SQL进阶技巧:SQL中的正则表达式应用?
目录
0 引言
1. 正则表达式函数
1.1 regexp_extract
1.2 regexp_replace
1.3 regexp_like
2. 在WHERE子句中使用正则表达式
3. 在GROUP BY中使用正则表达式
4. 性能考虑
5. 高级正则表达式技巧
5.1 使用正则表达式进行数据清洗
5.2 使用正则表达式处理JSON
6. 正则表达式与窗口函数的结合
7. 使用UDF扩展正则表达式功能
8. 性能优化技巧
9. 实际应用案例
9.1 日志分析
9.2 文本分类
10. 正则表达式在ETL过程中的应用
10.1 数据提取 (Extract)
10.2 数据转换 (Transform)
10.3 数据加载前的验证 (Load)
11 正则表达式性能调优
11.1 使用Explain计划
11.2 正则表达式优化技巧
12. 正则表达式安全性考虑
13. 正则表达式与机器学习的结合
14 正则表达式元字符总结
15 结论
如果觉得本文对你有帮助,想进一步学习SQL语言这门艺术的,那么不妨也可以选择去看看我的博客专栏 ,部分内容如下:
数字化建设通关指南
专栏 原价99,现在活动价59.9,按照阶梯式增长,直到恢复原价。
0 引言
“ 正则表达式是一种强大的文本处理工具,在 SQL中也得到了广泛支持。本文将介绍HiveSQL中使用正则表达式的主要方法和常见场景。”

1. 正则表达式函数
Hive SQL提供了几个内置函数来处理正则表达式:
1.1 regexp_extract
regexp_extract(string, pattern, idx) 函数用于从字符串中提取匹配正则表达式的子串。
SELECT regexp_extract('foo|bar|baz', '(\\w+)\\|(\\w+)', 2) AS extracted;-- 结果: bar
1.2 regexp_replace
regexp_replace(string, pattern, replacement) 函数用于替换匹配正则表达式的内容。
SELECT regexp_replace('100-200', '(\\d+)', 'num') AS replaced;-- 结果: num-num
1.3 regexp_like
regexp_like(string, pattern) 函数用于检查字符串是否匹配给定的正则表达式。
SELECT regexp_like('Apple', '[A-Z][a-z]+') AS is_match;-- 结果: true
2. 在WHERE子句中使用正则表达式
你可以在WHERE子句中使用正则表达式来过滤数据:
SELECT * FROM usersWHERE regexp_like(email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}$');
这个查询会选择所有email格式正确的用户。
3. 在GROUP BY中使用正则表达式
正则表达式可以用于复杂的分组操作:
SELECT regexp_extract(url, '^(https?://)?([^/]+)', 2) AS domain,COUNT(*) AS visit_count
FROM web_logs
GROUP BY regexp_extract(url, '^(https?://)?([^/]+)', 2);这个查询会按照URL的域名部分进行分组统计。
4. 性能考虑
虽然正则表达式非常强大,但它们可能会影响查询性能,特别是在处理大量数据时。在使用正则表达式时,请考虑以下建议:
尽可能使用更简单的字符串函数(如LIKE)代替复杂的正则表达式。对于频繁执行的查询,考虑预处理数据,将正则表达式的结果存储起来。使用正则表达式时,尽量避免回溯,使用高效的模式。
5. 高级正则表达式技巧
5.1 使用正则表达式进行数据清洗
正则表达式在数据清洗过程中非常有用,特别是处理非结构化或半结构化数据时。
-- 清理电话号码格式
SELECTregexp_replace(phone_number, '(\\D)', '') AS cleaned_phone_numberFROM customers;
-- 提取邮政编码
SELECTregexp_extract(address, '\\b\\d{5}(?:-\\d{4})?\\b', 0) AS zip_codeFROM addresses;
5.2 使用正则表达式处理JSON
虽然HiveSQL提供了专门的JSON处理函数,但有时使用正则表达式可能更灵活:
-- 从JSON字符串中提取特定字段
SELECTregexp_extract(json_column, '"name":\\s*"([^"]*)"', 1) AS name,regexp_extract(json_column, '"age":\\s*(\\d+)', 1) AS ageFROM json_table;
6. 正则表达式与窗口函数的结合
正则表达式可以与窗口函数结合,实现更复杂的分析:
-- 按域名分组,计算每个URL在其域名中的排名SELECTurl,domain,RANK() OVER (PARTITION BY domain ORDER BY visit_count DESC) AS rank_in_domainFROM (SELECTurl,regexp_extract(url, '^(https?://)?([^/]+)', 2) AS domain,COUNT(*) AS visit_countFROM web_logsGROUP BY url)
7. 使用UDF扩展正则表达式功能
当内置的正则表达式函数不足以满足需求时,可以创建自定义UDF (User-Defined Function):
8. 性能优化技巧
除了之前提到的性能考虑,还有一些额外的优化技巧:
缓存正则表达式: 如果在UDF中频繁使用相同的正则表达式,考虑将编译后的Pattern对象缓存。使用非捕获组: 当不需要捕获结果时,使用非捕获组 (?:...) 可以提高性能。避免贪婪匹配: 在可能的情况下,使用非贪婪匹配 *? 或 +? 来减少回溯。利用索引: 如果经常按照正则表达式的结果进行过滤或分组,考虑将结果存储并建立索引。
9. 实际应用案例
9.1 日志分析
-- 从日志中提取IP地址、时间戳和请求方法
SELECTregexp_extract(log_line, '^(\\S+)', 1) AS ip_address,regexp_extract(log_line, '\\[(.*?)\\]', 1) AS timestamp,regexp_extract(log_line, '"(\\S+)\\s+\\S+\\s+\\S+"', 1) AS http_methodFROM log_table;
9.2 文本分类
-- 基于文本内容进行简单的主题分类
SELECTtext,CASEWHEN regexp_like(LOWER(text), '\\b(stock|market|finance|economy)\\b') THEN 'Finance'WHEN regexp_like(LOWER(text), '\\b(health|medical|doctor|patient)\\b') THEN 'Healthcare'WHEN regexp_like(LOWER(text), '\\b(technology|software|hardware|internet)\\b') THEN 'Technology'ELSE 'Other'END AS category
FROM articles;10. 正则表达式在ETL过程中的应用
在Extract, Transform, Load (ETL)过程中,正则表达式可以发挥重要作用:
10.1 数据提取 (Extract)
-- 从非结构化文本中提取结构化数据
SELECTregexp_extract(raw_text, 'Name: (.*?), Age: (\\d+), Email: (\\S+@\\S+)', 1) AS name,regexp_extract(raw_text, 'Name: (.*?), Age: (\\d+), Email: (\\S+@\\S+)', 2) AS age,regexp_extract(raw_text, 'Name: (.*?), Age: (\\d+), Email: (\\S+@\\S+)', 3) AS email
FROM raw_data_table;10.2 数据转换 (Transform)
-- 标准化日期格式
SELECTCASEWHEN regexp_like(date_string, '^\\d{4}-\\d{2}-\\d{2}$') THEN date_stringWHEN regexp_like(date_string, '^\\d{2}/\\d{2}/\\d{4}$') THENregexp_replace(date_string, '^(\\d{2})/(\\d{2})/(\\d{4})$', '$3-$1-$2')ELSE NULLEND AS standardized_dateFROM dates_table;
10.3 数据加载前的验证 (Load)
-- 在加载数据之前验证格式
SELECT *FROM staging_tableWHEREregexp_like(email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}$')AND regexp_like(phone, '^\\+?\\d{10,14}$')AND regexp_like(zipcode, '^\\d{5}(-\\d{4})?$');
11 正则表达式性能调优
11.1 使用Explain计划
使用EXPLAIN命令来分析包含正则表达式的查询的执行计划:
EXPLAIN EXTENDEDSELECT *FROM large_tableWHERE regexp_like(complex_column, '(pattern1|pattern2|pattern3)');
分析执行计划可以帮助你理解正则表达式对查询性能的影响。
11.2 正则表达式优化技巧
使用锚点: 在可能的情况下,使用^和$锚点来限制匹配范围。避免过度使用通配符: 尽量使用更具体的字符类,而不是.通配符。使用原子分组: 使用(?>...)来防止不必要的回溯。利用possessive量词: 使用++、*+等possessive量词来减少回溯。
-- 优化前SELECT * FROM table WHERE regexp_like(column, '.*pattern.*');
-- 优化后SELECT * FROM table WHERE regexp_like(column, '^.*?pattern.*?$');
12. 正则表达式安全性考虑
在处理用户输入时,需要注意正则表达式的安全性:
避免ReDoS攻击: 某些正则表达式模式可能导致灾难性的回溯,造成所谓的正则表达式拒绝服务(ReDoS)攻击。
-- 潜在的不安全模式WHERE regexp_like(user_input, '(a+)+b');
-- 更安全的替代方案
WHERE regexp_like(user_input, 'a+b');限制正则表达式的复杂度: 对于用户定义的正则表达式,考虑实施复杂度限制或使用超时机制。
使用预定义的正则表达式: 对于常见的模式(如邮箱、URL等),使用经过验证的预定义正则表达式。
13. 正则表达式与机器学习的结合
正则表达式可以在机器学习管道中发挥作用,特别是在特征工程阶段:
-- 使用正则表达式创建特征SELECTtext,regexp_extract_all(LOWER(text), '\\b\\w+\\b') AS words,size(regexp_extract_all(LOWER(text), '\\b\\w+\\b')) AS word_count,size(regexp_extract_all(text, '[A-Z]\\w+')) AS capitalized_word_count,size(regexp_extract_all(text, '\\d+')) AS number_countFROM documents;
-- 这些特征可以用于后续的机器学习任务
14 正则表达式元字符总结
(1)特殊单字符

(2)空白符

(3)量词

(4)范围

(5)元字符小结

15 结论
正则表达式在SQL中是一个强大而versatile的工具,它不仅能够处理文本数据,还能在ETL流程、数据验证、特征工程等多个方面发挥重要作用。
然而,使用正则表达式需要在表达能力和性能之间找到平衡。
通过深入理解正则表达式的工作原理,结合HiveSQL的特性,并注意安全性考虑,我们可以更好地利用这一工具来解决复杂的数据处理问题。
掌握和灵活运用正则表达式是数据工程师和数据科学家的重要技能。
如果觉得本文对你有帮助,想进一步学习SQL语言这门艺术的,那么不妨也可以选择去看看我的博客专栏 ,部分内容如下:
数字化建设通关指南
专栏 原价99,现在活动价59.9,按照阶梯式增长,直到恢复原价。
专栏主要内容:
(1)SQL进阶实战技巧
可以参考如下教程,具体链接如下
SQL很简单,可你却写不好?也许这才是SQL最好的教程
上面链接中的文章及技巧会不定期更新。
(2)数仓建模实战技巧和个人心得
1)新人入职新公司后应如何快速了解业务?
2)以业务视角看宽表化建设?
3) 维度建模 or 关系型建模?
4)业务模型与数据模型有什么区别?业务阶段的模型该如何建设?
5)业务指标体系该如何建设?指标体系该如何维护?指标平台应如何建设?指标体系 该由谁来搭建?
6)如何优雅设计DWS层?DWS层模型好坏该如何评价?
7)指标发生异常,该如何排查?应从哪些方面入手寻找问题点?
8) 数据架构的选择,mpp or hadoop?
9)数仓团队应如何体现自己的业务价值,讲好数据故事?
10)BI与大数据有什么关系?BI与信息化、数字化之间有什么关系?BI与报表之间的关 系?
11)数据部门如何与业务部门沟通,并规划指引业务需求?
文章不限于以上内容,有新的想法也会及时更新到该专栏。
具体专栏链接如下:
数字化建设通关指南_莫叫石榴姐的博客-CSDN博客

相关文章:
SQL进阶技巧:SQL中的正则表达式应用?
目录 0 引言 1. 正则表达式函数 1.1 regexp_extract 1.2 regexp_replace 1.3 regexp_like 2. 在WHERE子句中使用正则表达式 3. 在GROUP BY中使用正则表达式 4. 性能考虑 5. 高级正则表达式技巧 5.1 使用正则表达式进行数据清洗 5.2 使用正则表达式处理JSON 6. 正则…...
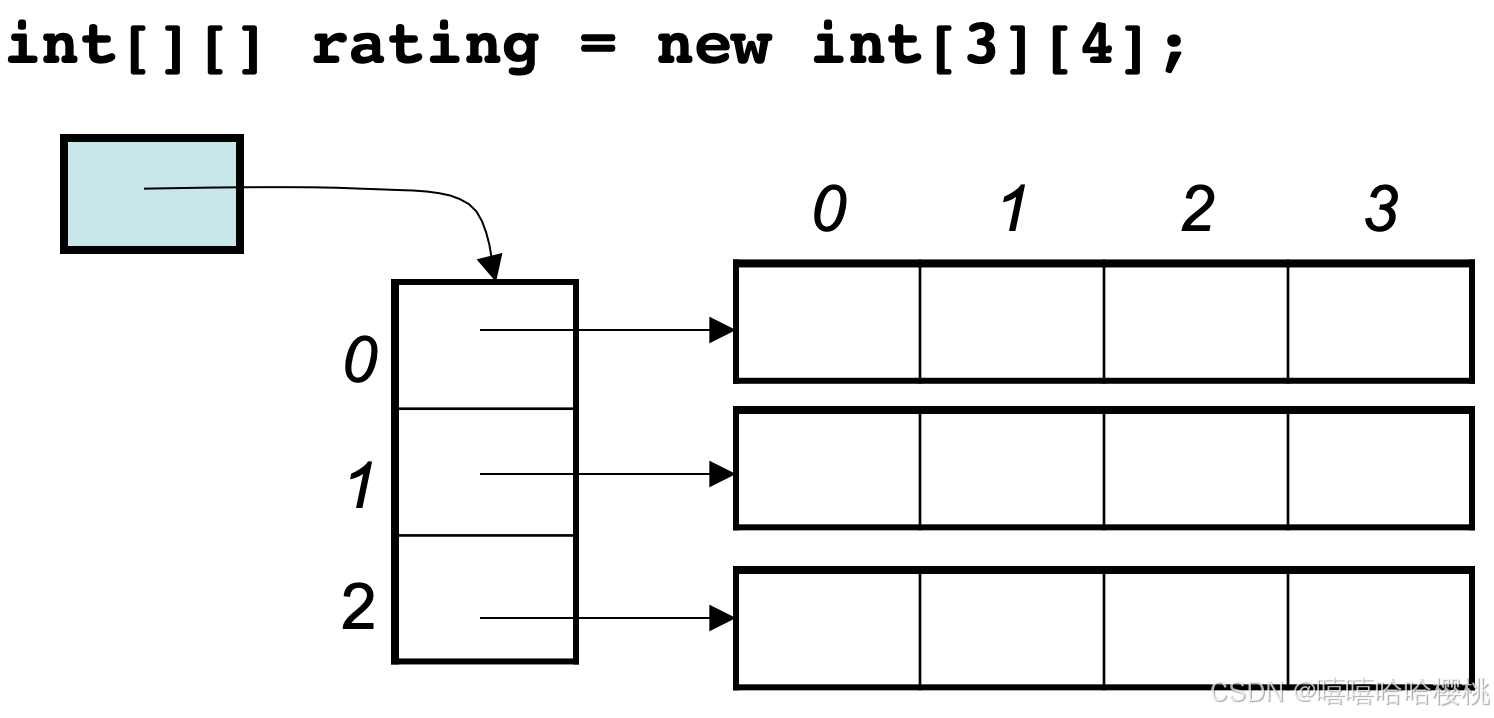
算法数组面试理论
数组是存放在连续内存空间内的相同类型数据的集合 (所以在删除添加元素的时候需要移动其他的元素的地址) 数组的元素是不能删除的,只能覆盖。(因为内存地址是连续的,所以不能删除。或者可以这么理解:在一…...

ASP.NET Zero是什么?适合哪些业务场景?
一、ASP.NET Zero是什么? ASP.NET Zero 是一个基于 ASP.NET Boilerplate (ABP) 框架的模板项目,它提供了预建的页面和强大的基础设施架构,以便开发者能够快速开发应用层。它的特点包括但不限于: 多合一解决方案:提供多…...
获取期货股票分钟级别数据以及均线策略
【数据获取】 银河金融数据库(yinhedata.com) 能够获取国内外金融股票、期货历史行情数据,包含各分钟级别。 【搭建策略】 均线策略作为一种广泛应用于股票、期货等市场的技术分析方法,凭借其简单易懂、操作性强等特点…...

入门篇-1 数据结构简介
数据结构简介 在计算机科学中,数据结构是指组织、存储和管理数据的方式,它使得数据可以被高效地访问和修改。数据结构是计算机程序设计和算法分析中的一个重要概念,因为它们直接影响到程序的执行效率和内存使用。 1. 什么是数据结构&#x…...

Anaconda安装
1.进入Anaconda官网 2.填写邮箱信息 3.在邮箱消息中获取下载链接 4.进入下载页面,选择合适版本下载 5.进入Anaconda安装界面 6.点击“I agree” 7.选择个人即可“Just Me” 8.选择文件安装路径 9.允许创建快捷方式 10.等待下载 11.完成安装...

Elasticsearch学习笔记(六)使用集群令牌将新加点加入集群
随着业务的增长,陆续会有新的节点需要加入集群。当我们在集群中的某个节点上使用命令生成令牌时会出现报错信息。 # 生成令牌 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node出现报错信息: Unable to create enrollment…...

项目建设方案,软件技术方案,整体技术方案,软件建设文档编制(word原件)
1 引言 1.1 编写目的 1.2 项目概述 1.3 名词解释 2 项目背景 3 业务分析 3.1 业务需求 3.2 业务需求分析与解决思路 3.3 数据需求分析【可选】 4 项目建设总体规划【可选】 4.1 系统定位【可选】 4.2 系统建设规划 5 建设目标 5.1 总体目标 5.2 分阶段目标【可选】 5.2.1 业务目…...

vue3定义组件
在Vue 3中,定义组件有多种方式,包括使用单文件组件(Single File Components, SFC)、使用JavaScript对象定义组件、以及使用组合式API(Composition API)。 1. 单文件组件(SFC) 这是…...

BOM常见操作方法汇总
BOM(Browser Object Model,浏览器对象模型)提供了与浏览器窗口交互的方法和属性。BOM 包括了许多对象,如 window、location、history、navigator 等,这些对象提供了与浏览器窗口相关的各种功能。 以下是一些常见的 BO…...

Python+whisper/vosk实现语音识别
目录 一、Whisper 1、Whisper介绍 2、安装Whisper 3、使用Whisper-base模型 4、使用Whisper-large-v3-turbo模型 二、vosk 1、Vosk介绍 2、vosk安装 3、使用vosk 三、总结 一、Whisper 1、Whisper介绍 Whisper 是一个由 OpenAI 开发的人工智能语音识别模型…...

如何在算家云搭建LivePortrait(视频生成)
一、LivePortrait简介 LivePortrait 是一个可控人像视频生成框架,能够准确、实时地将驱动视频的表情、姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果。 该项目的模型产生了定性肖像动画。只要输入一张静态的肖像图像,我们的模型…...

CSS 命名规范及 BEM 在前端开发中的实践
一:CSS命名规范的重要性 1、提高代码可读性 对于开发者自身来说,遵循规范的命名可以让你在日后回顾代码时,快速理解每个样式类的用途。例如,使用 “.header-logo” 这样的命名,一眼就能看出是头部的 logo 元素的样式,而不是一些无意义的命名如 “.box1”。当团队协作开发…...

SwiftUI 6.0(iOS 18)新增的网格渐变色 MeshGradient 解惑
概述 在 SwiftUI 中,我们可以借助渐变色(Gradient)来实现更加灵动多彩的着色效果。从 SwiftUI 6.0 开始,苹果增加了全新的网格渐变色让我们对其有了更自由的定制度。 因为 gif 格式图片自身的显示能力有限,所以上面的…...

【计算机网络】详谈TCP协议确认应答机制捎带应答机制超市重传机制连接管理机制流量管理机制滑动窗口拥塞控制延迟应答
一、TCP 协议段格式 1.1、4位首部长度 4位首部长度的基本单位是4字节,也就是说如果4位首部长度填6,那报头长度就是24字节。报头长度的取值范围为[0,60]字节,也就是说选项的最大长度为40字节。 二、确认应答机制 发送数据和发送应答&#x…...

rk3566开发之rknn npu 部署
目录 NPU使用 RKNN 模型 非 RKNN 模型 RKNN-Toolkit2工具 RKNN NPU 测试代码如下 main.cc ssd.cc 调用 ssd模型进行目标检测测试 ssd.h qt 中调用 rknn npu 接口 NPU使用 RK3566 内置 NPU 模块。使用该NPU需要下载RKNN SDK,RKNN SDK 为带有 NPU 的 RK3566/RK3568 芯片…...

项目生产经理需要具备哪些技能和素质
一、专业技能 1、技术知识 熟悉项目所涉及的工程领域专业知识,包括施工工艺、技术规范、质量标准等。能够准确理解设计图纸,指导施工人员进行正确的施工操作。掌握工程测量、材料检验、工程试验等基本技能,确保工程质量符合要求。 利用进度猫…...

Java数据类型常量
目录 一、数据类型 1.1分类 1.2关键字&内存占用&范围 1.3包装类 1.4说明 1.5类型转换 1.6类型提升 二、常量 2.1java中的常量 2.2定义常量 2.3分类 一、数据类型 1.1分类 1.2关键字&内存占用&范围 数据类型关键字内存占用范围字节型byte1字节-128…...

如何提高浮点类型计算的精度
把下面这篇文章的表达方式改成像正常的人类作者写的,而不是AI写的。 —————— 如何提高浮点类型计算的精度 在后端开发中,浮点数的计算一直一个常见难题,特别是在需要与GPU协作进行复杂计算时,浮点精度的偏差可能带来预期之…...

RabbitMQ简介及安装类
RabbitMQ概述-MQ介绍 RabbitMQ是一个开源的消息代理和队列服务器,它支持多种消息协议,并且可以轻松地与多种编程语言和框架集成。RabbitMQ是使用Erlang语言编写的,因此它具有高并发和高可用性的特点。以下是RabbitMQ的一些关键特性和概念 消息…...

NotebookLM概念关联分析终极对照表,覆盖12类典型文档结构,99.2%的关联断裂问题可秒级定位
更多请点击: https://intelliparadigm.com 第一章:NotebookLM概念关联分析 NotebookLM 是 Google 推出的基于用户自有文档构建可信 AI 助手的实验性工具,其核心能力在于对上传 PDF、TXT 等文本进行语义理解与跨文档概念链接。它并非通用大模…...

证件照换装API实战指南:一键换装,告别服装不合格!
还在为证件照服装不符合要求而烦恼?可立图ClipImg证件照换装API,自动识别身形与姿态,一键替换为正装,让你的照片瞬间专业起来!一、痛点场景:你的证件照是否也遇到过这些尴尬吗?求职简历…...

终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼
终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常需要在不同窗口间来回切换?是否觉得频…...

智能识别整理会议内容,让开会后怎么列待办更清晰更省事
作为经常跑客户、开会议的销售,此前我常被整理沟通内容、梳理待办的工作困扰,不仅耗时久,还容易漏记客户需求、搞错时间节点。结合大半年的实测体验,整理出一套AI整理方法,能快速清晰梳理待办,节省大量时间…...
)
第53节:倾斜模型osgb转3dtiles(免费工具)
1、下载cesiumlab工具 下载地址 2、启动cesiumlab,进行登录访问(网页版) 没有账号的可以用手机号注册一个 3、 选择倾斜模型切片 4、选择倾斜模型数据路径 5、设置空间参考、零点坐标 如果选择完osgb数据后能自动带出来则不用设置&…...

如何用QTTabBar彻底告别Windows资源管理器的混乱:一个完整的高效文件管理解决方案
如何用QTTabBar彻底告别Windows资源管理器的混乱:一个完整的高效文件管理解决方案 【免费下载链接】qttabbar QTTabBar is a small tool that allows you to use tab multi label function in Windows Explorer. https://www.yuque.com/indiff/qttabbar 项目地址:…...

系统级开发中的夜间MVP构建与Boneyard归档实践
1. 项目概述:一个名为“Boneyard”的夜间MVP构建最近在开源社区里,我注意到一个挺有意思的项目,叫sys-fairy-eve/nightly-mvp-2026-04-05-boneyard。光看这个标题,信息量就很大,它像是一个系统构建流水线上的一个特定快…...

Node.js调用Llama.cpp:本地部署大语言模型的完整指南
1. 项目概述:当Llama遇见Node.js如果你最近在折腾大语言模型(LLM)的本地部署,特别是对Meta的Llama系列模型情有独钟,同时又是一名Node.js开发者,那么你很可能已经听说过或者正在寻找一个像withcatai/node-l…...

DIY改造:为Hakko FX-901烙铁打造USB-C充电电池包
1. 项目概述:打造你的专属USB充电无线烙铁 如果你和我一样,经常需要带着烙铁跑现场——无论是调试RC模型、在Maker Faire上修复作品,还是在户外临时搭建一个电子装置——那你一定对传统无线烙铁的痛点深有体会。四节AA电池,用不了…...

企业内网开发环境通过Taotoken安全调用外部大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网开发环境通过Taotoken安全调用外部大模型API 对于许多企业开发团队而言,在内部研发流程中引入大模型能力已成为…...