pytorh学习笔记——波士顿房价预测
机器学习的“hello world”:波士顿房价预测
波士顿房价预测的背景不用提了,简单了解一下数据集的结构。
波士顿房价的数据集,共有506组数据,每组数据共14项,前13项是影响房价的各种因素,比如:城镇人均犯罪率、一氧化氮浓度之类的,最后一项是基于前面的因素的房价。
一、逻辑框架

二、程序框架
import torch # 导入pytorch# data 解析数据# net # 搭建网络# loss # 计算损失# optimizer # 优化器# train # 训练# test # 测试1、训练的初步的脚本
新建demo_net.py,输入代码:
import torch# data 解析数据
import numpy as np
import reff = open('housing.data', 'r').readlines() # 读取数据
data = [] # 存储数据
for item in ff:out = re.sub(r'\s{2,}', ' ', item).strip() # 去除多余空格(将多个空格替换为一个空格)data.append(out.split(' ')) # 按照空格分割数据并添加到data中data = np.array(data, dtype=np.float32) # 转换为numpy数组
# print(data.shape) # 打印数据形状 (506, 14)
Y = data[:, -1] # 获取标签(所有行的最后一列)
X = data[:, :-1] # 获取特征(所有行的除最后一列的所有列)Y_train = Y[0:496, ...] # 训练集标签
X_train = X[0:496, ...] # 训练集特征
Y_test = Y[496:, ...] # 测试集标签
X_test = X[496:, ...] # 测试集特征# print(Y_train.shape) # 打印训练集标签形状 (496,)
# print(X_train.shape) # 打印训练集特征形状 (496, 13)
# print(Y_test.shape) # 打印测试集标签形状 (10,)
# print(X_test.shape) # 打印测试集特征形状 (10, 13)# net # 搭建网络
class Net(torch.nn.Module): # 定义网络def __init__(self, n_feature, n_output): # n_feature:输入特征数,n_output:输出特征数super(Net, self).__init__()self.predict = torch.nn.Linear(n_feature, n_output) # 定义网络结构(线性回归)def forward(self, x): # 前向传播y = self.predict(x)return ynet = Net(13, 1) # 实例化网络# loss # 计算损失
loss_func = torch.nn.MSELoss() # 定义损失函数(均方误差)# optimizer # 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.0001) # 定义优化器# train # 训练
x_data = torch.tensor(X_train, dtype=torch.float32) # 将训练集特征转换为tensor
y_data = torch.tensor(Y_train, dtype=torch.float32) # 将训练集标签转换为tensor
for i in range(10000): # 训练10000次pred = net.forward(x_data) # 前向传播,返回的是一个二维tensor# print(pred.shape) # 打印预测结果形状 (496, 1)pred = torch.squeeze(pred) # 由于返回的是二维的tensor,所以需要去掉维度为1的维度loss = loss_func(pred, y_data) # 计算损失optimizer.zero_grad() # 清空上一次的梯度loss.backward() # 反向传播optimizer.step() # 优化器更新参数if (i+1) % 1000 == 0: # 每1000次打印一次损失print('第{}次训练,损失为{}'.format(i+1, loss))print('预测结果为{}'.format(pred[:10]))print('真实结果为{}'.format(y_data[:10]))# test # 测试运行结果:
第1000次训练,损失为213.7091064453125
预测结果为tensor([30.3859, 35.9642, 30.5334, 27.4028, 29.8967, 30.7044, 31.1800, 38.9477,41.2886, 35.3080], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第2000次训练,损失为115.01570129394531
预测结果为tensor([25.6781, 28.8944, 24.1358, 20.5663, 22.7628, 23.5741, 26.7624, 33.8008,35.9616, 30.7862], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第3000次训练,损失为92.31402587890625
预测结果为tensor([24.9008, 25.9834, 22.5986, 19.7416, 21.3243, 21.9060, 25.3798, 30.4637,31.5297, 28.2170], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第4000次训练,损失为78.46049499511719
预测结果为tensor([24.7822, 24.7402, 22.6722, 20.6557, 21.6591, 21.9934, 24.7024, 27.8985,27.8058, 26.3184], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第5000次训练,损失为69.00062561035156
预测结果为tensor([24.8879, 24.1986, 23.2193, 21.9481, 22.4841, 22.6186, 24.2389, 25.9268,24.7516, 24.8738], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第6000次训练,损失为62.37424850463867
预测结果为tensor([25.2287, 24.1047, 23.8811, 23.1481, 23.3747, 23.3950, 23.9017, 24.6387,22.4893, 23.9274], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第7000次训练,损失为57.1735954284668
预测结果为tensor([25.7705, 24.3499, 24.5864, 24.1829, 24.2396, 24.2240, 23.6420, 23.9154,20.8723, 23.3721], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第8000次训练,损失为52.881893157958984
预测结果为tensor([26.3800, 24.6829, 25.2719, 25.0930, 25.0307, 25.0057, 23.3551, 23.3264,19.4090, 22.8640], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第9000次训练,损失为49.33217239379883
预测结果为tensor([26.9553, 24.9474, 25.9011, 25.8923, 25.7059, 25.6638, 22.9824, 22.6079,17.8117, 22.2006], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第10000次训练,损失为46.42286682128906
预测结果为tensor([27.4543, 25.1425, 26.4893, 26.5836, 26.2601, 26.1888, 22.5538, 21.7727,16.1070, 21.4219], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])看得出,当前的预测结果还是有很大的偏差的。
2、改进后的训练脚本
.提高学习率,将学习率设为0.01
第10000次训练,损失为22.985254287719727
预测结果为tensor([29.2464, 24.2876, 30.5644, 28.9724, 28.4927, 25.0255, 21.5255, 18.3571,10.0867, 17.6953], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])提高学习率之后,收敛更快,所以损失从46.4降到了22.9。
.增加训练次数,训练100000次
第100000次训练,损失为21.93065071105957
预测结果为tensor([30.0387, 25.0656, 30.6645, 28.7074, 28.0154, 25.3406, 22.7764, 19.2288,11.0369, 18.6134], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])增加训练次数后,损失略有下降,但不明显。
.加入隐藏层
将网络的定义更换为下面的代码:
# net # 搭建网络
class Net(torch.nn.Module): # 定义网络def __init__(self, n_feature, n_output): # n_feature:输入特征数,n_output:输出特征数super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100) # 定义隐藏层self.predict = torch.nn.Linear(100, n_output) # 定义网络结构(线性回归)def forward(self, x): # 前向传播y = self.hidden(x) # 隐藏层y = torch.relu(y) # 激活函数y = self.predict(y)return y运行结果:
第1000次训练,损失为16.16332244873047
预测结果为tensor([31.5807, 24.7012, 31.1625, 33.0276, 29.9564, 28.7967, 21.1699, 17.8390,11.0052, 17.8434], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第2000次训练,损失为10.760713577270508
预测结果为tensor([31.2304, 21.0812, 30.4874, 34.0178, 30.2638, 26.8140, 21.4654, 19.2940,15.2969, 18.9148], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第3000次训练,损失为9.041060447692871
预测结果为tensor([30.0590, 22.6623, 31.4998, 34.3279, 34.0962, 28.8110, 22.4006, 20.0406,17.4557, 19.8644], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第4000次训练,损失为7.654926776885986
预测结果为tensor([28.6500, 22.9828, 31.4478, 34.5795, 35.0444, 28.6649, 22.2122, 20.1728,17.4889, 19.9103], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第5000次训练,损失为7.204400539398193
预测结果为tensor([25.6355, 21.1540, 29.2047, 32.6562, 33.3360, 26.2489, 20.5876, 18.6758,15.7114, 18.5272], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第6000次训练,损失为4.584250450134277
预测结果为tensor([25.8020, 21.5723, 30.2412, 33.8467, 34.3686, 27.0365, 21.3067, 19.1034,16.5482, 19.0247], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第7000次训练,损失为3.7115399837493896
预测结果为tensor([26.3502, 21.7220, 30.8541, 34.7135, 35.1162, 27.7273, 22.0456, 19.7786,17.4401, 19.6452], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第8000次训练,损失为4.195467472076416
预测结果为tensor([25.8955, 21.2075, 30.6258, 34.2735, 34.5896, 27.4262, 21.6917, 19.4653,17.4221, 19.2694], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第9000次训练,损失为3.0317327976226807
预测结果为tensor([26.5321, 21.7933, 32.1591, 34.9432, 34.8340, 28.1285, 22.0055, 20.0637,18.4400, 19.3234], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第10000次训练,损失为2.727705478668213
预测结果为tensor([26.0240, 21.3191, 32.9476, 35.2049, 34.8349, 27.9297, 22.2083, 20.0651,18.3588, 18.8366], grad_fn=<SliceBackward0>)
真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
看得出,10000次训练后,损失已经降到了2.7,比起之前已经大有提高。
3、测试
加入测试代码后:
import torch# data 解析数据
import numpy as np
import reff = open('housing.data', 'r').readlines() # 读取数据
data = [] # 存储数据
for item in ff:out = re.sub(r'\s{2,}', ' ', item).strip() # 去除多余空格(将多个空格替换为一个空格)data.append(out.split(' ')) # 按照空格分割数据并添加到data中data = np.array(data, dtype=np.float32) # 转换为numpy数组
# print(data.shape) # 打印数据形状 (506, 14)
Y = data[:, -1] # 获取标签(所有行的最后一列)
X = data[:, :-1] # 获取特征(所有行的除最后一列的所有列)Y_train = Y[0:496, ...] # 训练集标签
X_train = X[0:496, ...] # 训练集特征
Y_test = Y[496:, ...] # 测试集标签
X_test = X[496:, ...] # 测试集特征# print(Y_train.shape) # 打印训练集标签形状 (496,)
# print(X_train.shape) # 打印训练集特征形状 (496, 13)
# print(Y_test.shape) # 打印测试集标签形状 (10,)
# print(X_test.shape) # 打印测试集特征形状 (10, 13)# net # 搭建网络
class Net(torch.nn.Module): # 定义网络def __init__(self, n_feature, n_output): # n_feature:输入特征数,n_output:输出特征数super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100) # 定义隐藏层self.predict = torch.nn.Linear(100, n_output) # 定义网络结构(线性回归)def forward(self, x): # 前向传播y = self.hidden(x) # 隐藏层y = torch.relu(y) # 激活函数y = self.predict(y)return ynet = Net(13, 1) # 实例化网络# loss # 计算损失
loss_func = torch.nn.MSELoss() # 定义损失函数(均方误差)# optimizer # 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.01) # 定义优化器# train # 训练
train_x_data = torch.tensor(X_train, dtype=torch.float32) # 将训练集特征转换为tensor
train_y_data = torch.tensor(Y_train, dtype=torch.float32) # 将训练集标签转换为tensor
test_x_data = torch.tensor(X_test, dtype=torch.float32) # 将测试集特征转换为tensor
test_y_data = torch.tensor(Y_test, dtype=torch.float32) # 将测试集标签转换为tensor
for i in range(10000): # 训练10000次pred_train = net.forward(train_x_data) # 前向传播,返回的是一个二维tensor# print(pred.shape) # 打印预测结果形状 (496, 1)pred_train = torch.squeeze(pred_train) # 由于返回的是二维的tensor,所以需要去掉维度为1的维度loss_train = loss_func(pred_train, train_y_data) # 计算损失optimizer.zero_grad() # 清空上一次的梯度loss_train.backward() # 反向传播optimizer.step() # 优化器更新参数# test # 测试pred_test = net.forward(test_x_data)pred_test = torch.squeeze(pred_test)loss_test = loss_func(pred_test, test_y_data) # 计算损失if (i+1) % 1000 == 0: # 每1000次打印一次损失print('第{}次训练,训练损失为{}'.format(i + 1, loss_train))print('训练预测结果为{}'.format(pred_train[:10]))print('训练真实结果为{}'.format(train_y_data[:10]))print('第{}次训练,测试损失为{}'.format(i + 1, loss_test))print('测试预测结果为{}'.format(pred_test[:10]))print('测试真实结果为{}'.format(test_y_data[:10]))运行结果:
C:\Users\DY\.conda\envs\torch\python.exe E:\AI_tset\boston\main.py
第1000次训练,训练损失为13.062897682189941
训练预测结果为tensor([32.4538, 22.4545, 31.6084, 34.6321, 30.7499, 28.7717, 21.2537, 18.4388,14.3816, 17.8076], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第1000次训练,测试损失为15.603384017944336
测试预测结果为tensor([17.2584, 20.4116, 21.6079, 19.7471, 20.3963, 21.4410, 21.3918, 28.3847,25.5809, 21.5427], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第2000次训练,训练损失为9.312514305114746
训练预测结果为tensor([28.3546, 20.2573, 28.6708, 33.5919, 31.0789, 25.5264, 20.3330, 18.5948,15.6572, 17.6856], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第2000次训练,测试损失为14.083860397338867
测试预测结果为tensor([18.4503, 20.9926, 22.3660, 20.1845, 21.4613, 22.1625, 20.6208, 28.3789,25.4795, 20.2372], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第3000次训练,训练损失为6.208388328552246
训练预测结果为tensor([28.0445, 21.0570, 29.5777, 34.5575, 34.3055, 28.3384, 20.9634, 19.6007,16.1345, 18.6369], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第3000次训练,测试损失为6.905886650085449
测试预测结果为tensor([16.9234, 19.6245, 21.3344, 18.5896, 20.3094, 21.4729, 19.0355, 24.3601,22.2127, 18.4200], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第4000次训练,训练损失为5.641458511352539
训练预测结果为tensor([25.9988, 21.0524, 29.1003, 33.8196, 34.5036, 27.8455, 20.7901, 19.6908,15.6711, 18.6173], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第4000次训练,测试损失为8.056257247924805
测试预测结果为tensor([17.5898, 20.1642, 21.8730, 19.0862, 21.0310, 22.3734, 19.6710, 24.7076,22.8086, 18.9423], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第5000次训练,训练损失为5.656107425689697
训练预测结果为tensor([25.2531, 20.6933, 28.9231, 32.7898, 34.1414, 27.3489, 20.4208, 19.7374,15.6711, 18.3137], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第5000次训练,测试损失为10.021121978759766
测试预测结果为tensor([19.1231, 20.8267, 22.5154, 19.6338, 21.5662, 23.3536, 20.3911, 25.4182,23.7853, 19.5190], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第6000次训练,训练损失为4.3244428634643555
训练预测结果为tensor([26.9243, 21.3463, 30.2934, 34.4237, 35.6593, 29.0201, 21.4505, 20.5173,17.6037, 18.9231], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第6000次训练,测试损失为6.1388702392578125
测试预测结果为tensor([19.1049, 20.0117, 21.6194, 18.9644, 20.5173, 22.2967, 19.1247, 23.9584,22.5197, 18.1853], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第7000次训练,训练损失为4.283013343811035
训练预测结果为tensor([27.0127, 22.1808, 30.9352, 35.3205, 36.2137, 29.5154, 21.7429, 20.6820,18.5019, 19.3641], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第7000次训练,测试损失为4.814659118652344
测试预测结果为tensor([18.5595, 19.3107, 21.0298, 18.4600, 19.9520, 21.3664, 17.8218, 23.2565,21.3452, 16.9308], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第8000次训练,训练损失为4.039644718170166
训练预测结果为tensor([26.9686, 22.5262, 31.3496, 35.2846, 36.3410, 29.3871, 21.7442, 20.7460,18.5969, 19.5158], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第8000次训练,测试损失为4.698439598083496
测试预测结果为tensor([18.2167, 19.3340, 21.3022, 18.2839, 20.1922, 21.6993, 17.1337, 23.3157,21.3075, 16.1727], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第9000次训练,训练损失为4.54683256149292
训练预测结果为tensor([23.9196, 20.3218, 29.5554, 32.8275, 34.2579, 27.2489, 20.4540, 18.9822,17.2778, 18.3638], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第9000次训练,测试损失为8.086548805236816
测试预测结果为tensor([19.2664, 20.9391, 22.9442, 19.6506, 21.8333, 23.6144, 18.8776, 24.7309,22.6941, 17.8243], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])
第10000次训练,训练损失为3.7810146808624268
训练预测结果为tensor([23.9642, 20.4657, 29.9442, 32.6707, 34.3400, 27.2285, 20.6211, 19.3677,17.7232, 18.5607], grad_fn=<SliceBackward0>)
训练真实结果为tensor([24.0000, 21.6000, 34.7000, 33.4000, 36.2000, 28.7000, 22.9000, 27.1000,16.5000, 18.9000])
第10000次训练,测试损失为7.744905948638916
测试预测结果为tensor([19.1582, 20.7719, 22.6360, 19.5414, 21.7677, 23.4768, 19.0810, 24.2579,22.2269, 17.9408], grad_fn=<SliceBackward0>)
测试真实结果为tensor([19.7000, 18.3000, 21.2000, 17.5000, 16.8000, 22.4000, 20.6000, 23.9000,22.0000, 11.9000])进程已结束,退出代码0
4、保存和加载
# 第一种保存和加载方法
torch.save(net.state_dict(), 'net_dict.pkl') # 保存模型参数
net.load_state_dict(torch.load('net_dict.pkl')) # 加载模型参数# 第二种保存和加载方法
torch.save(net, 'net.pkl') # 保存模型
torch.load('net.pkl') # 加载模型加入保存代码后的完整代码:
import torch# data 解析数据
import numpy as np
import reff = open('housing.data', 'r').readlines() # 读取数据
print(ff)
data = [] # 存储数据
for item in ff:out = re.sub(r'\s{2,}', ' ', item).strip() # 去除多余空格(将多个空格替换为一个空格)data.append(out.split(' ')) # 按照空格分割数据并添加到data中data = np.array(data, dtype=np.float32) # 转换为numpy数组
# print(data.shape) # 打印数据形状 (506, 14)
Y = data[:, -1] # 获取标签(所有行的最后一列)
X = data[:, 0:-1] # 获取特征(所有行的除最后一列的所有列)Y_train = Y[0:496, ...] # 训练集标签
X_train = X[0:496, ...] # 训练集特征
Y_test = Y[496:, ...] # 测试集标签
X_test = X[496:, ...] # 测试集特征# print(Y_train.shape) # 打印训练集标签形状 (496,)
# print(X_train.shape) # 打印训练集特征形状 (496, 13)
# print(Y_test.shape) # 打印测试集标签形状 (10,)
# print(X_test.shape) # 打印测试集特征形状 (10, 13)# net # 搭建网络
class Net(torch.nn.Module): # 定义网络def __init__(self, n_feature, n_output): # n_feature:输入特征数,n_output:输出特征数super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100) # 定义隐藏层self.predict = torch.nn.Linear(100, n_output) # 定义网络结构(线性回归)def forward(self, x): # 前向传播y = self.hidden(x) # 隐藏层y = torch.relu(y) # 激活函数y = self.predict(y)return ynet = Net(13, 1) # 实例化网络# loss # 计算损失
loss_func = torch.nn.MSELoss() # 定义损失函数(均方误差)# optimizer # 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.01) # 定义优化器# train # 训练
train_x_data = torch.tensor(X_train, dtype=torch.float32) # 将训练集特征转换为tensor
train_y_data = torch.tensor(Y_train, dtype=torch.float32) # 将训练集标签转换为tensor
test_x_data = torch.tensor(X_test, dtype=torch.float32) # 将测试集特征转换为tensor
test_y_data = torch.tensor(Y_test, dtype=torch.float32) # 将测试集标签转换为tensor
for i in range(10000): # 训练10000次pred_train = net.forward(train_x_data) # 前向传播,返回的是一个二维tensor# print(pred.shape) # 打印预测结果形状 (496, 1)pred_train = torch.squeeze(pred_train) # 由于返回的是二维的tensor,所以需要去掉维度为1的维度loss_train = loss_func(pred_train, train_y_data) # 计算损失optimizer.zero_grad() # 清空上一次的梯度loss_train.backward() # 反向传播optimizer.step() # 优化器更新参数# test # 测试pred_test = net.forward(test_x_data)pred_test = torch.squeeze(pred_test)loss_test = loss_func(pred_test, test_y_data) # 计算损失if (i+1) % 1000 == 0: # 每1000次打印一次损失print('第{}次训练,训练损失为{}'.format(i + 1, loss_train))print('训练预测结果为{}'.format(pred_train[:10]))print('训练真实结果为{}'.format(train_y_data[:10]))print('第{}次测试,测试损失为{}'.format(i + 1, loss_test))print('测试预测结果为{}'.format(pred_test[:10]))print('测试真实结果为{}'.format(test_y_data[:10]))# # 第一种保存和加载方法
# torch.save(net.state_dict(), 'net_dict.pkl') # 保存模型参数
# net.load_state_dict(torch.load('net_dict.pkl')) # 加载模型参数# 第二种保存和加载方法
torch.save(net, 'net.pkl') # 保存模型
# torch.load('net.pkl') # 加载模型
print('已保存')5、推理
新建inference.py,输入:
import torch
# from demo_net import Net # 使用这种方法会重复训练
# data 解析数据
import numpy as np
import reclass Net(torch.nn.Module): # 定义网络 # 将之前定义的网络复制过来def __init__(self, n_feature, n_output): # n_feature:输入特征数,n_output:输出特征数super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100) # 定义隐藏层self.predict = torch.nn.Linear(100, n_output) # 定义网络结构(线性回归)def forward(self, x): # 前向传播y = self.hidden(x) # 隐藏层y = torch.relu(y) # 激活函数y = self.predict(y)return yff = open('housing.data', 'r').readlines() # 读取数据
data = [] # 存储数据
for item in ff:out = re.sub(r'\s{2,}', ' ', item).strip() # 去除多余空格(将多个空格替换为一个空格)data.append(out.split(' ')) # 按照空格分割数据并添加到data中data = np.array(data).astype(np.float32) # 转换为numpy数组
# print(data.shape) # 打印数据形状 (506, 14)
Y = data[:, -1] # 获取标签(所有行的最后一列)
X = data[:, :-1] # 获取特征(所有行的除最后一列的所有列)Y_train = Y[0:496, ...] # 训练集标签
X_train = X[0:496, ...] # 训练集特征
Y_test = Y[496:, ...] # 测试集标签
X_test = X[496:, ...] # 测试集特征net = torch.load('net.pkl')
loss_func = torch.nn.MSELoss() # 定义损失函数(均方误差)test_x_data = torch.tensor(X_test, dtype=torch.float32) # 将测试集特征转换为tensor
test_y_data = torch.tensor(Y_test, dtype=torch.float32) # 将测试集标签转换为tensor
pred_test = net.forward(test_x_data)
pred_test = torch.squeeze(pred_test)
loss_test = loss_func(pred_test, test_y_data) # 计算损失print('测试集预测结果:', pred_test)
print('测试集实际结果:', Y_test)
print('测试集损失:', loss_test) # 打印测试集损失运行后,直接得出了推理结果:
测试集预测结果: tensor([17.9976, 20.7273, 22.6870, 19.7387, 22.0204, 23.5350, 19.9008, 23.2567,22.4825, 18.6679], grad_fn=<SqueezeBackward0>)
测试集实际结果: [19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9 22. 11.9]
测试集损失: tensor(9.1494, grad_fn=<MseLossBackward0>)存疑:在推理的脚本里使用torch.load()调用之前自定义并保存的网络,如使用from demo_net import Net的方法调用,运行推理脚本后,则会又执行一次训练过程。而将之前定义的网络直接复制到推理脚本则不会。
相关文章:
pytorh学习笔记——波士顿房价预测
机器学习的“hello world”:波士顿房价预测 波士顿房价预测的背景不用提了,简单了解一下数据集的结构。 波士顿房价的数据集,共有506组数据,每组数据共14项,前13项是影响房价的各种因素,比如&…...
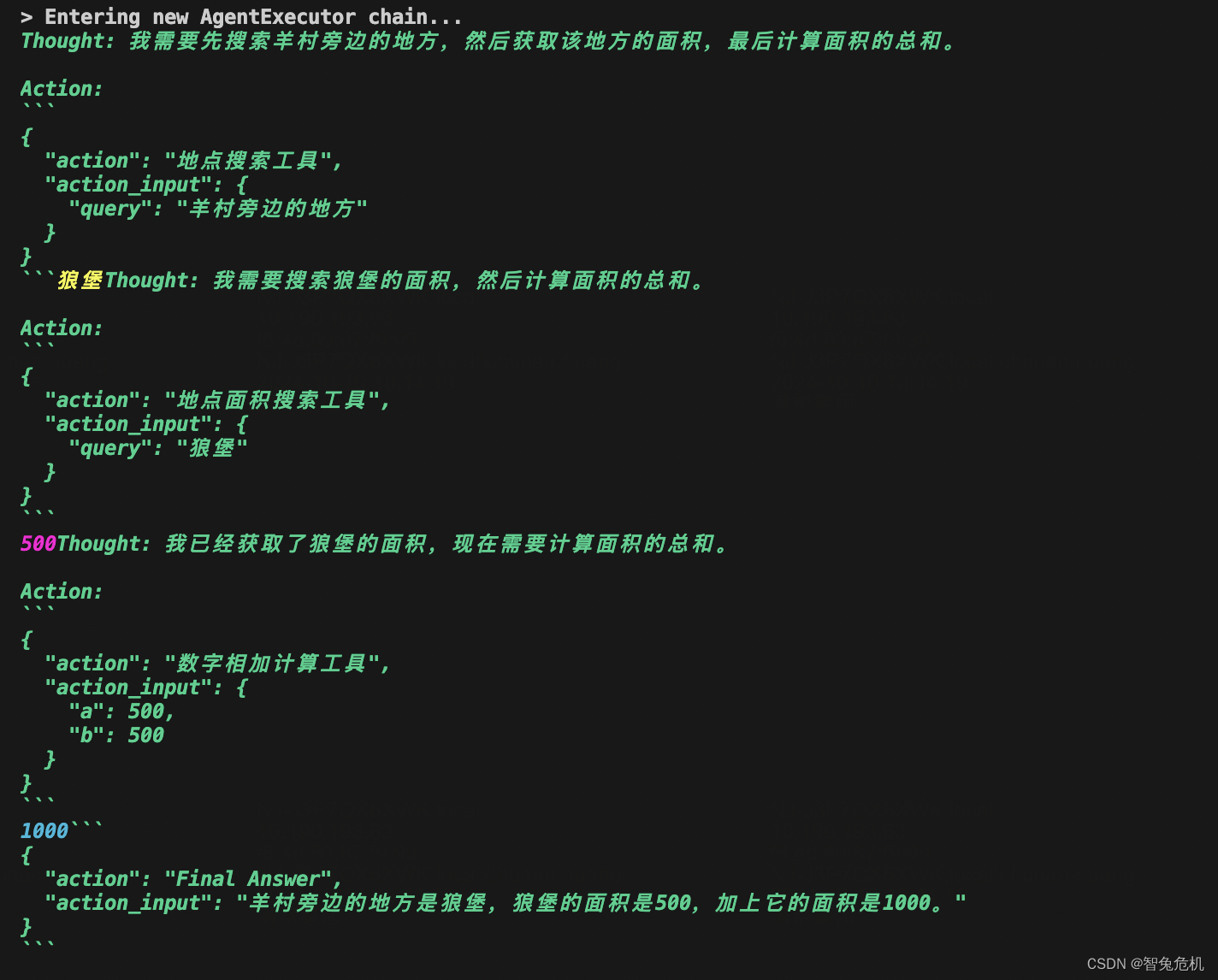
让AI像人一样思考和使用工具,reAct机制详解
reAct机制详解 reAct是什么reAct的关键要素reAct的思维过程reAct的代码实现查看效果引入依赖,定义模型定义相关工具集合工具创建代理启动测试完整代码 思考 reAct是什么 reAct的核心思想是将**推理(Reasoning)和行动(Acting&…...

Linux系列-常见的指令(二)
🌈个人主页: 羽晨同学 💫个人格言:“成为自己未来的主人~” mv 剪切文件,目录 重命名 比如说,我们在最开始创建一个新的文件hello.txt 然后我们将这个文件改一个名字,改成world.txt 所以,…...

Leecode刷题之路第17天之电话号码的字母组合
题目出处 17-电话号码的字母组合-题目出处 题目描述 个人解法 思路: todo 代码示例:(Java) todo复杂度分析 todo 官方解法 17-电话号码的字母组合-官方解法 方法1:回溯 思路: 代码示例:&a…...

2023牛客暑期多校训练营3(题解)
今天下午也是小小的做了一下,OI,也是感觉手感火热啊,之前无意间看到的那个哥德巴赫定理今天就用到了,我以为根本用不到的,当时也只是感兴趣看了一眼,还是比较激动啊 话不多说,直接开始看题 Wo…...

Magnum IO
NVIDIA Magnum IO 文章目录 前言加速数据中心 IO 性能,随时随地助力 AINVIDIA Magnum IO 优化堆栈1. 存储 IO2. 网络 IO3. 网内计算4. IO 管理跨数据中心应用加速 IO1. 数据分析Magnum IO 库和数据分析工具2. 高性能计算Magnum IO 库和 HPC 应用3. 深度学习Magnum IO 库和深度…...

Flink job的提交流程
在Flink中,作业(Job)的提交流程是一个复杂的过程,涉及多个组件和模块,包括作业的编译、优化、序列化、任务分发、任务调度、资源分配等。Flink通过分布式架构来管理作业的生命周期,确保作业在不同节点上以高…...

git操作pull的时候出现冲突怎么解决
问: PS C:\Users\fury_123\Desktop\consumptionforecast> git branch * dev main PS C:\Users\fury_123\Desktop\consumptionforecast> git add . PS C:\Users\fury_123\Desktop\consumptionforecast> git commit -m 修改部分样式 [dev 74693e0] 修改部分样…...

Sentinel 1.80(CVE-2021-44139)
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性 Report a Sentinel Security Vulnerability …...

黑马程序员C++提高编程学习笔记
黑马程序员C提高编程 提高阶段主要针对泛型编程和STL技术 文章目录 黑马程序员C提高编程一、模板1.1 函数模板1.1.1 函数模板基础知识 案例一: 数组排序1.2.1 普通函数与函数模板1.2.2 函数模板的局限性 1.2 类模板1.2.1 类模板的基础知识1.2.2 类模板与函数模板1.…...

力扣第1题:两数之和(图解版)
Golang版本 func twoSum(nums []int, target int) []int {m : make(map[int]int)for i : range nums {if _, ok : m[target - nums[i]]; ok {return []int{i, m[target - nums[i]]}} m[nums[i]] i}return nil }...

aws(学习笔记第三课) AWS CloudFormation
aws(学习笔记第三课) 使用AWS CloudFormation 学习内容: AWS CloudFormation的模板解析使用AWS CloudFormation启动ec2 server 1. AWS CloudFormation 的模版解析 CloudFormation模板结构 CloudFormation是AWS的配置管理工具,属于Infrastructure as Co…...

浅学React和JSX
往期推荐 一文搞懂大数据流式计算引擎Flink【万字详解,史上最全】-CSDN博客 数仓架构:离线数仓、实时数仓Lambda和Kappa、湖仓一体数据湖-CSDN博客 一文入门大数据准流式计算引擎Spark【万字详解,全网最新】_大数据 spark-CSDN博客 浅谈维度建…...

React 为什么 “虚拟 DOM 顶部有很多 provider“?
1、介绍React中的Context Provider 在 React 中,虚拟 DOM(Virtual DOM)是 React 用来高效更新 UI 的核心机制,它通过对比前后两次虚拟 DOM 树,确定哪些部分需要更新,以减少直接操作真实 DOM 的开销。而 “…...

忘记了 MySQL 8.0 的 root 密码,应该怎么办?
如果你忘记了 MySQL 8.0 的 root 密码,可以通过以下步骤来重置密码。请注意,这些步骤需要你有对 MySQL 服务器的物理或命令行访问权限。 步骤 1: 停止 MySQL 服务 首先,你需要停止正在运行的 MySQL 服务。你可以使用以下命令来停止 MySQL 服…...
)
Promise.reject()
Promise.reject() 静态方法返回一个已拒绝(rejected)的 Promise 对象,拒绝原因为给定的参数。 语法 Promise.reject(reason)参数 reason 该 Promise 对象被拒绝的原因。 返回值 返回一个已拒绝(rejected)的 Promi…...

大数据-163 Apache Kylin 全量增量Cube的构建 手动触发合并 JDBC 操作 Scala
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

云手机与传统手机的区别是什么?
随着科技的快速进步,云手机逐渐成为手机市场的热门选择。与传统的智能手机相比,云手机具有许多独特的功能和优势,尤其在多账号管理和高效操作方面备受关注。那么,云手机究竟与普通手机有哪些区别呢? 1. 更灵活的操作与…...

微知-Bluefield DPU命名规则各字段作用?BF2 BF3全系列命名大全
文章目录 背景字段命名C是bmc的意思NOT的N是是否加密S表示不加密但是secureboot enable倒数第四个都是E倒数第五个是速率 V和H是200GM表示E serials,H表示P serials(区别参考兄弟篇:[more](https://blog.csdn.net/essencelite/article/detail…...
)
Ubuntu 上使用 Nginx 实现反向代理并启用 HTTPS(详细教程)
拒绝使用宝塔,虽然宝塔很好用方便,但是他非常占用资源,所以我正在尝试转换我使用服务器的方式,通过命令来才做这些,下面是我的详细步骤。 在这篇教程中,我们将详细介绍如何在 Ubuntu 系统上使用 Nginx 搭建…...

VK视频下载器:三步实现VKontakte视频永久保存的实用方案
VK视频下载器:三步实现VKontakte视频永久保存的实用方案 【免费下载链接】VK-Video-Downloader Скачивайте видео с сайта ВКонтакте в желаемом качестве 项目地址: https://gitcode.com/gh_mirrors/vk/VK-Video…...

WaveTools深度解析:鸣潮性能调优与数据统计的技术实现
WaveTools深度解析:鸣潮性能调优与数据统计的技术实现 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 为什么传统游戏优化方法在鸣潮中失效? 我们在实际测试中发现,鸣潮…...

【免费下载】 探索双面神技:STM32G474的USB跨界应用
探索双面神技:STM32G474的USB跨界应用 在物联网与嵌入式开发的世界里,寻找一款能兼顾数据传输与控制沟通的神器是每个开发者的心头好。今天,我们就来揭秘这样一个宝藏项目——STM32G474实现USB的MSCCDC组合功能,它巧妙地将STM32G4…...

【亲测免费】 VisionPro培训文档全中文版
VisionPro培训文档全中文版 【下载地址】VisionPro培训文档全中文版 VisionPro培训文档全中文版欢迎使用VisionPro培训文档全中文版!本资源是专为机器视觉领域从业者及学习者精心准备的一套全面指南,旨在帮助您快速掌握VisionPro软件的强大功能与应用技巧…...

探索Qt高级停靠系统:打造灵活强大的用户界面
探索Qt高级停靠系统:打造灵活强大的用户界面 【下载地址】Qt-Advanced-Docking-System使用教程与示例代码 Qt-Advanced-Docking-System 使用教程与示例代码本仓库提供了一个关于如何使用 Qt-Advanced-Docking-System 的详细教程及示例代码 项目地址: https://gitc…...

AI Agent设计模式:从ReAct到Plan-and-Execute
Agent 设计模式:ReAct 与 Plan-Execute 讲透Function Calling 让 Agent 会用工具,但真正让 Agent「聪明」的,是它的思考模式。这就像给你一本字典不意味着你会写文章——你需要方法论。ReAct 和 Plan-Execute 就是 Agent 的两种核心方法论。一…...

3步掌握LRC歌词制作:开源工具的终极实践指南
3步掌握LRC歌词制作:开源工具的终极实践指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作精准同步的歌词文件而烦恼吗?传统歌词…...

凌晨两点还在逐行审计?DeepAudit 让我从焦虑到上瘾
前言 说起来不怕你们笑话,前段时间接了个小项目,上线前代码审计那几天,我基本天天熬到凌晨两点才敢合眼。不是我不想睡,是真睡不着——脑子里反复过那些没检查到的角落,SQL注入、XSS、权限绕过……每个词都像悬在头顶的…...

抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南
抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频盛行的时代,抖音作为内容创作的宝库,汇聚了海…...

ncmdump终极解密指南:如何快速解锁网易云音乐NCM加密文件
ncmdump终极解密指南:如何快速解锁网易云音乐NCM加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否遇到过这样的困扰?在网易云音乐下载的歌曲只能在特定播放器中使用,换到其他设备或播…...