[Linux#58][HTTP] 自己构建服务器 | 实现网页分离 | 设计思路
目录
一. 最简单的HTTP服务器
二.服务器 2.0
Protocol.hpp
httpServer.hpp
子进程的创建和退出
子进程退出的意义
父进程关闭连接套接字
httpServer.cc
argc (argument count)
argv (argument vector)
三.服务器和网页分离
思考与补充:
一. 最简单的HTTP服务器
基于上一篇文章的理论:

我们可以尝试实现一个简单的 HTTP 服务器,它可以接受客户端连接并返回一个 "Hello World" 网页。为了详细说明这段代码,让我们逐行进行解释。
#include <sys/socket.h> // 引入套接字相关的头文件
#include <netinet/in.h> // 引入处理IPv4地址的头文件
#include <arpa/inet.h> // 引入INET相关函数的头文件
#include <unistd.h> // 引入UNIX标准函数,如close()
#include <stdio.h> // 引入标准输入输出头文件
#include <string.h> // 引入字符串处理函数的头文件
#include <stdlib.h> // 引入标准库函数,如atoi()这些头文件包含了程序所需的各种函数和类型:
sys/socket.h: 提供套接字函数和数据结构。netinet/in.h: 提供了用于处理 IPv4 地址的结构和函数。arpa/inet.h: 提供了用于操作 IP 地址的函数,如inet_addr。unistd.h: 提供了 UNIX 标准函数,如close。stdlib.h: 提供了一些标准库函数,如atoi。
void Usage() {printf("usage: ./server [ip] [port]\n");
}定义了一个 Usage 函数,该函数打印使用说明,说明程序需要两个命令行参数,即 IP 地址和端口号。
int main(int argc, char* argv[]) {程序的 main 函数开始。
if (argc != 3) {Usage();return 1;}检查命令行参数的数量。如果参数数量不等于 3(程序名、IP 地址和端口号)
int fd = socket(AF_INET, SOCK_STREAM, 0);if (fd < 0) {perror("socket"); // 如果创建失败,打印错误信息return 1;}创建一个套接字。AF_INET 表示使用 IPv4,SOCK_STREAM 表示使用 TCP。
struct sockaddr_in addr; // 定义一个地址结构体addr.sin_family = AF_INET; // 设置为IPv4地址族addr.sin_addr.s_addr = inet_addr(argv[1]); // 设置IP地址addr.sin_port = htons(atoi(argv[2])); // 设置端口号,并转换为网络字节序设置服务器端地址:
sin_family:家族类型为AF_INET,即 IPv4。sin_addr.s_addr:将命令行参数中的 IP 地址转化为网络字节序的二进制地址。sin_port:将命令行参数中的端口号转化为网络字节序的端口号。
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));if (ret < 0) {perror("bind"); // 如果绑定失败,打印错误信息return 1;}将套接字绑定到指定的 IP 地址和端口。
ret = listen(fd, 10);if (ret < 0) {perror("listen"); // 如果监听失败,打印错误信息return 1;}开始监听连接,允许最多 10 个连接等待队列。
for (;;) {struct sockaddr_in client_addr; // 定义客户端地址结构体socklen_t len = sizeof(client_addr); // 定义长度变量int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);if (client_fd < 0) {perror("accept"); // 如果接受连接失败,打印错误信息continue; // 继续下一次循环}进入一个无限循环,持续接受客户端的连接:
client_addr:用于存储客户端的地址。len:保存地址client_addr的长度。accept:接受一个客户端连接。
如果 accept 失败,打印错误信息并继续下一次循环。
char input_buf[1024 * 10] = {0};ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);if (read_size < 0) {perror("read"); // 如果读取失败,打印错误信息close(client_fd); // 关闭客户端套接字continue; // 继续下一次循环}printf("[Request] %s\n", input_buf);定义一个缓冲区并读取客户端数据:
input_buf:存储从客户端读取的数据。read:从客户端套接字读取数据至缓冲区。
如果读取失败,打印错误信息,关闭客户端套接字,并继续下一次循环。
char buf[1024] = {0};const char* hello = "<h1>hello world</h1>";sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);write(client_fd, buf, strlen(buf));定义一个缓冲区并发送响应:
hello:要发送的 HTML 内容。sprintf:格式化 HTTP 响应,包括头部和内容。write:将响应发送回客户端。
close(client_fd); // 关闭客户端套接字}关闭客户端连接。
close(fd); // 关闭服务器套接字return 0; // 正常退出
}关闭服务器套接字并正常退出程序。
总结:
该程序是一个基本的 HTTP 服务器,负责监听指定的 IP 地址和端口,接受客户端连接,读取请求并发送一个包含 "Hello World" 的 HTML 响应。它通过使用 UNIX 系统调用(如 socket、bind、listen 和 accept 等)来实现这一功能。
完整代码:
#include <sys/socket.h> // 引入套接字相关的头文件
#include <netinet/in.h> // 引入处理IPv4地址的头文件
#include <arpa/inet.h> // 引入INET相关函数的头文件
#include <unistd.h> // 引入UNIX标准函数,如close()
#include <stdio.h> // 引入标准输入输出头文件
#include <string.h> // 引入字符串处理函数的头文件
#include <stdlib.h> // 引入标准库函数,如atoi()// 打印服务器的使用方法
void Usage() {printf("usage: ./server [ip] [port]\n");
}int main(int argc, char* argv[]) {// 确保命令行参数数量正确(应为3个:程序名、IP地址和端口号)if (argc != 3) {Usage();return 1;}// 创建一个基于IPv4的TCP套接字int fd = socket(AF_INET, SOCK_STREAM, 0);if (fd < 0) {perror("socket"); // 如果创建失败,打印错误信息return 1;}struct sockaddr_in addr; // 定义一个地址结构体addr.sin_family = AF_INET; // 设置为IPv4地址族addr.sin_addr.s_addr = inet_addr(argv[1]); // 设置IP地址addr.sin_port = htons(atoi(argv[2])); // 设置端口号,并转换为网络字节序// 将套接字绑定到指定的IP地址和端口int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));if (ret < 0) {perror("bind"); // 如果绑定失败,打印错误信息return 1;}// 开始监听传入的连接,允许最多10个连接同时等待ret = listen(fd, 10);if (ret < 0) {perror("listen"); // 如果监听失败,打印错误信息return 1;}// 无限循环,持续接受客户端的连接for (;;) {struct sockaddr_in client_addr; // 定义客户端地址结构体socklen_t len = sizeof(client_addr); // 定义长度变量// 接受一个客户端连接,并将客户端的地址信息存储在client_addr中int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);if (client_fd < 0) {perror("accept"); // 如果接受连接失败,打印错误信息continue; // 继续下一次循环}// 定义一个缓冲区,用于存储从客户端读取的数据char input_buf[1024 * 10] = {0};// 从客户端读取数据,最多读取缓冲区大小-1字节ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);if (read_size < 0) {perror("read"); // 如果读取失败,打印错误信息close(client_fd); // 关闭客户端套接字continue; // 继续下一次循环}// 打印接收到的请求printf("[Request] %s\n", input_buf);// 定义一个缓冲区,用于存储响应数据char buf[1024] = {0};// 定义要发送的HTML内容const char* hello = "<h1>hello world</h1>";// 格式化HTTP响应消息,包括HTTP头部和HTML内容sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);// 将响应消息发送回客户端write(client_fd, buf, strlen(buf));// 关闭客户端套接字close(client_fd);}// 关闭服务器套接字close(fd);return 0; // 正常退出
}
二.服务器 2.0
Protocol.hpp
#pragma once#include <iostream>
#include <string>using namespace std;//客户端
class httpRequest
{public:httpRequest(){};~httpRequest(){};public:string inbuffer;//缓冲区//简单一点主要看一下http的细节// string reqline;//请求行// vector<std::string> reqheader;//报头// string body;//请求正文//第一行细分// string method;// string url;// string httpversion;
};//服务器
class httpResponse
{public:string outbuffer;//缓冲区
};
httpServer.hpp
#pragma once
// 确保头文件只被包含一次#include "Protocol.hpp"
// 包含自定义的协议处理头文件,可能定义了 httpRequest 和 httpResponse 类#include <iostream>
#include <string>
#include <stdlib.h>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
#include <functional>using namespace std;// 定义错误码枚举
enum {USAGG_ERR = 1, // 使用错误SOCKET_ERR, // 套接字创建错误BIND_ERR, // 绑定错误LISTEN_ERR // 监听错误
};const int backlog = 5;
// 定义监听队列的最大长度// 定义函数类型别名,用于处理HTTP请求和响应的回调函数
typedef function<void(const httpRequest&, httpResponse&)> func_t;// 处理HTTP请求的函数
void handlerEntery(int sock,func_t callback)
{// 1. 读到完整的http请求// 2. 反序列化// 3. httprequst, httpresponse, callback(req, resp)// 4. resp序列化// 5. sendchar buffer[4096];httpRequest req;httpResponse resp;ssize_t n=recv(sock,buffer,sizeof(buffer)-1,0);//大概率我们直接就能读取到完整的http请求if(n>0){buffer[n]=0;req.inbuffer=buffer;callback(req,resp);send(sock,resp.outbuffer.c_str(),resp.outbuffer.size(),0);}
}// HTTP服务器类
class httpServer {
public:// 构造函数,初始化端口号和监听套接字httpServer(const uint16_t port) : _port(port), _listensock(-1) {}// 初始化服务器void initServer() {// 创建套接字_listensock = socket(AF_INET, SOCK_STREAM, 0);if (_listensock < 0) {exit(SOCKET_ERR); // 如果创建失败,退出程序}// 绑定套接字到本地地址和端口struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = INADDR_ANY; // 绑定到任意地址if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0) {exit(BIND_ERR); // 如果绑定失败,退出程序}// 设置套接字为监听状态if (listen(_listensock, backlog) < 0) { // 设置监听队列长度exit(LISTEN_ERR); // 如果监听失败,退出程序}}// 启动服务器,处理请求void start(func_t func) {// 忽略子进程结束的信号signal(SIGCHLD, SIG_IGN);for (;;) { // 无限循环,等待连接// 接受新连接struct sockaddr_in peer;socklen_t len = sizeof(peer);int sock = accept(_listensock, (struct sockaddr *)&peer, &len);if (sock < 0) {continue; // 如果接受失败,继续下一次循环}// 创建子进程处理连接int fd = fork();if (fd == 0) {close(_listensock); // 子进程关闭监听套接字handlerEntery(sock, func); // 处理HTTP请求close(sock); // 处理完毕后关闭连接套接字exit(0); // 子进程退出}close(sock); // 父进程关闭连接套接字}}// 析构函数~httpServer() {// 可以在这里进行资源清理}private:uint16_t _port; // 服务器监听的端口号int _listensock; // 监听套接字的文件描述符
};
⭕ 如何理解这个地方子进程的退出和关闭?
在 start 函数中,服务器通过 fork() 系统调用创建子进程来处理每个新的连接。以下是对子进程退出和关闭操作的详细解释:
子进程的创建和退出
- 创建子进程:
-
int fd = fork();: 这行代码是创建子进程的关键。fork()调用会创建一个新的子进程。在父进程中,fork()返回子进程的进程ID;在子进程中,fork()返回0。
- 在子进程中 (
if (fd == 0)):
-
close(_listensock);: 子进程不需要监听新的连接,因此它关闭监听套接字。这是因为监听套接字由父进程负责,并且所有子进程都会继承父进程的文件描述符。handlerEntery(sock, func);: 子进程调用handlerEntery函数来处理HTTP请求。这个函数会读取请求、反序列化、调用回调函数处理请求、序列化响应并发送响应。close(sock);: 在处理完请求并发送响应后,子进程关闭与客户端的连接套接字,因为它不再需要这个套接字。exit(0);: 子进程通过exit(0)退出。这个调用会导致子进程终止,并且操作系统会回收子进程占用的所有资源。
子进程退出的意义
- 资源回收: 当子进程退出时,操作系统会自动回收子进程所占用的所有资源,包括打开的文件描述符、内存等。这是非常重要的,因为如果不回收资源,可能会导致资源泄漏。
- 避免僵尸进程: 在调用
fork()之前,父进程通过signal(SIGCHLD, SIG_IGN);忽略了SIGCHLD信号。这意味着当子进程结束时,父进程不会收到通知,操作系统会自动清理掉子进程,防止产生僵尸进程。
父进程关闭连接套接字
close(sock);: 在父进程中,fork()返回的是子进程的ID,因此父进程不会进入if (fd == 0)块。父进程也不需要这个与客户端的连接套接字,因为它只负责监听新的连接,所以它关闭这个套接字。
总结来说,子进程的退出和关闭操作确保了每个HTTP请求都能被单独的子进程处理,并且在处理完成后,子进程能够干净地退出,不会留下僵尸进程或资源泄漏。父进程继续监听新的连接请求,而子进程则负责处理已经接受的连接。
httpServer.cc
#include "httpServer.hpp"
#include <memory>// 打印程序使用方法的函数
void Usage(const string& proc) {cout << "\nUsage:\n\t" << proc << " local_port\n\n";
}// 处理HTTP GET请求的函数,参数为请求和响应对象
void Get(const httpRequest &req, httpResponse &resp)
{cout << "----------------http start---------------" << endl;cout << req.inbuffer << endl;cout << "----------------http end-----------------" << endl;string respline = "HTTP/1.1 200 OK\r\n";// string respheader;string respblank = "\r\n";//随便做一个网页string body="<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>for test</title><h1>hello world</h1></head><body><p>你好呀 祝你天天开心~</p></body></html>";//序列化resp.outbuffer += respline;resp.outbuffer += respblank;resp.outbuffer += body;
}// 程序入口点
int main(int argc, char* argv[]) {// 检查命令行参数数 量是否正确if (argc != 2) {// 如果参数数量不正确,显示使用方法并退出Usage(argv[0]);exit(USAGG_ERR); // 假设 USAGG_ERR 是一个定义的错误代码}// 将命令行参数转换为端口号uint16_t serverport = static_cast<uint16_t>(atoi(argv[1]));// 使用智能指针创建httpServer实例,自动管理内存std::unique_ptr<httpServer> server(new httpServer(serverport));// 初始化服务器server->initServer();// 启动服务器,并传入Get函数作为处理HTTP请求的回调server->start(Get);// 程序正常结束return 0;
}⭕ 解释argc 和argv的设计与运用
在C和C++程序中,argc 和 argv 是 main 函数的两个参数,它们用于处理命令行参数。
argc (argument count)
argc 是一个整数,代表传递给程序的命令行参数的数量。它至少总是为1,因为 argv[0] 总是包含程序的名称或路径。
argv (argument vector)
argv 是一个指向字符指针的指针,它指向一个字符串数组,这些字符串包含了程序的命令行参数。argv[0] 是程序的名称或路径,argv[1] 是第一个命令行参数,依此类推。
以下是 argc 和 argv 在上述代码中的设计与运用:
- 程序入口点:
int main(int argc, char* argv[]) {这里 main 函数接收 argc 和 argv 作为参数。
- 检查参数数量:
if (argc != 2) {程序期望用户输入一个命令行参数,即端口号。如果 argc 不等于2(程序名称和一个参数),则说明用户没有正确输入参数。
- 打印使用方法:
Usage(argv[0]);如果参数数量不正确,程序调用 Usage 函数,并传递 argv[0] 作为参数,这通常是程序的名称。Usage 函数会打印出如何正确使用程序的信息。
- 获取端口号:
uint16_t serverport = static_cast<uint16_t>(atoi(argv[1]));程序将 argv[1](第一个命令行参数,即用户输入的端口号字符串)转换为整数,并将其存储在 serverport 变量中。
- 启动服务器:
程序使用serverport来初始化和启动httpServer实例。
通过这种方式,argc和argv提供了一种灵活的方式来从命令行接收用户输入,使得程序可以根据不同的输入执行不同的操作。在上述代码中,它们用于指定HTTP服务器监听的端口号。如果用户没有提供正确的参数,程序会提示正确的使用方法并退出。
我们发现udp、tcp、http所有的底层逻辑都是差不多的,而我们只要写上层逻辑就好了。
这里我们主要说原理,下面1-5的工作我们都不做了,所以httpRequest,httpResponse也都给一个缓冲区就行了。
callback 的是 Get 函数
下面我们用浏览器充当客户端发起请求看一下结果

无法访问,我们来开放一下端口号,腾讯云可以直接在小程序上开,就还挺方便的~

然后就可以看到

报头我们暂时不要后面慢慢填,正文部分我们搞一个网页。
网页不会写,可以搜一下w3cschool html教程
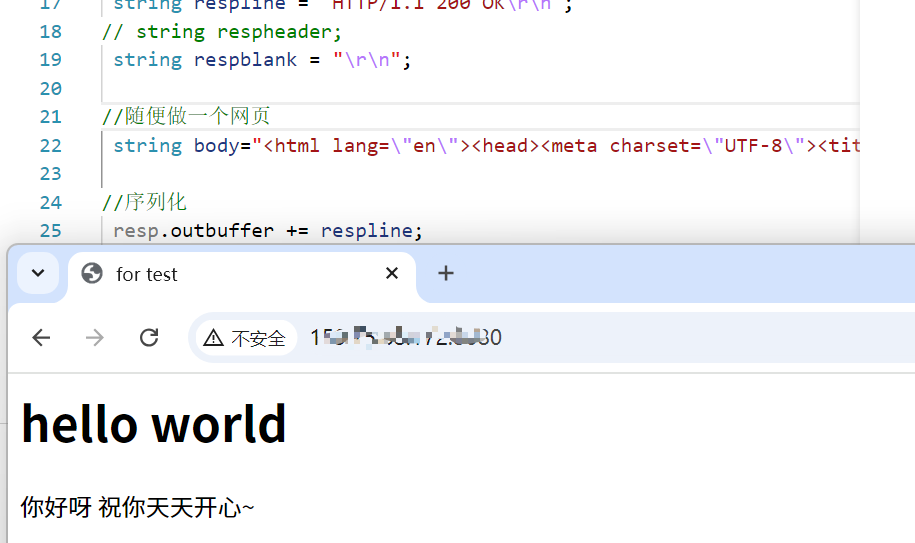
这里我们先写到Get函数里,后面我们在分离
void Get(const httpRequest &req, httpResponse &resp)
{cout << "----------------http start---------------" << endl;cout << req.inbuffer << endl;cout << "----------------http end-----------------" << endl;string respline = "HTTP/1.1 200 OK\r\n";// string respheader;string respblank = "\r\n";//随便做一个网页string body="<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>for test</title><h1>hello world</h1></head><body><p>你好呀 祝你天天开心~</p></body></html>";//序列化resp.outbuffer += respline;resp.outbuffer += respblank;resp.outbuffer += body;
}虽然我们在响应的时候没有带响应报头,但是我们的浏览器依旧是能识别的,这里想说的是现在浏览器很智能了,可以不用告诉它正文是什么也可以根据正文内容识别这是什么东西,但是有的浏览器做不到。这里我们用的是chrome浏览器。
如果我们要加一个报头里面可以带一些属性呢?
如Content-Type ,告诉别人返回的是什么资源。网上可以搜一下Content-Type 对照表,来进行添加
三.服务器和网页分离
简单实现之后,我们来解决服务器和网页分离,然后通过服务器把网页返回
引入:
在C++中,istringstream 类是在 <sstream> 头文件中定义的,所以你需要包含这个头文件来使用 istringstream 对象。下面是如何在代码中包含它的示例:
#include <sstream>
int main() {std::string line = "一些文本";std::istringstream iss(line);// ... 使用 iss ...return 0;
}在这个例子中,istringstream 被用来从字符串 line 中读取数据,就像从文件中读取一样。
运用更新:
#pragma once#include <iostream>
#include <string>
#include <sstream>
using namespace std;class Util
{
public:// xxx yyy zzz\r\naaastatic string GetOneline(string &buffer, const string &sep){auto pos = buffer.find(sep);if (pos == string::npos)return "";string sub = buffer.substr(0, pos);return sub;}
};const string sep = "\r\n";//切割符class httpRequest
{public:httpRequest(){};~httpRequest(){};void parse(){// 1. 从inbuffer中拿到第一行,分隔符\r\nstring line = Util::GetOneline(inbuffer, sep);if (line.empty())return;// 2. 从请求行中提取三个字段istringstream iss(line);iss >> method >> url >> httpversion;}public:string inbuffer;// string reqline;// vector<std::string> reqheader;// string body;string method;string url;string httpversion;
};//服务器
class httpResponse
{public:string outbuffer;//缓冲区
};#pragma once#include <iostream>
#include <string>using namespace std;class Util
{
public:// xxx yyy zzz\r\naaastatic string GetOneline(string &buffer, const string &sep){auto pos = buffer.find(sep);if (pos == string::npos)return "";string sub = buffer.substr(0, pos);return sub;}
};什么是web根目录?
实际上未来一个web服务器写好之后,可不仅仅有这些代码。每一个web服务器都有web根目录,未来所有图片、视频、音频等各种web资源都在这个目录下,按照目录结构组织号好,未来想请求资源就从url请求。那如何保证按照我们的需求在指定路径下去寻找呢?
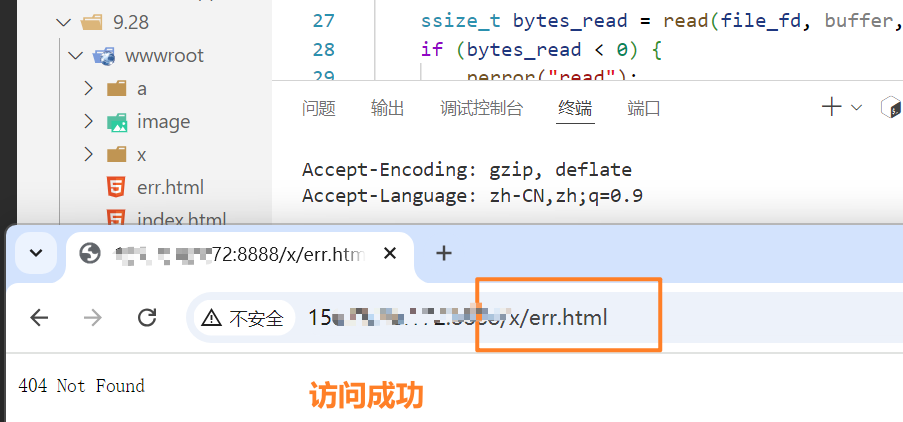
设计如下目录
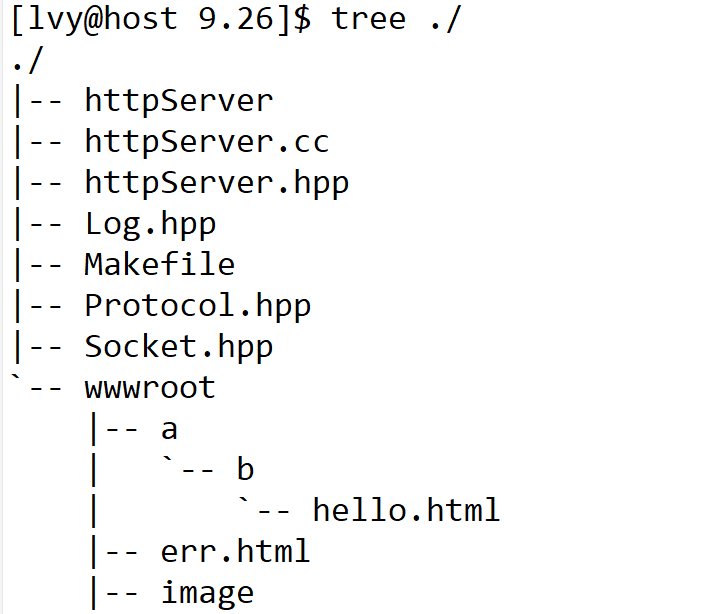
err.html
<!doctype html>
<html lang="en"><head><meta charset="UTF-8"><title>404 Not Found</title><style>body {text-align: center;padding: 150px;}h1 {font-size: 50px;}body {font-size: 20px;}a {color: #008080;text-decoration: none;}a:hover {color: #005F5F;text-decoration: underline;}</style></head><body><div><h1>404</h1><p>页面未找到<br></p><p>您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>请尝试使用以下链接或者自行搜索:<br><br><a href="https://www.baidu.com">百度一下></a></p></div></body></html>index.html:
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title></head><body><!-- <form action="/a/b/hello.html" method="post">name: <input type="text" name="name"><br>password: <input type="password" name="passwd"><br><input type="submit" value="提交"></form> --><h1>这个是我们的首页</h1><!-- <img src="/image/1.png" alt="这是一直猫" width="100" height="100"> 根据src向我们的服务器浏览器自动发起二次请求 --><!-- <img src="/image/2.jpg" alt="这是花"> --></body></html>
实现分离:
现在我们给网页添加一下功能,比如说网页是支持点击然后跳转链接的
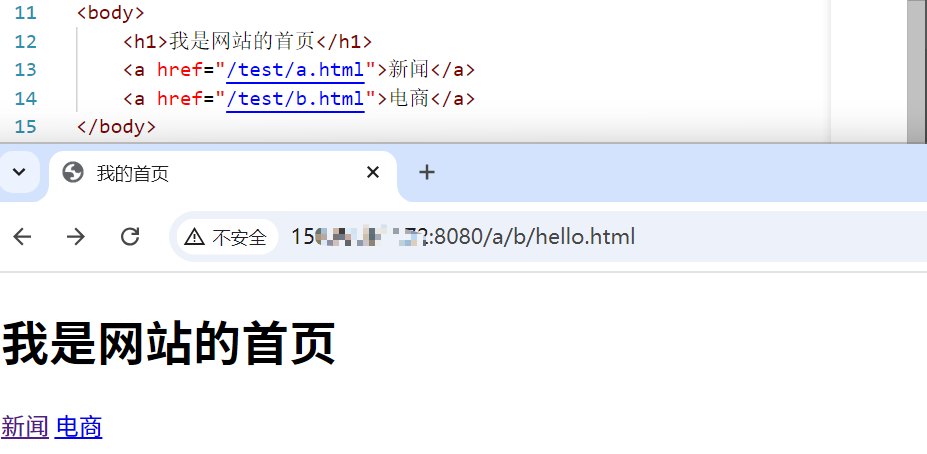
跳转成功啦~

思考与补充:
1.请求和响应怎么保证应用层完整读取完毕了呢?
首先我们发现http请求都是字符串按行为单位,所以
- 我可以读取完整的一行
- while(读取完整一行) --> 所有的请求行+请求行报文全部读完 --> 直到空行!
- 我们没说正文也是按行为单位分开的没有办法保证把正文读完,但是我们能保证把报头读完,而报头里有一个Content-Length:xxx(代表正文长度)
- 解析出来内容长度,在根据内容长度,读取正文即可!
2.请求和响应是怎么做到序列化和反序列化的?
- http是用的特殊字符自己实现的。http序列化什么都不做直接发就好了,反序列化 :第一行+请求/响应报头,只要按照\r\n将字符串1->n即可!不用借助任何东西如Json
- protobuf等。而正文序列化反序列也不用做直接发送就行了。如果你的正文携带结构化数据就要自己处理了。
- 上面我们也通过写代码的方式,验证上面说的东西。
- 以前写udp和tcp我们都写过服务端用过套接字,这里还是直接拿过来用啦
3. 如何监视查看网页端
按图片操纵即可
就可以查看到啦
下篇文章将继续讲解网页对图片的插入,和 http 设计的详细解读~
相关文章:
[Linux#58][HTTP] 自己构建服务器 | 实现网页分离 | 设计思路
目录 一. 最简单的HTTP服务器 二.服务器 2.0 Protocol.hpp httpServer.hpp 子进程的创建和退出 子进程退出的意义 父进程关闭连接套接字 httpServer.cc argc (argument count) argv (argument vector) 三.服务器和网页分离 思考与补充: 一. 最简单的HTT…...

7.MySQL内置函数
目录 日期函数时间函数字符串函数数学函数其他函数 日期函数 函数名称描述current_date()当前日期current_time()当前时间current_timesamp()当前时间戳date(datetime)返回datetime参数的日期部分date_add(date, interval d_value_tyep)在date中添加日期函数或时间。interval后…...

如何快速自定义一个Spring Boot Starter!!
目录 引言: 一. 我们先创建一个starter模块 二. 创建一个自动配置类 三. 测试启动 引言: 在我们项目中,可能经常用到别人的第三方依赖,又是引入依赖,又要自定义配置,非常繁琐,当我们另一个项…...
)
【音视频】ffmpeg其他常用过滤器filter实现(6-4)
最近一直在研究ffmpeg的过滤器使用,发现挺有意思的,这里列举几个个人感觉比较有用的过滤器filter,如下是代码实现,同样适用于命令行操作: 1、视频模糊:通过boxblur可以将画面进行模糊处理,第1个…...

云栖3天,云原生+ AI 多场联动,新产品、新体验、新探索
云栖3天,云原生 AI 20场主题分享,三展互动,为开发者带来全新视听盛宴 2024.9.19-9.21 云栖大会 即将上演“云原生AI”的全球盛会 展现最新的云计算技术发展与 AI技术融合之下的 “新探索” 一起来云栖小镇 见证3天的云原生AI 前沿探索…...

jackson对于对象序列化的时候默认空值和手动传入的null的不同处理
Jackson 在序列化对象时如何处理默认的空值和手动传入的 null,其实归结于它的序列化机制和注解配置。默认情况下,Jackson 不区分 手动设置的 null 和 对象中字段的默认空值,但可以通过配置来改变其行为。具体细节如下: 1. 默认行为…...

L8打卡学习笔记
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 SVM与集成学习 SVMSVM线性模型SVM非线性模型SVM常用参数 集成学习随机森林导入数据查看数据信息数据分析随机森林模型预测结果结果分析 个人总结 SVM 超平面&…...

VBA解除Excel工作表保护
Excel工作表保护解除 工作表保护后无法编辑内容,可能是密码忘记,不可暴力破解隐私 1 打开需的Excel 2 Alt F11 打开代码编辑,点击任意代码编辑项,将如下代码复制,并运行。 Public Sub GetWorkbookPassword()Dim w1 A…...

bash: unzip: 未找到命令,sudo: nano:找不到命令
在 Ubuntu/Debian 系统上 打开终端并运行以下命令: sudo apt update sudo apt install unzip在 CentOS/RHEL 系统上 打开终端并运行以下命令: sudo yum install unzip在 macOS 上 如果您使用的是 macOS,可以使用 Homebrew 安装 unzip&#…...

tauri开发配置文件和文件夹访问路径问题
文件夹没权限:Unhandled Promise Rejection: path not allowed on the configured scope: /Users/song/Library/Application Support/com.pakeplus.app/assets/default.png 没有文件夹,需要先创建:Unhandled Promise Rejection: path: /Users…...
【web安全】——信息收集
一、收集域名信息 1.1域名注册信息 工具:站长之家 whois查询 SEO综合查询 1.2子域名收集 原理:字典爆破,通过字典中的各种字符串与主域名拼接,尝试访问。 站长之家 直接查询子域名 ip138.com https://phpinfo.me/domain/ …...

赵长鹏今日获释,下一步会做什么?币安透露2024年加密货币牛市的投资策略!
中国时间2024年9月28日,加密货币行业的风云人物赵长鹏(Changpeng Zhao,简称CZ)终于从监狱获释。他因在担任币安首席执行官期间未能有效执行反洗钱(AML)计划而被判刑四个月。赵长鹏的获释引发了广泛关注,不仅因为他是全…...

SpringMVC之ContextHolder
员工不必为自己的弱点而太多的忧虑,而是要大大地发挥自己的优点,使自己充满自信,以此来解决自己的压抑问题。我自己就有许多地方是弱项,常被家人取笑小学生水平,若我全力以赴去提升那些弱的方面,也许我就做…...

什么是SQL注入?
SQL注入是一种安全漏洞,攻击者通过在应用程序的输入字段中插入恶意SQL代码,从而操控数据库。此类攻击通常利用应用程序未对用户输入进行适当验证和清理的弱点。 工作原理: 输入字段:攻击者在登录表单或搜索框等输入区域插入恶意…...

混合密码系统——用对称密钥提高速度,用公钥密码保护会话密钥
混合密码系统(Hybrid Cryptosystem)是一种结合了多种密码学技术和算法的加密方案,旨在充分利用不同密码算法的优势,以提供更强大的安全性、更高的效率或更好的功能特性。以下是对混合密码系统的详细解释: 组成要素 对…...

Three.js粒子系统与特效
目录 粒子系统基础常见粒子系统特效粒子系统基础 基础的粒子系统 使用THREE.ParticleSystem和THREE.ParticleBasicMaterial实现: // 导入Three.js库 import * as THREE from three...

Tableau数据可视化入门
目录 一、实验名称 二、实验目的 三、实验原理 四、实验环境 五、实验步骤 1、Tableau界面引导 2、数据来源 3、数据预处理操作 4、制作中国各个地区的利润图表 4.1条形图 4.2气泡图 5、制作填充地球图 一、实验名称: 实验一:Tableau数据可视…...

Linux云计算 |【第四阶段】RDBMS1-DAY2
主要内容: 常用函数(函数分类1:单行、分组;函数分类2:字符、数学、日期、流程控制)、分组查询group by、连接查询 一、常用函数 1. 按使用方式分类 ① 单行函数 单行函数(Scalar Functions&…...

后台监控中的云边下控耗时、边缘采集耗时 、云边下控量
云边下控耗时:指云端控制边缘设备的时间,从云端下发指令到边缘设备响应完成的时间。该指标反映了云端控制边缘设备的效率和响应速度。 边缘采集耗时:指边缘设备采集数据到云端处理完成的时间,包括数据采集、传输、处理等环节。该…...

【学习笔记】手写 Tomcat 四
目录 一、Read 方法返回 -1 的问题 二、JDBC 优化 1. 创建配置文件 2. 创建工具类 3. 简化 JDBC 的步骤 三、修改密码 优化返回数据 创建修改密码的页面 注意 测试 四、优化响应动态资源 1. 创建 LoginServlet 类 2. 把登录功能的代码放到 LoginServlet 类 3. 创…...

多模态Agent架构实战落地:从需求分析到生产部署
多模态Agent架构实战落地:从需求分析到生产部署 随着大语言模型技术的普及,单一文本交互的智能系统已无法满足复杂业务场景需求——电商平台需要同时理解用户的商品描述文本、实拍图片和售后语音诉求,教育场景需要处理手写作业、视频讲解和文…...

3步搭建PP-DocLayoutV3服务:快速体验文档版面分析的强大能力
3步搭建PP-DocLayoutV3服务:快速体验文档版面分析的强大能力 1. 引言:文档版面分析的价值 在日常工作中,我们经常需要处理各种文档——合同、论文、报告、书籍等。传统OCR技术虽然能识别文字,但往往无法理解文档的结构ÿ…...

Zephyr与MCUBoot的深度整合:从构建到安全启动的完整指南
1. 为什么需要安全启动? 在嵌入式开发中,设备固件的安全性往往是最容易被忽视的一环。想象一下,如果你的智能门锁固件被恶意篡改,或者医疗设备的程序被非法替换,后果会有多严重?这就是为什么我们需要MCUBoo…...

Graphormer开源大模型实战:分子图建模替代传统GNN的5大优势解析
Graphormer开源大模型实战:分子图建模替代传统GNN的5大优势解析 1. Graphormer模型概述 Graphormer是微软研究院开发的基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。与传统…...

浅谈MIKE URBAN转SWMM的方法
01 前言近期有群友咨询MIKE URBAN怎么转换成SWMM的INP文件格式,其实这个是很简单的,前提是你对两个软件格式足够熟悉,另一方面,很多年前SWMM就开发了inpPNS软件。可以利用这个软件便可实现转换,小编抽时间给大家分享下…...
)
用STM32和示波器搞定美的/格力空调红外遥控(附完整C代码)
STM32实战:从示波器捕获到空调红外协议逆向全解析 红外遥控技术看似简单,却蕴含着精妙的时序设计和协议逻辑。作为一名长期混迹于硬件开发领域的工程师,我经常遇到需要逆向控制家电的场景。最近在智能家居项目中,就遇到了需要通过…...

深入OpenHarmony NAPI引擎:从‘@ohos.hilog’导入到so库加载的底层链路剖析
深入OpenHarmony NAPI引擎:从‘ohos.hilog’导入到so库加载的底层链路剖析 当开发者在OpenHarmony应用中写下import hilog from ohos.hilog时,背后隐藏着一套精密的系统级协作机制。这条看似简单的语句,实际上触发了从JavaScript语法解析到原…...

GHelper:华硕笔记本的轻量级性能管理解决方案
GHelper:华硕笔记本的轻量级性能管理解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, and …...
)
FunASR Docker部署SSL配置的四个‘天坑’与避坑指南(附完整启动命令)
FunASR Docker部署SSL配置的四个‘天坑’与避坑指南(附完整启动命令) 在语音识别服务的安全部署中,SSL/TLS加密已成为行业标配。但当我们实际为FunASR配置HTTPS时,那些看似简单的步骤背后却暗藏玄机。本文将带您穿越四个最具迷惑性…...
)
告别繁琐配置:用Docker一键搞定RKNN模型转换环境(Windows/Linux/Mac通用)
跨平台RKNN模型转换实战:Docker化环境搭建与高效部署指南 当AI开发者需要在不同设备上部署模型时,环境配置往往成为最耗时的环节。特别是在使用Rockchip NPU进行边缘计算时,传统的虚拟机配置、交叉编译等方法既繁琐又容易出错。本文将介绍如何…...