进阶岛 任务3: LMDeploy 量化部署进阶实践
进阶岛 任务3: LMDeploy 量化部署进阶实践
任务:https://github.com/InternLM/Tutorial/blob/camp3/docs/L2/LMDeploy/task.md
使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话,作业截图需包括显存占用情况与大模型回复,参考4.1 API开发(优秀学员必做),请注意2.2.3节与4.1节应使用作业版本命令。
使用Function call功能让大模型完成一次简单的"加"与"乘"函数调用,作业截图需包括大模型回复的工具调用情况,参考4.2 Function call(选做)
文档:
https://github.com/InternLM/Tutorial/blob/camp3/docs/L2/LMDeploy/readme.md
视频:
https://www.bilibili.com/video/BV1df421q7cR/?vd_source=4ffecd6d839338c9390829e56a43ca8d
任务
gpu显存计算
进入创建好的conda环境并启动InternLM2_5-7b-chat,交互式环境:
lmdeploy chat /root/models/internlm2_5-7b-chat

显存占用23G:
lmdeploy默认设置cache-max-entry-count为0.8,即kv cache占用剩余显存的80%;
对于24GB的显卡,权重占用14GB显存,剩余显存24-14=10GB,因此kv cache占用10GB*0.8=8GB,加上原来的权重14GB,总共占用14+8=22GB。
实际加载模型后,其他项也会占用部分显存,因此剩余显存比理论偏低,实际占用会略高于22G.
大模型封装为API接口服务,供客户端访问
命令启动API服务器,部署InternLM2.5模型
lmdeploy serve api_server
/root/models/internlm2_5-7b-chat
–model-format hf
–quant-policy 0
–server-name 0.0.0.0
–server-port 23333
–tp 1
端口映射:
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 48626
windows下可以查看
打开浏览器,访问http://127.0.0.1:23333看到如下界面即代表部署成功。
启动命令行客户端。
lmdeploy serve api_client http://localhost:23333
以Gradio网页形式连接API服务器
使用Gradio作为前端,启动网页。
lmdeploy serve gradio http://localhost:23333
–server-name 0.0.0.0
–server-port 6006

量化
启动API服务器。
lmdeploy serve api_server
/root/models/internlm2_5-7b-chat
–model-format hf
–quant-policy 4
–cache-max-entry-count 0.4
–server-name 0.0.0.0
–server-port 23333
–tp 1
quant_policy=4 表示 kv int4 量化,
显存占用情况和对话:

解释:
都使用BF16精度下的internlm2.5 7B模型,故剩余显存均为10GB。 且 cache-max-entry-count 均为0.4,这意味着LMDeploy将分配40%的剩余显存用于kv cache,即10GB*0.4=4GB。 但quant-policy 设置为4时,意味着使用int4精度进行量化。因此,LMDeploy将会使用int4精度提前开辟4GB的kv cache。
相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
启动命令行客户端。
lmdeploy serve api_client http://localhost:23333
对话:

W4A16 模型量化和部署
lmdeploy lite auto_awq
/root/models/internlm2_5-1_8b-chat
–calib-dataset ‘ptb’
–calib-samples 128
–calib-seqlen 2048
–w-bits 4
–w-group-size 128
–batch-size 1
–search-scale False
–work-dir /root/models/internlm2_5-1_8b-chat-w4a16-4bit
命令解释:lmdeploy lite auto_awq: lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重量化(auto-weight-quantization)。
/root/models/internlm2_5-7b-chat: 模型文件的路径。
--calib-dataset 'ptb': 这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。
--calib-samples 128: 这指定了用于校准的样本数量—128个样本
--calib-seqlen 2048: 这指定了校准过程中使用的序列长度—2048
--w-bits 4: 这表示权重(weights)的位数将被量化为4位。
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit: 这是工作目录的路径,用于存储量化后的模型和中间结果。
量化后模型大小:
(torch2_py310) root@intern-studio-50208960:~/models# du -sh *
0 InternVL2-26B
0 internlm2_5-1_8b-chat
1.5G internlm2_5-1_8b-chat-w4a16-4bit
0 internlm2_5-7b-chat
原模型大小:
(torch2_py310) root@intern-studio-50208960:~/models# du -sh /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat
3.6G /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat
启动量化后的模型。
lmdeploy chat internlm2_5-1_8b-chat-w4a16-4bit --model-format awq
显存占用:

W4A16量化之后:
1.在 int4 精度下,1.5B,float16 模型权重占用:3G/4=0.75GGB
2.kv cache占用18.6GB:剩余显存24-0.75=23.25GB,kv cache默认占用80%,即23.25*0.8=18.6GB
3.其他项: 1G
20.3GB=权重占用0.75GB+kv cache占用18.6GB+其它项1GB
W4A16 量化+ KV cache+KV cache 量化
同时启用量化后的模型、设定kv cache占用和kv cache int4量化
lmdeploy serve api_server
/root/models/internlm2_5-1_8b-chat-w4a16-4bit/
–model-format awq
–quant-policy 4
–cache-max-entry-count 0.4
–server-name 0.0.0.0
–server-port 23333
–tp 1
1.在 int4 精度下,1.5B,float16 模型权重占用:3G/4=0.75GGB
2.kv cache占用18.6GB:剩余显存24-0.75=23.25GB,kv cache默认占用80%,即23.25*0.4=9.3GB
3.其他项: 1G
11GB=权重占用0.75GB+kv cache占用9.3GB+其它项1GB

LMDeploy之FastAPI与Function call
启动API服务器。
lmdeploy serve api_server
/root/models/internlm2_5-1_8b-chat-w4a16-4bit
–model-format awq
–cache-max-entry-count 0.4
–quant-policy 4
–server-name 0.0.0.0
–server-port 23333
–tp 1
internlm2_5.py
# 导入openai模块中的OpenAI类,这个类用于与OpenAI API进行交互
from openai import OpenAI# 创建一个OpenAI的客户端实例,需要传入API密钥和API的基础URL
client = OpenAI(api_key='YOUR_API_KEY', # 替换为你的OpenAI API密钥,由于我们使用的本地API,无需密钥,任意填写即可base_url="http://0.0.0.0:23333/v1" # 指定API的基础URL,这里使用了本地地址和端口
)# 调用client.models.list()方法获取所有可用的模型,并选择第一个模型的ID
# models.list()返回一个模型列表,每个模型都有一个id属性
model_name = client.models.list().data[0].id# 使用client.chat.completions.create()方法创建一个聊天补全请求
# 这个方法需要传入多个参数来指定请求的细节
response = client.chat.completions.create(model=model_name, # 指定要使用的模型IDmessages=[ # 定义消息列表,列表中的每个字典代表一个消息{"role": "system", "content": "你是一个友好的小助手,负责解决问题."}, # 系统消息,定义助手的行为{"role": "user", "content": "帮我讲述一个关于狐狸和西瓜的小故事"}, # 用户消息,询问时间管理的建议],temperature=0.8, # 控制生成文本的随机性,值越高生成的文本越随机top_p=0.8 # 控制生成文本的多样性,值越高生成的文本越多样
)# 打印出API的响应结果
print(response.choices[0].message.content)Function call
函数调用功能,它允许开发者在调用模型时,详细说明函数的作用,并使模型能够智能地根据用户的提问来输入参数并执行函数。完成调用后,模型会将函数的输出结果作为回答用户问题的依据。
internlm2_5_func.py
from openai import OpenAIdef add(a: int, b: int):return a + bdef mul(a: int, b: int):return a * btools = [{'type': 'function','function': {'name': 'add','description': 'Compute the sum of two numbers','parameters': {'type': 'object','properties': {'a': {'type': 'int','description': 'A number',},'b': {'type': 'int','description': 'A number',},},'required': ['a', 'b'],},}
}, {'type': 'function','function': {'name': 'mul','description': 'Calculate the product of two numbers','parameters': {'type': 'object','properties': {'a': {'type': 'int','description': 'A number',},'b': {'type': 'int','description': 'A number',},},'required': ['a', 'b'],},}
}]
messages = [{'role': 'user', 'content': 'Compute (3+5)*2'}]client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(model=model_name,messages=messages,temperature=0.8,top_p=0.8,stream=False,tools=tools)
print(response)
func1_name = response.choices[0].message.tool_calls[0].function.name
func1_args = response.choices[0].message.tool_calls[0].function.arguments
func1_out = eval(f'{func1_name}(**{func1_args})')
print(func1_out)messages.append({'role': 'assistant','content': response.choices[0].message.content
})
messages.append({'role': 'environment','content': f'3+5={func1_out}','name': 'plugin'
})
response = client.chat.completions.create(model=model_name,messages=messages,temperature=0.8,top_p=0.8,stream=False,tools=tools)
print(response)
func2_name = response.choices[0].message.tool_calls[0].function.name
func2_args = response.choices[0].message.tool_calls[0].function.arguments
func2_out = eval(f'{func2_name}(**{func2_args})')
print(func2_out)笔记
对于一个7B(70亿)参数的模型,每个参数使用16位浮点数(等于 2个 Byte)表示,则模型的权重大小约为:
70亿个参数×每个参数占用2个字节=14GB,所以我们需要大于14GB的显存

大模型缓存推理计数
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存
internLm实现:
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的
在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。

位置编码和缓存代码细节:

lmdeploy 对kv cache的实现
预先申请,申请剩余显存的,用cache_max_entry_count 控制kv缓存占用剩余显存的最大比例。默认的比例为0.8。

量化技术:
模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现
LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和cache-max-entry-count参数。目前,LMDeploy 规定 quant_policy=4 表示 kv int4 量化,

lmdeploy 量化方案
kv cache 量化

w4A16量化
使用awq算法:
w:权重 4:4bit 量化。 A: 激活值 16: 反量化为16 。
表示存储的时候量化4,计算的时候反量化为16 。
官方解释:
W4A16又是什么意思呢?
W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
W4A16的量化配置意味着:
权重被量化为4位整数。
激活保持为16位浮点数。

LMDeploy的量化方案-Awq量化原理
核心观点1:权重并不等同重要,仅有0.1~1%小部分显著权重对推理结果影响较大
在线如果有办法将这0.1~1%的小部分显著权重保持FP16,对其他权重进行低比特量化,可以大幅降低内存占用问题来了:如果选出显著权重?
随机挑选 -听天由命
基于权重分布挑选-好像应该这样
基于激活值挑选-竟然是这样---最终方案
核心观点2:量化时对显著权重进行放大可以降低量化误差
外推技术
什么是外推?
长度外推性是一个训练和预测的长度不一致的问题。
外推引发的两大问题
预测阶段用到了没训练过的位置编码模型不可避免地在一定程度上对位置编码“过拟合预测注意力时注意力机制所处理的token数量远超训练时的数量导致计算注意力“熵”的差异较大
大模型为什么需要位置编码
并行化的自注意力机制并不具备区分token相对位置的能力
“mod”的主要特性是周期性,因此与周期函数cos/sin具有一定的等效性
因此,Sinusoidal位置编码可以认为是一种特殊的B进制编码

大模型外推技术-用位置编码

方案:训练阶段就预留好足够的位数
Transformer的原作者就是这么想的,认为预留好位数后模型就能具备对位置编码的泛化性。
现实情况:模型并没有按照我们的期望进行泛化
训练阶段大多数高位都是“0”,因此这部分位数没有被充分训练,模型无法处理这些新编码,
最终方案:
大模型其实并不知道我们输入的位置编码具体是多少“进制”的,他只对相对大小关系敏感
通过“进制转换”:来等效“内插”,即NTK-aware外推技术


function calling
什么是 Function Calling? 为什么要有 Function Calling?
Function Calling,即为让 LLM 调用外部函数解决问题,,从而拓展 LLM 的能力边界。
Timm
Timm(PyTorch Image Models)是一个广泛使用的开源库,它为计算机视觉任务提供了大量的预训练模型、层、实用工具、优化器、调度器、数据加载器、增强策略以及训练和验证脚本。这个库旨在简化模型的选择、创建和微调过程,让研究人员和开发者能够更容易地在自己的项目中尝试不同的模型结构和预训练权重。
Timm 库的特点包括:
- 提供了超过700种预训练模型,包括各种最新的视觉模型。
- 支持通过简单的接口快速加载模型,并可选择是否加载预训练权重。
- 包含了多种优化器和调度器,以及数据加载和增强的工具。
- 提供了灵活的模型创建和调整方法,使得用户可以根据自己的需求修改模型结构。
使用 Timm 库,你可以轻松地进行以下操作:
- 通过
timm.create_model函数创建模型,并通过pretrained=True参数加载预训练权重。 - 使用
timm.list_models()函数列出所有可用的模型名称,或者通过正则表达式匹配特定模型。 - 对模型进行迁移学习或微调,以适应特定的任务或数据集。
Timm 库适用于多种应用场景,包括图像分类、目标检测、语义分割等,并且可以与快速AI(fastai)等其他库集成,提供更强大的功能。
如果你想要开始使用 Timm 库,可以通过以下命令安装:
pip install timm
然后,你可以按照官方文档中的指南开始使用库中的模型和工具。更多详细信息和教程,可以参考 Timm 的官方文档 。
gradio
Gradio 是一个用于快速构建机器学习模型演示或 Web 应用程序的 Python 库。你可以使用 Gradio 轻松地将任何 Python 函数包装成交互式的 Web 界面,并与他人分享。以下是如何使用 Gradio 的基本步骤:
-
安装 Gradio:
首先,你需要安装 Gradio。可以通过 pip 安装:pip install gradio如果你使用的是 Python 虚拟环境,确保在安装时已经激活了虚拟环境。
-
创建 Gradio 应用:
你可以在 Python 文件、Jupyter Notebook 或 Google Colab 中创建 Gradio 应用。以下是一个简单的 Gradio 应用示例:import gradio as grdef greet(name):return "Hello " + name + "!"demo = gr.Interface(fn=greet, inputs="text", outputs="text") demo.launch()这段代码创建了一个简单的 Gradio 应用,它接受文本输入并返回问候语。
-
分享 Gradio 应用:
你可以通过设置share=True参数在launch()函数中创建一个公共链接,以便与他人分享你的 Gradio 应用:demo.launch(share=True)这将生成一个可以在互联网上访问的链接,你可以将这个链接发送给任何人,让他们在你的机器上远程使用你的 Gradio 应用。
-
托管 Gradio 应用:
如果你想永久托管你的 Gradio 应用,可以使用 Hugging Face Spaces。这是一个免费托管 Gradio 应用的平台。 -
Gradio 组件:
Gradio 提供了多种内置组件,如文本框、滑块、图像、下拉菜单等,你可以根据需要选择适当的组件来构建你的应用界面。 -
样式和布局:
你可以通过 CSS 自定义 Gradio 应用的样式,并通过 Blocks API 来创建更复杂的布局。 -
事件和交互:
Gradio 支持事件监听和交互式组件,你可以使用这些功能来创建动态和响应式的用户界面。 -
流式输入和输出:
对于需要处理实时数据的应用,Gradio 支持流式输入和输出,这对于视频流或实时数据可视化非常有用。 -
批处理:
Gradio 还支持批处理函数,这允许你的函数一次处理多个输入并返回多个输出。 -
文档和资源:
你可以在 Gradio 的官方文档中找到更多关于如何使用 Gradio 的信息和示例,以及如何构建和分享你的应用。
通过这些步骤,你可以快速开始使用 Gradio 来构建和分享你的机器学习模型或任何 Python 函数的 Web 界面。如果你需要更详细的指导,可以参考 Gradio 的官方文档 。
相关文章:
进阶岛 任务3: LMDeploy 量化部署进阶实践
进阶岛 任务3: LMDeploy 量化部署进阶实践 任务:https://github.com/InternLM/Tutorial/blob/camp3/docs/L2/LMDeploy/task.md 使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话,作业截图需包…...

vue 使用jszip,file-saver下载压缩包,自定义文件夹名,文件名打包下载为zip压缩包文件,全局封装公共方法使用。
记录一下后台管理全局封装一个压缩包下载方法,文件夹名自定义,文件名自定义,压缩包名自定义。 安装必要的库 npm install jszip npm install file-saver自定义一个公共方法全局注入 页面使用 /** 下载按钮操作 */handleDownload() {const i…...

计网八股文
1.HTTP和HTTPS的区别 安全性: HTTP:是未加密的协议,意味着数据在传输过程中可以被截获、篡改或监听。它不提供任何数据加密。HTTPS:在HTTP的基础上加入了SSL/TLS协议,提供了数据加密、完整性校验和身份验证。这使得传输…...

[001-03-007].第07节:Redis中的事务
我的后端学习大纲 我的Redis学习大纲 1、Redis事务是什么: 1.可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化, 按顺序地串行化执行而不会被其他命令插入,不许加塞2.一个队列中,一次性、…...

WLAN实验简述
一:配置生产AP1上级接入层交换机LSW3 sys [Huawei]sysname LSW3 [LSW3]undo info-center enable [LSW3]vlan batch 10 100 [LSW3]int g0/0/2 [LSW3-GigabitEthernet0/0/2]port link-type trunk [LSW3-GigabitEthernet0/0/2]port trunk allow-pass vlan 10 100 [LSW…...

Docker简介在Centos和Ubuntu环境下安装Docker
文章目录 1.Docker简介2.Docker镜像与容器3.安装Docker3.1 Centos环境3.2 Ubuntu环境 1.Docker简介 Docker 是一个开源的应用容器引擎,它允许开发者将应用程序及其依赖项打包到一个可移植的容器中,然后发布到任何流行的 Linux 或 Windows 操作系统上。D…...

C:字符串函数(续)-学习笔记
穗 一些闲话: 最近玩了这款饿殍-明末千里行,不知大家是否有听过这款游戏,颇有感触!!! 游戏中最让我难以忘怀的便是饿殍穗线的故事,生在如今时代的我之前无法理解杜甫在目睹人间悲剧时的心情&…...
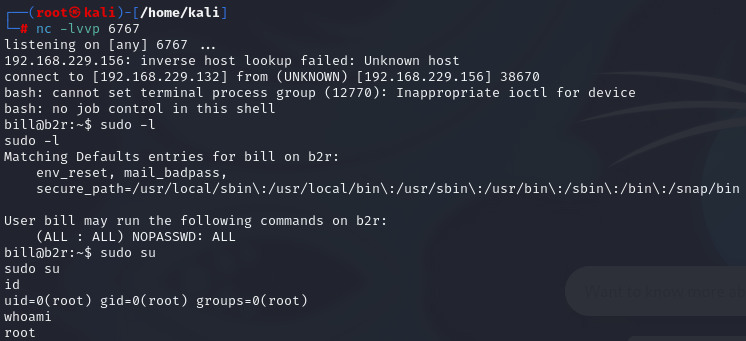
Depth靶机详解
靶机下载地址 https://www.vulnhub.com/entry/depth-1,213/ 主机发现 arp-scan -l 端口扫描 nmap -sV -A -T4 192.168.229.156 端口利用 http://192.168.229.156:8080/ 目录扫描 dirb "http://192.168.229.156:8080" dirsearch -u "http://192.168.229.15…...

go get -u @latest没有更新依赖模块
使用 go get -u gitee.com/qingfeng-169/hello-blatest 时,如果没有进行更新,可能有以下几种原因: 1. 没有发布稳定版本 (vX.X.X) latest 表示获取该模块最新的稳定版本(即带有 vX.X.X 形式的版本号),而不…...

介绍一些免费 的 html 5模版网站 和配色 网站
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、H5 网站介绍网站 二、配色网站个人推荐 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、H5 网站介绍 以下是一些提供免费…...

【C++】入门基础(下)
Hi!很高兴见到你~ 目录 7、引用 7.3 引用的使用(实例) 7.4 const引用 【第一分点】 【第二分点1】 【第二分点2】 7.5 指针和引用的关系(面试点) 8、inline 9、nullptr Relaxing Time! ———…...

Spring Boot 集成 MongoDB - 入门指南
引言 随着NoSQL数据库的流行,MongoDB 成为了许多现代Web应用程序的首选数据库之一。它提供了高性能、高可用性和易于扩展的能力。Spring Boot 框架以其开箱即用的理念简化了Java应用程序的开发过程。本文将指导您如何在Spring Boot项目中集成MongoDB,以…...

基于云计算的虚拟电厂负荷预测
基于云计算的虚拟电厂负荷预测 随着电网规模的扩大及新能源的不断应用,并网电网的安全性和经济性备受关注。 电网调度不再是单一或局部控制,而是采用智能网络集成方式调度 。 智能电网应具有以下特点:坚强自愈,可以抵御外来干扰甚…...

Android应用性能优化
Android手机由于其本身的后台机制和硬件特点,性能上一直被诟病,所以软件开发者对软件本身的性能优化就显得尤为重要;本文将对Android开发过程中性能优化的各个方面做一个回顾与总结。 Cache优化 ListView缓存: ListView中有一个回…...
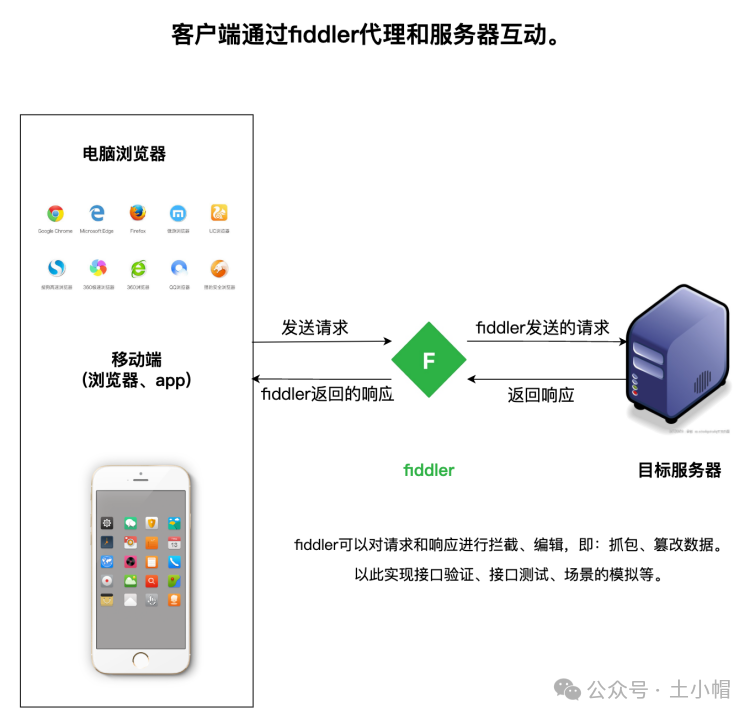
fiddler抓包01:工具介绍
课程大纲 fiddler是一款常见的抓包工具,可以对web端和移动端的接口请求进行抓包(截获)、分析、编辑、模拟等,还可以导出jmeter、Loadrunner测试脚本。 1、原理 fiddler作为代理服务器,拦截请求和服务器响应。 2、使用…...

Spring Boot母婴商城:打造一站式购物体验
1 绪论 1.1 研究背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这样的大环境让那些止步不前&#…...

【面试八股总结】GC垃圾回收机制
垃圾回收策略(Garbage Collection,GC)用于回收不再使用的内存,避免系统的内存被占满。Go1.3之前采用标记清除法, Go1.3之后采用三色标记法,Go1.8采用三色标记法混合写屏障。 前置概念: 1&#x…...

arcgisPro修改要素XY容差
1、在arcgisPro中XY容差的默认值为1个毫米,及0.001米。为了更精细的数据,需要提高这个精度,如何提高呢? 2、如果直接在数据库下新建要素类,容差只能调至0.0002米。所以,需要在数据库下新建要素数据集。 3…...

Java 21的Enhanced Deprecation的笔记
Java Core Libraries Enhanced Deprecation 废弃API,一般可以理解为不推荐开发者在项目中使用的API,当前为了保持兼容,在JDK中保留,未来可能会删除。 作为开发者,使用工具jdeprscan可以方便的查找现有代码中存在的一些…...

Ubuntu下Git使用教程:从入门到实践
引言 在软件开发和版本控制领域,Git无疑是最为流行的工具之一。它不仅能够帮助我们高效地管理代码,还能促进团队协作,确保项目的持续集成与交付。对于使用Ubuntu操作系统的开发者而言,掌握Git的使用技巧尤为重要。本文将带您一步…...

番茄小说下载器:打造个人离线图书馆的终极指南 [特殊字符]
番茄小说下载器:打造个人离线图书馆的终极指南 🍅 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 想要随时随地畅读番茄小说,不受网络限制&…...

STEP3-VL-10B一文详解:多模态对齐损失函数设计与人类反馈强化学习细节
STEP3-VL-10B一文详解:多模态对齐损失函数设计与人类反馈强化学习细节 1. 引言:为什么一个“小”模型能比肩“大”模型? 最近,一个只有100亿参数的“小”模型在技术圈里引起了不小的轰动。它就是阶跃星辰开源的STEP3-VL-10B。你…...

Qwen3-TTS使用避坑指南:新手常犯的5个错误及解决方法
Qwen3-TTS使用避坑指南:新手常犯的5个错误及解决方法 语音合成技术正在改变我们与数字世界的交互方式,而Qwen3-TTS-12Hz-1.7B-CustomVoice作为一款支持多语言的先进语音合成模型,为用户提供了丰富的语音风格选择。但在实际使用过程中&#x…...

Windows 11安装终极指南:5分钟绕过所有硬件限制
Windows 11安装终极指南:5分钟绕过所有硬件限制 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat 还在为Wind…...

从Harness工程视角深度解读Claude Code源码,AI编码Agent的工业级实现逻辑
2026年3月底,Anthropic旗下命令行编码Agent工具Claude Code,因npm发布包中的source map文件意外暴露存储在官方R2存储桶内的未混淆源码,让外界首次得以窥见工业级AI Agent系统的真实架构。这份超过51万行TypeScript代码的工程样本,…...

csp信奥赛c++之字符数组与字符串的区别
csp信奥赛c之字符数组与字符串的区别 一、字符数组与字符串的区别(详细讲解) 在C(尤其信奥赛CSP常用环境)中,“字符数组”和“字符串”通常指两种不同的数据类型或存储方式: 特性字符数组 (char[])字符串…...

3秒破解百度网盘提取码:告别资源获取困扰的智能解决方案
3秒破解百度网盘提取码:告别资源获取困扰的智能解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾经面对一个急需的学习资料或软件资源,却因为不知道百度网盘提取码而束手无策࿱…...

Elasticsearch面试八股整理
1. Elasticsearch 和 Lucene 是什么关系?这是高频第一问。你可以答:“Lucene 是底层全文检索库,负责倒排索引、分词、评分这些核心能力。Elasticsearch 是在Lucene 之上做的分布式封装,提供了集群、分片、副本、REST API、聚合分析…...

AI编程赋能研发效率:核心能力与实践经验总结
作为常年泡在代码里的开发者,想必大家都有过这样的体验:用AI插件补几行代码很快,但一到实际项目,环境配置、多任务并行、代码审查这些环节还是得靠人工一点点磨;不同的AI编程能力各有优势,切换适配却十分繁…...

2026年服装收银软件选型指南:五大功能决定门店提效与增长
很多服装门店都遇到过这样的困境:网络波动导致无法收款,眼睁睁看着顾客放下衣服离开;促销规则设置不到位,收银时算错优惠引发客诉;活动结束了,线上线下数据对不上,投入的钱看不到效果。这些问题…...