提升动态数据查询效率:应对数据库成为性能瓶颈的优化方案
引言
在现代软件系统中,数据库性能是决定整个系统响应速度和处理能力的关键因素之一。然而,当系统负载增加,特别是在高并发、大数据量场景下,数据库性能往往会成为瓶颈,导致查询响应时间延长,影响用户体验。动态数据查询作为应用程序中非常常见的操作,尤其容易受到数据库瓶颈的影响。
本文将讨论如何在数据库成为性能瓶颈的情况下,提升动态数据查询的效率。文章将从数据库设计、索引优化、缓存机制、分库分表、SQL优化、以及Java应用层面的一系列优化方案入手,通过代码示例详细讲解如何提高系统查询效率。
第一部分:数据库性能瓶颈的常见原因
在我们进行优化之前,首先要了解数据库性能瓶颈的常见原因:
1.1 查询负载过高
数据库在处理大量查询时,如果没有足够的资源(如CPU、内存、IO),会导致响应时间变长,甚至出现阻塞。
1.2 缺乏有效的索引
如果没有正确设计索引,数据库需要进行全表扫描,导致查询效率低下。特别是在处理复杂的动态查询时,索引的设计显得尤为重要。
1.3 数据库连接耗尽
高并发访问时,数据库连接池中的连接可能会耗尽,导致应用程序等待连接,影响整体响应时间。
1.4 数据库锁竞争
在频繁的读写操作中,数据库表或记录可能会被锁定,造成其他查询无法及时执行。
1.5 数据库设计不合理
数据表设计不当、字段冗余、数据表过大,都会影响查询效率。
第二部分:优化方案概述
针对上述瓶颈,我们将通过以下几个方面来提升数据库的查询效率:
- 索引优化:通过正确设计和使用索引来提高查询性能。
- 缓存机制:引入缓存系统,减少数据库查询压力。
- 分库分表:对大表进行拆分,减轻单库和单表的负载。
- SQL 优化:通过分析和优化 SQL 查询,减少查询时间。
- 数据库连接池优化:提高数据库连接池的使用效率。
- Java 应用层优化:通过合理的代码设计和多线程并发提升查询效率。
第三部分:索引优化
3.1 索引的作用
索引是提升查询效率最直接、有效的方法。它可以大幅度减少查询的数据量,从而加快查询速度。索引的类型主要包括主键索引、唯一索引、普通索引和全文索引。
3.2 索引设计的原则
- 避免过多的索引:索引虽然能够加快查询速度,但过多的索引会增加数据插入和更新的成本。因此,需要在查询速度和写入性能之间找到平衡点。
- 合理选择索引类型:根据查询场景选择合适的索引类型。常见的场景包括:
- 单字段查询:可以为查询字段建立普通索引。
- 多字段查询:使用组合索引(多列索引)来优化多条件查询。
- 模糊查询:适合使用全文索引或者倒排索引(如在 Elasticsearch 中)。
3.3 Java 代码实现索引优化
通过 Java 操作数据库(如 MySQL),我们可以通过 JDBC 或 ORM 框架来管理索引。下面是一个使用 JPA(Hibernate)的示例,展示如何在表中创建索引:
@Entity
@Table(name = "users", indexes = {@Index(name = "idx_username", columnList = "username"),@Index(name = "idx_email", columnList = "email")
})
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name = "username", nullable = false)private String username;@Column(name = "email", nullable = false)private String email;// getters and setters
}
在上述代码中,@Index 注解为 username 和 email 字段分别创建了索引,提升这两个字段的查询效率。
3.4 使用 Explain 分析 SQL 性能
在数据库查询中,可以使用 EXPLAIN 关键字来分析 SQL 执行计划,了解查询是如何进行的。下面是一个示例:
EXPLAIN SELECT * FROM users WHERE username = 'john_doe';
查询结果会显示数据库是如何处理查询的(如是否使用了索引,查询的成本如何等),帮助我们进一步优化查询。
第四部分:缓存机制
4.1 缓存的作用
缓存是提高查询效率的另一种重要手段。通过将经常访问的数据存储在内存中,减少对数据库的直接访问,从而减轻数据库的负载。常用的缓存技术包括 Redis、Memcached 等。
4.2 缓存设计策略
- 缓存热点数据:将频繁访问的数据存入缓存,减少对数据库的查询。
- 缓存更新策略:
- TTL(Time-to-Live):为缓存数据设置一个过期时间,过期后重新从数据库加载。
- 主动更新:当数据库中的数据发生变化时,主动更新缓存。
- 缓存与数据库一致性:通过合理的策略设计,确保缓存与数据库中的数据保持一致。
4.3 Redis 缓存的 Java 实现
在 Java 中,我们可以通过 Redis 来缓存查询结果。下面是一个使用 Spring Data Redis 的示例:
@Service
public class UserService {@Autowiredprivate UserRepository userRepository;@Autowiredprivate RedisTemplate<String, Object> redisTemplate;private static final String USER_CACHE_PREFIX = "user_";// 查询用户,先从缓存中获取,如果没有则查询数据库public User getUserById(Long id) {String key = USER_CACHE_PREFIX + id;// 尝试从缓存中获取数据User user = (User) redisTemplate.opsForValue().get(key);if (user == null) {// 缓存中没有数据,从数据库查询user = userRepository.findById(id).orElse(null);if (user != null) {// 将查询结果存入缓存redisTemplate.opsForValue().set(key, user, 1, TimeUnit.HOURS);}}return user;}
}
在这个示例中,getUserById 方法首先尝试从 Redis 缓存中获取数据。如果缓存中没有,则查询数据库,并将查询结果存入缓存,供下次查询使用。
4.4 本地缓存与分布式缓存
缓存可以分为本地缓存和分布式缓存:
- 本地缓存:存储在应用服务器本地内存中,速度最快,但适用于单实例部署。
- 分布式缓存:如 Redis、Memcached,适用于多实例应用,保证缓存数据的一致性。
通过引入缓存,可以有效减少对数据库的访问,从而提高查询性能。
第五部分:分库分表
5.1 分库分表的必要性
当单张表的数据量过大时,查询性能会显著下降。此时,分库分表是一种有效的优化手段。通过将数据分散到多个数据库或多张表中,可以减少单表的查询压力,从而提高查询效率。
5.2 垂直拆分与水平拆分
- 垂直拆分:根据业务逻辑将表中的字段拆分到不同的表或数据库中。例如,将用户表的基本信息和账户信息分别存储在不同的表中。
- 水平拆分:根据某个字段(如用户ID)将表的数据拆分到多张表中。例如,将用户表按照ID范围拆分为多个子表,如
user_01、user_02等。
5.3 分库分表的 Java 实现
分库分表通常需要结合分布式数据库中间件(如 ShardingSphere、Mycat)来实现。下面是一个使用 ShardingSphere 的示例:
ShardingSphere 配置示例:
sharding:tables:user:actual-data-nodes: ds${0..1}.user_${0..1}table-strategy:inline:sharding-column: idalgorithm-expression: user_${id % 2}key-generator:column: idtype: SNOWFLAKE
在这个配置中,user 表被水平拆分为两张子表 user_0 和 user_1,并且使用 id 进行分片。ShardingSphere 会根据 id 的值自动路由
查询到对应的子表。
第六部分:SQL 优化
6.1 避免全表扫描
全表扫描是导致查询性能低下的一个主要原因。在查询时,尽量避免使用 SELECT *,而是明确列出需要查询的字段,减少数据传输量。
-- 优化前
SELECT * FROM users WHERE age > 30;-- 优化后
SELECT username, email FROM users WHERE age > 30;
6.2 避免复杂的子查询
复杂的子查询往往会导致数据库需要进行多次扫描,影响查询性能。可以通过使用连接(JOIN)来替代子查询,减少扫描次数。
-- 使用子查询
SELECT * FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);-- 使用 JOIN 优化
SELECT users.* FROM users JOIN orders ON users.id = orders.user_id WHERE orders.amount > 100;
6.3 使用分页查询
在大数据量查询时,分页查询是有效减少数据量的方法之一。通过 LIMIT 和 OFFSET 可以实现分页查询。
-- 分页查询,返回第 2 页的数据,每页 10 条
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 10;
在分页查询时,尽量避免使用 OFFSET 的大值,这会导致性能下降。可以通过优化查询条件来减少 OFFSET 的影响。
第七部分:数据库连接池优化
7.1 数据库连接池的作用
数据库连接池可以复用数据库连接,减少频繁创建和关闭连接的开销。对于高并发场景,合理配置连接池的大小和连接超时时间,可以有效提高数据库访问性能。
7.2 Java 数据库连接池配置示例
在 Spring Boot 中,我们可以通过配置 HikariCP 连接池来优化数据库连接的使用:
spring:datasource:url: jdbc:mysql://localhost:3306/mydbusername: rootpassword: passwordhikari:maximum-pool-size: 20 # 最大连接数minimum-idle: 5 # 最小空闲连接数connection-timeout: 30000 # 连接超时时间(毫秒)idle-timeout: 600000 # 空闲连接存活时间(毫秒)
通过合理配置连接池的参数,可以有效提高数据库连接的复用率,减少连接创建和销毁的开销。
第八部分:Java 应用层优化
8.1 使用多线程并发提升查询效率
在 Java 应用中,可以通过引入多线程并发处理来提高查询效率。尤其在处理大量数据时,使用线程池并发执行多个查询任务可以显著提升系统的吞吐量。
8.2 多线程查询的 Java 实现
下面是一个使用 ExecutorService 实现多线程查询的示例:
import java.util.concurrent.*;public class MultiThreadQuery {public static void main(String[] args) throws InterruptedException {ExecutorService executor = Executors.newFixedThreadPool(10);for (int i = 0; i < 10; i++) {int queryId = i;executor.submit(() -> {// 模拟查询任务String result = queryDatabase(queryId);System.out.println("Query result for ID " + queryId + ": " + result);});}executor.shutdown();executor.awaitTermination(1, TimeUnit.MINUTES);}// 模拟数据库查询操作public static String queryDatabase(int id) {return "Result for ID " + id;}
}
在这个示例中,我们使用了线程池来并发执行多个查询任务,从而提高系统的查询吞吐量。
8.3 批量查询与处理
对于大批量数据的查询,可以采用批量查询和处理的方式,减少数据库查询的次数。批量查询可以通过分页实现,将查询结果按页返回并处理。
结论
当数据库成为性能瓶颈时,通过索引优化、缓存机制、分库分表、SQL 优化、连接池配置和 Java 应用层优化等手段,可以有效提升系统的查询效率。在实际项目中,开发者需要根据具体的业务场景,灵活选择和组合这些优化策略,以应对不同的性能挑战。
在大规模高并发的场景下,数据库性能瓶颈往往是整个系统性能的关键所在。通过本文中介绍的优化方案,能够帮助您有效解决数据库瓶颈问题,提升动态数据查询的效率。
相关文章:

提升动态数据查询效率:应对数据库成为性能瓶颈的优化方案
引言 在现代软件系统中,数据库性能是决定整个系统响应速度和处理能力的关键因素之一。然而,当系统负载增加,特别是在高并发、大数据量场景下,数据库性能往往会成为瓶颈,导致查询响应时间延长,影响用户体验…...

Prometheus+grafana+kafka_exporter监控kafka运行情况
使用Prometheus、Grafana和kafka_exporter来监控Kafka的运行情况是一种常见且有效的方案。以下是详细的步骤和说明: 1. 部署kafka_exporter 步骤: 从GitHub下载kafka_exporter的最新版本:kafka_exporter项目地址(注意ÿ…...

在vue中:style 的几种使用方式
在日常开发中:style的使用也是比较常见的: 亲测有效 1.最通用的写法 <p :style"{fontFamily:arr.conFontFamily,color:arr.conFontColor,backgroundColor:arr.conBgColor}">{{con.title}}</p> 2.三元表达式 <a :style"{height:…...

商城小程序后端开发实践中出现的问题及其解决方法
前言 商城小程序后端开发中,开发者可能会面临多种问题。以下是一些常见的问题及其解决方法: 一、性能优化 问题:随着用户量的增加和功能的扩展,商城小程序可能会出现响应速度慢、处理效率低的问题。 解决方法: 对数…...

阿里Arthas-Java诊断工具,基本操作和命令使用
Arthas 是阿里巴巴开源的一款Java诊断工具,深受开发者喜爱。它可以帮助开发者在不需要修改代码的情况下,对运行中的Java程序进行问题诊断和性能分析。 软件具体使用方法 1 启动 Arthas,此时可能会出现好几个jvm的进程号,输入序号…...

Go 1.19.4 路径和目录-Day 15
1. 路径介绍 存储设备保存着数据,但是得有一种方便的模式让用户可以定位资源位置,操作系统采用一种路径字符 串的表达方式,这是一棵倒置的层级目录树,从根开始。 相对路径:不是以根目录开始的路径,例如 a/b…...

jEasyUI 创建标签页
jEasyUI 创建标签页 jEasyUI(jQuery EasyUI)是一个基于jQuery的框架,它为Web应用程序提供了丰富的用户界面组件。标签页(Tabs)是jEasyUI中的一个常用组件,用于在一个页面内组织多个面板,用户可…...

鸿蒙HarmonyOS开发:一次开发,多端部署(界面级)天气应用案例
文章目录 一、布局简介二、典型布局场景三、侧边栏 SideBarContainer1、子组件2、属性3、事件 四、案例 天气应用1、UX设计2、实现分析3、主页整体实现4、具体代码 五、运行效果 一、布局简介 布局可以分为自适应布局和响应式布局,二者的介绍如下表所示。 名称简介…...

使用 Python 模拟光的折射,反射,和全反射
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

大厂太卷了!又一款国产AI视频工具上线了,免费无限使用!(附提示词宝典)
大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~ 记得去年刚开始分享 AI 视频工具的时候,介绍的大多…...

vue3扩展echart封装为组件库-快速复用
ECharts ECharts,全称Enterprise Charts,是一款由百度团队开发并开源,后捐赠给Apache基金会的纯JavaScript图表库。它提供了直观、生动、可交互、可个性化定制的数据可视化图表,广泛应用于数据分析、商业智能、网页开发等领域。以…...

随机掉落的项目足迹:Vue3 + wangEditor5富文本编辑器——toolbar.getConfig() 查看工具栏的默认配置
问题引入 小提示:问题引入是一个讲故事的废话环节,各位小伙伴可以直接跳到第二大点:问题解决 我的项目不需要在富文本编辑器中引入添加代码块的功能,于是我寻思在工具栏上把操作代码的菜单删一删 于是我来到官网文档工具栏配置 …...

更新 Git 软件
更新 Git 软件本身是指将你当前安装的 Git 版本升级到最新版本。不同的操作系统有不同的更新方法。以下是针对 Windows、macOS 和 Linux 的 Git 更新步骤: Windows 检查当前版本: git --version访问官网下载最新版本: 访问 Git 官方网站 (ht…...
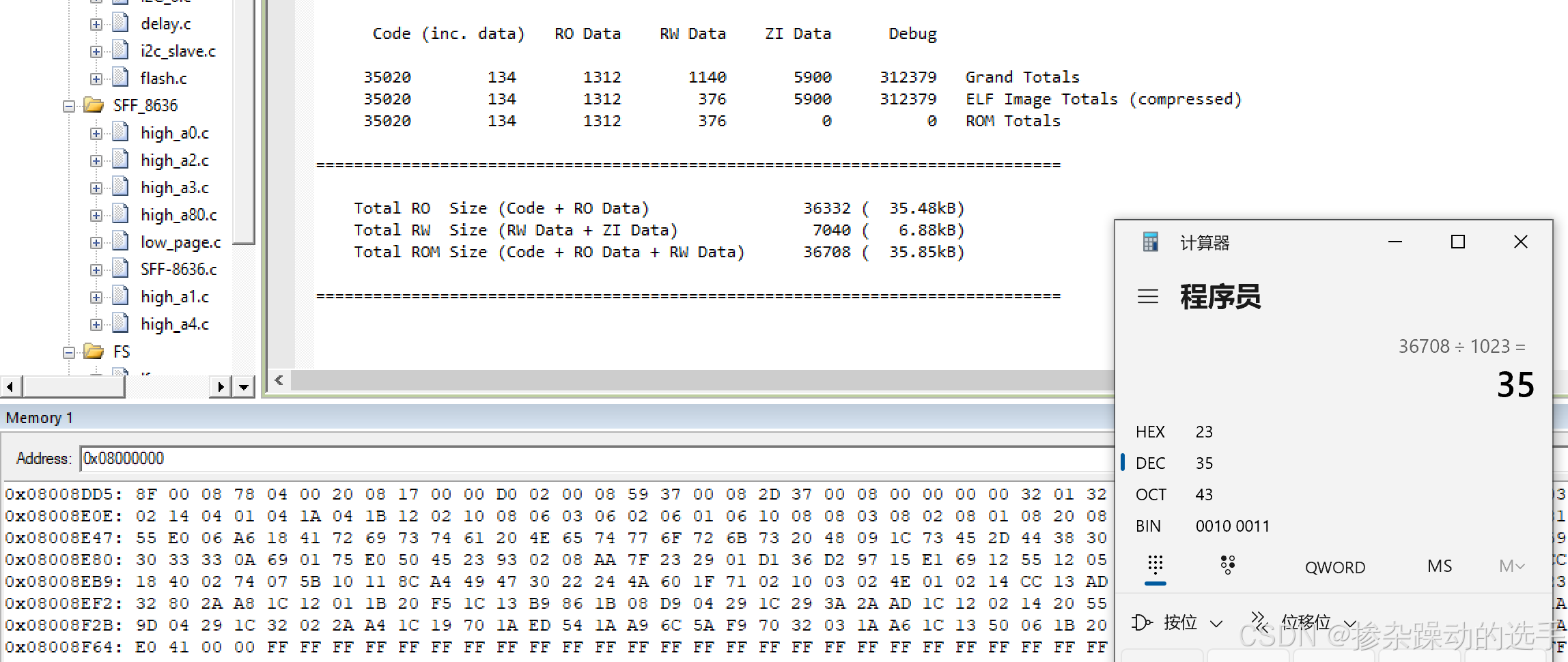
Keil根据map文件确定单片机代码存储占用flash情况
可以从map文件中查看得知,代码占用内存情况大概为35KB,而在在线仿真时,可以看到在flash的0x8008F64地址前均有数据,是代码数据,8F64(HEX)36708(DEC),36708/102335,刚好35。因此,要想操作读写flash,必须在不…...

ByteTrack多目标跟踪流程图
ByteTrack多目标跟踪流程图 点个赞吧,谢谢。...

什么是L2范数
定义: 在数学和计算中,L2 范数是一种用于测量向量长度或大小的方法,也被称为欧几里得范数。对于一个 n 维向量 x ( x 1 , x 2 , … , x n ) \mathbf{x} (x_1, x_2, \dots, x_n) x(x1,x2,…,xn),其 L2 范数定义为&#x…...
Scrapy爬虫IP代理池:提升爬取效率与稳定性
在互联网时代,数据就是新的黄金。无论是企业还是个人,数据的获取和分析能力都显得尤为重要。而在众多数据获取手段中,使用爬虫技术无疑是一种高效且广泛应用的方法。然而,爬虫在实际操作中常常会遇到IP被封禁的问题。为了解决这个…...
行业的发展)
信息技术(IT)行业的发展
近年来,信息技术(IT)行业的发展呈现出前所未有的活力和潜力。随着全球数字化转型的加速,IT行业正逐步成为推动社会经济发展的重要引擎。无论是互联网、大数据、人工智能,还是云计算、物联网,这些新兴技术都…...

C++primer第十一章使用类(矢量随机游走实例)
操作符重载 操作符重载(operator overoading)是一种形式的 C多态。 第8章介绍了C是如何使用户能够定义多个名称相同但特征标(参数列表)不同的函数的。这被称为函数重载(function overloading)或函数多态(functional polymorphism),旨在让您能够用同名的函数来完成…...

服务器为什么会受到网络攻击?
随着科技的 快速发展,企业也开展了越来越多的线上业务,但同时也遭受到各种各样的网络攻击,那服务器为什么会受到网络攻击呢?下面就让小编带领大家一起来了解一下吧! 首先企业中服务器被攻击的原因有很多,主…...
)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码) 在编程的世界里,字符处理是最基础却又最容易被忽视的技能之一。很多C语言初学者在学习过程中,往往对字符和字符串的操作感到困惑——为什么a和A是不同的&…...
)
uni-app视频播放二选一:手把手对比调试video.js与MuiPlayer插件(H5/m3u8实战)
uni-app视频播放方案深度对比:video.js与MuiPlayer在H5/m3u8场景下的实战抉择 当uni-app开发者面临H5端m3u8视频播放需求时,技术选型往往成为项目推进的第一道门槛。video.js与MuiPlayer作为两大主流解决方案,各自拥有独特的生态优势与适配特…...

CANN/asc-devkit log1pf函数文档
log1pf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

UVM寄存器模型简化实践:提升芯片验证效率的封装与自动化方案
1. 项目概述:为什么我们需要简化UVM寄存器模型?如果你在芯片验证领域摸爬滚打过几年,尤其是深度参与过SoC或复杂IP的验证,那么对UVM寄存器模型(UVM Register Model)一定是又爱又恨。爱的是,它提…...

RT-Thread Studio开发RA2L1:从环境搭建到GPIO输入输出实战
1. 项目概述与核心价值最近在捣鼓瑞萨电子的RA2L1 MCU开发板,想基于RT-Thread Studio这个国产IDE快速上手。我发现很多朋友拿到一块新板子,第一步“点亮LED”或者“读取按键”这个看似简单的操作,往往就卡在了环境搭建上。网上的资料要么过于…...
)
5个真正赚钱的 AI 工作流 (2026)
AI驱动的创作者经济预计在2026年将达到57.1亿美元。但大多数使用AI工具的人仍然把它们当作搜索引擎——提问,获取答案,关闭标签页,明天重新开始。真正赚到钱的人发现了不同的东西:他们建立了能复合增长的工作流。代理每次运行都会…...

3分钟免费汉化Android Studio:社区中文语言包完整安装教程
3分钟免费汉化Android Studio:社区中文语言包完整安装教程 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Andr…...

基于Atmega8的红外通信系统:从原理到自定义协议实现
1. 项目概述:为什么是Atmega8?在嵌入式开发领域,红外遥控是一个经典且应用广泛的课题。从家里的电视、空调遥控器,到一些工业设备的非接触式控制,红外通信无处不在。市面上有大量现成的红外编解码芯片,比如…...
)
告别轮询!用STM32CubeMX和DMA实现ADC多通道‘无感’采集与串口打印(附完整工程)
告别轮询!STM32CubeMX与DMA实现ADC多通道无感采集实战指南 在嵌入式开发中,数据采集系统的效率往往决定了整个应用的性能上限。传统轮询方式不仅消耗大量CPU资源,还会引入不可预测的延迟。想象一下,当你需要同时监测多个环境传感器…...
)
【会议征稿通知 | E3S出版 | EI 、Scopus稳定检索】第十二届能源材料与环境工程国际学术会议(ICEMEE 2026)
第十二届能源材料与环境工程国际学术会议(ICEMEE 2026) 2026 12th International Conference on Energy Materials and Environment Engineering 2026年6月12-14日 | 线上会议 大会官网:www.icemee.net 截稿时间:见官网&#x…...