Rocprofiler测试
Rocprofiler测试
- 一.参考链接
- 二.测试过程
- 1.登录服务器
- 2.使用smi获取列表
- 3.使用rocminfo获取Agent信息
- 4.准备测试用例
- 5.The hardware counters are called the basic counters
- 6.The derived metrics are defined on top of the basic counters using mathematical expression
- 7.Profing
Rocprofiler测试
一.参考链接
- Compatibility matrix
- AMD Radeon Pro VII
- Radeon™ PRO VII Specifications
- 6.2.0 Supported GPUs
- Performance model&相关名词解释
二.测试过程
1.登录服务器
.TODO
2.使用smi获取列表
rocm-smi
输出
=========================================== ROCm System Management Interface ===========================================
===================================================== Concise Info =====================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%(DID, GUID) (Edge) (Socket) (Mem, Compute, ID)
========================================================================================================================
0 1 0x66a1, 3820 35.0°C 20.0W N/A, N/A, 0 860Mhz 350Mhz 9.41% auto 190.0W 0% 0%
1 2 0x66a1, 22570 38.0°C 17.0W N/A, N/A, 0 860Mhz 350Mhz 9.41% auto 190.0W 0% 0%
========================================================================================================================
================================================= End of ROCm SMI Log ==================================================
3.使用rocminfo获取Agent信息
在 ROCm(Radeon Open Compute)平台中,Agent 通常指的是计算设备或处理单元,这些可以是 CPU 或 GPU。每个 Agent 可以执行计算任务并具有自己的计算资源,如计算核心、内存等。在 ROCm 的程序模型中,Agent 是负责执行特定任务的实体,当你使用 ROCm 进行并行计算时,任务通常会分配给不同的 Agent 来处理。Agent 是 ROCm 的异构计算环境中进行任务调度和管理的基本单元之一
rocminfo
输出
*******
Agent 2
*******Name: gfx906Uuid: GPU-021860c17348c2f7Marketing Name: AMD Radeon (TM) Pro VIIVendor Name: AMDFeature: KERNEL_DISPATCHProfile: BASE_PROFILEFloat Round Mode: NEARMax Queue Number: 128(0x80)Queue Min Size: 64(0x40)Queue Max Size: 131072(0x20000)Queue Type: MULTINode: 1Device Type: GPUCache Info:L1: 16(0x10) KBL2: 8192(0x2000) KBChip ID: 26273(0x66a1)ASIC Revision: 1(0x1)Cacheline Size: 64(0x40)Max Clock Freq. (MHz): 1700BDFID: 1792Internal Node ID: 1Compute Unit: 60SIMDs per CU: 4Shader Engines: 4Shader Arrs. per Eng.: 1WatchPts on Addr. Ranges:4Coherent Host Access: FALSEMemory Properties:Features: KERNEL_DISPATCHFast F16 Operation: TRUEWavefront Size: 64(0x40)Workgroup Max Size: 1024(0x400)Workgroup Max Size per Dimension:x 1024(0x400)y 1024(0x400)z 1024(0x400)Max Waves Per CU: 40(0x28)Max Work-item Per CU: 2560(0xa00)Grid Max Size: 4294967295(0xffffffff)Grid Max Size per Dimension:x 4294967295(0xffffffff)y 4294967295(0xffffffff)z 4294967295(0xffffffff)Max fbarriers/Workgrp: 32Packet Processor uCode:: 472SDMA engine uCode:: 145IOMMU Support:: NonePool Info:Pool 1Segment: GLOBAL; FLAGS: COARSE GRAINEDSize: 16760832(0xffc000) KBAllocatable: TRUEAlloc Granule: 4KBAlloc Recommended Granule:2048KBAlloc Alignment: 4KBAccessible by all: FALSEPool 2Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINEDSize: 16760832(0xffc000) KBAllocatable: TRUEAlloc Granule: 4KBAlloc Recommended Granule:2048KBAlloc Alignment: 4KBAccessible by all: FALSEPool 3Segment: GROUPSize: 64(0x40) KBAllocatable: FALSEAlloc Granule: 0KBAlloc Recommended Granule:0KBAlloc Alignment: 0KBAccessible by all: FALSEISA Info:ISA 1Name: amdgcn-amd-amdhsa--gfx906:sramecc+:xnack-Machine Models: HSA_MACHINE_MODEL_LARGEProfiles: HSA_PROFILE_BASEDefault Rounding Mode: NEARDefault Rounding Mode: NEARFast f16: TRUEWorkgroup Max Size: 1024(0x400)Workgroup Max Size per Dimension:x 1024(0x400)y 1024(0x400)z 1024(0x400)Grid Max Size: 4294967295(0xffffffff)Grid Max Size per Dimension:x 4294967295(0xffffffff)y 4294967295(0xffffffff)z 4294967295(0xffffffff)FBarrier Max Size: 32
*******
4.准备测试用例
tee ROCmMatrixTranspose.cpp<<-'EOF'
#include <iostream>
// hip header file
#include <hip/hip_runtime.h>
// roctx header file
#include <roctracer/roctx.h>#define WIDTH 1024
#define NUM (WIDTH * WIDTH)
#define THREADS_PER_BLOCK_X 4
#define THREADS_PER_BLOCK_Y 4
#define THREADS_PER_BLOCK_Z 1// Device (Kernel) function, it must be void
__global__ void matrixTranspose(float* out, float* in, const int width) {int x = hipBlockDim_x * hipBlockIdx_x + hipThreadIdx_x;int y = hipBlockDim_y * hipBlockIdx_y + hipThreadIdx_y;out[y * width + x] = in[x * width + y];
}// CPU implementation of matrix transpose
void matrixTransposeCPUReference(float* output, float* input, const unsigned int width) {for (unsigned int j = 0; j < width; j++) {for (unsigned int i = 0; i < width; i++) {output[i * width + j] = input[j * width + i];}}
}int main() {float* Matrix;float* TransposeMatrix;float* cpuTransposeMatrix;float* gpuMatrix;float* gpuTransposeMatrix;hipDeviceProp_t devProp;hipGetDeviceProperties(&devProp, 0);std::cout << "Device name " << devProp.name << std::endl;int i;int errors;Matrix = (float*)malloc(NUM * sizeof(float));TransposeMatrix = (float*)malloc(NUM * sizeof(float));cpuTransposeMatrix = (float*)malloc(NUM * sizeof(float));// initialize the input datafor (i = 0; i < NUM; i++) {Matrix[i] = (float)i * 10.0f;}// allocate the memory on the device sidehipMalloc((void**)&gpuMatrix, NUM * sizeof(float));hipMalloc((void**)&gpuTransposeMatrix, NUM * sizeof(float));uint32_t iterations = 1;while (iterations-- > 0) {std::cout << "## Iteration (" << iterations << ") #################" << std::endl;// Memory transfer from host to devicehipMemcpy(gpuMatrix, Matrix, NUM * sizeof(float), hipMemcpyHostToDevice);roctxMark("ROCTX-MARK: before hipLaunchKernel");roctxRangePush("ROCTX-RANGE: hipLaunchKernel");roctx_range_id_t roctx_id = roctxRangeStartA("roctx_range with id");// Lauching kernel from hosthipLaunchKernelGGL(matrixTranspose, dim3(WIDTH / THREADS_PER_BLOCK_X, WIDTH / THREADS_PER_BLOCK_Y),dim3(THREADS_PER_BLOCK_X, THREADS_PER_BLOCK_Y), 0, 0, gpuTransposeMatrix, gpuMatrix, WIDTH);roctxRangeStop(roctx_id);roctxMark("ROCTX-MARK: after hipLaunchKernel");// Memory transfer from device to hostroctxRangePush("ROCTX-RANGE: hipMemcpy");hipMemcpy(TransposeMatrix, gpuTransposeMatrix, NUM * sizeof(float), hipMemcpyDeviceToHost);roctxRangePop(); // for "hipMemcpy"roctxRangePop(); // for "hipLaunchKernel"// CPU MatrixTranspose computationmatrixTransposeCPUReference(cpuTransposeMatrix, Matrix, WIDTH);// verify the resultserrors = 0;double eps = 1.0E-6;for (i = 0; i < NUM; i++) {if (std::abs(TransposeMatrix[i] - cpuTransposeMatrix[i]) > eps) {errors++;}}if (errors != 0) {printf("FAILED: %d errors\n", errors);} else {printf("PASSED!\n");}}// free the resources on device sidehipFree(gpuMatrix);hipFree(gpuTransposeMatrix);// free the resources on host sidefree(Matrix);free(TransposeMatrix);free(cpuTransposeMatrix);return errors;
}EOF/opt/rocm/bin/hipcc -c ROCmMatrixTranspose.cpp -o ROCmMatrixTranspose.cpp.o
/opt/rocm/bin/hipcc ROCmMatrixTranspose.cpp.o -o ROCmMatrixTranspose \/opt/rocm/lib/libamd_comgr.so.2.8.60200 /usr/lib/x86_64-linux-gnu/libnuma.so /opt/rocm/lib/libroctx64.so
./ROCmMatrixTranspose
5.The hardware counters are called the basic counters
rocprof --list-basic | grep -A 2 "gpu-agent2"
输出
gpu-agent2 : TCC_EA1_WRREQ[0-15] : Number of transactions (either 32-byte or 64-byte) going over the TC_EA_wrreq interface. Atomics may travel over the same interface and are generally classified as write requests. This does not include probe commands.block TCC has 4 countersgpu-agent2 : TCC_EA1_WRREQ_64B[0-15] : Number of 64-byte transactions going (64-byte write or CMPSWAP) over the TC_EA_wrreq interface.block TCC has 4 countersgpu-agent2 : TCC_EA1_WRREQ_STALL[0-15] : Number of cycles a write request was stalled.block TCC has 4 countersgpu-agent2 : TCC_EA1_RDREQ[0-15] : Number of TCC/EA read requests (either 32-byte or 64-byte)block TCC has 4 countersgpu-agent2 : TCC_EA1_RDREQ_32B[0-15] : Number of 32-byte TCC/EA read requestsblock TCC has 4 countersgpu-agent2 : GRBM_COUNT : Tie High - Count Number of Clocksblock GRBM has 2 countersgpu-agent2 : GRBM_GUI_ACTIVE : The GUI is Activeblock GRBM has 2 countersgpu-agent2 : SQ_WAVES : Count number of waves sent to SQs. (per-simd, emulated, global)block SQ has 8 countersgpu-agent2 : SQ_INSTS_VALU : Number of VALU instructions issued. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_VMEM_WR : Number of VMEM write instructions issued (including FLAT). (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_VMEM_RD : Number of VMEM read instructions issued (including FLAT). (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_SALU : Number of SALU instructions issued. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_SMEM : Number of SMEM instructions issued. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_FLAT : Number of FLAT instructions issued. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_FLAT_LDS_ONLY : Number of FLAT instructions issued that read/wrote only from/to LDS (only works if EARLY_TA_DONE is enabled). (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_LDS : Number of LDS instructions issued (including FLAT). (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_INSTS_GDS : Number of GDS instructions issued. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_WAIT_INST_LDS : Number of wave-cycles spent waiting for LDS instruction issue. In units of 4 cycles. (per-simd, nondeterministic)block SQ has 8 countersgpu-agent2 : SQ_ACTIVE_INST_VALU : regspec 71? Number of cycles the SQ instruction arbiter is working on a VALU instruction. (per-simd, nondeterministic). Units in quad-cycles(4 cycles)block SQ has 8 countersgpu-agent2 : SQ_INST_CYCLES_SALU : Number of cycles needed to execute non-memory read scalar operations. (per-simd, emulated)block SQ has 8 countersgpu-agent2 : SQ_THREAD_CYCLES_VALU : Number of thread-cycles used to execute VALU operations (similar to INST_CYCLES_VALU but multiplied by # of active threads). (per-simd)block SQ has 8 countersgpu-agent2 : SQ_LDS_BANK_CONFLICT : Number of cycles LDS is stalled by bank conflicts. (emulated)block SQ has 8 countersgpu-agent2 : TA_TA_BUSY[0-15] : TA block is busy. Perf_Windowing not supported for this counter.block TA has 2 countersgpu-agent2 : TA_FLAT_READ_WAVEFRONTS[0-15] : Number of flat opcode reads processed by the TA.block TA has 2 countersgpu-agent2 : TA_FLAT_WRITE_WAVEFRONTS[0-15] : Number of flat opcode writes processed by the TA.block TA has 2 countersgpu-agent2 : TCC_HIT[0-15] : Number of cache hits.block TCC has 4 countersgpu-agent2 : TCC_MISS[0-15] : Number of cache misses. UC reads count as misses.block TCC has 4 countersgpu-agent2 : TCC_EA_WRREQ[0-15] : Number of transactions (either 32-byte or 64-byte) going over the TC_EA_wrreq interface. Atomics may travel over the same interface and are generally classified as write requests. This does not include probe commands.block TCC has 4 countersgpu-agent2 : TCC_EA_WRREQ_64B[0-15] : Number of 64-byte transactions going (64-byte write or CMPSWAP) over the TC_EA_wrreq interface.block TCC has 4 countersgpu-agent2 : TCC_EA_WRREQ_STALL[0-15] : Number of cycles a write request was stalled.block TCC has 4 countersgpu-agent2 : TCC_EA_RDREQ[0-15] : Number of TCC/EA read requests (either 32-byte or 64-byte)block TCC has 4 countersgpu-agent2 : TCC_EA_RDREQ_32B[0-15] : Number of 32-byte TCC/EA read requestsblock TCC has 4 countersgpu-agent2 : TCP_TCP_TA_DATA_STALL_CYCLES[0-15] : TCP stalls TA data interface. Now Windowed.block TCP has 4 counters
6.The derived metrics are defined on top of the basic counters using mathematical expression
rocprof --list-derived | grep -A 2 "gpu-agent2"
输出
gpu-agent2 : TCC_EA1_RDREQ_32B_sum : Number of 32-byte TCC/EA read requests. Sum over TCC EA1s.TCC_EA1_RDREQ_32B_sum = sum(TCC_EA1_RDREQ_32B,16)gpu-agent2 : TCC_EA1_RDREQ_sum : Number of TCC/EA read requests (either 32-byte or 64-byte). Sum over TCC EA1s.TCC_EA1_RDREQ_sum = sum(TCC_EA1_RDREQ,16)gpu-agent2 : TCC_EA1_WRREQ_sum : Number of transactions (either 32-byte or 64-byte) going over the TC_EA_wrreq interface. Sum over TCC EA1s.TCC_EA1_WRREQ_sum = sum(TCC_EA1_WRREQ,16)gpu-agent2 : TCC_EA1_WRREQ_64B_sum : Number of 64-byte transactions going (64-byte write or CMPSWAP) over the TC_EA_wrreq interface. Sum over TCC EA1s.TCC_EA1_WRREQ_64B_sum = sum(TCC_EA1_WRREQ_64B,16)gpu-agent2 : TCC_WRREQ1_STALL_max : Number of cycles a write request was stalled. Max over TCC instances.TCC_WRREQ1_STALL_max = max(TCC_EA1_WRREQ_STALL,16)gpu-agent2 : RDATA1_SIZE : The total kilobytes fetched from the video memory. This is measured on EA1s.RDATA1_SIZE = (TCC_EA1_RDREQ_32B_sum*32+(TCC_EA1_RDREQ_sum-TCC_EA1_RDREQ_32B_sum)*64)gpu-agent2 : WDATA1_SIZE : The total kilobytes written to the video memory. This is measured on EA1s.WDATA1_SIZE = ((TCC_EA1_WRREQ_sum-TCC_EA1_WRREQ_64B_sum)*32+TCC_EA1_WRREQ_64B_sum*64)gpu-agent2 : FETCH_SIZE : The total kilobytes fetched from the video memory. This is measured with all extra fetches and any cache or memory effects taken into account.FETCH_SIZE = (TCC_EA_RDREQ_32B_sum*32+(TCC_EA_RDREQ_sum-TCC_EA_RDREQ_32B_sum)*64+RDATA1_SIZE)/1024gpu-agent2 : WRITE_SIZE : The total kilobytes written to the video memory. This is measured with all extra fetches and any cache or memory effects taken into account.WRITE_SIZE = ((TCC_EA_WRREQ_sum-TCC_EA_WRREQ_64B_sum)*32+TCC_EA_WRREQ_64B_sum*64+WDATA1_SIZE)/1024gpu-agent2 : WRITE_REQ_32B : The total number of 32-byte effective memory writes.WRITE_REQ_32B = (TCC_EA_WRREQ_sum-TCC_EA_WRREQ_64B_sum)+(TCC_EA1_WRREQ_sum-TCC_EA1_WRREQ_64B_sum)+(TCC_EA_WRREQ_64B_sum+TCC_EA1_WRREQ_64B_sum)*2gpu-agent2 : TA_BUSY_avr : TA block is busy. Average over TA instances.TA_BUSY_avr = avr(TA_TA_BUSY,16)gpu-agent2 : TA_BUSY_max : TA block is busy. Max over TA instances.TA_BUSY_max = max(TA_TA_BUSY,16)gpu-agent2 : TA_BUSY_min : TA block is busy. Min over TA instances.TA_BUSY_min = min(TA_TA_BUSY,16)gpu-agent2 : TA_FLAT_READ_WAVEFRONTS_sum : Number of flat opcode reads processed by the TA. Sum over TA instances.TA_FLAT_READ_WAVEFRONTS_sum = sum(TA_FLAT_READ_WAVEFRONTS,16)gpu-agent2 : TA_FLAT_WRITE_WAVEFRONTS_sum : Number of flat opcode writes processed by the TA. Sum over TA instances.TA_FLAT_WRITE_WAVEFRONTS_sum = sum(TA_FLAT_WRITE_WAVEFRONTS,16)gpu-agent2 : TCC_HIT_sum : Number of cache hits. Sum over TCC instances.TCC_HIT_sum = sum(TCC_HIT,16)gpu-agent2 : TCC_MISS_sum : Number of cache misses. Sum over TCC instances.TCC_MISS_sum = sum(TCC_MISS,16)gpu-agent2 : TCC_EA_RDREQ_32B_sum : Number of 32-byte TCC/EA read requests. Sum over TCC instances.TCC_EA_RDREQ_32B_sum = sum(TCC_EA_RDREQ_32B,16)gpu-agent2 : TCC_EA_RDREQ_sum : Number of TCC/EA read requests (either 32-byte or 64-byte). Sum over TCC instances.TCC_EA_RDREQ_sum = sum(TCC_EA_RDREQ,16)gpu-agent2 : TCC_EA_WRREQ_sum : Number of transactions (either 32-byte or 64-byte) going over the TC_EA_wrreq interface. Sum over TCC instances.TCC_EA_WRREQ_sum = sum(TCC_EA_WRREQ,16)gpu-agent2 : TCC_EA_WRREQ_64B_sum : Number of 64-byte transactions going (64-byte write or CMPSWAP) over the TC_EA_wrreq interface. Sum over TCC instances.TCC_EA_WRREQ_64B_sum = sum(TCC_EA_WRREQ_64B,16)gpu-agent2 : TCC_WRREQ_STALL_max : Number of cycles a write request was stalled. Max over TCC instances.TCC_WRREQ_STALL_max = max(TCC_EA_WRREQ_STALL,16)gpu-agent2 : TCP_TCP_TA_DATA_STALL_CYCLES_sum : Total number of TCP stalls TA data interface.TCP_TCP_TA_DATA_STALL_CYCLES_sum = sum(TCP_TCP_TA_DATA_STALL_CYCLES,16)gpu-agent2 : TCP_TCP_TA_DATA_STALL_CYCLES_max : Maximum number of TCP stalls TA data interface.TCP_TCP_TA_DATA_STALL_CYCLES_max = max(TCP_TCP_TA_DATA_STALL_CYCLES,16)gpu-agent2 : VFetchInsts : The average number of vector fetch instructions from the video memory executed per work-item (affected by flow control). Excludes FLAT instructions that fetch from video memory.VFetchInsts = (SQ_INSTS_VMEM_RD-TA_FLAT_READ_WAVEFRONTS_sum)/SQ_WAVESgpu-agent2 : VWriteInsts : The average number of vector write instructions to the video memory executed per work-item (affected by flow control). Excludes FLAT instructions that write to video memory.VWriteInsts = (SQ_INSTS_VMEM_WR-TA_FLAT_WRITE_WAVEFRONTS_sum)/SQ_WAVESgpu-agent2 : FlatVMemInsts : The average number of FLAT instructions that read from or write to the video memory executed per work item (affected by flow control). Includes FLAT instructions that read from or write to scratch.FlatVMemInsts = (SQ_INSTS_FLAT-SQ_INSTS_FLAT_LDS_ONLY)/SQ_WAVESgpu-agent2 : LDSInsts : The average number of LDS read or LDS write instructions executed per work item (affected by flow control). Excludes FLAT instructions that read from or write to LDS.LDSInsts = (SQ_INSTS_LDS-SQ_INSTS_FLAT_LDS_ONLY)/SQ_WAVESgpu-agent2 : FlatLDSInsts : The average number of FLAT instructions that read or write to LDS executed per work item (affected by flow control).FlatLDSInsts = SQ_INSTS_FLAT_LDS_ONLY/SQ_WAVESgpu-agent2 : VALUUtilization : The percentage of active vector ALU threads in a wave. A lower number can mean either more thread divergence in a wave or that the work-group size is not a multiple of 64. Value range: 0% (bad), 100% (ideal - no thread divergence).VALUUtilization = 100*SQ_THREAD_CYCLES_VALU/(SQ_ACTIVE_INST_VALU*MAX_WAVE_SIZE)gpu-agent2 : VALUBusy : The percentage of GPUTime vector ALU instructions are processed. Value range: 0% (bad) to 100% (optimal).VALUBusy = 100*SQ_ACTIVE_INST_VALU*4/SIMD_NUM/GRBM_GUI_ACTIVEgpu-agent2 : SALUBusy : The percentage of GPUTime scalar ALU instructions are processed. Value range: 0% (bad) to 100% (optimal).SALUBusy = 100*SQ_INST_CYCLES_SALU*4/SIMD_NUM/GRBM_GUI_ACTIVEgpu-agent2 : FetchSize : The total kilobytes fetched from the video memory. This is measured with all extra fetches and any cache or memory effects taken into account.FetchSize = FETCH_SIZEgpu-agent2 : WriteSize : The total kilobytes written to the video memory. This is measured with all extra fetches and any cache or memory effects taken into account.WriteSize = WRITE_SIZEgpu-agent2 : MemWrites32B : The total number of effective 32B write transactions to the memoryMemWrites32B = WRITE_REQ_32Bgpu-agent2 : L2CacheHit : The percentage of fetch, write, atomic, and other instructions that hit the data in L2 cache. Value range: 0% (no hit) to 100% (optimal).L2CacheHit = 100*sum(TCC_HIT,16)/(sum(TCC_HIT,16)+sum(TCC_MISS,16))gpu-agent2 : MemUnitStalled : The percentage of GPUTime the memory unit is stalled. Try reducing the number or size of fetches and writes if possible. Value range: 0% (optimal) to 100% (bad).MemUnitStalled = 100*max(TCP_TCP_TA_DATA_STALL_CYCLES,16)/GRBM_GUI_ACTIVE/SE_NUMgpu-agent2 : WriteUnitStalled : The percentage of GPUTime the Write unit is stalled. Value range: 0% to 100% (bad).WriteUnitStalled = 100*TCC_WRREQ_STALL_max/GRBM_GUI_ACTIVEgpu-agent2 : LDSBankConflict : The percentage of GPUTime LDS is stalled by bank conflicts. Value range: 0% (optimal) to 100% (bad).LDSBankConflict = 100*SQ_LDS_BANK_CONFLICT/GRBM_GUI_ACTIVE/CU_NUMgpu-agent2 : GPUBusy : The percentage of time GPU was busy.GPUBusy = 100*GRBM_GUI_ACTIVE/GRBM_COUNTgpu-agent2 : Wavefronts : Total wavefronts.Wavefronts = SQ_WAVESgpu-agent2 : VALUInsts : The average number of vector ALU instructions executed per work-item (affected by flow control).VALUInsts = SQ_INSTS_VALU/SQ_WAVESgpu-agent2 : SALUInsts : The average number of scalar ALU instructions executed per work-item (affected by flow control).SALUInsts = SQ_INSTS_SALU/SQ_WAVESgpu-agent2 : SFetchInsts : The average number of scalar fetch instructions from the video memory executed per work-item (affected by flow control).SFetchInsts = SQ_INSTS_SMEM/SQ_WAVESgpu-agent2 : GDSInsts : The average number of GDS read or GDS write instructions executed per work item (affected by flow control).GDSInsts = SQ_INSTS_GDS/SQ_WAVESgpu-agent2 : MemUnitBusy : The percentage of GPUTime the memory unit is active. The result includes the stall time (MemUnitStalled). This is measured with all extra fetches and writes and any cache or memory effects taken into account. Value range: 0% to 100% (fetch-bound).MemUnitBusy = 100*max(TA_TA_BUSY,16)/GRBM_GUI_ACTIVE/SE_NUMgpu-agent2 : ALUStalledByLDS : The percentage of GPUTime ALU units are stalled by the LDS input queue being full or the output queue being not ready. If there are LDS bank conflicts, reduce them. Otherwise, try reducing the number of LDS accesses if possible. Value range: 0% (optimal) to 100% (bad).ALUStalledByLDS = 100*SQ_WAIT_INST_LDS*4/SQ_WAVES/GRBM_GUI_ACTIVE
7.Profing
tee input.txt<<-'EOF'
pmc : Wavefronts, VALUInsts, SALUInsts, SFetchInsts,FlatVMemInsts,
LDSInsts, FlatLDSInsts, GDSInsts, VALUUtilization, FetchSize,
WriteSize, L2CacheHit, VWriteInsts, GPUBusy, VALUBusy, SALUBusy,
MemUnitStalled, WriteUnitStalled, LDSBankConflict, MemUnitBusy
# Filter by dispatches range, GPU index and kernel names
# supported range formats: "3:9", "3:", "3"
range: 0 : 1
gpu: 0
kernel:matrixTranspose
EOFrocprof -i input.txt ./ROCmMatrixTranspose
cat /root/input.csv
rocprofv2 -i input.txt ./ROCmMatrixTranspose
rocprofv2 --hsa-trace ./ROCmMatrixTranspose
输出
RPL: on '240920_102257' from '/opt/rocm-6.2.0' in '/root'
RPL: profiling '"./ROCmMatrixTranspose"'
RPL: input file 'input.txt'
RPL: output dir '/tmp/rpl_data_240920_102257_47892'RPL: result dir '/tmp/rpl_data_240920_102257_47892/input0_results_240920_102257'
ROCProfiler: input from "/tmp/rpl_data_240920_102257_47892/input0.xml"gpu_index = 0kernel = matrixTransposerange = 0:14 metricsWavefronts, VALUInsts, SALUInsts, SFetchInsts
Device name AMD Radeon (TM) Pro VII
## Iteration (0) #################
PASSED!ROCPRofiler: 1 contexts collected, output directory /tmp/rpl_data_240920_102257_47892/input0_results_240920_102257
File '/root/input.csv' is generating
Index,KernelName,gpu-id,queue-id,queue-index,pid,tid,grd,wgr,lds,scr,arch_vgpr,accum_vgpr,sgpr,wave_size,sig,obj,Wavefronts,VALUInsts,SALUInsts,SFetchInsts
0,"matrixTranspose(float*, float*, int) [clone .kd]",1,0,0,48178,48178,1048576,16,0,0,8,0,16,64,0x0,0x742031870880,65536.0000000000,14.0000000000,4.0000000000,3.0000000000ROCProfilerV2: Collecting the following counters:
- Wavefronts
- VALUInsts
- SALUInsts
- SFetchInsts
Enabling Counter Collection
Device name AMD Radeon (TM) Pro VII
## Iteration (0) #################
PASSED!
Dispatch_ID(0), GPU_ID(1), Queue_ID(1), Process_ID(48209), Thread_ID(48209), Grid_Size(1048576), Workgroup_Size(16), LDS_Per_Workgroup(0), Scratch_Per_Workitem(0), Arch_VGPR(8), Accum_VGPR(0), SGPR(16), Wave_Size(64), Kernel_Name("matrixTranspose(float*, float*, int) (.kd)"), Begin_Timestamp(951172884265490), End_Timestamp(951172884454463), Correlation_ID(0), SALUInsts(4.000000), SFetchInsts(3.000000), VALUInsts(14.000000), Wavefronts(65536.000000)
相关文章:

Rocprofiler测试
Rocprofiler测试 一.参考链接二.测试过程1.登录服务器2.使用smi获取列表3.使用rocminfo获取Agent信息4.准备测试用例5.The hardware counters are called the basic counters6.The derived metrics are defined on top of the basic counters using mathematical expression7.P…...

基于python flask的高血压疾病预测分析与可视化系统的设计与实现,使用随机森林、决策树、逻辑回归、xgboost等机器学习库预测
研究背景 随着现代社会的快速发展,生活方式的改变和人口老龄化的加剧,心血管疾病,尤其是高血压,已成为全球范围内的重大公共健康问题。高血压是一种常见的慢性疾病,其主要特征是动脉血压持续升高。长期不控制的高血压…...

Lombok 与 EasyExcel 兼容性问题解析及建议
在 Java 开发中,Lombok 被广泛用于减少样板代码,如 Getter、Setter、构造函数等。然而,在与像 EasyExcel 这样依赖反射机制的库一起使用时,可能会遇到一些意想不到的问题。本文将深入探讨 Lombok 与 EasyExcel 之间的兼容性问题&a…...

Kubeadm快速安装 Kubernetes集群
1. Kubernetes简介 Kubernetes(k8s)是谷歌开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它具有以下特点: 开源容器化自动部署扩展高可用 2. Kubernetes架构 Kubernetes遵循主从式架构设计,主要分…...

OpenJudge | 八皇后问题
总时间限制: 10000ms 内存限制: 65536kB 描述 在国际象棋棋盘上放置八个皇后,要求每两个皇后之间不能直接吃掉对方。 输入 无输入。 输出 按给定顺序和格式输出所有八皇后问题的解(见Sample Output)。 样例输入 (null)样例输出 No. 1 …...

C#往压缩包Zip文件的文件追加数据
C#往压缩包Zip文件的文件追加数据 往一个已经压缩好的压缩包里追加数据,一般就有两种方式,一种是前面已经学习过的,就是追加一个新的文件, 另外一种就是往已经存在的文件追加数据。 往已经存在的文件追加数据,需要先找到文件索引。 在压缩包里声明的名称,与外面的文件路…...

局域网共享文件夹:您没有权限访问,请与网络管理员联系
局域网共享文件夹:您没有权限访问,请与网络管理员联系 win10 1909 专业版背景 我有两个电脑,还有两块外挂硬盘,较大的一块放在老电脑上,为了方便用垃圾百度网盘在里边下载东西,又不污染新电脑的环境。 如…...

科技修复记忆:轻松几步,旧照变清晰
在时间的长河中,旧照片承载着无数珍贵的记忆与故事。然而,随着岁月的流逝,这些照片往往变得模糊不清,色彩黯淡,令人惋惜。 幸运的是,随着科技的发展,我们有了多种方法来修复这些旧照片的画质&a…...

java -versionbash:/usr/lib/jvm/jdk1.8.0_162/bin/java:无法执行二进制文件:可执行文件格式错误
实验环境:Apple M1在VMwareFusion使用Utubun Jdk文件错误  尝试: 1、重新在网盘下载java1.8 2、在终端通过命令下载 3、确保 JDK 正确安装在系统中,可以通过 echo $JAVA_HOME 检查 JAVA_HOME 环境变量是否设置正确。 ࿿…...

大数据-141 - ClickHouse 集群 副本和分片 Zk 的配置 Replicated MergeTree原理详解
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

Django-cookie和session
文章目录 前言CookieSession 一、Django 中 Cookie二、Django 中 Session三.区别 前言 Cookie Cookie 是由服务器发送到用户浏览器的小文件,用于存储用户的相关信息。每次用户访问网站时,浏览器会将这些 cookie 发送回服务器 特点: 1. 数据存储在客户…...

前端进阶,使用Node.js做中间层,实现接口转发和服务器渲染
在Web开发中,Node.js经常被用作中间层(也称为后端或服务器端),用于处理各种任务,包括接口转发(API Gateway)、服务器渲染(Server-Side Rendering, SSR)等。下面我将分别解…...

iPhone 16系列:熟悉的味道,全新的体验
来看看iPhone 16和Plus这两个新成员,实话说,它们和之前曝光的样子几乎完全一致。下面我们就一起来细数一下这次的几大变化吧。 外观设计:焕然一新 首先,最显眼的变化就是后置镜头模组的布局调整为了垂直排列。这一改变使得整个背…...

改进拖放PDF转换为图片在转换为TXT文件的程序
前段时间我写了Python识别拖放的PDF文件再转成文本文件-CSDN博客 最近有2点更新,一是有一些pdf文件转换出来的图片是横的,这样也可以识别文字,但是可能会影响效果,另一个是发现有一些文字识别不出来,看了关于提高Padd…...

在 Flutter 开发中如何选择状态管理:Provider 和 GetX 比较
在 Flutter 开发中,状态管理是一个至关重要的部分。正确的状态管理方案能够提高应用的可维护性和可扩展性。在众多状态管理方案中,Provider 和 GetX 是两种非常流行的选择。本文将对这两者进行比较,并提供代码示例,以帮助开发者选…...

python中ocr图片文字识别样例(二)
一、说明 本次解决图片相关出现中文乱码问题,属于上篇文章的优化,前提条件依赖上篇文章的包,当然ocr的具体应用场景很多,根据自身需求进行调整 二、具体实现 2.1 代码实现: # -*- coding: utf-8 -*- import easyoc…...
2024 新手指南:轻松掌握 Win10 的录屏操作
之前为了节约成本我们公司都采用录制软件操作都方式来为异地的同事进行远程操作培训的。所以我们尝试了不少的录屏工具,这里我就分享下win10怎么录屏的操作过程。 1.福昕录屏大师 链接:www.foxitsoftware.cn/REC/ 这款录屏工具是初学者的理想之选&…...
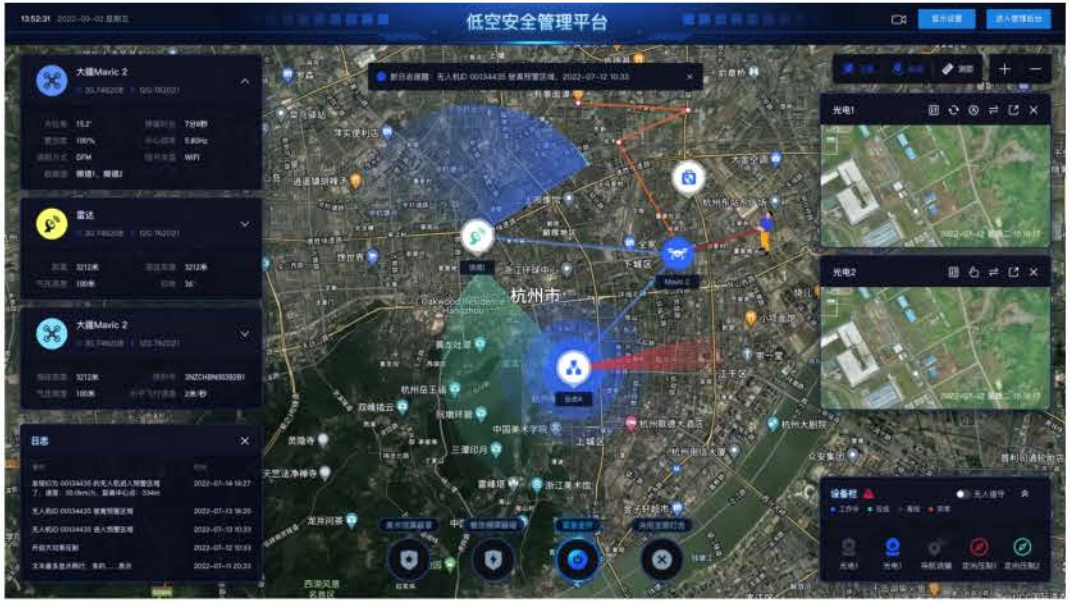
无人机黑飞打击技术详解
随着无人机技术的普及,无人机“黑飞”(未经授权或违反规定的飞行)现象日益严重,对公共安全、隐私保护及重要设施安全构成了严重威胁。为有效应对这一挑战,各国政府和安全机构纷纷研发并部署了一系列无人机黑飞打击技术…...

GoFly快速开发框架/Go语言封装的图像相似性比较插件使用说明
说明 图像相似性搜索应用广泛、除了使用搜索引擎搜索类似图片外,像淘宝可以让顾客直接拍照搜索类似的商品信息、应用在商品购物上,也可以应用物体识别比如拍图识花等领域。还有在调研图片鉴权的方案,通过一张图片和图片库中的图片进行比对&a…...

【牛客】小白赛101-B--tb的字符串问题
题目传送门 思路:括号匹配板子 反思:我用了模拟打标记的方式但是还是wa了 ac代码 用了栈维护 当栈里面个数到达1个以上的时候就可以判断栈顶是否匹配然后重复出入栈操作 #include<bits/stdc.h> using namespace std; const int N1e63; string…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

Noto字体终极指南:告别“豆腐块“,让全球文字清晰显示
Noto字体终极指南:告别"豆腐块",让全球文字清晰显示 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在数字世界中,你是否经常看到那些令人困…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...

结肠“瑞士卷”制片法
在肠道病理研究中,如何完整保留小鼠结肠的全层结构、同时避免人为损伤,一直是实验操作的难点。本文分享一套改良版“瑞士卷”制片技术,无需剖开肠管、无需机械顶压,即可获得高质量的全结肠切片,特别适合炎症、隐窝异常…...