纠删码参数自适应匹配问题ECP-AMP实验方案(中)
6.方法设计
6.1.数据获取
为了收集不同的文件大小和纠删码参数对性能指标的影响,本文在Hadoop平台上进行了模拟实验。Hadoop是一种开源的分布式存储和计算框架,它可以支持不同类型的纠删码,并提供了一些应用程序接口和工具来测试和评估纠删码的性能 。
本文选取了以下六个性能指标作为评价纠删码参数选择的依据:
-
数据冗余度(DR):表示存储一个文件所需的编码块总数与数据块总数的比值,反映了存储空间的利用率。数据冗余度越小,表示存储空间利用率越高。在具有k个数据块和m个奇偶校验块的存储系统中,冗余度定义为 DR=m/(k+m)。
-
存储成本(SC):表示存储一个文件所需的编码块总数与单位编码块价格的乘积,反映了存储费用的开销。存储成本越小,表示存储费用开销越低。在具有k个数据块和m个奇偶校验块的存储系统中,存储成本定义为 SC=(k+m)/m。
-
传输开销(TO):传输开销是指纠删码在读写和恢复过程中消耗的网络带宽资源,它反映了纠删码对网络负载的影响。一般来说,传输开销越低,表示网络负载越低。传输成本TO定义为恢复工作负载传输的数据块数。
-
计算开销(CO):计算开销是指纠删码在编码和解码过程中消耗的计算资源,它反映了纠删码对系统性能的影响。计算成本定义为GF乘法/异或算法操作数。
-
可靠性(RE):表示在任意m个编码块丢失或损坏的情况下,仍然可以恢复原始文件的概率,反映了数据完整性的保障。可靠性越大,表示数据完整性保障越高。
R E = ∑ i = 0 m C k + m i p i ( 1 − p ) ( k + m − i ) RE=\sum_{i=0}^{m}C_{k+m}^ip^i(1-p)^{(k+m-i)} RE=∑i=0mCk+mipi(1−p)(k+m−i) -
恢复时间(RT):表示从任意k个编码块中恢复原始文件所需的时间,反映了数据恢复速度的效率。恢复性能越大,表示数据恢复速度越快。恢复性能 RP 是通过对恢复工作负载进行解码的平均开销(包括计算和访问成本)来衡量的 。
本文选取了以下四个变量作为影响纠删码参数选择的因素:
- 数据大小(filesize):表示一个文件占用的字节数,反映了文件内容的规模。文件大小范围为0MB-1GB,每隔10MB取一个值,共有101个值。
- 数据块个数(k):表示一个文件被分割成的数据块的个数,反映了文件分割的粒度。数据块个数范围为2-16,每隔1取一个值,共有15个值。
- 冗余块个数(m):表示一个文件生成的冗余块的个数,反映了文件编码的冗余度。冗余块个数范围为1-16,每隔1取一个值,共有16个值。
- 故障编码块个数(m’):表示一个文件在传输或存储过程中丢失或损坏的编码块的个数,反映了文件遭受的故障程度。故障编码块个数范围为0-m,每隔1取一个值,共有M+1个值。
本文使用了Reed-Solomon纠删码,这是一种现代的软件系统中随处可见的纠删码技术。
为了模拟不同文件大小和不同纠删码参数下的各项性能指标,我们使用了Hadoop软件作为实验平台。Hadoop是一种分布式计算框架,它可以将大量的数据存储在多个节点上,并通过MapReduce模型进行并行处理。Hadoop提供了一个分布式文件系统(HDFS),它可以支持纠删码技术的存储和访问。
我们搭建了一个由32个节点组成的Hadoop集群,每个节点都具有以下配置:
- CPU:Intel Core i7-8700K @ 3.70GHz
- 内存:16GB DDR4
- 硬盘:1TB SATA
- 网络:千兆以太网
我们在每个节点上安装了以下软件:
- 操作系统:Ubuntu 18.04 LTS
- Hadoop版本:3.2.2
- PyCharm版本:17.0.8+7-b1000.8 amd64
我们使用了以下数据集作为实验对象:
- 文件大小范围:0MB-1GB
- 文件类型:文本
- 文件数量:100个
我们将这些文件上传到HDFS中,并对每个文件应用不同的纠删码参数(k,m),其中k的范围为2-16,m的范围为1-16。我们使用了RS纠删码来生成和恢复冗余块。我们修改了Hadoop提供的内置纠删码配置来完成纠删码技术的编码和解码过程。
6.2.CRITIC确定权重
为了综合考虑各项性能指标,我们使用了critic客观权重法为这些指标赋权,计算出每种情况下的综合评分。
CRITIC(CRiteria Importance Through Intercriteria Correlation)方法,旨在确定多准则决策(MCDM,MutltipleCritier Decision Making) 问题中相对重要性的客观权重。它是基于评价指标的对比强度和指标之间的冲突性来综合衡量指标的客观权重。考虑指标变异性大小的同时兼顾指标之间的相关性,并非数字越大就说明越重要,完全利用数据自身的客观属性进行科学评价。
对比强度是指同一个指标各个评价方案之间取值差距的大小,以标准差的形式来表现。标准差越大,说明波动越大,即各方案之间的取值差距越大,权重会越高;
指标之间的冲突性,用相关系数进行表示,若两个指标之间具有较强的正相关,说明其冲突性越小,权重会越低。
对于 CRITIC 法而言,在标准差一定时,指标间冲突性越小,权重也越小;冲突性越大,权重也越大;另外,当两个指标间的正相关程度越大时,(相关系数越接近 1),冲突性越小,这表明这两个指标在评价方案的优劣上反映的信息有较大的相似性。
critic客观权重法的基本思想是:
- 如果一个属性的取值变化越大,说明该属性越能反映决策对象的差异性,因此该属性的权重应该越大。
- 如果一个属性与其他属性的相关性越高,说明该属性越能反映决策对象的整体性,因此该属性的权重应该越大。
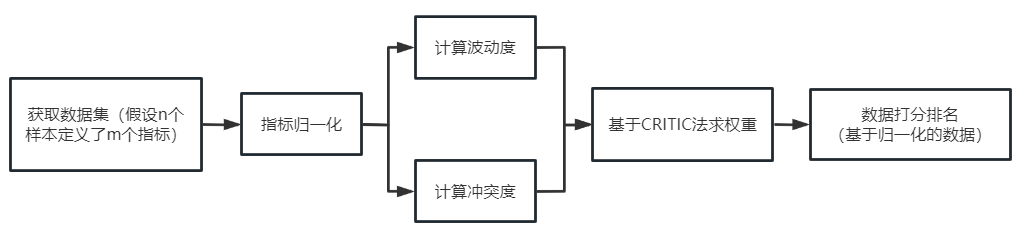
6.2.1.归一化处理
步骤一:为了消除不同性能指标的量纲和取值范围的影响,本文对收集的数据进行了归一化处理,使其取值在[0,1]之间。对于正向指标(越大越好),使用以下公式:
对于正向指标:
x i j ′ = X i j − m i n ( X 1 j , X 2 j , . . . , X n j ) m a x ( X 1 j , X 2 j , . . . , X n j ) − m i n ( X 1 j , X 2 j , . . . , X n j ) x'_{ij}=\frac{X_{ij}-min(X_{1j},X_{2j} ,...,X_{nj})}{max(X_{1j},X_{2j},...,X_{nj})-min(X_{1j},X_{2j},...,X_{nj})} xij′=max(X1j,X2j,...,Xnj)−min(X1j,X2j,...,Xnj)Xij−min(X1j,X2j,...,Xnj)
对于负向指标:
x i j ′ = m a x ( X 1 j , X 2 j , . . . , X n j ) − X i j m a x ( X 1 j , X 2 j , . . . , X n j ) − m i n ( X 1 j , X 2 j , . . . , X n j ) x'_{ij}=\frac{max(X_{1j},X_{2j} ,...,X_{nj})-X_{ij}}{max(X_{1j},X_{2j},...,X_{nj})-min(X_{1j},X_{2j},...,X_{nj})} xij′=max(X1j,X2j,...,Xnj)−min(X1j,X2j,...,Xnj)max(X1j,X2j,...,Xnj)−Xij
其中,x_ij是第i个文件在第j个指标上的原始值,x_ij是第i个文件在第j个指标上的标准化值。
6.2.2指标变异性
步骤二:对于每个指标,计算其差异系数,表示其差异程度。使用以下公式:
以标准差的形式来表现,Sj表示第j个指标的标准差:
{ x j ˉ = 1 n ∑ i = 1 n x i j S j = 1 n − 1 ∑ i = 1 n ( x i j − x ˉ j ) 2 \left\{\begin{matrix} \bar{x_j}=\frac{1}{n}\textstyle\sum_{i=1}^{n}x_{ij} \\ \\ \ S_j= \sqrt{\frac{1}{n-1}\sum_{i=1}^n (x_{ij}-\bar{x}_j)^2} \end{matrix}\right. ⎩ ⎨ ⎧xjˉ=n1∑i=1nxij Sj=n−11∑i=1n(xij−xˉj)2
在CRITIC法中使用指标差来表示各指标的内取值的差异波动情况,标准差越大表示该指标的数值差异越大,越能放映出更多的信息,该指标本身的评价强度也就越强,应该给该指标分配更多的权重。
6.2.3.指标冲突性
步骤三:对于每两个指标,计算其指标冲突性,表示指标间的相关性程度。使用以下公式:
R j = ∑ i = 1 p ( 1 − r i j ) R_j=\sum_{i=1}^{p}(1-r_{ij}) Rj=∑i=1p(1−rij)
以相关系数的形式来表现,rij表示评价指标i和j之间的相关系数。
使用相关系数来表示指标间的相关性,与其他指标的相关性越强,则该指标就与其他指标的冲突性越小,反映出相同的信息越多,所能体现的评价内容就越有重复之处,一定程度上也就削弱了该指标的评价强度,应该减少对指标分配的权重。
6.2.4.信息量
步骤四:对于每个指标,计算其信息熵权重,表示其重要程度,使用如下公式:
C j = S j ∑ i = 1 p ( 1 − r i j ) = S j ∗ R j C_j=S_j\sum_{i=1}^{p}(1-r_{ij})=S_j*R_j Cj=Sj∑i=1p(1−rij)=Sj∗Rj
Cj越大,第j个评价指标在整个评价指标体系的作用越大,就应该给其分配更多的权重。
6.2.5.权重
步骤五:对于每个指标,计算其critic权重,表示其综合影响能力。使用以下公式:
W j = C j ∑ j = 1 p C j W_j=\frac{C_j}{\textstyle\sum_{j=1}^{p}C_j} Wj=∑j=1pCjCj
所以第j个指标的客观权重Wj
6.2.6.赋值
步骤六:对于每种情况,计算其综合评分,表示其总性能。使用以下公式:
s i = ∑ j = 1 m v j ∗ x i j s_i=\sum_{j=1}^{m}v_j*x_{ij} si=∑j=1mvj∗xij
si表示第i中情况的综合评分。
得到各个指标使用critic权重法的权重,每个指标会获得一个如下的权重值。

将通过CRITIC方法得到的权重与原指标数据相乘,然后各指标相加得到一个综合指标评分goal,将每组filesize的goal数据做比较,选出最大的goal,然后将所有的filesize都依次得到,形成一张filesize,k,m,goal表,即达成目标。
6.3.DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise),DBSCAN聚类分析是一种基于密度的无监督学习算法,它可以在不需要指定簇的数量的情况下,根据数据点的密度将它们分成不同的簇,并且可以识别出噪声点和异常值。
6.3.1.DBSCAN聚类分析算法的计算公式:
给定一个数据集D={x1,x2,…,xn},其中xi是一个d维的向量,表示第i个数据点的特征。DBSCAN聚类分析需要两个参数:ϵ和MinPts,分别表示邻域的半径和最小密度点数。DBSCAN聚类分析的算法步骤如下:
- 从数据集D中任意选择一个未被访问过的点xi,标记为已访问。
- 计算xi的ϵ-邻域N(xi)={xj∈D∣d(xi,xj)≤ϵ},其中d(xi,xj)表示xi和xj之间的距离。
- 如果∣N(xi)∣≥MinPts,则将xi标记为核心点,并将N(xi)中的所有未被访问过的点加入一个队列Q,表示它们属于同一个簇C。
- 如果∣N(xi)∣<MinPts,则将xi标记为边界点或噪声点,并转到步骤6。
- 重复以下过程,直到队列Q为空:
- 从队列Q中弹出一个点xk,标记为已访问。
- 计算xk的ϵ-邻域N(xk)。
- 如果∣N(xk)∣≥MinPts,则将xk标记为核心点,并将N(xk)中的所有未被访问过的点加入队列Q,表示它们属于同一个簇C。
- 如果∣N(xk)∣<MinPts,则将xk标记为边界点。
- 如果数据集D中还有未被访问过的点,转到步骤1,否则结束算法。
6.3.2.现实中部署分组
我现在有一张最佳的file,k,m的表,我已经知道了各个文件大小如何选择数据块k,冗余块m的大小,将会得到最小的存储成本和最高的数据可靠性之间的权衡,但是如果说将这张表直接给公司,让公司给每个边缘服务器都部署上
unique((k,m))个文件配置显然是不合理的,因为每个配置文件都会生成对应的存储池,存储池的存在本身就会占用服务器的存储成本,如果在每个边缘服务器都生成unique((k,m))个文件配置对应的存储池,那存储消耗是巨大的,不可取的,故我们给出如下方案。
如,0MB–200MB被分为一大组,即小于140MB的文件的大组文件配置为k,m=(5,3)中,每大组的文件配置按最高的k,m配置向下兼容的方法,剩余数据按类似的方法进行分组,大约分5组即可,分组不能过多,不能超越超越总存储成本。
| filesize | k | m | goal |
|---|---|---|---|
| 10 | 2 | 1 | 0.86 |
| 20 | 2 | 2 | 0.75 |
| 30 | 3 | 1 | 0.78 |
| … | … | … | … |
| 190 | 4 | 3 | 0.78 |
| 200 | 5 | 3 | 0.92 |
相关文章:
纠删码参数自适应匹配问题ECP-AMP实验方案(中)
6.方法设计 6.1.数据获取 为了收集不同的文件大小和纠删码参数对性能指标的影响,本文在Hadoop平台上进行了模拟实验。Hadoop是一种开源的分布式存储和计算框架,它可以支持不同类型的纠删码,并提供了一些应用程序接口和工具来测试和评估纠删…...

在设计接口时,什么时候应该用路径参数,什么时候将数据保存到方法体中,它们各自的优势是什么?
在设计 RESTful API 接口时,选择将数据放在路径参数(Path Parameters)还是方法体(Request Body)中,取决于具体的需求和使用场景。每种方式都有其优势和适用的场景。 路径参数(Path Parameters&a…...

JVa冒泡排序
------------------------------冒泡排序--------------- let arry[1,2,3,4,5,6]; let temo;//容器交换 //两层循环 for(let i1;i<arry.length;i){ for(let j0;j<arry.length-i;j){ if(arry[j]>arry[j1]){ temparry[j]; arry[j]arry[j1]; arry[j1]temp; } } } console…...

10/11
一、ARM课程大纲 二、ARM课程学习的目的 2.1 为了找到一个薪资水平达标的工作(单片机岗位、驱动开发岗位) 应用层(APP) 在用户层调用驱动层封装好的API接口,编写对应的API接口 ----------------------------------------------------…...

C语言复习第6章 指针(未完成)
目录 一、内存单元与指针1.1 内存单元与内存单元的编号(地址/指针)1.2 内存单元的编号是如何产生的?1.3 地址/内存单元的编号/指针 本身是不需要保存的1.4 32/64位机器最多可以管理多大的内存空间?1.5 怎么计算指针(地址/编号)的大小 二、指针到指针变量2.1 怎么把二进制转换…...

Carrier Aggregation 笔记
### Carrier Aggregation 笔记 #### 引言 - Carrier Aggregation(CA)是 LTE 高级技术之一,srsRAN 4G 支持在 srsENB 和 srsUE 中进行双载波聚合。 - 使用 srsRAN 4G 进行 CA 实验需要能够调谐不同频率的 RF 设备,例如 Ettus Rese…...

JAVA的ArrayList 和 LinkedList的区别
ArrayList 和 LinkedList 都是 Java 中常用的 List 接口的实现类,主要的区别有: 1. 底层数据结构不同 -ArrayList 底层使用的是动态数组数据结构,LinkedList 底层使用的是双向链表数据结构。 2. 获取元素效率不同 ArrayList 支持快速随机访问,通过索引直接获取元素,时间复杂…...

AI知识库如何提升服装电商的运营效率
随着人工智能技术的飞速发展,AI知识库在服装电商领域的应用日益广泛。AI知识库作为一个集成了海量数据、通过高级算法进行智能分析和处理的信息系统,正在深刻改变服装电商的运营模式和效率。本文将详细阐述AI知识库在商品信息管理、库存管理、订单处理等…...
【使用fetch发送网络请求】远场通信服务)
鸿蒙开发(NEXT/API 12)【使用fetch发送网络请求】远场通信服务
场景介绍 发送一个HTTP请求,也可以设置请求头和请求体等参数,并返回来自服务器的HTTP响应。使用Promise异步回调。常用于获取资源,支持流处理和通过拦截器来处理请求和响应。 接口说明 接口名描述fetch(request: Request): Promise发送一个…...

详细解读“霸王面”战术
“霸王面”战术是指在没有得到雇主面试通知的情况下,强行加入面试,以此争取工作机会的求职策略。以下将以3000字左右的篇幅,通过生动形象的例子详细解释这一战术。 一、背景介绍 在当今竞争激烈的就业市场中,求职者需要经历网申…...

【网络安全】注册流程:电子邮件验证绕过
未经许可,不得转载。 文章目录 正文步骤1:修改电子邮件参数步骤2:拦截请求正文 目标:https://app.example.me 注册新账户时,需要输入邮箱进行注册,再在邮箱中验证链接。电子邮件验证链接如下所示: https://app.example.me/signup/activation?token=c6dc625e-5b5a-46…...

Spring和Spring Boot事务讲解和案例示范
引言 Spring框架提供了强大的事务管理支持,使得开发者能够更轻松地实现事务控制。在本篇文章中,我们将深入探讨Spring的事务管理机制,特别是编程式事务管理、声明式事务管理以及在多数据源环境下的事务处理。 第一章 编程式事务管理 编程式…...

前端的全栈混合之路Meteor篇:关于前后端分离及与各框架的对比
这篇属于番外,属于技术性的讨论文,主要谈一下可能困惑不少人的问题。meteor看似一个前后端混合的框架,但实际上它并不是前后端混合的,只是共享了一个数据结构(数据对象)。现实中很多团队都说是前后端分离的…...

OJ在线评测系统 微服务 OpenFeign调整后端下 nacos注册中心配置 不给前端调用的代码 全局引入负载均衡器
OpenFeign内部调用二 4.修改各业务服务的调用代码为feignClient 开启nacos注册 把Client变成bean 该服务仅内部调用,不是给前端的 将某个服务标记为“内部调用”的目的主要有以下几个方面: 安全性: 内部API通常不对外部用户公开,这样可以防止…...

QD1-P19 HTML 总结
本节简单总结:《前端学习笔记1》专题前18篇文章关于HTML的内容。 下一节开始学习CSS了。HTML还是挺易学的,比Linux命令容易。 本节视频 www.bilibili.com/video/BV1n64y1U7oj?p19 在前面18节中,我们了解了HTML的基础知识: …...

Android Framework AMS(03)AMS关键类解读
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要涉AMS的关键类及其设计理念的解读,主要关注图中下方AMS关键类解读部分即可。这么做的目的是为了后面章节分析AMS时更容易理解…...

Pygame开发贪吃蛇
Pygame专为Python设计,支持多平台(如Windows、Mac OS X、Linux、Android等),提供简单易用的API来创建2D游戏。它不仅仅局限于游戏开发,还可用于图形界面和音频应用。 Pygame提供了简洁的API,使得开发者可以…...

Linux进程间通信(个人笔记)
Linux进程通信 1.进程通信介绍1.1进程间通信目的1.2进程间通信发展1.3进程间通信的具体分类 2.管道2.1匿名管道2.1.1代码实例2.1.2 fork共享管道原理2.1.3 管道的读写规则与特点2.1.4 进程池 2.2 命名管道2.2.1 命名管道的创建2.2.2匿名管道与命名管道的区别2.2.3代码实例 3.Sy…...

SAP S/4HANA 迁移:IT 高管实用指南
新版《通往SAP S/4HANA之路》指南为计划从SAP ERP或SAP S/4HANA本地版本迁移到云端的组织提供了全面的参考。随着数字化转型的加速,尤其是在面临挑战的汽车行业等领域,企业必须采用云ERP解决方案,例如SAP S/4HANA云私有版,以应对瞬…...

Qt源码-Qt多媒体音频框架
Qt 多媒体音频框架 一、概述二、音频设计1. ALSA 基础2. Qt 音频类1. 接口实现2. alsa 插件实现 一、概述 环境详细Qt版本Qt 5.15操作系统Deepin v23代码工具Visual Code源码https://github.com/qt/qtmultimedia/tree/5.15 这里记录一下在Linux下Qt 的 Qt Multimedia 模块的设…...

TensorFlow GPU内存分配失败怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 TensorFlow GPU内存分配失败的终极解决方案:一招避坑指南 目录 TensorFlow GPU内存分配失败的终极解决方案࿱…...

TDengine数据迁移与备份实战:使用taosdump将2.x数据安全升级到3.0
TDengine 2.x到3.0数据迁移完全指南:从备份策略到避坑实践 时序数据库的版本升级往往伴随着数据迁移的挑战。当企业决定将TDengine从2.x升级到3.0时,如何确保数据安全迁移成为技术团队面临的首要问题。本文将深入解析使用taosdump工具进行数据迁移的全流…...

对比直接使用官方api体验taotoken在计费透明性与灵活性上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 在计费透明性与灵活性上的优势 在开发基于大模型的应用时,除了模型效果和稳定性&…...

DyDiT++动态计算架构:优化扩散模型效率
1. 动态计算架构DyDiT的核心设计理念 在生成式AI领域,扩散模型因其出色的生成质量而备受关注,但其高昂的计算成本一直是实际应用的主要瓶颈。传统静态架构在处理不同复杂度任务时采用相同的计算资源配置,这造成了显著的资源浪费。DyDiT通过动…...

Google关键词能带来多少流量?大词和长尾词的真实流量比例
一家销售软件的公司耗费六个月将“CRM”排至谷歌首页第五名。该词每月产生50万次搜索。网页获得2100次点击。跳出率高达89%。停留时间仅12秒。投入资金4万美元。获得零份询盘。做“外贸企业定制管理软件”排名首页第一。此词汇每月搜索量150次。每月收获62次点击。停留时间4分3…...

京东购物自动化评价:3步解放双手的Python智能助手
京东购物自动化评价:3步解放双手的Python智能助手 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 还在为京东购物后堆积如山的待评价订单烦恼吗?每次大促后面对几十个商…...
)
告别环境配置烦恼:用PHPStudy+VSCode搭建PHP调试环境(含XDebug配置避坑指南)
告别环境配置烦恼:用PHPStudyVSCode搭建PHP调试环境(含XDebug配置避坑指南) 刚接触PHP开发时,最令人头疼的莫过于环境配置。明明跟着教程一步步操作,却总是卡在某个环节无法继续。特别是XDebug调试器的配置,…...

高效管理300+模组:XCOM 2专业模组管理器AML完整指南
高效管理300模组:XCOM 2专业模组管理器AML完整指南 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/x…...

二维码识读设备选购全攻略:从核心需求到实战测试
1. 项目概述:为什么选对二维码识读设备这么重要?你可能觉得,不就是扫个码吗?手机摄像头都能搞定,专门的设备能有多大区别?我刚开始接触这个领域时也是这么想的,直到自己踩过几次坑,才…...

5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南
5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...