llama3 implemented from scratch 笔记
github地址:https://github.com/naklecha/llama3-from-scratch?tab=readme-ov-file
分词器的实现
from pathlib import Path
import tiktoken
from tiktoken.load import load_tiktoken_bpe
import torch
import json
import matplotlib.pyplot as plttokenizer_path = "Meta-Llama-3-8B/tokenizer.model"
special_tokens = ["<|begin_of_text|>","<|end_of_text|>","<|reserved_special_token_0|>","<|reserved_special_token_1|>","<|reserved_special_token_2|>","<|reserved_special_token_3|>","<|start_header_id|>","<|end_header_id|>","<|reserved_special_token_4|>","<|eot_id|>", # end of turn] + [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)]
mergeable_ranks = load_tiktoken_bpe(tokenizer_path)
tokenizer = tiktoken.Encoding(name=Path(tokenizer_path).name,pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",mergeable_ranks=mergeable_ranks,special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},
)tokenizer.decode(tokenizer.encode("hello world!"))
读取模型文件
model = torch.load("Meta-Llama-3-8B/consolidated.00.pth")
print(json.dumps(list(model.keys())[:20], indent=4))
["tok_embeddings.weight","layers.0.attention.wq.weight","layers.0.attention.wk.weight","layers.0.attention.wv.weight","layers.0.attention.wo.weight","layers.0.feed_forward.w1.weight","layers.0.feed_forward.w3.weight","layers.0.feed_forward.w2.weight","layers.0.attention_norm.weight","layers.0.ffn_norm.weight","layers.1.attention.wq.weight","layers.1.attention.wk.weight","layers.1.attention.wv.weight","layers.1.attention.wo.weight","layers.1.feed_forward.w1.weight","layers.1.feed_forward.w3.weight","layers.1.feed_forward.w2.weight","layers.1.attention_norm.weight","layers.1.ffn_norm.weight","layers.2.attention.wq.weight"
]
with open("Meta-Llama-3-8B/params.json", "r") as f:config = json.load(f)
config
{'dim': 4096,'n_layers': 32,'n_heads': 32,'n_kv_heads': 8,'vocab_size': 128256,'multiple_of': 1024,'ffn_dim_multiplier': 1.3,'norm_eps': 1e-05,'rope_theta': 500000.0}
dim = config["dim"]
n_layers = config["n_layers"]
n_heads = config["n_heads"]
n_kv_heads = config["n_kv_heads"]
vocab_size = config["vocab_size"]
multiple_of = config["multiple_of"]
ffn_dim_multiplier = config["ffn_dim_multiplier"]
norm_eps = config["norm_eps"]
rope_theta = torch.tensor(config["rope_theta"])
将文本转换为 tokens(这里没有手动实现分词器)
这里用 tiktoken 作为 tokenizer
prompt = "the answer to the ultimate question of life, the universe, and everything is "
tokens = [128000] + tokenizer.encode(prompt)
print(tokens)
tokens = torch.tensor(tokens)
prompt_split_as_tokens = [tokenizer.decode([token.item()]) for token in tokens]
print(prompt_split_as_tokens)
[128000, 1820, 4320, 311, 279, 17139, 3488, 315, 2324, 11, 279, 15861, 11, 323, 4395, 374, 220]
['<|begin_of_text|>', 'the', ' answer', ' to', ' the', ' ultimate', ' question', ' of', ' life', ',', ' the', ' universe', ',', ' and', ' everything', ' is', ' ']
将令牌嵌入(这里用的内置的神经网络模块,也没有手动实现)
总之,[17, 1]的 tokens 现在变成了 [17, 4096]的嵌入向量

embedding_layer = torch.nn.Embedding(vocab_size, dim)
embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])
token_embeddings_unnormalized = embedding_layer(tokens).to(torch.bfloat16)
token_embeddings_unnormalized.shape
torch.Size([17, 4096])
使用均方根 RMS 对嵌入进行归一化
这里并不会进行形状的改变,值只是进行了归一化,为了防止除以零的情况,会设置一个 norm_eps。

# def rms_norm(tensor, norm_weights):
# rms = (tensor.pow(2).mean(-1, keepdim=True) + norm_eps)**0.5
# return tensor * (norm_weights / rms)
def rms_norm(tensor, norm_weights):return (tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + norm_eps)) * norm_weights
tensor.pow(2):
这一步将输入张量 tensor 中的每个元素进行平方操作。假设 tensor 的形状为 (batch_size, seq_len, hidden_dim),那么 tensor.pow(2) 的结果形状仍然是 (batch_size, seq_len, hidden_dim),但每个元素都被平方了。
tensor.pow(2).mean(-1, keepdim=True):
这一步计算张量在最后一个维度(即 hidden_dim 维度)上的均值。mean(-1, keepdim=True) 表示在最后一个维度上求均值,并且保持该维度的形状(即 keepdim=True)。结果的形状为 (batch_size, seq_len, 1)。
tensor.pow(2).mean(-1, keepdim=True) + norm_eps:
这一步在均值的基础上加上一个小的常数 norm_eps,以避免除零错误。norm_eps 通常是一个非常小的正数,例如 1e-8。
torch.rsqrt(...):
torch.rsqrt 是平方根的倒数(即 1 / sqrt(x))。这一步计算的是 1 / sqrt(mean + norm_eps),即 RMS 值的倒数。
tensor * torch.rsqrt(...):
这一步将输入张量 tensor 乘以 RMS 值的倒数,从而实现归一化。归一化后的张量在最后一个维度上的 RMS 值为1。
* norm_weights:
最后,将归一化后的张量乘以 norm_weights。norm_weights 是一个可学习的权重张量,形状为 (hidden_dim,),用于对归一化后的特征进行缩放。
通常,归一化操作会将特征缩放到一个固定的范围,然而,不同的特征可能需要不同的缩放因子来更好地适应模型的需求。通过引入可学习的权重,模型可以根据数据的特点和任务的需求,自动调整每个特征的缩放因子。
构建 transformer 的第一层

归一化
# 这里是attention之前的normalization
token_embeddings = rms_norm(token_embeddings_unnormalized, model["layers.0.attention_norm.weight"])
token_embeddings.shape
torch.Size([17, 4096])
手动实现注意力

从模型中加载查询(query)、键(key)、值(value)和输出(output)向量时,我们注意到它们的形状分别是 [4096x4096]、[1024x4096]、[1024x4096]、[4096x4096]。
假设我们有以下形状的矩阵:
query_matrix: [4096x4096]
key_matrix: [1024x4096]
value_matrix: [1024x4096]
output_matrix: [4096x4096]
我们可以通过以下方式解开它们:
解开查询
q_layer0 = model["layers.0.attention.wq.weight"]
head_dim = q_layer0.shape[0] // n_heads
q_layer0 = q_layer0.view(n_heads, head_dim, dim)
q_layer0.shape
torch.Size([32, 128, 4096])
32 是 llama3 的注意力头的数量,128 是查询向量的大小,4096 是令牌嵌入的大小。
实现第一层的第一个头
查询权重矩阵的大小是 [128, 4096]
q_layer0_head0 = q_layer0[0]
q_layer0_head0.shape
torch.Size([128, 4096])
现在将查询权重矩阵和令牌嵌入相乘,以接收对令牌的查询

最终的形状是 [17, 128],这是因为有 17 个令牌,和 128 长度的查询。
q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T)
q_per_token.shape
torch.Size([17, 128])
位置编码
当前阶段是,我们为提示(prompt)中的每个令牌都有一个查询向量,但是单独的查询向量并不知道它在提示中的位置,在例子中,使用了三次 “the” 标记的查询向量([1, 128])。使用 RoPE 旋转位置编码来执行这些旋转。

q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)
q_per_token_split_into_pairs.shape
torch.Size([17, 64, 2])
这一步将查询向量分成对,并对每对应用旋转角度偏移。

用复数的点积来旋转向量
# 生成一个从0到1的等间隔序列,分成64个部分。这个序列表示每个部分的归一化位置
zero_to_one_split_into_64_parts = torch.tensor(range(64))/64
# 计算频率freqs,这里的rope_theta是llama3给的500000.0
freqs = 1.0 / (rope_theta ** zero_to_one_split_into_64_parts)# 生成一个 [17, 64] 的矩阵,其中每一行对应一个标记的频率。torch.outer函数计算两个向量的外积,生成一个矩阵
freqs_for_each_token = torch.outer(torch.arange(17), freqs)
# 将频率转换为复数形式,其中实部为1,虚部为频率。torch.polar函数生成复数形式的向量,其中模为1,相位为频率
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
freqs_cis.shape
等间隔序列 zero_to_one_split_into_64_parts:
tensor([0.0000, 0.0156, 0.0312, 0.0469, 0.0625, 0.0781, 0.0938, 0.1094, 0.1250,0.1406, 0.1562, 0.1719, 0.1875, 0.2031, 0.2188, 0.2344, 0.2500, 0.2656,0.2812, 0.2969, 0.3125, 0.3281, 0.3438, 0.3594, 0.3750, 0.3906, 0.4062,0.4219, 0.4375, 0.4531, 0.4688, 0.4844, 0.5000, 0.5156, 0.5312, 0.5469,0.5625, 0.5781, 0.5938, 0.6094, 0.6250, 0.6406, 0.6562, 0.6719, 0.6875,0.7031, 0.7188, 0.7344, 0.7500, 0.7656, 0.7812, 0.7969, 0.8125, 0.8281,0.8438, 0.8594, 0.8750, 0.8906, 0.9062, 0.9219, 0.9375, 0.9531, 0.9688,0.9844])
频率:
tensor([1.0000e+00, 8.1462e-01, 6.6360e-01, 5.4058e-01, 4.4037e-01, 3.5873e-01,2.9223e-01, 2.3805e-01, 1.9392e-01, 1.5797e-01, 1.2869e-01, 1.0483e-01,8.5397e-02, 6.9566e-02, 5.6670e-02, 4.6164e-02, 3.7606e-02, 3.0635e-02,2.4955e-02, 2.0329e-02, 1.6560e-02, 1.3490e-02, 1.0990e-02, 8.9523e-03,7.2927e-03, 5.9407e-03, 4.8394e-03, 3.9423e-03, 3.2114e-03, 2.6161e-03,2.1311e-03, 1.7360e-03, 1.4142e-03, 1.1520e-03, 9.3847e-04, 7.6450e-04,6.2277e-04, 5.0732e-04, 4.1327e-04, 3.3666e-04, 2.7425e-04, 2.2341e-04,1.8199e-04, 1.4825e-04, 1.2077e-04, 9.8381e-05, 8.0143e-05, 6.5286e-05,5.3183e-05, 4.3324e-05, 3.5292e-05, 2.8750e-05, 2.3420e-05, 1.9078e-05,1.5542e-05, 1.2660e-05, 1.0313e-05, 8.4015e-06, 6.8440e-06, 5.5752e-06,4.5417e-06, 3.6997e-06, 3.0139e-06, 2.4551e-06])
z = r ⋅ e i θ z=r \cdot e^{i \theta} z=r⋅eiθ表示一个旋转角度为 θ \theta θ的复数
旋转矩阵中的每一个元素freqs_cis[i,j]可以表示为 e i ⋅ f r e q s _ f o r _ e a c h _ t o k e n [ i , j ] e ^{i⋅{freqs\_for\_each\_token[i,j]}} ei⋅freqs_for_each_token[i,j],其中 i i i是标记的索引, j j j是频率的索引。
这就是所有 token 对应的旋转矩阵,下面进行相乘得到旋转后的所有 token
的查询
现在我们有了每个 token 查询的复数(角度变化向量)
我们可以将我们的查询转换为复数然后进行点积以根据位置旋转查询。
q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)
q_per_token_as_complex_numbers.shape
torch.Size([17, 64])
q_per_token_as_complex_numbers_rotated = q_per_token_as_complex_numbers * freqs_cis
q_per_token_as_complex_numbers_rotated.shape
torch.Size([17, 64])
这样就是旋转后的查询。
得到旋转后的向量之后
通过将查询再次从复数看成实数(从[a+bj]的存储形式变成[a, b]),可以得到
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers_rotated)
q_per_token_split_into_pairs_rotated.shape
torch.Size([17, 64, 2])
旋转后的对现在已经合并,我们现在有了一个新的查询向量,其形状是[17, 128]。
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
q_per_token_rotated.shape
torch.Size([17, 128])
键,几乎和查询的处理是一样的
键也生成维度为 128 的键向量。键的权重数量只有查询(queries)的 1/4,这是因为键的权重在 4 个注意力头之间共享,以减少所需的计算量。键也像查询一样旋转以添加位置信息,因为同样的原因。
k_layer0 = model["layers.0.attention.wk.weight"]
k_layer0 = k_layer0.view(n_kv_heads, k_layer0.shape[0] // n_kv_heads, dim)
k_layer0.shape
torch.Size([8, 128, 4096])
k_layer0_head0 = k_layer0[0]
k_layer0_head0.shape
torch.Size([128, 4096])
k_per_token = torch.matmul(token_embeddings, k_layer0_head0.T)
k_per_token.shape
torch.Size([17, 128])
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)
k_per_token_split_into_pairs.shape
torch.Size([17, 64, 2])
k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)
k_per_token_as_complex_numbers.shape
torch.Size([17, 64])
k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis)
k_per_token_split_into_pairs_rotated.shape
torch.Size([17, 64, 2])
k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
k_per_token_rotated.shape
torch.Size([17, 128])
在这个阶段,现在有每个令牌的查询和键的旋转值

下一步,把查询和键相乘
这样做会给我们一个分数,将每个标记与其他标记进行映射。这个分数描述了每个标记的查询与每个标记的键之间的关系。这就是自注意力机制(Self-Attention)😃
注意力分数矩阵(qk_per_token)的形状为 [17x17],其中 17 是提示中的标记数量。
详细解释
在自注意力机制中,我们通过计算查询(queries)和键(keys)之间的点积来生成注意力分数。注意力分数矩阵描述了每个标记与其他标记之间的关系。

qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(head_dim)**0.5
qk_per_token.shape
torch.Size([17, 17])
现在我们必须 mask 查询键分数
在训练过程中,Llama3 的未来标记的 qk 分数被掩码。
为什么?因为在训练过程中,我们只使用过去的标记来预测未来的标记。
因此,在推理过程中,我们将未来的标记设置为零。

# 显示注意力分数矩阵的热力图
def display_qk_heatmap(qk_per_token):_, ax = plt.subplots()# 生成热力图,使用 `viridis` 颜色映射im = ax.imshow(qk_per_token.to(float).detach(), cmap='viridis')ax.set_xticks(range(len(prompt_split_as_tokens)))ax.set_yticks(range(len(prompt_split_as_tokens)))ax.set_xticklabels(prompt_split_as_tokens)ax.set_yticklabels(prompt_split_as_tokens)ax.figure.colorbar(im, ax=ax)display_qk_heatmap(qk_per_token)

# 生成一个掩码矩阵, 初始都为-inf
mask = torch.full((len(tokens), len(tokens)), float("-inf"), device=tokens.device)
# 将掩码矩阵转换为上三角矩阵,diagonal=1保留对角线下一个元素及其以上的元素,其余为0
mask = torch.triu(mask, diagonal=1)
mask
tensor([[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
qk_per_token_after_masking = qk_per_token + mask
display_qk_heatmap(qk_per_token_after_masking)

qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
display_qk_heatmap(qk_per_token_after_masking_after_softmax)
Values

值权重在每 4 个注意力头(所以总共 8 个注意力头)之间共享,以节省计算量。这意味着每个注意力头使用相同的值权重矩阵。
v_layer0 = model["layers.0.attention.wv.weight"]
v_layer0 = v_layer0.view(n_kv_heads, v_layer0.shape[0] // n_kv_heads, dim)
v_layer0.shape
torch.Size([8, 128, 4096])
第一层, 第一个权重矩阵为:
v_layer0_head0 = v_layer0[0]
v_layer0_head0.shape
torch.Size([128, 4096])
值向量

我们现在使用值权重来获取每个标记的注意力值,其大小为 [17x128],其中 17 是提示中的标记数量,128 是每个标记的值向量的维度。
v_per_token = torch.matmul(token_embeddings, v_layer0_head0.T)
v_per_token.shape
torch.Size([17, 128])
注意力
在自注意力机制中,我们将注意力分数矩阵与值矩阵相乘,生成最终的注意力输出。注意力输出的形状为 [17x128]
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
qkv_attention.shape
torch.Size([17, 128])
多头注意力

我们现在有了第一层和第一个注意力头的注意力值。现在,我将运行一个循环,对第一层的每个注意力头执行与上述单元格相同的数学运算。
qkv_attention_store = []for head in range(n_heads):q_layer0_head = q_layer0[head]k_layer0_head = k_layer0[head//4] # key weights are shared across 4 headsv_layer0_head = v_layer0[head//4] # value weights are shared across 4 headsq_per_token = torch.matmul(token_embeddings, q_layer0_head.T)k_per_token = torch.matmul(token_embeddings, k_layer0_head.T)v_per_token = torch.matmul(token_embeddings, v_layer0_head.T)q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis[:len(tokens)])q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis[:len(tokens)])k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5mask = torch.full((len(tokens), len(tokens)), float("-inf"), device=tokens.device)mask = torch.triu(mask, diagonal=1)qk_per_token_after_masking = qk_per_token + maskqk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)qkv_attention_store.append(qkv_attention)len(qkv_attention_store)
32

我们现在有了第一层所有 32 个注意力头的 qkv_attention 矩阵。接下来,把所有注意力分数合并成一个大小为 [17x4096] 的大矩阵。
stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)
stacked_qkv_attention.shape
torch.Size([17, 4096])
权矩阵,最后一个步骤

w_layer0 = model["layers.0.attention.wo.weight"]
w_layer0.shape
在完成第 0 层注意力机制的最后一步是,将注意力输出与权重矩阵相乘。具体来说,我们将最终的注意力输出矩阵与权重矩阵相乘,生成最终的注意力输出。
torch.Size([4096, 4096])
这是一个简单的线性层,所以我们只需要进行矩阵乘法(matmul)。
embedding_delta = torch.matmul(stacked_qkv_attention, w_layer0.T)
embedding_delta.shape
torch.Size([17, 4096])
我们现在有了注意力机制之后的嵌入值变化,这应该加到原始的标记嵌入值上。
embedding_after_edit = token_embeddings_unnormalized + embedding_delta
embedding_after_edit.shape
torch.Size([17, 4096])
我们将其归一化然后运行一个前馈神经网络通过嵌入 δ \delta δ

embedding_after_edit_normalized = rms_norm(embedding_after_edit, model["layers.0.ffn_norm.weight"])
embedding_after_edit_normalized.shape
torch.Size([17, 4096])
在加载前馈网络(Feed-Forward Network, FFN)的权重并实现前馈网络时,我们需要执行以下步骤:

在 Llama3 中,他们使用了 SwiGLU 前馈网络。这种网络架构在模型需要时能够很好地添加非线性。如今,在大型语言模型(LLMs)中使用这种前馈网络架构是非常标准的。
w1 = model["layers.0.feed_forward.w1.weight"]
w2 = model["layers.0.feed_forward.w2.weight"]
w3 = model["layers.0.feed_forward.w3.weight"]
output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T)) * torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)
output_after_feedforward.shape
torch.Size([17, 4096])
在 Llama3 中,前馈网络使用了 SwiGLU 架构。具体来说,前馈网络由三个线性层组成,其中第一个线性层的输出通过 Swish 激活函数,然后与第三个线性层的输出相乘,最后通过第二个线性层生成新的嵌入值。
Swish 激活函数:
Swish 激活函数是一种平滑的非线性函数,定义为:
S w i s h ( x ) = x ⋅ σ ( β x ) Swish(x)=x\cdot \sigma(\beta x) Swish(x)=x⋅σ(βx)
其中, σ \sigma σ 是 sigmoid 函数, β \beta β 是一个可学习的参数(通常设为 1). Swish 激活函数在许多情况下表现优于 ReLU 和其他常见的激活函数.
GLU (Gated Linear Unit):
GLU 是一种门控机制,用于控制信息的流动。GLU 的定义为:
G L U ( a , b ) = a ⋅ σ ( b ) GLU(a, b)=a\cdot \sigma(b) GLU(a,b)=a⋅σ(b)
其中, a a a 和 b b b 是两个线性变换的输出, σ \sigma σ是 sigmoid 函数. GLU 通过门控信号 σ ( b ) \sigma(b) σ(b)来控制 a a a 的信息流动.
SwiGLU 结构:
SwiGLU 结合了 Swish 激活函数和 GLU 结构,定义为:
S w i G L U ( x , W 1 , W 2 , W 3 ) = S w i s h ( x W 1 ) ⋅ σ ( x W 3 ) W 2 SwiGLU(x, W_1, W_2, W_3)=Swish(xW_1)\cdot \sigma(xW_3)W_2 SwiGLU(x,W1,W2,W3)=Swish(xW1)⋅σ(xW3)W2
我们终于在第一层之后为每个标记生成了新的编辑后的嵌入值。
在自注意力机制和前馈网络之后,我们为每个标记生成了新的嵌入值。这些新的嵌入值包含了更多的上下文信息,从而提高了模型的性能和理解能力。
在完成之前,我们还有 31 层要处理(只需要一个循环)。
你可以想象这个编辑后的嵌入值包含了第一层中所有查询的信息。现在,每一层都会对提出的问题进行越来越复杂的编码,直到我们有一个嵌入值,它包含了我们需要了解的关于下一个标记的所有信息。
layer_0_embedding = embedding_after_edit+output_after_feedforward
layer_0_embedding.shape
torch.Size([17, 4096])
总和
final_embedding = token_embeddings_unnormalized
for layer in range(n_layers):qkv_attention_store = []layer_embedding_norm = rms_norm(final_embedding, model[f"layers.{layer}.attention_norm.weight"])q_layer = model[f"layers.{layer}.attention.wq.weight"]q_layer = q_layer.view(n_heads, q_layer.shape[0] // n_heads, dim)k_layer = model[f"layers.{layer}.attention.wk.weight"]k_layer = k_layer.view(n_kv_heads, k_layer.shape[0] // n_kv_heads, dim)v_layer = model[f"layers.{layer}.attention.wv.weight"]v_layer = v_layer.view(n_kv_heads, v_layer.shape[0] // n_kv_heads, dim)w_layer = model[f"layers.{layer}.attention.wo.weight"]for head in range(n_heads):q_layer_head = q_layer[head]k_layer_head = k_layer[head//4]v_layer_head = v_layer[head//4]q_per_token = torch.matmul(layer_embedding_norm, q_layer_head.T)k_per_token = torch.matmul(layer_embedding_norm, k_layer_head.T)v_per_token = torch.matmul(layer_embedding_norm, v_layer_head.T)q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis)q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis)k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5mask = torch.full((len(token_embeddings_unnormalized), len(token_embeddings_unnormalized)), float("-inf"))mask = torch.triu(mask, diagonal=1)qk_per_token_after_masking = qk_per_token + maskqk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)qkv_attention_store.append(qkv_attention)stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)w_layer = model[f"layers.{layer}.attention.wo.weight"]embedding_delta = torch.matmul(stacked_qkv_attention, w_layer.T)embedding_after_edit = final_embedding + embedding_deltaembedding_after_edit_normalized = rms_norm(embedding_after_edit, model[f"layers.{layer}.ffn_norm.weight"])w1 = model[f"layers.{layer}.feed_forward.w1.weight"]w2 = model[f"layers.{layer}.feed_forward.w2.weight"]w3 = model[f"layers.{layer}.feed_forward.w3.weight"]output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T)) * torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)final_embedding = embedding_after_edit+output_after_feedforward
现在我们有了最终的嵌入, 这是模型对下一个令牌的最好猜测
嵌入的形状和常规令牌的形状相同 [ 17 , 4096 ] [17, 4096] [17,4096].

final_embedding = rms_norm(final_embedding, model["norm.weight"])
final_embedding.shape
torch.Size([17, 4096])
最后, 将嵌入解码成令牌值

我们将使用输出解码器将最终嵌入解码成令牌
model["output.weight"].shape
torch.Size([128256, 4096])
我们使用最后一个标记的嵌入值来预测下一个值。
根据《银河系漫游指南》这本书,42 是“生命、宇宙以及一切的终极问题的答案”。所以大多数 LLMs 在这里都会回答 42.
# 通过线性层生成 logits 向量, 训练过程中隐式调用了 softmax
logits = torch.matmul(final_embedding[-1], model["output.weight"].T)
logits.shape
torch.Size([128256])
预测的 token number 是 2983, 解码后是 42
next_token = torch.argmax(logits, dim=-1)
next_token
tensor(2983)
tokenizer.decode([next_token.item()])
'42'
相关文章:
llama3 implemented from scratch 笔记
github地址:https://github.com/naklecha/llama3-from-scratch?tabreadme-ov-file 分词器的实现 from pathlib import Path import tiktoken from tiktoken.load import load_tiktoken_bpe import torch import json import matplotlib.pyplot as plttokenizer_p…...
照片在线转成二维码展示,更方便分享图片的好办法
怎么能把照片生成二维码后,分享给其他人展示呢?现在很多人为了能够更方便的将自己的图片展现给其他人会使用生成二维码的方式,将图片存储到云空间,通过扫码调取图片查看内容。与其他方式相比,这样会更加的方便…...
『网络游戏』登陆协议制定客户端发送账号密码CMD【19】
修改服务器脚本:ServerSession 修改服务器脚本:GameMsg 修改客户端脚本:ClientSession.cs 修改客户端脚本:NetSvc.cs 修改客户端脚本:WindowRoot.cs 修改客户端脚本:SystemRoot.cs 修改客户端脚本ÿ…...

独享动态IP是什么?它有什么独特优势吗?
在网络世界中,IP地址扮演着连接互联网的关键角色。随着互联网的发展,不同类型的IP地址也应运而生,其中独享动态ip作为一种新型IP地址,备受关注。本文将围绕它的定义及其独特优势展开探讨,以帮助读者更好地理解和利用这…...

gaussdb hccdp认证模拟题(单选)
1.在GaussDB逻辑架构中,由以下选项中的哪一个组件来负责提供集群日常运维、配置管理的管理接口、工具?(1 分) A. CN B. DN C. GTM D. OM --D 2.在以下命令中,使用以下哪一个选项中的命令可以以自定义归档形式导出表t1的定义…...
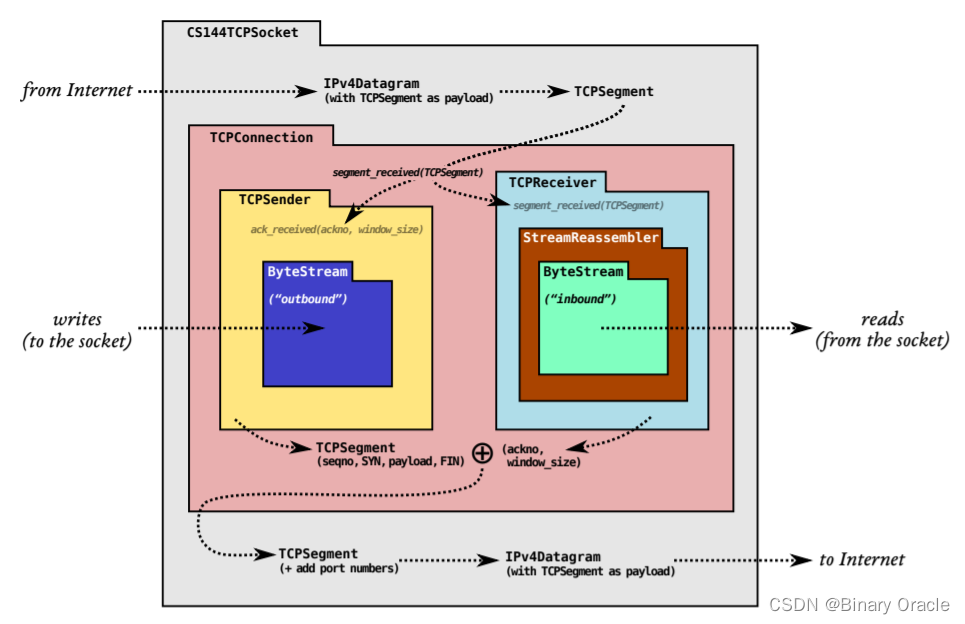
【斯坦福CS144】Lab1
一、实验目的 1.实现一个流重组器——一个将字节流的小块 (称为子串或段 )按正确顺序组装成连续的字节流的模块; 2.深入理解 TCP 协议的工作方式。 二、实验内容 编写一个名为"StreamReassembler"的数据结构,它负责…...

药箱里的药及其常见药的作用
药箱里有常备药,经常买药,但是忘了自己有什么药。容易之间弄混,以此作为更新存储的媒介。 1、阿莫西林胶囊 处方药 是指需要由医师或者医疗人员开局处方才能购买的药物(常见的OTC是非处方药的意思)。 截止时间 2024 10/10 药品资料汇总&am…...
)
Android屏幕旋转流程(2)
(1)疑问 (1)settings put system user_rotation 1是什么意思? 答:设置用户期望的屏幕转向,0代表:Surface.ROTATION_0竖屏;1代表:Surface.ROTATION_90横屏&a…...

gaussdb hccdp认证模拟题(判断)
1.在事务ACID特性中,原子性指的是事务必须始终保持系统处于一致的状态。(1 分) 错。 2.某IT公司在开发软件时,需要使用GaussDB数据库,因此需要实现软件和数据的链接,而DBeaver是一个通用的数据库管理工具和 SQL 客户端ÿ…...

高效架构设计:JPA 实现单据管理,MyBatis 赋能报表查询的最佳实践
在现代企业应用开发中,数据持久层的设计与实现是至关重要的部分。开发者常常会面临选择如何合理地使用不同的数据访问框架,以最大限度地提升系统性能和开发效率。本文将讨论一种有效的搭配方案:使用 JPA 处理单据的增删改查操作,使…...

深入理解 CSS 浮动(Float):详尽指南
“批判他人总是想的太简单 剖析自己总是想的太困难” 文章目录 前言文章有误敬请斧正 不胜感恩!目录1. 什么是 CSS 浮动?2. CSS 浮动的历史背景3. 基本用法float 属性值浮动元素的行为 4. 浮动对文档流的影响5. 清除浮动clear 属性清除浮动的技巧1. 使用…...

ElasticSearch学习笔记(三)Ubuntu 2204 server elasticsearch集群配置
如果你只是学习elasticsearch的增、删、改、查等相关操作,那么在windows上安装一个ES就可以了。但是你如果想在你的生产环境中使用Elasticsearch提供的强大的功能,那么还是建议你使用Linux操作系统。 本文以在Ubuntu 2204 server中安装elasticsearch 8.…...

基于STM32的简易交通灯proteus仿真设计(仿真+程序+设计报告+讲解视频)
基于STM32的简易交通灯proteus仿真设计(仿真程序设计报告讲解视频) 仿真图proteus 8.9 程序编译器:keil 5 编程语言:C语言 设计编号:C0091 **1.**主要功能 功能说明: 以STM32单片机和数码管、LED灯设计简易交通…...

linux下新增加一块sata硬盘并使用
1)确认新硬盘能被正确识别到 2)对新硬盘进行分区 说明:fdisk指令中输入“m”,可以看到详细的指令含义。 3)确认新创建的分区 5)格式化新创建的分区 6)挂载新分区并使用...

主从复制遇到的问题点
1.解决主从复制的配置问题 大致逻辑: 主库: 进入mysql的my.in文件,配置 server-id 1 log-bin mysql-bin log-bin D:/mysql/log binlog-do-db 数据库名 从库 进入mysql的my.in文件,配置 server-id 2 replicate-do-db 数据库名…...

Macbook ToDesk 无法连接网络
描述 网络连接的是 Wi-Fi,打开浏览器能跟正常浏览内容,说明 Wi-Fi 是正常的。 现象:显示网络连接失败,一直无法登陆! 检查防火墙是没有阻止ToDesk 的任何连接,说明防火墙也是正常的。 解决 检查登录项&a…...

C++-容器适配器- stack、queue、priority_queue和仿函数
目录 1.什么是适配器 2.deque 1.简单了解结构 2.deque的缺陷 3.为什么选择deque作为stack和queue的底层默认容器 3.stack(栈) 4.queue(队列) 5.仿函数 6.priority_queue(优先级队列)(堆…...

C++游戏开发指南
C游戏开发指南 引言 在这个数字娱乐时代,游戏行业炙手可热,你是否也憧憬着能亲自开发出一款独特的游戏呢?你是否想过,为什么越来越多的开发者选择C作为他们的开发语言?没错,C不仅是一种高效的编程语言&am…...

k8s的pod管理及优化
资源管理介绍 资源管理方式 命令式对象管理:直接用命令去操作kubernetes资源 命令式对象配置:通过命令配置和配置文件去操作kubernets资源 声明式对象配置:通过apply命令和配置文件去操作kubernets资源 命令式对象管理: 资源类…...

HTML 常用的块级元素和行内元素
1. 常用的块级元素 块级元素具有如下特点: 占据父容器的整行宽度。通常从新的一行开始。可以包含其他块级元素和行内元素。 常用的块级元素: div:通用的容器,用于布局和分块内容。 h1 到 h6:标题标签,定义…...

避开这3个坑,你的STM32F103+LoRa+阿里云项目才能跑得稳
STM32F103LoRa阿里云物联网项目稳定性优化实战指南 在物联网设备开发中,稳定性往往是区分业余原型与工业级产品的关键分水岭。许多开发者能够快速搭建起STM32F103与LoRa模块的基础通信框架,并实现阿里云物联网平台的数据上传,却在长期运行中频…...
)
WRF-CHEM模拟翻车?可能是你的namelist.chem没设对(附MEIC数据实战配置清单)
WRF-CHEM模拟异常排查指南:MEIC数据与namelist.chem的深度适配 当WRF-CHEM模拟结果出现异常时,很多用户会第一时间怀疑MEIC数据处理环节的问题,但实际上,namelist.chem参数与MEIC特性的匹配度才是更隐蔽的关键因素。本文将带您深入…...

掌握ComfyUI视频处理:5步构建高效AI视频工作流
掌握ComfyUI视频处理:5步构建高效AI视频工作流 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI视频创作和内容制作领域,ComfyUI-Video…...

5分钟上手biliTickerBuy:开源B站会员购抢票自动化工具终极指南
5分钟上手biliTickerBuy:开源B站会员购抢票自动化工具终极指南 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy biliTickerBuy是一款开源免费的B站会员购辅助工具,专为技…...

命令行AI工具gemini-cli:无缝集成Gemini大模型提升终端效率
1. 项目概述:一个与AI对话的命令行工具 如果你和我一样,大部分工作时间都泡在终端里,那么 eliben/gemini-cli 这个项目可能会让你眼前一亮。简单来说,它是一个让你能在命令行里直接与 Google 的 Gemini 大模型对话的工具。你不…...

Habitat-Lab:Meta开源具身AI仿真平台,从零搭建智能体训练场
1. 项目概述:从虚拟到现实的智能体训练场如果你对机器人、具身智能或者强化学习感兴趣,那么“Habitat-Lab”这个名字你大概率不会陌生。简单来说,Habitat-Lab是一个由Meta AI(前Facebook AI Research)开源的、用于具身…...

期权量化交易基础库:模块化设计与回测实战指南
1. 项目概述:一个为期权交易者打造的“地基” 如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会和我有同样的感受:每次想测试一个新想法,都得从零开始搭建数据接口、计算希腊字母、管理仓位、回测框架……这些重…...

机器学习工作流编排利器:machiney-engine 轻量级流水线引擎详解
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫Reidston/machiney-engine。光看名字,你可能会觉得这又是一个“机器学习引擎”或者“AI框架”,市面上这类项目多如牛毛,从TensorFlow、PyTorch这样的巨头࿰…...

ThinkPad风扇控制革命:TPFanCtrl2如何让你的笔记本更安静、更凉爽
ThinkPad风扇控制革命:TPFanCtrl2如何让你的笔记本更安静、更凉爽 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经在深夜工作时被ThinkPad风扇的…...
)
【2026最新】应对维普算法升级,5大降AI工具横测,一次稳降至25%(附手改秘籍)
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...