CenterNet官方代码—目标检测模型推理部分解析与项目启动
CenterNet模型推理部分解析
CenterNet官方代码环境部署
CenterNet作为2019年CVPR推出的论文,论文中给出了官方代码所在的github仓库地址。https://github.com/xingyizhou/CenterNet。

整个代码的代码量并不是特别大,但整个项目的难点在于使用了老版本的pytorch<1.0与一些依赖的资源库从而导致了整个项目在启动和加载时或产生很多的错误。
GPU版本安装问题

在官方代码的Readme文件夹的下面给出了安装步骤的文件。首先文件中说明了当时使用的时python3.6版本。(不建议使用python3.6版本)
自己使用的conda激活虚拟环境后使用的是3.8版本。
对出错的部分没有进行截图,因此只是简单的进行一定的陈述。
- 错误一:使用pip来安装CUDA的pytorch版本,我在安装的时候发现,如果使用pip来安装torch会安装的是torch+cu这种版本。而使用conda安装的话会安装一些CUDA相关的依赖

而在安装dcnv2的过程中需要CUDA相关库的支持。所以pytorch要使用conda来进行安装。 (最好之间安装Gpu的版本)
gpu.c相关文件也需要编译而且容易报错。
- DCNV2文件对torch版本的不支持,(自己当时使用git切换conda的虚拟环境安装.make.sh文件时候报错)需要使用最新的DCNV2库,卸载之后重新安装替代。

- 踩坑的地方在启动setup.py文件之后,可能会产生两个错误,第一个是因为缺少c++的编译环境,缺少支持库的错误。第二个是说c++库的版本过高不支持
网上查的原因是因为CUDA更新比较慢,而vistual Studio的更新过快。我自己将2022的版本降为2019年的启动成功。
- 一定要下载nvcc完全对应的版本,我自己的是12.1但当时安装习惯安装的是11.8nvcc会报错

总结:我个人使用的是pytorch2.3.0的版本来进行安装的,如果安装过程中出现错误,可以联系博主简单交流。
模型推理部分代码
检测部分的启动参数示例
ctdet
–demo
…/images/17790319373_bd19b24cfc_k.jpg
–load_model
…/models/ctdet_coco_dla_2x.pth
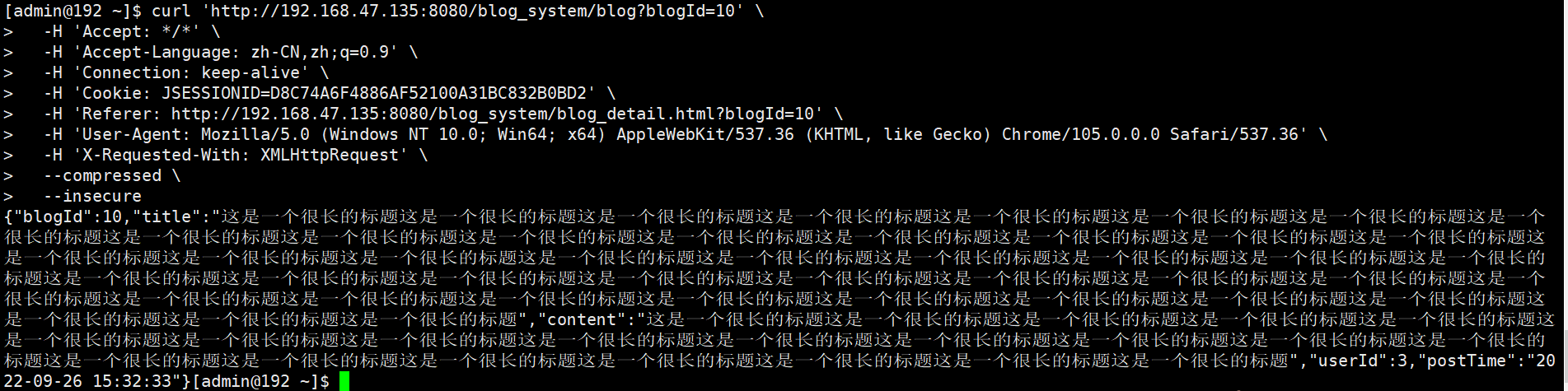
启动部分会产生一个模型下载失败的错误,将模型自己手动的下载到C盘的cache->torch…文件下面即可以启动模型成功。
自己断点调试,报错的一部分主要是网络错误,作用是加载预训练的一部分权重数据。

和Yolo一样也是可以检测视频文件的。
断点调试分析

推理过程整体的执行流程图与代码

def demo(opt):os.environ['CUDA_VISIBLE_DEVICES'] = opt.gpus_str #指定GPU对哪些环境变量可用opt.debug = max(opt.debug, 1) # 设置debug属性便于进行调试Detector = detector_factory[opt.task]detector = Detector(opt)if opt.demo == 'webcam' or \opt.demo[opt.demo.rfind('.') + 1:].lower() in video_ext:cam = cv2.VideoCapture(0 if opt.demo == 'webcam' else opt.demo)detector.pause = Falsewhile True:_, img = cam.read()cv2.imshow('input', img)ret = detector.run(img)time_str = ''for stat in time_stats:time_str = time_str + '{} {:.3f}s |'.format(stat, ret[stat])print(time_str)if cv2.waitKey(1) == 27:return # esc to quitelse:if os.path.isdir(opt.demo): # 如果参数中的待检测数据是文件夹image_names = []ls = os.listdir(opt.demo)for file_name in sorted(ls):ext = file_name[file_name.rfind('.') + 1:].lower()if ext in image_ext:image_names.append(os.path.join(opt.demo, file_name))else: # 普通文件image_names = [opt.demo] #获取文件名for (image_name) in image_names:ret = detector.run(image_name) # 通过检测网络执行推理(核心)time_str = ''for stat in time_stats:time_str = time_str + '{} {:.3f}s |'.format(stat, ret[stat])print(time_str)
核心推理函数的细化分析

run()函数整体的部分
def run(self, image_or_path_or_tensor, meta=None):load_time, pre_time, net_time, dec_time, post_time = 0, 0, 0, 0, 0 #时间变量初始化merge_time, tot_time = 0, 0debugger = Debugger(dataset=self.opt.dataset, ipynb=(self.opt.debug==3), # Debugger便于调试与错误诊断theme=self.opt.debugger_theme)start_time = time.time()pre_processed = Falseif isinstance(image_or_path_or_tensor, np.ndarray):image = image_or_path_or_tensorelif type(image_or_path_or_tensor) == type (''): image = cv2.imread(image_or_path_or_tensor) # 通过opencv读取图片else:image = image_or_path_or_tensor['image'][0].numpy()pre_processed_images = image_or_path_or_tensorpre_processed = Trueloaded_time = time.time()load_time += (loaded_time - start_time)detections = [] # 检测列表for scale in self.scales:scale_start_time = time.time()if not pre_processed:images, meta = self.pre_process(image, scale, meta) # 执行图片的预处理else:# import pdb; pdb.set_trace()images = pre_processed_images['images'][scale][0]meta = pre_processed_images['meta'][scale]meta = {k: v.numpy()[0] for k, v in meta.items()}images = images.to(self.opt.device) # 将image张量移动到GPU上torch.cuda.synchronize() # 确保CUDA操作完成pre_process_time = time.time()pre_time += pre_process_time - scale_start_timeoutput, dets, forward_time = self.process(images, return_time=True)torch.cuda.synchronize()net_time += forward_time - pre_process_time # 根据之前的函数计算出推理解码等一系列的时间decode_time = time.time()dec_time += decode_time - forward_timeif self.opt.debug >= 2:self.debug(debugger, images, dets, output, scale)dets = self.post_process(dets, meta, scale) # 执行后处理的过程(得到80个类别的列表信息部分含有数据)torch.cuda.synchronize()post_process_time = time.time()post_time += post_process_time - decode_time # 计算后处理时间detections.append(dets)results = self.merge_outputs(detections)torch.cuda.synchronize()end_time = time.time()merge_time += end_time - post_process_timetot_time += end_time - start_timeif self.opt.debug >= 1:self.show_results(debugger, image, results) # 调用opencv函数显示结果return {'results': results, 'tot': tot_time, 'load': load_time, # 放入所有的信息进行返回'pre': pre_time, 'net': net_time, 'dec': dec_time,'post': post_time, 'merge': merge_time}
预处理函数的执行部分
def pre_process(self, image, scale, meta=None):height, width = image.shape[0:2]new_height = int(height * scale)new_width = int(width * scale)if self.opt.fix_res: # 转为输入大小512 x 512inp_height, inp_width = self.opt.input_h, self.opt.input_wc = np.array([new_width / 2., new_height / 2.], dtype=np.float32)s = max(height, width) * 1.0else:inp_height = (new_height | self.opt.pad) + 1inp_width = (new_width | self.opt.pad) + 1c = np.array([new_width // 2, new_height // 2], dtype=np.float32)s = np.array([inp_width, inp_height], dtype=np.float32)trans_input = get_affine_transform(c, s, 0, [inp_width, inp_height])# 获取仿射变换矩阵resized_image = cv2.resize(image, (new_width, new_height))# 读取图片裁剪inp_image = cv2.warpAffine(resized_image, trans_input, (inp_width, inp_height),flags=cv2.INTER_LINEAR) # 应用之前的仿射矩阵进行仿射变换inp_image = ((inp_image / 255. - self.mean) / self.std).astype(np.float32) # 归一化处理images = inp_image.transpose(2, 0, 1).reshape(1, 3, inp_height, inp_width)if self.opt.flip_test:images = np.concatenate((images, images[:, :, :, ::-1]), axis=0)images = torch.from_numpy(images) # 转为张量的格式meta = {'c': c, 's': s, 'out_height': inp_height // self.opt.down_ratio, # opt.down_ratio:下采样倍率'out_width': inp_width // self.opt.down_ratio} # 储存c:中心点坐标 s:缩放因子return images, meta # 128x128(下采样4倍的特征图)
解码扩增部分对应的代码信息
def ctdet_decode(heat, wh, reg=None, cat_spec_wh=False, K=100):batch, cat, height, width = heat.size() # cat:表示类别的数目# heat = torch.sigmoid(heat)# perform nms on heatmapsheat = _nms(heat) # maxpooling(3x3)类似nms算法# scores:得分最高的 K 个点的得分。# inds:得分最高的 K 个点的索引。# clses:得分最高的 K 个点对应的类别。# ys:得分最高的 K 个点的 y 坐标。# xs:得分最高的 K 个点的 x 坐标。scores, inds, clses, ys, xs = _topk(heat, K=K) # 在热力图 heat 上执行 Top-K 操作提取最高 K 个得分的点提取最高 K 个得分的点if reg is not None: # 位置微调的过程reg = _transpose_and_gather_feat(reg, inds) # 将回归参数 reg 按照 inds(Top-K 操作返回的索引)重新排列,以便收集与 Top-K 操作选择的热力图位置相对应的回归参数reg = reg.view(batch, K, 2) # 收集到的回归参数 reg 调整为形状 [batch, K, 2] 的张量,其中 batch 是批次大小,K 是 Top-K 操作选择的点的数量,2 表示每个点的两个回归参数(通常是一个点的 x 和 y 方向的偏移量)xs = xs.view(batch, K, 1) + reg[:, :, 0:1] # x坐标与回归偏移量的坐标相加ys = ys.view(batch, K, 1) + reg[:, :, 1:2]else:xs = xs.view(batch, K, 1) + 0.5ys = ys.view(batch, K, 1) + 0.5wh = _transpose_and_gather_feat(wh, inds) # 特征图的维度从 [batch, num_anchors, height, width] 转换为 [batch, K, num_anchors]if cat_spec_wh: # 是否每个类别有特定的宽度和高度预测wh = wh.view(batch, K, cat, 2) # wh 张量的形状调整为 [batch, K, num_classes, 2]clses_ind = clses.view(batch, K, 1, 1).expand(batch, K, 1, 2).long() # 创建一个索引张量,用于从 wh 中收集特定类别的宽度和高度wh = wh.gather(2, clses_ind).view(batch, K, 2) # 得到结果值else:wh = wh.view(batch, K, 2)clses = clses.view(batch, K, 1).float()scores = scores.view(batch, K, 1)bboxes = torch.cat([xs - wh[..., 0:1] / 2, # torch.cat 函数将四个坐标点(左上角和右下角)拼接成一个检测框的坐标张量ys - wh[..., 1:2] / 2,xs + wh[..., 0:1] / 2, # xs + wh[..., 0:1] / 2 和 ys + wh[..., 1:2] / 2:计算右下角的坐标。ys + wh[..., 1:2] / 2], dim=2) # xs - wh[..., 0:1] / 2 和 ys - wh[..., 1:2] / 2:计算左上角的坐标。detections = torch.cat([bboxes, scores, clses], dim=2)return detections # 连接之后返回检测框结果(论文中提到的扩增的过程)
后处理函数的执行部分
def post_process(self, dets, meta, scale=1):dets = dets.detach().cpu().numpy() # 转为numpy格式进入cpu进行计算dets = dets.reshape(1, -1, dets.shape[2])dets = ctdet_post_process( # 尺度变换、坐标转换、非极大值抑制(NMS) 传入的meta['c']中心点 meta['s']缩放尺度dets.copy(), [meta['c']], [meta['s']],meta['out_height'], meta['out_width'], self.opt.num_classes)for j in range(1, self.num_classes + 1): # 后处理转换类型dets[0][j] = np.array(dets[0][j], dtype=np.float32).reshape(-1, 5)dets[0][j][:, :4] /= scalereturn dets[0]
剩余的部分函数不在进行说明了,但模型推理代码的复现流程主要还是需要按照我自己绘制的流程图进行debug
相关文章:
CenterNet官方代码—目标检测模型推理部分解析与项目启动
CenterNet模型推理部分解析 CenterNet官方代码环境部署 CenterNet作为2019年CVPR推出的论文,论文中给出了官方代码所在的github仓库地址。https://github.com/xingyizhou/CenterNet。 整个代码的代码量并不是特别大,但整个项目的难点在于使用了老版本的…...
测试开发基础——测试用例的设计
三、测试用例的设计 1. 什么是测试用例 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境、操作步骤、测试数据、预期结果等要素。 设计测试用例原则一:测试用例中一个必需部分是对预期输出或结果进…...

C++第五十一弹---IO流实战:高效文件读写与格式化输出
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】 目录 1. C语言的输入与输出 2. 流是什么 3. CIO流 3.1 C标准IO流 3.2 C文件IO流 3.2.1 以写方式打开文件 3.2.1 以读方式打开文件 4 stringstre…...

C++中使用分治法求最大值
在C++中使用分治法(Divide and Conquer)来求一个数组中的最大值是一个经典的问题。分治法是一种通过将原问题分解为若干个小规模相似子问题,递归地求解这些子问题,然后将子问题的解合并成原问题的解的方法。 以下是使用分治法求数组中最大值的步骤: 分解(Divide):将数…...

数据集 CULane 车道线检测 >> DataBall
数据集 CULane 车道线检测 自动驾驶 无人驾驶目标检测 CULane是用于行车道检测学术研究的大规模具有挑战性的数据集。它由安装在六辆由北京不同驾驶员驾驶的不同车辆上的摄像机收集。收集了超过55小时的视频,并提取了133,235帧。数据示例如上所示。我们将数据集分为…...

Android CustomDialog圆角背景不生效的问题
一行解决: window?.setBackgroundDrawableResource(android.R.color.transparent) 原文件: /*** Created by Xinghai.Zhao* 自定义选择弹框*/ SuppressLint("InflateParams", "MissingInflatedId") class CustomDialog(context: Context?) : AlertDia…...

C++速通LeetCode简单第9题-二叉树的最大深度
深度优先算法递归: /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right…...

com.microsoft.sqlserver:sqljdbc4:jar:4.0 was not found产生原因及解决步骤
文章目录 问题sqlserver 包找不到 报错原因分析主要原因 解决方案步骤 1:检查 pom.xml 中的依赖声明步骤 2:配置 Microsoft 的 Maven 仓库步骤 3:强制更新 Maven 依赖步骤 4:清理本地仓库缓存步骤 5:手动下载并安装 sq…...

【算法】 滑动窗口—最长无重复子串
“无重复字符的最长子串”,难度为Medium,看下题目: 输入一个字符串 s,请计算 s 中不包含重复字符的最长子串长度。 比如,输入 s "aabab",算法返回2,因为无重复的最长子串是 "ab…...

SpringBoot2:web开发常用功能实现及原理解析-上传与下载
文章目录 一、上传文件1、前端上传文件给Java接口2、Java接口上传文件给Java接口 二、下载文件1、前端调用Java接口下载文件2、Java接口下载网络文件到本地3、前端调用Java接口下载网络文件 一、上传文件 1、前端上传文件给Java接口 Controller接口 此接口支持上传单个文件和…...

Linux:进程状态和优先级
一、进程状态 1.1 操作系统学科(运行、阻塞、挂起) 为了弄明白正在运行的进程是什么意思,我们需要知道进程的不同状态 大多数操作系统都遵循以下原则 1.1.1 运行状态 因为有一个调度器需要确保CPU的资源被合理使用,所以需要维护…...

代码随想录算法训练营day37
1.携带研究材料 1.1 题目 52. 携带研究材料(第七期模拟笔试) 1.2 题解 #include <iostream> #include <functional> #include <vector> using namespace std;int main() {//输入相关信息int classes, cabaity;cin >> classe…...

Java-idea小锤子图标
这一版的idea小锤子图标其实就在这里 点进去就找到了~...

最强神器Typora 2024(亲测有效)| Markdown 工具推荐
听俺讲一下 大家好,我是程序员-杨胡广,今天想给大家分享一个在编写文档时的神器——Typora。相信不少小伙伴都在寻找一款既简洁又强大的 Markdown 编辑工具,而 Typora 无疑是最值得推荐的选择。 当我在大学时偶然发现了它,直到今…...

【时时三省】tessy 单元测试 集成测试 专栏 文章阅读说明
目录 1,关于更新 2,关于文章阅读 3,关于文章分类 1,单元测试 2,集成测试 3,通用便捷操作 4,编译问题集锦 5,需求管理 6,CTE的使用 7,tessy自动化执…...

力扣刷题(6)
两数之和 II - 输入有序数组 两数之和 II - 输入有序数组-力扣 思路: 因为该数组是非递减顺序排列,因此可以设两个左右下标当左右下标的数相加大于target时,则表示右下标的数字过大,因此将右下标 - -当左右下标的数相加小于targ…...

TiDB 扩容过程中 PD 生成调度的原理及常见问题丨TiDB 扩缩容指南(一)
导读 作为一个分布式数据库,扩缩容是 TiDB 集群最常见的运维操作之一。本系列文章,我们将基于 v7.5.0 具体介绍扩缩容操作的具体原理、相关配置及常见问题的排查。 通常,我们根据当前资源状态来决定是否需要调整 TiKV 节点的规模࿰…...

匿名管道详解
进程间通讯的目的 数据传输:一个进程需要把它的数据发送给另一个数据资源共享:多个进程需要共享同样的资源通知事件:一个进程需要向另一个或者一组进程发送消息,通知它发生了某种事件(如进程终止时要通知父进程&#…...

深度解读MySQL意向锁的工作原理机制与应用场景
意向锁 意向锁的概念 意向锁是InnoDB自动添加的一种锁,不需要用户去干预。 是数据库中的一种表级锁,一个事务要给一个资源加锁时,必须要先获取到对应类型的意向锁之后,才可以给这个资源加上自己想要的共享锁或者排他锁࿰…...

ZYNQ TCP 协议的远程更新 QSPI Flash
1 SDK直接少些Flash过程 ****** Xilinx Program Flash ****** Program Flash v2019.1 (64-bit)**** SW Build 2552052 on Fri May 24 14:49:42 MDT 2019** Copyright 1986-2019 Xilinx, Inc. All Rights Reserved.WARNING: Failed to connect to hw_server at TCP:127.0.0.1:3…...

告别重复劳动:用快马AI生成自动化脚本,提升日常运维效率三倍
告别重复劳动:用快马AI生成自动化脚本,提升日常运维效率三倍 日常运维工作中,最让人头疼的就是那些重复性操作。比如每周都要手动检查几十台服务器的配置文件状态,或者挨个备份关键配置。这种工作不仅枯燥,还容易出错…...

如何用LRC Maker在10分钟内制作专业级滚动歌词:免费在线歌词编辑终极指南
如何用LRC Maker在10分钟内制作专业级滚动歌词:免费在线歌词编辑终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾为制作歌词时间轴而烦…...

Jimeng AI Studio Z-Image Turbo性能压测:并发生成请求处理能力实测
Jimeng AI Studio Z-Image Turbo性能压测:并发生成请求处理能力实测 1. 为什么需要压测影像生成工具? 你有没有遇到过这样的情况:刚打开AI绘图工具,输入提示词,点击生成,结果等了快半分钟——画面才慢慢浮…...
)
手把手教你用Python模拟勒索病毒代码(仅供安全研究,附完整代码与注释)
Python模拟勒索病毒代码解析:防御视角的技术实践 在网络安全领域,理解攻击者的思维方式和工具运作原理是构建有效防御体系的关键。本文将从防御性学习的角度,通过Python代码模拟勒索病毒的核心功能模块,帮助安全研究人员和技术爱好…...

Vue工业互联网平台:多租户跨平台支持,涵盖工业4.0主流业务需求,助力企业数字化转型
工业互联网CPS系统是一套前端基于Vue2.6,后端基于.NetCore3.1,前后端分离,支持跨平台、支持多租户、多语言、多数据库的平台型应用软件。 它涵盖了工业4.0领域主流的业务需求,如MES、WMS、SRM、EMS、QMS、Scada等。 本人深耕工业4…...
TranslucentTB错误代码0x80070490:从现象到本质的解决之道
TranslucentTB错误代码0x80070490:从现象到本质的解决之道 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 问题定位 今天收到…...

DAMO-YOLO医疗影像应用:CT扫描病灶自动标注
DAMO-YOLO医疗影像应用:CT扫描病灶自动标注 1. 引言 放射科医生每天需要分析大量的CT扫描影像,寻找可能存在的病灶区域。传统的人工标注方式不仅耗时耗力,还容易因疲劳导致漏诊或误诊。一张肺部CT可能包含数百张切片,医生需要逐…...

Android蓝牙安全服务注册机制解析——bta_security结构体与btm_cb.api的关联
1. Android蓝牙安全服务注册机制概览 在Android蓝牙模块中,安全服务注册是整个通信链路建立的关键环节。简单来说,这就像你去银行办业务前需要先登记个人信息一样,设备间建立安全连接前也需要完成类似的"身份登记"过程。这里涉及两…...

法律文书助手:OpenClaw调用Qwen3.5-9B生成合规合同草案
法律文书助手:OpenClaw调用Qwen3.5-9B生成合规合同草案 1. 为什么需要本地化的法律文书助手? 作为一名经常需要处理合同的法律从业者,我深知传统文书起草流程的痛点。过去要么手动从零开始撰写,要么使用SaaS平台的模板工具&…...

NE555芯片应用与15个经典电路项目详解
1. NE555芯片:电子工程师的瑞士军刀NE555这颗小小的8脚芯片,自1971年由Signetics公司推出以来,已经陪伴电子工程师走过了半个世纪。它就像电子设计领域的瑞士军刀,凭借其稳定的定时精度、灵活的配置方式和低廉的价格,至…...