二、kafka生产与消费全流程
一、使用java代码生产、消费消息
1、生产者
package com.allwe.client.simple;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;/*** kafka生产者配置** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class HelloKafkaProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器地址,多台就用“,”隔开,如果某一台宕机生产者依然可以连接properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 设置key和value的序列化器,使java对象转换成二进制数组properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// new一个生产者producerKafkaProducer<String, String> producer = new KafkaProducer<>(properties);try {ProducerRecord<String, String> producerRecord;try {// 构建消息producerRecord = new ProducerRecord<>("topic_1", "student", "allwe");// 发送消息producer.send(producerRecord);System.out.println("消息发送成功");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
2、消费者
package com.allwe.client.simple;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** kafka生产者配置** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class HelloKafkaConsumer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器地址,多台就用“,”隔开,如果某一台宕机生产者依然可以连接properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 设置key和value的序列化器,使java对象转换成二进制数组properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// new一个消费者consumerKafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);try {// 订阅哪些主题,可以多个,推荐订阅一个主题consumer.subscribe(Collections.singleton("topic_1"));// 死循环里面实现监听while (true) {// 每间隔1s,取一次消息,可能取到多条消息// 设置一秒的超时时间ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {System.out.println("key:" + record.key() + ",value:" + record.value());}}} finally {// 释放连接consumer.close();}}
}
3、踩坑
如果连接的不是本机的kafka,需要在目标机器的kafka配置文件中配置真实的ip地址,如果使用默认的配置或者配置为localhost:9092,kafka.clients会将目标机器的ip解析为127.0.0.1,导致连接不上kafka。

二、生产者
1、序列化器
在上面的demo中,由于消息的key和value都是String类型的,就可以使用kafka.client提供的String序列化器,如果想要发送其他自定义类型的对象,可以手动编写一个序列化器和反序列化器,实现Serializer接口,将对象和byte数组互相转换即可。
需要注意的是,生产者使用的自定义序列化器必须和消费者使用的反序列化器对应,否则无法正确解析消息。
那么什么情况下需要使用自定义序列化器呢?
-- 需要兼容一些其他协议。
2、分区器
发送的消息被分配到哪个分区中?分区是如何选择的?假设上面的demo中,主题topic_1有4个分区,分别发送4次消息,处理分区的逻辑是怎样的?
这里需要先配置kafka在创建新的主题时,默认的分区数量,我这里配置为了4。

1)指定分区器
可以选择在创建生产者时,给生产者配置相关的分区器,指定具体分区算法。kafka.client提供了一些分区器,或者自己实现一个分区器。
// 设置分区规则
Properties properties = new Properties();
// 1、默认分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class);
// 2、统一粘性分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UniformStickyPartitioner.class);
// 3、自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);自定义分区器:
package com.allwe.client.partitioner;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;import java.util.List;
import java.util.Map;/*** 自定义分区器 - 以value值分区*/
public class MyPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitionInfoList = cluster.partitionsForTopic(topic);// 以value值的byte数组处理后再和分区数取模,决定放在哪个分区上return Utils.toPositive(Utils.murmur2(valueBytes)) % partitionInfoList.size();}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
2)指定分区
也可以选择在构建消息时指定分区,此时的分区优先级最高,不会被其他分区器影响。
# 创建消息时指定分区为 0
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic_1", 0, "student", "allwe");3、生产者发送消息的回调
package com.allwe.client.partitioner;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;
import java.util.concurrent.Future;/*** kafka生产者配置 - 自定义分区器 & 发送消息回调** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class PartitionerProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器地址,多台就用“,”隔开,如果某一台宕机生产者依然可以连接properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 设置key和value的序列化器,使java对象转换成二进制数组properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 设置自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);// new一个生产者producerKafkaProducer<String, String> producer = new KafkaProducer<>(properties);try {ProducerRecord<String, String> producerRecord;try {// 构建指定分区的消息,此时指定的分区不会变// producerRecord = new ProducerRecord<>("topic_1", 0, "student", "allwe");for (int i = 0; i < 10; i++) {// 构建消息producerRecord = new ProducerRecord<>("topic_2", "student", "allwe" + i);// 发送消息Future<RecordMetadata> future = producer.send(producerRecord);// 解析回调元数据RecordMetadata recordMetadata = future.get();System.out.println(i + ",offset:" + recordMetadata.offset() + ",partition:" + recordMetadata.partition());}} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
打印结果:

4、异步解析生产者发送消息的回调
package com.allwe.client.callBack;import com.allwe.client.partitioner.MyPartitioner;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;/*** kafka生产者配置 - 异步解析发送消息回调** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class AsynPartitionerProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器地址,多台就用“,”隔开,如果某一台宕机生产者依然可以连接properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 设置key和value的序列化器,使java对象转换成二进制数组properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 设置自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);// new一个生产者producerKafkaProducer<String, String> producer = new KafkaProducer<>(properties);try {ProducerRecord<String, String> producerRecord;try {for (int i = 0; i < 10; i++) {// 构建消息producerRecord = new ProducerRecord<>("topic_3", "student", "allwe" + i);// 发送消息, 设置异步回调解析器producer.send(producerRecord, new CallBackImpl());}System.out.println("发送完成,topic_4");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
package com.allwe.client.callBack;import cn.hutool.core.util.ObjectUtil;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.RecordMetadata;/*** 异步发送消息回调解析器*/
public class CallBackImpl implements Callback {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (ObjectUtil.isNull(e)) {// 解析回调元数据System.out.println("offset:" + recordMetadata.offset() + ",partition:" + recordMetadata.partition());} else {e.printStackTrace();}}
}
5、生产者缓冲
1)为什么kafka在客户端发送消息的时候需要做一个缓冲?
① 减少IO的开销(单个 -> 批次),需要修改配置文件。
② 减少GC(核心)。
2)如何配置缓冲?
producer.properties配置文件中修改下面两个参数:
消息的大小:batch.size = 默认16384(16K)
暂存的时间:linger.ms = 默认0ms
上面两个条件只要达到一个,就会发送消息,所以在默认配置下,生产一条消息就立即发送。
3)减少GC的原理
producer.properties配置文件的参数:
缓冲池大小:buffer.memory = 默认32M

kafka客户端使用了缓冲池,默认大小32M,当有一条新的消息进入缓冲池,达到了任何一个条件后就发送。发送后不用立即回收内存,而是初始化一下缓冲池即可,减少了GC的次数。
简单说就是利用池化技术减少了对象的创建 -> 减少内存分配次数 -> 减少了垃圾回收次数。
4)使用缓冲池的风险
当缓存的消息超出缓冲池的大小,kafka就会抛出OOM异常。
如果写入消息太快,但是上一次send方法没有执行完,就会导致上一次缓存的消息不能删除,这一次进来的消息又太多,最终写满了缓冲池,触发OOM异常。
解决办法就是适当调整buffer.memory参数和batch.size参数,增加缓冲池大小,缩小每一批次的大小。
三、Kafka Broker
消息从生产者发送出去后,就进入了broker中。在kafka broker中,每一个分区就是一个文件。
四、消费者
1、消费者群组
在消费的过程中,一般情况下使用群组消费,设置group_id_config。
核心:kafka群组消费的负载均衡建立在分区级别。
1)单个群组场景
一个分区只能由一个消费者消费。
在kafka执行过程中,支持动态添加或者减少消费者。

2)多个群组场景
群组之间的消费是互不干扰的,比如群组A的消费者和群组B的消费者可以同时消费同一个分区的消息。

2、Demo记录
写一个生产者,我为了测试顺畅写了一个无限循环的。只启动一次,输入参数即可实现批量发送消息。
package com.allwe.client.singleGroup;import com.allwe.client.partitioner.MyPartitioner;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;
import java.util.Scanner;/*** kafka生产者配置 - 无限生产消息** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class Producer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);// new一个生产者producerKafkaProducer<String, String> producer = new KafkaProducer<>(properties);Scanner scanner = new Scanner(System.in);;try {int count;while (true) {System.out.println("==================输入消息条数===================");String nextLine = scanner.nextLine();if ("exit".equals(nextLine)) {break;}count = Integer.parseInt(nextLine);ProducerRecord<String, String> producerRecord;try {for (int i = 0; i < count; i++) {// 构建消息producerRecord = new ProducerRecord<>("topic_5", "topic_5", "allwe" + i);producer.send(producerRecord);}} catch (Exception e) {e.printStackTrace();}System.out.println("发送完成,topic_5");}} catch (Exception e) {throw new RuntimeException(e);} finally {// 释放连接producer.close();scanner.close();}}
}

写一个消费者base类,由于测试消费者需要启动很多类,我这里为了方便写了一个baseConsumer类,调用时new这个类的对象即可调用消费方法。
package com.allwe.client.singleGroup;import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** kafka 消费者配置** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
@Data
public class SingleGroupBaseConsumer {private String groupIdConfig;private String topicName;private KafkaConsumer<String, String> consumer;public SingleGroupBaseConsumer(String groupIdConfig, String topicName) {this.groupIdConfig = groupIdConfig;this.topicName = topicName;createConsumer();}private void createConsumer() {// 设置属性Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupIdConfig);consumer = new KafkaConsumer<>(properties);}public void poll() {try {consumer.subscribe(Collections.singleton(topicName));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));int count = 0;for (ConsumerRecord<String, String> record : records) {count = 1;System.out.println("partition:" + record.partition() + ",key:" + record.key() + ",value:" + record.value());}if (count == 1) {// 消费到消息了就打印分隔线System.out.println("===============================");}}} finally {consumer.close();}}
}
1)单个群组场景
群组id:allwe01
package com.allwe.client.singleGroup;import lombok.extern.slf4j.Slf4j;/*** kafka消费者启动器** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class SingleGroupConsumer_1 {public static void main(String[] args) {SingleGroupBaseConsumer singleGroupBaseConsumer = new SingleGroupBaseConsumer("allwe01", "topic_5");singleGroupBaseConsumer.poll();}
}

我这里只放了一个消费者的消费记录,根据消费者控制台打印的数据,可以看到两条信息:
① 该消费者只能消费分区=1的消息。
② 消费者消费消息时,每次拿到的消息数量不确定。
2)多个群组场景
群组id:allwe02
package com.allwe.client.group;import com.allwe.client.singleGroup.SingleGroupBaseConsumer;
import lombok.extern.slf4j.Slf4j;/*** kafka消费者启动器** @Author: AllWe* @Date: 2024/09/24/17:57*/
@Slf4j
public class GroupConsumer_1 {public static void main(String[] args) {SingleGroupBaseConsumer singleGroupBaseConsumer = new SingleGroupBaseConsumer("allwe02", "topic_5");singleGroupBaseConsumer.poll();}
}

可以看到,这里新加入了一个消费者群组,只有一个消费者,它就消费到了全部分区的消息。
3、ACK确认
消费者在成功消费消息后,会进行ACK确认。提交最后一次消费消息的偏移量,下一次消费就从上次提交的偏移量开始,如果一个新的消费者群组消费一个主题的消息,可以根据不同的配置来指定起始的偏移量。
// 从最早的消息开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 从已提交的偏移量开始消费 - 默认配置
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");在kafka内部,有一个名字叫【__consumer_offsets】的主题,保存了消费者对各个主题的消费偏移量。消费者每一次发送的ACK确认,都会更新这个主题中的偏移量数据。
1)自动提交ACK的消费模式
默认的消费模式。
只要拿到了消息,就自动提交ACK确认。
但是有一个风险,就是虽然消费者成功取到了消息,但是在程序处理过程中出现了异常,同时提交了ACK确认,那么这条消息就永远不会被正确地处理。
所以有时候我们需要避免自动提交ACK确认,改成手动提交ACK确认。
2)手动提交ACK确认
取消自动提交
// 取消自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);① 同步提交
// 同步提交ACK确认 - 提交不成功就一直重试,成功后才会继续往下执行
consumer.commitSync();立刻进行ACK确认。但是容易造成阻塞,只有等待ACK确认成功后,才会继续执行程序。如果ACK确认不成功,就会一直重试。
② 异步提交
// 异步提交ACK确认
consumer.commitAsync();异步提交不会阻塞应用程序,提交失败不会重试提交。
③ 组合使用demo
public void poll() {try {consumer.subscribe(Collections.singleton(topicName));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));int count = 0;for (ConsumerRecord<String, String> record : records) {count = 1;System.out.println("partition:" + record.partition() + ",offset:" + record.offset() +",key:" + record.key() + ",value:" + record.value());}if (count == 1) {// 消费到消息了就打印分隔线System.out.println("===============================");}// 异步提交ACK确认consumer.commitAsync();}} finally {try {// 同步提交ACK确认 - 提交不成功就一直重试,成功后才会继续往下执行consumer.commitSync();} finally {consumer.close();}}}3)手动批量提交ACK确认
如果消费者在某一时刻取到的消息数量太多,那么给每一条消息单独提交ACK确认太浪费资源,可以选择批量提交ACK确认。核心思想就是在程序中暂存偏移量,达到设定的阈值后就触发批量提交。

kafka.Consumer提供的异步提交ACK方法支持批量提交。
相关文章:
二、kafka生产与消费全流程
一、使用java代码生产、消费消息 1、生产者 package com.allwe.client.simple;import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.pr…...
本地搭建OnlyOffice在线文档编辑器结合内网穿透实现远程协作
文章目录 前言1. 安装Docker2. 本地安装部署ONLYOFFICE3. 安装cpolar内网穿透4. 固定OnlyOffice公网地址 前言 本篇文章讲解如何使用Docker在本地Linux服务器上安装ONLYOFFICE,并结合cpolar内网穿透实现公网访问本地部署的文档编辑器与远程协作。 Community Editi…...

ScrapeGraphAI 大模型增强的网络爬虫
在数据驱动的动态领域,从在线资源中提取有价值的见解至关重要。从市场分析到学术研究,对特定数据的需求推动了对强大的网络抓取工具的需求。 NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线…...

PDF转换为TIF,JPG的一个简易工具(含下载链接)
目录 0.前言: 1.工具目录 2.工具功能(效果),如何运行 效果 PDF转换为JPG(带颜色) PDF转换为TIF(LZW形式压缩,可以显示子的深浅) PDF转换为TIF(CCITT形…...

Wireshark 解析QQ、微信的通信协议|TCP|UDP
写在前面 QQ,微信这样的聊天软件。我们一般称为im,Instant Messaging,即时通讯系统。那大家会不会有疑问,自己聊天内容会不会被黑客或者不法分子知道?这种体量的im是基于tcp还是udp呢?这篇文章我们就来探索…...
——模拟伪闭包实现连接的安全回收)
网络编程(5)——模拟伪闭包实现连接的安全回收
六、day6 今天学习如何利用C11模拟伪闭包实现连接的安全回收,之前的异步服务器为echo模式,但存在安全隐患,在极端情况下客户端关闭可能会导致触发写和读回调函数,二者都进入错误处理逻辑,进而造成二次析构。今天学习如…...

C#绘制动态曲线
前言 用于实时显示数据动态曲线,比如:SOC。 //用于绘制动态曲线,可置于定时函数中,定时更新数据曲线 void DrawSocGraph() {double f (double)MainForm.readData[12]; //display datachart1.Series[0].Points.Add(f);if (ch…...
用Python实现运筹学——Day 10: 线性规划的计算机求解
一、学习内容 1. 使用 Python 的 scipy.optimize.linprog 进行线性规划求解 scipy.optimize.linprog 是 Python 中用于求解线性规划问题的函数。它实现了单纯形法、内点法等算法,能够处理求解最大化或最小化问题,同时满足线性约束条件。 线性规划问题的…...
[C++]使用C++部署yolov11目标检测的tensorrt模型支持图片视频推理windows测试通过
官方框架: https://github.com/ultralytics/ultralytics yolov8官方最近推出yolov11框架,标志着目标检测又多了一个检测利器,于是尝试在windows下部署yolov11的tensorrt模型,并最终成功。 重要说明:安装环境视为最基…...

霍夫曼树及其与B树和决策树的异同
霍夫曼树是一种用于数据压缩的二叉树结构,通常应用于霍夫曼编码算法中。它的主要作用是通过对符号进行高效编码,减少数据的存储空间。霍夫曼树在压缩领域扮演着重要角色,与B树、决策树等数据结构都有一些相似之处,但又在应用场景和…...
CompletableFuture常用方法
一、获得结果和触发计算 1.获取结果 (1)public T get() public class CompletableFutureAPIDemo{public static void main(String[] args) throws ExecutionException, InterruptedException{CompletableFuture<String> completableFuture Com…...

本地化测试对游戏漏洞修复的影响
本地化测试在游戏开发的质量保证过程中起着至关重要的作用,尤其是在修复bug方面。当游戏为全球市场做准备时,它们通常会被翻译和改编成各种语言和文化背景。这种本地化带来了新的挑战,例如潜在的语言错误、文化误解,甚至是不同地区…...

使用rust实现rtsp码流截图
中文互联网上的rust示例程序源码还是太稀少,找资料很是麻烦,下面是自己用业余时间开发实现的一个对批量rtsp码流源进行关键帧截图并存盘的rust demo源码记录。 要编译这个源码需要先安装vcpkg,然后用vcpkg install ffmpeg安装最新版本的ffmpe…...

Cpp::STL—string类的模拟实现(12)
文章目录 前言一、string类各函数接口总览二、默认构造函数string(const char* str "");string(const string& str);传统拷贝写法现代拷贝写法 string& operator(const string& str);传统赋值构造现代赋值构造 ~string(); 三、迭代器相关函数begin &…...

一文搞懂SentencePiece的使用
目录 1. 什么是 SentencePiece?2. SentencePiece 基础概念2.1 SentencePiece 的工作原理2.2 SentencePiece 的优点 3. SentencePiece 的使用3.1 安装 SentencePiece3.2 训练模型与加载模型3.3 encode(高频)3.4 decode(高频&#x…...

一个简单的摄像头应用程序1
这个Python脚本实现了一个基于OpenCV的简单摄像头应用,我们在原有的基础上增加了录制视频等功能,用户可以通过该应用进行拍照、录制视频,并查看已拍摄的照片。以下是该脚本的主要功能和一些使用时需要注意的事项: 功能 拍照: 用户可以通过点击界面上的“拍照”按钮或按…...

通过PHP获取商品详情
在电子商务的浪潮中,数据的重要性不言而喻。商品详情信息对于电商运营者来说尤为宝贵。PHP,作为一种广泛应用的服务器端脚本语言,为我们提供了获取商品详情的便捷途径。 了解API接口文档 开放平台提供了详细的API接口文档。你需要熟悉商品详…...

【Android】获取备案所需的公钥以及签名MD5值
目录 重要前提 获取签名MD5值 获取公钥 重要前提 生成jks文件以及gradle配置应用该文件。具体步骤请参考我这篇文章:【Android】配置Gradle打包apk的环境_generate signed bundle or apk-CSDN博客 你只需要从头看到该文章的配置build.gradle(app&…...
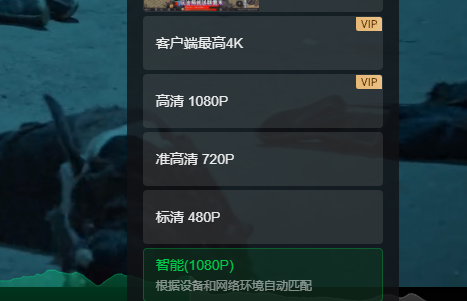
看480p、720p、1080p、2k、4k、视频一般需要多大带宽呢?
看视频都喜欢看高清,那么一般来说看电影不卡顿需要多大带宽呢? 以4K为例,这里引用一位网友的回答:“视频分辨率4092*2160,每个像素用红蓝绿三个256色(8bit)的数据表示,视频帧数为60fps,那么一秒钟画面的数据量是:4096*2160*3*8*60≈11.9Gbps。此外声音大概是视频数据量…...

解决IDEA中@Autowired红色报错的实用指南:原因与解决方案
前言: 在使用Spring Boot开发时,Autowired注解是实现依赖注入的常用方式。然而,许多开发者在IDEA中使用Autowired时,可能会遇到红色报错,导致代码的可读性降低。本文将探讨导致这种现象的原因,并提供几种解…...

独立开发者如何下载使用Taotoken管理多个AI项目的模型与密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何下载使用Taotoken管理多个AI项目的模型与密钥 对于独立开发者或小型工作室而言,同时推进多个AI应用项目…...

Dify数据库查询插件:让AI应用轻松连接业务数据的实战指南
1. 项目概述与核心价值 如果你正在使用 Dify 构建企业级 AI 应用,并且经常需要让 AI 助手去查询数据库里的数据——比如让 LLM 帮你分析销售报表、查找用户信息或者生成业务洞察——那么你很可能遇到过这样的痛点:Dify 本身并不直接支持数据库连接。你需…...

基于MCP协议与FFmpeg构建AI视频处理服务器:原理、部署与实战
1. 项目概述:一个面向视频处理的MCP服务器 最近在折腾一些AI应用,发现很多工具在处理视频内容时,总感觉差了那么一口气。要么是功能太单一,只能做简单的剪辑或转码;要么就是流程太复杂,需要把视频下载、处…...

星际软件开发:为火星殖民地编写第一批代码
一、引言:当测试左移到大气层之外2041年,第一批火星殖民者即将启程。他们携带的不仅是氧气和速食,还有一座预装在密封舱里的微型数据中心。在这片红色荒漠上,代码将比氧气更早醒来——生命维持系统的控制逻辑、通讯中继的协议栈、…...

2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置
2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token P…...

Cursor Pro 终极破解指南:如何永久免费使用AI编程神器
Cursor Pro 终极破解指南:如何永久免费使用AI编程神器 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

先进制程重塑晶圆代工格局:从HPC需求到供应链博弈
1. 行业现状:先进制程如何重塑晶圆代工格局最近和几位在芯片设计公司负责流片的朋友聊天,大家讨论最激烈的,除了产能紧张,就是到底要不要、以及何时上更先进的工艺节点。一个普遍的共识是:7纳米和5纳米这类所谓“先进制…...

从YOLOv1到YOLOv5:一个算法工程师的实战避坑与版本选择指南
从YOLOv1到YOLOv5:算法工程师的版本选择与实战调优指南 在计算机视觉领域,目标检测算法的发展日新月异,而YOLO(You Only Look Once)系列作为其中的佼佼者,凭借其出色的实时性和准确性,已成为工业界和学术界广泛采用的核…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...

告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南
告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南 在独立游戏开发中,角色往往是玩家情感投射的核心载体。一个缺乏生命力的角色模型,即使建模精度再高,也会让玩家产生"纸片人"的疏…...