【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】
- 一、上篇回顾
- 二、项目准备
- 2.1 准备模板项目
- 2.2 支持计时功能
- 2.3 配置UART4引脚
- 2.4 支持printf重定向到UART4
- 2.5 支持printf输出浮点数
- 2.6 支持printf不带`\r`的换行
- 2.7 支持ccache编译缓存
- 三、TFLM集成
- 3.1 添加tflite-micro源码
- 3.2 修正micro_time.cc代码
- 3.3 构建micro_time.cc的规则
- 3.4 添加TFLM构建规则
- 3.5 添加TFLM函数调用
- 3.6 添加TFLM依赖关系
- 四、TFLM测试
- 4.1 编译TFLM和Appli项目
- 4.2 下载Boot代码
- 4.3 下载Appli代码
- 4.3 运行TFLM基准测试
- 五、问题解决
- 5.1 benchmark编译失败
- 5.2 Appli链接报错
- 5.3 benchmark无法正常开始
- 5.4 Release版无法正常返回
- 六、源码分享
- 七、参考链接
本文将会继续介绍——如何为STM32H7S78-DK开发板准备CMake项目、如何将TFLM集成到基于CMake的STM32项目中、如何在STM32H7S78-DK开发板上运行TFLM基准测试,具体包括如何支持计时和printf输出、如何集成TFLM到基于CMake的STM32项目,以及解决过程中遇到的一些问题。
一、上篇回顾
书接上回,上篇文章主要分为TFLM是什么、TFLM初步体验、TFLM源码浅析、TFLM主体移植几个部分。其中,TFLM初步体验部分将会介绍如何在PC上运行TFLM基准测试,TFLM源码浅析部分主要介绍TFLM源码是如何进行构建的,TFLM主体移植主要介绍如何在基于CMake的STM32项目中构建TFLM库和基准测试。
上篇链接: https://blog.csdn.net/xusiwei1236/article/details/142467410
二、项目准备
2.1 准备模板项目
项目模板采用基于CMake的STM32H7S78-DK项目,代码仓为:
https://gitcode.com/xusiwei1236/STM32H7S78-DK-XIP
该项的ioc文件来自官方STM32CubeH7RS软件包Template_XIP项目,修改了部分配置,项目类型改为了CMake;然后使用CubeMX生成的项目代码即为本项目的主要代码。
2.2 支持计时功能
STM32上,使用HAL库记录耗时非常简单,只需要用:
HAL_GetTick()获取Tick数即可,默认的Tick频率是1000Hz;- 需要注意的是:
HAL_GetTickFreq()返回的枚举值,并不是实际的频率(例如默认的HAL_TICK_FREQ_1KHZ,其值为1,而不是1000)。
因此,记录使用HAL_GetTick记录耗时,代码类似:
uint32_t start = HAL_GetTick();// 需要记录耗时的代码uint32_t end = HAL_GetTick();
float cost_s = (end - start) / 1000.0f; // 实际耗时(单位:秒)
这部模板本身已经支持了,不需要额外的工作。
2.3 配置UART4引脚
开发板上自带了ST-Link V3调试器,该调试器带有虚拟串口功能。通过查阅原理图,我们知道主控MCU和ST-Link之间的连接关系如下图:
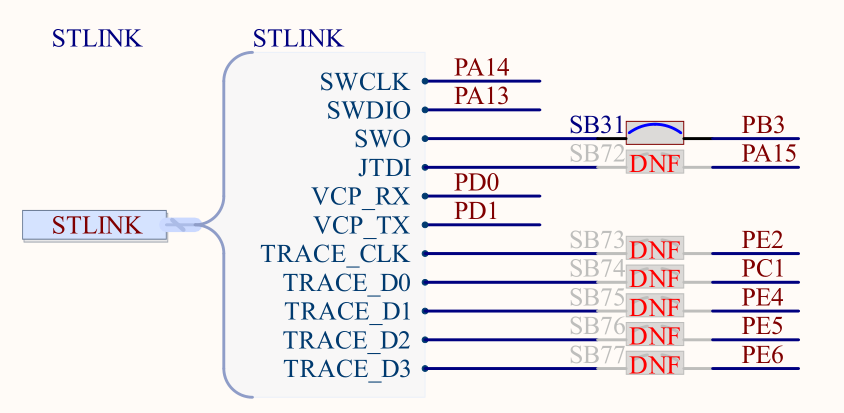
可以看到,ST-Link的虚拟串口和主控芯片的连接关系为:
- VCP_RX连接到主控芯片的 PD0上;
- VCP_TX连接到主控芯片的 PD1上;
接下来,需要修改这两个引脚的功能:

启用UART4功能:
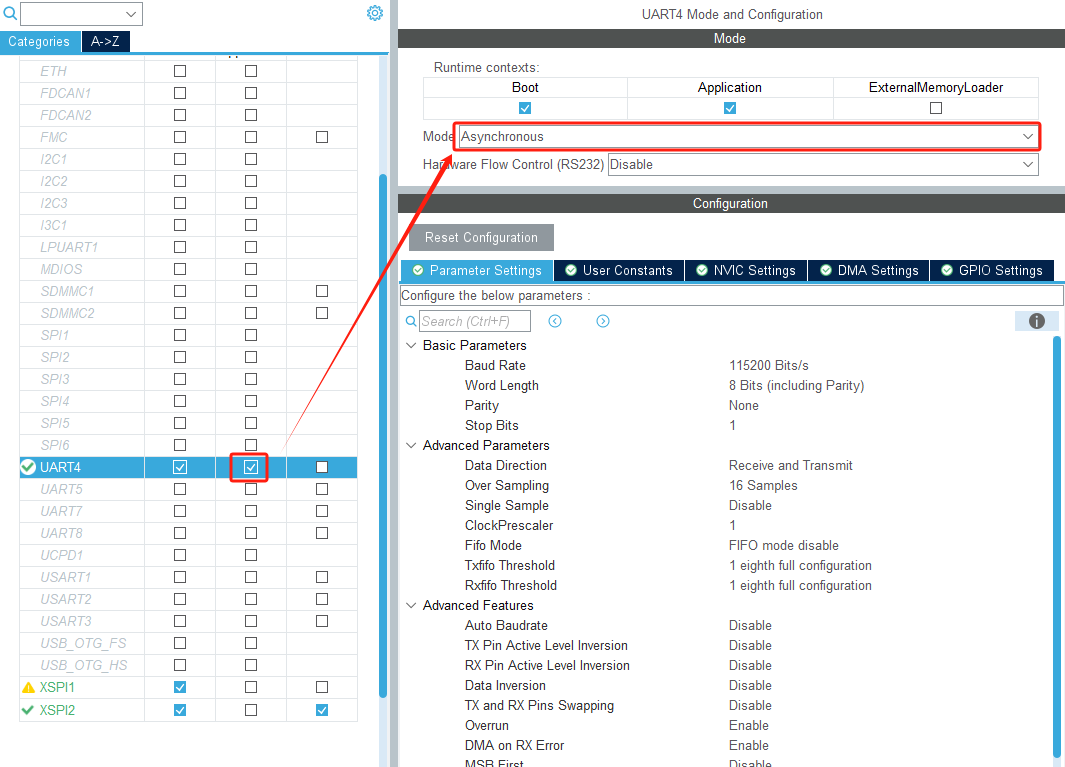
完成上述修改后,Ctrl+S保存,然后重新生成项目代码。
2.4 支持printf重定向到UART4
CubeMX选择CMake项目后,默认已经生成了 syscalls.c文件,已经实现了支持gcc工具链的printf输出的一半功能:
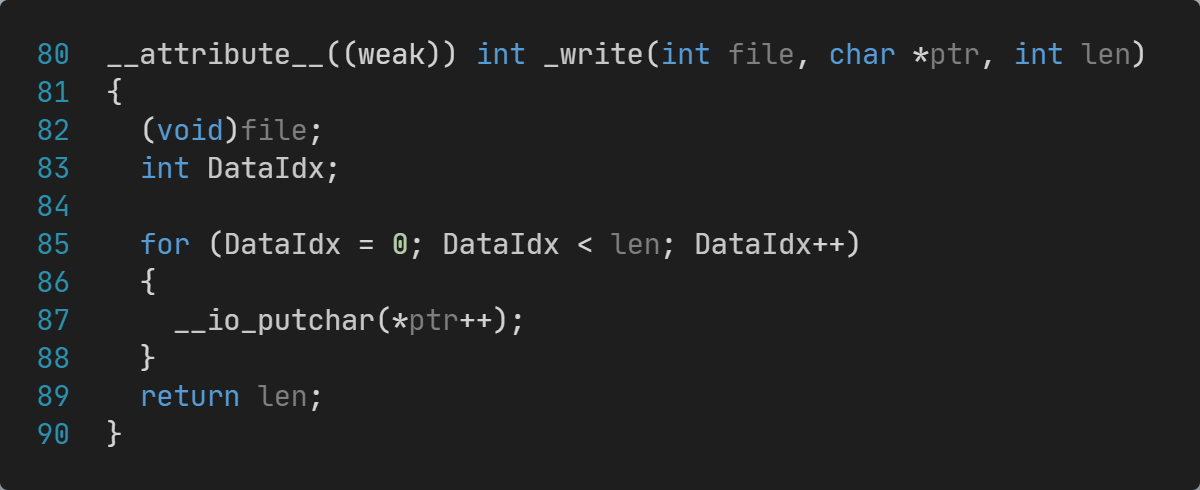
这个_write支持printf和fprintf调用__io_puchar进行输出。
另外一半功能——实现__io_puchar输出到UART即可实现printf输出到UART。
需要手动修改main.c文件,实现__io_puchar函数:
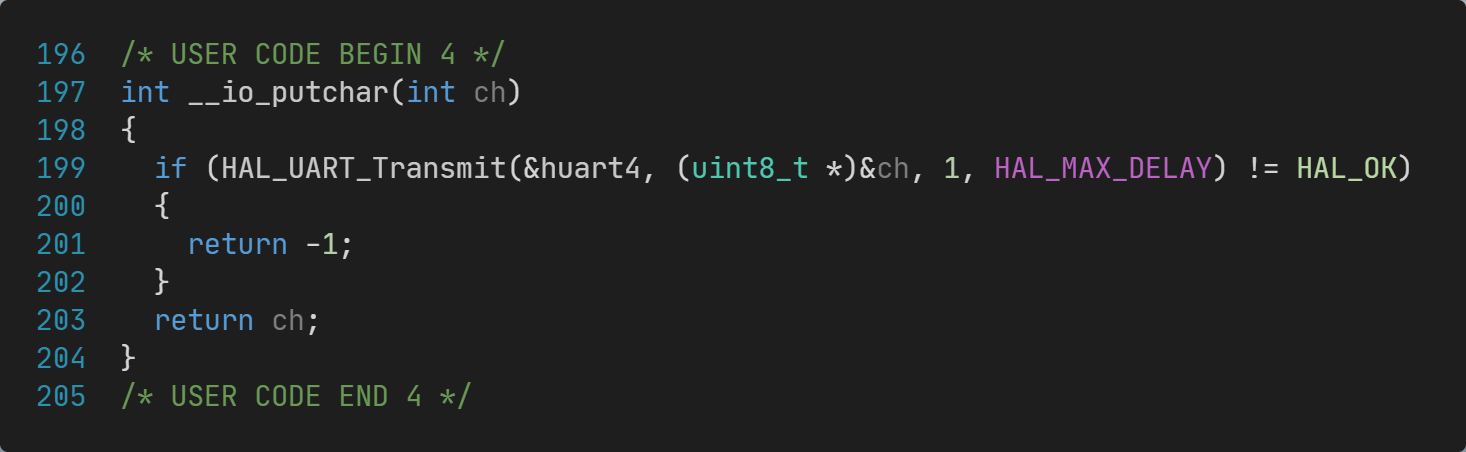
2.5 支持printf输出浮点数
默认生成的CMake项目不支持浮点数打印,需要修改链接选项,修改文件Appli\CMakeLists.txt:
在末尾添加如下代码片段:
target_link_options(${CMAKE_PROJECT_NAME} PRIVATE-u _printf_float
)
之后,再次编译,就可以输出浮点数了。
2.6 支持printf不带\r的换行
大部分串口终端工具,例如MobaXterm,换行需要收到\r\n两个字符才能正常换行。通过修改代码,可以让测试代码输出\n结尾也能和\r\n一样自动换行,具体实现方式为:
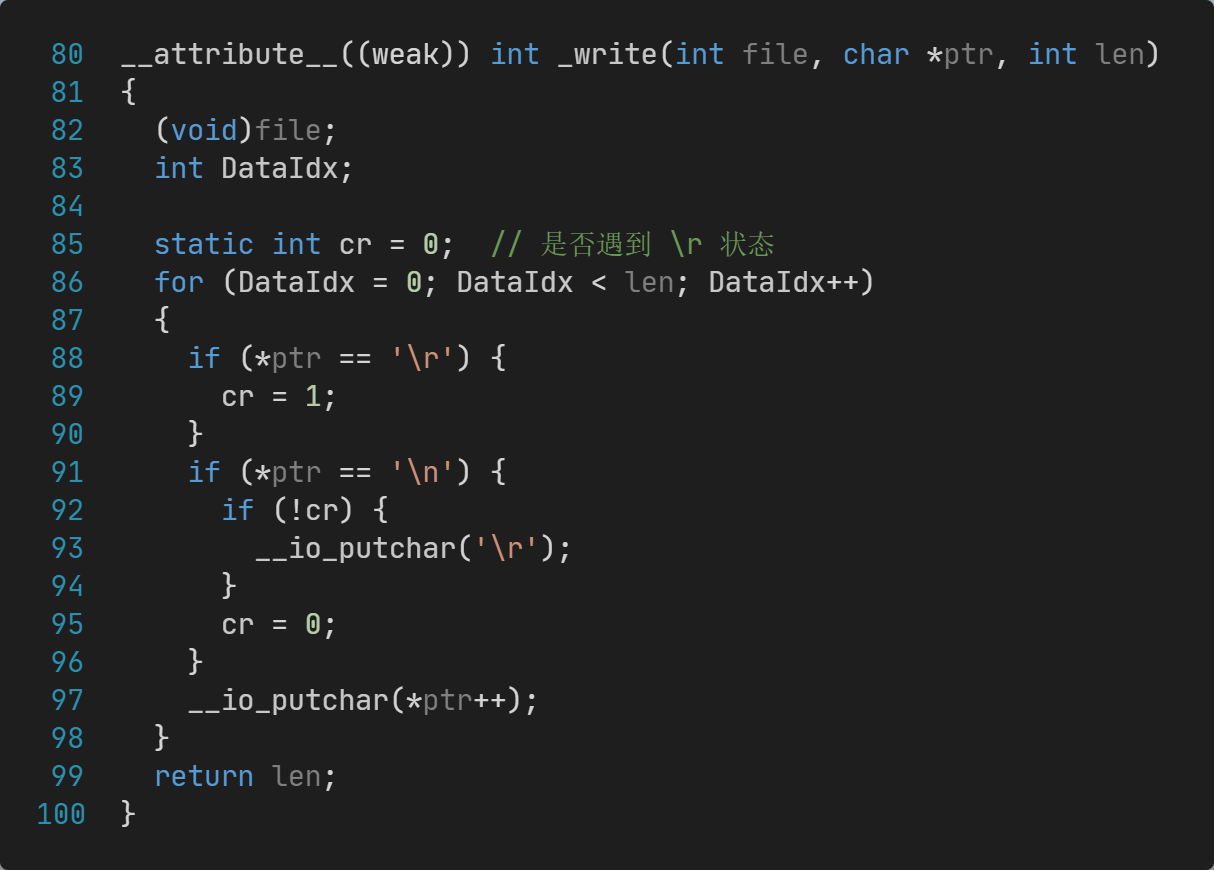
这样修改之后,printf就同时支持了\r\n和\n两种换行符。
2.7 支持ccache编译缓存
修改CMake有时候需要清理build目录才能正常出发重新配置和构建,但清理了build目录后重新构建的过程非常耗时。为了解决这个问题,我们可以使用ccache进行加速。
ccache下载链接: Ccache — Download
Windows平台的ccache是压缩包,解压到合适的目录后,将其配置到PATH环境变量,即可在任意位置使用ccache命令。
完成ccache配置之后,可以咋CMake代码中加入如下片段,实现CMake支持ccache加速:
find_program(CCACHE_PROGRAM ccache)
if (CCACHE_PROGRAM)set(CMAKE_C_COMPILER_LAUNCHER "${CCACHE_PROGRAM}")set(CMAKE_CXX_COMPILER_LAUNCHER "${CCACHE_PROGRAM}")message(STATUS "Ccache found: ${CCACHE_PROGRAM}!")
else ()message(STATUS "Ccache not found!")
endif ()
三、TFLM集成
3.1 添加tflite-micro源码
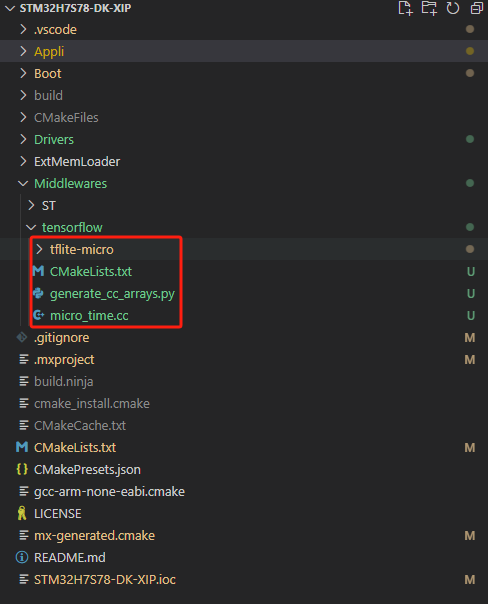
首先,将PC上运行过基准测试的TFLM代码拷贝到CubeMX生成的基于CMake的STM32H7S78-DK项目中,并放在如下目录:
Middlewares/tensorflow
然后,将前“TFLM移植”章节编写完成的CMakeLists.txt文件、micro_time.cc文件,也放到这个目录中。另外,将后下一步需要修改的generate_cc_arrays.py文件也拷贝一份放到该目录中。
完成上述操作后,项目文件布局如下:
3.2 修正micro_time.cc代码
TFLM默认的micro_time.cc文件在STM32上不能正常工作,上篇文章已经给出了一个版本的实现,经过测试上篇文章的代码不能实现预期。
实际需要修改为使用调用HAL库的代码:
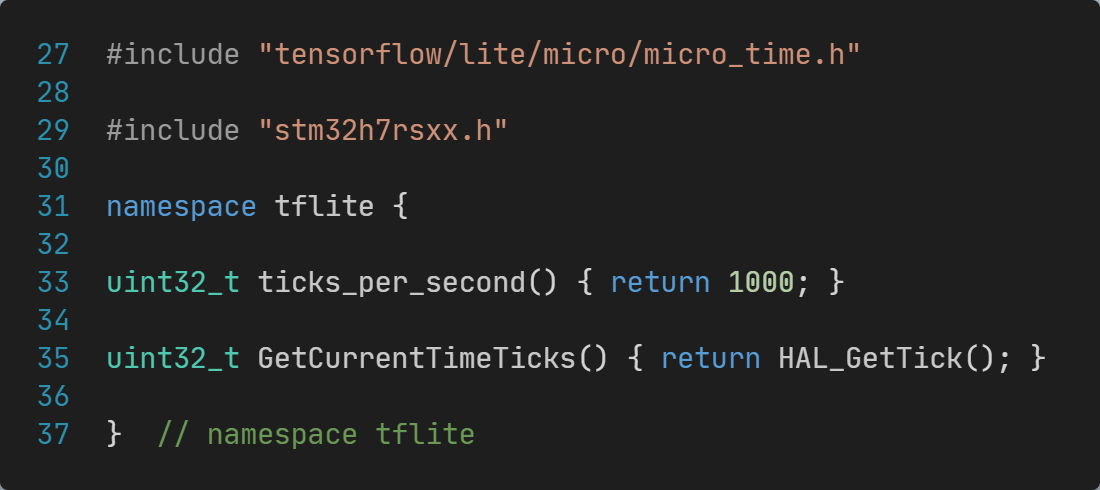
这里的ticks_per_second函数用于返回ticks频率,GetCurrentTimeTicks函数用于返回当前的ticks数;
3.3 构建micro_time.cc的规则
为了正确的构建micro_time.cc,需要将TFLM默认的micro_time.cc文件过滤掉,因此需要修改上一篇文章中我们实现的CMakeLists.txt代码,具体修改为:
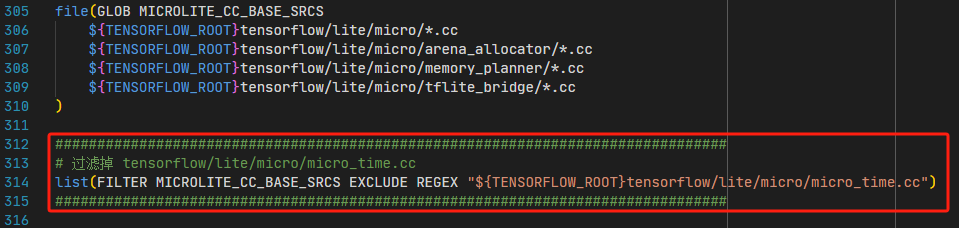
这里,默认的micro_time.cc由306行代码匹配上,314行实现了将其从MICROLITE_CC_BASE_SRCS中过滤掉。
3.4 添加TFLM构建规则
接下来修改顶层的CMakeLists.txt文件,在最后追加两行:
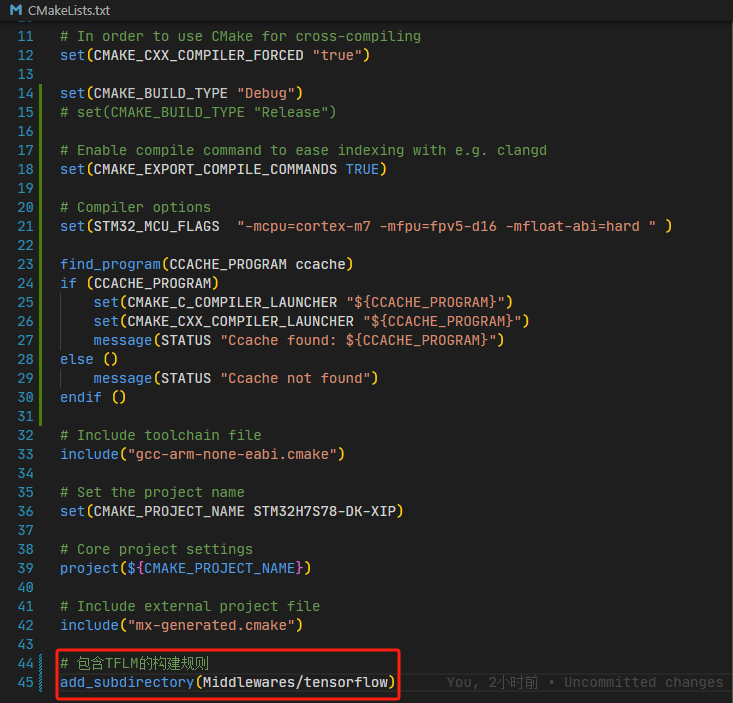
这样,就将TFLM的构建规则添加到了CubeMX生成的CMake项目中了。
3.5 添加TFLM函数调用
上篇文章中,我们实现的TFLM的CMakeLists.txt以及完成了对TFLM库和基准测试库的构建,并且最终会生成三个静态库:
- TFLM库,包含TFLM所有类和函数实现代码;
- keyword_benchmark 库,包含
keyword_benchmark函数实现代码; - person_detection_benchmark 库,包含
person_detection_benchmark函数实现代码;
接着,在我们的Appli子项目的代码中,添加对TFLM的调用。
由于C++函数支持参数重载,编译器生成C++函数会经过名称修饰。同样的函数声明代码,放在C++代码文件中和C代码文件中经过编译生成的二进制符号不同。这导致,在C代码中,我们无法通过声明函数或包含头文件的方式,直接调用C++函数;否则,链接时报告符号找不到。
因此,我们无法通过在Appli子项目的main.c中直接调用keyword_benchmark函数或者person_detection_benchmark函数的方式实现基准测试的集成。
为了解决C代码中不能直接调用C++函数的问题,我们需要引入一个中间层。这里需要用到几个C++相关的知识:
- 使用
extern "C"修饰C++函数,可以让编译器将该C++函数按照C函数的方式生成符号,不进行名称修饰; - C代码中可以调用由名称修饰的C++函数,就像调用其他C函数一样;
- C++有默认的内置宏,
__cplusplus用于只是当前C++编译器支持的语言标准版本,例如201103L表示C++11;
在Appli\Src目录中,创建tflm_benchmark.h文件,内容如下:

与之对应的tflm_benchmark.cc文件,内容为:
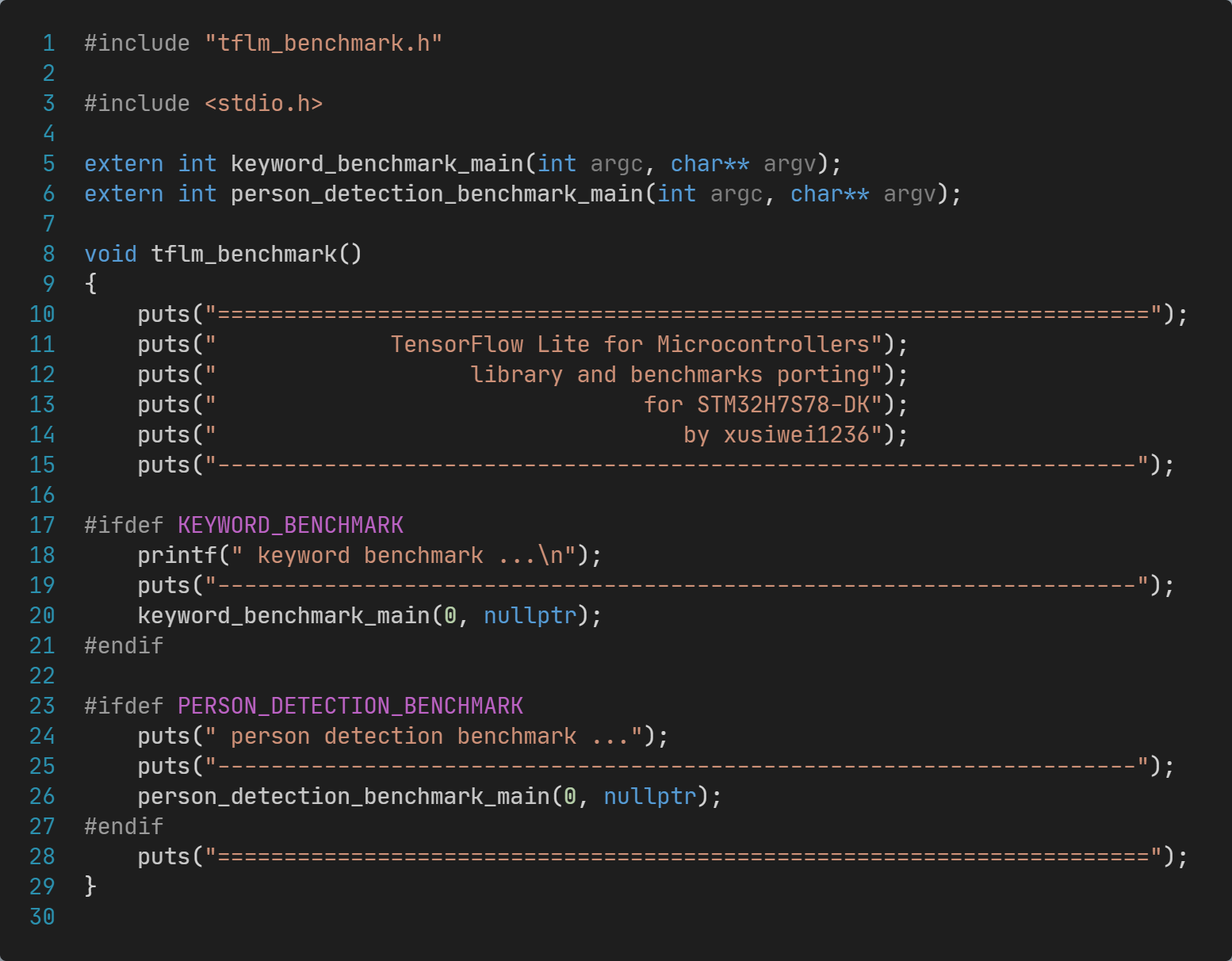
这里,通过KEYWORD_BENCHMARK和PERSON_DETECTION_BENCHMARK两个宏,实现两个基准测试的开关。
接下来就可以修改Appli子项目的main.c,调用这个tflm_benchmark函数了:
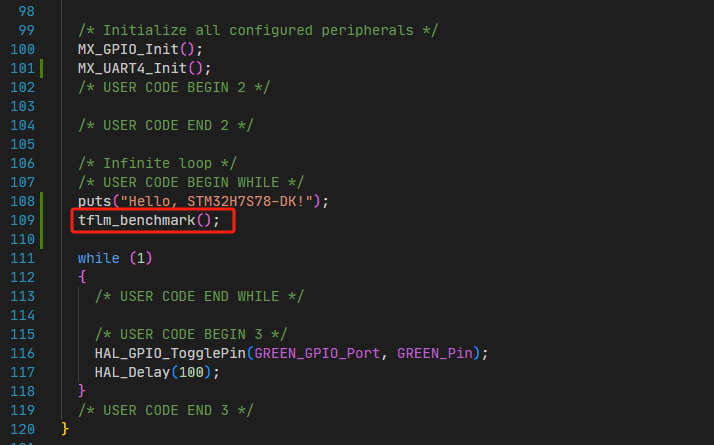
3.6 添加TFLM依赖关系
接下来,需要为我们的Appli添加对TFLM的依赖关系,包括对TFLM库和基准测试的依赖,具体修改的代码为:
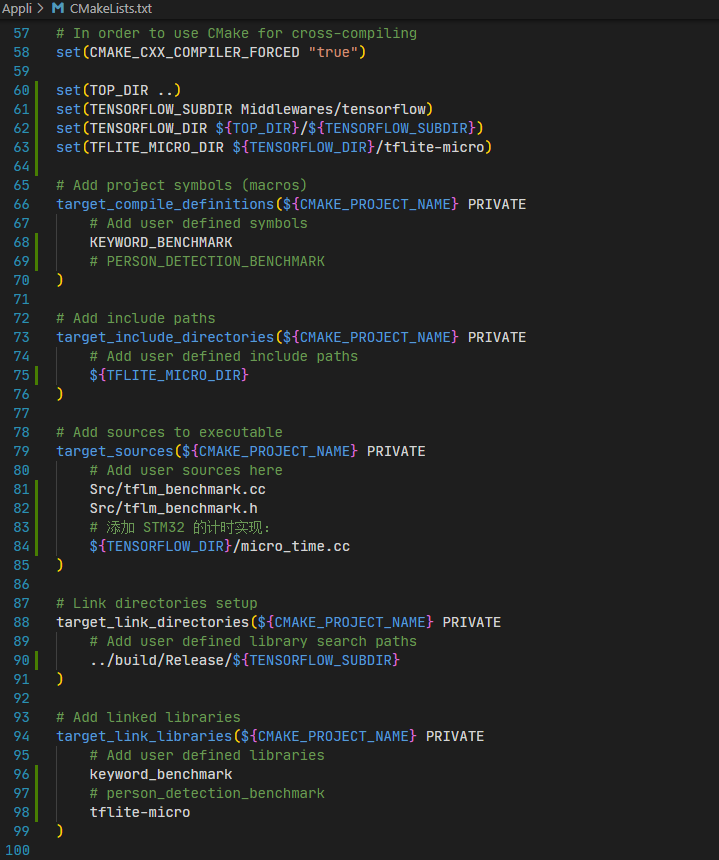
左侧行号标记绿色的即为新增代码行,一共六处,作用分别为:
- 60~64行,定义了几个CMake变量,后面会用到;
- 68~69行,为当前Appli子项目的构建目标,添加
KEYWORD_BENCHMARK(或PERSON_DETECTION_BENCHMARK)宏; - 75行,为当前Appli子项目的构建目标,添加头文件搜索目录;
- 81~84行,为当前Appli子项目的构建目标,添加三个源代码文件;
- 90行,为当前Appli子项目的构建目标,添加库文件搜索目录;
- 96~98行,为当前Appli子项目的构建目标,添加链接
keyword_benchmark(或person_detection_benchmark)库、tflite-micro库;
完成以上全部修改后,就完成了对TFLM库和基准测试的集成工作。
四、TFLM测试
好了,万事俱备,只欠东风!
完成前面的所有工作后,就可以准备在我们的STM32H7S78-DK上进行TFLM基准测试了。
4.1 编译TFLM和Appli项目
编译构建,主要使用VSCode的CMake插件工具栏,具体方法不再赘述,感兴趣的可以参考我之前发的帖子: 【STM32H7S78-DK评测】搭建基于ST官方VSCode扩展的STM32开发环境 - STM32团队 ST意法半导体中文论坛 (stmicroelectronics.cn)
编译之前,先清理一下项目:
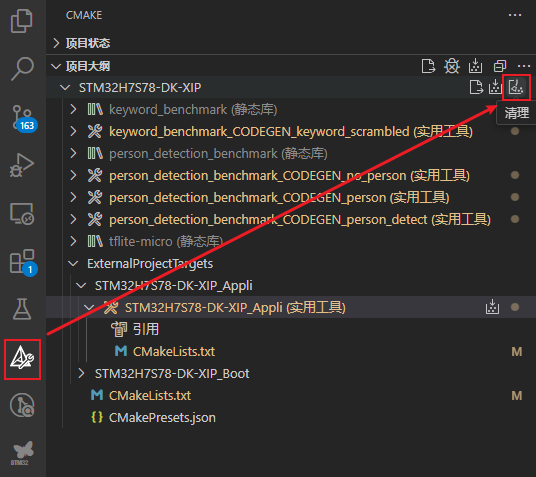
接着,构建TFLM核心库:
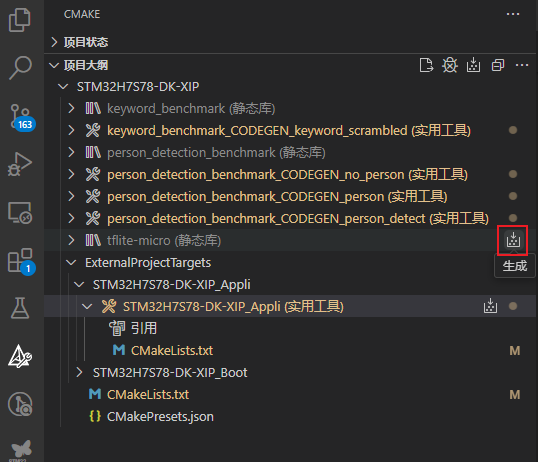
继续,生成基准测试库keyword_benchmark:
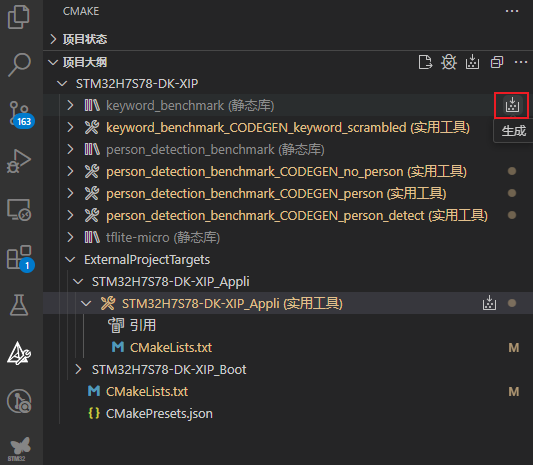
以及基准测试库person_detection_benchmark:
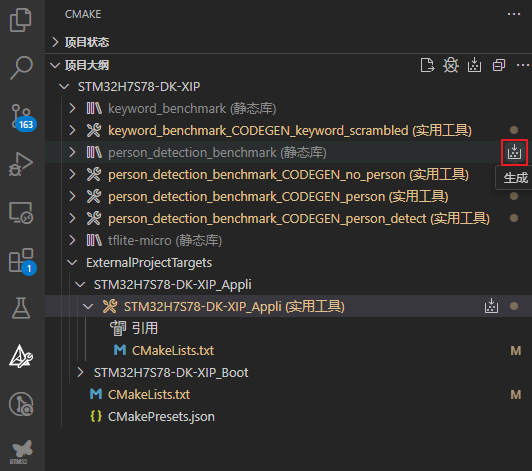
紧接着,构建Appli项目:

构建完成后,可以看到RAM、Flash占用信息:
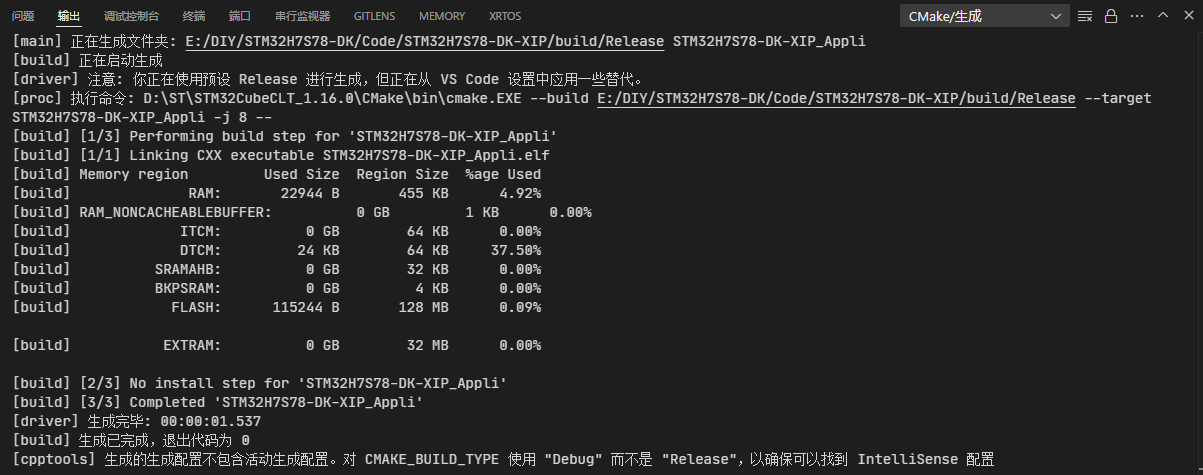
例如,图中的Flash占用为115244 B。
和Appli类似的方式,进行Boot子项目的构建,不再赘述。
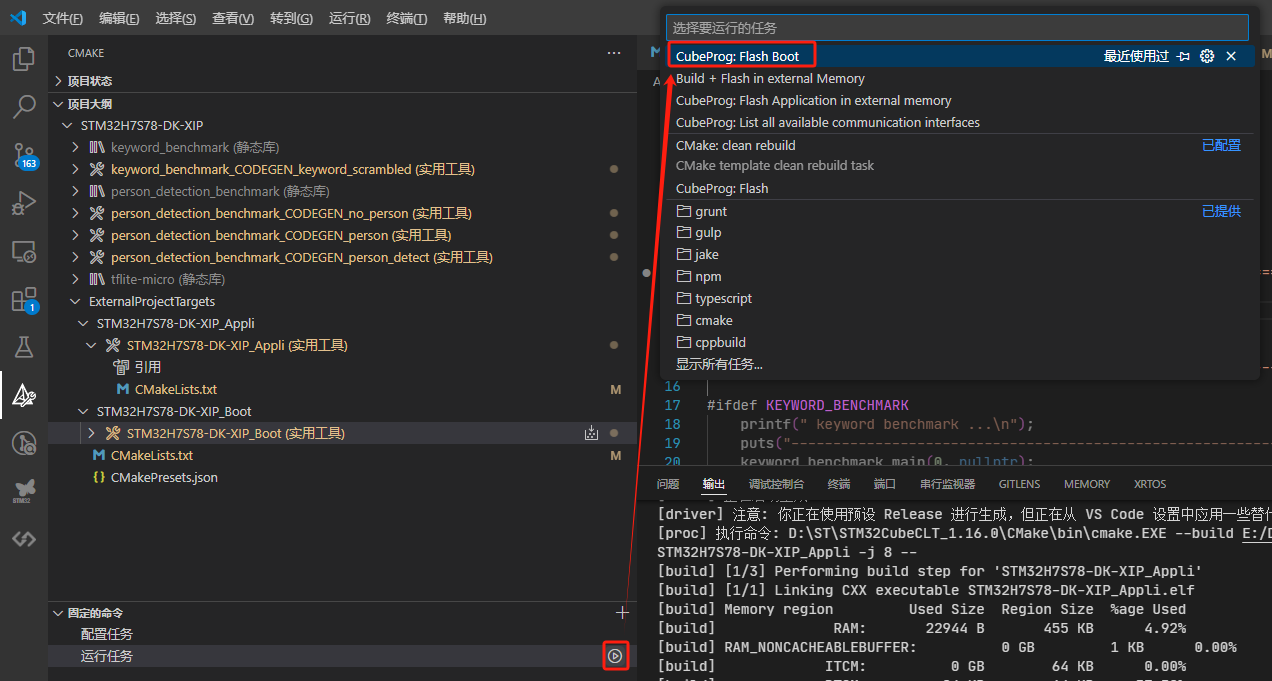
4.2 下载Boot代码
由于Appli代码需要使用Boot代码进行跳转,因此,下载Appli代码之前,需要线下载Boot代码到开发板上。
下载之前,先将STM32H7S78-DK开发板和PC通过USB线连接好,板子由三个USB口,注意连接到标有STLK的。
接着,VSCode上上操作:
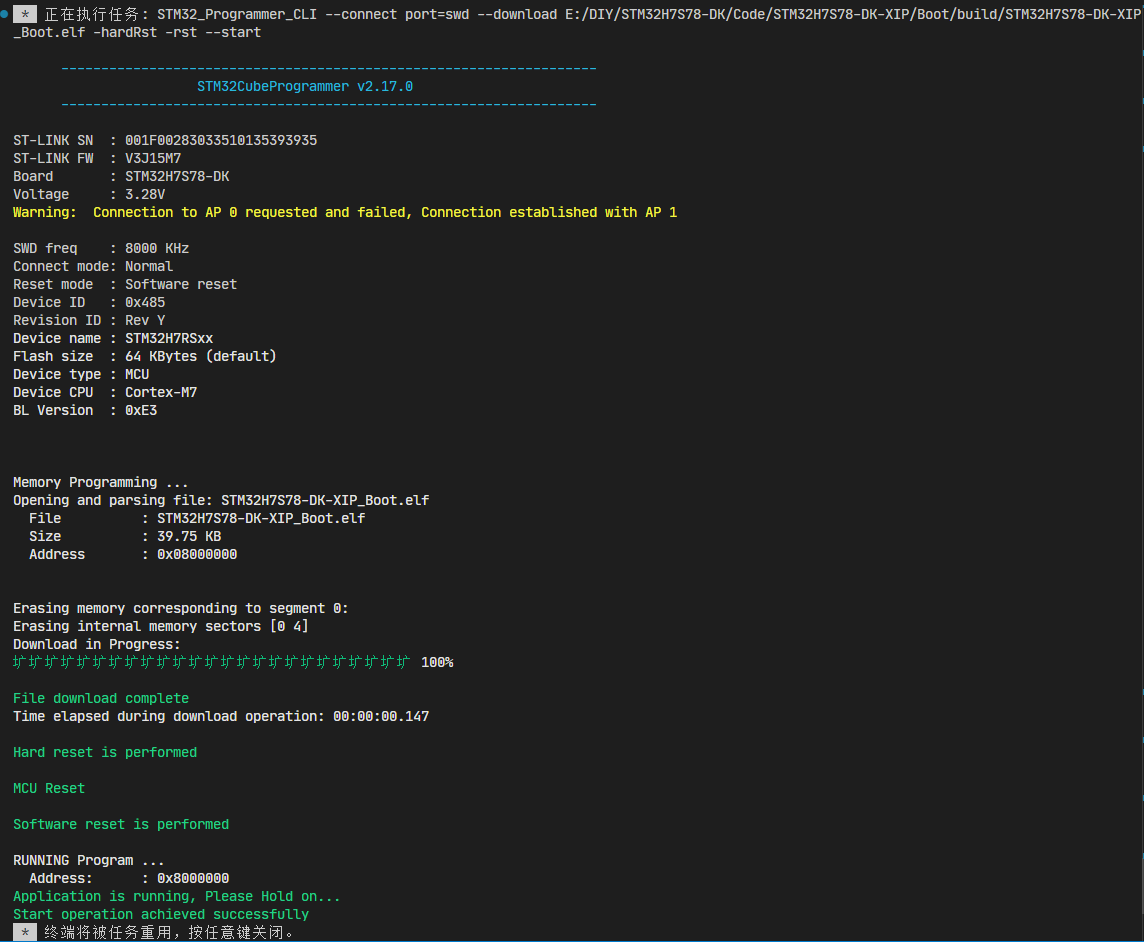
终端子窗口可以看到输出:
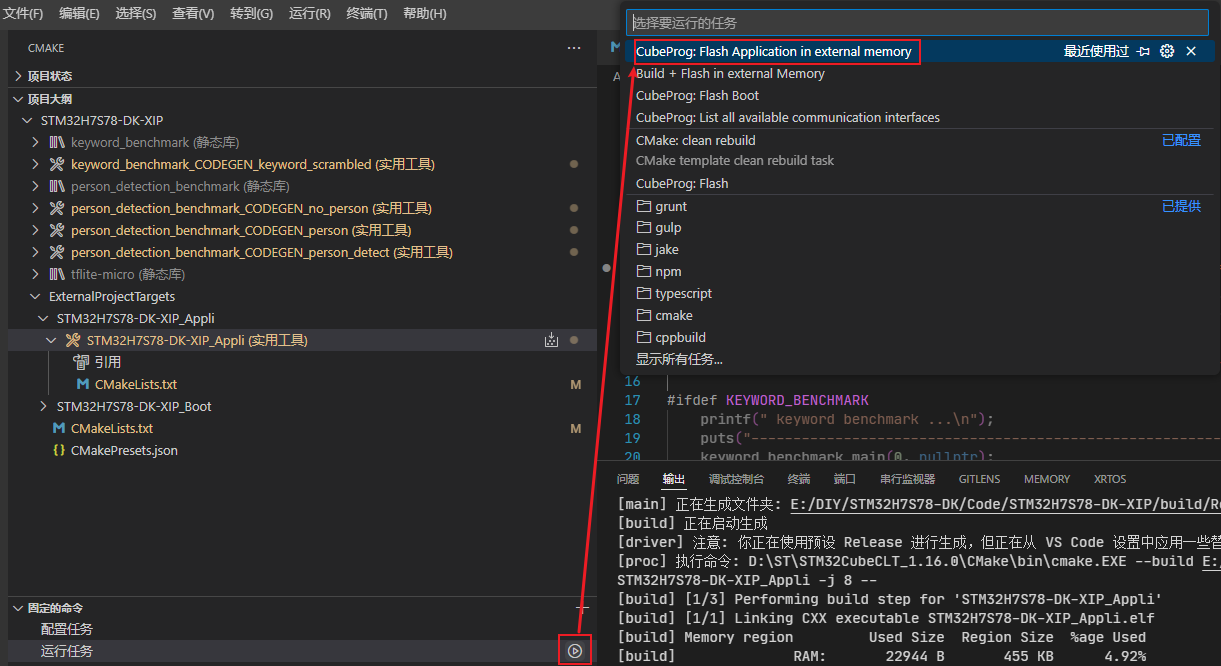
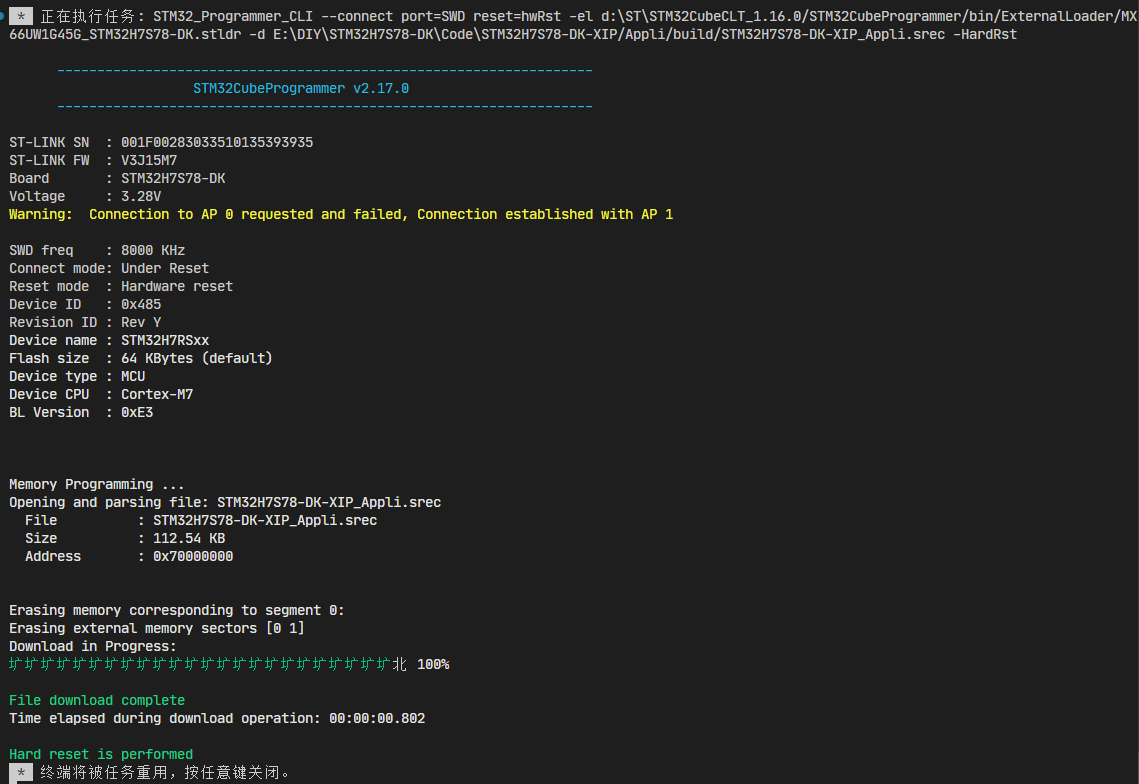
4.3 下载Appli代码
接下来,将我们的STM32H7S78-DK开发板和PC通过USB线连接好,板子由三个USB口,注意连接到标有STLK的。
然后,在VSCode上操作:
终端子窗口可以看到输出:
4.3 运行TFLM基准测试
打开MobaXterm,添加会话,选择STLink的虚拟串口设备,参数如下:
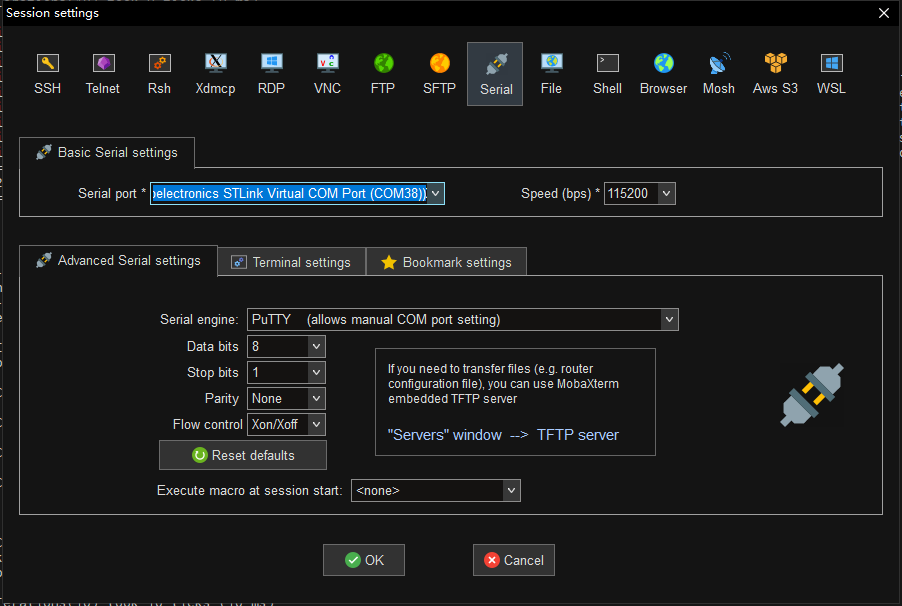
连接设备之后,按下开发板上的NRST按钮,重启设备,可以看到串口输出如下:
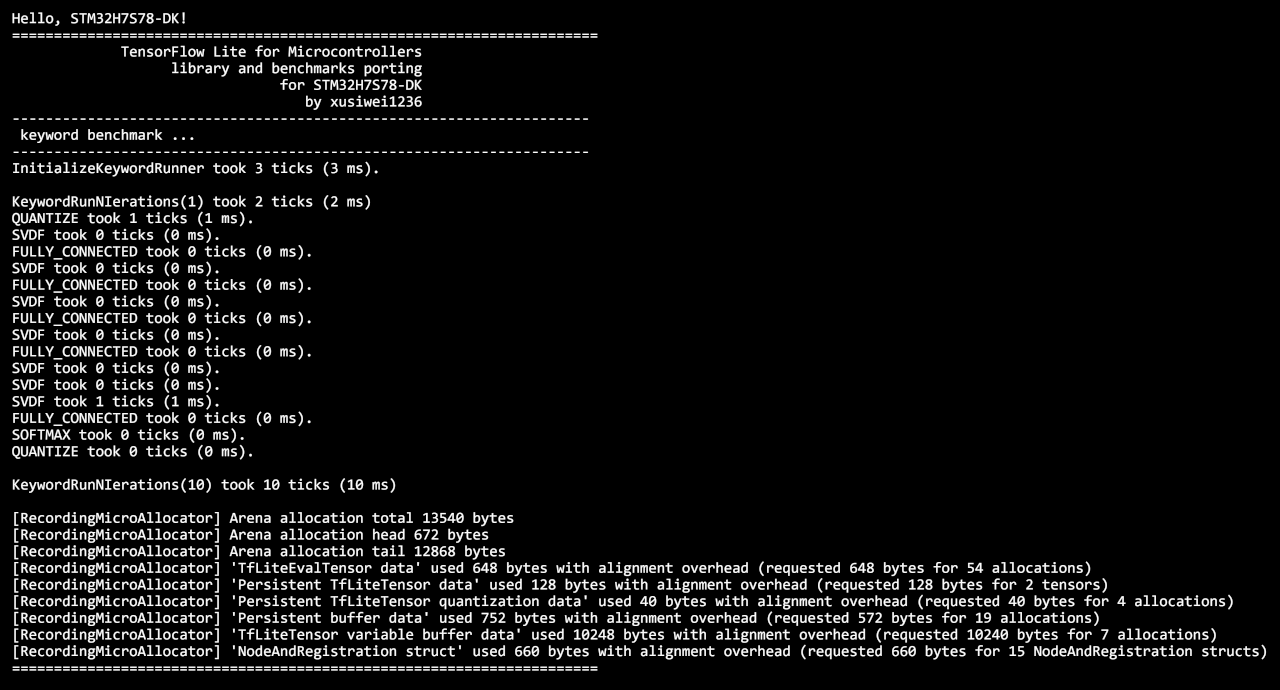
可以看到,keyword模型初始化耗时3毫秒,单独运行一次耗时2毫秒,连续运行10次耗时10毫秒,速度还是可以的。
与之对比的,在PC上运行keyword_benchmark的结果数据:
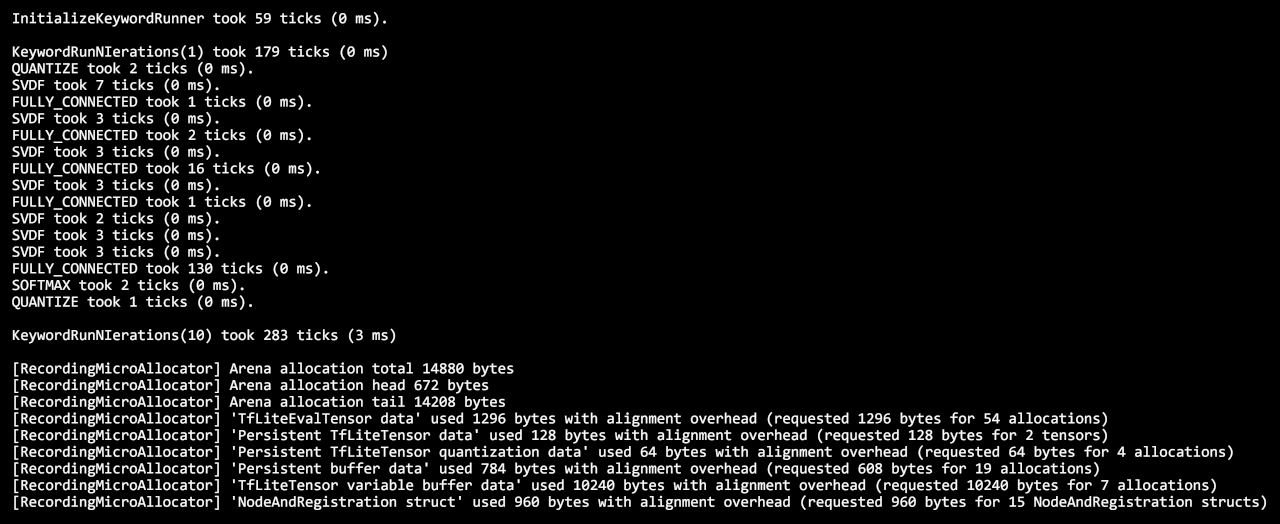
可以看到,PC上模型初始化和单独运行一次耗时都不到1毫秒,连续运行10次耗时3毫秒。
同样,稍加修改Appli\CMakeLists.txt,我们可以编译person_detection_benchmark,并得到在开发板上运行结果数据:
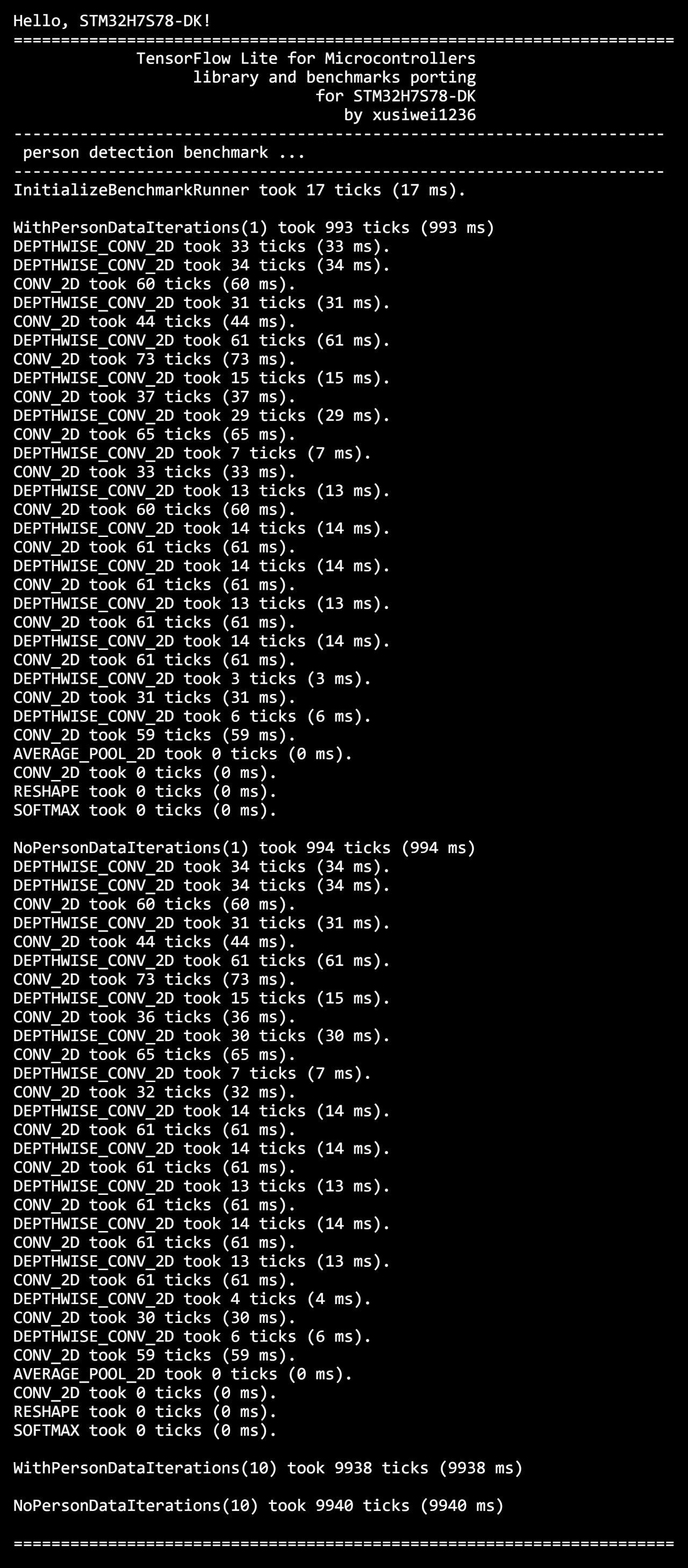
可以看到,开发板上,运行有人图像的人体检测耗时为993毫秒,没有人的耗时为994毫秒;连续运行10次的耗时分别为9938毫秒和9940毫秒,速度有点慢。
与之对应的,PC上运行person_detection_benchmark的结果数据为:
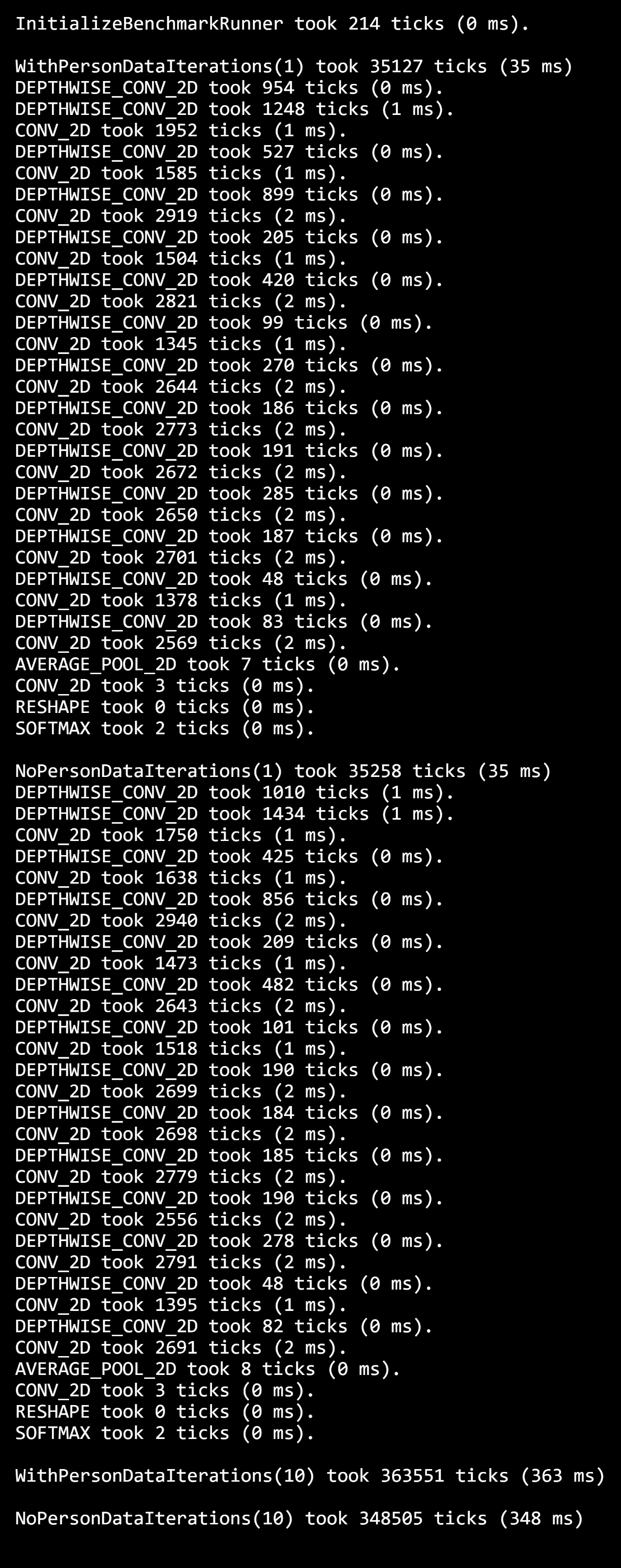
可以看到,PC上运行有人图像的人体检测耗时为36毫秒,没有人的耗时为35毫秒;连续运行10次的耗时分别为9938毫秒和9940毫秒,
五、问题解决
在前面的第三章、第四章的实践过程中,我遇到了一些问题,为了保持主体部分的简洁清晰,没有将问题描述和解决方法写在第三章、第四章内容中。本章将介绍预提遇到的问题,以及问题的解决方法,如果你在实践过程中遇到类似的问题,可以参考本章的方法进行解决。
5.1 benchmark编译失败
【问题现象】 编译失败,报错信息:

【问题原因】 直接原因是脚本生成代码中,数组和变量定义有问题(把路径带入进去了):

【解决方法】 修改代码生成脚本:
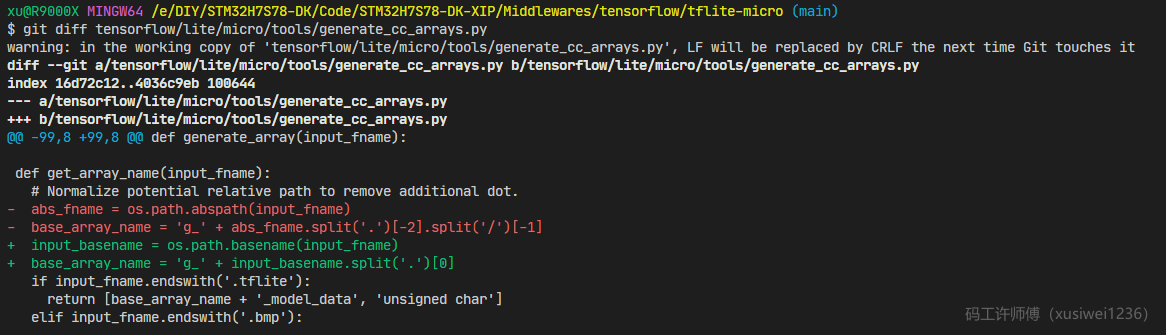
通过排查脚本生成代码,可以知道**【问题根因】**是Windows系统的路径分隔符不是/,.split('/')失败。
根据走读代码,可以知道代码中的base_array_name是文件名的基础部分,也就是去掉路径和扩展名;重新实现一下就好了。
5.2 Appli链接报错
【问题现象】 Appli链接失败,报错信息:
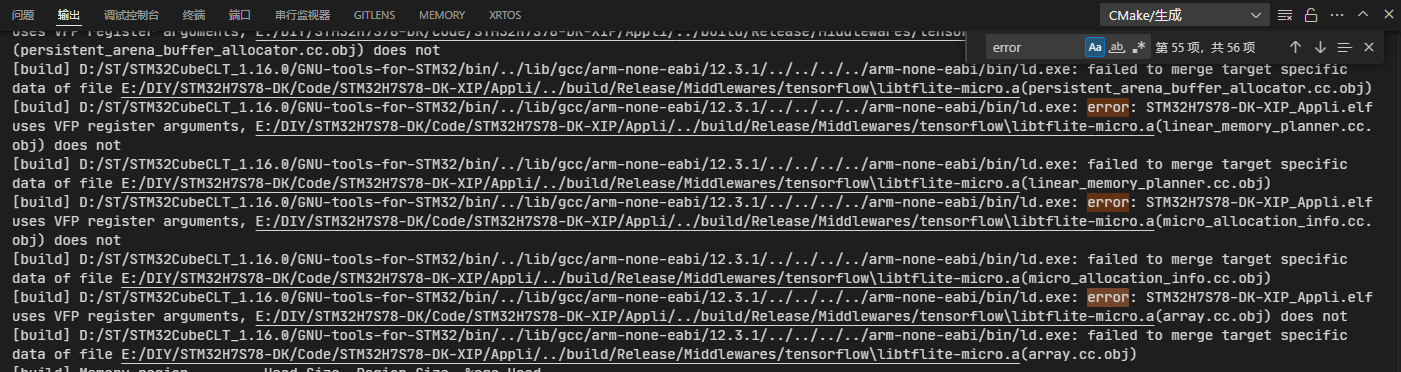
【问题原因】 Appli子项目使用了VFP寄存器参数(VFP register arguments),而libtflite-micro.a没有使用;
【解决方法】 顶层修改CMakeLists.txt,添加一行:

5.3 benchmark无法正常开始
【问题现象】 无法正常运行benchmark;
【初步调试】 运行到benchmark入口函数之后,无法进入tflite::InitializeTarget函数;
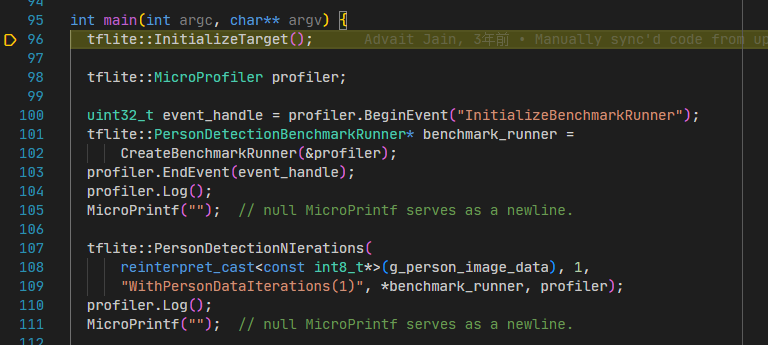
下一步直接进入HardFault_Handler;
【问题分析】 查看寄存器,发现栈指针位置异常:
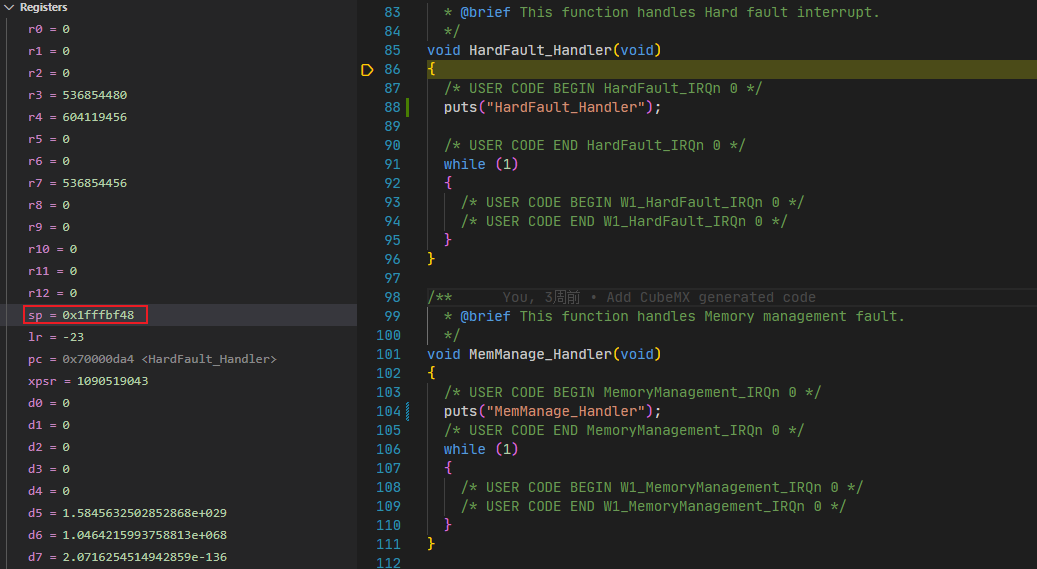
已经超出了链接脚本设置的栈范围:
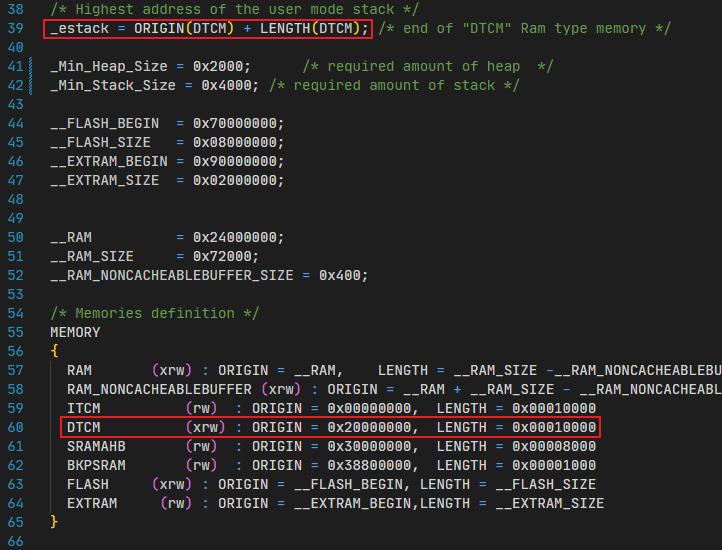
根据这段代码,可以知道正常的栈指针范围应该在[0x20000000, 0x20010000)的64K范围内。
【代码排查】 反汇编查看benchmark入口代码:
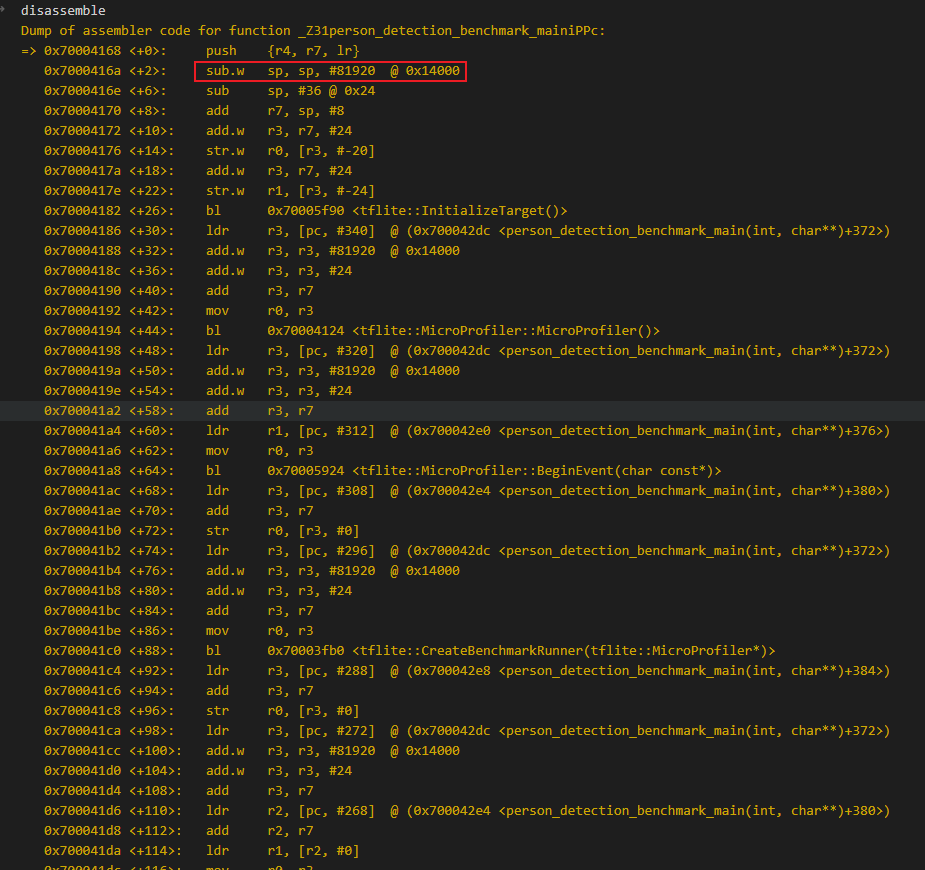
可以看到入口处申请的栈内存空间为81920(80K),超过链接脚本设置的64K栈空间,结合代码内容,可以知道是MicroProfiler对象占用的空间。
【解决方法】 修改MicroProfiler代码,具体修改如下:
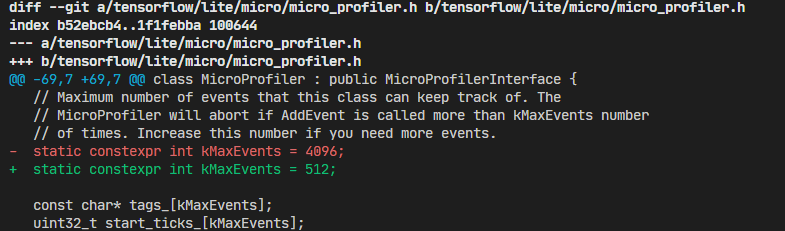
因为,这个常量是几个数组的大小:
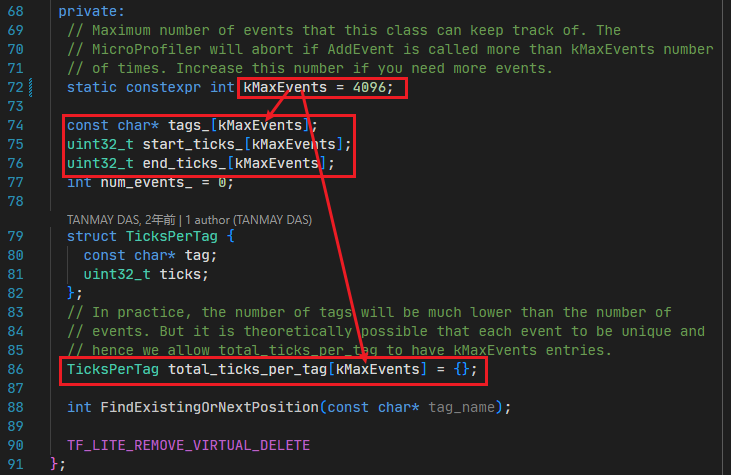
初步估算:5*4*4K正好是80K;
因此,把这个常量的值改小即可解决该问题。
5.4 Release版无法正常返回
【问题现象】 Debug版本可以正常运行,Release版benchmark函数无法正常返回到main函数;
【问题原因】 经过排查, 发现原因是benchmark函数写了返回值类型int,但没有写return语句;
【解决方法】 修改代码,benchmark函数最后添加一行return 0;语句即可;
六、源码分享
本项目的所有代码已经开源到GitCode平台,感兴趣的小伙伴可以免费下载体验: https://gitcode.com/xusiwei1236/STM32H7S78-DK-TFLM.git
本代码仓使用了git submodule特性,需要用--recursive选项进行克隆:
git clone --recursive https://gitcode.com/xusiwei1236/STM32H7S78-DK-TFLM.git
另外,tflite-micro依赖的一些三方软件已经打包到了如下仓库:
https://gitcode.com/tflm/downloads.git
下载方法:
# 跳转到 tflite-micro 子目录
cd Middlewares/tensorflow/tflite-micro# 下载 downloads 下的三方软件源码
git clone https://gitcode.com/tflm/downloads.git tensorflow/lite/micro/tools/make/downloads/
七、参考链接
- CCache下载页面: Ccache — Download
- CMake中使用CCache: Use Ccache with CMake | Lindevs
- 官方STM32CubeH7RS软件包的XIP项目模板: Template_XIP
- TensorFlow Lite for Microcontrollers介绍: TensorFlow Lite for Microcontrollers (google.cn)
- TensorFlow Lite for Microcontrollers入门: 微控制器入门 | TensorFlow (google.cn)
- tflite-micro 源码GitHub仓: https://github.com/tensorflow/tflite-micro
- CMake最新文档: CMake Reference Documentation — CMake 3.30.3 Documentation
相关文章:
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】 一、上篇回顾二、项目准备2.1 准备模板项目2.2 支持计时功能2.3 配置UART4引脚2.4 支持printf重定向到UART42.5 支持printf输出浮点数2.6 支持printf不带\r的换行2.7 支持ccache编译缓存 三、TFLM集成3.1 添加tfli…...

畅阅读小程序|畅阅读系统|基于java的畅阅读系统小程序设计与实现(源码+数据库+文档)
畅阅读系统小程序 目录 基于java的畅阅读系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师…...

【机器学习(十一)】糖尿病数据集分类预测案例分析—XGBoost分类算法—Sentosa_DSML社区版
文章目录 一、XGBoost算法二、Python代码和Sentosa_DSML社区版算法实现对比(一) 数据读入和统计分析(二)数据预处理(三)模型训练与评估(四)模型可视化 三、总结 一、XGBoost算法 关于集成学习中的XGBoost算法原理,已经进行了介绍与总结,相关内容可参考【…...

二分查找一>寻找峰值
1.题目: 2.解析: 暴力遍历代码:O(N),由于该题数据很少所以可以通过 暴力遍历:O(N),由于该题数据很少所以可以通过int index 0;for(int i 1; i < nums.length-1; i) {//某段区域内一直递增,更新就indexif(nums[i]…...

《Linux从小白到高手》理论篇:深入理解Linux的网络管理
今天继续宅家,闲来无事接着写。本篇详细深入介绍Linux的网络管理。 如你所知,在Linux中一切皆文件。网卡在 Linux 操作系统中用 ethX,是由 0 开始的正整数,比如 eth0、eth1… ethX。而普通猫和ADSL 的接口是 pppX,比如 ppp0 等。 …...

redis数据类型介绍
1. 字符串(String) 字符串是 Redis 中最基本的数据类型,它可以存储任何形式的字符串,包括文本、数字等。字符串类型的操作非常丰富,比如 SET、GET、INCR(自增)、DECR(自减࿰…...
一张照片变换古风写真,Flux如何做到?
前言 解锁图像创作新体验:ComfyUI指南 在AI图像生成领域,ComfyUI 已成为不可忽视的力量。它是基于Stable Diffusion的图像生成工具,提供了一个节点式图形用户界面(GUI),让用户可以通过简单的拖拽与配置来…...

医药行业的智能合同审查:大模型与AI赋能合规管理
随着医药行业的快速发展,尤其是在全球化背景下,企业在业务拓展、合作协议签订中需要处理大量复杂的合同。合同不仅是业务的法律保障,更是风险管理的重要工具。医药行业合同审查的复杂性源于其严格的合规性要求,包括与政府机构、研…...

幂等性接口实现
1、什么是幂等性 幂等(idempotence),这个词源自数学,幂等性是数学中的一个概念,常见于抽象代数中。表达的是N次变换与1次变换的结果相同。简单来说,就是如果方法调用一次和调用多次产生的效果是相同的&…...

C++ 语言特性29 - 协程介绍
一:什么是协程 C20 引入了协程(coroutine),这是 C 标准库中一个强大的新特性。协程是一种可以在执行中暂停并随后恢复的函数,允许程序在异步或并行场景下高效管理任务,而不需要传统的线程或复杂的回调机制。…...

[Day 84] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
AI在公共安全中的應用實例 引言 隨著技術的進步,人工智能(AI)在公共安全領域的應用越來越廣泛。AI不僅能夠提高安全部門的工作效率,還能有效幫助預防和處理各類公共安全事件。從人臉識別、行為分析到災害預測,AI正在…...

八大排序--01冒泡排序
假设有一组数据 arr[]{2,0,3,4,5,7} 方法:开辟两个指针,指向如图,前后两两进行比较,大数据向后冒泡传递,小数据换到前面。 一次冒泡后,数组中最大…...
)
【Kubernetes】常见面试题汇总(五十)
目录 112.考虑一个公司要向具有各种环境的客户提供所有必需的分发产品的方案。您如何看待他们如何动态地实现这一关键目标? 113.假设一家公司希望在从裸机到公共云的不同云基础架构上运行各种工作负载。在存在不同接口的情况下,公司将如何实现这一目标&…...

Linux 操作系统中的 main 函数参数和环境变量
在聊进程替换之前,有一些基础知识我们得先弄清楚。掌握了这些内容,不仅能让你更轻松地理解 Shell 是如何工作的,还能为之后的进程替换操作铺好路。进程替换说白了就是 Shell 的基本原理,它能把一个命令的输出直接当成另一个命令的…...

Vue项目中通过插件pxtorem实现大屏响应式
一、原理 rem单位代表的是根节点的font-size大小,所以当我们在页面上使用rem去替代px的时候,就可以通过修改根节点font-size的值,动态地让页面上的元素根据不同浏览器宽高下去实现变化。 二、工具 1.postcss-pxtorem 作用:在编…...

(Django)初步使用
前言 Django 是一个功能强大、架构良好、安全可靠的 Python Web 框架,适用于各种规模的项目开发。它的高效开发、数据库支持、安全性、良好的架构设计以及活跃的社区和丰富的文档,使得它成为众多开发者的首选框架。 目录 安装 应用场景 良好的架构设计…...

【星汇极客】单片机竞赛之2024睿抗机器人大赛-火线速递赛道(持续更新)
前言 本人是一名嵌入式学习者,在大学期间也参加了不少的竞赛并获奖,包括但不限于:江苏省电子设计竞赛省一、睿抗机器人国二、中国高校智能机器人国二、嵌入式设计竞赛国三、光电设计竞赛国三、节能减排竞赛国三。 后面会经常写一下博客&…...

生信科研,教授(优青)团队一站式指导:高通量测序技术--农业植物基因组分析、组蛋白甲基化修饰、DNA亲和纯化测序、赖氨酸甲基化
组蛋白甲基化修饰工具(H3K4me3 ChIP-seq) 组蛋白甲基化类型也有很多种,包括赖氨酸甲基化位点H3K4、H3K9、H3K27、H3K36、H3K79和H4K20等。组蛋白H3第4位赖氨酸的甲基化修饰(H3K4)在进化上高度保守,是被研究最多的组蛋白修饰之一。 DNA亲和纯化测序 DNA亲…...
【Immich部署与访问】自托管媒体文件备份服务 Immich 本地化部署与远程访问存储数据
文章目录 前言1.关于Immich2.安装Docker3.本地部署Immich4.Immich体验5.安装cpolar内网穿透6.创建远程链接公网地址7.使用固定公网地址远程访问 前言 本篇文章介绍如何在本地搭建lmmich图片管理软件,并结合cpolar内网穿透实现公网远程访问到局域网内的lmmich&#…...

AI少女/HS2甜心选择2 仿逆水寒人物卡全合集打包
内含AI少女/甜心选择2 仿逆水寒角色卡全合集打包共6张 内含:白灵雪魅落霞飞雁君临华歌白君临华歌黑平野星罗晚香幽韵 下载地址: https://www.51888w.com/436.html 部分演示图:...
)
STM32串口屏通信避坑指南:为什么你的陶晶驰T0屏有时没反应?(附示波器调试实录)
STM32与陶晶驰串口屏通信故障深度解析:从波形诊断到稳定传输实战 实验室里,你盯着那块沉默不语的陶晶驰T0串口屏,STM32F103C8T6的开发板指示灯正常闪烁,串口调试助手显示数据已发送——但屏幕依然漆黑一片。这种"通信玄学&qu…...

Android 11 热点永不关闭的三种实现方案:从源码修改到API调用
Android 11热点持久化方案深度解析:从系统底层到应用层的完整实现 在移动设备开发领域,热点功能的稳定性与持久性一直是开发者关注的重点。Android 11系统默认的热点超时机制(10分钟无连接自动关闭)虽然考虑了节能因素,…...

TQVaultAE:为《泰坦之旅》周年版打造的无限仓库管理工具
TQVaultAE:为《泰坦之旅》周年版打造的无限仓库管理工具 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》中堆积如山的传奇装备无处存放而烦恼…...
)
保姆级教程:用VMware Workstation Pro 16给虚拟机装Win11,手把手教你用Ghost镜像(含UEFI/BIOS切换避坑)
VMware Workstation Pro 16实战:零基础Ghost安装Windows 11全流程解析 在虚拟化技术日益普及的今天,使用VMware Workstation Pro创建虚拟机已成为开发者测试新系统的首选方案。特别是对于Windows 11这样的新操作系统,直接在物理机上安装可能存…...

Solopreneur 7×24 Agent 工作流:从 ARIS 论文里抠出 5 个可落地步骤
论文:ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration arXiv:2605.03042(2026.5.4 上海交大) 适合人群:独立开发者 / Solopreneur / 想搭"睡眠工作流"的人 一、先讲一个我自己的故事 我做独立开…...

基于DS18B20与WipperSnapper的无代码物联网温度监测方案
1. 项目概述:当经典传感器遇上无代码物联网 在物联网和智能硬件的世界里,温度监测是一个永恒的基础需求。无论是想监控家里的温室环境、记录鱼缸水温,还是追踪服务器机柜的热量变化,你都需要一个可靠、精确且易于集成的温度传感器…...

从ok-skills项目解析技能树:设计理念、技术实现与工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ok-skills”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“技能树”或“知识图谱”的开源项目。简单来说,它试图用一种结构化的…...

DLSS Swapper终极指南:一键管理游戏图形增强文件,释放显卡全部性能
DLSS Swapper终极指南:一键管理游戏图形增强文件,释放显卡全部性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为游戏玩家设计的智能图形增强文件管理工具,…...

终极硬件调优指南:如何用UXTU免费解锁电脑隐藏性能
终极硬件调优指南:如何用UXTU免费解锁电脑隐藏性能 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性能…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...