Day11笔记-字典基本使用系统功能字典推导式
二、字典【重点掌握】
1.概念
列表和元组的使用缺点:当存储的数据要动态添加、删除的时候,我们一般使用列表,但是列表有时会遇到一些麻烦,定位元素比较麻烦
# 一个列表/元组保存5个学生的成绩, score_list = [66,100,70,78,99] score_tuple = (66,100,70,78,99)解决方案:既能存储多个数据,还能在访问元素的很方便的定位到需要的元素,采用字典
# 一个字典保存5个学生的成绩, score_dict = {"小明":66,"小花":100,"jack":70,"tom":70,"bob":99}
字典习惯使用场景【不是绝对的】:
列表更适合保存相似数据,比如多个商品、多个姓名、多个时间
字典更适合保存不同数据 或者 需要定位数据,比如一个商品的不同信息、一个人的不同信息
2.定义字典
语法:{键1:值1, 键2:值2, 键3:值3, ..., 键n:值n}
说明:
字典和列表类似,都可以用来存储多个数据
在列表中查找某个元素时,是根据索引进行的;字典中找某个元素时,是根据键查找的(就是冒号:前面的那个值,例如上面代码中的'name'、'id'、'sex')
字典中的每个元素都由2部分组成,键:值。例如 'name':'班长' ,'name'为键,'班长'为值
键可以使用数字、布尔值、元组,字符串等不可变数据类型,但是一般习惯使用字符串,切记不能使用列表等可变数据类型,但是,值的数据类型没有限制
每个字典里的key都是唯一的,如果出现了多个相同的key,后面的value会覆盖之前的value
# 【面试题】定义字典的方式有几种,举例说明
# 1. {key1:value1,key2:value2....}
# 2. 字典[key]=value
# 3.dict(key1=value1,key2=value2....)
# 4.dict([(key1,value1),(key2,value2)....])
# 5.dict(zip([key1,key2......],[value1,value2.......]))
# 【面试题】定义字典的方式有几种,举例说明
# 1. {key1:value1,key2:value2....} *******
dict1 = {'a':10,'b':20}
print(dict1)
# 2. 字典[key]=value,当key不存在时,表示添加键值对 ******
dict2 = {}
dict2['aa'] = 66
dict2['bb'] = 77
print(dict2)
# 3.dict(key1=value1,key2=value2....)
# 注意:key=value这种语法和变量的定义类似,最终变量名会被识别为字典中的key
dict31 = dict(x=10,y=20,z=30)
print(dict31) # {'x': 10, 'y': 20, 'z': 30}
dict32 = {10:11,20:22}
print(dict32) # {10: 11, 20: 22}
# dict32 = dict(10=11,20=22) # 不能被识别
# 4.dict([(key1,value1),(key2,value2)....]) ****
dict4 = dict([('name','zhangsan'),('age',10)])
print(dict4)
# dict4 = dict([['name','zhangsan'],['age',10]]) # 列表是可变的
# print(dict4)
dict4 = dict((('name','zhangsan'),('age',10)))
print(dict4)
# 5.dict(zip([key1,key2......],[value1,value2.......])) **********
# zip:映射,[key1,key2......]中的key和[value1,value2.......]中的value会一一对应
dict5 = dict(zip(['a','b','c'],[45,7,89]))
print(dict5)
dict5 = dict(zip(['a','b','c','d'],[45,7,89]))
print(dict5)
dict5 = dict(zip(['a','b','c'],[45,7,89,56,7,8]))
print(dict5)
3.字典的使用
# 1.{}
a = {'fafg','vdfgv'}
print(a,type(a)) # {'fafg', 'vdfgv'} <class 'set'>
b = {'a':10,'b':20}
print(b,type(b)) # {'a': 10, 'b': 20} <class 'dict'>
c = {} # 空字典
print(c,type(c)) # {} <class 'dict'>
d = set() # 空集合
print(d,type(d))
# 2.key和value的数据类型
# a.key:只能是不可变的数据类型【int float bool tuple str】,不能使用可变的数据类型【list dict set 】
d21 = {10:34,34.5:56,False:23,'abv':6,(45,7):67}
print(d21)
# d22 = {[34,6,7]:567}
# print(d22) # TypeError: unhashable type: 'list'
# b.value:可以是任意类型
d21 = {10:34,34.5:5.6,False:True,'abv':'faf',(45,7):[7,8,9]}
print(d21)
# 3.key和value是否可以重复
# a.key:每个字典里的key都是唯一的,如果出现了多个相同的key,后面的value会覆盖之前的value
d31 = {'name':'张三','age':10,'name':'李四'}
print(d31) # {'name': '李四', 'age': 10}
# b.value:可以重复
d32 = {'张三':100,'李四':100}
print(d32)
# 4.字典是无序的
'''
列表/元组/字符串:都是通过索引访问其中的元素/字符,都是有序的
字典:通过key获取value
字典本质上是无序的在Python3.7之前,输出字典的结果显示就是无序的在Python3.7之后,输出字典的结果显示是有序的,但本质上是无序的,容易误导大家
'''
# 集合是无序的
set1 = {45,7,8,9,80,23,34,6}
print(set1) # {34, 6, 7, 8, 9, 45, 80, 23}
4.字典的遍历
info_dict = {'name':'张三','age':18,'hobby':'dance'}
# 注意:通过key可以直接获取value【字典[key]】,但是value无法直接直接获取key,只能通过遍历字典,然后比对获取
# 方式一:遍历所有的key,xxx.keys()
# print(info_dict.keys())
for key in info_dict.keys():print(key,info_dict[key])
# 方式二:遍历所有的key ********
for key in info_dict:print(key,info_dict[key])
# 方式三:遍历所有的value
# print(info_dict.values())
for value in info_dict.values():print(value)
# 方式四:同时遍历key和value ********
# print(info_dict.items())
for key,value in info_dict.items():print(key,value)
5.字典系统功能
d1.update(d2):将d2中的键值对合并到d1中
d1.pop(key):通过指定的key删除key-value对
d.1clear():清空字典
# 【面试题】 d1 = {'a':34,'b':13} d2 = d1.copy() d1['a'] = 88 print(d2) import copy d3 = {'aga':26,'hgh':132,'m':[1,2,3]} d4 = copy.deepcopy(d3) d3['m'][-1] = 88 print(d3) print(d4) d3 = {'aga':26,'hgh':132,'m':[1,2,3]} d4 = copy.copy(d3) # d3.copy() d3['m'][-1] = 88 print(d3) print(d4)
# 1.增
# a.字典[key] = value,当key不存在时,表示添加键值对
dict1 = {}
dict1['aa'] = 66
dict1['bb'] = 77
print(dict1)
# b.d1.update(d2):将d2中的键值对合并到d1中
info_dict = {'name':'张三','age':18,'hobby':'dance'}
sub_dict = {'a':10,'b':20}
info_dict.update(sub_dict) # 类似于列表中的extend
print(info_dict)
print(sub_dict)
# 2.删
# a.xx.pop(key):通过指定的key删除对应的键值对
info_dict = {'name':'张三','age':18,'hobby':'dance'}
# 注意:从字典中删除键值对的时候,最好判断key是否存在
info_dict.pop('age')
print(info_dict)
# 优化
key = 'score'
if key in info_dict:info_dict.pop(key)
else:print('key不存在')
# b.clear():清空字典
info_dict = {'name':'张三','age':18,'hobby':'dance'}
info_dict.clear()
print(info_dict)
# c.del xx[key]
info_dict = {'name':'张三','age':18,'hobby':'dance'}
del info_dict['name']
print(info_dict)
# 3.查
info_dict = {'name':'张三','age':18,'hobby':'dance'}
print(len(info_dict))
print(info_dict.keys())
print(info_dict.values())
print(info_dict.items())
# 注意:默认情况下,求的是所有的key的最值
print(max(info_dict)) # name
print(min(info_dict)) # age
# 4.copy()
# 注意:但凡是可变的数据类型,都有拷贝的功能,字典和列表的深浅拷贝的使用完全相同
# 【面试题】
d1 = {'a':34,'b':13}
d2 = d1.copy()
d1['a'] = 88
print(d1)
print(d2) # {'a':34,'b':13}
import copy
d3 = {'aga':26,'hgh':132,'m':[1,2,3]}
d4 = copy.deepcopy(d3)
d3['m'][-1] = 88
print(d3) # {'aga':26,'hgh':132,'m':[1,2,88]}
print(d4) # {'aga':26,'hgh':132,'m':[1,2,3]}
d3 = {'aga':26,'hgh':132,'m':[1,2,3]}
d4 = copy.copy(d3) # d3.copy()
d3['m'][-1] = 88
print(d3) # {'aga': 26, 'hgh': 132, 'm': [1, 2, 88]}
print(d4) # {'aga': 26, 'hgh': 132, 'm': [1, 2, 88]}
6.字典练习
# 1.已知列表list1 = [34,56,87,78,98,9,34,345,78,9],统计每个元素出现的次数,生成一个字典
# key是列表中的元素,value是该元素在列表中出现的次数
# 2.已知列表,找出最大的年龄,及最大年龄的人的名字
list2 = [{'name':'张三','age':10},{'name':'李四','age':9},{'name':'aaa','age':12},{'name':'小明','age':14},{'name':'bbb','age':10},{'name':'王五','age':8},{'name':'ccc','age':14}
]
# 1.已知列表list1 = [34,56,87,78,98,9,34,345,78,9],统计每个元素出现的次数,生成一个字典
# key是列表中的元素,value是该元素在列表中出现的次数
list1 = [34,56,87,78,98,9,34,345,78,9]
# 方式一
dict1 = {}
for num in list1:if num not in dict1:dict1[num] = 1 # 添加键值对else:dict1[num] += 1 # 修改指定key对应的值
print(dict1)
# 方式二
dict1 = {}
for num in list1:dict1[num] = list1.count(num)
print(dict1)
# 2.已知列表,找出最大的年龄,及最大年龄的人的名字
list2 = [{'name':'张三','age':10},{'name':'李四','age':9},{'name':'aaa','age':12},{'name':'小明','age':14},{'name':'bbb','age':10},{'name':'王五','age':8},{'name':'ccc','age':14}
]
max_age = max([user_dict['age'] for user_dict in list2])
print(max_age)
names_list = []
for user_dict in list2:if user_dict['age'] == max_age:names_list.append(user_dict['name'])
print(f'最大年龄为{max_age},对应的人为:{names_list}')
7.字典推导式
'''
列表推导式:[新列表中的元素 for循环 if语句]
字典推导式:{key:value for循环 if语句}
'''# 1.已知字典dict1 = {'a':10,'b':20},交换dict1中的key和value,生成一个一个新的字典new_dict1
dict1 = {'a':10,'b':20}
# 方式一
new_dict1 = {}
for key,value in dict1.items():
new_dict1[value] = key
print(new_dict1)# 方式二
new_dict1 = {value:key for key,value in dict1.items()}
print(new_dict1)# 练习:生成一个字典{1:1,2:4,3:9,4:16,5:25}
dict2 = {n:n ** 2 for n in range(1,6)}
print(dict2)# 2.如果有if条件
dict3 = {n:n ** 2 for n in range(1,10) if n % 2 == 0}
print(dict3)# 3.
list4 = [m + n for m in 'abc' for n in '123']
print(list4) # 9 ['a1', 'a2', 'a3', 'b1', 'b2', 'b3', 'c1', 'c2', 'c3']dict4 = {m:n for m in 'abc' for n in '123'}
print(dict4) # {'a': '3', 'b': '3', 'c': '3'}
相关文章:

Day11笔记-字典基本使用系统功能字典推导式
二、字典【重点掌握】 1.概念 列表和元组的使用缺点:当存储的数据要动态添加、删除的时候,我们一般使用列表,但是列表有时会遇到一些麻烦,定位元素比较麻烦 # 一个列表/元组保存5个学生的成绩, score_list [66,100,70,78,99] sc…...

Ribbon (WPF)
Ribbon (WPF) 在本文中主要包含以下内容: Ribbon组件和功能应用程序菜单快速访问工具栏增强的工具提示 Ribbon是一个命令栏,它将应用程序的功能组织到应用程序窗口顶部的一系列选项卡中。Ribbon用户界面(UI)增加了特性和功能的可发现性,使用…...

解锁编程潜力,从掌握GitHub开始
目录: 一、搜索开源项目 1、什么是Git 2、Github常用词含义 3、一个完整的项目界面 4、使用Github搜索项目 1)in关键词 2)star或fork数量去查找 3)awesome加强搜索 二、访问速度慢的解决 1、使用网易UU加速器 2、使用…...

HTML转义字符对照表
HTML特殊字符转义对照表一 字符十进制转义字符字符十进制转义字符""&&<<<à>>>不断开空格 ?¡¡Ááâ⢢¢ˆ£££&…...
】)
【zabbix监控软件(配置及常用键值)】
监控软件–zabbix 同类产品:nagios、cacti 简介:能够部署企业级监控平台。 监控范围 1)zabbix SNMP 监控网络设备 防火墙、交换机 2)zabbix agent 监控 服务器:raid插槽 CPU 内存插槽 温度 风扇 操作系统࿱…...

98、RS485全自动收发电路入坑笔记
因为RS485采用叉分信号,只支持半双工。正常的RS485芯片驱动电路是需要GPIO来切换发送和接收模式。如下图所示,一般的RS485电平转换芯片都有RE/DE脚,用来切换收发模式。 例如这篇推荐:芯片RS485自动收发电路常见问题与应对策略 但…...
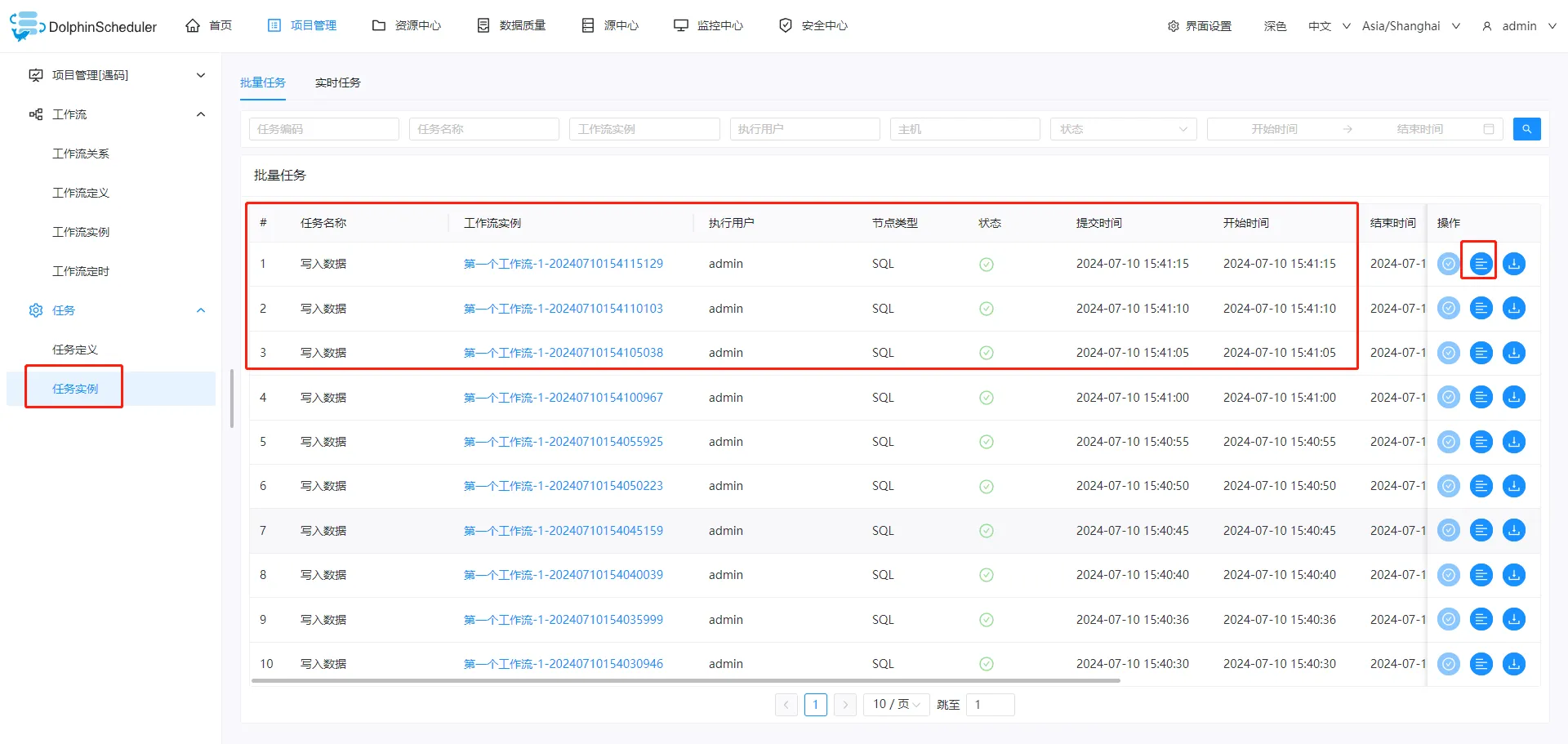
单机快速部署开源、免费的分布式任务调度系统——Apache DolphinScheduler
本文主要为大家介绍Apache DolphinScheduler的单机部署方式,方便大家快速体验。 环境准备 需要Java环境,这是一个老生常谈的问题,关于Java环境的安装与配置期望大家都可以熟练掌握。 验证java环境 java -version 下载安装包并解压 使用wg…...

【运维监控】Prometheus+grafana监控zookeeper运行情况
运维监控系列文章入口:【运维监控】系列文章汇总索引 文章目录 一、prometheus二、grafana三、prometheus集成grafana监控zookeeper1、修改zookeeper配置2、修改prometheus配置3、导入grafana模板4、验证 本示例通过zookeeper自带的监控信息暴露出来,然后…...

【C++二分查找】2560. 打家劫舍 IV
本文涉及的基础知识点 C二分查找 LeetCode2560. 打家劫舍 IV 沿街有一排连续的房屋。每间房屋内都藏有一定的现金。现在有一位小偷计划从这些房屋中窃取现金。 由于相邻的房屋装有相互连通的防盗系统,所以小偷 不会窃取相邻的房屋 。 小偷的 窃取能力 定义为他在…...

位段、枚举、联合
位段 在一个结构体中以位(最小单位)为单位来指定其成员所占的内存长度。位段成员名后面有一个冒号,冒号后有一个数字(这个数字是小于等于这个成员所占的位)。 typedef struct S {char a : 2;//8char b : 8;//8char c …...

golang学习笔记15——golang依赖管理方法
推荐学习文档 golang应用级os框架,欢迎star基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总golang学习笔记01——基本数据类型golang学习笔记02——gin框架及基本原理golang学习笔记03——gin框架的核心数据结构golang学…...

Linux 挂载磁盘与开机自动挂载操作指南
Linux 挂载磁盘与开机自动挂载操作指南 文章目录 Linux 挂载磁盘与开机自动挂载操作指南一 挂载磁盘1 查看硬盘信息2 新增数据盘执行分区3 新建分区4 创建一个主分区5 分区编号6 初始磁柱编号7 截止磁柱编号8 查看新建分区信息9 分区结果写入10 新分区同步操作系统11 设置新分区…...
『功能项目』单例模式框架【37】
我们打开上一篇36C#拓展 - 优化冗余脚本的项目, 本章要做的事情是编写单例模式基类,让继承其基类的子类在运行时只存在一个,共有两个单例基类框架,分别是不继承MonoBehaviour的单例和继承MonoBehaviour的单例框架 首先编写不继承…...

【计算机网络 - 基础问题】每日 3 题(三)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏&…...

SpringCloud Nacos
**************************** 准备工作 首先准备号nacos的镜像 根据镜像创建nacos容器 nacos:container_name: nacosimage: nacos/nacos-server:v2.1.0-slimports: #需要监听三个端口- "8848:8848"- "9848:9848"- "9849:9849"privileged: tr…...

机器学习算法详细解读和python实现
文章目录 一、机器学习概述1.1 机器学习的定义与分类机器学习的分类 1.2 机器学习的基本流程1.3 Python在机器学习中的应用Python的优势Python在机器学习中的应用场景 2.1 线性回归的基本概念线性回归的数学表达线性回归的目标 2.2 最小二乘法技术最小二乘法的数学推导最小二乘…...

【Linux】Linux权限历险记---组和用户的关系
欢迎来到 CILMY23 的博客 🏆本篇主题为:Linux权限历险记---组和用户的关系 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:Python | C | C语言 | 数据结构与算法 | 贪心算法 | Linux | 算法专题 | 代码训练营…...

华为HCIA、HCIP和HCIE认证考试明细
华为认证体系包括三个主要等级:HCIA(华为认证ICT助理)、HCIP(华为认证ICT高级工程师)和HCIE(华为认证ICT专家)。每个等级的认证都有其特定的考试内容和费用。 HCIA(华为认证ICT助理…...

C++数据结构
单向链表 // // Created by 19342 on 2024/9/14. // #include <iostream> using namespace std;// 定义链表节点 struct Node {int data; // 节点存储的数据Node* next; // 指向下一个节点的指针 };// 初始化链表 Node* initList() {return nullptr; }// 在链表末尾添加…...

Linux下read函数详解
在Linux中,read 函数是最常用的系统调用之一,用于从文件或其他输入设备读取数据。它是低级别的I/O操作的核心,直接与操作系统的内核交互,提供了高效的数据读取方式。 一、read 函数简介 read 函数的声明如下: #inclu…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

基于BLE HID与旋转编码器打造双模式无线遥控器
1. 项目概述你有没有过这样的时刻:窝在沙发里看剧,想调个音量或者暂停一下,却不得不伸手去够茶几上的键盘或鼠标,打断那份沉浸的惬意?或者,在电脑上回味一些经典老游戏时,觉得用键盘移动、鼠标射…...

基于GitHub Actions的自动化代码质量守护:CodeBuddy实战指南
1. 项目概述与核心价值最近在和一些团队做代码评审和协作时,我经常遇到一个痛点:大家写的代码风格各异,注释要么缺失要么过时,一些潜在的安全漏洞和性能问题在提交前很难被系统性地发现。虽然市面上有各种静态分析工具,…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...

Deep Lake:AI数据湖与向量数据库一体化管理实践
1. 项目概述:当数据湖遇上深度学习如果你正在构建一个AI应用,无论是图像识别、自然语言处理还是多模态模型,数据管理绝对是你绕不开的“硬骨头”。数据分散在各个文件夹、云存储、数据库里,格式五花八门,加载速度慢&am…...

大语言模型长上下文建模:从注意力优化到Mamba架构的工程实践
1. 项目概述:为什么长上下文建模是LLM的“圣杯”?如果你在过去一年里深度使用过任何主流的大语言模型,无论是ChatGPT、Claude还是开源的Llama、Qwen,一个共同的痛点一定让你印象深刻:“它好像不记得我们之前聊了什么”…...

低配置电脑适配 OpenClaw 搭配 Ollama 流畅使用技巧
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑已成功安装运行 OpenClaw 客户端,顶部 Gateway 状态保持在线网络正常,可顺利访问 Ollama 官方网站电脑空余磁盘空间充足,本地 AI 模型占用体积较大提…...