关于 NLP 应用方向与深度训练的核心流程
文章目录
- 主流应用方向
- 核心流程(5步)
- 1.选定语言模型结构
- 2.收集标注数据
- 3.forward 正向传播
- 4.backward 反向传播
- 5.使用模型预测真实场景
主流应用方向
- 文本分类
- 文本匹配
- 序列标注
- 生成式任务
核心流程(5步)

基本流程实现的先后顺序(每一步都包含很多技术点):
1.选定语言模型结构
- 语言模型作用
判断那一句话相对更合理,相对不合理的会得到较底的分值,需要挑选成句概率分值最高的。 - 评价指标:PPL(Perplexity) 困惑度
- 评估一个语言模型在给定数据集上的预测效果
- PPL 值与成句概率成反比(PPL 越小,成句概率越高)
- 模型分类
- SLM 统计语言模型
ngram - NLM 神经语言模型(2003)
RNN(循环神经网络)
LSTM(RNN 进阶版)
CNN(卷积神经网络)
GRU - PLM 预训练语言模型(2018)
- 基于 Transformer 架构
- BERT(预训练模型)
生成式任务是逐词预测,bert 是预测缺失的词或者句子前后关系 - GPT
生成式模型 - 一系列类 bert 模型
- BERT(预训练模型)
- 基于 Transformer 架构
- LLM 大语言模型(2023)
GhatGPT
- SLM 统计语言模型
2.收集标注数据
- 样本数据
- 预测数据
3.forward 正向传播
- 模型超参数随机初始化
- 训练轮数:epoch_num
- 每次训练样本个数:batch_size
- 样本文本长度:window_size
- 学习率:lr
- 隐藏层:hidden_size
- 模型层数:layer_num
-
构建词表
load_vocab -
构建数据集
dataset -
模型组成
-
离散值连续化(可选)
- Padding(可选)
- 将不同长度的文本补齐或截断到统一长度
- 使得不同长度的文本可以放在同一个batch内运算
- 补齐所使用的token需要有对应的embedding向量
- embedding 层
- 作用:
- 将字符转为向量
将离散型的输入数据(如单词、类别等)映射到连续的向量空间中 - 核心
将离散值转化为向量
- 将字符转为向量
- 形状:[vocab_dim, hidden_size]
hidden_size 是embedding 的下一层模型的输入形状
- 作用:
- Padding(可选)
-
模型结构处理连续数据
-
pooling 池化层
embedding 结果要先转置后才能 pooling
embedding.transpose(1,2)- 作用
- 降低后续网络层的输入维度
- 缩减模型大小
-提高计算速度 - 提高鲁棒性,防止过拟合
- 分类
- 平均池化
- 最大池化
- 作用
-
全连接层
- 作用
- 将前面层提取到的特征进行组合和加权
- 参数可通过反向传播学习,适应不同数据和任务
- 提高模型的表示能力
- 更好地捕捉数据中的复杂模式和关系
- 通过堆叠多个全连接层,结合非线性激活函数,模型就可以学习更复杂的非线性映射
- 分类与回归
- 分类任务中
- 将特征映射到不同类别的概率分布上
- 方便模型对输入进行分类
- 回归任务中
生成连续值的预测
- 分类任务中
- 参数
- 权重(Weights)
- 是模型中每个神经元或连接的参数
- 权重矩阵定义了输入和输出之间的关系
- 偏置(Biases)
额外参数,与权重一起用于计算激活函数的输入
- 权重(Weights)
- 作用
-
激活函数(可选)
不会改变输入内容的形状- 作用
- 引入非线性变换
- 全连接层仅可线性变换
- 将激活函数结果传递给下一个全连接层,可在学习复杂任务时,更好的表达数据的抽象特征
- 约束输出范围
- 提高模型的数值稳定性
- 引入非线性变换
- 常用激活函数
- Sigmoid
- tanh
RNN 自带一个 tanh - Relu
可以防止梯度消失问题 - Gelu
- 作用
-
Normalization 归一化层(可选)
对输入数据进行归一化处理,使其具有零均值和单位方差,加速模型训练过程,提高模型稳定性和收敛速度
- 代码
from torch.nn import BatchNorm1d
self.bn1 = BatchNorm1d(50) - 分类
- 批量归一化 batch normalization
对每一层的向量求平均,再求标准差,之后进行公式计算,获得可训练参数- 样本与其他样本归一化,适合 cv
- 适合两张图片之间相似度评价
- 层归一化 layer normalization
纵向向量求平均,再求标准差,之后进行公式计算,获得可训练参数- 样本内进行归一化,适合 nlp
- 适合文本
- 批量归一化 batch normalization
- dropout 层(可选)
- 代码
from torch.nn import Dropout
self.dropout = Dropout(0.5) - 是一种常用的正则化技术
- 作用
- 减少神经网络的过拟合
- 提高模型的泛化能力
- 强制网络学习更加健壮和泛化的特征
- 减少神经元之间的依赖关系
- 使得网络更加鲁棒
- 在训练期间
- 随机“丢弃”一些神经元
以一定的概率(通常在0.2到0.5之间)随机地将隐藏单元的输出置为零 - 保持总体期望值不变
将其余值按比例进行缩放
- 随机“丢弃”一些神经元
- 在测试期间
Dropout不会应用,而是将所有神经元的输出乘以保留概率,以保持输出的期望值
- 作用
- 代码
-
-
获取预测值
-
计算 loss
是指预测值与样本真实值之间的loss计算。- 常见 loss 函数
- 均方差(MSE)
回归场景 - 交叉熵(Cross Entropy)
分类场景 - BCE 0/1损失
分类场景,一般输入为 sigmod 的输出 - 指数损失
- 对数损失
- Hinge损失
- 均方差(MSE)
- 常见 loss 函数
4.backward 反向传播
- Optimizer 优化器
-
Adam
- SGD 进阶版
- 在模型的权重没有收敛之前(没有训练到预期结果之前),不断循环计算,历史每轮的梯度都参与计算。
- 可无脑选择使用的优化器。是非常好的baseLine,一般出问题,不会因为adam 出问题。
- 特点

- 实现

- 一阶动量
历史 n 轮梯度差值 - 二阶动量
历史 n 轮梯度的平方差 - 避免由于一阶动量与二阶动量初始值为零向量,引起参数估计偏向于 0 的问题
- 一阶动量偏差修正
一阶动量历史累计值/(1-超参数 t 次方) - 二阶动量偏差修正
二阶动量历史累计值/(1-超参数 t 次方)
- 一阶动量偏差修正
- 权重更新
- 一阶动量
-
SGD
计算逻辑:新权重 = 旧权重 - 学习率 * 梯度
- optmi->梯度归零
optimizer.zero_grad() - loss->反向传播,计算梯度
loss.backward() - optim->更新权重
optimizer.step()
-
5.使用模型预测真实场景
经过前4步,得到训练好的模型,将模型投放到真实场景进行预测。
相关文章:
关于 NLP 应用方向与深度训练的核心流程
文章目录 主流应用方向核心流程(5步)1.选定语言模型结构2.收集标注数据3.forward 正向传播4.backward 反向传播5.使用模型预测真实场景 主流应用方向 文本分类文本匹配序列标注生成式任务 核心流程(5步) 基本流程实现的先后顺序…...

linux如何启用ipv6随机地址
简介 在 IPv6 中,临时随机地址(Temporary IPv6 Address)是一种为了提高隐私和安全而设计的功能。通常,默认的 IPv6 地址是基于设备的 MAC 地址生成的,容易导致跟踪和识别设备。启用临时 IPv6 地址可以避免这个问题&am…...

探索 Android DataBinding:实现数据与视图的完美融合
在 Android 开发中,数据与视图的交互一直是一个关键的问题。为了更好地实现数据的展示和更新,Google 推出了 DataBinding 库,它为开发者提供了一种简洁、高效的方式来处理数据与视图之间的绑定关系,大大提高了开发效率和代码的可读…...

Java 编码系列:线程基础与最佳实践
引言 在多任务处理和并发编程中,线程是不可或缺的一部分。Java 提供了丰富的线程管理和并发控制机制,使得开发者可以轻松地实现多线程应用。本文将深入探讨 Java 线程的基础知识,包括 Thread 类、Runnable 接口、Callable 接口以及线程的生命…...

《深度学习》—— ResNet 残差神经网络
文章目录 一、什么是ResNet?二、残差结构(Residual Structure)三、Batch Normalization(BN----批归一化) 一、什么是ResNet? ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获…...

针对考研的C语言学习(定制化快速掌握重点3)
1.数组常见错误 数组传参实际传递的是数组的起始地址,若在函数中改变数组内容,数组本身也会发生变化 #include<stdio.h> void change_ch(char* str) {str[0] H; } int main() {char ch[] "hello";change_ch(ch);printf("%s\n&q…...

pikachu XXE(XML外部实体注入)通关
靶场:pikachu 环境: 系统:Windows10 服务器:PHPstudy2018 靶场:pikachu 关卡提示说:这是一个接收xml数据的api 常用的Payload 回显 <?xml version"1.0"?> <!DOCTYPE foo [ <!ENTITY …...

shell脚本定时任务通知到钉钉
shell脚本定时任务通知到钉钉 1、背景 前两天看了一下定时任务,垃圾清理、日志相关、系统巡检这些,有的服务器运行就有问题,或者不运行,正好最近在做运维标准重制运维手册,顺便把自动化这块优化一下,所…...
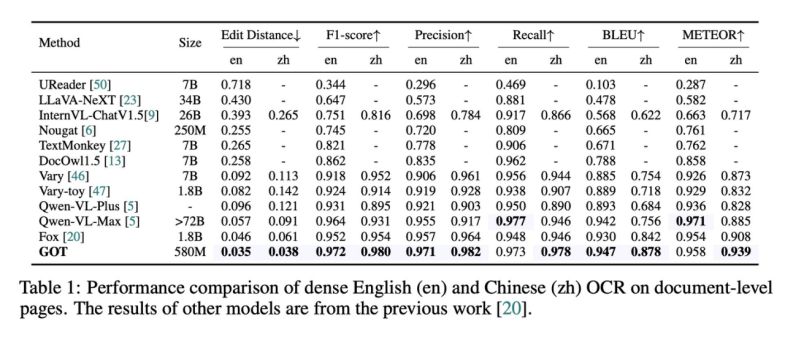
2.4K star的GOT-OCR2.0:端到端OCR 模型
GOT-OCR2.0是一款新一代的光学字符识别(OCR)技术,标志着人工智能在文本识别领域的重大进步。作为一款开源模型,GOT-OCR2.0不仅支持传统的文本和文档识别,还能够处理乐谱、图表以及复杂的数学公式,为用户提供…...

【JavaEE】——线程的安全问题和解决方式
阿华代码,不是逆风,就是我疯,你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 一:问题引入 二:问题深入 1:举例说明 2:图解双线程计算…...

初步认识了解分布式系统
背景认识:我们要学习redis,还是得了解一下什么是分布式。为什么呢?因为redis只有在分布式系统中才能发挥它最大的作用,也就是领域展开,所以接下来我们就简单过一下什么是分布式系统 一些术语认识: &#x…...

react 为什么不能学习 vue3 进行静态节点标记优化性能?
因为 React 使用的是 JSX,而 JSX 本质上就是 JS 语言,是具有非常高的动态的,而 Vue 使用的 template 则是给了足够的约束,比如说 Vue 的 template 里面使用了很多特定的标记来做不同的事情,比如说 v-if 就是进行变量判…...

Elasticsearch黑窗口启动乱码问题解决方案
问题描述 elasticsearch启动后有乱码现象 解决方案: 提示:这里填写该问题的具体解决方案: 到 \config 文件下找到 jvm.options 文件 打开后 在文件末尾空白处 添加 -Dfile.encodingGBK 保存后重启即可。...

Logtus IT员工参加国际技术大会
Logtus IT的员工参加了国际技术大会,该大会致力于在金砖国家框架内开发俄罗斯的技术。该活动包括一个展览,俄罗斯开发商展示了他们的信息技术、电子和电信成就。展示了面向国内和国际市场(包括政府机构)的解决方案、产品和平台。 …...

ant design vue组件中table组件设置分组头部和固定总结栏
问题:遇到了个需求,不仅要设置分组的头部,还要在顶部有个统计总和的栏。 分组表头的配置主要是这个,就是套娃原理,不需要展示数据的直接写个title就行,需要展示数据的字段才需要详细的配置属性。 const co…...
2024年信息安全企业CRM选型与应用研究报告
数字化的生活给人们带来便利的同时也带来一定的信息安全隐患,如网络侵权、泄露用户隐私、黑客攻击等。在互联网高度发展的今天,信息安全与我们每个人、每个组织甚至每个国家都息息相关。 信息安全行业蓬勃发展。根据智研咨询数据,2021年&…...

【后端开发】JavaEE初阶——计算机是如何工作的???
前言: 🌟🌟本期讲解计算机工作原理,希望能帮到屏幕前的你。 🌈上期博客在这里:【MySQL】MySQL中JDBC编程——MySQL驱动包安装——(超详解) 🌈感兴趣的小伙伴看一看小编主…...
源码安装postgresql16.3)
Linux(Ubuntu)源码安装postgresql16.3
文章目录 Linux(Ubuntu)源码安装postgresql016.3下载程序包编译安装软件初次执行configure错误调试1:configure: error: ICU library not found再次执行configureBuild 设置环境初始化数据库启动数据库参考 Linux(Ubuntu)源码安装…...
面向对象 | 7.6、多态)
Python 入门教程(7)面向对象 | 7.6、多态
文章目录 一、多态1、鸭子类型2、实现多态的机制2.1、鸭子类型2.2、继承与重写 3、Python多态的优势4、总结 前言: 在面向对象编程(OOP)中,多态(Polymorphism)是一种非常重要的概念,多态就是同一…...

Cilium + ebpf 系列文章-什么是ebpf?(一)
前言: 这篇非常非常干,很有可能读不懂。 这里非常非常推荐,建议使用Cilium官网的lab来辅助学习!!!Resources Library - IsovalentExplore Isovalents Resource Library, your one-stop destination for ins…...

WarcraftHelper:魔兽争霸3现代化增强插件,解锁经典游戏新体验
WarcraftHelper:魔兽争霸3现代化增强插件,解锁经典游戏新体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是…...

1987年4月26日中午11-13点出生性格、运势和命运
在1987年4月26日中午11 - 13点出生的人,正处于火兔年的特定时段。从性格层面来看,这一时间段出生者往往有着热情似火且积极向上的特质。他们如同正午炽热的阳光,充满活力与冲劲,对生活始终保持着乐观的态度,面对困难时…...

046、PCIE桥设备与交换:当拓扑开始复杂起来
046、PCIE桥设备与交换:当拓扑开始复杂起来 最近在调一块自定义的PCIE扩展板,系统里突然出现了几个“神秘”的端点设备。在lspci列表里,它们出现在一个我从未配置过的总线号上,而且设备ID全对不上。折腾了两天才发现,原…...

开源中国双核战略:AI普惠生态的破局之道
当全球AI产业进入深水区,技术突破与商业落地之间的鸿沟日益凸显。开源中国以"模力方舟"和"口袋龙虾"双核驱动战略,正在构建一个从云端到终端的完整AI应用生态,为中国AI产业提供了一条独特的普惠化路径。这一战略不仅解决…...

XSS-Game 实战解析:从Level1到Level18的攻防思维演进
1. XSS-Game入门:理解基础注入逻辑 第一次接触XSS-Game时,很多人会疑惑这到底是个什么游戏。简单来说,这是一个专门设计用来练习XSS(跨站脚本攻击)技术的在线靶场,包含18个难度递增的关卡。每个关卡都模拟了…...

血管分割新突破:详解DSCNet中的蛇形卷积如何解决管状结构难题
血管分割新突破:详解DSCNet中的蛇形卷积如何解决管状结构难题 在医学影像分析领域,血管分割一直是个令人头疼的问题。想象一下,当你面对一张OCTA(光学相干断层扫描血管成像)图像时,那些细如发丝、蜿蜒曲折…...

Mac玩转老游戏:手把手教你用Wineskin配置RPG Maker游戏所需RTP环境
Mac玩转老游戏:手把手教你用Wineskin配置RPG Maker游戏所需RTP环境 在Mac上重温经典RPG游戏是许多怀旧玩家的梦想,但RPG Maker游戏往往依赖Windows特有的运行时包(RTP),这让Mac用户望而却步。本文将带你深入探索如何利…...

Python开发者三步完成Taotoken API密钥配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken API密钥配置与调用 对于希望快速接入大模型能力的Python开发者而言,Taotoken平台提供的…...

新手如何通过Taotoken控制台快速创建并管理自己的API Key
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手如何通过Taotoken控制台快速创建并管理自己的API Key 对于初次接触大模型服务的开发者而言,如何安全、便捷地获取和…...

Spring Cloud整合XXL-Job避坑指南:调度过期策略选错,你的定时任务可能就白跑了
Spring Cloud微服务中XXL-Job调度策略深度解析与实战避坑 在微服务架构盛行的今天,定时任务作为业务系统中不可或缺的一环,其稳定性和可靠性直接影响着核心业务流程。XXL-Job作为一款轻量级分布式任务调度平台,凭借其简单易用、功能强大的特性…...