年度巨献 | OpenCSG开源最大中文合成数据集Chinese Cosmopedia
01
背景
近年来,生成式语言模型(GLM)的飞速发展正在重塑人工智能领域,尤其是在自然语言处理、内容创作和智能客服等领域展现出巨大潜力。然而,大多数领先的语言模型主要依赖于英文数据集进行训练,中文数据资源在规模和多样性方面相对不足,限制了中文生成式模型的实际应用表现。为应对这一挑战,OpenCSG算法团队启动了 Chinese Cosmopedia 项目,对标Huggingface Cosmopedia,旨在构建一个专为中文语言模型设计的大规模合成数据集,推动中文大模型的性能提升和广泛应用。
Chinese Cosmopedia 项目通过整合中文互联网中的多种数据来源和内容类型,构建了涵盖约1500万条数据和600亿个token的庞大数据集。该数据集包括了多种文体和风格,如大学教科书、中学教科书、幼儿故事、技术教程和普通故事等,内容广泛涉及学术、教育、技术等多个领域。这些多样化的数据能够满足不同应用场景的需求,帮助训练更加智能和精准的中文生成式语言模型。
OpenCSG团队在数据生成过程中,通过种子数据和prompt设计来控制数据的主题和风格,确保数据的多样性和高质量。例如,种子数据来源于各类中文百科、知识问答和技术博客等,而prompt则用于生成具有不同受众和风格的内容,从学术教科书到儿童故事,内容广泛且具有针对性。团队还利用先进的生成技术,确保生成数据具备连贯性和深度。
通过推出 Chinese Cosmopedia,OpenCSG团队致力于提升中文语言模型在多种任务中的表现,使得中文模型在准确性、生成能力和实际应用中的表现更加优越。该项目不仅将帮助研究人员和开发者加速中文大模型的训练和应用,也将为企业和行业提供丰富的工具和数据支持。Chinese Cosmopedia 的成功实施将成为中文AI技术发展中的一个重要里程碑,推动人工智能技术的普及和民主化,让更多人和企业能够享受到AI带来的创新和效益。

02
Cosmopedia数据集介绍
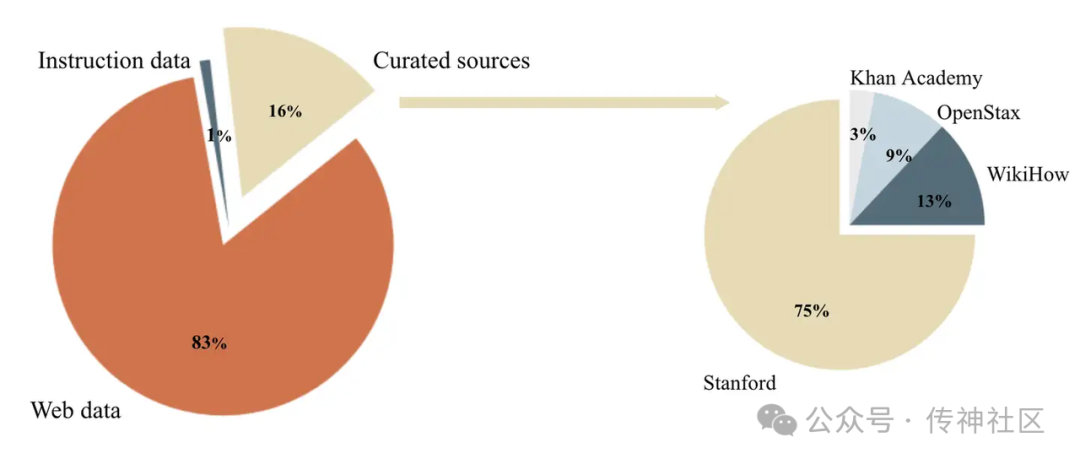
Cosmopedia 是 Hugging Face 社区开发的一个庞大的开放合成数据集,旨在支持大语言模型(LLM)的预训练。该数据集包含超过 3000 万个文件,总共约 250 亿个 tokens,是迄今为止最大规模的公开合成数据集之一。Cosmopedia 的主要目的是生成用于模型训练的多样化、高质量数据,以复现类似于微软的 Phi-1.5 模型的训练数据。

内容覆盖面广泛
Cosmopedia 涵盖多种文本类型,包括合成教科书、博客文章、故事以及类似 WikiHow 的教程文章。这些内容从不同的来源获取和加工,既包括精选的教育资源,如 斯坦福课程、可汗学院、OpenStax 和 WikiHow。这些资源涵盖了许多有价值的主题可供 LLM 学习。
Cosmopedia 中 80% 以上的提示数据来自网络,经过复杂的聚类算法,确保生成数据的多样性和质量。这些数据广泛覆盖多个主题,从教育、科学到日常生活,几乎涵盖了人类知识的方方面面。
生成方法与挑战
Cosmopedia 的生成过程中,使用了 Mixtral-8x7B-Instruct-v0.1 模型。提示生成是该项目的核心部分,为了确保生成的内容在不同主题和受众间保持多样性,开发团队设计了数百万条不同的 prompts,调整了生成文本的风格和目标受众。这些提示不仅包括学术教科书式的生成任务,还包括为少年儿童、研究人员等不同受众定制的内容。
数据集链接:https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
03
Chinese Cosmopedia 数据集
数据集简介
Chinese Cosmopedia数据集共包含1500万条数据,约60B个token,构建合成数据集的两个核心要素是种子数据和prompt。种子数据决定了生成内容的主题,prompt则决定了数据的风格(如教科书、故事、教程或幼儿读物)。数据来源丰富多样,涵盖了中文维基百科、百度百科、知乎问答和技术博客等平台,确保内容的广泛性和权威性。生成的数据形式多样,涵盖大学教科书、中学教科书、幼儿故事、普通故事和WikiHow风格教程等多种不同风格。通过对每条种子数据生成多种不同风格的内容,数据集不仅适用于学术研究,还广泛应用于教育、娱乐和技术领域。

下载地址:
huggingface社区:https://huggingface.co/datasets/opencsg/chinese-cosmopedia
数据来源与种类
Chinese Cosmopedia的数据来源丰富,涵盖了多种中文内容平台和知识库,包括:
-
中文维基百科:提供了大量精确、权威的知识性文章。
-
百度百科:作为国内最具影响力的百科平台之一,百度百科为数据集提供了广泛的中文知识资源。
-
知乎问答:从互动式问答平台中提取的内容,涵盖了多个领域的讨论与见解。
-
技术博客:来自技术社区的文章,涵盖了从编程到人工智能等多个技术方向的深入讨论。
这些种子数据构成了Chinese Cosmopedia数据集的核心内容来源,确保了不同领域知识的覆盖。
数据形式与风格
Chinese Cosmopedia数据集特别注重生成内容的风格与形式,涵盖了从学术到日常应用的多种文本类型,主要包括以下几类:
-
大学教科书:内容结构严谨,深入探讨各类大学学科的核心概念。
-
中学教科书:适合中学生的教学内容,简洁易懂,注重基本知识的传达。
-
幼儿故事:面向5岁儿童,语言简洁易懂,帮助幼儿理解世界和人际关系。
-
普通故事:通过引人入胜的情节和人物对话,展开对某一概念的生动描述。
-
WikiHow风格教程:详细的步骤指导,帮助用户完成特定任务。
每种文体都根据不同的应用场景和目标读者群体,进行了精细化的风格调整。通过这种设计,Cosmopedia不仅适用于学术研究,还能广泛应用于教育、娱乐、技术等领域。
统计
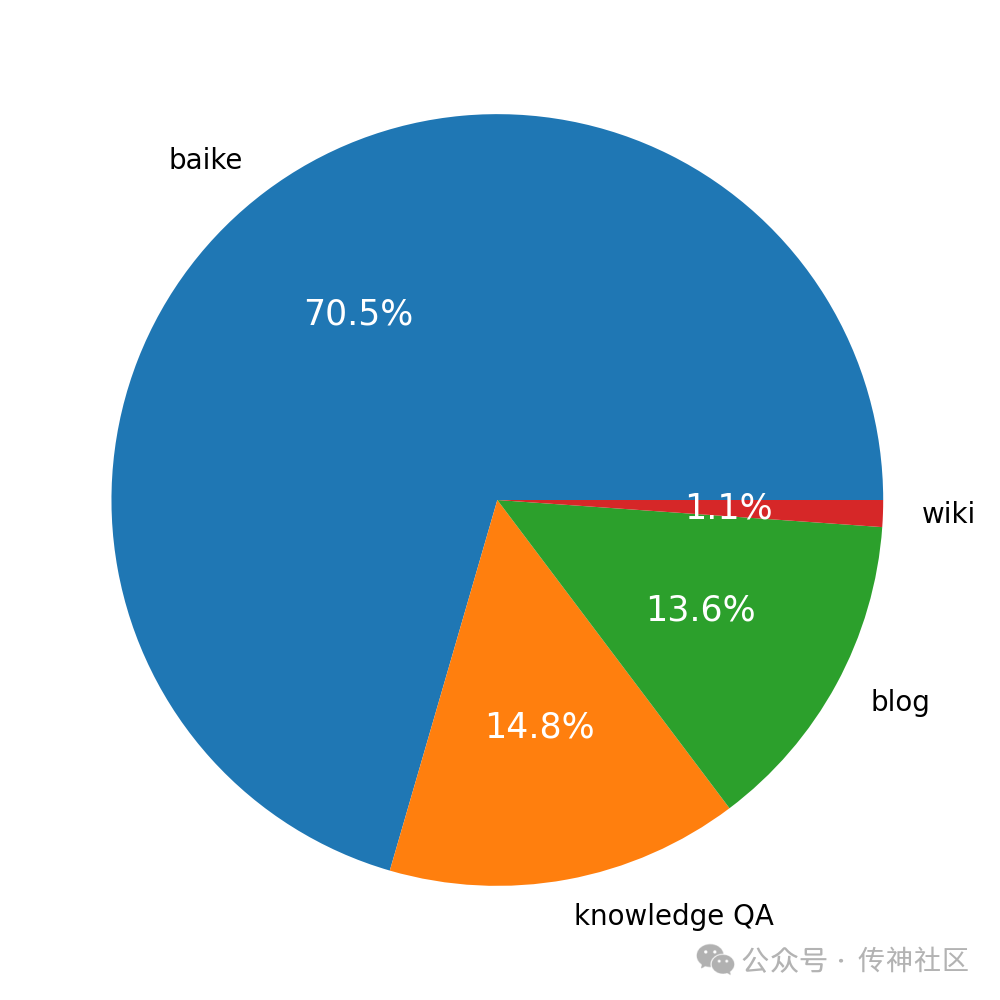
种子数据来源:{'blog': 2111009, 'baike': 10939121, 'wiki': 173671, 'knowledge QA': 2291547}
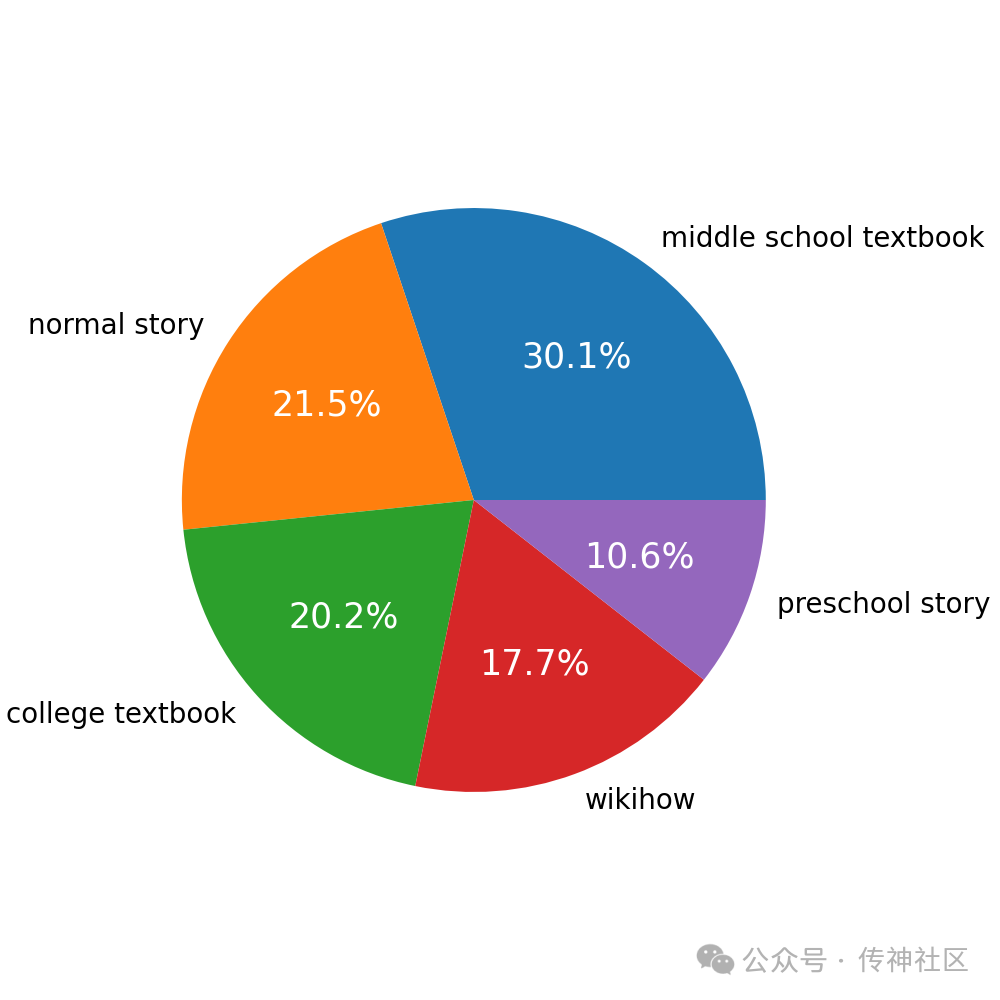
数据形式:{'preschool story': 1637760, 'normal story': 3332288, 'middle school textbook': 4677397, 'college textbook': 3127902, 'wikihow': 2740001}
数据生成与模型
Chinese Cosmopedia的数据生成基于OpenCSG团队自主开发的OpenCSG-Wukong-Enterprise-Long模型。该模型通过强大的长文本生成能力,确保了生成数据的连贯性和内容深度。在数据生成过程中,OpenCSG团队为每种文体和内容类型设计了专门的prompt(提示词),以确保数据生成的风格与内容准确匹配。例如,对于教科书类型的内容,prompt会引导模型生成严谨且具有深度的学术文本,而对于故事类内容,则引导模型创造生动、引人入胜的情节。
我们用于生成各种格式的数据的prompt如下
大学教科书
这是一段来自网页的摘录:“{}”。请编写一个针对大学生的足够详细的教科书课程单元,该单元与给定的摘录中的某个概念或多个概念相关。不需要包含摘录中的所有内容,只需要发掘其中适合作为教科书内容的部分。你可以自由补充其他相关知识。不能仅仅列出概念,而是要深入发展和详细探讨每个概念,因为我们优先考虑深入理解主题内容,而不是广度。要求:1. 严谨性:确保对概念/章节的深入覆盖。2. 吸引性:用学术、专业且引人入胜的语气撰写,以吸引兴趣。3. 应用:融入具体的实践例子,例如微积分中要给出公式、严格证明,历史中要给出关键日期和人物,计算机操作中要给出代码。4.不需要给出参考文献。内容中不应包含广告或涉及隐私的信息。请记住,要针对大学生制作内容,他们可能拥有一些基础知识,但不是该领域的专家。内容应该详细且发人深省。请立即开始撰写教科书,不要使用图片,不要输出除了教科书以外的内容。
中学教科书
网页摘录:“{}”。创建一个与上述网页摘录中的某个概念相关的具有教育意义的内容,针对中学生,尽量长而详细。你可以自由补充其他相关知识。不能仅仅列出概念,而是要深入发展和详细探讨每个概念,因为我们优先考虑深入理解主题内容,而不是广度,不需要包含摘录中的所有内容。不应该使用像微积分这样的复杂大学级主题,因为这些通常不是中学的内容。如果主题是关于这些的,寻找一个更简单的科学替代内容来解释,并使用日常例子。例如,如果主题是“线性代数”,你可能会讨论如何通过将物体排列成行和列来解决谜题。避免使用技术术语和LaTeX,只讨论中学级别的主题。内容中不应包含广告或涉及隐私的信息。请直接开始撰写教育内容,不要输出除了教育内容以外的内容。
普通故事
写一个与以下文本片段相关的引人入胜的故事:“{}”。故事不需要提及片段中的所有内容,只需使用它来获得灵感并发挥创意!可以加入其它知识。故事应包括:1.小众概念或兴趣:深入研究特定的概念、爱好、兴趣或幽默情况 2.意想不到的情节转折或引人入胜的冲突,引入具有挑战性的情况或困境。3.对话:故事必须至少包含一个有意义的对话,以揭示人物深度、推进情节或揭开谜团的关键部分4.反思和洞察:以具有教育意义的新理解、启示的结论结束。5.故事中的人物应使用中国式的名字。请勿包含广告或涉及隐私的信息。请马上开始讲故事,不要输出除了故事以外的内容。
幼儿故事
网页摘录:“{}”创建一个与上述网页摘录中的某个概念相关的具有教育意义的儿童故事,重点针对对世界和人际交往零知识的5岁儿童。故事不需要提及片段中的所有内容,只需使用它来获得灵感并发挥创意。故事应该使用简单的术语。你可以补充额外的知识来帮助理解。使用易于理解的示例,并将 5 岁儿童可能提出的问题及其答案纳入故事中。故事应涵盖日常行为和常见物品的使用。不应该使用像微积分这样的复杂大学级主题,因为这些通常不是幼儿能理解的内容。如果主题是关于这些的,寻找一个更简单的科学替代内容来解释,并使用日常例子。例如,如果主题是“线性代数”,你可能会讨论如何通过将物体排列成行和列来解决谜题。请直接开始撰写故事,不要输出除了故事以外的内容。
wikihow教程
网页摘录:“{}”。以 WikiHow 的风格写一篇长而非常详细的教程,教程与此网页摘录有相关性。教程中需要包括对每个步骤的深入解释以及它如何帮助实现预期结果。你可以自由补充其他相关知识。确保清晰性和实用性,让读者能够轻松遵循教程完成任务。内容中不应包含广告或涉及隐私的信息。不要使用图像。请直接开始撰写教程。
我们诚邀对这一领域感兴趣的开发者和研究者关注和联系社区,共同推动技术的进步。敬请期待数据集的开源发布!
作者及单位
原文作者:俞一炅、戴紫赟、Tom Pei
单位:OpenCSG LLM Research Team

欢迎加入OpenCSG开源社区
OpenCSG作为一家大模型开源社区,基于线上线下一体的CSGHub平台上开源了丰富的训练数据资产、模型资产可以供广大的爱好者免费获取。其中OpenCSG的 Open是开源开放;C 代表 Converged resources,整合和充分利用的混合异构资源优势,算力降本增效;S 代表 Software Refinement,重新定义软件的交付方式,通过大模型驱动软件开发,人力降本增效;G 代表 Generative LM,大众化、普惠化和民主化的可商用的开源生成式大模型。OpenCSG的愿景是让每个行业、每个公司、每个人都拥有自己的模型。我们坚持开源开放的原则,将OpenCSG的大模型软件栈开源到社区。欢迎使用、反馈和参与共建,欢迎关注和Star⭐️
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https:// github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区

相关文章:
年度巨献 | OpenCSG开源最大中文合成数据集Chinese Cosmopedia
01 背景 近年来,生成式语言模型(GLM)的飞速发展正在重塑人工智能领域,尤其是在自然语言处理、内容创作和智能客服等领域展现出巨大潜力。然而,大多数领先的语言模型主要依赖于英文数据集进行训练,中文数据…...

Mac 上,终端如何开启 proxy
文章目录 为什么要这么做前提步骤查看 port查看代理的port配置 bash测试 为什么要这么做 mac 上的终端比较孤僻吧,虽然开了,但是终端并不走🪜…产生的现象就是,浏览器可以访问🌍,但是终端不可以访问&#…...

Linux中的进程入门
冯诺依曼体系结构 操作系统(Operator System) 进程控制块(PCB) struct task_struct{//该进程的所有属性//该进程对应的代码和属性地址struct task_struct* next; }; struct task_struct 内核结构体——>创建内核结构体对象(task_struct)…...

Redis面试真题总结(三)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 什么是缓存雪崩?该如何解决? 缓存雪崩是指…...
:大疆)
ARM/Linux嵌入式面经(三三):大疆
嵌入式工程师考察主要蕴含:C/C++,处理器的架构,操作系统(linux或嵌入式实时操作系统),常见硬件接口协议/总线,文件存储系统等几方面 文章目录 1)C/C++static作用,变量加入static以后在内存中存储位置的变化。static的作用变量加入static后在内存中存储位置的变化面试官…...

《DevOps实践指南》笔记-Part 2
一篇文章显得略长,本文对应第3-4章。前言、第1-2章请参考Part 1;第5-6章、附录、认证考试、参考资源等内容,请参考Part 3。 流动的技术实践 持续交付:降低在生产环境中部署和发布变更的风险。包括:打好自动化部署流水…...

树莓派智能语音助手实现音乐播放
树莓派语音助手从诞生的第一天开始,我就想着让它能像小爱音箱一样,可以语音控制播放音乐。经过这些日子的倒腾,今天终于实现了。 接下里,和大家分享下我的实现方法:首先音乐播放模块用的是我在上一篇博文写的《用sound…...

【sgCreateCallAPIFunctionParam】自定义小工具:敏捷开发→调用接口方法参数生成工具
<template><div :class"$options.name" class"sgDevTool"><sgHead /><div class"sg-container"><div class"sg-start"><div style"margin-bottom: 10px">参数列表[逗号模式]<el-too…...
完整版:NacosDocker 安装
第一步:先直接通过命令安装 Nacos docker run --name nacos2.2.3 -d -p 8848:8848 -e MODEstandalone f151dab7a111 第二步:创建 Docker 挂载目录 # 创建 log 目录 mkdir -p /root/nacos 第三步:将 Docker 容器的文件复制到挂载目录中 …...

mysql RR是否会导致幻读?
除了rr级别的当前读,都会幻读 mysql不同隔离级别: 而对于RC级别的语句级快照和RR级别的事务级快照的之间的区别,其实是由read_view生成的时机来实现的。 RC级别在执行语句时,会先关闭原来的read_view,重新生成新的r…...

一篇进阶Python深入理解函数之高阶函数与函数式编程
当我们深入探讨了函数的作用域与闭包,了解到函数不仅是代码的执行单元,还能通过闭包完成数据的封装与保护.接下来,我们将进一步挖掘函数的强大特性,尤其是高阶函数与函数式编程,帮助你更全面地理解 Python 中函数的特性与应用. 高阶函数 高阶函数是指接受一个或多个函数作为参…...

python中Web开发框架的使用
Python 的 Web 开发框架种类繁多,常见的有 Django 和 Flask 这两个框架。它们各有优点,适合不同类型的 Web 应用开发需求。下面,我将详细介绍这两大主流框架的使用方法,让你快速上手 Python 的 Web 开发。 1. Django Django 是一…...

【AI视频】Runway:Gen-2 运镜详解
博客主页: [小ᶻZ࿆] 本文专栏: AI视频 | Runway 文章目录 💯前言💯Camera Control(运镜)💯Camera Control功能测试Horizonta(左右平移)Vertical(上下平移࿰…...

Python “函数” ——Python面试100道实战题目练习,巩固知识、检查技术、成功就业
本文主要是作为Python中函数的一些题目,方便学习完Python的函数之后进行一些知识检验,感兴趣的小伙伴可以试一试,含选择题、判断题、实战题、填空题,答案在第五章。 在做题之前可以先学习或者温习一下Python的函数,推荐…...

[产品管理-15]:NPDP新产品开发 - 13 - 产品创新流程 - 具体产品的创新流程:精益生产与敏捷开发
目录 前言: 一、集成产品开发IPD模型——集成跨功能团队的产品开发 1.1 概述 1、IPD模型的核心思想 2、IPD模型的主要组成部分 3、IPD模型的实施步骤 4、IPD模型的优点 1.2 基于IPD系统的组织实践等级 1.3 IPD的优缺点 二、瀑布开发模型 1、定义与特点…...
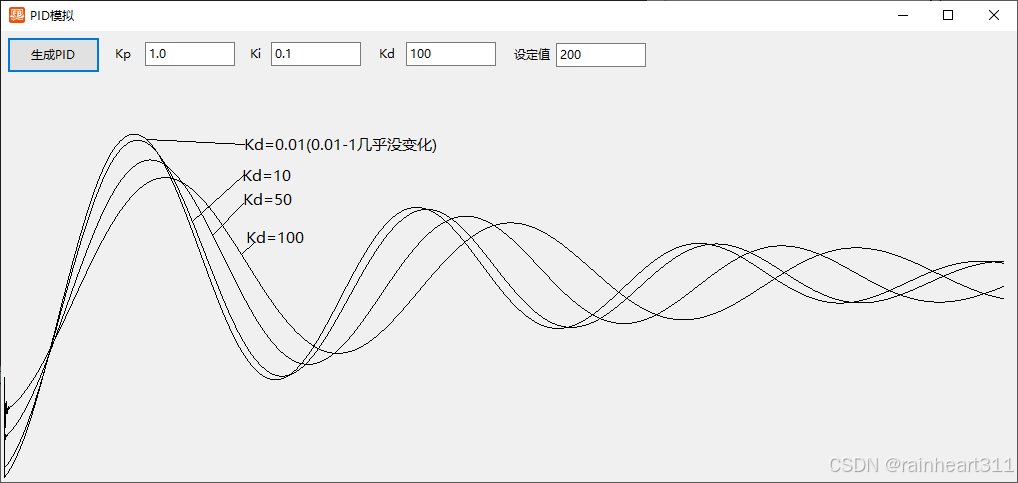
FB仿真模拟PID曲线数据
为了能直观的理解PID的参数调整与曲线数据的变化关系,使用FB写了一个模拟PID曲线数据的程序。 PID类如下: Type PIDController Private : kp_ As Double //比例增益 ki_ As Double //积分增益 kd_ As Double …...

【变化检测】基于ChangeStar建筑物(LEVIR-CD)变化检测实战及ONNX推理
主要内容如下: 1、LEVIR-CD数据集介绍及下载 2、运行环境安装 3、ChangeStar模型训练与预测 4、Onnx运行及可视化 运行环境:Python3.8,torch1.12.0cu113,onnxruntime-gpu1.12.0 likyoo变化检测源码:https://github.c…...

kafka动态认证 自定义认证 安全认证-亲测成功
kafka动态认证 自定义认证 安全认证-亲测成功 背景 Kafka默认是没有安全机制的,一直在裸奔。用户认证功能,是一个成熟组件不可或缺的功能。在0.9版本以前kafka是没有用户认证模块的(或者说只有SSL),好在kafka0.9版本…...

航空航司reese84逆向
reese84逆向 Reese84 是一种用于保护网站防止自动化爬虫抓取的防护机制,尤其是在航空公司网站等需要严格保护数据的平台上广泛使用。这种机制通过复杂的指纹识别和行为分析技术来检测和阻止非人类的互动。例如,Reese84 可以通过分析访问者的浏览器指纹、…...
【HTTP】请求“报头”,Referer 和 Cookie
Referer 描述了当前这个页面是从哪里来的(从哪个页面跳转过来的) 浏览器中,直接输入 URL/点击收藏夹打开的网页,此时是没有 referer。当你在 sogou 页面进行搜索时,新进入的网页就会有 referer 有一个非常典型的用…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹
Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹 在三维地理信息系统中,实时数据可视化一直是开发者面临的挑战之一。想象一下,当我们需要在地球表面追踪一架正在飞行的无人机,或者监控城市中数百辆出…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...