Java集合(一)
目录
Java集合(一)
集合介绍
单列集合分类
Collection接口
创建Collection实现类对象
常用方法
迭代器
基本使用
迭代器的执行过程
迭代器底层原理
集合中的并发修改异常及原因分析
List接口
ArrayList类
介绍
常用方法
遍历集合
ArrayList底层源码分析
初始容量
数组扩容
LinkedList类
介绍
常用方法
遍历集合
LinkedList底层源码分析
LinkedList成员分析
LinkedList中add方法源码分析
LinkedList中get方法源码分析
增强for循环
Java集合(一)
集合介绍
在前面已经使用了一个最基本的数据结构:数组,但是数组的缺点很明显:定长,这个缺点导致数组的增删不够方便,为了解决这个问题,可以使用Java的相关集合
Java集合分为两种:
- 单列集合:集合中每一个元素只有一种元素类型
- 多列集合:集合中每一个元素包括两种数据类型,第一个数据类型对应的元素被称为
key,第二个数据类型对应的元素被称为value,二者组成的共同体被称为键值对
Java集合有以下三个特点:
- 只能存储引用数据类型的数据,而不能存储基本数据类型的数据
- 每一种集合长度均是可变的
- 集合中有很多使用的方法,便于调用
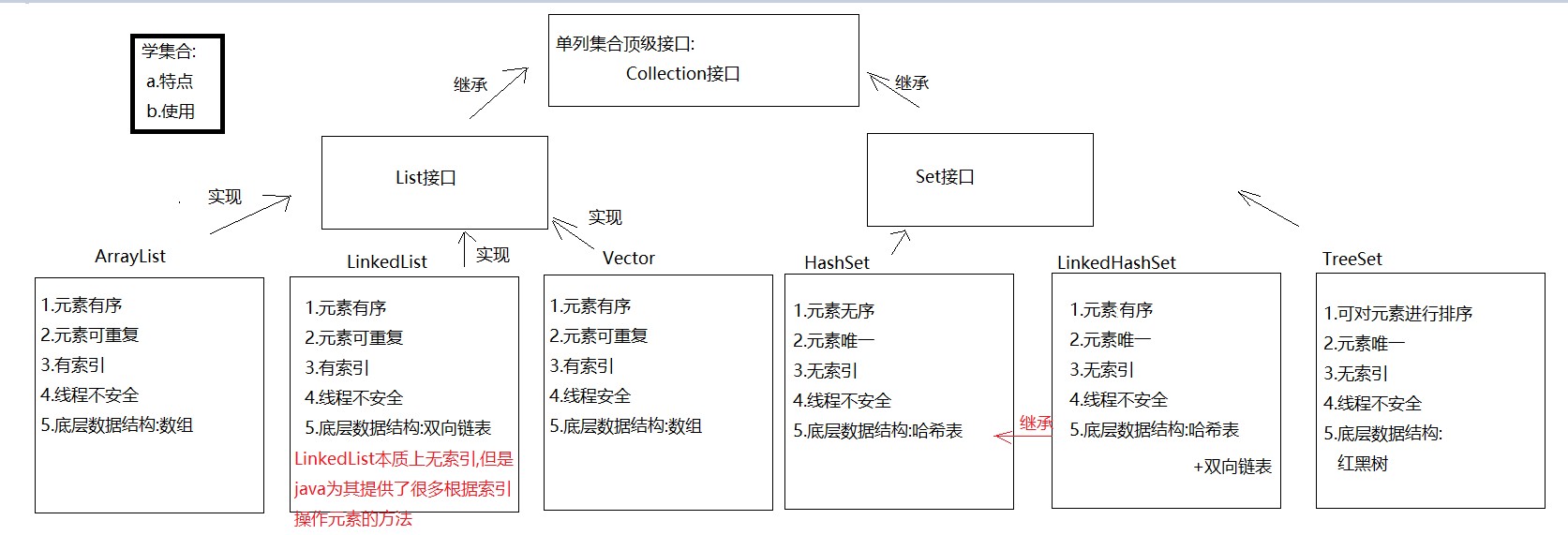
单列集合分类
在Java中,单列集合最大的接口是Collection接口,该接口下有两个子接口,分别是list接口和set接口
对于list接口来说,一共有三个实现类:
ArrayList类LinkedList类Vector类(现不常用)
三个实现类都具有以下特点:
- 元素存储顺序与插入顺序一致
- 集合中元素可重复
- 可以使用索引方式操作
三个实现类中,ArrayList类和Vector类底层的数据结构是数组,LinkedList类底层的数据结构是不带头双向不循环链表,并且只有Vector类是线程安全的类,但是Vector类的效率低
对于set接口来说,一共有三个实现类:
HashSet类LinkedHashSet类TreeSet类
三个实现类都具有以下特点:
- 不可以添加重复的数据,即元素唯一
- 不可以使用索引方式操作
- 线程不安全
三个实现类中,HashSet类底层数据结构是哈希表,LinkedHashSet类底层数据结构是哈希表+双向链表,TreeSet类底层数据结构是红黑树,并且对于HashSet来说,其插入的数据在结构中的顺序与插入时的顺序不一定相同,对于LinkedHashSet类来说,插入的数据在结构中的顺序与插入时的顺序相同,对于TreeSet类来说,因为红黑树会按照一定比较方式对插入顺序进行排序,所以数据在结构中都是在一定规则下有序的
总结如下图所示:
Collection接口
创建Collection实现类对象
Collection接口是单列集合的顶级接口,创建对象时使用对应的实现类创建,但是可以使用Collection接口的引用接收,即多态,基本格式如下:
Collection<E> 对象名 = new 实现类对象<E>()其中 <E>表示泛型,Java中的泛型只可以写引用数据类型,所以导致集合只能存储引用数据类型的数据
使用泛型时,赋值符号左侧的部分必须写具体类型,但是赋值符号右侧的部分可以省略,JVM会自动根据左侧泛型的具体类型推导右侧部分
常用方法
注意,下面的方法本质使用的还是实现类中重写的方法
boolean add(E e):向集合中插入元素,返回值表示插入成功(true)或者失败(false),一般情况下可以不用接收boolean addAll(Collection<? extends E> c):将另一个集合元素添加到当前集合中(相当于集合的合并)void clear():清除当前集合中所有的元素boolean contains(Object o):查找对应集合中是否含有指定元素,存在返回true,否则返回falseboolean isEmpty():判断集合是否为空,为空返回true,否则返回falseboolean remove(Object o):从当前集合中移除指定元素,返回值代表删除成功或者失败int size():返回集合中的元素个数Object[] toArray():将集合中的数据存储到数组中
基本使用如下:
public class Test {public static void main(String[] args) {Collection<String> collection = new ArrayList<>();//boolean add(E e)collection.add("萧炎");collection.add("萧薰儿");collection.add("彩鳞");collection.add("小医仙");collection.add("云韵");collection.add("涛哥");System.out.println(collection);//boolean addAll(Collection<? extends E> c)Collection<String> collection1 = new ArrayList<>();collection1.add("张无忌");collection1.add("小昭");collection1.add("赵敏");collection1.add("周芷若");collection1.addAll(collection);System.out.println(collection1);//void clear()collection1.clear();System.out.println(collection1);//boolean contains(Object o)boolean result01 = collection.contains("涛哥");System.out.println("result01 = " + result01);//boolean isEmpty()System.out.println(collection1.isEmpty());//boolean remove(Object o)collection.remove("涛哥");System.out.println(collection);//int size() :返回集合中的元素个数。System.out.println(collection.size());//Object[] toArray()Object[] arr = collection.toArray();System.out.println(Arrays.toString(arr));}
}迭代器
基本使用
当需要遍历一个集合时,最常用的就是迭代器,在Java中,迭代器是Iterator<E>接口,获取当前集合的迭代器可以使用Collection中的方法:
Iterator<E> iterator()常用的方法有两种:
boolean hasNext():判断集合中的下一个元素是否存在E next():获取下一个元素,其中E由创建集合时的数据类型决定
基本使用如下:
public class Test01 {public static void main(String[] args) {Collection<String> list = new ArrayList<>();list.add("a");list.add("b");list.add("c");list.add("d");// 使用迭代器遍历Iterator<String> iterator = list.iterator();while (iterator.hasNext()) {// 存在下一个元素就更新String next = iterator.next();System.out.println(next);}}
}需要注意,尽量不要在遍历过程中使用多次next()方法,不同情况下可能结果不一样,当next()方法没有访问到指定的数据,此时就会抛出异常:NoSuchElementException
迭代器的执行过程
以前面的代码为例,当前size为4:
当执行hasNext方法时,对应的源码如下:
public boolean hasNext() {return cursor != size;
}int cursor; // 下一个元素的下标
int lastRet = 1; // 上一个元素的下标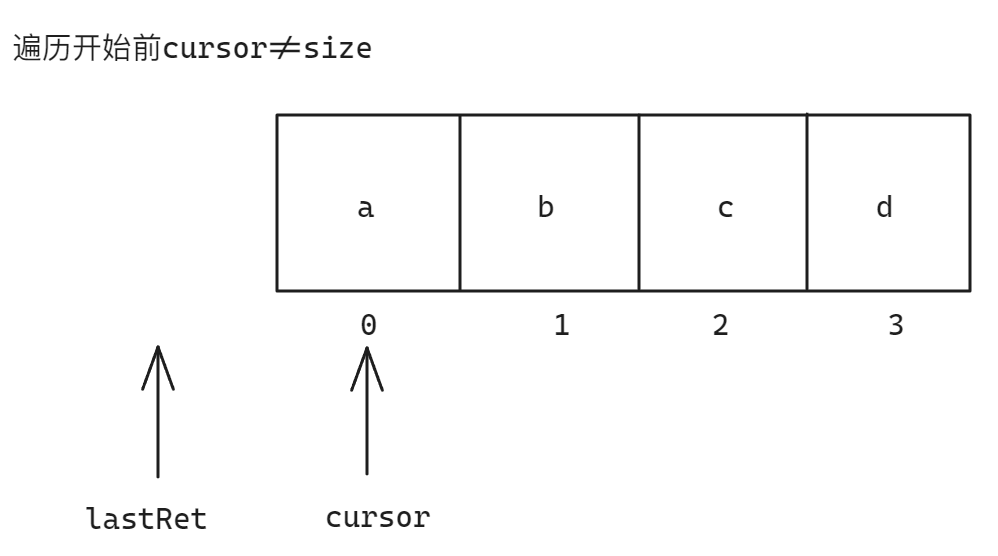
满足条件进入循环,执行next方法,对应源码如下:
public E next() {// ...int i = cursor;if (i >= size)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i + 1;return (E) elementData[lastRet = i];
}因为cursor既不大于size,也不大于新建数组elementData的长度,所以两个分支语句均不执行
因为ArrayList实现的Iterator是一个Iterator<E>的内部实现类,所以访问ArrayList中的elementData成员相当于内部类访问外部类的成员,而ArrayList中的elementData数组存储的是当前集合中的数据,因为ArrayList底层是数组,所以直接将对应的elementData的地址给新数组引用即可实现数组数据共享
接下来,cursor=i+1使cursor走到下一个元素的位置,因为前面已经判断cursor!=size表示一定存在下一个元素,所以此处不会出现越界问题,接着返回elementData数组中的元素,但是因为新数组引用是Object类型,所以此处需要进行强制类型转换,以确保返回的数据类型与泛型对应的数据类型一致
此处返回的elementData数组元素下标使用到了赋值符号的返回值,赋值符号的返回值为赋值符号左侧变量的值,因为取下标需要先计算内部lastRet=i表达式,所以此处既让lastRet向后移动,又拿到了lastRet向后移动对应位置的值
所以本过程运行结果如下图:
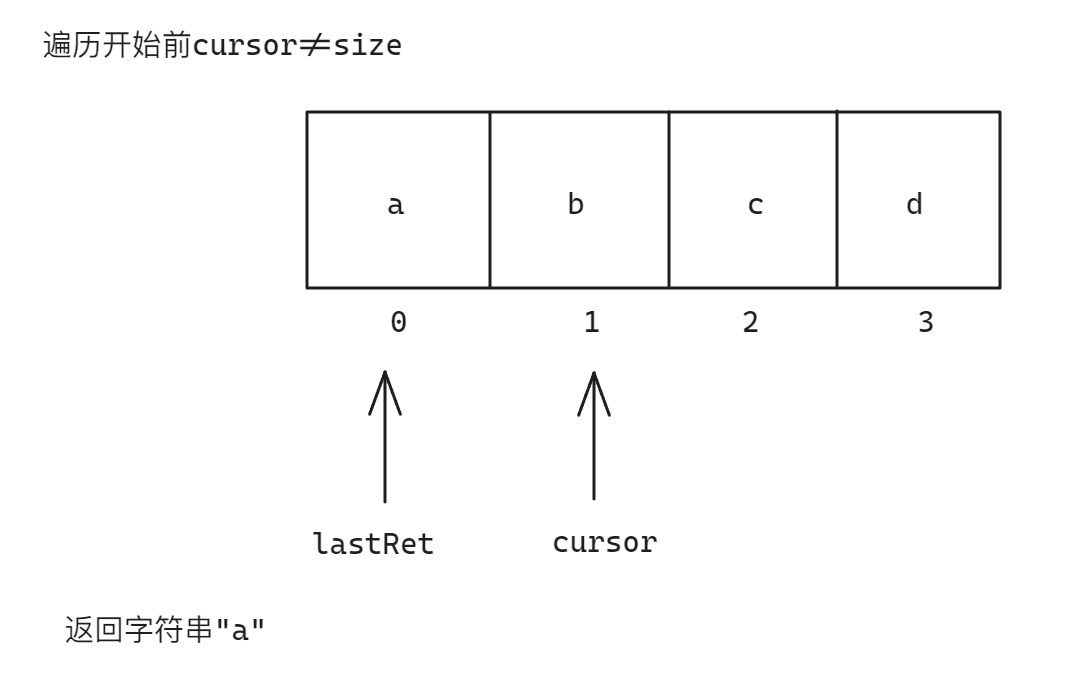
其余情况以此类推,直到cursor!=size返回false,代表已经没有下一个元素,循环结束
迭代器底层原理
在获取迭代器时,调用到了对应集合的成员方法,例如前面ArrayList获取其迭代器对象时使用的代码:
Iterator<String> iterator = list.iterator();对应的源码如下:
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{// 返回迭代器对象public Iterator<E> iterator() {return new Itr();}// ...private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = 1; // index of last element returned; 1 if no suchint expectedModCount = modCount;Itr() {}// ...}// ...
}实际上获取到的迭代器就是Collection<E>实现类的ArrayList类中内部实现Iterator<E>的对象
需要注意,并不是所有的集合都是new Itr(),例如HashSet的源码
// HashSet中
public Iterator<E> iterator() {return map.keySet().iterator();
}// HashMap中
public Set<K> keySet() {Set<K> ks = keySet;if (ks == null) {ks = new KeySet();keySet = ks;}return ks;
}final class KeySet extends AbstractSet<K> {// ...public final Iterator<K> iterator() { return new KeyIterator(); }// ...
}在HashSet中,iterator()方法返回的是HashMap中的内部类KeySet中的迭代器
集合中的并发修改异常及原因分析
并发修改异常出现于使用迭代器遍历集合的过程中修改集合中的内容,例如下面的代码:
以 ArrayList为例,其余集合类似
public class Test02 {public static void main(String[] args) {//需求:定义一个集合,存储 唐僧,孙悟空,猪八戒,沙僧,遍历集合,如果遍历到猪八戒,往集合中添加一个白龙马ArrayList<String> list = new ArrayList<>();list.add("唐僧");list.add("孙悟空");list.add("猪八戒");list.add("沙僧");Iterator<String> iterator = list.iterator();while(iterator.hasNext()){String element = iterator.next();// 使用迭代器遍历过程中修改集合中的内容if ("猪八戒".equals(element)){list.add("白龙马");}}System.out.println(list);}
}
报错信息:
Exception in thread "main" java.util.ConcurrentModificationExceptionat java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911)at java.util.ArrayList$Itr.next(ArrayList.java:861)at com.epsda.advanced.test_Collection.Test02.main(Test02.java:24)查看源码分析出现这个异常的原因:
public E next() {checkForComodification();// ...
}// 迭代器内部类
int expectedModCount = modCount;final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();
}在执行next方法时,第一行先调用checkForComodification()方法,该方法用于检测modCount和expectedModCount是否一致,其作用是在多线程环境下检测集合是否被其他线程修改过。而在对应的add函数中,代码如下:
public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;
}private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflowconscious codeif (minCapacity elementData.length > 0)grow(minCapacity);
}如果在使用迭代器遍历时修改集合元素就会因为迭代器对象已经创建完毕,而此时的expectedModCount与modCount初始值相等,因为每一次添加数据都会导致modCount改变,导致此时的modCount和expectedCount不对应,从而在checkForComodification()方法中抛出异常,具体流程如下:
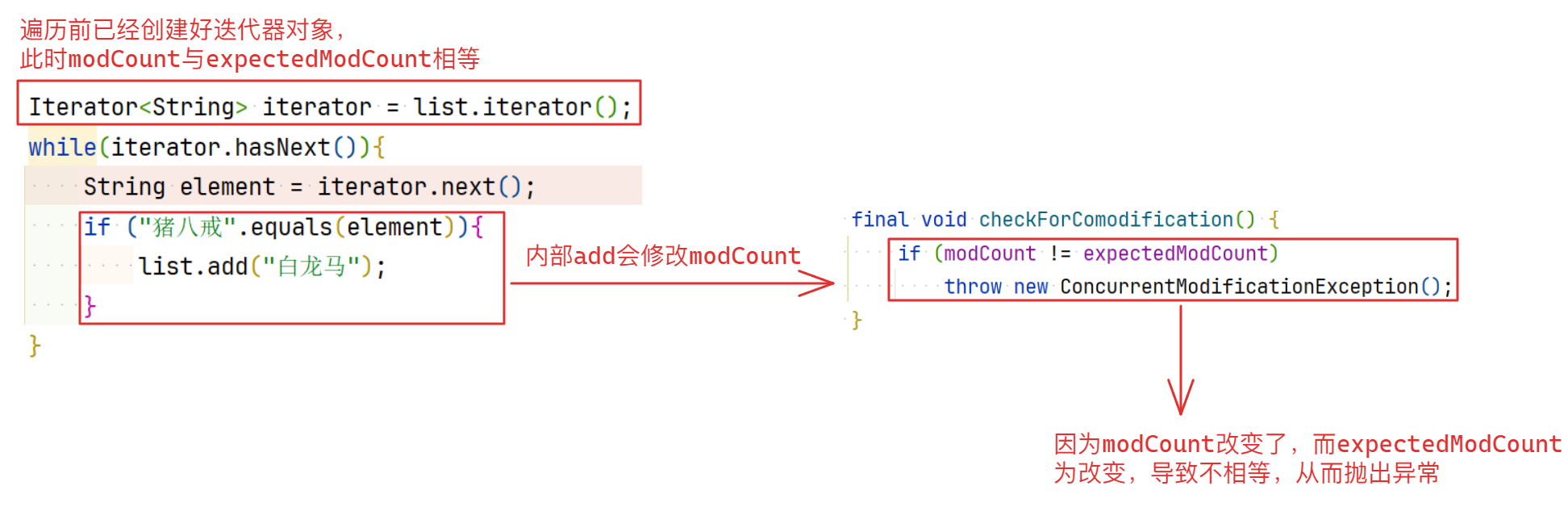
总结:不要在使用迭代器遍历集合的同时修改集合中的内容
List接口
根据前面的单列集合图可以看出,List接口是Collection接口的子接口,常见的实现类一共有三种:
ArrayList类LinkedList类Vector类(现不常用)
ArrayList类
介绍
ArrayList类是List接口的实现类,其特点如下:
- 存储顺序与插入顺序相同
- 元素可重复
- 可以使用索引方式操作
- 线程不安全
- 底层数据结构是数组(可扩容)
常用方法
boolean add(E e):向集合尾部插入元素,返回值表示插入成功(true)或者失败(false),一般情况下可以不用接收void add(int index, E element):在指定位置添加元素,如果指定位置有元素,则在该元素前插入元素boolean remove(Object o):从当前集合中移除指定元素,返回值代表删除成功或者失败E remove(int index):根据索引删除元素,返回被删除的元素E set(int index, E element):修改指定索引的元素,返回被修改的元素E set(int index):根据索引获取元素int size():返回集合中的元素个数
基本使用如下:
public class Test03 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();//boolean add(E e)list.add("铁胆火车侠");list.add("喜洋洋");list.add("火影忍者");list.add("灌篮高手");list.add("网球王子");System.out.println(list);//void add(int index, E element)list.add(2,"猪猪侠");System.out.println(list);//boolean remove(Object o)list.remove("猪猪侠");System.out.println(list);//E remove(int index)String element = list.remove(0);System.out.println(element);System.out.println(list);//E set(int index, E element)String element2 = list.set(0, "金莲");System.out.println(element2);System.out.println(list);//E get(int index)System.out.println(list.get(0));//int size()System.out.println(list.size());}
}遍历集合
既可以使用迭代器遍历集合,也可以使用for循环+下标遍历,例如下面的代码:
public class Test03 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("铁胆火车侠");list.add("喜洋洋");list.add("火影忍者");list.add("灌篮高手");list.add("网球王子");// 迭代器遍历集合Iterator<String> iterator = list.iterator();while(iterator.hasNext()) {String next = iterator.next();System.out.println(next);}// for循环+下标遍历for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}}
}ArrayList底层源码分析
初始容量
实际上ArrayList还有一种构造方法:ArrayList(int initialCapacity),根据给定的数值初始化ArrayList的容量
如果使用空参构造,则默认情况下ArrayList的容量为10,但是需要注意,ArrayList在使用无参构造并且之后不添加任何元素时,其初始容量依旧是0,只有在第一次添加数据时才会开辟容量为10的空间,源码如下:
// 默认容量为0的空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// ArrayList的数据结构
transient Object[] elementData;
// 无参构造方法开始时直接使用空数组构造
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}第一次调用add方法时:
// 默认容量
private static final int DEFAULT_CAPACITY = 10;// add方法
public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;
}// 计算容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;
}// 确保内部数组容量方法
private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}// 修改内部数组大小
private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflowconscious codeif (minCapacity elementData.length > 0)grow(minCapacity);
}private void grow(int minCapacity) {// overflowconscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity minCapacity < 0)newCapacity = minCapacity;if (newCapacity MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);
}因为此时底层数组的容量大小为0,所以在calculateCapacity方法中进入分支语句,此时判断默认容量大小成员DEFAULT_CAPACITY和minCapacity哪一个大,而minCapacity在add方法中是size成员加1的结果,此时因为数组长度为0,所以size也为0,所以minCapacity此时就是1,很明显DEFAULT_CAPACITY和minCapacity,DEFAULT_CAPACITY会更大,所以calculateCapacity方法返回DEFAULT_CAPACITY给ensureExplicitCapacity方法,在该方法中的分支语句判断时,因为minCapacity为1,elementData.length为0,所以此时需要扩容,进入grow方法,传递minCapacity,在grow方法中,oldCapacity为0,newCapacity此时也为0,所以newCapacityminCapacity(此时是DEFAULT_CAPACITY)满足小于0的条件,newCapacity就被更新为DEFAULT_CAPACITY的值,开辟空间后拷贝原数组的数据即可
综上所述:使用ArrayList的无参构造时,默认情况下不会开辟一个容量为10的数组,只有在第一次添加数据时,该数组容量才会变为10
数组扩容
private void grow(int minCapacity) {// overflowconscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity minCapacity < 0)newCapacity = minCapacity;if (newCapacity MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);
}public static <T> T[] copyOf(T[] original, int newLength) {return (T[]) copyOf(original, newLength, original.getClass());
}public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {@SuppressWarnings("unchecked")T[] copy = ((Object)newType == (Object)Object[].class)? (T[]) new Object[newLength]: (T[]) Array.newInstance(newType.getComponentType(), newLength);System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));return copy;
}从这个源码可以看出,当newCapacity大于minCapacity时,两个分支if都不会执行,并且扩容大小为原数组大小的1.5倍,传递newCapacity和当前数组,调用copyOf方法,进入该方法后底层调用系统数组拷贝方法arraycopy,在拷贝时,使用了min方法控制是否要改变数组长度,将原数组的数据拷贝到新数组中,再改变成员elementData的指向,但是不论是否原数组长度小于新长度还是其他情况,都会对原数据进行拷贝
需要注意,尽管在某些情况下不需要扩容,但为了简化代码逻辑和保证数据一致性,通常会统一处理,即总是创建一个新数组并拷贝原有内容。这样做虽然在某些场景下可能有些许性能开销,但在整体上更加安全可靠。
LinkedList类
介绍
LinkedList类是List接口的实现类,其特点如下:
- 存储顺序与插入顺序相同
- 元素可重复
- 可以使用索引方式操作
- 线程不安全
- 底层数据结构是不带头双向不循环链表
常用方法
public void addFirst(E e):将指定元素插入此列表的开头public void addLast(E e):将指定元素添加到此列表的结尾public E getFirst():返回此列表的第一个元素public E getLast():返回此列表的最后一个元素public E get(int index):获取索引位置的元素public E removeFirst():移除并返回此列表的第一个元素,返回被删除的元素public E removeLast():移除并返回此列表的最后一个元素,返回被删除的元素public boolean isEmpty():如果列表没有元素,则返回true,否则返回false
基本使用如下:
public class Test05 {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("吕布");linkedList.add("刘备");linkedList.add("关羽");linkedList.add("张飞");linkedList.add("貂蝉");System.out.println(linkedList);linkedList.addFirst("孙尚香");System.out.println(linkedList);linkedList.addLast("董卓");System.out.println(linkedList);System.out.println(linkedList.getFirst());System.out.println(linkedList.getLast());linkedList.removeFirst();System.out.println(linkedList);linkedList.removeLast();System.out.println(linkedList);}
}需要注意两个比较特殊的方法
public E pop():删除链表头数据,返回被删除的元素public void push(E e):在链表头插入数据
public class Test06 {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("吕布");linkedList.add("刘备");linkedList.add("关羽");linkedList.add("张飞");linkedList.add("貂蝉");linkedList.pop();System.out.println(linkedList);linkedList.push("孙尚香");System.out.println(linkedList);}
}遍历集合
与ArrayList一样,可以使用迭代器,也可以使用for循环+下标
需要注意,默认情况下LinkedList不支持下标访问,因为链表没有下标的概念,但是因为LinkedList提供了类似于下标访问的方法,所以可以使用下标
public class Test06 {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("吕布");linkedList.add("刘备");linkedList.add("关羽");linkedList.add("张飞");linkedList.add("貂蝉");// 迭代器遍历Iterator<String> iterator = linkedList.iterator();while (iterator.hasNext()) {String next = iterator.next();System.out.println(next);}// for循环+下标for (int i = 0; i < linkedList.size(); i++) {System.out.println(linkedList.get(i));}}
}LinkedList底层源码分析
LinkedList成员分析
对于LinkedList来说:
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{transient int size = 0;/*** Pointer to first node.* Invariant: (first == null && last == null) ||* (first.prev == null && first.item != null)*/transient Node<E> first;/*** Pointer to last node.* Invariant: (first == null && last == null) ||* (last.next == null && last.item != null)*/transient Node<E> last;// ...
}对于其中的Node<E>类型(LinkedList的内部类)来说:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}下图是一种情况,对于每一个成员的作用进行解释:
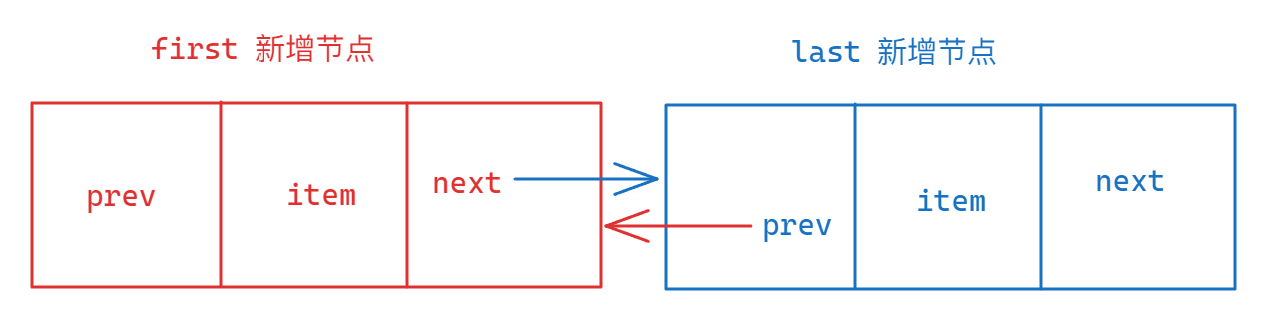
LinkedList中add方法源码分析
public boolean add(E e) {linkLast(e);return true;
}void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;
}调用add方法,相当于调用linkLast方法,当last节点为空节点时,说明当前不存在任何一个节点,此时将头结点指向新插入的节点,否则让最后一个节点的next引用新插入的节点
LinkedList中get方法源码分析
public E get(int index) {checkElementIndex(index);return node(index).item;
}Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}对于LinkedList中的get方法,采用了一种二分的思想,但不完全是二分查找算法的思想,其基本思想是将链表的长度切一半,如果查找的下标小于链表大小的一半,说明需要在前一半中顺序遍历查找,否则在后一半中顺序遍历查找
增强for循环
增强for循环对于集合来说,本质是使用到了迭代器,而对于数组来说,本质是数组的下标遍历
使用格式如下:
for(集合/数组元素的类型 存储元素的变量名 : 集合/数组名) {// 遍历操作
}基本使用如下:
public class Test07 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("张三");list.add("李四");list.add("王五");list.add("赵六");for (String s : list) {System.out.println(s);}System.out.println("=====================");int[] arr = {1,2,3,4,5};for (int i : arr) {System.out.println(i);}}
}反编译查看底层:

相关文章:
Java集合(一)
目录 Java集合(一) 集合介绍 单列集合分类 Collection接口 创建Collection实现类对象 常用方法 迭代器 基本使用 迭代器的执行过程 迭代器底层原理 集合中的并发修改异常及原因分析 List接口 ArrayList类 介绍 常用方法 遍历集合 Array…...
)
车载软件架构 --- SOA设计与应用(下)
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

网络原理 IP协议与以太网协议
博主主页: 码农派大星. 数据结构专栏:Java数据结构 数据库专栏:MySQL数据库 JavaEE专栏:JavaEE 关注博主带你了解更多数据结构知识 目录 1.网络层 IP协议 1.IP协议格式 2.地址管理 2.1 IP地址 2.2 解决IP地址不够用的问题 2.3NAT网络地址转换 2.4网段划分 3.路由选择…...

k8s的安装
k8s的安装 1.创建主机,设置ip,hostname,关闭firewalld,selinux,NetworkManager 编号主机名称ip1k8s-master192.168.118.662k8s-node01192.168.118.773k8s-node02192.168.118.88 2.设置主机之间的ssh免密 [rootk8s-master ~]# ssh-keygen [rootk8s-ma…...

Qt中样式表常用的属性名称定义
Qt中,用好样式表,不但可以做出意想不到的酷炫效果,有时候也能减轻开发量,可能由于你不了解某些样式使用,想破脑袋通过代码实现的效果,反倒不如别人用样式,一两句样式脚本就搞定。 Qt中ÿ…...

React源码学习(一):如何学习React源码
本系列源码学习,是基于 v16.13.1,v17.x与v16.x区别并不太大! 一、如何正确的学习React源码? 找到Github,转到React仓库,fork / clone源码:React 查看Readme,在Documentation中有Cont…...

云计算服务的底层,虚拟化技术的实现原理
虚拟化技术: 一、 从cpu说起, intel和amd等cpu制造商 为了提高其cpu对 虚拟化程序的运算速度, 给cpu硬件里面 增加了指令集 VMLAUNCH, VMRESUME, VMEXIT, VMXOFF 这些指令集称为硬件辅助虚拟化技术的指令集。 ---------------------…...

大数据Flink(一百一十六):Flink SQL的时间属性
文章目录 Flink SQL的时间属性 一、Flink 三种时间属性简介 二、Flink 三种时间属性的应用场景 三、SQL 指定时间属性的两种方式 四、SQL 处理时间DDL定义 五、SQL 事件时间DDL定义 Flink SQL的时…...

Ansible自动化部署kubernetes集群
机器环境介绍 1.1. 机器信息介绍 IP hostname application CPU Memory 192.168.204.129 k8s-master01 etcd,kube-apiserver,kube-controller-manager,kube-scheduler,kubelet,kube-proxy,containerd 2C 4G 192.168.204.130 k8s-w…...

网络通信流程
目录 ♫IP地址 ♫子网掩码 ♫MAC地址 ♫相关设备 ♫ARP寻址 ♫网络通信流程 ♫IP地址 我们已经知道 IP 地址由网络号主机号组成,根据 IP 地址的不同可以有5钟划分网络号和主机号的方案: 其中,各类地址的表示范围是: 分类范围适用…...

数据结构一:绪论
(一)数据结构的基本概念 1.相关名词 【1】数据 1.信息的载体,描述客观事物 2.能被输入到计算机中 3.能被计算机程序识别和处理的符号的集合。 【2】数据元素 1.数据的一个“个体” 2.数据的基本单位 3.有时候也被称为元素、结点、顶点…...

使用OpenFeign在不同微服务之间传递用户信息时失败
文章目录 起因原因解决方法: 起因 从pay-service中实现下单时,会调用到user-service中的扣减余额。 因此这里需要在不同微服务之间传递用户信息。 但是user-service中始终从始至终拿不到user的信息。 原因 在pay-service中,不仅要Enable O…...

js中【Worker】相关知识点详细解读
什么是 JavaScript 中的 Worker? JavaScript 中的 Worker 是一个可以在后台线程中运行代码的 API,这样可以避免主线程(通常是 UI 线程)被阻塞。使用 Worker 时,JavaScript 可以在多线程环境中工作,解决了单…...

使用Apify加载Twitter消息以进行微调的完整指南
# 使用Apify加载Twitter消息以进行微调的完整指南## 引言在自然语言处理领域,微调模型以适应特定任务是提升模型性能的常见方法。本文将介绍如何使用Apify从Twitter导出聊天信息,以便进一步进行微调。## 主要内容### 使用Apify导出推文首先,我…...

【C++算法】滑动窗口
长度最小的子数组 题目链接: 209. 长度最小的子数组 - 力扣(LeetCode)https://leetcode.cn/problems/minimum-size-subarray-sum/description/ 算法原理 代码步骤: 设置left0,right0设置sum0,len0遍历l…...

(c++)猜数字(含根据当前时间生成伪随机数代码)
#include<iostream> #include<ctime>/*用srand((unsigned int)time(NULL));要包含这个头文件,如果没有这两个,rand()函数会一直生成42这个伪随机数。*/using namespace std;int main() {srand((unsigned int)time(NULL));//种子,…...

优化批处理流程:自定义BatchProcessorUtils的设计与应用
优化批处理流程:自定义BatchProcessorUtils的设计与应用 | 原创作者/编辑:凯哥Java | 分类:个人小工具类 在我们开发过程中,处理大量的数据集是一项常见的任务。特别是在数据库操作、文件处理或者…...

Framebuffer应用编程
目录 前言 LCD操作原理 涉及的 API 函数 open函数 ioctl 函数 mmap 函数 Framebuffer程序分析 源码 1.打开设备 2.获取LCD参数 3.映射Framebuffer 4.描点函数 5.随便画几个点 上机实验 前言 本文介绍LCD的操作原理和涉及到的API函数,分析Framebuffer…...

MongoDB根据字段内容长度查询语句
db.getCollection("qlzx_penalties_business_raw").find({$expr: {$lt: [{ $strLenCP: "$punish_name" }, 5]},"punish_name_type" : "机构", "source_data" : /中国/,})解释: 1-"source_data" : /中…...

Android中的单例模式
在Android开发中,单例模式(Singleton Pattern)是一种常用的设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。单例模式在需要控制资源访问、管理共享资源或配置信息的场景下特别有用。在Androi…...
)
1520上市公司企业短期并购绩效和长期并购绩效数据+dofile(2008-2022)
数据来源参考《管理世界》陈仕华老师的做法,详情点击查看更多详情信息时间跨度2008-2022区域跨度企业数据格式dta/excel数据简介今天数据皮皮侠团队为大家分享一份最新的上市公司企业短期并购绩效和长期并购绩效数据,供大家研究使用。数据指标上市公司企…...

KSA工具实战:5分钟搞定内网穿透,无需公网IP也能远程办公
KSA工具实战:5分钟搞定内网穿透,无需公网IP也能远程办公 远程办公已成为现代职场的新常态,但许多人在家访问公司内网资源时,常被复杂的网络配置和公网IP需求劝退。想象一下,周五晚上突然需要调取公司服务器上的方案文件…...

效率提升秘籍:用快马AI一键生成可复用的课堂管理系统登录组件代码
在开发课堂管理系统这类教育软件时,登录模块往往是第一个需要实现的组件。传统手动编写方式不仅耗时,还容易遗漏关键细节。最近尝试用InsCode(快马)平台的AI生成功能,发现它能快速产出符合生产标准的代码,这里分享我的实践心得。 …...

十分钟搞定飞书机器人:用快马平台快速原型化你的openclaw应用
最近在做一个飞书机器人的小项目,发现用openclaw框架配合InsCode(快马)平台可以快速完成原型验证,整个过程比想象中简单很多。这里分享一下我的实践过程,从零开始十分钟就能跑通一个基础功能的飞书机器人。 项目准备阶段 传统开发需要先配置本…...

SEO优化与网站内链优化有什么区别_SEO优化的方法论有哪些
SEO优化与网站内链优化有什么区别 在现代数字营销中,SEO优化和网站内链优化是两个紧密相关但又各有侧重的领域。了解它们之间的区别,对于提升网站的整体流量和搜索引擎排名至关重要。本文将详细探讨这两者的不同之处,并为你提供一些SEO优化的…...
)
医疗AI辅助诊断渲染延迟>180ms?立即执行这4项C++17 constexpr预计算+SIMD向量化改造(附VS2022 / CLion双环境调试checklist)
第一章:医疗AI辅助诊断渲染延迟的临床影响与性能基线定义在放射科、病理科及急诊超声等实时影像决策场景中,AI辅助诊断系统若出现毫秒级渲染延迟,可能直接干扰医生对动态血流、心室壁运动或微小结节增强特征的连续性判读。临床研究表明&#…...
)
告别虚拟机!在Win11的WSL2里用Rust给STM32点灯,保姆级避坑指南(含CMSIS-DAP配置)
在Win11的WSL2中用Rust点亮STM32:全流程避坑指南 当传统虚拟机因性能损耗和资源占用成为开发瓶颈时,WSL2的出现为嵌入式开发者提供了全新选择。本文将带你体验如何在Windows 11环境下,通过WSL2构建完整的Rust嵌入式开发工具链,并解…...

感官伪造风暴:AI用触觉反馈实施千万美元诈骗
一场静默的技术入侵当公众的注意力还停留在AI换脸与拟声诈骗的警示时,一条更隐蔽、更具欺骗性的技术路径已在黑暗中悄然铺就。如果说视觉与听觉的伪造尚可通过“多看两眼”、“多问一句”来警觉,那么当触觉——这一人类最原始、最信赖的感官——也被人工…...
从理论到实战)
用Python手把手教你实现隐马尔可夫模型(HMM)从理论到实战
用Python手把手教你实现隐马尔可夫模型(HMM)从理论到实战 在自然语言处理、语音识别和生物信息学等领域,隐马尔可夫模型(Hidden Markov Model, HMM)是一种经典的概率图模型。本文将带你从零开始,用Python实…...
中的时序约束映射)
深入解析Standard Delay Format(SDF)中的时序约束映射
1. 什么是Standard Delay Format(SDF)? Standard Delay Format(标准延迟格式)是数字电路设计中用于描述时序信息的标准文件格式。简单来说,它就像电路设计的"时间说明书",告诉EDA工具信号在电路中传播需要多…...