决策树基础概论
1. 概述
在机器学习领域,决策树(Decision Tree) 是一种高度直观且广泛应用的算法。它通过一系列简单的是/否问题,将复杂的决策过程分解为一棵树状结构,使得分类或回归问题的解决过程直观明了。决策树的最大特点在于可解释性强,每个决策节点都代表对特定特征的判断,最终根据这些判断得出结论。
决策树适用于多种任务,例如:垃圾邮件分类、病症诊断、股票价格预测等。不仅如此,它还可以处理连续变量和离散变量,并且无需对数据进行过多预处理,如标准化或归一化。
为了更好地理解决策树的结构,我们使用 Mermaid 图来表示一个简单的二分类决策树的工作流程:
在这个简单的决策树结构中:
- A 是根节点,表示根据第一个条件对数据进行划分。
- B 和 C 代表数据集在第一次判断后的两条路径。
- D, E, F 等表示进一步的划分,直到到达叶子节点,即最终的分类结果。
通过这样的树形结构,决策树逐步将问题细分,并通过一系列条件判断,将数据映射到相应的类别或回归值。本文将带领大家详细了解决策树的构建过程、优缺点、以及实际应用场景,并通过代码示例展示如何使用决策树解决实际问题。
2. 决策树的基本概念
决策树(Decision Tree)是一种树状结构,用于分类或回归问题。每一个内部节点代表一个特征或属性的判断条件,每一条边代表根据该特征划分数据的路径,最终的叶子节点代表分类结果或回归值。决策树通过递归地将数据集按特征划分成不同的子集,逐步逼近最终的目标。
决策树的基本构成:
- 根节点(Root Node): 决策树的起点,表示整个数据集。根节点基于某个特征进行第一次划分。
- 内部节点(Internal Nodes): 每个内部节点代表对某个特征进行一次判断,节点上的判断将数据划分为不同的子集。
- 叶子节点(Leaf Nodes): 叶子节点是决策树的终端节点,表示最终的分类或回归结果。
- 分支(Branches): 连接节点的路径,代表基于某个特征的取值,划分数据集的不同可能。
决策树的工作流程:
- 特征选择: 在决策树的构建过程中,算法会选择最能区分目标变量(类别或数值)的特征作为划分标准。
- 递归划分: 对每一层的数据集进行递归划分,直到满足停止条件(例如达到某个树的深度或所有数据属于同一个类)。
- 停止条件: 决策树会在一定条件下停止进一步划分,例如达到最大深度,或者某个叶子节点的数据不能再划分。
决策树的运行过程可以简单地总结为:
- 从根节点开始,根据某个特征对数据集进行第一次划分。
- 根据划分后的子集递归地选择新的特征,继续划分数据。
- 最终的叶子节点输出分类结果或回归值。
为了更好地理解决策树的工作流程,我们可以想象以下情境:
假设你在设计一个基于客户数据的分类器,目的是预测客户是否会购买某款产品。首先,你可能根据客户的年龄将数据划分为两组:年轻客户和年长客户。如果年轻客户购买的比例高,你会继续根据其他特征(如收入水平、职业等)进一步细分,直到能够得出客户是否会购买的预测结果。
决策树的类型:
- 分类决策树(Classification Tree): 用于解决分类问题。叶子节点表示某个类别,例如预测邮件是否是垃圾邮件。
- 回归决策树(Regression Tree): 用于解决回归问题,叶子节点表示一个连续数值,例如预测房价。
决策树示例:
在这个简单的示例中,决策树首先根据年龄划分,然后根据收入和婚姻状态进一步细分数据,最终预测客户是否会购买某产品。
通过这样的方式,决策树将数据一步步划分为更细的子集,直到找到最有可能的结果。
3. 决策树的构建过程
构建决策树的过程本质上是递归地将数据集划分为越来越小的子集,直到这些子集都属于同一个类别或满足其他停止条件。在每一步中,决策树会选择当前最优的特征进行划分,以便最大限度地减少分类的不确定性。
决策树的构建步骤:
-
特征选择:
每次划分数据集时,算法需要选择一个特征作为划分标准。这个特征应当是最能区分目标变量的特征。常用的特征选择指标包括:- 信息增益(Information Gain): 通过计算特征在划分数据集时减少了多少不确定性(熵),来选择最优特征。
- 基尼不纯度(Gini Impurity): 衡量数据集中混杂不同类别的程度,基尼不纯度越小,数据集越纯净。
- 方差减少(Variance Reduction): 在回归任务中,减少数据的方差是常见的目标。
-
递归划分:
一旦选择了某个特征进行划分,算法就会继续对每一个子集进行相同的操作,递归地选择特征并继续划分,直到满足停止条件。 -
停止条件:
决策树的构建是一个递归的过程,但不能无限递归下去,因此需要设置停止条件。常见的停止条件有:- 达到预设的树的最大深度。
- 每个叶子节点包含的数据点少于预设的最小数量。
- 数据集无法再被有效划分,即所有的数据点都属于同一个类别。
- 所有特征都已经使用完,无法继续划分。
-
生成叶子节点:
当递归划分停止后,数据集最终会被划分到叶子节点处。每个叶子节点要么代表一个类别(分类问题),要么是一个具体的数值(回归问题)。
特征选择的具体方法:
-
信息增益:
信息增益基于信息熵的概念。信息熵用于衡量数据集的纯度,熵越小,数据集的纯度越高。信息增益表示在使用某个特征划分数据集后,信息熵减少的程度。信息增益的计算公式为:信息增益 = 熵 ( S ) − ∑ i = 1 k ∣ S i ∣ ∣ S ∣ ⋅ 熵 ( S i ) \text{信息增益} = \text{熵}(S) - \sum_{i=1}^{k} \frac{|S_i|}{|S|} \cdot \text{熵}(S_i) 信息增益=熵(S)−i=1∑k∣S∣∣Si∣⋅熵(Si)
其中,( S ) 是当前的数据集,( S_i ) 是根据特征划分后的子集,( k ) 是子集的数量。 -
基尼不纯度:
基尼不纯度度量了数据集内的样本属于不同类别的概率。基尼不纯度的公式为:基尼不纯度 = 1 − ∑ i = 1 k p i 2 \text{基尼不纯度} = 1 - \sum_{i=1}^{k} p_i^2 基尼不纯度=1−i=1∑kpi2
其中,( p_i ) 是样本属于第 ( i ) 类的概率。
示例:
假设我们有以下数据集,需要根据“年龄”、“收入”等特征来预测某人是否会购买产品。我们可以逐步构建决策树,选择最能区分目标变量(购买与否)的特征。
-
选择特征:
- 根据“年龄”划分:
- 年龄 > 30 → 继续细分。
- 年龄 <= 30 → 分类为“不购买”。
- 根据“年龄”划分:
-
继续划分:
- 年龄 > 30 的群体根据“收入”进行划分:
- 收入 > 50K → 分类为“购买”。
- 收入 <= 50K → 分类为“不购买”。
- 年龄 > 30 的群体根据“收入”进行划分:
决策树示例:
在此示例中:
- 决策树首先根据年龄划分数据集,将年龄大于30岁和小于等于30岁的人群分开。
- 对于年龄大于30岁的人群,再根据收入进行进一步划分,判断他们是否会购买产品。
- 对于年龄小于等于30岁的人群,直接判断为“不购买”。
决策树的停止条件:
在实际应用中,为了避免过度拟合(即模型过于复杂、只适用于训练数据),我们可以设置停止条件来防止决策树过度生长。常用的策略包括:
- 限制决策树的最大深度。
- 设置叶子节点包含的最小样本数。
- 使用剪枝技术(后续部分会详细讨论)来减少树的复杂度。
决策树的构建是一种逐步细化的过程,随着数据集的划分,模型能够做出更为精确的预测。然而,过度细化可能会导致过拟合,因此合理的停止条件和剪枝策略是必要的。
在接下来的部分中,我们将详细讨论决策树的优缺点,以及如何在实际项目中应用决策树模型。
4. 决策树的优缺点
决策树是一种功能强大且直观的机器学习算法,它在很多场景下表现出色。然而,与任何算法一样,决策树也有其优点和缺点。理解这些特性可以帮助我们在合适的场景中选择决策树并应用正确的调整策略。
优点:
-
易于理解和解释:
决策树的树状结构与人类的决策过程非常相似,因此它非常容易理解。无论是对技术人员还是非技术人员,决策树的结构都很直观,可以清楚地展示决策步骤。- 每一个内部节点代表一个特征的判断,路径代表决策步骤,叶子节点表示最终的分类或回归结果。
- 比起黑箱模型(如神经网络),决策树是一个“白箱模型”,可以追踪每个预测结果的产生过程。
-
不需要大量的数据预处理:
决策树不需要对数据进行复杂的预处理步骤。它可以处理连续和离散的数据,不需要特征归一化或标准化处理,也能够处理缺失值。- 与其他需要特征缩放或标准化的算法(如支持向量机)相比,决策树对数据格式的要求较少,减少了数据预处理的工作量。
-
适用于分类和回归任务:
决策树可以用于处理分类(Classification)和回归(Regression)任务,这使得它在不同场景下都能应用。- 分类任务的示例:垃圾邮件分类、客户购买预测。
- 回归任务的示例:房价预测、销售预测。
-
能够处理多维特征数据:
决策树可以很好地处理具有多个特征的数据集,通过逐步细分数据,使得复杂的决策过程得以简化。 -
能够处理非线性关系:
决策树通过特征的分裂划分数据,可以有效捕捉数据中复杂的非线性关系。
缺点:
-
容易过拟合:
决策树容易在训练数据上表现得过于复杂,捕捉到数据中的噪声和异常值,导致在测试集上的表现不佳。这个问题被称为过拟合(Overfitting)。- 决策树会根据每个特征尽可能地细分数据,导致生成的树过于复杂。对于小的数据集或噪声较多的数据集,决策树可能生成过多的分支,使模型泛化能力降低。
解决方法:可以通过**剪枝(Pruning)**技术、限制树的深度或设定最小样本数来减少过拟合。
-
对数据的小变化敏感:
决策树对数据的敏感度较高,训练数据中的小变化可能导致树的结构发生较大改变。一个特征值的微小调整可能会改变整个树的划分过程,进而导致完全不同的分类结果。解决方法:集成学习方法,如随机森林(Random Forest),通过生成多个决策树来减少对单一数据集变化的敏感性。
-
偏向具有较多类别的特征:
决策树倾向于选择具有较多取值的特征作为划分依据,这可能导致一些重要的特征被忽略,尤其是在分类问题中。这种现象被称为**偏差(Bias)**问题。解决方法:使用信息增益比或基尼不纯度等指标进行特征选择,可以减少这种偏向。
-
模型容易变得过于复杂:
决策树的树结构随着数据集的复杂度增长,容易生成深度过大的树。这不仅导致过拟合,还可能增加训练和推理的时间成本。
决策树的改进方案:
-
剪枝(Pruning):
剪枝是减少过拟合的一种常见技术。剪枝可以通过两种方式进行:- 预剪枝(Pre-Pruning):在生成树的过程中提前限制树的深度或节点数量,从而避免过拟合。
- 后剪枝(Post-Pruning):先生成一棵完整的决策树,然后逐步剪除一些不必要的分支,简化模型。
-
随机森林(Random Forest):
随机森林是一种集成学习方法,它通过构建多个决策树,并对这些树的结果进行投票或平均,减少单棵树过拟合的风险,同时提高预测的准确性。 -
提升方法(Boosting):
提升方法(如梯度提升树,Gradient Boosting Decision Tree, GBDT)通过连续训练多个弱分类器(如决策树)来提升模型的性能。它可以有效地减少误差,并在许多任务中表现优异。
示例场景:
-
分类任务: 在电子商务中,决策树可以用于预测客户是否会购买某个产品。通过根据客户的年龄、购买历史、收入等特征进行划分,决策树可以逐步缩小目标客户的范围,得出预测结果。
-
回归任务: 在房价预测任务中,决策树可以基于房屋的面积、地段、装修等特征进行回归分析,预测房屋的市场价值。
决策树是一种功能强大且易于理解的模型,尤其在数据预处理要求较低的场景中具有明显的优势。然而,它的缺点也需要特别注意,尤其是过拟合和对数据敏感的问题。通过使用剪枝、随机森林等改进方法,我们可以有效地提升决策树的性能,使其在实际应用中表现更加稳健。
5. 决策树的实际应用
在实际项目中,决策树因其直观、易于实现以及较低的数据预处理要求,常常被用作解决分类和回归问题的首选模型之一。接下来,我们将介绍决策树的常见应用场景,并提供一个简单的代码示例,帮助你快速上手。
决策树的常见应用场景:
-
分类任务(Classification Tasks):
- 垃圾邮件检测:根据邮件的特征(如发件人、主题、内容关键词)来判断邮件是否为垃圾邮件。
- 客户购买预测:根据客户的年龄、收入、历史购买记录等信息,预测客户是否会购买某款产品。
- 医疗诊断:基于患者的症状、病史等特征,判断患者是否患有某种疾病。
- 信用风险评估:根据申请人的信用评分、收入、负债情况等,预测其是否有违约风险。
-
回归任务(Regression Tasks):
- 房价预测:根据房屋的面积、地段、装修等信息,预测房屋的市场价值。
- 销售预测:根据历史销售数据、节假日因素、促销活动等特征,预测未来某一时间段的销售额。
- 股票价格预测:通过历史价格、成交量、宏观经济数据等,预测未来股票价格。
-
其他领域:
- 图像分类:虽然深度学习在图像分类中表现更好,但在某些简单的场景中,决策树仍然可以用于根据图像的特征(如颜色、纹理)进行分类。
- 文本分析:决策树也可以应用于自然语言处理任务,如文本分类或情感分析。
决策树的代码示例:
接下来,我们通过 Python 中的 scikit-learn 库来演示如何使用决策树进行分类。我们将使用一个简单的鸢尾花(Iris)数据集,并构建一个决策树分类器来预测花的种类。
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 目标标签# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier()# 训练模型
clf.fit(X_train, y_train)# 使用模型进行预测
y_pred = clf.predict(X_test)# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy * 100:.2f}%")
在上述代码中:
- 我们使用了
scikit-learn提供的 鸢尾花数据集,该数据集包含 150 条记录,每条记录有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),目标是预测鸢尾花的三种不同种类。 - 使用
train_test_split函数将数据集划分为训练集(70%)和测试集(30%)。 - 创建了一个
DecisionTreeClassifier,并使用训练数据进行训练。 - 最后,通过模型对测试集进行预测,并计算模型的准确率。
实践中的注意事项:
-
调整参数:
决策树有许多可以调整的参数,例如树的最大深度(max_depth)、叶子节点的最小样本数(min_samples_leaf)等。通过调整这些参数,你可以控制决策树的复杂度,从而在过拟合和欠拟合之间找到平衡。- max_depth:限制决策树的深度可以防止过拟合。
- min_samples_split 和 min_samples_leaf:限制分裂节点和叶子节点的最小样本数,避免树过度复杂化。
-
交叉验证:
为了评估模型的稳健性,应该使用交叉验证技术。交叉验证可以帮助评估模型在不同训练数据集上的表现,确保其泛化能力。from sklearn.model_selection import cross_val_score scores = cross_val_score(clf, X, y, cv=5) print(f"5折交叉验证平均得分: {scores.mean():.2f}") -
特征的重要性:
决策树模型提供了特征的重要性评分,可以帮助你理解哪些特征对最终的分类或回归结果影响最大。import matplotlib.pyplot as plt feature_importances = clf.feature_importances_ plt.barh(iris.feature_names, feature_importances) plt.xlabel('特征重要性') plt.ylabel('特征') plt.title('决策树中特征的重要性') plt.show() -
可视化:
scikit-learn提供了简单的可视化工具来展示决策树的结构。通过绘制决策树,你可以更清晰地看到每个决策节点和叶子节点。from sklearn import tree import matplotlib.pyplot as pltplt.figure(figsize=(12, 8)) tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names) plt.show()这将生成一张决策树的可视化图,展示每个节点的特征和分类。
决策树作为一种简单且高效的算法,在实际项目中具有广泛的应用场景。从分类问题(如垃圾邮件分类、信用风险评估)到回归问题(如房价预测、销售预测),决策树都能够通过直观的树状结构来处理复杂的任务。
在实际应用中,我们可以通过调整模型参数、交叉验证以及结合集成方法(如随机森林)来提高决策树的性能,并避免常见的过拟合问题。在接下来的部分中,我们将讨论决策树的改进方法以及如何通过集成算法来增强模型的泛化能力。
6. 决策树的改进方法
尽管决策树在很多应用中表现良好,但它也有一些局限性,特别是在处理复杂或大规模数据集时。为了解决决策树的缺陷并提高其泛化能力,研究人员提出了多种改进方法,其中包括剪枝技术和集成学习(如随机森林和梯度提升树)。这些改进方法帮助决策树模型在保持可解释性的同时,提升了它的预测性能和稳健性。
6.1 剪枝技术(Pruning)
剪枝是防止决策树过拟合的一种常用方法。决策树容易生成过深的树结构,从而学习到数据中的噪声。剪枝通过限制树的复杂度,减少不必要的分支,从而提高模型的泛化能力。剪枝通常分为两类:
-
预剪枝(Pre-Pruning):
- 预剪枝是在决策树的构建过程中,通过提前设置停止条件来避免树结构过于复杂。
- 例如,通过限制树的最大深度(
max_depth)、叶子节点的最小样本数(min_samples_leaf)或划分节点的最小样本数(min_samples_split)来控制树的增长。
示例:
clf = DecisionTreeClassifier(max_depth=3, min_samples_split=4, min_samples_leaf=2) clf.fit(X_train, y_train) -
后剪枝(Post-Pruning):
- 后剪枝是在生成完整的决策树后,移除一些不必要的分支,使模型更加简化。这个过程通常通过对子树进行评估,移除那些对最终预测贡献较小的分支。
- 后剪枝通常较为复杂,因为需要在生成完决策树后对其各个部分进行评估,确保减少的分支不会对模型性能造成过大影响。
6.2 集成方法(Ensemble Methods)
集成学习方法通过结合多个弱模型的预测结果,来提高模型的准确性和稳健性。对于决策树来说,集成学习方法可以有效地解决单一决策树容易过拟合和对数据变化敏感的问题。
-
随机森林(Random Forest):
- 随机森林是一种将多棵决策树集成在一起的算法。通过对数据集的不同子集构建多棵决策树,然后对它们的结果进行投票或平均,随机森林能够显著提高模型的准确性并减少过拟合的风险。
- 随机森林的关键在于每棵决策树都在一个不同的随机子集上进行训练,并且在每次分裂节点时随机选择特征,这样可以防止决策树对某些特征的过度依赖。
示例:
from sklearn.ensemble import RandomForestClassifierclf_rf = RandomForestClassifier(n_estimators=100, random_state=42) clf_rf.fit(X_train, y_train) y_pred_rf = clf_rf.predict(X_test)- 优点:通过集成多棵决策树,随机森林能够减少单一决策树过拟合的问题,并提高模型的泛化能力。
- 缺点:随机森林虽然提高了模型性能,但在一些极端情况下,它的预测结果可能不如一些更复杂的模型,如梯度提升树。
-
梯度提升树(Gradient Boosting Decision Tree, GBDT):
- 梯度提升树是一种集成方法,通过连续训练多个弱分类器(通常是决策树)来提高模型的性能。每棵新树的训练目标是修正前一棵树的错误,从而逐步提升模型的预测能力。
- 常见的实现包括 XGBoost、LightGBM 和 CatBoost,它们在实际应用中表现非常优异,尤其是在结构化数据上。
示例:
from sklearn.ensemble import GradientBoostingClassifierclf_gbdt = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42) clf_gbdt.fit(X_train, y_train) y_pred_gbdt = clf_gbdt.predict(X_test)- 优点:梯度提升树能够处理复杂的非线性关系,并且通常比单一决策树或随机森林表现更好。
- 缺点:相比随机森林,梯度提升树的训练时间较长,且对参数调优较为敏感。
-
极端随机树(Extra Trees, Extremely Randomized Trees):
- 极端随机树是随机森林的变种,它通过在构建树的过程中增加随机性来减少模型的方差。与随机森林不同,极端随机树在每次划分时不仅随机选择特征,还随机选择分裂点。
示例:
from sklearn.ensemble import ExtraTreesClassifierclf_et = ExtraTreesClassifier(n_estimators=100, random_state=42) clf_et.fit(X_train, y_train) y_pred_et = clf_et.predict(X_test)- 优点:比随机森林更快,随机性更强。
- 缺点:由于随机性增加,极端随机树可能在某些情况下表现不如传统的随机森林。
6.3 模型调优与参数调整
在使用决策树或集成方法时,合理地调整模型的参数可以显著提高模型的性能。常见的参数调整方法包括:
- 网格搜索(Grid Search):通过穷举多个参数组合,找到表现最好的参数。
- 随机搜索(Random Search):在参数空间中随机抽样,找到可能的最佳参数组合。
示例:
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'max_depth': [3, 5, 10],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 5]
}# 使用 GridSearchCV 进行参数调优
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)print(f"最佳参数: {grid_search.best_params_}")
6.4 使用特征重要性进行特征选择
决策树模型提供了特征重要性评分,可以帮助我们理解哪些特征对分类或回归结果影响最大。通过分析这些特征的重要性,数据科学家可以减少特征维度,提升模型的效率。
import matplotlib.pyplot as plt# 绘制特征重要性图
feature_importances = clf.feature_importances_
plt.barh(iris.feature_names, feature_importances)
plt.xlabel('特征重要性')
plt.ylabel('特征')
plt.title('决策树中特征的重要性')
plt.show()
决策树虽然简单且直观,但其原始模型容易过拟合且对数据变化敏感。通过剪枝技术和集成方法(如随机森林和梯度提升树),我们可以显著提升模型的泛化能力和准确性。此外,通过合理的参数调优和特征选择,可以进一步优化决策树的性能。
在接下来的部分中,我们将总结决策树的整体应用,并提供一些最终的建议,以帮助你在实际项目中有效地使用这一强大的工具。
7. 总结与展望
决策树是一种功能强大、直观且易于理解的机器学习算法,在分类和回归任务中表现出色。通过其层层递进的决策方式,决策树能够将复杂的决策过程分解为简单的二分判断,并通过树状结构将数据划分为更细的子集,从而完成分类或回归预测。
7.1 回顾决策树的核心要点:
-
易于理解和解释:
决策树的树状结构非常直观,易于解释。它模仿了人类的决策过程,通过每个特征进行逐步划分,最终达到分类或回归的结果。 -
不需要过多的数据预处理:
决策树不需要标准化、归一化等复杂的数据预处理步骤,能够处理连续和离散数据,甚至应对缺失值。 -
适用于多种任务:
决策树不仅可以用于分类任务(如垃圾邮件分类、医疗诊断等),也能很好地用于回归任务(如房价预测、销售预测等)。 -
过拟合问题:
虽然决策树模型在很多场景下表现优异,但它容易出现过拟合问题,尤其在训练数据噪声较大时。通过剪枝和限制树的深度等技术,我们可以控制决策树的复杂度,从而减少过拟合。 -
对数据的小变化敏感:
决策树对训练数据的变化非常敏感,可能因为小的变动而生成完全不同的树。为了解决这一问题,集成方法如随机森林和梯度提升树可以有效提高模型的稳定性和预测性能。
7.2 未来的展望:
-
集成学习方法的持续发展:
随着数据规模和复杂度的增加,单一决策树模型的局限性逐渐显现。未来,集成学习方法(如随机森林、梯度提升树等)将会越来越广泛地应用于实际问题中。这些方法通过结合多个弱学习器(如决策树),显著提高了模型的稳定性和准确性。 -
自动化机器学习(AutoML)的普及:
自动化机器学习(AutoML)工具的不断发展将会推动决策树及其变种在不同领域的应用。AutoML 可以帮助数据科学家自动选择模型、调整参数,简化机器学习模型的构建过程,从而提升开发效率。 -
深度学习与决策树的结合:
尽管决策树和深度学习模型有不同的应用场景,未来可能会有更多研究尝试将两者结合。例如,通过在深度神经网络中嵌入决策树的结构,使得模型既能具备深度学习的强大拟合能力,又能保持决策树的可解释性。 -
应用场景的扩展:
决策树和集成模型不仅在经典的分类和回归问题中表现出色,在未来,它们也将在更多领域展现其价值。例如,随着数据隐私和安全问题的日益重要,决策树的可解释性使其在金融、医疗和法律等对解释性要求较高的领域有着广阔的应用前景。
7.3 最后的建议:
-
根据问题选择合适的模型:如果任务需要高度解释性,且数据集相对简单,决策树是一个非常好的选择。如果数据集较大且复杂,考虑使用随机森林或梯度提升树等集成方法。
-
避免过拟合:通过剪枝或限制决策树深度等方式,控制树的复杂度,以减少过拟合的风险。
-
结合其他算法:在项目中,可以尝试将决策树与其他模型(如支持向量机、神经网络等)结合,使用集成方法或混合模型提升预测性能。
7.4 总结:
决策树作为一种经典的机器学习算法,尽管其本身存在一些局限性,但通过剪枝和集成方法等改进,可以在多个任务中实现优异的表现。无论是分类、回归还是特征选择,决策树及其衍生模型(如随机森林、梯度提升树)都在实际项目中得到了广泛应用。
未来,随着集成学习、深度学习和自动化机器学习技术的进步,决策树将在更多复杂应用场景中发挥更大的作用。如果你对数据建模和算法解释有需求,决策树无疑是一个强大且易于使用的工具。
8. 参考文献与资源
在学习和应用决策树的过程中,了解相关的理论背景和实践技巧至关重要。以下是一些推荐的参考文献和资源,能够帮助你深入理解决策树以及相关的集成方法。
8.1 书籍推荐:
-
《统计学习方法》 - 李航
这本书详细介绍了包括决策树在内的多种机器学习算法,提供了理论基础和实际应用案例,适合有一定数学基础的读者。 -
《机器学习》 - 周志华
该书系统地介绍了机器学习的基础理论、典型算法和技术实现,特别是在集成学习、决策树等主题上有深入讨论。 -
《Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow》 - Aurélien Géron
这是一本非常实用的机器学习指南,适合使用 Python 和 Scikit-Learn 的初学者,其中包括决策树和随机森林的详细实现。 -
《Pattern Recognition and Machine Learning》 - Christopher M. Bishop
本书是机器学习领域的经典教材,涉及决策树的数学背景、算法推导以及与其他模型的比较分析。
8.2 在线教程与文档:
-
Scikit-learn Documentation on Decision Trees
官方文档详细说明了如何使用DecisionTreeClassifier和DecisionTreeRegressor,并附有大量示例代码。
Scikit-learn Documentation -
Kaggle 学习平台
Kaggle 提供了多种机器学习任务的决策树教程和竞赛,可以帮助你通过实际项目掌握算法的应用技巧。
Kaggle Learn -
Coursera - Machine Learning by Andrew Ng
这是斯坦福大学开设的经典机器学习课程,课程中包含了决策树的应用以及集成方法的介绍。
Coursera - Machine Learning -
Google Machine Learning Crash Course
Google 提供的机器学习速成课程,涵盖了决策树、随机森林和其他基础算法的应用。
Google ML Crash Course
8.3 开源库与工具:
-
Scikit-learn
Scikit-learn 是一个广泛使用的 Python 机器学习库,提供了非常简单易用的 API 来实现决策树、随机森林、梯度提升等多种算法。
Scikit-learn GitHub -
XGBoost
XGBoost 是实现梯度提升树的高效库,常用于竞赛和实际项目中。它具备出色的性能和灵活性,能够处理大规模数据。
XGBoost GitHub -
LightGBM
LightGBM 是微软开发的另一个高效的梯度提升框架,针对大数据和高维数据进行了优化。
LightGBM GitHub -
CatBoost
CatBoost 是 Yandex 开发的一种特别适用于分类和回归问题的梯度提升工具,特别是在处理类别特征上表现优异。
CatBoost GitHub
8.4 学术论文:
-
Quinlan, J. R. (1986). Induction of Decision Trees.
这篇论文是决策树算法的奠基作之一,详细介绍了 ID3 算法的理论基础与实践应用。- 链接:Induction of Decision Trees
-
Breiman, L. (2001). Random Forests.
Breiman 的随机森林论文详细阐述了集成方法的理论基础,是理解随机森林算法的核心文献。- 链接:Random Forests Paper
-
Friedman, J., Hastie, T., & Tibshirani, R. (2000). Additive Logistic Regression: A Statistical View of Boosting.
这篇论文阐述了梯度提升树(GBDT)的数学理论,是理解该算法的重要参考文献。- 链接:A Statistical View of Boosting
通过这些参考文献和资源,您将能够进一步深入理解决策树的理论和应用,并且在不同的项目中有效地利用这些知识提升机器学习模型的表现。
相关文章:

决策树基础概论
1. 概述 在机器学习领域,决策树(Decision Tree) 是一种高度直观且广泛应用的算法。它通过一系列简单的是/否问题,将复杂的决策过程分解为一棵树状结构,使得分类或回归问题的解决过程直观明了。决策树的最大特点在于可…...
Spring Boot集成Akka Cluster快速入门Demo
1.什么是Akka Cluster? Akka Cluster将多个JVM连接整合在一起,实现消息地址的透明化和统一化使用管理,集成一体化的消息驱动系统。最终目的是将一个大型程序分割成若干子程序,部署到很多JVM上去实现程序的分布式并行运算…...

django学习入门系列之第十点《A 案例: 员工管理系统10》
文章目录 12 管理员操作12.4 密码加密12.5 获取对象(防止id错误--编辑界面等)12.6 编辑管理员12.7 重置密码 往期回顾 12 管理员操作 12.4 密码加密 密码不应该以明文的方式直接存储到数据库,应该加密才放进去 定义一个md5的方法ÿ…...

Unity实战案例全解析:PVZ 植物卡片状态分析
Siki学院2023的PVZ免费了,学一下也坏 卡片状态 卡片可以有三种状态: 1.阳光足够,(且cd好了可以种植) 2.阳光不够,(cd?好了:没好 (三目运算符)&…...

判断变量是否为有限数字(非无穷大或NaN)math.isfinite() 判断变量是否为无穷大(正无穷大或负无穷大)math.isinf()
【小白从小学Python、C、Java】 【考研初试复试毕业设计】 【Python基础AI数据分析】 判断变量是否为有限数字(非无穷大或NaN) math.isfinite() 判断变量是否为无穷大(正无穷大或负无穷大) math.isinf() 请问关于以下代码表述错误…...

idea使用阿里云服务器运行jar包
说明:因为我用的阿里云服务器不是自己的,所以一些具体的操作可能不太全面。看到一个很完整的教程,供参考。 0. 打包项目 这里使用的是maven打包。 在pom.xml中添加以下模块。 <build><plugins><plugin><groupId>org…...

解决nginx代理SSE接口的响应没有流式返回
目录 现象原来的nginx配置解决 现象 前后端分离的项目,前端访问被nginx反向代理的后端SSE接口,预期是流式返回,但经常是很久不响应,一响应全部结果一下子都返回了。查看后端项目的日志,响应其实是流式产生的。推测是n…...
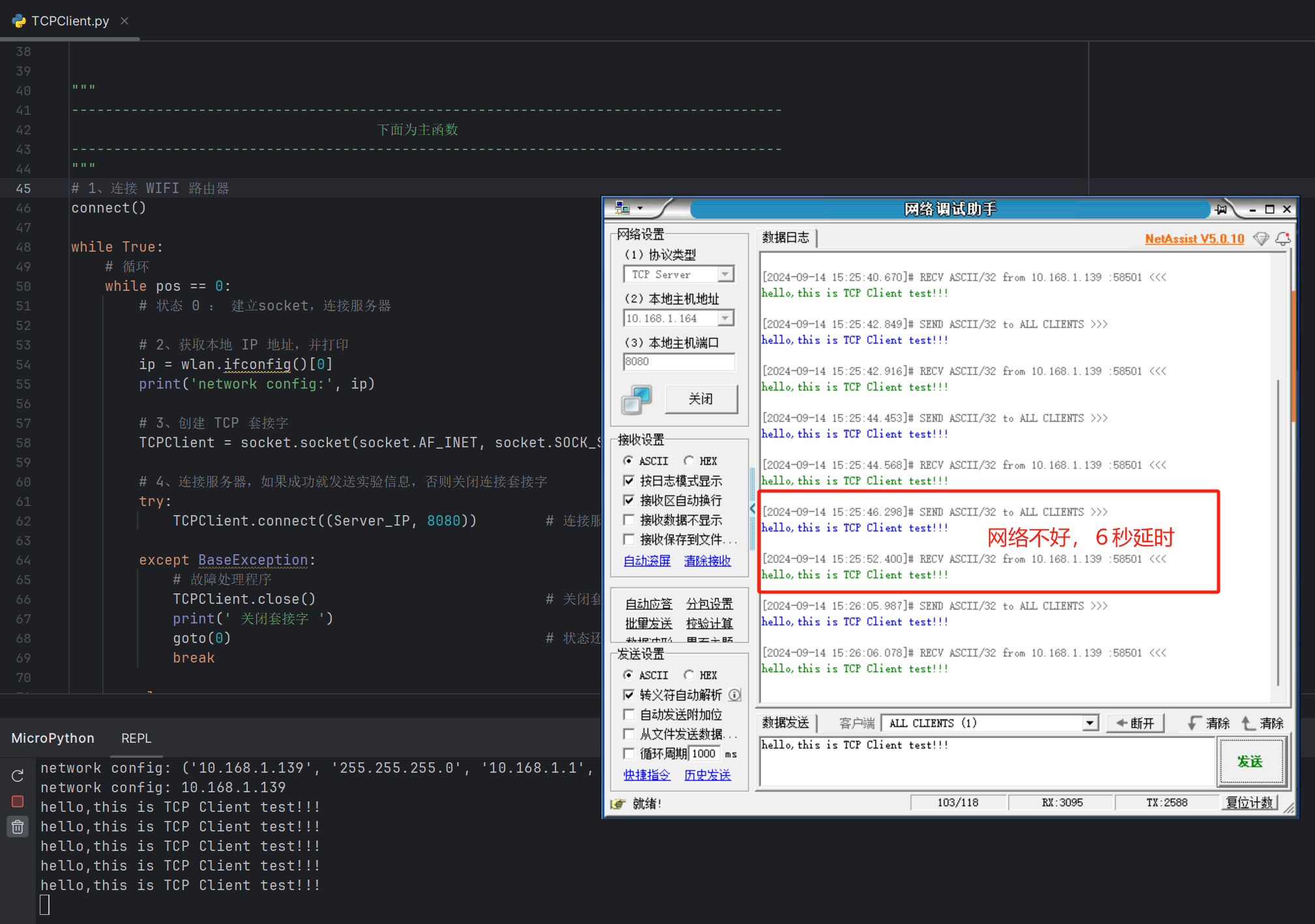
11 - TCPClient实验
在上一个章节的UDP通信测试中,尽管通信的实现过程相对简洁,但出现了通信数据丢包的问题。因此,本章节将基于之前建立的WIFI网络连接,构建一个基础的TCPClient连接机制。我们利用网络调试助手工具来发送数据,测试网络通…...

React框架搭建,看这一篇就够了,看完你会感谢我
传统搭建框架的方式 在2024年以前,我们构建框架基本上采用官方脚手架,但是官方脚手架其实大概率都不符合我们的项目要求,搭建完了以后往往需要再继续集成一些第三方的包。这时候又会碰到一些版本冲突,配置教程等,往往…...

【rust】rust条件编译
在c语言中,条件编译是一个非常好用的功能,那么rust中如何实现条件编译呢? rust的条件编译需要两个部分,一个是fratures,另一个是cfg。Cargo feature是一个非常强大的功能,可以提供条件编译和可选依赖项的高级特性&…...

一键文本提示实现图像对象高质量剪切与透明背景生成
按照提示词裁剪 按照边框裁剪 要实现您描述的功能,即通过一个文本提示就能自动从图片中切割出指定的对象并生成一个带有透明背景的新图像,这需要一个结合了先进的计算机视觉技术和自然语言处理能力的系统。这样的系统可以理解输入的文本指令,并将其转化为对图像内容的精确分…...
游戏客服精华回复快捷语大全
以黑神话悟空为代表的国内的游戏行业,最近发展非常迅猛,大量游戏玩家需要足够的游戏客服支持,这里整理了游戏客服精华回复快捷语,涵盖了接待客户,游戏级数,游戏外挂,游戏要求,游戏特…...

国内版Microsoft Teams 基础版部署方案
目录 前言Microsoft Teams简介部署前的准备 环境需求账户和许可网络要求部署步骤 初步配置和设置安装Microsoft Teams客户端Teams管理中心配置用户管理 用户添加与分配角色与权限管理通讯与协作 团队和频道管理即时消息和会议功能文件共享与协作安全性与合规性 数据保护措施合规…...

计算机网络 ---- OSI参考模型TCP/IP模型
目录 一、OSI参考模型 1.1 学习路线 1.2 OSI参考模型和TCP/IP模型 1.3 具体设备与具体层次对应关系 1.3.1 物理层 1.3.2 数据链路层 1.3.3 网络层 1.3.4 传输层 1.3.5 会话层、表示层、应用层 1.4 各层次数据传输单位 二、TCP/IP模型 2.1 学习路线 2.2 TCP/I…...

在Windows环境下部署Java的Web项目集成工具的整体流程和详细步骤
好的,以下是一份关于“Windows环境下部署Java的Web项目集成工具”的手把手操作流程,由浅入深,先整体后分部: 一、引言 在现代软件开发中,Java作为一种广泛应用的编程语言,其Web项目开发尤为常见。为了提高…...

9.18作业
提示并输入一个字符串,统计该字符串中字母、数字、空格、其他字符的个数并输出 代码展示 #include <iostream>using namespace std;int main() {string str;int countc 0; // 字母计数int countn 0; // 数字计数int count 0; // 空格计数int counto 0;…...

【算法】滑动窗口—最小覆盖子串
题目 ”最小覆盖子串“问题,难度为Hard,题目如下: 给你两个字符串 S 和 T,请你在 S 中找到包含 T 中全部字母的最短子串。如果 S 中没有这样一个子串,则算法返回空串,如果存在这样一个子串,则可…...

“Fast-forward“ in git-pull result
当你执行 git pull 并且结果显示 Fast-forward 时,这意味着你的本地分支可以直接快进到远程分支的最新提交,没有任何冲突或者需要合并的内容。具体来说,Fast-forward 是一种合并方式,它的特点是将当前分支的指针直接移动到远程分支…...
如何创建表空间(Tablespace)?)
Oracle(133)如何创建表空间(Tablespace)?
在Oracle数据库中,表空间(Tablespace)是存储数据的逻辑单位,它由一个或多个数据文件组成。表空间是数据库数据管理的基本结构,了解如何创建表空间对于数据库管理员至关重要。 创建表空间的基本语法 创建表空间的基本…...

Linux中权限和指令
💥1、Linux基本指令 1.1 mv 指令 mv指令是move的缩写,用来移动或重命名文件、目录,经常用来备份文件或目录。 mv old_name new_name: 重命名文件或目录mv file /path/to/directory: 移动文件到指定目录 roothcss-ecs…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...