mini-lsm通关笔记Week2Overview
Week 2 Overview: Compaction and Persistence

在上周,您已经实现了LSM存储引擎的所有必要结构,并且您的存储引擎已经支持读写接口。在本周中,我们将深入探讨SST文件的磁盘组织,并研究在系统中实现性能和成本效益的最佳方法。我们将花4天时间学习不同的compaction策略,从最简单的到最复杂的,然后为存储引擎持久化实现剩下的部分。在本周结束时,您将拥有一个功能齐全且高效的LSM存储引擎。
合并和读放大
我们先来说说合并。在前面的部分中,我们简单地将memtable转储到一个L0 SST中。想象一下,你已经写入了千兆字节的数据,现在你有100个SST。每个读请求(不过滤)需要从这些SST读取100个块。这个放大就是读放大——一个get操作需要发送到磁盘的I/O请求数。
为了减少读取放大,我们可以将所有L0 SST合并到一个更大的结构中,这样就可以只读取一个SST和一个块来检索请求的数据。假设我们还有这100个SST,现在,我们对这100个SST进行合并排序,以生成另外100个SST,每个SST都包含不重叠的键值范围。这个过程就是合并,这100个不重叠的SST就是一个排序的run。
为了使这一过程更加清晰,让我们来看一个具体的示例:
SST 1: key range 00000 - key 10000, 1000 keys
SST 2: key range 00005 - key 10005, 1000 keys
SST 3: key range 00010 - key 10010, 1000 keys
在LSM结构中,我们有3个SST。如果我们需要访问键02333,我们需要探测这3个SST。如果我们可以进行合并,我们可能会得到以下3个新的SST:
SST 4: key range 00000 - key 03000, 1000 keys
SST 5: key range 03001 - key 06000, 1000 keys
SST 6: key range 06000 - key 10010, 1000 keys
通过合并SST 1、2和3创建3个新SST。我们可以得到一个排序后的3000个key,然后将它们拆分成3个文件,这样就可以避免一个超大的SST文件。现在我们的LSM状态有3个不重叠的SST,我们只需要访问SST 4,找到键02333。
合并和写放大的两个极端
因此,从上面的例子中,我们有2种幼稚的方法来处理LSM结构—根本不进行合并,和总是在转储新的SST时进行完全合并。
合并是一个耗时的操作。它需要从某些文件中读取所有数据,并将相同数量的文件写入磁盘。这个操作会占用大量的CPU资源和I/O资源。完全不做合并会导致高读放大,但它不需要写入新文件。总是执行完全合并可以减少读取放大,但它需要不断地重写磁盘上的文件。


转储到磁盘的memtables与写入磁盘的总数据的比值就是写放大。也就是说,没有合并的写放大率是1倍,因为一旦SST被转储到磁盘,它们就会一直停留在那里。总是做合并有非常高的写放大。如果我们在每次获取SST时都执行一次完全合并,那么写入磁盘的数据将是转储SST数量的二次方。例如,如果我们将100个SST转储到磁盘,我们将执行2个文件、3个文件、…100个文件的合并,其中我们实际写入磁盘的数据总量约为5000个SST。在这种情况下,写入100个SST后的写放大将是50倍。
一个好的合并策略可以在读放大、写放大和空间放大(我们后面会讲到)之间取得平衡。在通用的LSM存储引擎中,通常不可能找到一种策略,可以在所有这3个因素中实现最低的放大,除非引擎可以使用某些特定的数据模式。LSM的好处是,我们可以从理论上分析合并策略的放大,所有这些事情都发生在后台。我们可以选择合并策略,并动态地改变其中的一些参数,从而将我们的存储引擎调整到最佳状态。合并策略都是关于权衡的,基于LSM的存储引擎让我们可以在运行时选择要交换的内容。

业内一个典型的业务场景是这样的:用户在启动一个产品时,首先将数据批量注入到存储引擎中,通常是每秒千兆字节。然后,系统上线,用户开始在系统上做小交易。在第一阶段,引擎应该能够快速存储数据,因此我们可以使用最小化写入放大的合并策略来加速这一过程。然后,我们调整合并算法的参数,使其针对读放大进行优化,并做一次完全的合并,对已有的数据进行重新排序,这样系统上线后就可以稳定运行了。
如果业务场景类似于时间序列数据库,则用户可能总是按时间填充和截断数据。因此,即使没有合并,这些append-only的数据仍然可以在磁盘上具有低放大。因此,在现实生活中,你应该注意用户的模式或特定需求,并利用这些信息来优化你的系统。
合并策略概述
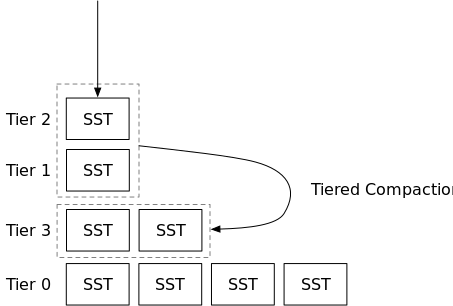
合并策略通常的目的是控制排序的run层数,从而使读放大保持在一个合理的数量。通常有两类合并策略:分级(leveled)和分层(tiered)。
在分级合并中,用户可以指定最大级别数,即系统中排序的run的层数(L0除外)。例如,RocksDB通常在分级合并模式下保持6级(排序的run)。在合并过程中,来自两个相邻层的SST将被合并,然后产生的SST将被放到两个层的较低层。因此,在分级合并中,您通常会看到一个小的排序的run与一个大的排序的run合并。排序的run(级别)在大小上呈指数增长-较低的级别在大小上将是较高的级别的<some number>倍。

在分层合并中,引擎将通过合并它们或让转储新的SST作为新的排序的run(层)来动态调整排序的run的数量,以最小化写入放大。在此策略中,您通常会看到引擎合并两个大小相等的排序的run。如果合并策略不选择合并层,则层数可能会很高,因此读取放大率会很高。在本教程中,我们将实现RocksDB的通用合并,这是一种分层合并策略。
空间放大
计算空间放大的最直观方法是将LSM引擎使用的实际空间除以用户空间使用量(即数据库大小或数据库中的行数等)。引擎将需要存储删除的墓碑,有时,如果合并发生得不够频繁,则会有同一个键的多个版本,因此会导致空间放大。
在引擎端,通常很难知道用户存储的确切数据量,除非我们扫描整个数据库,看看引擎中到底有多少个不再使用的版本。因此,估计空间放大的一种方法是将完整存储文件大小除以最后一级大小。这种估算方法背后的假设是,用户填充初始数据后,工作负载的插入率和删除率应该是相同的。我们假设用户端的数据大小不会改变,因此最后一层包含用户数据在某个时刻的快照,而上层包含新的更改。当合并将所有内容合并到最后一层时,使用这种估计方法,我们可以得到1x的空间放大系数。
请注意,合并也会占用空间——在合并完成之前,您不能删除正在合并的文件。如果您对数据库执行完全合并,您将需要与当前引擎文件大小相同的可用存储空间。
在这一部分中,我们将有一个合并模拟器来帮助你可视化合并过程和你的合并算法的决策。我们提供了最小的测试用例来检查您的合并算法的属性,您应该密切关注统计信息和合并模拟器的输出,以了解您的合并算法的工作情况。
持久化
在实现了合并算法之后,我们将在系统中实现两个关键组件:manifest,这是一个存储LSM状态的文件,WAL,它将memtable数据持久化到磁盘,然后作为SST刷新。完成这两个组件后,存储引擎将拥有完整的持久化支持,可以在您的产品中使用。
如果不想太深入探讨合并,也可以先看完2.1和2.2章,实现一个非常简单的Leveled合并算法,直接进入持久化部分。在第2周构建一个可工作的存储引擎时,不需要实现完全的leveled合并和universal合并。
零食时间
在实现了合并和持久化之后,我们将有一个关于实现批量写入接口和校验和的简短章节。
相关文章:
mini-lsm通关笔记Week2Overview
Week 2 Overview: Compaction and Persistence 在上周,您已经实现了LSM存储引擎的所有必要结构,并且您的存储引擎已经支持读写接口。在本周中,我们将深入探讨SST文件的磁盘组织,并研究在系统中实现性能和成本效益的最佳方法。我们…...
基于SpringBoot的在线点餐系统【附源码】
基于SpringBoot的高校社团管理系统(源码L文说明文档) 4 系统设计 4.1 系统概述 网上点餐系统的结构图4-1所示: 图4-1 系统结构 模块包括主界面,首页、个人中心、用户管理、美食店管理、美食分类管理、美食…...

生成式语言模型底层技术面试
在准备生成式语言模型的底层技术面试时,可以关注以下几个关键领域: 1. 模型架构 Transformer架构:了解自注意力机制、编码器-解码器结构,以及如何处理序列数据。预训练与微调:解释预训练和微调的过程,如何…...

HTML开发指南
目录 一、HTML基础1. HTML简介(1)标记语言(2)结构化文档(3)标签与属性(4)注释(5)版本演变 2. HTML文档结构(1)文档类型声明࿰…...

共筑数据安全防线!YashanDB与SPU完成兼容性互认证
近日,深圳计算科学研究院崖山数据库系统YashanDB与深圳市机密计算科技有限公司SPU机密计算协处理器顺利完成兼容性互认证。测试结果表明,双方产品完全兼容,稳定运行,能为用户提供全链路的数据安全管理解决方案,助力央国…...
)
【FastAPI】使用FastAPI和Redis实现实时通知(SSE)
在当今快速发展的Web应用程序中,实时通知已成为用户体验的重要组成部分。无论是社交媒体更新、消息通知,还是系统状态提醒,实时数据推送可以极大地提升用户互动性。本文将详细介绍如何使用FastAPI和Redis实现Server-Sent Events (SSE) 来推送…...

Keyence_PL_MC_HslCommunication import MelsecMcNet
import tkinter as tk from tkinter import messagebox from datetime import datetime from HslCommunication import MelsecMcNet, OperateResult def 创建_plc_应用程序(): class 应用程序(tk.Tk): def __init__(self): super().__init__() …...
)
软件架构的演变与趋势(软件架构演变的阶段、综合案例分析:在线电商平台架构演变、开发补充)
随着软件开发技术的不断进步,软件架构从最初的简单结构演变为如今的复杂系统,架构设计不再是简单的代码组合,而是战略性的系统设计,确保系统具备可扩展性、可靠性、安全性和可维护性。 文章目录 1. 软件架构演变的阶段1.1 单体架…...

Shopify独立站运营必知必会:选品与防封技巧
独立站和第三方平台是目前最常见的跨境电商销售模式,相比于第三方平台,独立站的商家可以自己建站,自行决定运营模式和营销手段等策略,尤其是在准入门槛上,难度会更低,这些特点吸引了不少商家选择独立站开店…...

Unity开发绘画板——03.简单的实现绘制功能
从本篇文章开始,将带着大家一起写代码,我不会直接贴出成品代码,而是会把写代码的历程以及遇到的问题、如何解决这些问题都记录在文章里面,当然,同一个问题的解决方案可能会有很多,甚至有更好更高效的方式是…...

R语言的基础知识R语言函数总结
R语言与数据挖掘:公式;数据;方法 R语言特征 对大小写敏感通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母)。不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头&…...

龙年国庆专属姓氏头像
关注▲洋洋科创星球▲一起成长! 2024年,我们迎来了龙年,龙年国庆姓氏头像! 慢慢找! 你的和你朋友的都有。 01赵 02 钱 03 孙 04 李 05 周 06 吴 07 郑 08 王 09 冯 010 陈 011 褚 012 卫 013 蒋 014 沈 015 韩 姓氏…...

基于Es和智普AI实现的语义检索
1、什么是语义检索 语义检索是一种利用自然语言处理(NLP)和人工智能(AI)技术来理解搜索查询的语义,以提供更准确和相关搜索结果的搜索技术,语义检索是一项突破性的技术,旨在通过深入理解单词和…...

URI和URL的区别
1: 将 URI 转换为 URL import java.net.URI; import java.net.URL;public class UriToUrlExample {public static void main(String[] args) {// 创建一个 URI 对象URI uri = new URI("http://example.com/path/to/resource");// 将 URI 转换为 URLtry {URL url = u…...

Java 入门指南:获取对象的内存地址
文章目录 hashCode()应用重写 hashCode() 方法示例 Symstem . indentityHashCode()应用 注意事项 在 Java 开发中,了解对象的内存管理是十分重要的,尽管 Java 的设计初衷是让开发者更专注于业务逻辑而非底层资源管理。但在某些情况下,了解对象…...

【Linux】项目自动化构建工具-make/Makefile 详解
🔥 个人主页:大耳朵土土垚 🔥 所属专栏:Linux系统编程 这里将会不定期更新有关Linux的内容,欢迎大家点赞,收藏,评论🥳🥳🎉🎉🎉 文章目…...

嵌入式开发中学习C++的用处?
这个问题一直有同学在问,其实从我的角度是一定是需要学的,最直接的就是你面试大厂的嵌入式岗位或者相关岗位,最后一定会问c,而很多人是不会的,这就是最大的用处,至于从技术角度考量倒是其次,因为…...

基于SAM大模型的遥感影像分割工具,用于创建交互式标注、识别地物的能力,可利用Flask进行封装作为Web后台服务
如有帮助,支持一下(GitHub - Lvbta/ImageSegmentationTool-SAM: An interactive annotation case developed based on SAM for remote sensing image annotation, which can generate corresponding segmentation results based on point, multi-point, …...

Selenium入门
Selenium 是一个用于自动化 web 应用程序测试的工具,它支持多种浏览器和编程语言。 下载驱动程序:根据你的浏览器类型和版本,下载相应的 WebDriver。例如,Chrome 浏览器需要 ChromeDriver。 安装 Selenium 库 pip install sele…...

USB 3.1 Micro-A 与 Micro-B 插头,Micro-AB 与 Micro-B 插座,及其引脚定义
连接器配对 下表列出 USB 插座可接受的插头: USB 3.1 Micro-B 连接器 USB 3.1 Micro-B 插头和 USB 3.1 Micro-B 插座连接器是为小型手持设备和其他可能使用小尺寸连接器的应用而定义的。其定义使得 USB 3.1 Micro-B 插座既可以接受 USB 3.1 Micro-B 插头ÿ…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

多模态AI实战:基于OpenGVLab/Ask-Anything构建视觉问答系统
1. 项目概述:当视觉大模型学会“看图说话”最近在折腾多模态AI应用,发现了一个挺有意思的开源项目,叫OpenGVLab/Ask-Anything。简单来说,它就像一个给AI装上了“眼睛”和“嘴巴”的系统,你给它一张图片或一段视频&…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

MacOS光标增强工具:命令行驱动,实现自动化与个性化配置
1. 项目概述:当光标成为生产力工具如果你是一名长期在macOS上工作的开发者、设计师或者文字工作者,你肯定对系统自带的光标功能又爱又恨。爱的是它简洁流畅,恨的是它在某些高强度、多任务场景下显得力不从心。比如,当你需要在多个…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...