python简单易懂的lxml读取HTML节点及常用操作方法
python简单易懂的lxml读取HTML节点及常用操作方法
1. 初始化和基本概念
lxml是一个强大的pyth库,用于处理XML和HTML文档。- 它提供了类似BeautifulSoup的功能,但性能更高。
- 在使用
lxml时,通常会先解析HTML或XML文档,得到一个ElementTree对象。
pip install lxml
2. 解析HTML文档
-
使用
lxml.html.fromstring(html)来从字符串中创建一个ElementTree对象。 -
示例:
from lxml import html html_content = '<html><body><p>Hello world!</p></body></html>' tree = html.fromstring(html_content)或者使用etree.HTML(rhtml_content)来创建ElementTree对象:
from lxml import etree
html_content = '<html><body><p>Hello world!</p></body></html>'
tree = etree.HTML(html_content)
3. XPath选择器
-
XPath是一种用于在XML文档中查找信息的语言。
-
lxml支持XPath选择器,可以用来定位文档中的元素。 -
示例:
# 获取所有的段落标签 paragraphs = tree.xpath('//p')
4. 遍历节点
-
iter_node()函数可以用来遍历一个节点的所有子节点。 -
示例:
for node in iter_node(body):# 处理每个节点pass
5. 获取节点属性
-
使用
.attrib属性来获取节点的所有属性。 -
示例:
class_name = node.attrib.get('class', '')
在使用lxml处理HTML或XML文档时,获取节点的属性和属性值是非常常见的需求。下面详细解释如何获取标签的全部属性以及如何分别获取单个属性和属性值。
1. 获取标签的全部属性
在lxml中,你可以通过访问节点的attrib属性来获取所有属性。attrib是一个字典,键是属性名,值是属性值。
示例代码:
from lxml import htmlhtml_content = '''
<div id="content" class="main-content"><p>Hello, world!</p>
</div>
'''tree = html.fromstring(html_content)
div_node = tree.xpath('//div')[0]# 获取所有属性
all_attributes = div_node.attrib
print("All attributes:", all_attributes)# 输出:
# All attributes: {'id': 'content', 'class': 'main-content'}
2. 分别获取单个属性和属性值
如果你只需要获取某个特定属性的值,可以直接通过键访问字典中的值。如果属性不存在,则可以使用get方法提供一个默认值。
示例代码:
# 获取单个属性
id_attribute = div_node.attrib.get('id', 'default-id')
print("ID attribute:", id_attribute)class_attribute = div_node.attrib.get('class', 'default-class')
print("Class attribute:", class_attribute)# 输出:
# ID attribute: content
# Class attribute: main-content
3. 获取属性值
如果属性名已知,可以直接通过键访问字典中的值。如果属性名未知或需要处理多个属性,可以遍历attrib字典来获取所有属性及其值。
示例代码:
# 遍历所有属性
for attr_name, attr_value in div_node.attrib.items():print(f"Attribute: {attr_name}, Value: {attr_value}")# 输出:
# Attribute: id, Value: content
# Attribute: class, Value: main-content
4. 处理特殊情况
在某些情况下,属性可能包含空格分隔的多个值(例如class属性),这时你可以使用split方法来分割字符串。
示例代码:
# 处理包含多个值的属性
class_values = div_node.attrib.get('class', '').split()
print("Class values:", class_values)# 输出:
# Class values: ['main-content']
5. 综合示例
下面是一个综合示例,展示了如何获取节点的所有属性、单个属性以及如何处理特殊情况下的属性值。
from lxml import htmlhtml_content = '''
<div id="content" class="main-content secondary"><p>Hello, world!</p>
</div>
'''tree = html.fromstring(html_content)
div_node = tree.xpath('//div')[0]# 获取所有属性
all_attributes = div_node.attrib
print("All attributes:", all_attributes)# 获取单个属性
id_attribute = div_node.attrib.get('id', 'default-id')
print("ID attribute:", id_attribute)class_attribute = div_node.attrib.get('class', 'default-class')
print("Class attribute:", class_attribute)# 遍历所有属性
for attr_name, attr_value in div_node.attrib.items():print(f"Attribute: {attr_name}, Value: {attr_value}")# 处理包含多个值的属性
class_values = div_node.attrib.get('class', '').split()
print("Class values:", class_values)# 输出:
# All attributes: {'id': 'content', 'class': 'main-content secondary'}
# ID attribute: content
# Class attribute: main-content secondary
# Attribute: id, Value: content
# Attribute: class, Value: main-content secondary
# Class values: ['main-content', 'secondary']
6. 获取节点文本
-
使用
.text属性来获取节点的文本内容。 -
示例:
node_text = node.text
或者如果下面还有子节点的话,最好是用:
# 将所有的文本拼接起来
link_name = ''.join(child.itertext()).strip().replace('\n', '').strip()
# 去掉过多的空格
link_name = re.sub(r'\s+', ' ', link_name ).strip()
7. 获取节点路径
-
使用
.getroottree().getpath(node)来获取节点的完整XPath路径。 -
示例:
path = node.getroottree().getpath(node)
1.获取最末尾节点路径
# 提取最后一个 '/' 后面的元素last_element = path.split('/')[-1] if '/' in path else path
8. 检查节点类型(标签名)
-
通过
.tag属性来检查节点的标签名。 -
示例:
if node.tag == 'p':# 处理段落节点pass
9. 子节点操作
-
使用
.getchildren()来获取节点的所有子节点,node.getparent()获取节点的所有父节点。 -
示例:
children = node.getchildren()
10. 提取属性值
-
使用
@属性名来提取属性值。 -
示例:
image_srcs = node.xpath('.//img/@src')
11. 节点转换为字符串HTML
-
使用
etree.tostring(node)来将节点转换为字符串形式。 -
示例:
node_html = etree.tostring(node, pretty_print=True, encoding='unicode')
12. 计算文本密度
-
文本密度是指文本相对于其他非文本内容(如图片、链接)的比例。
-
通过计算节点中的文本长度与节点总长度的比例来估算文本密度。
-
示例:
text_density = len(node.text_content()) / len(etree.tostring(node))
13. 处理列表页面
-
在处理列表页面时,有时候需要检查是否有特定的类名来进行对应操作,如
'list'。 -
示例:
if 'list' in a_element[0].get('class', '').lower():# 处理列表节点pass
扩展
构建包含属性的XPath路径
流程:
1. 获取子节点的XPath路径
首先,我们遍历一个节点的所有子节点,并获取每个子节点的XPath路径。
for child in node.getchildren():xpath_path = '/' + node.getroottree().getpath(child)
2. 获取子节点的所有属性
对于每个子节点,我们获取其所有属性:
attributes = child.attrib
3. 构建包含属性的XPath路径
接下来,我们根据子节点的属性构建一个完整的XPath路径。如果子节点有属性,我们会在XPath路径后面加上属性条件。
3.1 属性存在时
如果子节点有属性,我们构建一个包含所有属性的XPath路径:
if attributes:xpath_with_attributes = xpath_path + "["for i, (key, value) in enumerate(attributes.items()):xpath_with_attributes += f"@{key}='{value}'"if i < len(attributes) - 1:xpath_with_attributes += " and "xpath_with_attributes += "]"
attributes.items()返回一个迭代器,其中包含了属性的键值对。enumerate(attributes.items())为每个属性分配一个索引。f"@{key}='{value}'"构建一个XPath条件,表示属性key的值为value。- 如果不是最后一个属性,则添加
" and "以连接多个条件。 - 最后添加
"]"来结束XPath条件。
3.2 属性不存在时
如果子节点没有属性,我们直接使用原始的XPath路径:
else:xpath_with_attributes = xpath_path
综合示例
下面是一个完整的示例代码,展示了如何遍历节点的子节点并构建包含属性的XPath路径:
from lxml import htmlhtml_content = '''
<html><body><div id="container" class="main"><p>Hello, world!</p><a href="/link" id="example">Example Link</a></div></body>
</html>
'''tree = html.fromstring(html_content)
root_node = tree.xpath('//div[@id="container"]')[0]# 遍历根节点的所有子节点
for child in root_node.getchildren():xpath_path = '/' + root_node.getroottree().getpath(child)# 获取子节点的所有属性attributes = child.attrib# 构建包含所有属性的XPath路径if attributes:xpath_with_attributes = xpath_path + "["for i, (key, value) in enumerate(attributes.items()):xpath_with_attributes += f"@{key}='{value}'"if i < len(attributes) - 1:xpath_with_attributes += " and "xpath_with_attributes += "]"else:xpath_with_attributes = xpath_pathprint(f"XPath Path: {xpath_path}")print(f"XPath with Attributes: {xpath_with_attributes}")print("Attributes:", attributes)print("")# 输出:
# XPath Path: /html/body/div/p
# XPath with Attributes: /html/body/div/p
# Attributes: {}
#
# XPath Path: /html/body/div/a
# XPath with Attributes: /html/body/div/a[@href='/link' and @id='example']
# Attributes: {'href': '/link', 'id': 'example'}
详细解释
-
获取子节点的XPath路径:
node.getchildren()返回节点的所有子节点。node.getroottree().getpath(child)获取子节点的XPath路径。- 我们在路径前加上
/来确保路径格式正确。
-
获取子节点的所有属性:
child.attrib返回子节点的所有属性及其值。
-
构建包含属性的XPath路径:
- 如果子节点有属性,我们构建一个包含所有属性的XPath路径。
- 使用
enumerate来为每个属性分配一个索引,以便在多个属性之间添加and。 - 如果子节点没有属性,我们直接使用原始的XPath路径。
相关文章:

python简单易懂的lxml读取HTML节点及常用操作方法
python简单易懂的lxml读取HTML节点及常用操作方法 1. 初始化和基本概念 lxml 是一个强大的pyth库,用于处理XML和HTML文档。它提供了类似BeautifulSoup的功能,但性能更高。在使用lxml时,通常会先解析HTML或XML文档,得到一个Eleme…...

Java | Leetcode Java题解之第406题根据身高重建队列
题目: 题解: class Solution {public int[][] reconstructQueue(int[][] people) {Arrays.sort(people, new Comparator<int[]>() {public int compare(int[] person1, int[] person2) {if (person1[0] ! person2[0]) {return person2[0] - perso…...

安卓获取apk的公钥,用于申请app备案等
要申请app的icp备案等场景,需要app的 证书MD5指纹和公钥,示例如下: 步骤1:使用keytool从APK中提取证书 1. 打开命令行,cd 到你的apk目录,如:app/release 2. 解压APK文件: unzip yo…...
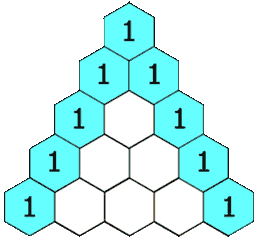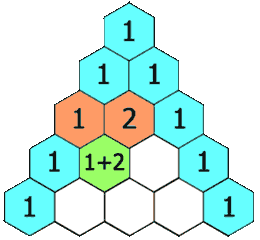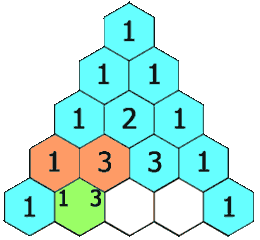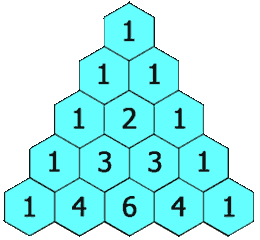
【leetcode_python】杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2: 输入: numRows 1 输出: [[1]] 方案&#…...

Parallels Desktop 20 for Mac中文版发布了?会哪些新功能
Parallels Desktop 20 for Mac 正式发布,完全支持 macOS Sequoia 和 Windows 11 24H2,并且在企业版中引入了全新的管理门户。 据介绍,新版本针对 Windows、macOS 和 Linux 虚拟机进行了大量更新,最大的亮点是全新推出的 Parallels…...

SpringBoot整合SSE-灵活管控连接
SpringBoot整合SSE(管控连接) 1、sse单向通信整成逻辑双向通信。 2、轻量级实现端对端信息互通。 3、避免繁琐配置学习。 核心点通过记录连接码和心跳检测实现伪双向通道,避免无效连接占用过多内存。 服务器推送(Server Push)技术允许网站和应用在有新内容可用时主动向用户…...

挖矿木马-Linux
目录 介绍步骤 介绍 1、挖矿木马靶机中切换至root用户执行/root目录下的start.sh和attack.sh 2、题目服务器中包含两个应用场景,redis服务和hpMyAdmin服务,黑客分别通过两场景进行入侵,入侵与后续利用线路路如下: redis服务&…...

【leetcode——415场周赛】——python前两题
3289. 数字小镇中的捣蛋鬼 数字小镇 Digitville 中,存在一个数字列表 nums,其中包含从 0 到 n - 1 的整数。每个数字本应 只出现一次,然而,有 两个 顽皮的数字额外多出现了一次,使得列表变得比正常情况下更长。 为了…...

【CSS in Depth 2 精译_029】5.2 Grid 网格布局中的网格结构剖析(上)
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第一章 层叠、优先级与继承(已完结) 1.1 层叠1.2 继承1.3 特殊值1.4 简写属性1.5 CSS 渐进式增强技术1.6 本章小结 第二章 相对单位(已完结) 2.1 相对…...
 TCP函数学习)
ZYNQ LWIP(RAW API) TCP函数学习
1 LWIP TCP函数学习 tcp_new()–新建控制块 这个函数用于分配一个TCP控制块,它通过tcp_alloc()函数分配一个TCP控制块结构来存储TCP控制块的数据信息, 如果没有足够的内容分配空间,那么tcp_alloc()函数就会尝试释放一些不太重要的TCP控制块, 比如就会释放处于TIME_WAIT、C…...

Spring Boot,在应用程序启动后执行某些 SQL 语句
在 Spring Boot 中,如果你想在应用程序启动后执行某些 SQL 语句,可以利用 spring.sql.init 属性来配置初始化脚本。这通常用于在应用启动时创建数据库表、索引、视图等,或者填充默认数据。data-locations 和 schema-locations 指定了 SQL 脚本…...

【SQL】百题计划:SQL最基本的判断和查询。
[SQL]百题计划 Select product_id from Products where low_fats "Y" and recyclable "Y";...

04_Python数据类型_列表
Python的基础数据类型 数值类型:整数、浮点数、复数、布尔字符串容器类型:列表、元祖、字典、集合 列表 列表(List)是一种非常灵活的数据类型,它可以用来存储一系列的元素。容器类型,能够存储多个元素的…...

F5设备绑定EIP
公网IP 公网IP(Public IP Address)是指可以直接在互联网上访问的IP地址,用于标识网络上的设备或主机。它允许外部网络访问您的云服务器,如提供远程登录服务、访问Web服务器等。然而,这并不意味着公网IP不需要路由。 …...

使用 PyCharm 新建 Python 项目详解
使用 PyCharm 新建 Python 项目详解 文章目录 使用 PyCharm 新建 Python 项目详解一 新建 Python 项目二 配置环境1 项目存放目录2 Python Interpreter 选择3 创建隔离环境4 选择你的 Python 版本5 选择 Conda executable 三 New Window 打开项目四 目录结构五 程序编写运行六 …...

从0开始学习 RocketMQ:分布式事务消息的实现
消息队列中的事务,主要是解决消息生产者和消息消费者数据一致性的问题。 应用场景 比如订单系统创建订单后,会发消息给购物车系统,将已下单的商品从购物车中删除。 由于购物车删除商品这一步骤并不是用户下单支付这个主流程中的核心步骤&a…...

MySQL 查询数据库的数据总量
需求:查看MySQL数据库的数据总量,以MB为单位展示数据库占用的磁盘空间 实践: 登录到MySQL数据库服务器。 选择你想要查看数据总量的数据库: USE shield;运行查询以获取数据库的总大小: SELECT table_schema AS Datab…...

[C++]——vector
🌇个人主页:_麦麦_ 📚今日小句:快乐的方式有很多种,第一种便是见到你。 目录 一、前言 二、vector的介绍及使用 2.1 vector的介绍 2.2 vector的使用 2.2.1 vector的定义(构造函数) 2.2.2…...
自动驾驶:LQR、ILQR和DDP原理、公式推导以及代码演示(七、CILQR约束条件下的ILQR求解)
(七)CILQR约束条件下的ILQR求解 CILQR((Constrained Iterative Linear Quadratic Regulator)) 是为了在 iLQR 基础上扩展处理控制输入和状态约束的问题。在这种情况下,系统不仅要优化控制输入以最小化代价函数&#x…...

随想录笔记-二叉树练习题
合并二叉树 617. 合并二叉树 - 力扣(LeetCode) dfs递归 class Solution {public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {if(root1null||root2null){return root1null?root2:root1;}return dfs(root1,root2);}public TreeNode dfs(Tre…...

构建现代化小说下载解决方案:探索Rust驱动的番茄小说下载器
构建现代化小说下载解决方案:探索Rust驱动的番茄小说下载器 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读日益普及的今天,小说爱好者们面临…...

【Midjourney提示词黄金公式】:20年AI视觉专家亲授7大风格锚点+3层语义嵌套技巧
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词黄金公式的底层逻辑 Midjourney 的提示词(Prompt)并非自由文本堆砌,而是一套具有语法优先级与语义权重的结构化指令系统。其“黄金公式”——主体 …...

BurpSuite实战:从代理配置到漏洞扫描的完整工作流解析
1. BurpSuite入门:代理配置与证书安装 第一次打开BurpSuite时,那个黑底红字的启动界面总让我想起黑客电影里的场景。不过别被吓到,这其实是个非常友好的Web安全测试工具。我刚开始用的时候,最头疼的就是代理配置问题。这里分享下…...

【紧急更新】Perplexity v3.2.1已悄然移除默认引用锚点!立即启用这4种透明度兜底机制保学术安全
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用透明度优化的紧急背景与影响评估 在大型语言模型推理链(Chain-of-Thought)与多跳检索增强生成(RAG)系统中,Perplexity 作为核心…...

基于电容触控与伺服电机的互动雪人制作:嵌入式编程与物理计算实践
1. 项目概述与核心思路又到了可以折腾点有趣小玩意儿的季节。这次我想分享一个特别适合在室内营造节日气氛,又能把嵌入式编程和手工制作结合起来的项目:一个会跳舞的互动雪人。这个项目的核心很简单——你触摸雪人的帽子,它就会随着音乐扭动身…...

Scroll Reverser深度解析:macOS输入设备独立滚动控制实现原理与技术架构
Scroll Reverser深度解析:macOS输入设备独立滚动控制实现原理与技术架构 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser Scroll Reverser是一款解决macOS系统滚动方向…...

基于规则引擎的自动化文件管理工具smartcat实战指南
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里塞满了各种格式的文档、图片、压缩包,项目目录下混杂着不同版本的代码、设计稿和会议记录。手动分类不仅耗时,…...

041二叉树的层序遍历
二叉树的层序遍历 题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public List<List<Integer>> levelOrder(TreeNode root) {List<Lis…...

Swift集成飞书生态:使用feishu-swift SDK实现高效开发
1. 项目概述:一个连接飞书与Swift生态的桥梁最近在折腾一个内部工具,需要把iOS App里的某些数据自动同步到飞书文档里,方便团队协作查看。一开始想用飞书官方API直接写,但发现Swift这边原生的HTTP请求和JSON处理起来有点啰嗦&…...

基于CircuitPython与蓝牙BLE的交互式电子糖果心制作指南
1. 项目概述:一个可交互的蓝牙电子糖果心 情人节期间,那些印着“BE MINE”、“HUG ME”等短句的糖果心(Conversation Hearts)总是能传递简单而直接的情感。你有没有想过,如果能亲手制作一个可以随时改变文字和颜色的电…...