人力资源数据集分析(二)_随机森林与逻辑回归
数据入口:人力资源分析数据集 - Heywhale.com
数据说明
| 字段 | 说明 |
|---|---|
| EmpID | 唯一的员工ID |
| Age | 年龄 |
| AgeGroup | 年龄组 |
| Attrition | 是否离职 |
| BusinessTravel | 出差:很少、频繁、不出差 |
| DailyRate | 日薪 |
| Department | 任职部门:研发部门、销售部门、人力资源部门 |
| DistanceFromHome | 通勤距离 |
| Education | 教育等级 |
| EducationField | 专业领域:生命科学、医学、市场营销、技术、其他 |
| EnvironmentSatisfaction | 工作环境满意度 |
| Gender | 性别 |
| HourlyRate | 时薪 |
| JobInvolvement | 工作参与度 |
| JobLevel | 工作级别 |
| JobRole | 工作角色 |
| JobSatisfaction | 工作满意度 |
| MaritalStatus | 婚姻状况 |
| MonthlyIncome | 月收入 |
| SalarySlab | 工资单 |
| MonthlyRate | 月薪 |
| NumCompaniesWorked | 工作过的公司数量 |
| PercentSalaryHike | 加薪百分比 |
| PerformanceRating | 绩效评级 |
| RelationshipSatisfaction | 关系满意度 |
| StandardHours | 标准工时 |
| StockOptionLevel | 股票期权级别 |
| TotalWorkingYears | 总工作年数 |
| TrainingTimesLastYear | 去年培训时间 |
| WorkLifeBalance | 工作生活平衡评价 |
| YearsAtCompany | 在公司工作年数 |
| YearsInCurrentRole | 担任现职年数 |
| YearsSinceLastPromotion | 上次晋升后的年数 |
| YearsWithCurrManager | 与现任经理共事年数 |
import pandas as pd
data = 'HR_Analytics.csv'
data = pd.read_csv(file_path)
# 打印每一列的唯一值
for column in data.columns:print(f"Unique values in {column}:")print(data[column].unique())通过这段代码可以了解每一列的唯一值。观察到某些列含有缺失值且缺失值的行数较少,可以直接删去。
data_cleaned = data.dropna()
本文将通过随机森林与逻辑回归预测员工晋升路径和潜在的流失风险。
一:预测员工晋升路径
- 数据理解:首先,需要查看CSV文件的内容,以了解数据的结构和可用特征。这将帮助确定哪些特征可能与员工晋升路径相关。
- 数据预处理:基于数据理解,可能需要进行数据清洗,处理缺失值,转换分类数据,以及进行特征选择。
- 模型选择:选择一个合适的机器学习模型来预测员工晋升路径。考虑到这是一个分类问题,逻辑回归、决策树或随机森林等模型可能适用。
- 模型训练与评估:使用历史数据训练模型,并使用适当的评估指标(如准确率、召回率、F1分数)来评估模型性能。
- 结果解释:最后,我将解释模型结果,并提供关于员工晋升路径的预测。
首先检查数据集中的分类特征,以便进行适当的编码:
categorical_features = data.select_dtypes(include=['object', 'category']).columns.tolist()categorical_features数据集中有多个分类特征,包括员工ID、年龄组、离职情况、出差频率、部门、教育领域、性别、工作角色、婚姻状况和薪资等级。为了在机器学习模型中使用这些特征,我们需要对它们进行编码。常见的编码方法包括独热编码(One-Hot Encoding)和标签编码(Label Encoding)。独热编码适用于具有多个类别且类别之间没有顺序关系的特征,而标签编码适用于具有顺序关系的特征。
接下来,我将使用独热编码处理具有多个类别的分类特征。然后,我将选择与员工晋升路径相关的特征,并准备数据集以进行模型训练。
data_encoded = pd.get_dummies(data, columns=categorical_features, drop_first=True)data_encoded.head()数据集经过独热编码后,现在包含了1522个特征。这个特征数量对于建立一个有效的机器学习模型来说可能太多了,可能会导致过拟合。因此,我们需要进行特征选择,只保留与员工晋升路径最相关的特征。
为了选择相关特征,我们可以使用不同的特征选择方法,例如基于模型的特征选择(如使用随机森林的特征重要性)或使用统计测试(如卡方检验)来选择与目标变量最相关的特征。在这个案例中,我们的目标变量是员工是否晋升,这需要我们首先定义晋升的标准。例如,我们可以根据员工的工作等级(JobLevel)是否增加来定义晋升。
接下来,我将定义晋升的标准,并使用随机森林模型来确定哪些特征与晋升最相关。然后,我将选择这些特征来训练模型。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import numpy as npdata_encoded['Promotion'] = np.where(data_encoded['JobLevel'] > data_encoded['JobLevel'].shift(-1), 1, 0)data_encoded.dropna(subset=['Promotion'], inplace=True)relevant_features = ['Education', 'TotalWorkingYears', 'TrainingTimesLastYear','YearsAtCompany', 'YearsInCurrentRole', 'YearsSinceLastPromotion','YearsWithCurrManager'
]features = data_encoded[relevant_features]
target = data_encoded['Promotion']X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)rf_classifier.fit(X_train, y_train)y_pred = rf_classifier.predict(X_test)accuracy = accuracy_score(y_test, y_pred)accuracy, classification_report(y_test, y_pred)使用随机森林模型,我们得到了大约70%的准确率,可以使用该随机森林模型对数据进行预测。
此外,从分类报告中我们可以看到,模型在预测晋升(标签1)方面的召回率较低,这意味着它可能没有很好地识别出所有晋升的案例。这可能是因为晋升事件相对较少,导致数据集不平衡。在未来的工作中,可以考虑使用过采样或欠采样技术来处理这种不平衡,或者使用不同的评估指标,如F1分数,来更好地衡量模型性能。
二:预测员工流失风险
1:判断特征重要性
首先进行一些基本的特征工程,例如从现有特征中创建新的特征。
categorical_features = ['EmpID', 'AgeGroup', 'Attrition', 'BusinessTravel', 'Department', 'EducationField', 'Gender', 'JobRole', 'MaritalStatus', 'SalarySlab']
data[categorical_features] = data[categorical_features].astype('category')data_types_updated = data.dtypesdata['Experience'] = data['TotalWorkingYears'] - data['YearsAtCompany']data_types_updated, data['Experience'].head()
我已经将分类特征转换为正确的数据类型,并创建了一个新的特征Experience,它表示员工的总工作经验减去在当前公司的年数。
接下来,将进行特征选择,确定哪些特征对于预测流失风险最为重要。这可以通过多种方法来完成,例如使用相关性分析、基于模型的特征重要性等。在这里,我将使用随机森林模型的特征重要性来选择特征。
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import matplotlib.pyplot as pltX = data.drop(['EmpID', 'Attrition'], axis=1)
y = data['Attrition']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)le = LabelEncoder()for feature in categorical_features:if feature != 'Attrition': data[feature] = le.fit_transform(data[feature])X = data.drop(['EmpID', 'Attrition'], axis=1)
y = data['Attrition']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)rf_clf.fit(X_train, y_train)feature_importances = rf_clf.feature_importances_feature_importances_df = pd.DataFrame({'Feature': X_train.columns, 'Importance': feature_importances})feature_importances_sorted = feature_importances_df.sort_values(by='Importance', ascending=False)top_features = feature_importances_sorted.head(10)plt.figure(figsize=(12, 8))
plt.barh(top_features['Feature'], top_features['Importance'], color='skyblue')
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Top 10 Most Important Features for Attrition Prediction')
plt.gca().invert_yaxis()
plt.show()top_features
根据随机森林模型的特征重要性,我们可以看到
MonthlyIncome(月收入)是预测员工流失风险最重要的特征,其次是Age(年龄)、DailyRate(日薪)、MonthlyRate(月薪)等。这些特征对于预测员工是否流失具有显著的影响。接下来,我将使用这些特征来训练一个逻辑回归模型,并评估其在测试集上的性能。逻辑回归是一种常用的分类算法,特别适用于二元分类问题。
这段代码是一个使用Python语言和scikit-learn库进行数据预处理、模型训练、特征重要性评估和可视化的完整流程。以下是这段代码的详细解释:
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import matplotlib.pyplot as plt
import pandas as pd
LabelEncoder用于将分类特征转换为数值型数据。RandomForestClassifier是随机森林分类器,用于分类任务。train_test_split用于将数据集分割为训练集和测试集。classification_report和accuracy_score用于评估模型的性能。matplotlib.pyplot用于数据可视化。
X = data.drop(['EmpID', 'Attrition'], axis=1)
y = data['Attrition']
- 这部分代码从数据集中移除了不需要的列(例如员工ID和目标变量),并将剩余的数据作为特征集(X)和目标变量(y)。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- 使用
train_test_split函数将数据集分割为训练集和测试集,其中测试集占总数据的20%,random_state确保结果的可重复性。
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)le = LabelEncoder()
- 初始化一个随机森林分类器,其中包含100棵树。
- 初始化一个
LabelEncoder实例。
for feature in categorical_features:if feature != 'Attrition': data[feature] = le.fit_transform(data[feature])
- 遍历分类特征列表,使用
LabelEncoder对每个特征进行编码,排除目标变量。
X = data.drop(['EmpID', 'Attrition'], axis=1)
y = data['Attrition']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- 由于数据已经经过编码处理,再次执行特征和目标变量的分割以及训练集和测试集的分割。
rf_clf.fit(X_train, y_train)
- 使用训练集数据训练随机森林分类器。
feature_importances = rf_clf.feature_importances_feature_importances_df = pd.DataFrame({'Feature': X_train.columns, 'Importance': feature_importances})feature_importances_sorted = feature_importances_df.sort_values(by='Importance', ascending=False)top_features = feature_importances_sorted.head(10)
- 从训练好的模型中获取特征重要性。
- 创建一个DataFrame来存储特征和它们的重要性。
- 按照特征重要性对DataFrame进行排序。
- 显示最重要的前10个特征。
plt.figure(figsize=(12, 8))
plt.barh(top_features['Feature'], top_features['Importance'], color='skyblue')
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Top 10 Most Important Features for Attrition Prediction')
plt.gca().invert_yaxis()
plt.show()
- 使用条形图可视化最重要的前10个特征。
- 设置图表的大小、颜色、标签和标题。
- 反转y轴,使得最重要的特征在上方。
top_features
- 显示排序后的特征重要性DataFrame的前10行。
2:建立逻辑回归预测模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_auc_scorelog_clf = LogisticRegression(random_state=42)log_clf.fit(X_train, y_train)y_pred = log_clf.predict(X_test)accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
roc_auc = roc_auc_score(y_test, log_clf.predict_proba(X_test)[:, 1])accuracy, conf_matrix, roc_auc逻辑回归模型在测试集上的准确率为83.16%,混淆矩阵显示有48个实际流失的样本被错误地预测为未流失。模型的ROC AUC得分为0.709,这意味着模型在区分流失和非流失员工方面的性能是中等偏上。可以利用该逻辑回归根据员工数据预测员工是否流失。
注:roc_auc_score(y_test, log_clf.predict_proba(X_test)[:, 1]):
roc_auc_score是一个用于计算接收者操作特征曲线下面积(Receiver Operating Characteristic Area Under the Curve,简称 ROC AUC)的函数。ROC AUC 是一种衡量二分类模型性能的指标,它的值介于 0.5(随机猜测)和 1(完美分类)之间,值越接近 1 表示模型性能越好。
y_test是真实的测试集目标变量值,通常是 0 和 1 表示的二分类结果。
log_clf.predict_proba(X_test)是使用已经训练好的分类器(这里假设log_clf是一个逻辑回归分类器)对测试集X_test进行预测,得到的是一个概率矩阵,其中每一行表示一个样本属于不同类别的概率。
[:, 1]表示取这个概率矩阵的第二列,通常对应着正类(1)的概率预测值。整体而言,这段代码是计算使用逻辑回归分类器对测试集进行预测得到的正类概率与真实的测试集目标变量之间的 ROC AUC 值,以评估该分类器在测试集上的性能表现。
想要探索多元化的数据分析视角,可以关注之前发布的相关内容。
相关文章:
人力资源数据集分析(二)_随机森林与逻辑回归
数据入口:人力资源分析数据集 - Heywhale.com 数据说明 字段说明EmpID唯一的员工IDAge年龄AgeGroup年龄组Attrition是否离职BusinessTravel出差:很少、频繁、不出差DailyRate日薪Department任职部门:研发部门、销售部门、人力资源部门Dista…...

【30天玩转python】数据库操作
数据库操作 数据库是应用程序中用于存储和管理数据的核心组件。Python 提供了多种与数据库交互的方式,支持不同类型的数据库,包括关系型数据库(如 MySQL、PostgreSQL)和 NoSQL 数据库(如 MongoDB)。在这篇…...

PTT:Point Tree Transformer for Point Cloud Registration 论文解读
目录 一、导言 二、相关工作 1、基于Transformer的点云配准 2、针对点云的局部注意力 三、PTT 1、KPconv提取特征 2、Tree Transformer Encoder 3、Decoder 4、估计姿态 5、损失函数 四、实验 1、对比不同Backbone 2、运行时间对比 3、对比不同PTT方法下RR指标的…...

C++速通LeetCode中等第7题-和为K的子数组(巧用前缀和)
巧用哈希表与前缀和,前缀和差为k的两个序号之间的数组就是满足条件的子数组,用哈希表来存放每个序号的前缀和。 前缀和就是头元素到当前序号子数组元素的和 class Solution { public:int subarraySum(vector<int>& nums, int k) {unordered_…...

【读书笔记-《30天自制操作系统》-23】Day24
本篇内容依然比较简单,主要是优化窗口功能以及开发定时器应用程序。首先是优化窗口的切换功能,实现通过键盘和鼠标切换窗口,然后是实现通过鼠标关闭窗口。接着实现不同窗口输入状态的切换,最后是实现定时器的API与应用程序。 1.…...
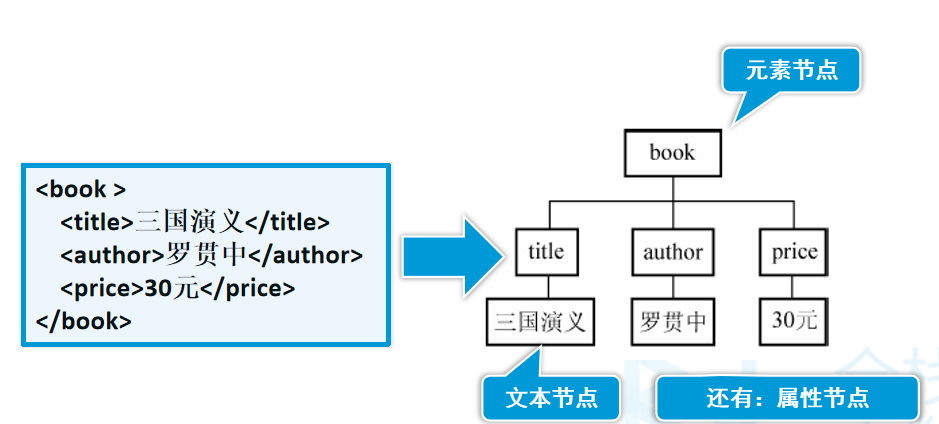
XML:DOM4j解析XML
XML简介: 什么是XML:XML 是独立于软件和硬件的信息传输工具。 XML 的设计宗旨是传输数据,而不是显示数据。XML 标签没有被预定义。您需要自行定义标签。XML不会做任何事情,XML被设计用来结构化、存储以及传输信息。 XML可以发明…...

15.5 创建监控控制平面的service
本节重点介绍 : k8s中service的作用和类型创建k8s控制平面的service 给prometheus采集用, 类型clusterIp kube-schedulerkube-controller-managerkube-etcd service的作用 Kubernetes Service定义了这样一种抽象: Service是一种可以访问 Pod逻辑分组…...

【Docker Nexus3】maven 私库
1.部署环境 window 11 x64Docker Desktop 4.34.1 (166053) Docker Engine v27.2.0 1.1.Docker 镜像源 1.1.1.Docker Engine 配置 {"builder": {"features": {"buildkit": true},"gc": {"defaultKeepStorage": "32…...
Docker本地部署Chatbot Ollama搭建AI聊天机器人并实现远程交互
文章目录 前言1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 前言 本文主要分享如何在群晖NAS本地部署并运行一个基于大语言模型Llama 2的个人本地聊天机器人并结合内网穿透工具…...

MySQL:用户管理
添加用户 create user usernamelocalhost identified by user_password;删除用户 drop user usernamelocalhost;查看所有用户 输入格式 select user,host from mysql.user; 输出 mysql> select user,host from mysql.user; ----------------------------- | user …...

论文《Mixture of Weak Strong Experts on Graphs》笔记
【Mowst 2024 ICLR】论文提出了一种新的图神经网络架构,称为Mixture of weak and strong experts(Mowst),通过将轻量级的多层感知机(MLP)作为弱专家和现成的GNN作为强专家相结合,以处理图中的节…...

【诉讼流程-健身房-违约-私教课-诉讼书提交流程-民事诉讼-自我学习-铺平通往法律的阶梯-讲解(3)】
【诉讼流程-健身房-违约-私教课-诉讼书提交流程-民事诉讼-自我学习-铺平通往法律的阶梯-讲解(3)】 1、前言说明2、流程说明3、现场提交(线下)4、网上提交1-起诉书样例2-起诉书编写(1)原告信息:&…...

数据结构(Day14)
一、学习内容 结构体 概念 引入:定义整数赋值为10 int a10; 定义小数赋值为3.14 float b3.14; 定义5个整数并赋值 int arr[5] {1 , 2 , 3 , 4 ,5}; 定义一个学生并赋值学号姓名成绩 定义一个雪糕并赋值名称产地单价 问题:没有学生、雪糕 数据类型 解决&…...

Paragon NTFS for Mac和Tuxera NTFS for Mac,那么两种工具有什么区别呢?
我们在使用Mac系统读取U盘的过程中往往会遇到一个问题,那就是U盘插进电脑无法显示,或者只能读取不能编辑。出现这种情况的原因就一般是格式错误。 很多小伙伴在解决这种问题的时候会选择使用U盘读写工具,那么哪一种读写工具比较好呢…...

HashTable结构体数组实现
写了个哈希表,底层逻辑基于结构体数组,核心结构:HashNode,结构外壳:HashTable_R,冲突处理以后会加的(QwQ)~ 目前代码: #ifndef PYIC_X #define PYIC_Xunsigned int PYIC_Hash(unsigned int Val, unsigned int Mov) {unsigned int Ht[4] { …...

Python 管理 AWS ElastiCache 告警
在 AWS 环境中,监控和管理 ElastiCache 集群的性能是至关重要的。本文将介绍如何使用 Python 和 AWS SDK (boto3) 来自动创建和删除 ElastiCache 集群的 CloudWatch 告警。我们将分两部分来讨论:创建告警和删除告警。 第一部分:创建 ElastiCache 告警 首先,让我们看看如何…...

【无人机设计与控制】四旋翼无人机俯仰姿态保持模糊PID控制(带说明报告)
摘要 为了克服常规PID控制方法在无人机俯仰姿态控制中的不足,本研究设计了一种基于模糊自适应PID控制的控制律。通过引入模糊控制器,实现了对输入输出论域的优化选择,同时解决了模糊规则数量与控制精度之间的矛盾。仿真结果表明,…...

[数据集][目标检测]不同颜色的安全帽检测数据集VOC+YOLO格式7574张5类别
重要说明:数据集里面有2/3是增强数据集,请仔细查看图片预览,确认符合要求在下载,分辨率均为640x640 数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件…...

确保 App 跟踪透明度权限:Flutter 中的实践
确保 App 跟踪透明度权限:Flutter 中的实践 在数字广告领域,用户隐私保护已成为一个重要议题。随着 iOS 14 的发布,Apple 引入了 App Tracking Transparency (ATT) 框架,要求开发者在跟踪用户行为以提供个性化广告之前必须获得用…...

李沐 过拟合和欠拟合【动手学深度学习v2】
模型容量 模型容量的影响 估计模型容量 难以在不同的种类算法之间比较,例如树模型和神经网络 给定一个模型种类,将有两个主要因素: 参数的个数参数值的选择范围 VC维...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...