深度学习01-概述



深度学习是机器学习的一个子集。机器学习是实现人工智能的一种途径,而深度学习则是通过多层神经网络模拟人类大脑的方式进行学习和知识提取。
深度学习的关键特点:
1. 自动提取特征:与传统的机器学习方法不同,深度学习不需要手动设计特征。传统机器学习依赖人工进行特征工程,而深度学习可以通过算法自动提取特征,从而提高分类、预测等任务的精度。
2. 模仿人脑的结构:深度学习通过使用多层神经网络(Deep Neural Networks)来模拟人类大脑的学习机制,学习数据的深层次特征。
3. 黑箱模型:由于深度学习涉及大量的参数和复杂的网络结构,模型的可解释性较差,因此常常被视为“黑箱”算法。
4. 应用广泛:深度学习广泛应用于图像识别、语音识别、自然语言处理等领域,能够处理大量复杂的非结构化数据。
模型的可解释性差主要是指模型在做出预测或决策时,我们很难清楚地了解其内部的工作机制和每个决策的依据。对于深度学习模型,尤其是深度神经网络,这个问题尤为突出,原因如下:
因此我们在学习深度学习的时候,我们普通人不必要去深究他这个为什么预测好,这个为什么预测差,因为顶尖的科学家,在目前而言也没法解释出来,所以。我们不太注重可解释性,但是深度学习的算法有时候的结果准确率会超过人类。还有一个好处就是,不需要人工的做特征工程的。
1. 复杂的结构:
-
深度学习模型通常包含多层神经网络,每层可能包含成百上千个神经元和大量的连接权重。随着网络层数的增加,模型的内部结构变得极其复杂。
-
各层神经元之间的交互和权重的更新过程并不是人类可以直观理解的,这导致我们难以解释为什么某个输入数据导致了某个输出结果。
2. 大量的参数:
-
深度学习模型通常有成千上万,甚至上百万的参数,这些参数决定了模型的行为。每个神经元的权重更新依赖于复杂的梯度计算,参数之间的相互影响极难追踪和解释。
-
在这些参数共同作用下,模型得出的决策很难归结为某几个显式的规则或特征。
3. 非线性关系:
-
深度神经网络利用非线性激活函数,通过多层非线性组合,使得输入和输出之间的关系变得复杂和难以解析。即使我们知道模型的输入和输出,也难以还原出中间的转换过程。
4. 黑箱特性:
-
深度学习模型中的决策过程被形象地称为“黑箱”,因为虽然我们可以看到输入和输出,但中间的决策过程是高度复杂和不透明的。即使我们通过技术手段可视化某些层或神经元的活动,也很难确切知道它们对最终决策的影响。
5. 缺乏明确的决策规则:
-
传统的机器学习算法(如决策树)有明确的规则和分支路径,方便人类理解其决策过程。而深度学习则不同,模型通过大量的训练数据自行学习特征和规则,无法直接得出类似“如果X则Y”的明确规则。
6. 高度依赖数据:
-
深度学习模型的决策过程是高度依赖于数据的。在训练过程中,模型会自适应调整大量的权重参数,从而适应特定的数据集。这意味着同样的模型在不同的数据集上可能学到完全不同的模式,这使得模型的可解释性更加困难。
例子:深度学习在图像分类中的可解释性问题
-
假设我们有一个用来识别猫的深度学习模型,它输出“是猫”或“不是猫”。虽然我们可以通过测试验证模型的准确性,但很难解释模型是基于哪些特征做出判断的。它是否注意到了猫的耳朵?还是猫的颜色?这些特征在网络层中的具体作用是如何的?这些都很难给出明确的解释。
改善可解释性的方法:
-
特征可视化:通过可视化中间层的输出,帮助我们了解模型在某些输入数据上的特征提取过程(如卷积神经网络中的特征图)。
-
局部可解释性模型:像 LIME(局部可解释模型)或 SHAP(Shapley Additive Explanations)等工具,能够在局部解释模型的预测过程,虽然不能解释整体模型,但可以帮助解释单个预测的依据。
-
模型简化:将复杂的深度学习模型转换成简化的模型(如决策树)进行近似解释。
总结:
深度学习模型可解释性差的主要原因在于其复杂的网络结构、巨大的参数数量、非线性变换以及数据驱动的学习方式。这使得即使模型在预测时表现优异,也难以追踪和理解其具体的决策过程。但是深度学习在实验上的效果是非常好的。


国内大概2016年开始关注深度学习。
深度学习的发展历史可以从以下几个方面进行分析,特别是结合中国的情况来做解释:
1. 符号主义阶段(20世纪50-70年代)
-
这个阶段的人工智能(AI)以符号主义为主,也就是专家系统。计算机依赖预先定义好的规则和逻辑来做推理和决策,类似于模仿人类专家的思维过程。
-
代表事件:1950年图灵设计了国际象棋程序,1962年IBM的Arthur Samuel开发了跳棋程序战胜人类高手。
-
中国的情况:在这一阶段,中国的人工智能技术还处于起步阶段,主要是跟随国际上的进展,尚未形成系统化的研究。
2. 统计主义阶段(20世纪80-2000年代)
-
这个阶段人工智能的发展主要依赖统计模型解决问题,特别是支持向量机(SVM)等技术的发展显著提升了机器学习的能力。
-
代表事件:1993年Vapnik提出SVM算法,1997年IBM的深蓝战胜国际象棋冠军卡斯帕罗夫,标志着人工智能的又一次浪潮。
-
中国的情况:中国在这一阶段主要以引进和应用为主,人工智能技术在一些高校和科研机构中开始研究和应用,但相对于国际仍有差距。
3. 神经网络和深度学习阶段(21世纪初期)
-
2012年,AlexNet的出现标志着深度学习开始成为主流方法。它通过卷积神经网络(CNN)显著提高了图像识别的能力。此后,深度学习在语音识别、自然语言处理等领域得到了广泛应用。
-
2016年,Google AlphaGo 战胜李世石,这是人工智能第三次浪潮的重要里程碑,展示了深度学习和强化学习的强大能力。
-
中国的情况:在这一阶段,中国的科技企业和研究机构也开始迅速发展深度学习技术。像百度、阿里巴巴、腾讯等大公司建立了强大的人工智能研究团队,推出了深度学习平台(如百度的PaddlePaddle)。中国高校和科研机构也在神经网络和深度学习方面取得了很多成果,人工智能技术在图像处理、语音识别、无人驾驶等领域广泛应用。
4. 大规模预训练模型阶段(2017年至今)
-
2017年,NLP领域的Transformer框架出现,极大地推动了自然语言处理的发展,成为主流架构。随后BERT、GPT等模型进一步提升了模型的语言理解能力。
-
2022年,chatGPT的出现,开启了大模型的AIGC(AI生成内容)时代。预训练模型在多个领域大显身手,特别是在生成文本、图像、甚至编写代码等方面都表现出色。
-
中国的情况:中国在这一阶段也涌现了很多大型预训练模型项目。像华为、阿里巴巴、百度等企业推出了类似GPT的中文预训练语言模型,如华为的“鹏程”、百度的“文心一言”等。中国还逐渐在国际人工智能领域占据一席之地,推出的预训练模型逐步应用于语言翻译、对话系统、自动生成新闻等领域。
2020年到2024年,人工智能领域,特别是深度学习技术在全球范围内取得了重大进展,中国在这一期间也展现出强劲的创新能力。以下是对每年发展状况的简要介绍:
2020年:疫情加速AI应用
-
全球疫情推动AI应用:
-
新冠疫情的全球爆发促使人工智能技术在医疗、公共安全和远程办公等领域的应用加速。AI被广泛用于疫情的跟踪、预测、疫苗研发和医疗影像识别中。
-
例如,AI模型被用来分析CT扫描图像,以辅助医生快速诊断新冠肺炎。
-
-
中国的AI发展:
-
中国在疫情期间快速部署了AI技术,特别是在智能城市、疫情监控和诊断系统方面,AI发挥了巨大作用。例如,AI算法被用于智能测温、面部识别(即使戴着口罩)以及密切接触者的追踪。
-
同时,远程教育、智慧办公和电子商务领域的AI应用蓬勃发展,推动了国内人工智能产业的全面升级。
-
2021年:预训练模型的进一步突破
-
预训练语言模型大热:
-
预训练模型(如GPT-3)在自然语言处理领域的影响继续扩大。OpenAI的GPT-3在生成文本、回答问题、代码生成等多个任务中展现出惊人的能力,推动了自然语言处理(NLP)的发展。
-
此时,预训练模型已经开始成为大多数NLP任务的标准,AI开始展现出更广泛的生成内容能力(AIGC)。
-
-
中国的预训练模型崛起:
-
中国的科技巨头和研究机构加大了在预训练模型方面的投入,推出了多个大规模中文语言模型。例如,百度推出了“文心大模型”,该模型可以用于对话、内容生成、文本分析等任务,表现出强大的中文处理能力。
-
同时,中国的企业开始将AI应用于法律、医疗、金融等垂直领域,并在工业制造中加速智能化转型。
-
2022年:AIGC(AI生成内容)的崛起
-
chatGPT引领AI生成内容热潮:
-
OpenAI发布的chatGPT在全球范围内掀起了AI生成内容(AIGC)的热潮。chatGPT能够生成具有语义和逻辑一致性的长文本,涵盖从编写代码到创作诗歌等多种任务。
-
AIGC技术开始逐渐应用于更多领域,如新闻自动生成、电影剧本撰写、广告文案创作等。
-
-
中国的AI大模型发展:
-
中国科技企业如阿里、百度、华为等纷纷推出大规模预训练模型,如阿里的“M6模型”、百度的“文心一言”等。这些模型的出现标志着中国在自然语言处理和AI生成内容方面已站在全球前沿。
-
政府和企业进一步推动AI与传统产业的结合,AI技术被广泛应用于智慧医疗、智能金融、智能制造等领域。AI生成内容技术也逐渐在广告、游戏等创意产业中展现出巨大潜力。
-
2023年:大模型与垂直领域结合加深
-
大模型应用逐渐多样化:
-
2023年,大规模预训练模型进一步优化,并开始更多应用于细分垂直领域。医疗、金融、教育等行业逐渐将AI大模型融入自身的工作流中。例如,AI模型在医疗诊断、金融风控、自动化教育辅导中得到了广泛应用。
-
AI伦理和安全成为讨论的焦点,全球范围内对AI的监管讨论加剧,各国都在探索如何制定AI发展的监管框架。
-
-
中国的大模型应用落地:
-
在中国,AI大模型应用越来越广泛地结合各行各业。智慧医疗领域,AI辅助诊断、药物研发等取得了显著进展;金融领域,AI大模型被用于风险评估、智能投顾等业务;教育领域,AI自动化辅导和个性化教育方案逐渐普及。
-
此外,中国科技企业在图像生成、虚拟主播等方面的AI生成内容技术也逐渐成熟,并广泛应用于电商、短视频平台等行业。
-
2024年:AIGC和AI治理并行发展
-
AIGC进入主流市场:
-
到2024年,AI生成内容(AIGC)技术已深度渗透到媒体、娱乐、教育等行业。AI不再仅仅是工具,而是成为创意生产的合作伙伴。用户可以通过简单的指令,生成高质量的文本、图片、视频等内容。
-
例如,AI能够生成完整的广告创意、新闻报道,甚至电影剧本,大大降低了创作门槛并提高了生产效率。
-
-
中国的AI政策与技术进步:
-
2024年,中国继续在全球AI领域保持强劲势头。随着AI在各个行业的落地,中国政府也加强了AI相关政策的制定与监督,确保AI技术的安全、透明、可控发展。
-
同时,随着5G、物联网等技术的进一步发展,AI在智能城市、自动驾驶、智慧农业等领域的应用变得更加深入。
-
此外,中国的AI人才培养体系进一步完善,人工智能学科在高校中蓬勃发展,为未来的科技进步奠定了坚实基础。
-
总结:
中国的深度学习和人工智能技术从引进、模仿到自主创新,已经走过了漫长的历程。在神经网络和大规模预训练模型阶段,中国科技企业和研究机构逐渐占据了重要地位,推动了深度学习技术在各个领域的应用与发展。
2020年到2024年,全球尤其是中国的人工智能技术经历了从疫情加速应用到大模型、生成内容的快速发展。中国的AI行业在这一阶段取得了长足的进步,不仅在技术上实现了突破,应用上也开始大规模落地,推动了传统产业的智能化转型,同时也逐步加快了与全球AI技术的接轨。
相关文章:
深度学习01-概述
深度学习是机器学习的一个子集。机器学习是实现人工智能的一种途径,而深度学习则是通过多层神经网络模拟人类大脑的方式进行学习和知识提取。 深度学习的关键特点: 1. 自动提取特征:与传统的机器学习方法不同,深度学习不需要手动…...

leetcode232. 用栈实现队列
leetcode232. 用栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾 int pop() 从队列的开头移除并返回元…...

智慧火灾应急救援航拍检测数据集(无人机视角)
智慧火灾应急救援。 无人机,直升机等航拍视角下火灾应急救援检测数据集,数据分别标注了火,人,车辆这三个要素内容,29810张高清航拍影像,共31GB,适合森林防火,应急救援等方向的学术研…...

eureka.client.service-url.defaultZone的坑
错误的配置 eureka: client: service-url: default-zone: http://192.168.100.10:8080/eureka正确的配置 eureka: client: service-url: defaultZone: http://192.168.100.10:8080/eureka根据错误日志堆栈打断电调试 出现两个key,也就是defaultZone不支持snake-c…...

统信服务器操作系统【d版字符系统升级到dde图形化】配置方法
统信服务器操作系统d版本上由字符系统升级到 dde 桌面系统的过程 文章目录 一、准备环境二、功能描述安装步骤1. lightdm 安装2. dde 安装 一、准备环境 适用版本:■UOS服务器操作系统d版 适用架构:■ARM64、AMD64、MIPS64 网络:连接互联网…...

学习IEC 62055付费系统标准
1.IEC 62055 国际标准 IEC 62055 是目前关于付费系统的唯一国际标准,涵盖了付费系统、CIS 用户信息系统、售电系统、传输介质、数据传输标准、预付费电能表以及接口标准等内容。 IEC 62055-21 标准化架构IEC 62055-31 1 级和 2 级有功预付费电能表IEC 62055-41 STS…...
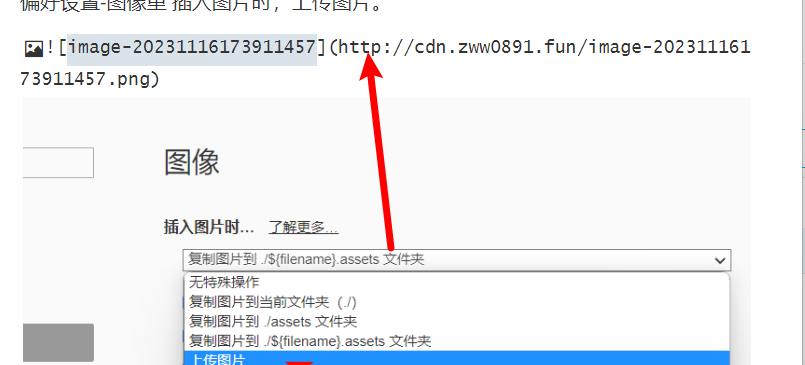
如何在Markdown写文章上传到wordpress保证图片不丢失
如何在Markdown写文章上传到wordpress保证图片不丢失 写文日期,2023-11-16 引文 众所周知markdown是一款nb的笔记软件,本篇文章讲解如何在markdown编写文件后上传至wordpress论坛。并且保证图片不丢失(将图片上传至云端而非本地方法) 一&…...

html,css基础知识点笔记(二)
9.18(二) 本文主要教列表的样式设计 1)文本溢出 效果图 文字限制一行显示几个字,多余打点 line-height: 1.8em; white-space: nowrap; width: 40em; overflow: hidden; text-overflow: ellipsis;em表示一个文字的大小单位&…...
kubernetes 部署Promehteus学习之路)
(k8s)kubernetes 部署Promehteus学习之路
整个Prometheus生态包含多个组件,除了Prometheus server组件其余都是可选的 Prometheus Server:主要的核心组件,用来收集和存储时间序列数据。 Client Library::客户端库,为需要监控的服务生成相应的 metrics 并暴露给…...

初写MySQL四张表:(3/4)
我们已经完成了四张表的创建,学会了创建表和查看表字段信息的语句。 初写MySQL四张表:(1/4)-CSDN博客 初写MySQL四张表:(2/4)-CSDN博客 接下来,我们来学点对数据的操作:增 删 查(一部分)改 先来看这四张表以及相关…...

【Java】线程暂停比拼:wait() 和 sleep()的较量
欢迎浏览高耳机的博客 希望我们彼此都有更好的收获 感谢三连支持! 在Java多线程编程中,合理地控制线程的执行是至关重要的。wait()和sleep()是两个常用的方法,它们都可以用来暂停线程的执行,但它们之间存在着显著的差异。本文将详…...

CQRS模型解析
简介 CQRS中文意思为命令于查询职责分离,我们可以将其了解成读写分离的思想。分为两个部分 业务侧和数据侧,业务侧主要执行的就是数据的写操作,而数据侧主要执行的就是数据的读操作。当然两侧的数据库可以是不同的。目前最为常用的CQRS思想方…...

qt-C++笔记之作用等同的宏和关键字
qt-C笔记之作用等同的宏和关键字 code review! Q_SLOT 和 slots: Q_SLOT是slots的替代宏,用于声明槽函数。 Q_SIGNAL 和 signals: Q_SIGNAL类似于signals,用于声明信号。 Q_EMIT 和 emit: Q_EMIT 是 Qt 中用于发射…...

java(3)数组的定义与使用
目录 1.前言 2.正文 2.1数组的概念 2.2数组的创建与初始化 2.2.1数组的创建 2.2.1数组的静态初始化 2.2.2数组的动态初始化 2.3数组是引用类型 2.3.1引用类型与基本类型区别 2.3.2认识NULL 2.4二维数组 2.5数组的基本运用 2.5.1数组的遍历 2.5.2数组转字符串 2.…...

Integer 源码记录
Integer 公共方法结构 注意: 通过构造函数创建一个Integer对象,每次都会返回一个新的对象,如果使用 进行对象的比较,那么结果是false。 public Integer(int value) {this.value value;}与之对应的是,valueOf 方法…...

【RocketMQ】一、基本概念
文章目录 1、举例2、MQ异步通信3、背景4、Rocket MQ 角色概述4.1 主题4.2 队列4.3 消息4.4 生产者4.5 消费者分组4.6 消费者4.7 订阅关系 5、消息传输模型5.1 点对点模型5.2 发布订阅模型 1、举例 以坐火车类比MQ: 安检大厅就像是一个系统的门面,接受来…...

笔记9.18
线程之间的通信是指在多线程程序中,不同线程之间如何交换数据或协调工作。这种通信对于实现复杂的并发程序是至关重要的。以下是几种常见的线程间通信方式: 共享内存: 这是最直接的方式,多个线程通过读写同一块内存区域࿰…...

时间序列8个基准Baseline模型及其详细解读
我是从去年11月份开始,选定时间序列预测这个方向,准备在工作之余继续独立进行一些科学研究。选定这个方向是因为我对金融量化一直挺感兴趣,希望能把时间序列中的深度学习算法模型,用到金融数据。现在看来,我太过于理想…...

将相机深度图转接为点云的ROS2功能包
depth_image_proc 是一个 ROS(Robot Operating System)包,它包含了一系列节点,用于处理来自深度相机的图像数据,并将其转换为点云。以下是 depth_image_proc 包中各个节点的作用: convert_metric_node&…...

计算机毕业设计选题推荐-共享图书管理系统-小程序/App
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

CANN/asc-devkit向量取反API
asc_neg 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

如何快速实现微信小游戏开发:weapp-adapter的完整实践指南
如何快速实现微信小游戏开发:weapp-adapter的完整实践指南 【免费下载链接】weapp-adapter weapp-adapter of Wechat Tiny Game in ES6 项目地址: https://gitcode.com/gh_mirrors/we/weapp-adapter 对于熟悉Web前端开发的程序员来说,微信小游戏开…...

书匠策AI到底有多懂毕业生?一个论文小白的“开挂“实录,看完你也想试!
嗨,各位正在为毕业论文头秃的宝子们!👋 我是你们的论文科普搭子,今天不讲枯燥的写作技巧,直接给大家安利一个我最近发现的"宝藏神器"——书匠策AI( 官网直达:www.shujiangce.com&…...

3步解锁你的专属B站:Bilibili-Evolved开源增强工具完全指南
3步解锁你的专属B站:Bilibili-Evolved开源增强工具完全指南 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 你是否曾对B站千篇一律的界面感到审美疲劳?是否被首页推荐…...

如何用AI瞄准技术实现职业级游戏体验:从零开始的完整配置指南
如何用AI瞄准技术实现职业级游戏体验:从零开始的完整配置指南 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 你是否曾在FPS游戏中因瞄准不稳而错失关键击杀?…...

AI+生产制造,车间里正在发生什么?
"人工智能生产制造"这个组合,听起来像是大型企业才玩得起的东西。但实际上,AI技术正在以一种很接地气的方式,渗透进制造企业的日常管理中。今天就来聊聊,AI在车间里到底能做什么。生产排产:从经验驱动到数据…...

AI MV 工具评测指南 2026:多模态音视频自动生成系统
AI MV 工具评测指南 2026:多模态音视频自动生成系统 适用读者:需要批量生产音乐可视化内容的自媒体创作者、社交媒体运营者、短视频内容创作者一、技术定义与核心功能 AI MV 工具是实现音频到视频自动转化的多模态生成系统。其工作原理是:输入…...

2026年最佳手机阅读器推荐:付费也值得的精品选择
在数字时代,阅读方式正在发生深刻变革。随着电子书、在线文章和多媒体内容的兴起,人们越来越倾向于通过智能手机进行阅读。然而,并非所有的阅读器都能提供优质的阅读体验。今天,我们将聚焦于一款即便付费也绝对物超所值的手机阅读…...

终极Mac微信插件:消息防撤回与多开登录完整指南
终极Mac微信插件:消息防撤回与多开登录完整指南 【免费下载链接】WeChatExtension-ForMac A plugin for Mac WeChat 项目地址: https://gitcode.com/gh_mirrors/we/WeChatExtension-ForMac 还在为Mac微信无法防撤回消息而烦恼吗?想要在同一台电脑…...

Neuralink脑机接口技术解析:从医疗应用到人机共生
1. 项目概述:从科幻到现实的神经接口革命最近几年,一个名字频繁出现在科技和医疗的交叉领域,引发无数讨论与遐想——Neuralink。这不仅仅是一家公司的名字,它更像是一个时代的符号,代表着人类试图用最前沿的工程技术&a…...