OrionX vGPU 研发测试场景下最佳实践之Jupyter模式
在上周的文章中,我们讲述了OrionX vGPU研发测试场景下最佳实践之SSH模式,今天,让我们走进 Jupyter模式下的最佳实践。
-
• Jupyter模式:Jupyter是最近几年算法人员使用比较多的一种工具,很多企业已经将其改造集成开发工具,将Jupyter部署在容器或者虚机给算法人员使用。
环境准备
环境包含物理机器或者虚机,网络环境、GPU卡,操作系统以及容器平台。
硬件环境
本次POC环境准备三台虚机,其中一台CPU节点,两台GPU节点,每台GPU节点有一块T4卡。
操作系统为ubuntu 18.04
管理网络:千兆TCP
远程调用网络:100G RDMA
Kubernetes环境
三个节点安装k8s环境,可以使用kubeadm来安装,或者一些部署工具:
-
• kubekey
-
• KUBOARD 喷雾
当前部署kubernetes环境如下:
root@sc-poc-master-1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
sc-poc-master-1 Ready control-plane,master,worker 166d v1.21.5
sc-poc-worker-1 Ready worker 166d v1.21.5
sc-poc-worker-2 Ready worker 166d v1.21.5其中master为CPU节点,worker节点为2个T4 GPU节点。
OrionX vGPU 池化环境
参考趋动科技《OrionX 实施方案-k8s版》
部署完之后我们可以在orion的namespace查看OrionX组件:
root@sc-poc-master-1:~# kubectl get pod -n orion
NAME READY STATUS RESTARTS AGE
orion-container-runtime-hgb5p 1/1 Running 3 63d
orion-container-runtime-qmghq 1/1 Running 1 63d
orion-container-runtime-rhc7s 1/1 Running 1 46d
orion-exporter-fw7vr 1/1 Running 0 2d21h
orion-exporter-j98kj 1/1 Running 0 2d21h
orion-gui-controller-all-in-one-0 1/1 Running 2 87d
orion-plugin-87grh 1/1 Running 6 87d
orion-plugin-kw8dc 1/1 Running 8 87d
orion-plugin-xpvgz 1/1 Running 8 87d
orion-scheduler-5d5bbd5bc9-bb486 2/2 Running 7 87d
orion-server-6gjrh 1/1 Running 1 74d
orion-server-p87qk 1/1 Running 4 87d
orion-server-sdhwt 1/1 Running 1 74d开发机场景:JupyterLab模式
jupyterlab包含了 的所有功能,并升级增加了很多功能。其支持python、R、java等多种编程语言及markdown、letex等写作语言及公式输入,可以集编程与写作于一身,非常适合于代码学习、笔记记录、演示及教学等。jupyter lab相比notebook最大的更新是模块化的界面,可以在同一个窗口以标签的形式同时打开好几个文档,同时插件管理非常强大,使用起来要比jupyter notebook功能丰富许多。jupyternotebook
JupyterLab作为一种基于web的集成开发环境,你可以使用它编写notebook、操作终端、编辑markdown文本、打开交互模式、查看csv文件及图片等功能。
本次场景,我们通过k8s部署jupyterlab来进行基本的机器学习开发,同时我们集成一个开源算法进行实践。
制作镜像
我们使用官方的pytorch镜像或者TensorFlow镜像作为Base镜像来编译一个新的jupyterlab镜像,在使用的时候就有cuda和框架了,省去很多时间。本次我们先以pytorch镜像来进行编译新镜像,新建一个Dockerfile
FROM pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel
#USER root
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list && \rm /etc/apt/sources.list.d/cuda.list && \rm /etc/apt/sources.list.d/nvidia-ml.list && \apt update -y && \apt install -y nodejs npm curl vim wget git && \apt install -y language-pack-zh-hans && \pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple/ jupyterlab && \pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple/ jupyterlab-language-pack-zh-CN RUN pip install pillow && \pip install cmake && \pip install dlib && \pip install face_recognition && \pip install matplotlib && \pip install scipyENV LANG='zh_CN.utf8'
CMD ["/bin/bash","-c","jupyter lab --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*'"]
我们使用了pytorch 1.8.1 cuda 10.2的镜像,然后将ubuntu的软件源改成阿里云的,同时删除nvidia的源,否则会因为网络问题无法安装其他软件。安装jupyterlab和一些基本的科学计算的库,重新build
docker build -t pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel-jupyterlab .build完之后,我们得到一个新的镜像,接下来我们部署该镜像pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel-jupyterlab
部署jupyterlab
通过yaml部署,由于该Pod需要对外提供服务,所以我们要暴露8888端口,同时创建svc和ingress提供对外服务地址
jupyterlab的yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:annotations:name: jupyterlab-orionnamespace: orion
spec:replicas: 1selector:matchLabels:name: jupyterlab-oriontemplate:metadata:labels:name: jupyterlab-orionspec:nodeName: sc-poc-worker-2#hostNetwork: trueschedulerName: orion-schedulercontainers:- name: jupyterlab-orionimage: pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel-jupyterlabports:- containerPort: 8888imagePullPolicy: IfNotPresentresources:requests:virtaitech.com/gpu: 1limits:virtaitech.com/gpu: 1env:- name : ORION_GMEMvalue : "5000"- name : ORION_RATIOvalue : "50"- name: ORION_VGPUvalue: "1"- name: ORION_RESERVEDvalue: "0"- name: ORION_CROSS_NODEvalue: "0"- name: ORION_TASK_IDLE_TIMEvalue: "30s"- name: ORION_EXPORT_CMDvalue: "env | grep ORION; orion-smi -j"- name : ORION_GROUP_IDvalueFrom:fieldRef:fieldPath: metadata.uid- name: ORION_K8S_POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: ORION_K8S_POD_UIDvalueFrom:fieldRef:fieldPath: metadata.uid- name: ORION_K8S_POD_NSvalueFrom:fieldRef:fieldPath: metadata.namespace---
apiVersion: v1
kind: Service
metadata:labels:name: jupyterlab-orionname: jupyterlab-orionnamespace: orion
spec:ports:- name: webport: 8888protocol: TCPtargetPort: 8888selector:name: jupyterlab-oriontype: ClusterIP我这边是使用traefik搭建的ingress服务,所以给jupyterlab创建的ingress如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: jupyterlab-ingressannotations:kubernetes.io/ingress.class: traefik traefik.ingress.kubernetes.io/router.entrypoints: web
spec:rules:- host: jupyterlab.10.10.10.180.nip.iohttp:paths:- pathType: Prefixpath: /backend:service:name: jupyterlab-orionport:number: 8888两个yaml文件部署完后,通过ingress地址可以访问该jupyterlab了

简单测试下pytorch是否可以正常调用vGPU,代码样例:
import torch
from torch import nn if_cuda = torch.cuda.is_available()
print("if_cuda=",if_cuda)gpu_count = torch.cuda.device_count()
print("gpu_count=",gpu_count)torch.cuda.get_device_name(0)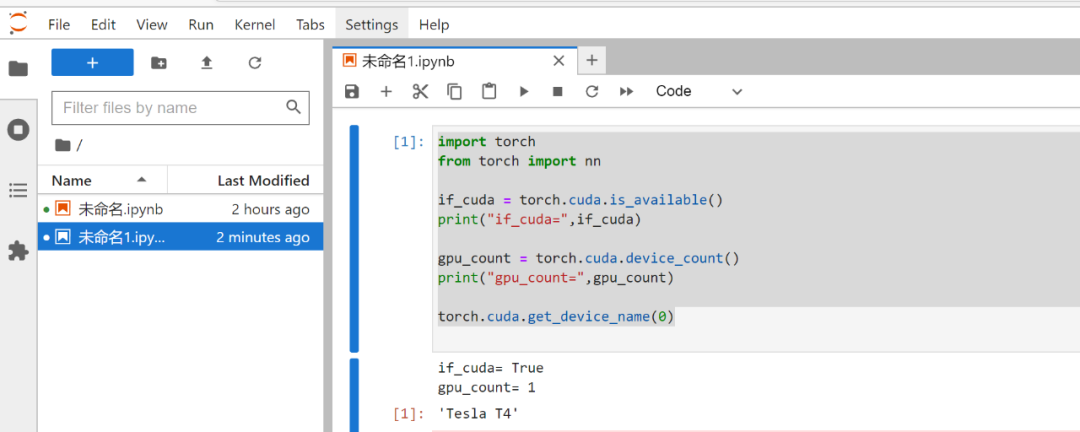
通过pytorch的api我们可以直接拿到GPU的信息,跟物理卡是一致的,物理卡是T4,vGPU同样是T4,此时vGPU是分配了一块卡,所以显示的数量也是一样的,根据pytorch拿到的信息我们可以发现对于上层的框架而言调用vGPU资源跟调用物理GPU资源是一样的,不会有什么改变,那对于上层的应用来说也是透明的使用vGPU资源。
跑一个demo
我们在jupyterlab中跑一个pytorch线性回归代码测试下pytorch调用vGPU是否正常使用。我们之前启动pod的时候申请了50%的算力和5G的显存
代码如下:
import time
import torch
from torch import nn # 准备数据
n = 1000000 #样本数量X = 10*torch.rand([n,2])-5.0 #torch.rand是均匀分布
w0 = torch.tensor([[2.0,-3.0]])
b0 = torch.tensor([[10.0]])
Y = X@w0.t() + b0 + torch.normal( 0.0,2.0,size = [n,1]) # @表示矩阵乘法,增加正态扰动# 移动到GPU上
print("torch.cuda.is_available() = ",torch.cuda.is_available())
X = X.cuda()
Y = Y.cuda()
print("X.device:",X.device)
print("Y.device:",Y.device)# 定义模型
class LinearRegression(nn.Module): def __init__(self):super().__init__()self.w = nn.Parameter(torch.randn_like(w0))self.b = nn.Parameter(torch.zeros_like(b0))#正向传播def forward(self,x): return x@self.w.t() + self.blinear = LinearRegression() # 移动模型到GPU上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
linear.to(device)#查看模型是否已经移动到GPU上
print("if on cuda:",next(linear.parameters()).is_cuda)# 训练模型
optimizer = torch.optim.Adam(linear.parameters(),lr = 0.1)
loss_func = nn.MSELoss()def train(epoches):tic = time.time()for epoch in range(epoches):optimizer.zero_grad()Y_pred = linear(X) loss = loss_func(Y_pred,Y)loss.backward() optimizer.step()if epoch%50==0:print({"epoch":epoch,"loss":loss.item()})toc = time.time()print("time used:",toc-tic)train(5000)运行结果如下:
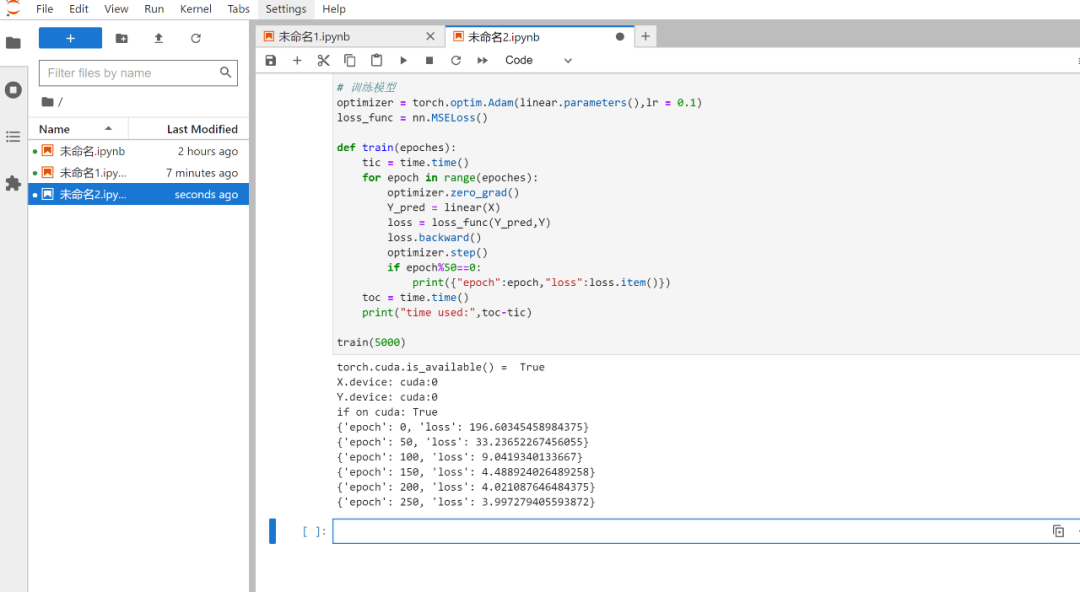
OrionX 申请资源情况如下
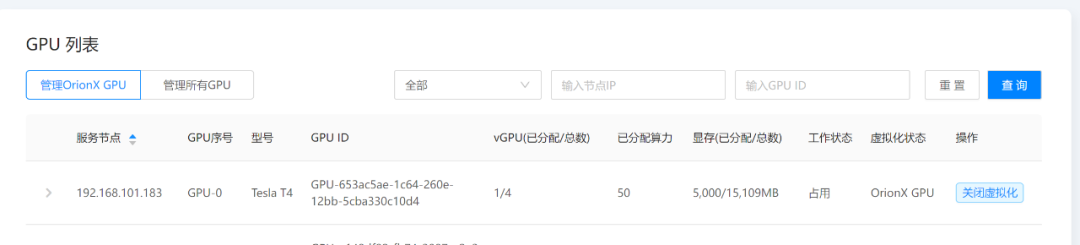
综上,我们在jupyterlab中通过pytorch调用vGPU能正常使用。
项目实践
我们基于一个开源项目在jupyterlab进行实际的开发体验,它可以将视频、人物、风景动漫化,我们本次使用的是pytorch版本的实现,项目地址为:animegan2-pytorchhttps://github.com/bryandlee/animegan2-pytorch
为了方便使用我们需要做一些准备工作,1、准备一个nfs server用来持久化 2、将该项目clone下来存入nfs中去,我在nfs server建了一个目录,然后把该项目拷贝进去;3、下载一个人脸关键点模型,后续可以直接使用该模型,当然你也可以训练自己的人脸关键点检测模型,该模型下载地址/mnt/nfs_share/animegan2-pytorchshape_predictor_68_face_landmarks.dat
https://github.com/davisking/dlib-models,将下载的模型同样拷贝到目录下面。接下来我们就将这个目录挂载给jupyterlab的pod里面,具体的挂载参考YAML文件如下:/mnt/nfs_share/animegan2-pytorch
apiVersion: apps/v1
kind: Deployment
metadata:annotations:name: jupyterlab-orionnamespace: orion
spec:replicas: 1selector:matchLabels:name: jupyterlab-oriontemplate:metadata:labels:name: jupyterlab-orionspec:nodeName: sc-poc-worker-2#hostNetwork: trueschedulerName: orion-schedulervolumes:- name: animegan2-datanfs:server: 10.10.10.180path: /mnt/nfs_share/animegan2-pytorchcontainers:- name: jupyterlab-orionimage: pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel-jupyterlabvolumeMounts:- name: animegan2-datamountPath: /workspace/animegan2-pytorchports:- containerPort: 8888imagePullPolicy: IfNotPresentresources:requests:virtaitech.com/gpu: 1limits:virtaitech.com/gpu: 1env:- name : ORION_GMEMvalue : "5000"- name : ORION_RATIOvalue : "50"- name: ORION_VGPUvalue: "1"- name: ORION_RESERVEDvalue: "0"- name: ORION_CROSS_NODEvalue: "0"- name: ORION_TASK_IDLE_TIMEvalue: "30s"- name: ORION_EXPORT_CMDvalue: "env | grep ORION; orion-smi -j"- name : ORION_GROUP_IDvalueFrom:fieldRef:fieldPath: metadata.uid- name: ORION_K8S_POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: ORION_K8S_POD_UIDvalueFrom:fieldRef:fieldPath: metadata.uid- name: ORION_K8S_POD_NSvalueFrom:fieldRef:fieldPath: metadata.namespace---
apiVersion: v1
kind: Service
metadata:labels:name: jupyterlab-orionname: jupyterlab-orionnamespace: orion
spec:ports:- name: webport: 8888protocol: TCPtargetPort: 8888selector:name: jupyterlab-oriontype: ClusterIP我们把该nfs上的目录直接挂载在jupyterlab的目录下面,启动之后我们通过ingress方式登录该jupyterlab就可以看到挂载的项目了/workspace/animegan2-pytorch
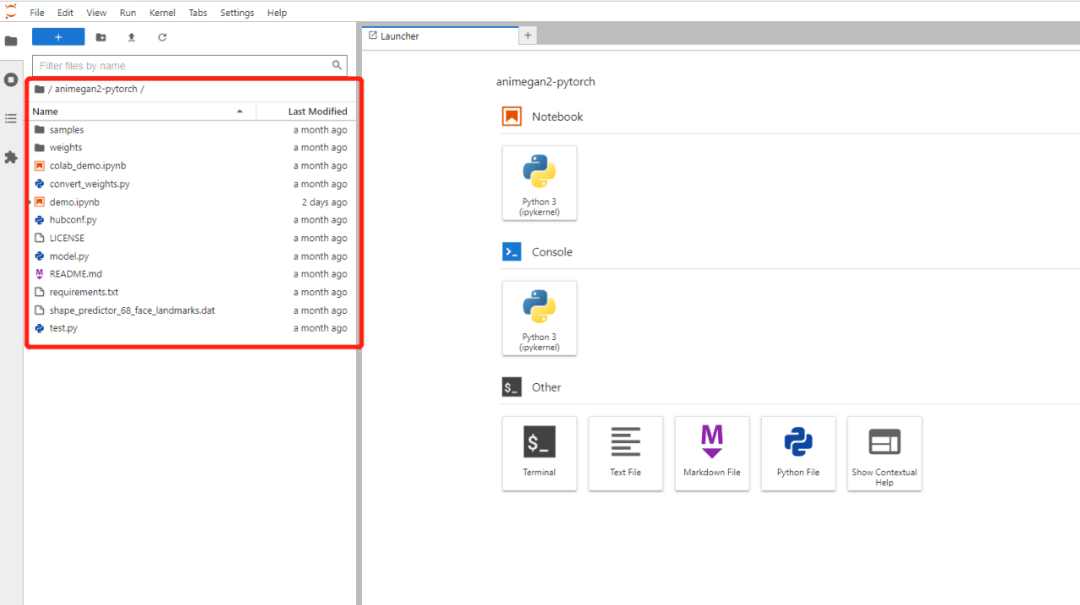
双击我们就可以运行该项目了,但是实际上在运行的时候他会在用户的根目录寻找一些文件,如果没有的话会自动下载,这些文件实际上就是项目里面的文件,由于github很不稳定,所以我们可以手动的在终端里面把这些文件复制到相关目录,需要复制两个目录,1、复制整个目录到;2、复制目录下的目录到 ,这样我们就可以在jupyterlab直接运行该demo了,我们可以通过点击来运行demo.ipynbanimegan2-pytorchanimegan2-pytorch/root/.cache/torch/hub/bryandlee_animegan2-pytorch_mainanimegan2-pytorchweights/root/.cache/torch/hub/checkpointsrun all cells
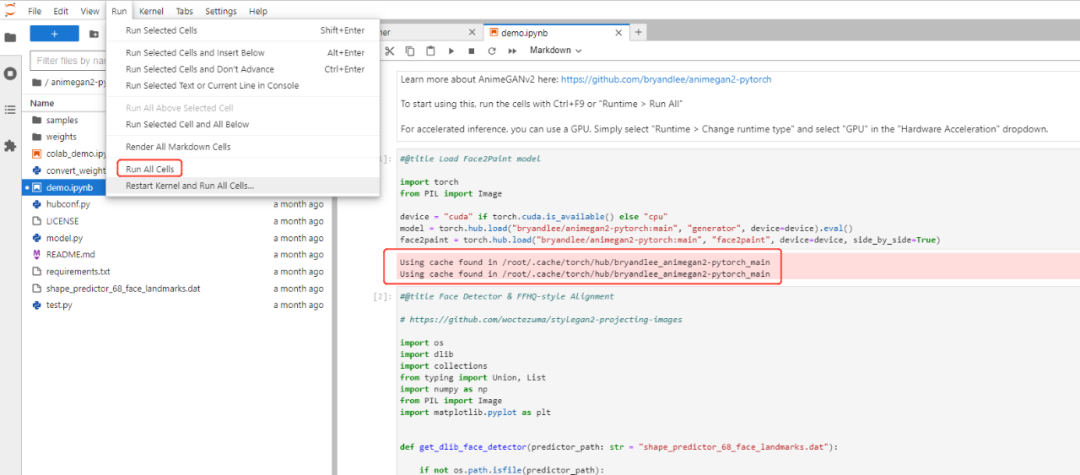
运行的时候我们就可以看到他会调用我们复制的这些目录文件了。
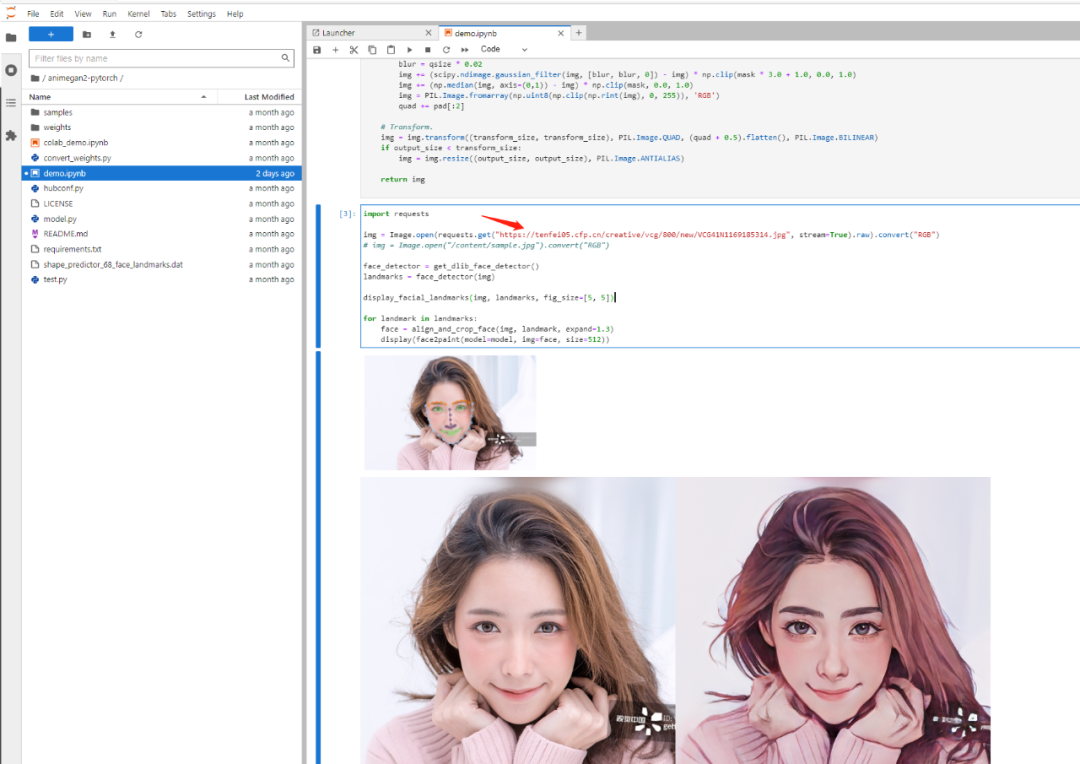
该demo自带了马斯克的人像来进行动漫化,我们也可以找一些图片链接进行替换来运行该demo
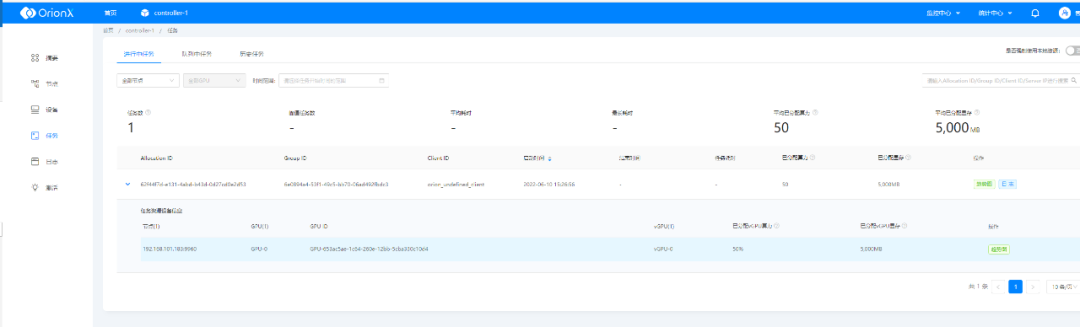
运行的时候我们通过OrionX GUI可以查看运行的任务和使用的资源
以上就是OrionX vGPU在Jupyter模式下的开发机场景的最佳实践,OrionX AI算力资源池化解决方案针对GPU管理粗放给出了相应的解决思路,旨在为用户提高GPU利用率、提供灵活调度平台、统一管理算力资源,实现弹性扩展,按需使用。我们将在以后的文章中继续分享OrionX vGPU基于CodeServer模式下的开发实践,欢迎留言探讨!
相关文章:
OrionX vGPU 研发测试场景下最佳实践之Jupyter模式
在上周的文章中,我们讲述了OrionX vGPU研发测试场景下最佳实践之SSH模式,今天,让我们走进 Jupyter模式下的最佳实践。 • Jupyter模式:Jupyter是最近几年算法人员使用比较多的一种工具,很多企业已经将其改造集成开发工…...

国风编曲:了解国风 民族调式 五声音阶 作/编曲思路 变化音 六声、七声调式
中国风 以流行为基础加入中国特色乐器、调式、和声融为一体的风格 如:青花瓷、菊花台、绝代风华、江南等等等等 省流:中国风=流行民族乐 两者结合,民族元素越多越中国风 流行民族/摇滚民族/电子民族 注意:中国风≠…...

HTTP 响应状态码详解
HTTP状态码详解:HTTP状态码,是用以表示WEB服务器 HTTP响应状态的3位数字代码 小技巧: CtrlF 快速查找 Http状态码状态码含义100客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当…...

在服务器上开Juypter Lab教程(远程访问)
在服务器上开Juypter Lab教程(远程访问) 文章目录 在服务器上开Juypter Lab教程(远程访问)一、安装anaconda1、安装anaconda2、提权限3、运行4、同意协议5、安装6、是否要自动初始化 conda7、结束8、检查 二、Anaconda安装Pytorch…...
【硬件模块】SHT20温湿度传感器
SHT20是一个用IIC通信的温湿度传感器。我们知道这个就可以了。 它支持的电压范围是2.1~3.6V,推荐是3V,所以如果我们的MCU是5V的,那么就得转个电压才能用了。 IIC常见的速率有100k,400k,而SHT20是支持400k的(…...

Redhat 8,9系(复刻系列) 一键部署Oracle23ai rpm
Oracle23ai前言 Oracle Database 23ai Free 让您可以充分体验 Oracle Database 的能力,世界各地的企业都依赖它来处理关键任务工作负载。 Oracle Database Free 的资源限制为 2 个 CPU(前台进程)、2 GB 的 RAM 和 12 GB 的磁盘用户数据。该软件包不仅易于使用,还可轻松下载…...

SIPp uac.xml 之我见
https://sipp.sourceforge.net/doc/uac.xml.html 这个 uac.xml 有没有问题呢? 有! 问题之一是: <recv response"200" rtd"true" rrs"true"> 要加 rrs, 仔细看注释就能看到 问题之二是࿱…...

引领智能家居新风尚,WTN6040F门铃解决方案——让家的呼唤更动听
在追求高效与便捷的智能家居时代,每一个细节都承载着我们对美好生活的向往。WTN6040F,作为一款专为现代家庭设计的低成本、高性能门铃解决方案,正以其独特的魅力,悄然改变着我们的居家生活体验。 芯片功能特点: 1.2.4…...

Android 蓝牙服务启动
蓝牙是Android设备中非常常见的一个feature,设备厂家可以用BT来做RC、连接音箱、设备本身做Sink等常见功能。如果一些设备不需要BT功能,Android也可以通过配置来disable此模块,方便厂家为自己的设备做客制化。APP操作设备的蓝牙功能ÿ…...
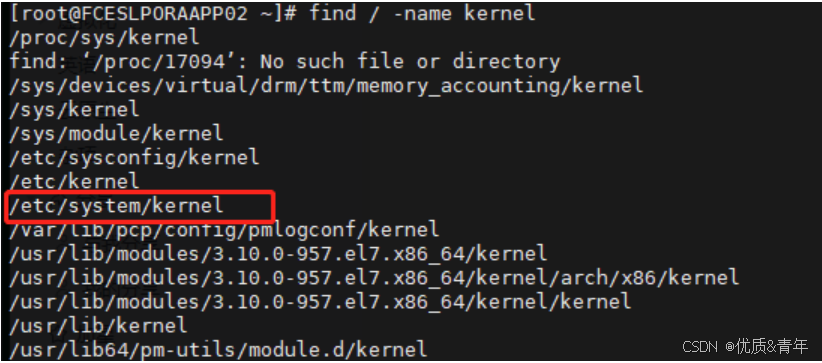
【安全系列--处理挖矿】
现象:我们云上waf提示有台服务器存在挖矿行为 解决思路: 1、查看服务器的进程情况 top发现服务的CPU使用率非常高 2、使用性能分析工具perf查看占用的cpu进程 sudo apt install linux-tools-common发现一些kernel进程存在异常 3、使用find查一下这…...

SpringBoot集成Thymeleaf模板引擎,为什么使用(详细介绍)
学习本技术第一件事:你为什么要使用,解决什么问题的? 1.为什么使用(使用背景)? 首先应用场景是单体项目,如果是前后端分离就不用关注这个了,因为单体项目你前后端都是写在一个项目…...
Docker突然宣布:涨价80%
从11月15日起,Docker的付费订阅中Pro和Team的价格都将大幅上调:Pro从原来的5美元每月激增到9美元每月,直接涨了80%;而Team也从之前的9美元每月来到15美元每月,涨价66.7%。只有Business保持此前的24美元每月不变。 同时…...
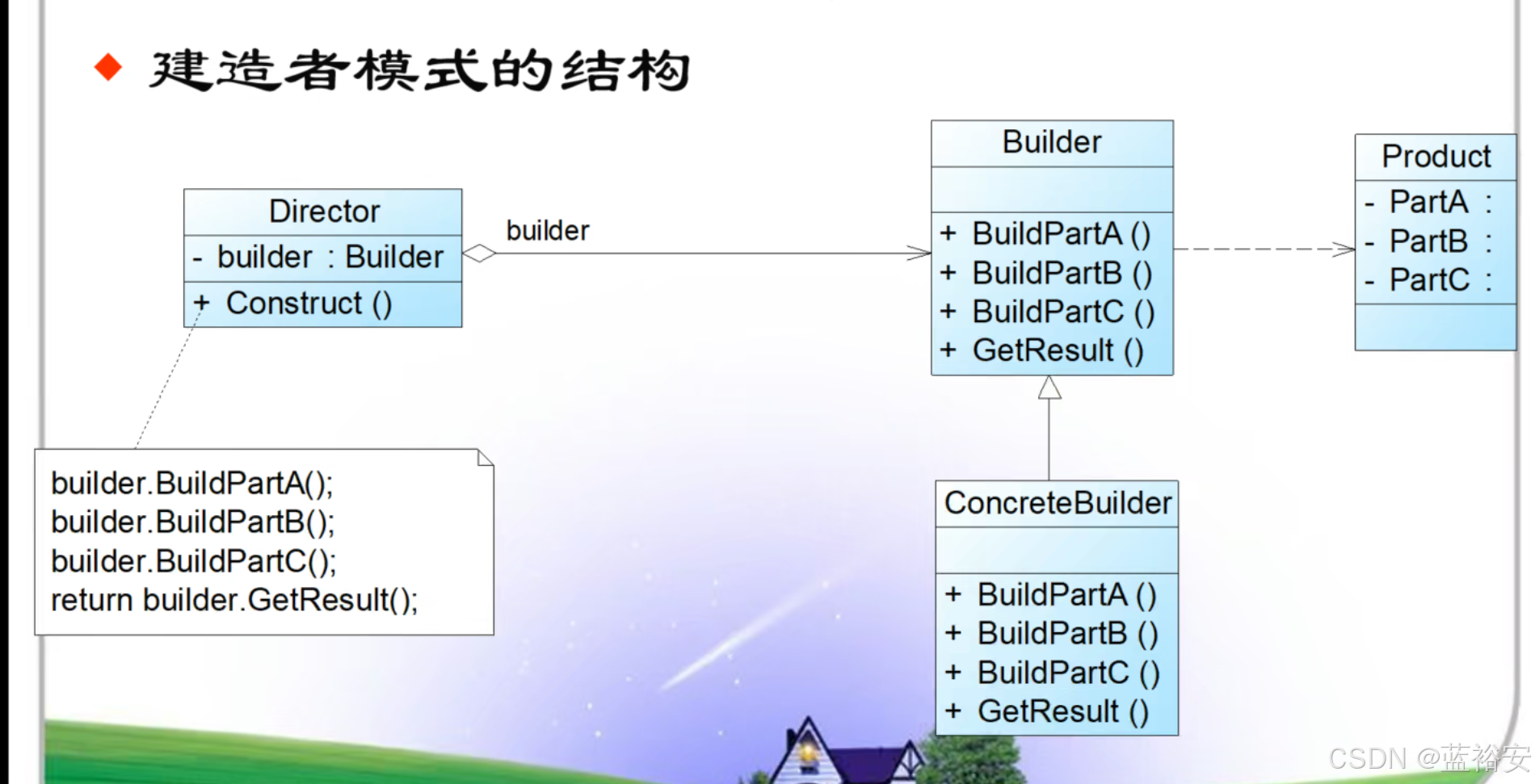
工厂方法模式和抽象工厂模式
工厂方法模式 一个工厂只能创建一种产品 工厂方法模式的结构 工厂方法模式包含以下4个角色 Product(抽象产品) ConcreteProduct(具体产品) Factory(抽象工厂) ConcreteFactory(具体工厂…...

【星海出品】go语言环境兼install
官网 https://golang.google.cn/dl/ go的安装包下载地址 https://go.dev/dl/ set GO111MODULEon //是否以Go modules的模式运行项目 auto,on,off set GOARCHamd64 //目标可执行程序操作系统构架 包括 386,amd64,arm set GOBIN //项目的第三方可执行文件目…...

Spring 源码解读:自定义实现BeanPostProcessor的扩展点
引言 在Spring的生命周期管理中,BeanPostProcessor是一个非常重要的扩展点。它允许开发者在Bean初始化的前后插入自定义的逻辑,从而实现更灵活的Bean管理。BeanPostProcessor是Spring框架中用于对Bean实例进行修改的机制之一。通过实现该接口࿰…...

Spring Boot-分布式系统问题
Spring Boot 在分布式系统中的常见问题及解决方案 随着互联网的发展,系统规模和复杂度越来越大,分布式系统成为应对高并发、大数据量场景的重要架构选择。Spring Boot 作为一种轻量级的开发框架,广泛应用于构建微服务和分布式系统中。然而&a…...
 -- 内存管理篇)
面试题总结(三) -- 内存管理篇
面试题总结(三) – 内存管理篇 文章目录 面试题总结(三) -- 内存管理篇<1> C 中堆内存和栈内存的区别是什么?<2> 如何在 C 中手动管理内存(new/delete 操作符)?<3> C 中内存泄漏的原因和避免方法<4> 谈谈…...

Qt 定时器-定时备份
定时备份 在Qt 中,可以使用QTimer类来实现定时备份功能。以下是一个示例代码,每隔一段时间自动执行备份操作: #include <QTimer>QTimer timer; int backupInterval 24 * 60 * 60 * 1000;//备份间隔为24小时connect(&timer, &…...
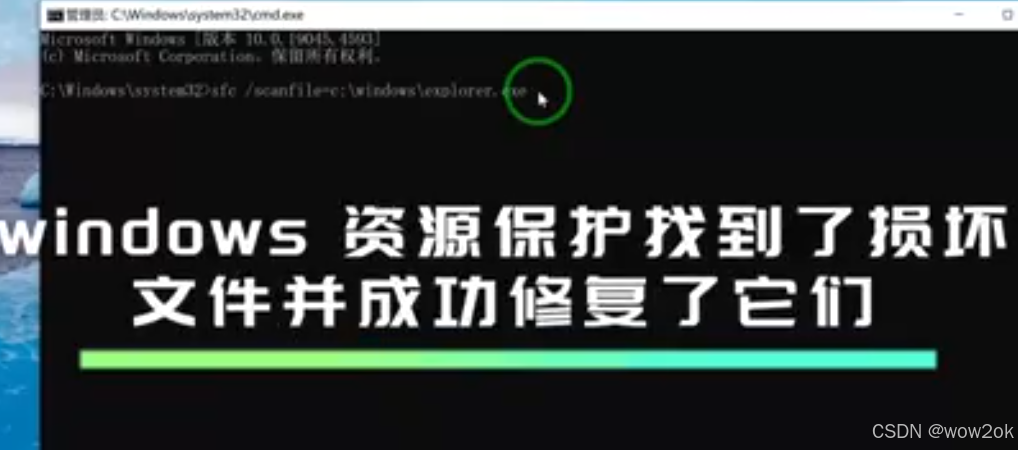
天融信把桌面explorer.exe删了,导致开机之后无windows桌面,只能看到鼠标解决方法
win10开机进入桌面,发现桌面无了,但是可以ctrlaltdelete调出任务管理器 用管理员权限打开cmd,输入: sfc /scanfilec:\windowslexplorer.exe 在运行C:\windows\Explorer.exe;可以进入桌面,但是隔离几秒钟…...
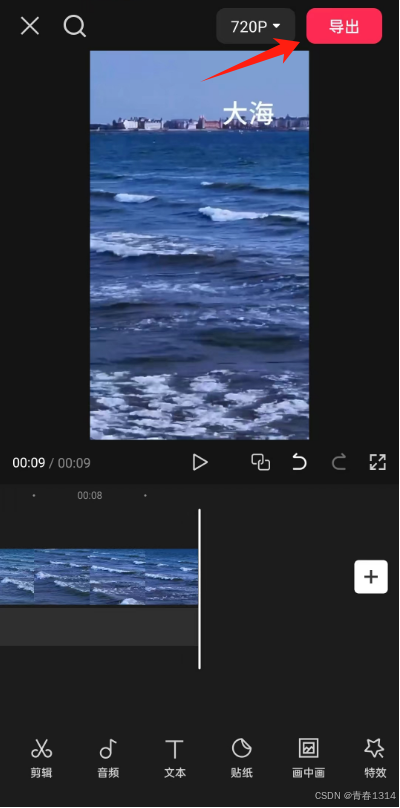
视频分割操作教程
1、打开剪映 2、点击开始创作上面的“”,选择视频,点击添加按钮,导入一个视频素材到剪映 3、滑动视频,让视频竖线到合适位置 4、点击视频,出现白色边框 5、点击工具栏“分割”,然后点击需要删除的视频部分 …...

C语言学习攻略
本人现在是一名非计算机专业学生,以此篇开始我的编程学习之旅。一.为什么学习编程就我最近而言,我们在数学建模竞赛中会因为不会写代码而发愁,虽然我们几个人都是第一次接触这种比赛,但是我作为一个编程手尤其差劲,这驱…...

网站seo排名工具有哪些
网站SEO排名工具有哪些?详细解析与实用建议 在互联网时代,网站的SEO(搜索引擎优化)已经成为提升网站流量和品牌知名度的关键手段。为了帮助网站管理者和数字营销人员更好地进行SEO优化,市面上涌现了各种各样的SEO排名…...

树莓派实战:Nextcloud私有云搭建与性能调优全指南
1. 树莓派与Nextcloud的完美组合 如果你手头有一台闲置的树莓派,又想要一个完全由自己掌控的私有云存储,那么Nextcloud绝对是最佳选择。我用了整整三个月时间,在树莓派4B上搭建并优化了Nextcloud系统,实测下来这套方案不仅稳定可靠…...
)
LeetCode--344.反转字符串(字符串/双指针法)
344.反转字符串 题目描述 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须**原地修改输入数组**、使用 O(1) 的额外空间解决这一问题。 示例 1: 输入&#x…...

Less 教程
Less 教程 引言 Less(Leaner Style Sheets)是一种由Sass作者开发的开源CSS预处理器。它增加了变量、混合(Mixins)、函数等特性,使CSS更加强大、灵活和易于维护。本教程将为您详细介绍Less的基本用法,帮助您快速上手。 Less 简介 什么是Less? Less 是一个 CSS 预处理…...

Halcon卡尺直线检测避坑指南:参数设置与常见错误排查
Halcon卡尺直线检测避坑指南:参数设置与常见错误排查 在工业视觉检测领域,直线边缘的精准定位是许多项目的基础需求。Halcon作为行业标杆工具,其卡尺直线检测功能看似简单,却暗藏诸多参数陷阱。不少开发者在初次接触时࿰…...

Facebook无法向他人发送消息?2026原因解析与解决思路
在使用Facebook过程中,有时会遇到无法向他人发送消息的情况。这可能影响正常沟通和工作协作。出现这一现象的原因多种多样,本文将从2026年的实际情况出发,系统梳理常见原因及对应解决方法,帮助你快速排查问题并恢复消息功能。一、…...

2026毕业论文降AI工具指南:实测4款高通过率方案
答辩前三天被通知AI率超标要重改的焦虑,我至今印象深刻。去年帮二十多位同专业学弟学妹调整过毕业论文的AI检测问题,整理出的实用经验今天全部分享给大家。 先说结论:SpeedAI科研小助手和思笔AI是我最推荐的两款。前者性价比极高且全平台适配…...

2026年4月OpenClaw怎么部署?腾讯云零门槛流程:含安装及大模型API、Skill配置
2026年4月OpenClaw怎么部署?腾讯云零门槛流程:含安装及大模型API、Skill配置。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉…...

你的Xbox手柄电量还能撑多久?解决游戏中断的电量管家
你的Xbox手柄电量还能撑多久?解决游戏中断的电量管家 【免费下载链接】XB1ControllerBatteryIndicator A tray application that shows a battery indicator for an Xbox-ish controller and gives a notification when the battery level drops to (almost) empty.…...