Redis存储原理
前言
我们从redis服务谈起,redis是单reactor,命令在redis-server线程处理。还有若干读写IO线程负责IO操作(redis6.0之后,Redis之pipeline与事务)。此外还有一个内存池线程负责内存管理、一个后台文件线程负责大文件的关闭、一个异步刷盘线程负责持久化。这就使得redis在设计方面对高效的贡献。

从io密集型的角度来看,redis的磁盘IO是fork子进程异步刷盘,不占用主线程。网络IO如果有多个连接,并且发送了大量的请求,才会考虑IO多线程;从cpu密集型的角度来看,redis有高效的数据结构,加之kv原理,避免了cpu密集。那redis为什么不采用多线程呢?硬伤就是redis的多种数据类型由多种不同的数据结构实现,加锁复杂,锁的粒度不易控制。此外频繁的上下文切换会降低整体性能。那除了单reactor,redis还在什么方面对高效做出来贡献呢?hash表。
存储原理
redis使用哈希表来组织所有数据,这次我们直接杀到源码。在redisDb中我们可以看到四个dict(散列表)类型的成员(英文这里就不翻译了,原汁原味)。
typedef struct redisDb {kvstore *keys; /* The keyspace for this DB */kvstore *expires; /* Timeout of keys with a timeout set */ebuckets hexpires; /* Hash expiration DS. Single TTL per hash (of next min field to expire) */dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/dict *blocking_keys_unblock_on_nokey; /* Keys with clients waiting for* data, and should be unblocked if key is deleted (XREADEDGROUP).* This is a subset of blocking_keys*/dict *ready_keys; /* Blocked keys that received a PUSH */dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */int id; /* Database ID */long long avg_ttl; /* Average TTL, just for stats */unsigned long expires_cursor; /* Cursor of the active expire cycle. */list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;可见我们需要对dict下手了,因为数据就存储在dict中。这其实类似c++类的封装,dictType中存放了所有成员函数,其中dictEntry指针数组就是元素存储的地方了。
struct dict {dictType *type;dictEntry **ht_table[2];//哈希表unsigned long ht_used[2];//实际存储的元素个数long rehashidx; /* rehashing not in progress if rehashidx == -1 *//* Keep small vars at end for optimal (minimal) struct padding */unsigned pauserehash : 15; /* If >0 rehashing is paused */unsigned useStoredKeyApi : 1; /* See comment of storedHashFunction above */signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */int16_t pauseAutoResize; /* If >0 automatic resizing is disallowed (<0 indicates coding error) */void *metadata[];
};
我们来看dictEntry,也就是存储元素的结构。
/* -------------------------- types ----------------------------------------- */
struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next; /* Next entry in the same hash bucket. */
};typedef struct {void *key;dictEntry *next;
} dictEntryNoValue;源码我们找到了,现在就可以来讨论一下哈希表了。哈希表通过hash运算得出index,如果这个地方有元素,就通过链表组织。这就对应了dictEntry **ht_table[2]。
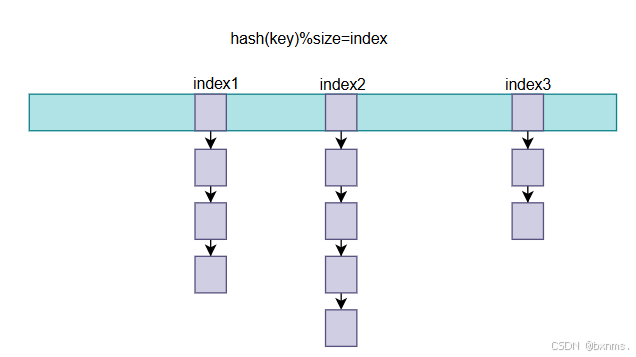
我们知道,通过链表组织就是一种应对hash冲突的策略,hash冲突会使索引效率降低,然鹅从源码可以看到有一个负载因子,也就是已有元素与数组长度之比(used/size),负载因子越大表示hash冲突就越大,而我们知道hash时间复杂度是O(1),hash冲突到后面会使时间复杂度增加到O(n)。当负载因子大于1的时候就要进行扩容操作,也就是将数组长度翻倍,增大分母减小负载因子。而当负载因子小于0.1(恰好大于used的2^n)的时候就要进行缩容,因为这是占着茅坑不拉屎,浪费空间。不管扩容还是缩容,数组长度都会改变,这时候hash算法就变了,就要对原来的元素重新hash。
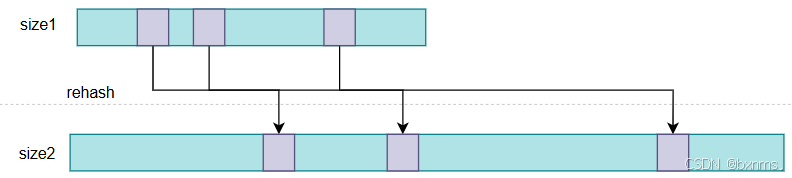
蛋是!redis是个数据库啊,rehash时就有可能有数据操作,所以它就不能像STL中的unordered_map一样直接rehash(CPU密集型的)。redis是采取渐进式rehash策略。Redis的渐进式rehash是一种在数据量增加时对哈希表进行动态扩容的机制,它能够保证数据的均匀分布和快速访问,同时避免了传统rehash操作可能带来的性能下降问题。在Redis中,渐进式rehash的实现原理和步骤如下:
- 触发条件:当哈希表中的节点数与哈希表大小的比例超过一定阈值(默认为1:1,或者在执行RDB或AOF操作时为5:1)时,就会触发rehash操作。
- 创建新的哈希表:Redis会创建一个新的哈希表,其大小是原哈希表的两倍,以容纳更多的键值对。
- 渐进式迁移:Redis不会一次性将所有键值对迁移到新哈希表,而是将迁移过程分散到后续的字典操作中。每次字典操作时,会顺便迁移一部分键值对到新哈希表,这个过程称为渐进式rehash。
- 迁移过程:在迁移过程中,Redis会维护一个
rehashidx索引,用于记录迁移的进度。每次字典操作时,会迁移rehashidx索引对应的桶中的所有键值对到新哈希表,然后rehashidx递增。 - 读写操作:在渐进式rehash进行期间,查找操作会在两个哈希表中进行,以确保不会遗漏任何键值对。而新增操作则只会在新的哈希表中进行。
- 完成rehash:当所有键值对都迁移到新哈希表后,Redis会将旧哈希表的空间释放,并将
rehashidx重置为-1,表示rehash操作完成。 - 缩容操作:除了扩容,Redis在数据量减少时也会进行缩容操作,其过程与扩容类似,也是通过渐进式rehash来完成。
渐进式rehash的优点在于它能够平滑地处理数据迁移,避免了一次性迁移可能导致的性能抖动,确保了Redis在扩容或缩容过程中的稳定性和性能。然而,它也会占用额外的内存空间,因为需要同时维护两个哈希表,并且在迁移过程中可能会导致一定程度的数据不一致。尽管如此,渐进式rehash是Redis中一个非常重要的特性,它使得Redis能够有效地处理动态数据集的变化。rehash源码如下,这里就不逐行解释了,扔给AI便可。
int dictRehash(dict *d, int n) {int empty_visits = n*10; /* Max number of empty buckets to visit. */unsigned long s0 = DICTHT_SIZE(d->ht_size_exp[0]);unsigned long s1 = DICTHT_SIZE(d->ht_size_exp[1]);if (dict_can_resize == DICT_RESIZE_FORBID || !dictIsRehashing(d)) return 0;/* If dict_can_resize is DICT_RESIZE_AVOID, we want to avoid rehashing. * - If expanding, the threshold is dict_force_resize_ratio which is 4.* - If shrinking, the threshold is 1 / (HASHTABLE_MIN_FILL * dict_force_resize_ratio) which is 1/32. */if (dict_can_resize == DICT_RESIZE_AVOID && ((s1 > s0 && s1 < dict_force_resize_ratio * s0) ||(s1 < s0 && s0 < HASHTABLE_MIN_FILL * dict_force_resize_ratio * s1))){return 0;}while(n-- && d->ht_used[0] != 0) {/* Note that rehashidx can't overflow as we are sure there are more* elements because ht[0].used != 0 */assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);while(d->ht_table[0][d->rehashidx] == NULL) {//旧数据为空就找下一个d->rehashidx++;if (--empty_visits == 0) return 1;}/* Move all the keys in this bucket from the old to the new hash HT */rehashEntriesInBucketAtIndex(d, d->rehashidx);d->rehashidx++;}return !dictCheckRehashingCompleted(d);
}static void rehashEntriesInBucketAtIndex(dict *d, uint64_t idx) {dictEntry *de = d->ht_table[0][idx];uint64_t h;dictEntry *nextde;while (de) {nextde = dictGetNext(de);void *key = dictGetKey(de);/* Get the index in the new hash table */if (d->ht_size_exp[1] > d->ht_size_exp[0]) {h = dictHashKey(d, key, 1) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);} else {/* We're shrinking the table. The tables sizes are powers of* two, so we simply mask the bucket index in the larger table* to get the bucket index in the smaller table. */h = idx & DICTHT_SIZE_MASK(d->ht_size_exp[1]);}if (d->type->no_value) {if (d->type->keys_are_odd && !d->ht_table[1][h]) {/* Destination bucket is empty and we can store the key* directly without an allocated entry. Free the old entry* if it's an allocated entry.** TODO: Add a flag 'keys_are_even' and if set, we can use* this optimization for these dicts too. We can set the LSB* bit when stored as a dict entry and clear it again when* we need the key back. */assert(entryIsKey(key));if (!entryIsKey(de)) zfree(decodeMaskedPtr(de));de = key;} else if (entryIsKey(de)) {/* We don't have an allocated entry but we need one. */de = createEntryNoValue(key, d->ht_table[1][h]);} else {/* Just move the existing entry to the destination table and* update the 'next' field. */assert(entryIsNoValue(de));dictSetNext(de, d->ht_table[1][h]);}} else {dictSetNext(de, d->ht_table[1][h]);}d->ht_table[1][h] = de;d->ht_used[0]--;d->ht_used[1]++;de = nextde;}d->ht_table[0][idx] = NULL;
} 那我们怎么访问元素?用keys命令吗?非也。当执行 KEYS 命令时,Redis 会锁定数据库,然后检索所有匹配给定模式的键。如果键的数量非常多,这个操作可能会花费很长时间,在此期间,服务器不能响应其他客户端的请求,从而导致服务器阻塞。这是因为 KEYS 命令在执行期间会阻止其他操作,包括但不限于写操作,直到命令执行完成。我们可以使用scan命令。Redis 的 SCAN 命令是一个基于游标的迭代器,用于逐个元素地访问(或迭代)集合类型的元素,如列表(list)、集合(set)、有序集合(sorted set)和哈希(hash)。这个命令非常有用,因为它提供了一种方式来逐步检索大数据集,而不会像使用传统的 KEYS 命令那样对服务器性能造成严重影响。SCAN 命令的基本用法如下:
SCAN cursor [MATCH pattern] [COUNT count]cursor:游标,每次调用SCAN命令时,都会返回一个新的游标,用于下一次迭代。MATCH pattern:可选参数,用于过滤返回的元素,只返回符合给定模式的元素。COUNT count:可选参数,建议 Redis 返回的元素数量,实际返回的数量可能会更多或更少。
SCAN 命令的优点包括:
- 性能:相比于
KEYS命令,SCAN命令不会阻塞服务器,因为它是迭代地返回元素,而不是一次性返回所有匹配的元素。 - 大数据集:对于包含大量元素的集合类型,
SCAN命令可以有效地进行分批处理,这对于处理大数据集非常有用。 - 模式匹配:通过
MATCH选项,可以只返回符合特定模式的元素,这在处理具有特定前缀或模式的键时非常有用。 - 分页:在分页应用中,
SCAN可以用于实现服务器端的分页功能,通过游标来控制返回的数据范围。 - 灵活性:
COUNT参数允许你建议 Redis 返回的元素数量,这有助于控制每次迭代的负载。
需要注意的是,SCAN 命令返回的元素可能会有重复,因为 Redis 并不保证每次迭代都是从上一次停止的地方开始。因此,客户端需要准备好处理可能的重复数据。此外,SCAN 命令提供的迭代器只能保证在迭代过程中添加的新元素会被返回,但不保证它们的顺序。
相关文章:
Redis存储原理
前言 我们从redis服务谈起,redis是单reactor,命令在redis-server线程处理。还有若干读写IO线程负责IO操作(redis6.0之后,Redis之pipeline与事务)。此外还有一个内存池线程负责内存管理、一个后台文件线程负责大文件的关…...

PHP、Java等其他语言转Go时选择GoFly快速快速开发框架指南
概要 经过一年多的发展GoFly快速开发框架已被一千多家科技企业或开发者用于项目开发,它的简单易学得到其他语言转Go首选框架。且企业版的发展为GoFly社区提供资金,这使得GoFly快速框架得到良好的发展,GoFly技术团队加大投入反哺科技企业和开…...

【MySQL】获取最近7天和最近14天的订单数量,使用MySQL详细写出,使用不同的方法
1. 获取最近7天和最近14天的订单数量,使用MySQL详细写出,使用不同的方法 要获取最近7天和最近14天的订单数量,我们可以使用不同的方法来优化查询性能。以下是两种方法: 1.1 方法一:使用日期计算 SELECTSUM(CASE WHE…...

WebView2新增、修改、删除、禁用右键菜单相关操作。
参考链接:WebView2操作右键菜单...
使用vue创建项目
一、安装环境 二、创建vue框架(创建文件夹,摁shift鼠标右键 打开) 1、项目配置 2、新增目录 三、路径别名配置 输入/ ,VSCode会联想出src下的所有子目录和文件,统一文件路径访问时不容易出错 四、ElementPlus配置 1、组件分为…...

Apache CVE-2021-41773 漏洞攻略
漏洞简介 该漏洞是由于Apache HTTP Server 2.4.49版本存在⽬录穿越漏洞,在路径穿越⽬录 <Directory/>Require all granted</Directory>允许被访问的的情况下(默认开启),攻击者可利⽤该路径穿越漏洞读取到Web⽬录之外的其他⽂件在…...

【redis-02】深入理解redis中RBD和AOF的持久化
redis系列整体栏目 内容链接地址【一】redis基本数据类型和使用场景https://zhenghuisheng.blog.csdn.net/article/details/142406325【二】redis的持久化机制和原理https://zhenghuisheng.blog.csdn.net/article/details/142441756 如需转载,请输入:htt…...

亚马逊IP关联揭秘:发生ip关联如何处理
在亚马逊这一全球领先的电商平台上,IP关联是一个不可忽视的问题,尤其是对于多账号运营的卖家而言。本文将深入解析亚马逊IP关联的含义、影响以及应对策略,帮助卖家更好地理解和应对这一问题。 什么是亚马逊IP关联? 亚马逊IP关联…...

jQuery Mobile 弹窗
jQuery Mobile 弹窗 引言 在移动设备上,弹窗是一种常见的用户界面元素,用于显示信息、获取用户输入或提供特定功能。jQuery Mobile 是一个流行的移动框架,它提供了丰富的组件来帮助开发者创建响应式的移动界面。本文将重点介绍如何在 jQuery Mobile 中使用弹窗(Popup)组…...

【macOS】【zsh报错】zsh: command not found: python
【macOS】【zsh Error】zsh: command not found: python 本地已经安装了Python,且能在Pycharm中编译Python程序并运行。 但是,在macOS终端,运行Python,报错。 首先要确认你在macOS系统下,是否安装了Python。 如果安…...

NoSql数据库Redis知识点
数据库的分类 关系型数据库 ,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库 中的数据主流的 MySQL 、 Oracle 、 MS SQL Server 和 DB2 都属于这类传统数据库。 NoSQL 数据库 ,全称为 Not Only SQL &a…...

Redis 使用指南
Redis 使用指南 概述 Redis 是一个开源的、基于内存的数据结构存储系统,可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串(strings)、哈希(hashes)、列表(lists…...

c++与cmake:完整的C++项目构建注意事项
个人博客:Sekyoro的博客小屋 个人网站:Proanimer的个人网站 最近常常使用cmake构建c项目有感,从创建项目到打包发布总结一下需要注意的事情. 项目组织方式 具体的项目组织方式因人而异,这里推荐一种,在src目录中创建模块目录,再在include目录中常见对应的同名目录包含头文件,…...

Linux自主学习篇
用户及权限管理 sudo 是 "superuser do" 的缩写,是一个在类 Unix 操作系统(如 Linux 和 macOS)中使用的命令。它允许普通用户以超级用户(root 用户)的身份执行命令,从而获得更高的权限。 useradd…...

MQ入门(4)
Erlang:面向高并发的 单机的吞吐量就是并发性:Rabbitmq是10w左右(现实项目中已经足够用了),RocketMQ是10w到20w,Kafka是100w左右。 公司里的并发(QPS) 大部分的公司每天的QPS大概…...

linux下共享内存的3种使用方式
进程是资源封装的单位,内存就是进程所封装的资源的一种。一般情况下,进程间的内存是相互隔离的,也就是说一个进程不能访问另一个进程的内存。如果一个进程想要访问另一个进程的内存,那么必须要进过内核这个桥梁,这就是…...

伊丽莎白·赫莉为杂志拍摄一组素颜写真,庆祝自己荣膺全球最性感女人第一名
语录:女性应该做任何她们想做的事,批评她们的人都见鬼去吧。 伊丽莎白赫莉为《Maxim》杂志拍摄一组素颜写真,庆祝自己荣膺全球最性感女人第一名 伊丽莎白赫莉 (Elizabeth Hurley) 实在是太惊艳了,如今,《马克西姆》杂…...

Qt快捷键说明与用法
编辑与查找 CtrlF:在当前编辑窗口中查找关键字。支持大小写相关、全词匹配、正则表达式匹配等选项,并且查找之后还可以进行替换操作。 CtrlShiftF:进行全局查找,不局限于当前文件。注意,在某些情况下,这个…...

技术周刊 | TS 5.6、Chrome DevTools 性能面板上新、Vite 6 Beta、Fastify v5、HTTP 新方法 Query
增长能力,就是持续做出正确决定的能力。 大家好,我是童欧巴,欢迎来到第 128 期技术周刊。 资讯 TypeScript 5.6 TypeScript 5.6 如期发布。 Chrome DevTools 发布全新性能功能 Chrome DevTools 的性能面板上新测试,包括 Core…...

使用Mockito进行单元测试
1、单元测试介绍 Mockito和Junit是用于单元测试的常用框架。单元测试即:从最小的可测试单元(如函数、方法或类)开始,确保每个单元都能按预期工作。单元测试是白盒测试的核心部分,它有助于发现单元内部的错误。 单元测试…...
)
文档分析准确率从61%跃升至98.7%的关键转折点(附2024Q2最新Claude-3.5 Sonnet文档理解基准测试对比表)
更多请点击: https://kaifayun.com 第一章:文档分析准确率跃升至98.7%的里程碑意义 当文档智能系统在真实业务场景中将结构化识别准确率稳定提升至98.7%,这不仅是一个数字的突破,更是文档理解能力从“可用”迈向“可信”的关键分…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》018、DeepLab-DEIM与SegFormer-DEIM语义分割优化全记录
CVPR2025-DEIM创新改进项目实战:DeepLab-DEIM与SegFormer-DEIM语义分割优化全记录 一、从一次令人崩溃的显存溢出说起 上周三凌晨两点,我盯着屏幕上那个“CUDA out of memory”的红色报错,差点把咖啡泼到键盘上。当时正在跑一个DeepLabV3+的语义分割实验,输入尺寸不过是1…...

第10章:自动化运维体系
第10章:自动化运维体系 10.1 为什么需要自动化运维 在大规模ES集群运维中,手动运维面临以下挑战: 手动运维的痛点: 效率低下: 100个集群,手动配置耗时巨大 配置不一致: 手动配置容易出错,配置不一致 响应慢: 故障时手动操作响应慢,影响SLA 不可追溯: 手动操作难以追溯,无法回…...

DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线
DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线 在电子工程和硬件测试领域,快速准确地获取元器件的伏安特性(V-A特性)曲线是一项基础但至关重要的任务。无论是LED的导通阈值、电机的启动电流,还是…...
)
告别Excel!用Python复现地理探测器(附完整代码与示例数据)
告别Excel!用Python复现地理探测器(附完整代码与示例数据) 地理探测器作为分析空间分异性的重要工具,长期以来依赖Excel插件实现计算。但对于需要批量处理、自定义分析流程的研究者而言,这种封闭式操作存在明显局限。…...

Aube:下一代 Node.js 包管理器,性能远超 pnpm
好的,我已经为您整理了关于新一代 Node.js 包管理器 Aube 的详细介绍文章。文章基于您提供的摘要和 GitHub 仓库的详细文档,扩充了功能介绍、使用场景和命令参考,以形成一个完整的详情页面。 Aube:下一代 Node.js 包管理器&#x…...

从 AI 工具到音乐生态:可酷加速布局,构建数字音乐全新基础设施
当数字音乐行业从流量竞争迈入生态竞争的新阶段,单一产品的功能边界已难以支撑企业长期增长,完善的生态协同能力逐渐成为企业突围的核心竞争力,也成为定义行业未来格局的关键变量。在此背景下,可酷公司近日对外披露其全新发展战略…...
手机版通用)
真・三国无双 起源 官方正版2026最新版pc免费下载(看到请立即转存 资源随时失效)手机版通用
下载链接 破局与重塑:——《真・三国无双 起源》制作团队、玩法架构与竞品技术对标 作为光荣特库摩(Koei Tecmo)旗下最具代表性的动作砍杀IP最新作,《真・三国无双 起源》(Dynasty Warriors: Origins)在延…...
)
ElevenLabs湖北话语音合成:从零部署到商用级TTS的7大避坑步骤(附武汉/宜昌/襄阳三方言测试数据)
更多请点击: https://kaifayun.com 第一章:ElevenLabs湖北话语音合成的技术定位与方言价值 ElevenLabs 作为全球领先的AI语音生成平台,其核心能力聚焦于高保真、情感化、多语言的文本到语音(TTS)合成。尽管官方尚未正…...

三分钟完成Taotoken的API Key配置与curl调用测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 三分钟完成Taotoken的API Key配置与curl调用测试 基础教程类,面向刚注册Taotoken并获取了API Key的开发者,…...