智能BI项目第五期
本期主要内容
- 系统问题分析
- 异步化业务流程分析
- 线程池讲解(入门 + 原理 + 实战)
- 系统异步化改造开发
1.系统问题分析
当系统面临大量用户请求时,我们后端的 AI 处理能力有限,例如服务器的内存、CPU、网络带宽等资源有限,这可能导致用户处在一个长时间的等待状态。为了确保平台的安全性,我们可能会限制用户的访问频率,即每秒或每几秒用户只能访问一次或几次。特别是在许多用户同时提交请求的情况下,服务器可能需要较长的时间来处理。
解决:在处理繁重任务的时候,我们应该考虑采用异步处理,避免让用户长时间等待。因此,本期的主题就是如何实现异步化,以有效解决这个问题。
异步化
同步:一件事情做完,再做另外一件事情(烧水后才能处理工作)。
异步:在处理一件事情的同时,可以处理另一件事情。
通常,如果想将同步变为异步,必须知道何时任务已经完成。因此,需要一个通知机制。
本项目流程
用户在点击提交后就不需要在当前界面等待,他们可以直接回到主界面,或者继续填写下一个需要生成或分析的数据。提交完成后,他们回到主页,在主页上就可以看到图表的生成状态。
如果图表已经生成好,那么我们的系统可以在界面的右上角添加一个消息通知功能,用户可以在那里看到相关信息,大致就是这样的一个流程。
标准异步化流程
1.当用户要进行耗时很长的操作时,点击提交后,不需要在界面空等,而是应该把这个任务保存到数据库中记录下来
2.用户要执行新任务时:
任务提交成功:
若程序存在空闲线程,可以立即执行此任务 若所有线程均繁忙,任务将入队列等待处理
任务提交失败:
比如所有线程都在忙碌且任务队列满了 选择拒绝此任务,不再执行
3.通过查阅数据库记录,发现提交失败的任务,并在程序空闲时将这些任务取出执行 程序(线程)
4.从任务队列中取出任务依次执行,每完成一项任务,就更新任务状态。
5.用户可以查询任务的执行状态,或者在任务执行成功或失败时接收通知(例如:发邮件、系统消息提示或短信),从而优化体验
6.对于复杂且包含多个环节的任务,在每个小任务完成时,要在程序(数据库中))记录任务的执行状态(进度)。
系统的业务流程总结
- 用户点击智能分析页的提交按钮时,先把图表立刻保存到数据库中(作为一个任务)。
- 用户可以在图表管理页面查看所有图表(已生成的、生成中的、生成失败)的信息和状态。
- 用户可以修改生成失败的图表信息,点击重新生成,以尝试再次创建图表。
原始架构图:

改造后的架构图
 存在的问题
存在的问题
- 任务队列的最大容量应该设置为多少?
- 程序怎么从任务队列中取出任务去执行?这个任务队列的流程怎么实现?怎么保证程序最多同时执行多少个任务?
线程池的讲解
为什么需要线程池?
- 线程的管理比较复杂(比如什么时候新增线程、什么时候减少空闲线程)
- 任务存取比较复杂(什么时候接受任务、什么时候拒绝任务、怎么保证大家不抢到同一个任务)
线程池的作用:帮助你轻松管理线程、协调任务的执行过程。 扩充:可以向线程池表达你的需求,比如最多只允许四个人同时执行任务。线程池就能自动为你进行管理。在任务紧急时,它会帮你将任务放入队列。而在任务不紧急或者还有线程空闲时,它会直接将任务交给空闲的线程,而不是放入队列。
线程池的实现
- 在 Spring 中,我们可以利用 ThreadPoolTaskExecutor 配合 @Async 注解来实现线程池(不太建议)。
ps.虽然 Spring 框架提供了线程池的实现,但并不特别推荐使用。因为 Spring 毕竟是一个框架,它进行了一定程度的封装,可能隐藏了一些细节。更推荐大家直接使用 Java 并发包中的线程池,请注意,这并不是绝对不使用 Spring 的线程池,对其使用有一定的保留意见。
- 在 Java 中,可以使用JUC并发编程包中的 ThreadPoolExecutor,来实现非常灵活地自定义线程池。
ps.建议学完 SpringBoot 并能够实现一个项目,以及学完 Redis 之后,再系统学习 Java 并发编程(JUC)。这样可以避免过早的压力和困扰,在具备一定实践基础的情况下,更好地理解并发编程的概念和应用。
1.创建配置类
在config目录下创建ThreadPoolExecutorConfig,并声明@Configuration
@Configuration 是 Spring 框架中的一个注解,它用于类级别,表明这个类是一个配置类,其目的是允许在应用程序上下文中定义额外的 bean。
package com.yupi.springbootinit.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.ThreadPoolExecutor;@Configuration
public class ThreadPoolExecutorConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor() {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor();return threadPoolExecutor;}
}
2. 线程池参数:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,threadFactory, defaultHandler);}
/**
该构造函数用于创建一个线程池:
设置核心线程数(corePoolSize);
设置最大线程数(maximumPoolSize);
设置空闲线程存活时间(keepAliveTime)及时间单位;
设置任务队列(workQueue)用于存放待执行任务;
设置线程工厂(ThreadFactory)用于创建新线程。
**/回归到我们的业务,要考虑系统最脆弱的环节(系统的瓶颈)在哪里? 现有条件:比如 AI 生成能力的并发是只允许 4 个任务同时去执行,AI 能力允许 20 个任务排队。
corePoolSize (核心线程数 => 正式员工数):正常情况下,我们的系统可以同时工作的线程数(随时就绪的状态)
maximumPoolSize (最大线程数 => 哪怕任务再多,你也最多招这些人):极限情况下,线程池最多可以拥有多少个线程?
keepAliveTime (空闲线程存活时间):非核心线程在没有任务的情况下,过多久要删除(理解为开除临时工),从而释放无用的线程资源。
TimeUnit unit (空闲线程存活时间的单位):分钟、秒 workQueue (工作队列):用于存放给线程执行的任务,存在一个队列的长度(一定要设置,不要说队列长度无限,因为也会占用资源) threadFactory (线程工厂):控制每个线程的生成、线程的属性(比如线程名) RejectedExecutionHandler (拒绝策略):任务队列满的时候,我们采取什么措施,比如抛异常、不抛异常、自定义策略
资源隔离策略:比如重要的任务(VIP 任务)一个队列,普通任务一个队列,保证这两个队列互不干扰。
3.线程工作流程
比如corePoolSize = 2,maximumPoolSize = 4,workQueue.size = 2
先来了两个请求,corePoolSize可以承受,当继续来请求,并且corePoolSize的两个请求还没有结束,那么就会先放到workQueue,如果workQueue满了,并且corePoolSize也没处理完,那么就会创建新的进程处理请求,但是所有线程数不能超过maximumPoolSize,如何超过了,会触发RejectedExecutionHandler拒绝策略。若是线程处理完请求后处于空闲状态,那么经过keepAliveTime unit 的时刻后,这个线程就会销毁
4.IO/CPU密集型
一般情况下,任务分为 IO 密集型和计算密集型两种。 计算密集型:吃 CPU,比如音视频处理、图像处理、数学计算等,一般是设置 corePoolSize 为 CPU 的核数 + 1(空余线程),可以让每个线程都能利用好 CPU 的每个核,而且线程之间不用频繁切换(减少打架、减少开销) IO 密集型:吃带宽/内存/硬盘的读写资源,corePoolSize 可以设置大一点,一般经验值是 2n 左右,但是建议以 IO 的能力为主。
5.线程池开发
基础配置类代码
package com.yupi.springbootinit.config;import org.jetbrains.annotations.NotNull;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;@Configuration
public class ThreadPoolExecutorConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor() {// 创建一个线程工厂ThreadFactory threadFactory = new ThreadFactory() {// 初始化线程数为 1private int count = 1;@Override// 每当线程池需要创建新线程时,就会调用newThread方法// @NotNull Runnable r 表示方法参数 r 应该永远不为null,// 如果这个方法被调用的时候传递了一个null参数,就会报错public Thread newThread(@NotNull Runnable r) {// 创建一个新的线程,记得要把参数传进去Thread thread = new Thread(r);// 给新线程设置一个名称,名称中包含线程数的当前值thread.setName("线程" + count);// 线程数递增count++;// 返回新创建的线程return thread;}};// 创建一个新的线程池,线程池核心大小为2,最大线程数为4,// 非核心线程空闲时间为100秒,任务队列为阻塞队列,长度为4,使用自定义的线程工厂创建线程ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 100, TimeUnit.SECONDS,new ArrayBlockingQueue<>(4), threadFactory);// 返回创建的线程池return threadPoolExecutor;}
}
为了方便测试效果,新建一个controller(控制器),以接口的方式实时控制这个线程池,查看线程池的参数;
复制controller目录下的ChartController,并重命名为QueueController,修改一下,删除多余的内容。
测试类代码
package com.yupi.springbootinit.controller;import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadPoolExecutor;/*** 队列测试** @author <a href="https://github.com/liyupi">程序员鱼皮</a>* @from <a href="https://yupi.icu">编程导航知识星球</a>*/
@RestController
@RequestMapping("/queue")
@Slf4j
@Profile({"dev","local"})
//指定只能开发、本地环境生效;正式上线前要把测试去掉,不要把测试暴露出去。
public class QueueController {@Resource// 自动注入一个线程池的实例private ThreadPoolExecutor threadPoolExecutor;@GetMapping("/add")// 接收一个参数name,然后将任务添加到线程池中public void add(String name) {// 使用CompletableFuture运行一个异步任务CompletableFuture.runAsync(() -> {// 打印一条日志信息,包括任务名称和执行线程的名称log.info("任务执行中:" + name + ",执行人:" + Thread.currentThread().getName());try {// 让线程休眠10分钟,模拟长时间运行的任务Thread.sleep(600000);} catch (InterruptedException e) {e.printStackTrace();}// 异步任务在threadPoolExecutor中执行}, threadPoolExecutor);}@GetMapping("/get")// 该方法返回线程池的状态信息public String get() {// 创建一个HashMap存储线程池的状态信息Map<String, Object> map = new HashMap<>();// 获取线程池的队列长度int size = threadPoolExecutor.getQueue().size();// 将队列长度放入map中map.put("队列长度", size);// 获取线程池已接收的任务总数long taskCount = threadPoolExecutor.getTaskCount();// 将任务总数放入map中map.put("任务总数", taskCount);// 获取线程池已完成的任务数long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();// 将已完成的任务数放入map中map.put("已完成任务数", completedTaskCount);// 获取线程池中正在执行任务的线程数int activeCount = threadPoolExecutor.getActiveCount();// 将正在工作的线程数放入map中map.put("正在工作的线程数", activeCount);// 将map转换为JSON字符串并返回return JSONUtil.toJsonStr(map);}
}
当核心线程满了,等待队列也满了,会创建新线程来处理,这时候先处理新的请求,而不是请求等待队列里的请求,当达到最大线程容量时,继续发送请求会报错
1、2由核心队列处理,3、4、5、6全部进入等待队列,7、8由最大线程数处理、9以后报错
前后端异步化改造
实现工作流程
- 给 chart 表新增任务状态字段(比如排队中、执行中、已完成、失败),任务执行信息字段(用于记录任务执行中、或者失败的一些信息)
- 用户点击智能分析页的提交按钮时,先把图表立刻保存到数据库中,然后提交任务
- 任务:先修改图表任务状态为 “执行中”。等执行成功后,修改为 “已完成”、保存执行结果;执行失败后,状态修改为 “失败”,记录任务失败信息。
- 用户可以在图表管理页面查看所有图表(已生成的、生成中的、生成失败)的信息和状态 → (优化点)
- 用户可以修改生成失败的图表信息,点击重新生成 → (优化点)
1.新增任务字段
先对sql进行归档(修改建表语句)

再去修改图表信息,记得到实体类补充这两个字段

2.任务执行逻辑
之前咱们的业务流程是校验 → 限流 → 构造用户输入、调用 AI;
现在可以把调用 AI 变成提交任务。

先修改图表任务状态为 “执行中”,减少重复执行的风险、同时让用户知道执行状态。等执行成功后,修改为 “已完成”、保存执行结果;执行失败后,状态修改为 “失败”,记录任务失败信息。
智能分析将会被拆分为同步和异步操作。由于异步操作没有返回值信息,我们无法解析并返回图表信息,这导致可视化图表和分析结果无法被展示。因此,我们保留之前的智能分析结果;
先注入刚刚的线程池实例到控制层中
@Resourceprivate ThreadPoolExecutor threadPoolExecutor;/*** 智能分析(异步)** @param multipartFile* @param genChartByAiRequest* @param request* @return*/
@PostMapping("/gen/async")
public BaseResponse<BiResponse> genChartByAiAsync(@RequestPart("file") MultipartFile multipartFile,GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {String name = genChartByAiRequest.getName();String goal = genChartByAiRequest.getGoal();String chartType = genChartByAiRequest.getChartType();// 校验ThrowUtils.throwIf(StringUtils.isBlank(goal), ErrorCode.PARAMS_ERROR, "目标为空");ThrowUtils.throwIf(StringUtils.isNotBlank(name) && name.length() > 100, ErrorCode.PARAMS_ERROR, "名称过长");// 校验文件long size = multipartFile.getSize();String originalFilename = multipartFile.getOriginalFilename();// 校验文件大小final long ONE_MB = 1024 * 1024L;ThrowUtils.throwIf(size > ONE_MB, ErrorCode.PARAMS_ERROR, "文件超过 1M");// 校验文件大小缀 aaa.pngString suffix = FileUtil.getSuffix(originalFilename);final List<String> validFileSuffixList = Arrays.asList("xlsx", "xls");ThrowUtils.throwIf(!validFileSuffixList.contains(suffix), ErrorCode.PARAMS_ERROR, "文件后缀非法");User loginUser = userService.getLoginUser(request);// 限流判断,每个用户一个限流器redisLimiterManager.doRateLimit("genChartByAi_" + loginUser.getId());// 指定一个模型id(把id写死,也可以定义成一个常量)long biModelId = 1659171950288818178L;// 分析需求:// 分析网站用户的增长情况// 原始数据:// 日期,用户数// 1号,10// 2号,20// 3号,30// 构造用户输入StringBuilder userInput = new StringBuilder();userInput.append("分析需求:").append("\n");// 拼接分析目标String userGoal = goal;if (StringUtils.isNotBlank(chartType)) {userGoal += ",请使用" + chartType;}userInput.append(userGoal).append("\n");userInput.append("原始数据:").append("\n");// 压缩后的数据String csvData = ExcelUtils.excelToCsv(multipartFile);userInput.append(csvData).append("\n");// 先把图表保存到数据库中Chart chart = new Chart();chart.setName(name);chart.setGoal(goal);chart.setChartData(csvData);chart.setChartType(chartType);// 插入数据库时,还没生成结束,把生成结果都去掉
// chart.setGenChart(genChart);
// chart.setGenResult(genResult);// 设置任务状态为排队中chart.setStatus("wait");chart.setUserId(loginUser.getId());boolean saveResult = chartService.save(chart);ThrowUtils.throwIf(!saveResult, ErrorCode.SYSTEM_ERROR, "图表保存失败");// 在最终的返回结果前提交一个任务// todo 建议处理任务队列满了后,抛异常的情况(因为提交任务报错了,前端会返回异常)CompletableFuture.runAsync(() -> {// 先修改图表任务状态为 “执行中”。等执行成功后,修改为 “已完成”、保存执行结果;执行失败后,状态修改为 “失败”,记录任务失败信息。(为了防止同一个任务被多次执行)Chart updateChart = new Chart();updateChart.setId(chart.getId());// 把任务状态改为执行中updateChart.setStatus("running");boolean b = chartService.updateById(updateChart);// 如果提交失败(一般情况下,更新失败可能意味着你的数据库出问题了)if (!b) {handleChartUpdateError(chart.getId(), "更新图表执行中状态失败");return;}// 调用 AIString result = aiManager.doChat(biModelId, userInput.toString());String[] splits = result.split("-----");if (splits.length < 3) {handleChartUpdateError(chart.getId(), "AI 生成错误");return;}String genChart = splits[1].trim();String genResult = splits[2].trim();// 调用AI得到结果之后,再更新一次Chart updateChartResult = new Chart();updateChartResult.setId(chart.getId());updateChartResult.setGenChart(genChart);updateChartResult.setGenResult(genResult);updateChartResult.setStatus("succeed");boolean updateResult = chartService.updateById(updateChartResult);if (!updateResult) {handleChartUpdateError(chart.getId(), "更新图表成功状态失败");}},threadPoolExecutor);BiResponse biResponse = new BiResponse();
// biResponse.setGenChart(genChart);
// biResponse.setGenResult(genResult);biResponse.setChartId(chart.getId());return ResultUtils.success(biResponse);
}
// 上面的接口很多用到异常,直接定义一个工具类
private void handleChartUpdateError(long chartId, String execMessage) {Chart updateChartResult = new Chart();updateChartResult.setId(chartId);updateChartResult.setStatus("failed");updateChartResult.setExecMessage(execMessage);boolean updateResult = chartService.updateById(updateChartResult);if (!updateResult) {log.error("更新图表失败状态失败" + chartId + "," + execMessage);}
}
如果为了给面试官看,建议把这两种处理方式都保留,你可以向面试官解释为什么要引入异步流程,异步的优点,以及如何实现异步。只要谈到线程池,有超过 50% 的可能性面试官会问你关于线程池的核心参数。这时你可以把本期中介绍的内容全都讲出来,相信面试官会认为你的思路非常清晰
3.前端开发
来到前端,在routes.ts内新增智能分析(异步)的路由。

复制page目录下的AddChart目录,粘贴至page目录下,并重命名为AddChartAsync

修改智能分析(异步)页面:
修改注释和页面名称。



修改类名为add-chart-async。

然后把一些没用到的东西删掉,再修改提示词

如果分析成功,就把表单清空,先定义一个 form,然后在表单引用。
 引用 form 之后,如果说分析成功就清空表单内容。
引用 form 之后,如果说分析成功就清空表单内容。

最终代码
import { genChartByAiUsingPOST } from '@/services/yubi/chartController';
import { UploadOutlined } from '@ant-design/icons';
import { Button, Card, Form, Input, message, Select, Space, Upload } from 'antd';
import TextArea from 'antd/es/input/TextArea';
import React, { useState } from 'react';
import {useForm} from "antd/es/form/Form";/*** 添加图表(异步)页面* @constructor*/
const AddChartAsync: React.FC = () => {// useForm:and design操作表单的语法const [form] = useForm();// 提交中的状态,默认未提交const [submitting, setSubmitting] = useState<boolean>(false);/*** 提交* @param values*/const onFinish = async (values: any) => {// 如果已经是提交中的状态(还在加载),直接返回,避免重复提交if (submitting) {return;}// 当开始提交,把submitting设置为truesetSubmitting(true);// 对接后端,上传数据const params = {...values,file: undefined,};try {// 需要取到上传的原始数据file→file→originFileObj(原始数据)const res = await genChartByAiUsingPOST(params, {}, values.file.file.originFileObj);// 正常情况下,如果没有返回值就分析失败,有,就分析成功if (!res?.data) {message.error('分析失败');} else {message.success('分析任务提交成功,稍后请在我的图表页面查看'); // 重置所有字段form.resetFields();} // 异常情况下,提示分析失败+具体失败原因} catch (e: any) {message.error('分析失败,' + e.message);}// 当结束提交,把submitting设置为falsesetSubmitting(false);}; return (<div className="add-chart-async"><Card title="智能分析"><Formform={form}name="addChart"labelAlign="left" labelCol={{ span: 4 }}wrapperCol={{ span: 16 }}onFinish={onFinish}initialValues={{ }}><Form.Item name="goal" label="分析目标" rules={[{ required: true, message: '请输入分析目标!' }]}><TextArea placeholder="请输入你的分析需求,比如:分析网站用户的增长情况"/></Form.Item><Form.Item name="name" label="图表名称"><Input placeholder="请输入图表名称" /></Form.Item><Form.Itemname="chartType"label="图表类型"><Selectoptions={[{ value: '折线图', label: '折线图' },{ value: '柱状图', label: '柱状图' },{ value: '堆叠图', label: '堆叠图' },{ value: '饼图', label: '饼图' },{ value: '雷达图', label: '雷达图' },]}/></Form.Item><Form.Itemname="file"label="原始数据"><Upload name="file" maxCount={1}><Button icon={<UploadOutlined />}>上传 CSV 文件</Button></Upload></Form.Item><Form.Item wrapperCol={{ span: 16, offset: 4 }}><Space><Button type="primary" htmlType="submit" loading={submitting} disabled={submitting}>提交</Button><Button htmlType="reset">重置</Button></Space></Form.Item></Form></Card></div>);
};
export default AddChartAsync;
如果图表生成成功就展示图表,没有生成成功就展示现在的状态(进度条、转圈圈);
访问 ant.design 组件库 找一下有没有失败的组件。

修改我的图表页

 然后在左下图的内容中加一层判断。
然后在左下图的内容中加一层判断。

最终代码
import { listMyChartByPageUsingPOST } from '@/services/yubi/chartController';
import { useModel } from '@@/exports';
import {Avatar, Card, List, message, Result} from 'antd';
import ReactECharts from 'echarts-for-react';
import React, { useEffect, useState } from 'react';
import Search from "antd/es/input/Search";/*** 我的图表页面* @constructor*/
const MyChartPage: React.FC = () => {const initSearchParams = {// 默认第一页current: 1,// 每页展示4条数据pageSize: 4,sortField: 'createTime',sortOrder: 'desc',};const [searchParams, setSearchParams] = useState<API.ChartQueryRequest>({ ...initSearchParams });// 从全局状态中获取到当前登录的用户信息const { initialState } = useModel('@@initialState');const { currentUser } = initialState ?? {};const [chartList, setChartList] = useState<API.Chart[]>();const [total, setTotal] = useState<number>(0);// 用来控制页面是否加载const [loading, setLoading] = useState<boolean>(true);const loadData = async () => {// 当触发搜索,把loading设置为truesetLoading(true);try {const res = await listMyChartByPageUsingPOST(searchParams);if (res.data) {setChartList(res.data.records ?? []);setTotal(res.data.total ?? 0);// 有些图表有标题,有些没有,直接把标题全部去掉if (res.data.records) {res.data.records.forEach(data => {// 要把后端返回的图表字符串改为对象数组,如果后端返回空字符串,就返回'{}'const chartOption = JSON.parse(data.genChart ?? '{}');// 把标题设为undefinedchartOption.title = undefined;// 然后把修改后的数据转换为json设置回去data.genChart = JSON.stringify(chartOption);})}} else {message.error('获取我的图表失败');}} catch (e: any) {message.error('获取我的图表失败,' + e.message);}// 搜索结束设置为falsesetLoading(false);};useEffect(() => {loadData();}, [searchParams]);return (<div className="my-chart-page">{/* 引入搜索框 */}<div>{/* 当用户点击搜索按钮触发 一定要把新设置的搜索条件初始化,要把页面切回到第一页;如果用户在第二页,输入了一个新的搜索关键词,应该重新展示第一页,而不是还在搜第二页的内容*/}<Search placeholder="请输入图表名称" enterButton loading={loading} onSearch={(value) => {// 设置搜索条件setSearchParams({// 原始搜索条件...initSearchParams,// 搜索词name: value,})}}/></div><div className="margin-16" /><List/*栅格间隔16像素;xs屏幕<576px,栅格数1;sm屏幕≥576px,栅格数1;md屏幕≥768px,栅格数1;lg屏幕≥992px,栅格数2;xl屏幕≥1200px,栅格数2;xxl屏幕≥1600px,栅格数2*/grid={{gutter: 16,xs: 1,sm: 1,md: 1,lg: 2,xl: 2,xxl: 2,}}pagination={{/*page第几页,pageSize每页显示多少条;当用户点击这个分页组件,切换分页时,这个组件就会去触发onChange方法,会改变咱们现在这个页面的搜索条件*/onChange: (page, pageSize) => {// 当切换分页,在当前搜索条件的基础上,把页数调整为当前的页数setSearchParams({...searchParams,current: page,pageSize,})},// 显示当前页数current: searchParams.current,// 页面参数改成自己的pageSize: searchParams.pageSize,// 总数设置成自己的total: total,}}loading={loading}dataSource={chartList}renderItem={(item) => (<List.Item key={item.id}><Card style={{ width: '100%' }}><List.Item.Meta// 把当前登录用户信息的头像展示出来avatar={<Avatar src={currentUser && currentUser.userAvatar} />}title={item.name}description={item.chartType ? '图表类型:' + item.chartType : undefined}/><>{// 当状态(item.status)为'wait'时,显示待生成的结果组件item.status === 'wait' && <><Result// 状态为警告status="warning"title="待生成"// 子标题显示执行消息,如果执行消息为空,则显示'当前图表生成队列繁忙,请耐心等候'subTitle={item.execMessage ?? '当前图表生成队列繁忙,请耐心等候'}/></>}{item.status === 'running' && <><Result// 状态为信息status="info"title="图表生成中"// 子标题显示执行消息subTitle={item.execMessage}/></>}{// 当状态(item.status)为'succeed'时,显示生成的图表item.status === 'succeed' && <><div style={{ marginBottom: 16 }} /><p>{'分析目标:' + item.goal}</p><div style={{ marginBottom: 16 }} /><ReactECharts option={item.genChart && JSON.parse(item.genChart)} /></>}{// 当状态(item.status)为'failed'时,显示生成失败的结果组件item.status === 'failed' && <><Resultstatus="error"title="图表生成失败"subTitle={item.execMessage}/></>}</></Card></List.Item>)}/></div>);
};
export default MyChartPage;
最终情况:
此时发起请求后可以在这里等待AI处理完成,返回结果

过一段时间再来看就已经生成了

优化思路
肯定有些同学会倾向于同步方式,因为他们可以随时查看结果,即使可能需要等待十几秒或者 20 秒。然而,另一些同学可能会觉得如果需要等待一分钟或者五分钟的话,异步方式可能会更合适。实际上,你也可以选择实时更新,比如每隔几秒刷新一下页面,自动获取新结果。批量异步也是一种可行的方式。
另外,还有一种策略。你可以根据系统当前的负载动态地调整用户查询的处理方式。比如,如果系统当前状态良好,就可以选择同步返回结果。而如果用户提交请求后发现系统非常繁忙,预计需要等待很长时间,那么就可以选择异步处理方式。这种思考方式在实际的企业项目开发中也是很常见的。
除了刚刚提到的一些点,我们还可以使用定时任务来处理失败的图表,添加重试机制。此外,我们也可以更精确地预见AI生成错误,并在后端进行异常处理,如提取正确的字符串。例如,AI 说一些多余的话,我们就需要提取出正确的信息。同时,如果任务没有提交,我们可以使用定时任务将其提取出来。我们还可以为任务增加一个超时时间。如果超时,任务将自动标记为失败,这就是超时控制,这一点非常重要。对于 AI 生成的脏数据,会导致最后出现错误,因此前端也需要进行异常处理,不能仅仅依赖于后端。
🐟之前写过一篇关于反向压力的文章,可以看一下。刚刚提到了一点,那就是在系统压力大的时候,使用异步,而在系统压力小的时候,使用同步,这就是反向压力的概念。
进一步扩展一下,关于我们的线程池,现在的核心参数不是设定为二嘛。实际上,如果 AI 最多允许四个任务同时执行,我们是否可以提前确认 AI 当前的业务是否繁忙,即我们调用的第三方 API 是否还有多余的资源给我们使用。如果他表示资源已经耗尽,我们为了保证系统的稳定性,是否可以将核心线程数调小一些。反之,如果我们询问 AI 第三方并发现它的状态是空闲,我们是否可以将核心线程数增加,以此来提高系统性能。这种通过下游服务来调整你的业务以及核心线程池参数,进而改变你的系统策略的方式就是反向压力。
例如,你发现当前 AI 服务的任务队列中没有任何人提交任务,那么你是否可以提高使用率。这其实是一个很好的点,如果你能在简历上写到反向压力,将会是一个很大的加分项。反向压力其实是我们在做大数据系统中,特别是在做实时数据流系统时经常会用到的一个术语。我们是不是可以在任务执行成功或失败后,给用户发送消息通知。比如说,在图表页面增加一个刷新或者定时自动刷新的按钮,以保证用户能够获取到图表的最新状态。这就是前端轮询的技术。还有就是在任务执行过程中,我们可以向用户发送消息通知,虽然这可能比较复杂。这东西后面🐟可能会带大家做这个系统。但是在短期内,大家可以自己尝试实现,如通过数据库记录消息,这是最简单的方式。当然还有其他的方式,如 websocket 实时通知或者 server side event,这都是实时的。
优化点
- guava Retrying 重试机制
- 提前考虑到 AI 生成错误的情况,在后端进行异常处理(比如 AI 说了多余的话,提取正确的字符串)
- 如果说任务根本没提交到队列中(或者队列满了),是不是可以用定时任务把失败状态的图表放到队列中(补偿)
- 建议给任务的执行增加一个超时时间,超时自动标记为失败(超时控制)
- 反向压力:https://zhuanlan.zhihu.com/p/404993753,通过调用的服务状态来选择当前系统的策略(比如根据 AI 服务的当前任务队列数来控制咱们系统的核心线程数),从而最大化利用系统资源。
- 我的图表页面增加一个刷新、定时自动刷新的按钮,保证获取到图表的最新状态(前端轮询)
- 任务执行成功或失败,给用户发送实时消息通知(实时:websocket、server side event)
下期:RabbitMQ 分布式消息队列(消息持久化、多机共享、可扩展性)
相关文章:
智能BI项目第五期
本期主要内容 系统问题分析异步化业务流程分析线程池讲解(入门 原理 实战)系统异步化改造开发 1.系统问题分析 当系统面临大量用户请求时,我们后端的 AI 处理能力有限,例如服务器的内存、CPU、网络带宽等资源有限,…...
Android-UI设计
控件 控件是用户与应用交互的元素。常见的控件包括: 按钮 (Button):用于执行动作。文本框 (EditText):让用户输入文本。复选框 (CheckBox):允许用户选择或取消选择某个选项。单选按钮 (RadioButton):用于在多个选项中…...

docker desktop windows stop
服务docker改为启动 cmd下查看docker版本 {"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://hub.atomgit.com/"]…...
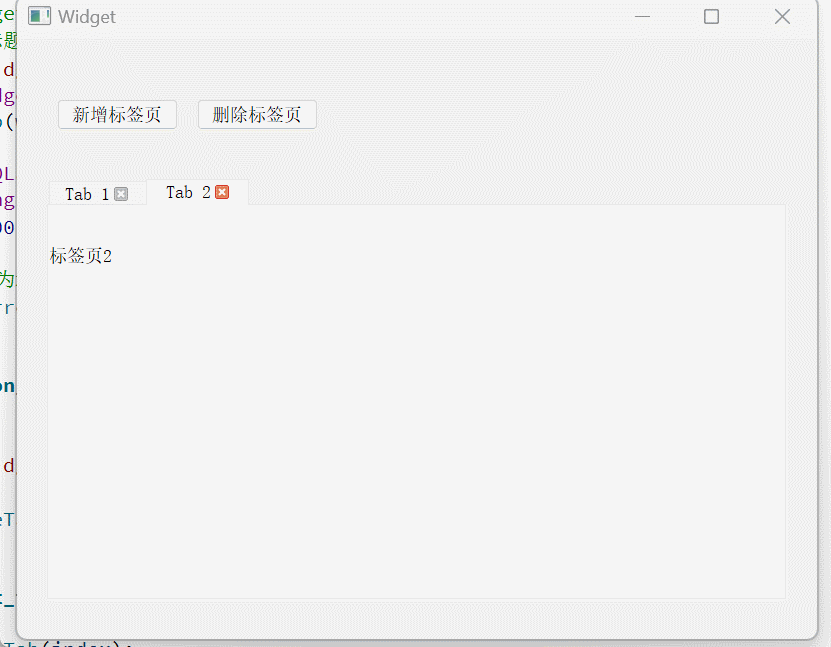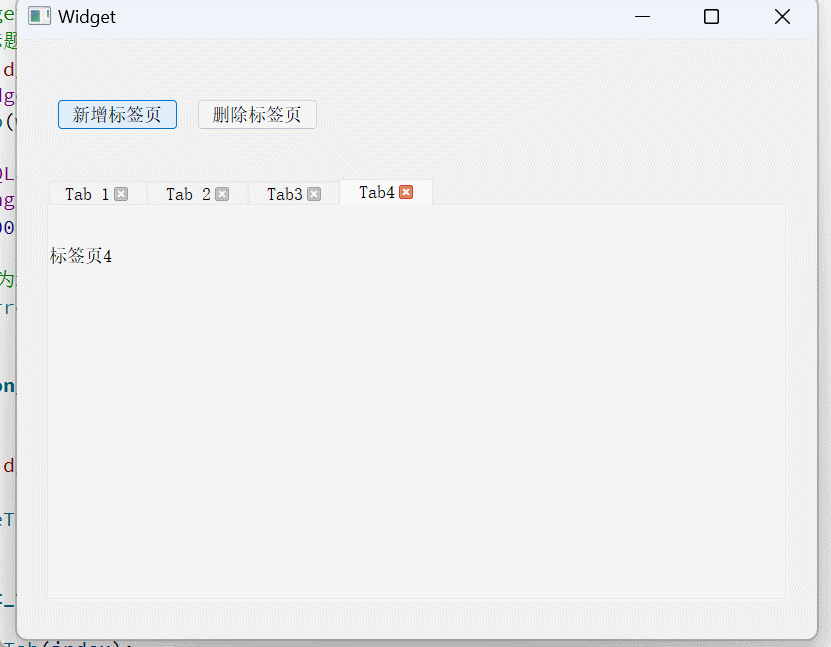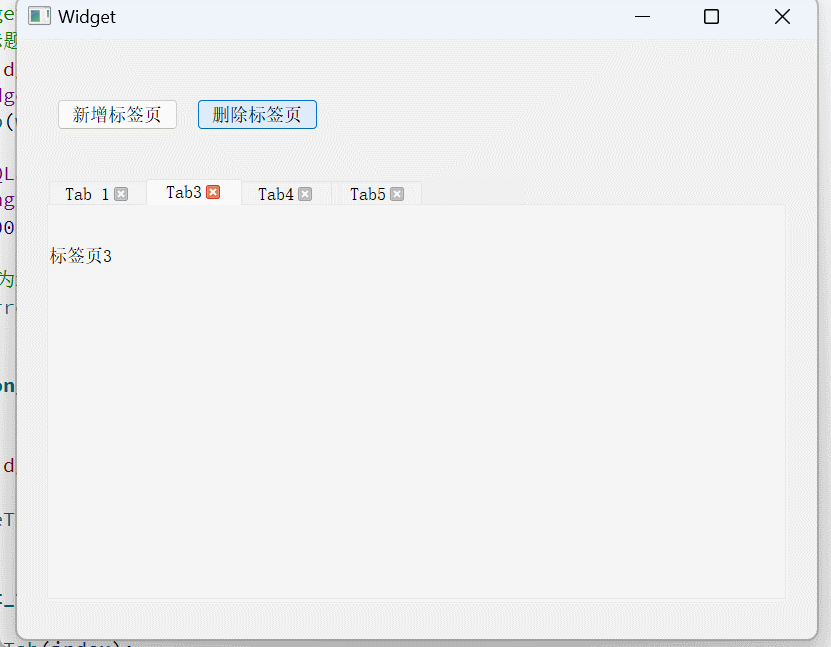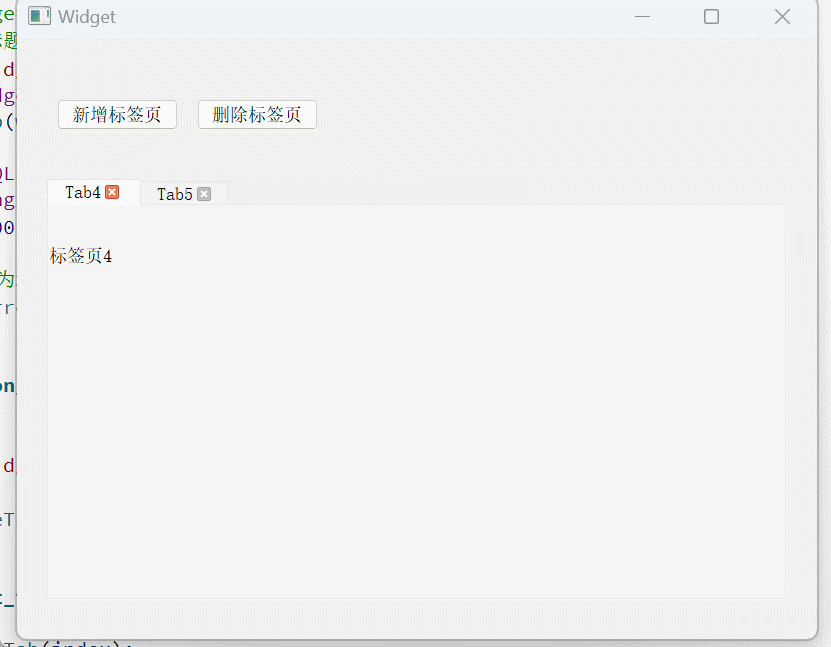
Qt容器类控件——QGroupBox和QTabWidget
文章目录 QGroupBox又来点餐QTabWidget使用演示 QGroupBox 容器类控件即里面可以容纳其他的控件 QGroupBox叫做分组框,可以把其他控件放在里面作为一组 QGroupBox的存在,只是为了让界面更好看一点,并不实现实质性的功能。 当界面较复杂的时候…...

qt-creator-10.0.2之后版本的jom.exe构建和编译速度慢下来了
1、Qt的IDE一直在升级,qt-creator的新版本下载地址 https://download.qt.io/official_releases/qtcreator/ 2、本人一直用的是qt-creator-10.0.2版本,官网历史仓库可以下载安装包qt-creator-opensource-windows-x86_64-10.0.2.exe https://download.qt…...

ESP32-WROOM-32 [创建AP站点-TCP服务端-数据收发]
简介 ESP32 创建TCP Server AP站点, PC作为客户端连接站点并收发数据 指令介绍 注意,下面指令需要在最后加上CRLF, 也就是\r\n(回车换行) ATRESTORE // 恢复出厂设置 ATCWMODE2 // 设置 Wi-Fi 模式为 softAP ATCIPMODE0 // 需要数据传输模式改为0, 普通…...

工业机器视觉中的常见需求
目录 学习目的 熟系 Halcon的原因 专业性强: 高性能: 丰富的功能库 学习 OpenCV 的原因 开源与免费: 灵活性与可扩展性: 广泛的应用: 学习资源丰富: 总结 学习背景 工业视觉检测中常见分类 一、定…...

JavaWeb的Filter详解
过滤器Filter 什么是Filter? 依据字面上的中文意思为过滤器。Filter的作用 当用户的请求到达指定的URL之前,可以借助Filter来改变这些请求的内容;同样地,当响应结果到达客户端之前,可以使用Filter修改输出的内容。什么…...

【iOS】KVC的学习
【iOS】KVC的学习 文章目录 【iOS】KVC的学习前言KVC定义KVC设值KVC取值KVC使用keyPathKVC处理异常处理nil异常 KVC的一些应用修改动态的设置值实现高阶的消息传递 小结 前言 笔者简单学习了有关与KVC的相关内容,这里写一篇博客简单介绍一下相关内容。 KVC 定义 KV…...

影刀RPA实战:网页爬虫之药品数据
1 实战目标 这次给大家带来的实战示例是采集中国医药信息平台上的药品数据,主要获取药品名称,介绍,药品类型,处方类型,医保类型,参考价格,药品成分,性状,适应病症&#…...

python禁止位置传参函数
这种函数定义方式使用了 Python 3.x 中的关键字参数(keyword-only arguments)的特性,通过在参数列表中使用 * 符号作为分隔符,来明确指示该函数之后的参数必须使用关键字(即参数名)来传递,而不能…...

java面试题第一弹
Java 的基本数据类型有哪些? Java 的基本数据类型(primitive data types)包括以下八种: byte: 尺寸:1 字节(8 位)。范围:-128 到 127。用途:节省内存&#x…...

住宅HTTP代理:提升网络隐私与安全的新选择
在互联网时代,我们的在线隐私和安全变得越来越重要。无论是浏览网页、进行在线交易,还是访问受限内容,住宅HTTP代理都能为我们提供一种可靠的解决方案。今天,我们就来深入探讨一下住宅HTTP代理,看看它是如何帮助我们提…...

字符串函数(2)
目录 前言1. strlen1.1 strlen函数的理解和使用1.2 strlen函数的模拟实现 2. strcpy2.1 strcpy函数的理解和使用2.2 strcpy函数的模拟实现 3.strcat3.1 strcat函数的理解和使用3.2 strcat 函数的模拟实现 前言 在上一篇文章中,我们对字符分类函数和字符转换函数进行…...

Linux--守护进程与会话
进程组 概念 进程组就是一个或多个进程的集合。 一个进程组可以包含多个进程。 下面我们通过一句简单的命令行来展示: 为什么会有进程组? 批量操作:进程组允许将多个进程组织在一起,形成一个逻辑上的整体。当需要对多个进程…...

C++ 笔试常用算法模板
C 笔试常用算法模板 一、二叉树遍历DFSBFS 二、回溯模板三、动态规划01背包朴素版本滚动数组优化 完全背包朴素版本滚动数组优化 最长递增子序列朴素版本贪心二分优化 最长公共子序列最长回文子串 四、图建图邻接矩阵邻接表 图的遍历DFSBFS 拓扑排序并查集最小生成树Kruskalpri…...
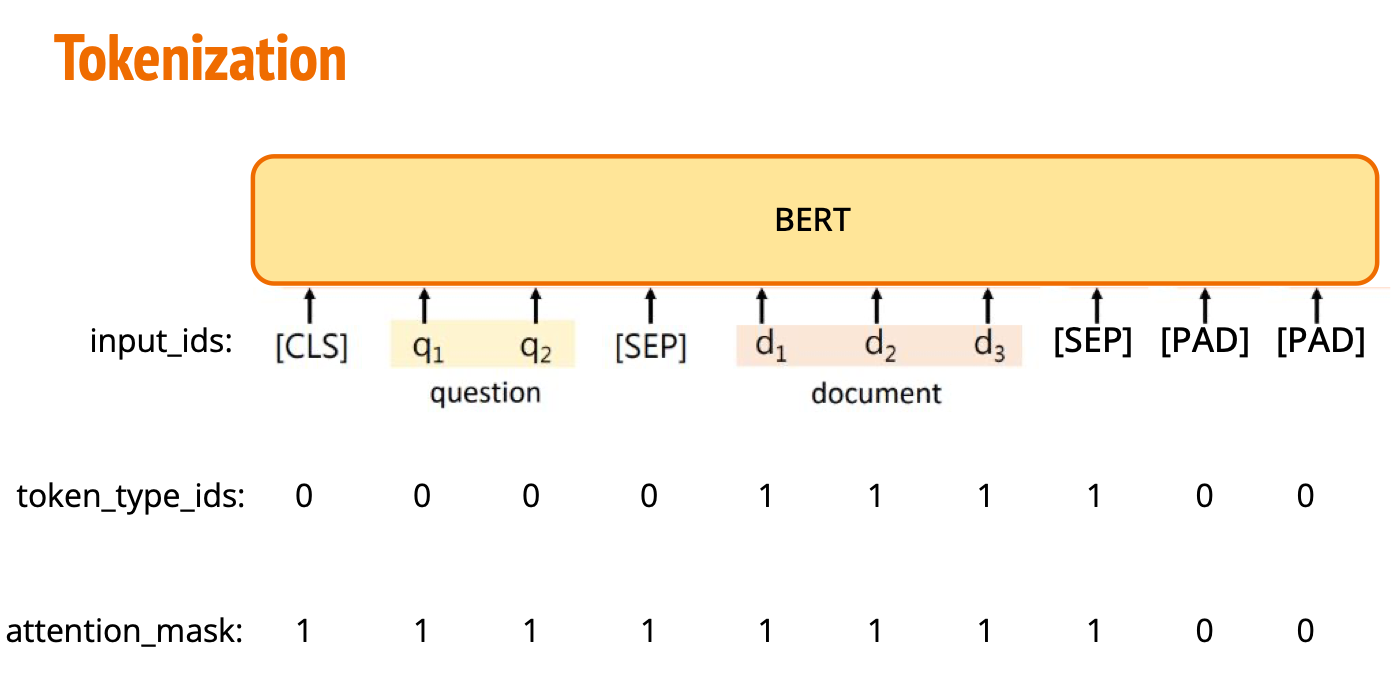
李宏毅2023机器学习作业HW07解析和代码分享
ML2023Spring - HW7 相关信息: 课程主页 课程视频 Kaggle link 回来了 : ) Sample code HW07 视频 HW07 PDF 个人完整代码分享: GitHub | Gitee | GitCode P.S. HW7 的代码都很易懂,可以和 2024 年的新课:生成式AI导论做一个很好的衔接&#…...

ansible远程自动化运维、常用模块详解
一、ansible是基于python开发的配置管理和应用部署工具;也是自动化运维的重要工具;可以批量配置、部署、管理上千台主机;只需要在一台主机配置ansible就可以完成其它主机的操作。 1.操作模式: 模块化操作,命令行执行…...

【若依框架】按时间查询数据的操作
【若依框架】按时间查询数据的操作 若依框架按起止时间查询数据示例: Date tempDate DateUtil.offsetDay(new Date(), -days);Map<String, Object> map new HashMap<>();map.put("beginRecordTime", DateUtil.beginOfHour(tempDate));map.…...

人工智能将来好就业吗?
人工智能将来好就业吗? 随着科技的不断进步,人工智能(AI)正逐渐成为推动全球经济发展的核心力量之一。从智能机器人到自动驾驶汽车,从语音识别到图像分析,AI正在改变我们的工作方式以及我们与世界的互动方式。那么&am…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...