6月Spark发布3.0.0正式版,目前学习的就是3.x
apache给它分配的网站:Apache Spark™ - Unified Engine for large-scale data analytics
定义:基于内存式计算的分布式的统一化的数据分析引擎。
分析引擎:hive 、spark、presto、impala 等。所谓的引擎,狭义理解就是sql。
2、spark能做什么?
实现离线数据批处理:类似于MapReduce、Pandas,写代码做处理:代码类的离线数据处理
实现交互式即时数据查询:类似于Hive、Presto、Impala,使 用SQL做即席查询分析:SQL类的离线数据处理
实现实时数据处理:类似于Storm、Flink实现分布式的实时计算:代码类实时计算或者SQL类的实时计算
实现机器学习的开发:代替传统一些机器学习工具
3、spark有哪些部分组成?
Hadoop的组成部分:common、MapReduce、Hdfs、Yarn
Spark Core:Spark最核心的模块,可以基于多种语言实现代码类的离线开发 【类似于MR】
Spark SQL:类似于Hive,基于SQL进行开发,SQL会转换为SparkCore离线程序 【类似Hive】
Spark Streaming:基于SparkCore之上构建了准实时的计算模块 【淘汰了】
Struct Streaming:基于SparkSQL之上构建了结构化实时计算模块 【替代了Spark Streaming】
Spark ML lib:机器学习算法库,提供各种机器学习算法工具,可以基于SparkCore或者SparkSQL实现开发。

开发语言:Python、SQL、Scala、Java、R【Spark的源码是通过Scala语言开发的】
一个软件是什么语言写的,跟什么语言可以操作这个软件是两回事儿。
Scala 语言是基于java实现的,底层也需要虚拟机。
4、spark运行有五种模式【重点】
本地模式:Local:一般用于做测试,验证代码逻辑,不是分布式运行,只会启动1个进程来运行所有任务。
集群模式:Cluster:一般用于生产环境,用于实现PySpark程序的分布式的运行
Standalone:Spark自带的分布式资源平台,功能类似于YARN
YARN:Spark on YARN,将Spark程序提交给YARN来运行,工作中主要使用的模式
Mesos:类似于YARN,国外见得多,国内基本见不到
K8s:基于分布式容器的资源管理平台,运维层面的工具。
解释:Spark是一个分布式的分析引擎,所以它部署的时候是分布式的,有用主节点,从节点这些内容。Standalone使用的是Spark自带的分布式资源平台,但是假如一个公司已经有Yarn分析平台了,就没必要再搭建spark分析平台,浪费资源。
学习过程中:本地模式 --> Standalone --> YARN ,将来spark在yarn上跑。
5、spark 为什么比MR快?
1、MR不支持DAG【有向无环图】,计算过程是固定,一个MR 只有1个Map和1个Reduce构成。 一个Map和Reduce是一个过程,和另一个Map和Reduce是不一样的。
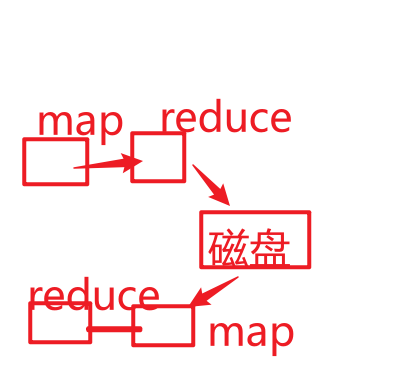
从落地到磁盘的那一刻,上一个过程已经结束了,下一个过程和上一个过程没有关系了。
2、MR是一个基于磁盘的计算框架,读写效率比较低
3、MR的Task计算是进程级别的,每次运行一个Task都需要启动一个进程,然后运行结束还是释放进程,比较慢。【一个进程可以包含多个线程,比如qq是一个进程,发消息,传文件是一个个线程】
MapTask:进程
ReduceTask:进程
进程启动和销毁是比较耗时的
spark为什么那么快?
1、Spark支持DAG,一个Spark程序中的过程是不固定,由代码 所决定。
2、Task任务都是线程级别的
3、计算是基于内存的。


总结:1.数据结构一个HDFS,一个是RDD
2.计算流结构一个用的MR,一个是DAG
3.中间存储一个放到磁盘,一个全在内存
4.运行方式一个用进程,一个是线程
一、Standalone集群环境安装
1、理解Standalone集群架构
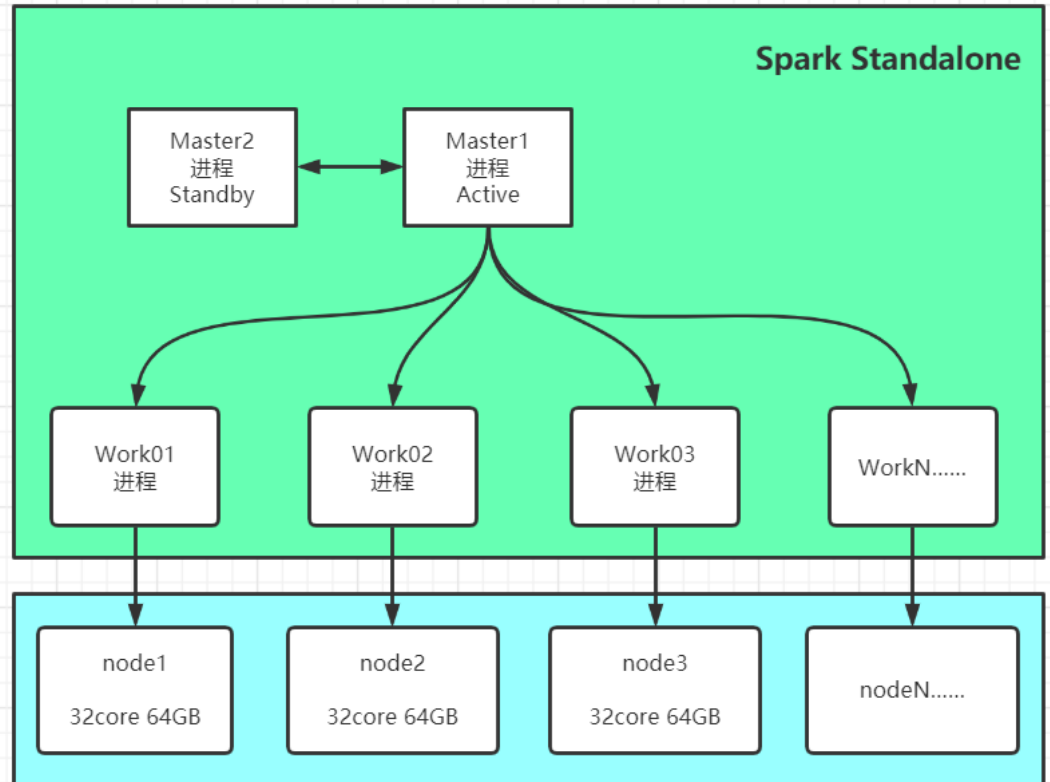

架构:普通分布式主从架构
主:Master:管理节点:管理从节点、接客、资源管理和任务
调度,等同于YARN中的ResourceManager
从:Worker:计算节点:负责利用自己节点的资源运行主节点
分配的任务
功能:提供分布式资源管理和任务调度,基本上与YARN是一致的
看着很像Yarn,其实作用跟yarn一样,是spark自带的计算平台。
每一台服务器上都要安装Annaconda ,否则会出现python3 找不到的错误!!
2、Standalone集群部署
第一步:将bigdata02和bigdata03安装Annaconda,因为里面有python3环境,假如没有安装的话,就报这个错误:
相关文章:
Spark的介绍
一、分布式的思想 不管是数据也好,计算也好,都没有最大的电脑,而是多个小电脑组合而成。 存储:将3T的文件拆分成若干个小文件,例如每500M一个小文件,将这些小文件存储在不同的机器上 。 -- HDFS 计算&#…...

SpringBoot项目是如何启动
启动步骤 概念 运行main方法,初始化SpringApplication 从spring.factories读取listener ApplicationContentInitializer运行run方法读取环境变量,配置信息创建SpringApplication上下文预初始化上下文,将启动类作为配置类进行读取调用 refres…...

科技之光,照亮未来之路“2024南京国际人工智能展会”
全球科技产业的版图正以前所未有的速度重构,而位于中国东部沿海经济带的江浙沪地区,作为科技创新与产业升级的高地,始终站在这一浪潮的最前沿。2024年,这一区域的科技盛宴——“2024南京人工智能展会”即将在南京国际博览中心盛大…...

在深度学习计算机视觉的语义分割中,Boundary和Edge的区别是?
在深度学习中的计算机视觉任务中,语义分割中的 Boundary 和 Edge 其实有一些相似之处,但它们的定义和使用场景略有不同。下面是两者的区别: 1. Boundary(边界) 定义:Boundary 是指一个对象或区域的边界&a…...

【JAVA入门】Day41 - 字节缓冲流和字符缓冲流
【JAVA入门】Day41 - 字节缓冲流和字符缓冲流 文章目录 【JAVA入门】Day41 - 字节缓冲流和字符缓冲流一、缓冲流的体系结构二、字节缓冲流2.1 字节缓冲流提高效率的底层原理 三、字符缓冲流 在IO流体系中,FileInputStream,FileOutputStream,F…...

collocate join,bucket join,broadcast join,shuffle join对比分析
在分布式计算和大数据处理中,尤其是在使用像 Apache Spark、Hive 等大数据处理框架时,Join 操作是非常常见的。根据数据分布方式和执行机制,Join 操作可以分为不同的类型,如 Collocate Join、Bucket Join、Broadcast Join 和 Shuffle Join。以下是它们的详细对比分析: 1.…...

微信自动通过好友和自动拉人进群,微加机器人这个功能太好用了
又发现一个好用的功能,之前就想找一个这种工具,现在发现可以利用微加机器人的两个功能来实现,分别是加好友和关键词拉群 首先 微加机器人的专业版 > 功能 > 加好友设置 可以设置一个关键词通过,这样别人加好友的时候只需要输入制定内…...

R语言统计分析——功效分析3(相关、线性模型)
参考资料:R语言实战【第2版】 1、相关性 pwr.r.test()函数可以对相关性分析进行功效分析。格式如下: pwr.r.test(n, r, sig.level, power, alternative) 其中,n是观测数目,r是效应值(通过线性相关系数衡量࿰…...

Django创建模型
1、根据创建好应用模块 python manage.py startapp tests 2、在models文件里创建模型 from django.db import modelsfrom book.models import User# Create your models here. class Tests(models.Model):STATUS_CHOICES ((0, 启用),(1, 停用),# 更多状态...)add_time mode…...

盘点2024年大家都在用的短视频剪辑工具
你现在休息的时间是不是都靠短视频来消遣?看着看着你就会发现短视频制作好像我也可以了吧?这次我就介绍一些简单好操作的短视频剪辑工具。 1.FOXIT视频剪辑 连接直达>>https://www.pdf365.cn/foxitclip/ 短视频剪辑其实也不难,只需…...

“左侧文字横向”的QTabWidget
左侧用 QToolButton 组, 右侧用 QStackedWidget,信号槽绑定切换页面 可定制化高 QButtonGroup* btnGp new QButtonGroup(this);btnGp->addButton(ui->btn1, 0);btnGp->addButton(ui->btn2, 1);btnGp->addButton(ui->btn3, 2);connect…...

python学习之字符串操作
str python # 定义一个字符串变量 print(id(str))print(str) # 打印整个字符串 print(str[0:-1]) # 打印字符串第一个到倒数第二个字符(不包含倒数第一个字符) print(str[0]) # 打印字符串的第一个字符 print(str[2:5]) # 打印字符串第三到第…...

第7篇:【系统分析师】计算机网络
考点汇总 考点详情 1网络模型和协议:OSI/RM七层模型,网络标准和协议,TCP/IP协议族,端口 七层:应用层,表示层,会话层,传输层,网络层,数据链路层,…...

无人机培训机构组装调试技术详解
一、基础知识学习 在进入无人机组装调试领域之前,扎实的基础知识是不可或缺的。学员需掌握以下内容: 1. 无人机基本原理:了解无人机的飞行原理,包括升力、推力、重力和阻力等基本物理概念,以及无人机的飞行控制系统&…...

汽车的舒适进入功能是什么意思?
移动管家汽车的舒适进入系统是指无钥匙进入功能,它允许驾驶者在距离车辆一定范围内自动感应解锁车辆,并具备无钥匙启动功能。舒适进入系统的核心优势包括: 智能化操作:无需传统钥匙,通过智能感应实现车门解锁和…...

杂七杂八-系统环境安装
杂七杂八-系统&环境安装 1. 系统安装2. 环境安装 仅个人笔记使用,后续会根据自己遇到问题记录,感谢点赞关注 1. 系统安装 Windows安装linux子系统WSL2:使用windows系统跑linux程序(大模型)WSL VSCode:VSCode连接WSL实现高效…...
Redis高可用,Redis性能管理
文章目录 一,Redis高可用,Redis性能管理二,Redis持久化1.RDB持久化1.1触发条件(1)手动触发(2)自动触发 1.2 Redis 的 RDB 持久化配置1.3 RDB执行流程(1) 判断是否有其他持久化操作在执行(2) 父进…...

React项目中使用发布订阅模式
React项目中使用发布订阅模式 1.创建发布订阅器2.在组件中使用发布订阅器3. 订阅数据 发布订阅模式(也称观察者模式)是一种管理跨组件通信的有效方式,尤其是在不希望直接依赖于特定组件的情况下。这种模式允许一个对象(发布者&…...
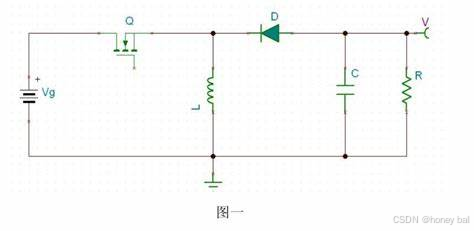
buck boost Ldo 经典模型的默写
BUCK: BOOST: LDO: BUCK-BOOST:...

velero v1.14.1迁移kubernetes集群
1 概述 velero是vmware开源的一个备份和恢复工具,可作用于kubernetes集群下的任意对象和应用数据(PV上的数据)。github地址是https://github.com/vmware-tanzu/velero。 对于应用数据,可分文件级别的复制和块级别的复制。文件级…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...

VSCode光标主题定制指南:从颜色令牌到扩展开发
1. 项目概述:一个为开发者定制的光标主题集合如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定会对编辑器里那个千篇一律的、闪烁的竖线光标感到审美疲劳。warrenwoodhouse/cursors这个项目,就是来解决这个“小…...
)
告别串口线!用STM32CubeMX配置USB-CDC虚拟串口,实现与电脑免驱动通信(附Win7驱动安装指南)
STM32虚拟串口革命:USB-CDC免驱动通信全实战指南 嵌入式开发调试过程中,最令人头疼的莫过于频繁插拔串口线导致的接口松动、接触不良问题。传统串口调试不仅占用宝贵的UART资源,还常常因为物理连接问题浪费大量调试时间。本文将彻底改变这一局…...

基于LLM的长文本摘要工具SumGPT:从原理到本地化部署实战
1. 项目概述:一个为长文本摘要而生的智能工具最近在折腾一些文档处理的工作流,发现一个挺普遍但很烦人的痛点:面对动辄几十页的PDF报告、冗长的会议纪要或是海量的研究论文,想要快速抓住核心要点,简直像大海捞针。手动…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

基于Docker构建标准化开发环境:原理、实践与VSCode集成指南
1. 项目概述:一个面向开发者的“开箱即用”环境在软件开发这条路上,我踩过最多的坑,往往不是来自复杂的业务逻辑,而是来自那句“在我机器上好好的”。环境配置,这个看似基础却又无比磨人的环节,消耗了无数开…...

AI全栈开发实战:基于Cursor的智能代码生成与架构设计
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI代码编辑器有关,并且涉及全栈应用开发。但它的价值远不止于此。作为一个在前…...